一种肺癌筛查患者就医行为偏好推测方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及肺癌数据处理技术领域,尤其是涉及一种肺癌筛查患者就医行为偏好推测方法。
背景技术
近年来,基于低剂量螺旋CT的肺癌筛查技术的筛查效果进一步被证实,并且在高危人群选择、筛查间隔及肺结节管理的研究方面取得了显著进展。但是由于普及率偏低和有限资源的配置错位导致进行该项筛查的人数偏低,进而导致肺癌筛查效果不佳。精准的患者肺癌筛查就医行为偏好推测有利于管理者了解患者行为,并进一步促进肺癌筛查医疗资源优化配置,从而从根本上协助解决上述问题。
目前对于患者肺癌筛查就医行为的预测模型少,且大多研究是仅考虑单个医疗机构内人群流向、就诊人次及排队等因素。针对患者就诊医院偏好,传统的二元Logistic回归模型仅适用于小范围预测,当特征空间大且特征变量复杂时,该方法预测性能较差且容易出现欠拟合的情况。而传统人工神经网络、支持向量机等机器学习模型解释性较差,对深层次理解多变量系统带来了较大困难。在实际情况中,影响因素复杂多变、数据空间庞大,因此运用这些传统的模型无法准确测度和理解系统多元特征变量并进行更为精准的预测。相比之下,贝叶斯网络提供了一种概率图的建模框架,通过有向无环图表示多个变量的复杂关系,适用于解决非线性及蕴含不确定性的问题。该类模型可以有效推断数据缺失值、融合多源数据、捕捉并深度理解特征变量之间的复杂因果关系,为患者肺癌筛查就医行为的推测提供了一种更具潜力的方法。
发明内容
本发明的目的是提供一种肺癌筛查患者就医行为偏好推测方法,解决了普通模型无法做出精确的预测的问题,且利用目前数据信息形成网络关联关系,将先验信息与样本知识有机结合起来,促进了先验知识和数据的集成,保证样本数据稀疏或数据较难获得时依旧可进行准确推测,解决传统模型数据样本获取少而推测不准确和对多变量系统解释性欠佳的问题。
为实现上述目的,本发明提供了一种肺癌筛查患者就医行为偏好推测方法,包括以下步骤:
S1、通过问卷调研获取数据,对收集的数据进行预处理,筛选影响就医行为偏好的变量;
S2、将步骤S1中筛选出的影响就医行为偏好的变量进行变量定义,形成数据集;
S3、根据步骤S2中定义的影响就医行为偏好的变量确定贝叶斯网络模型的隐变量,并优化隐变量状态数;
S4、利用步骤S2中的变量及步骤S3中确定的隐变量构建隐变量结构化改进的贝叶斯网络;
S5、利用步骤S4中构建的隐变量结构化改进的贝叶斯网络及实际调研数据训练得到训练好的模型,并依据该模型进行推理预测;
S6、利用步骤S4中构建隐变量结构化改进的贝叶斯网络及步骤S5中采用实际数据训练好的模型进一步识别影响患者就医行为偏好的敏感可控变量。
优选的,步骤S1中,剔除收集数据中的非基本特征,将影响就医行为偏好的变量分为个人基本特征和医疗健康特征两类;
其中,个人基本特征包括年龄、文化程度、家庭收入、性别、现居地五种影响变量;医疗健康特征包括家族史、肺癌了解度、CT筛查、筛查原因、医疗保险和健康体检六种影响变量;
针对推测目标,包括筛查机构和就诊医院两种变量;其中就诊医院为最终目标变量,用以表达患者就医行为的偏好。
优选的,步骤S2中,对筛选出的影响就医行为偏好的变量进行变量定义,形成数据集,包括以下步骤:
S21、将步骤S1选取的13种变量数据进行变量定义,并且为每个变量选取变量状态;为减少空间复杂程度,每个变量状态根据实际情况区分为2~4个层次;
具体变量状态划分方式为:性别为男和女;现居地、筛查机构、就诊医院按区域划分为省级和非省级;家族史、医疗保险、肺癌了解度、CT筛查为是和否的判断状态,其中,CT筛查中加入遗忘选项;筛查原因划分为家人朋友建议、医生建议、体检结果及抽烟影响四种状态,年龄、文化程度、家庭收入按阶段划分为高、中、低三种状态;健康体检按频次划分为从未、偶尔和经常三种状态;
S22、将步骤S21中定义好的数据组成建模数据集,建模数据集包括数据集1和数据集2,其中数据集1用于后续改进的贝叶斯网络学习,数据集2用于测试改进网络的推测准确性。
优选的,步骤S3中,确定隐变量及优化隐变量状态数,包括以下步骤:
S31、依据步骤S1中选取的个人基本特征及医疗健康特征两大类影响因素,引入两个隐变量:个人条件隐变量和医疗条件隐变量;
S32、进行隐变量状态数优化,利用KLD作为目标准则,用于衡量两个概率分布之间的差异性,KLD散度表示为:
其中,R为隐变量的状态数,K为隐变量的不同状态的索引;ρ
优选的,步骤S4中,构建隐变量结构化改进的贝叶斯网络,确定个人基本特征及医疗健康特征两大类影响因素中的多变量关联关系,根据关联关系及步骤S31确定的隐变量将多变量连接在一起,形成隐变量结构化的贝叶斯网络结构;其中,具有关联关系的多变量为家族史、健康体检、肺癌了解程度和筛查原因等变量。
优选的,步骤S5中,针对构建的模型结构采用实际数据训练得到最佳模型,并借助该模型进行推理预测,包括以下步骤:
S51、利用期望最大化算法进行网络参数学习:首先选择所有节点,将所有条件概率分布表随机化,并进行网络编译;将步骤S2中准备好的数据集1导入进行网络参数学习,迭代后,记录似然值;
S52、重复步骤S51执行多次重启的期望最大化算法,比较所有记录的对数似然值,选出对数似然值最大的模型作为最优模型,该最优模型即是训练好的模型;
S53、借助步骤S52训练好的模型,推断后验概率P(I=i|E=e),其公式表示为:
就目标变量而言,E为证据变量,即网络中的多个影响因素,e为E的实例化,I表示目标变量,真实的人群就医医院选择,i表示目标变量的实例化,R表示目标变量的最大状态数;通过隐变量结构化改进的贝叶斯网络,导入新数据进行学习推断,得出人群就诊医院偏好。
优选的,步骤S6中,采用方差减缩法进行变量敏感性分析,并识别影响患者就医行为偏好的敏感可控变量,包括以下步骤:
S61、变量敏感性分析,其中,变量X
其中,
其中,x
S62、敏感可控变量识别,基于可控性视角,区分个人基本特征和医疗健康特征两大类影响变量中的可控变量与不可控变量,其中,肺癌了解度、CT筛查、筛查原因、健康体检以及医疗保险五种影响变量是可控的;通过区分可控变量X
因此,本发明采用上述一种肺癌筛查患者就医行为偏好推测方法,其技术效果如下:
(1)本发明描述数据间的相互关系,易于理解,可直观性、给出预测结果,同时看出各特征变量对目标变量的影响程度,以便有针对性地提出政策建议,通过政策干预相关变量,最终改善患者的就医体验。
(2)基于隐变量结构化改进的贝叶斯网络,相比于具有相当网络规模的一般贝叶斯网络具有更小的参数空间、更小的计算复杂度和更好的泛化性能,可应对不确定性、非线性和多变量关系等复杂情景。利用目前数据信息形成网络关联关系,将先验信息与样本知识有机结合起来,促进了先验知识和数据的集成,保证样本数据稀疏或数据较难获得时依旧可进行准确推测,解决传统模型数据样本获取少而推测不准确和对多变量系统解释性欠佳的问题。
(3)利用该网络,探究得出收入是影响居民就诊医院的重要变量,这体现于居民的医疗费用支付水平,由此建议将该项检查纳入医保,以减少居民的负担,也便于肺癌筛查新技术的推广;此外,利用该网络可认知到肺癌了解程度是影响居民就医偏好重要的特征变量,因此肺癌相关知识的普及和新技术的推广成为重点方向。
(4)由预测结果可知,存在较大数量的居民倾向于在非省级医院进行肺癌筛查,而相较于省级医院发达的技术及设备,基层医疗存在一定的差距。由此,可提出加强基层医疗机构政策扶持,对低收入、偏远地区群体实行相应的医疗帮扶;加强基层医疗机构的资源投入,将新的技术普及到基层医院等建议。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
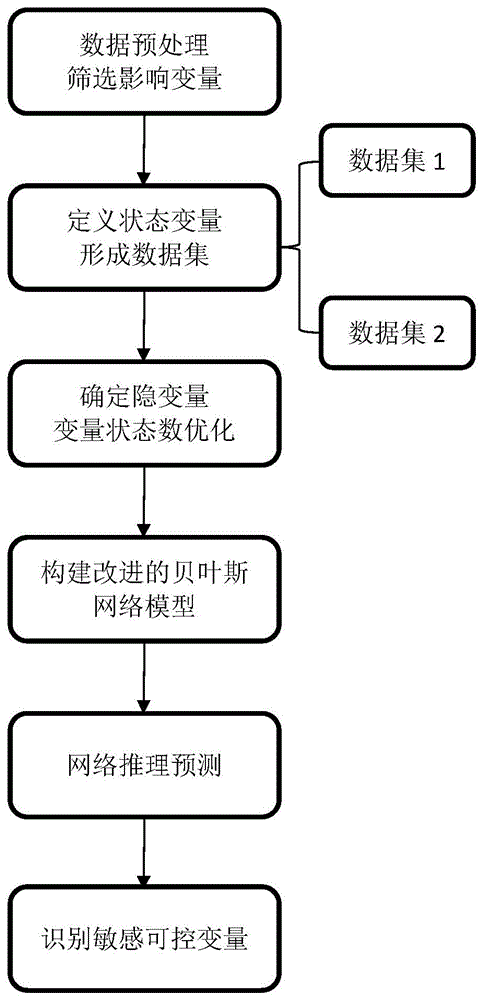
图1为一种肺癌筛查患者就医行为偏好推测方法的整体流程示意图;
图2为成都市居民就医偏好推测贝叶斯网络建模图。
具体实施方式
以下通过附图和实施例对本发明的技术方案作进一步说明。
除非另外定义,本发明使用的技术术语或者科学术语应当为本发明所属领域内具有一般技能的人士所理解的通常意义。
实施例一
如图1所示,本发明一种肺癌筛查患者就医行为偏好推测方法,包括以下步骤:
S1、通过问卷调研获取数据,对收集的数据进行预处理,筛选影响就医行为偏好的变量;
剔除收集数据中的非基本特征,将影响就医行为偏好的变量分为个人基本特征和医疗健康特征两类;
其中,个人基本特征包括年龄、文化程度、家庭收入、性别、现居地五种影响变量;医疗健康特征包括家族史、肺癌了解度、CT筛查、筛查原因、医疗保险和健康体检六种影响变量;
针对推测目标,包括筛查机构和就诊医院两种变量;其中就诊医院为最终目标变量,用以表达患者就医行为的偏好。
S2、将步骤S1中筛选出的影响就医行为偏好的变量进行变量定义,形成数据集;
S21、将步骤S1选取的13种变量数据进行变量定义,并且为每个变量选取变量状态;为减少空间复杂程度,每个变量状态根据实际情况区分为2~4个层次;
具体变量状态划分方式为:性别为男和女;现居地、筛查机构、就诊医院按区域划分为省级和非省级;家族史、医疗保险、肺癌了解度、CT筛查为是和否的判断状态,其中,CT筛查中加入遗忘选项;筛查原因划分为家人朋友建议、医生建议、体检结果及抽烟影响四种状态,年龄、文化程度、家庭收入按阶段划分为高、中、低三种状态;健康体检按频次划分为从未、偶尔和经常三种状态;
S22、将步骤S21中定义好的数据组成建模数据集,建模数据集包括数据集1和数据集2,其中数据集1用于后续改进的贝叶斯网络学习,数据集2用于测试改进网络的推测准确性。
S3、根据步骤S2中定义的影响就医行为偏好的变量确定贝叶斯网络模型的隐变量,并优化隐变量状态数;
S31、依据步骤S1中选取的个人基本特征及医疗健康特征两大类影响因素,引入两个隐变量:个人条件隐变量和医疗条件隐变量;
S32、进行隐变量状态数优化,利用KLD作为目标准则,用于衡量两个概率分布之间的差异性,KLD表示为:
其中,R为隐变量的状态数,K为隐变量的不同状态的索引;ρ
S4、利用步骤S2中的变量及步骤S3中确定的隐变量构建隐变量结构化改进的贝叶斯网络;
步骤S4中,构建隐变量结构化改进的贝叶斯网络,确定个人基本特征及医疗健康特征两大类影响因素中的多变量关联关系,根据关联关系及步骤S31确定的隐变量将多变量连接在一起,形成隐变量结构化的贝叶斯网络结构;其中,具有关联关系的多变量为家族史、健康体检、肺癌了解程度和筛查原因等变量。
S5、利用步骤S4中构建的隐变量结构化改进的贝叶斯网络及实际调研数据训练得到训练好的模型,并依据该模型进行推理预测;
步骤S5中,针对构建的模型结构采用实际数据训练得到最佳模型,并借助该模型进行推理预测,包括以下步骤:
S51、利用期望最大化算法进行网络参数学习:首先选择所有节点,将所有条件概率分布表随机化,并进行网络编译;将步骤S2中准备好的数据集1导入进行网络参数学习,迭代后,记录似然值;
S52、重复步骤S51执行多次重启的期望最大化算法,比较所有记录的对数似然值,选出对数似然值最大的模型作为最优模型,该最优模型即是训练好的模型;
S53、借助步骤S52训练好的模型,推断后验概率P(I=i|E=e),其公式表示为:
就目标变量而言,E为证据变量(可为多变量组合),即网络中的多个影响因素,e为E的实例化,I表示目标变量,真实的人群就医医院选择,i表示目标变量的实例化,R表示目标变量的最大状态数;通过隐变量结构化改进的贝叶斯网络,导入新数据进行学习推断,得出人群就诊医院偏好。
S6、利用步骤S4中构建隐变量结构化改进的贝叶斯网络及步骤S5中采用实际数据训练好的模型进一步识别影响患者就医行为偏好的敏感可控变量。
采用方差减缩法进行变量敏感性分析,并识别影响患者就医行为偏好的敏感可控变量,包括以下步骤:
S61、变量敏感性分析,其中,变量X
其中,
其中,x
S62、敏感可控变量识别,基于可控性视角,区分个人基本特征和医疗健康特征两大类影响变量中的可控变量与不可控变量,其中,肺癌了解度、CT筛查、筛查原因、健康体检以及医疗保险五种影响变量是可控的;通过区分可控变量X
下面通过具体实验来说明本发明的技术效果:
实验条件:依据上述步骤构建隐变量结构化改进的贝叶斯网络,模型效果验证依托成都市青江区数据集、成都市成华区数据集。
实验过程:利用构建的隐变量结构化改进的贝叶斯网络,将成都市青白江区、成都市成华区数据集利用期望最大化算法进行网络学习,并利用混淆矩阵进行精度计算。
实验结果:
(1)图2中可知37.8%的居民倾向于在非省级医院进行肺癌筛查。
(2)成都市青白江区及成都市成华区推测精度计算结果显示,青白江区准确率为93.6%,成华区准确率为89.5%。
因此,本发明采用上述一种肺癌筛查患者就医行为偏好推测方法,解决了普通模型无法做出精确的预测的问题,且利用目前数据信息形成网络关联关系,将先验信息与样本知识有机结合起来,促进了先验知识和数据的集成,保证样本数据稀疏或数据较难获得时依旧可进行准确推测,解决传统模型数据样本获取少而推测不准确和对多变量系统解释性欠佳的问题。
最后应说明的是:以上实施例仅用以说明本发明的技术方案而非对其进行限制,尽管参照较佳实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对本发明的技术方案进行修改或者等同替换,而这些修改或者等同替换亦不能使修改后的技术方案脱离本发明技术方案的精神和范围。
- 一种肺癌筛查模型的构建方法以及肺癌筛查的试剂盒
- 一种用于肺癌早期筛查的组合物及试剂盒、以及肺癌早期ctDNA甲基化的检测方法