一种安全帽佩戴检测方法、系统、设备及存储介质
文献发布时间:2023-06-19 11:19:16
技术领域
本发明属于小目标检测领域,涉及一种安全帽佩戴检测方法、系统、设备及存储介质。
背景技术
安全帽设施佩戴目标检测是利用基于深度学习的目标检测算法判断图像中的建筑施工人员是否合格佩戴安全帽。在传统的目标检测方法中,主要分为以下步骤:图像预处理、目标区域选择、特征提取、特征选择、特征分类五个步骤。作为人工提取的图像特征用作目标检测,使得获取的结果并不理想目前,基于深度学习的目标检测技术已经相当成熟,应用于各个领域。
目标检测领域的深度学习方法主要分为两类:two stage的目标检测算法;onestage的目标检测算法。Two stage的目标检测算法属于基于候选区的图像分类算法,先使用区域搜索型算法在图像上提取多个候选区域,再对候选区域进行特征提取对其分类。Onestage的目标检测算法直接回归物体的类别概率和位置坐标值,未使用RPN网络,检测速度相比Two stage目标检测网络更快。目前已有的YOLO算法可以很好的识别清晰、背景环境良好的目标物,但是对于建筑施工地环境复杂、建筑施工人员动作不一、目标物重叠以及背景色容易和目标物体的颜色冲突等情况,无法精准的做出识别。
发明内容
本发明的目的在于克服上述现有技术的缺点,提供一种安全帽佩戴检测方法、系统、设备及存储介质,实现多小目标复杂场景下的精准检测。
为达到上述目的,本发明采用以下技术方案予以实现:
一种安全帽佩戴检测方法,包括以下步骤;
步骤一、获取原始图像数据,将部分原始图像数据作为训练集;
步骤二、搭建安全帽检测网络YOLOv4;
步骤三、使用聚类算法获取训练集的先验框的大小,并且替换YOLOv4中的先验框数据;
步骤四、将训练集上传至安全帽检测网络YOLOv4中,采用迁移学习的方法训练得到安全帽识别模型;
步骤五、使用安全帽识别模型对现场人员是否佩戴安全帽进行检测。
优选的,步骤一中,将剩余部分原始图像作为测试集;步骤六中,得到安全帽识别模型后,输入测试集,用测试集对安全帽识别模型进行测试,得到测试结果集。
优选的,步骤一中,对训练集打上xml标签,xml标签分为正样本和负样本。
优选的,步骤二中,安全帽检测网络YOLOv4包括Input输入层、BackBone主干网络、Neck模块和Head检测头。
优选的,步骤四中,使用迁移学习的方式基于预训练权重文件训练出安全帽检测网络YOLOv4的权重文件,并将权重文件进行转换为.conv.23的文件,将生成的.conv.23文件作为下次训练的预训练模型。
进一步,训练时生成weights文件以及loss和map的变化过程图像,weights文件为权重文件。
一种安全帽佩戴检测系统,包括:
获取数据模块,用于获取原始图像数据,将部分原始图像数据作为训练集;
安全帽检测网络构建模块,用于搭建安全帽检测网络YOLOv4;
先验框更新模块,用于使用聚类算法获取训练集的先验框的大小,并且替换YOLOv4中的先验框数据;
训练模块,用于将训练集上传至安全帽检测网络YOLOv4中,采用迁移学习的方法训练得到安全帽识别模型;
检测模块,用于使用安全帽识别模型对现场人员是否佩戴安全帽进行检测。
一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述任意一项所述安全帽佩戴检测方法的步骤。
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述任意一项所述安全帽佩戴检测方法的步骤。
与现有技术相比,本发明具有以下有益效果:
本发明通过使用聚类算法获取训练集的先验框的大小,并且替换YOLOv4中的先验框数据,由于YOLOv4配置文件中的先验框大小是基于coco数据集的,并不适用本发明所用的VOC数据集,而使用合并聚类算法,其对小数据点也可以实现分类,以此得到的先验框在进行小目标检测时可提高检测率。本发明基于此得到较好的检测数据集和网络,增强了网络的识别度,提高了复杂施工场景下多行为的小目标检测的准确率和模型的鲁棒性,实现复杂场景下安全帽佩戴的精准检测。
附图说明
图1为本发明的流程图;
图2为本发明的安全帽检测网络YOLOv4的结构图;
图3为SafetyHelmetWearing-Dataset检测的loss损失和map图;
图4为本发明数据集检测的loss损失和map图。
具体实施方式
下面结合附图对本发明做进一步详细描述:
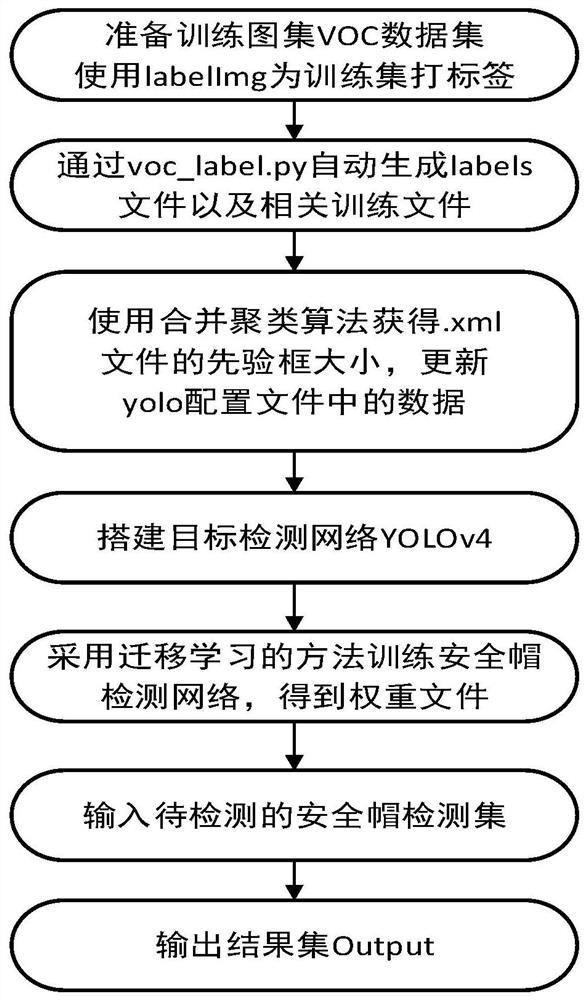
本发明所述的安全帽佩戴检测方法,如图1所示,包括以下步骤:
步骤1:准备训练所需的数据集。在建筑施工现场采集原始图像数据,将采集来的照片分为占75%的训练集和占25%的测试集,对训练集中的源图像进行预处理。
具体的:采集至少6000张有关安全帽佩戴图片,源图像数据采集时必须包含施工人员的多个角度,多个姿态,源图片中的施工人员远近大小不一,包含多个小目标,且环境不可单一,场地不可过于简单;此发明中使用的图集部分来源于GitHub上公开的Safety-Helmet-Wearing-Dataset数据集、手机拍摄的建筑施工地照片(拍摄地:西安)以及网络爬虫,对搜集到的照片进行严格的筛选,并使用Keras提供的图片预处理的类ImageDataGenerator对源图片集进行扩展,图片生成器会生成一个batch周期内的数据,它支持实时的数据扩展,训练的时候会无限生成数据,一直到达设定的epoch次数才停止。在数据集不够多的情况下,可以使用ImageDataGenerator()来扩大数据集并且防止搭建的网络出现过拟合现象。将预处理后的图片存入JPEGImages文件夹,命名格式统一为:00xxxx.jpg,作为训练集,训练集占所有数据的75%。
步骤2:制作VOC数据集,通过LabelImg工具对训练集打标签,标签分为正样本helmet和负样本no-helmets,将打好的xml标签统一存放在VOC文件夹下的Annotations文件中,源图片存放在JPEGImages文件下。
VOC数据集包含:1)步骤一中存放安全帽图片的JPEGImages文件夹;2)使用labalImg工具对每一张图片内的所有目标物体做标记,给目标物体建立box边框,对box边框内的物体贴上标签,分为正负样本:helmet和no-helmet,将生成的.xml文件存入Annotations文件夹,文件名与图片名保持一致;3)ImageSets文件中存放Main文件,其中包含:test.txt、train.txt、trainval.txt以及val.txt,保存着各个图片的索引,指导训练和测试的图片路径。至此,VOC数据集准备完成,只用此格式的VOC数据集无法满足yolo对数据集得要求,此时,使用voc_label.py生成相应的labels文件夹以及相应的图集路径文件,注意:将文件中classes类别换为helmet和no-helmet。
步骤3:搭建安全帽检测网络YOLOv4,使用cmake方式进行编译。据图2,YOLOv4包含以下四部分:Input输入层、BackBone主干网络、Neck以及Head检测头。BackBone主干网络包括CSPDarknet53、Mishap激活函数以及Dropblock,BackBone中共有72个卷积层,产生的Backbone结构,其中包含了5个CSP模块,每个CSP模块前面的卷积核的大小都是3×3,步长为2。Backbone有5个CSP模块,输入图像是608*608,所以特征图变化的规律是:608->304->152->76->38->19,经过5次CSP模块后得到19*19大小的特征图。
搭建安全帽检测网络YOLOv4具体过程为:
1)构建YOLOv4的骨干网络CSPDarknet53,如图2所示,其包含:CBM和5个CSPn残差模块拼接而成,残差块:CSP1由5个CBM和1个残差模块组合,CSP2由5个CBM和2个残差模块组合,CSP8由5个CBM和8个残差模块组合,CSP8由5个CBM和8个残差模块组合,CSP4由5个CBM和4个残差模块组合,没每经过一个CSPn,便有一次下采样,其中每个CBM由卷积层、BN批量归一化和Mish激活函数层组成。Mish激活函数用数学公式表示为:
Mish=x·tanh(ln(1+e
其中,tanh也为激活函数,tanh的数学表达式为:
其中,x代表非线性特征加权求和,ln()为以e为底的对数函数,e^x为指数函数。
Mish激活函数允许有比较小的负梯度流入,从而保证信息流动。且激活函数无边界,很好地避免了饱和问题,且Mish函数保证了没一点的平滑,梯度下降效果比Relu要好。
2)构建Neck模块。Neck模块包含:SPP+PANET。对于608*608的输入,SPP的构造为:1、5、9、13以及Concat连接,将SPP添加到CSPDarknet53,显著增加了感受野,分离出最重要的上下文特征,且几乎不会减少网络运行速度。使用PANet代替FPN作为作为不同骨干层对不同检测器层的参数聚合方法,在FPN的基础上做了bottom-up的路径增加。
3)构建Head检测头。经过5次CSP模块(608->304->152->76->38->19)后得到19*19大小的特征图。
步骤4:使用聚类算法对VOC数据集的Annotations文件夹中的.xml文件进行处理,获取训练集的先验框的大小,并且将YOLOv4中的先验框大小替换为训练集的先验框的大小。
此聚类算法是一个贪心算法。思想类似于经典图算法中计算最小支撑树的Kruskal算法。设需要将m个数据样本聚为k个类时,先将每一个数据样本自成一类,随后每一步都合并距离最近的两个类,直至将m个数据样本聚为k个类时为止。使用合并聚类算法获得.xml文件集的先验框的大小,更新到yolo文件中的数据。
步骤5:采用迁移学习的方式对安全帽检测网络YOLOv4基于CSPDarknet目标识别模型进行训练,将迭代次数设置为4000、更换mini-batch的大小分别进行训练,得到训练好的weights识别模型以及loss和map图像;weights识别模型为安全帽识别模型。
配置安全帽检测网络YOLOv4训练的环境,包含:CUDA10.0、cudnn v7、python3.6、Visual Studio2017、cmake等工具,操作环境:win10操作系统,CPU:InTel(R)Core(TM)i7-9700F,GPU:RTX 2080Ti,显存:11G。
配置预训练权重文件yolov4.conv.137到框架根目录下。
更新配置文件cfg中的相关参数,包含:检测集和训练集的路径信息,检测类的类文件obj.names,yolo-obj.cfg中的输入图片大小(width=608(或416)、hei ght=608(或416))、mini-batch=1或4、max_batches=4000(2000*classes)、steps=3200,3600(max_batches*0.8,max_batches*0.9)、classes=2、filters=21((classes+5)*3)、anchors,anchors为合并聚类生成的先验框数据。
输入构建好的数据集,并采用mosaic数据处理,每次向网络中传入4张图片。
使用迁移学习的方式基于预训练权重文件训练出本发明网络的权重文件,并将.weights权重文件进行转换为.conv.23的文件,将生成的新文件作为下次训练的预训练模型,此举的优势在于:训练速度快,模型优。
训练时生成weights文件以及loss和map的变化过程图像。
步骤6:输入带测试的安全帽图片集,用训练好的weights识别模型对准备好的测试集进行测试,筛选得到weights文件夹中较好的权重文件,得到测试结果集Output,约2000张图片。
具体的,原YOLOv4框架只支持单张图片测试,如果要测试大量图片,一张一张检测是非常麻烦的,为了能够批量检测图片,并保存在指定的文件夹中,需在detetor.c的开头位置,添加GetFilename函数,并重新make。将测试集输入网络中进行检测标记,输出带有标签的图集Output。
步骤7:使用安全帽识别模型对现场人员是否佩戴安全帽进行检测。
图3为公开数据集训练得到的map及loss图,明显看到此数据集上的loss为5以上(一般要求loss下降到2以内),这样得到的模型在做检测时明显对物体的识别率低,相对的模型鲁棒性较差。
图4为本发明新数据集及模型训练得到的map及loss图,本发明将loss下降至1以内,模型鲁棒性提高,且检测时对于小目标以及复杂行为的施工人员佩戴的识别效果高。
从表1可以看出,将合并聚类结合Yolov4使用之后,在不同的mini-batch和size下进行训练得到的权重文件检测精度(AP)明显提高,loss相比原始数据集上得到的loss下降了4左右,鲁棒性更好。
表1不同mini_batch下训练结果比较
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
- 一种安全帽佩戴检测方法、系统、设备及存储介质
- 一种佩戴安全帽检测方法、设备以及计算机存储介质