基于深度学习和重采样的河流-湖泊岩相测井识别方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及岩相识别技术领域,特别涉及一种基于深度学习和重采样的河流-湖泊岩相测井识别方法。
背景技术
岩相是在相同的沉积条件下,体现了不同实例的丰富信息的岩石组合。在有限数据的情况下,岩相知识对于预测地层单元的岩性分布和排列是必不可少的(Allen, 1975;Miall, 1995),这是重建古地球古地理和寻找油气勘探甜点的关键。
测井曲线在地下勘探中普遍存在,测井曲线通常是连续的,在不间断的剖面中采样。除了直接测量地下岩石的岩石物理特征外,它们还可以反映岩性、质地和结构的变化,以及岩性的堆积模式,这对于理解岩相至关重要。因此,测井有助于地下地层的时空关联,并广泛用于油气储层预测。
尽管测井曲线普遍用于岩相识别,但有两个主要的局限性。首先,要进行详细的岩相解释,需要同时使用多条测井曲线进行综合解释。然而,人工作业难以处理多个测井,有时可能会忽略大量有用的信息。其次,从测井中进行岩相识别需要经验丰富的解释人员付出巨大的努力,从而增加了成本,阻碍了效率。迄今为止,深层地下勘探需要大量的地理数据集来重建详细的古地理环境(Wang 等人,2021年),所以快速有效的岩相解释方法是很有必要的。
机器学习是近年来人工智能及模式识别领域的共同研究热点,其理论和方法已被广泛应用于解决工程应用和科学领域的复杂问题。在岩相划分方面,机器学习可以帮助研究人员从爆炸性数据集中提取有用信息并获得新见解,从而有效克服了传统方法的局限性。
然而,对于河流-湖泊岩相测井方面来说,虽然机器学习解决了有用信息的快速提取,但是河流-湖泊岩相组合主要以淡水湖相泥岩与河流-三角洲沉积互层为特征,且通常含有煤,因而具有较为强烈的岩相差异,这会导致实际勘探项目中存在数据不平衡的问题,所以单纯采用机器学习方法并不能有效提高河流-湖泊岩相的识别精度。
发明内容
本发明的目的在于提供一种基于深度学习和重采样的河流-湖泊岩相测井识别方法,不仅能从爆炸性数据集中快速提取有用信息,而且可以解决实际勘探项目中存在数据不平衡的问题,从而提高河流-湖泊岩相的识别精度。
为实现上述目的,本发明采用的技术方案如下:
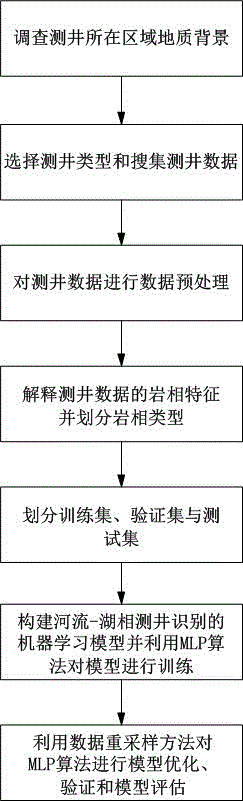
基于深度学习和重采样的河流-湖泊岩相测井识别方法,包括以下步骤:
(1)根据河流-湖泊岩相测井段所在区域的地质背景,选择测井类型和搜集测井数据;
(2)根据选择的测井类型和搜集的测井数据解释测井数据的岩相特征,并划分岩相类型;
(3)根据测井数据和岩相类型划分出训练集、验证集与测试集;
(4)构建河流-湖泊岩相测井识别的机器学习模型,并使用MLP算法结合训练集对模型进行训练,MLP中包含输入层、中间隐藏层和输出层,其中,输入层为测井数据;中间隐藏层为深度神经网络可调节参数层,且每个中间隐藏层为100个神经元的深度神经网络;输出层为岩相类型,并且相邻层节点的连接均配有权重;
训练过程如下:
(a)所有边的权重随机分配;
(b)前向传播:利用训练集中所有样本的输入特征,作为输入层,对于所有训练数据集中的输入,人工神经网络都被激活,然后经过前向传播,得到输出值;
(c)反向传播:利用输出值和样本值计算总误差,再利用反向传播更新权重;
(d)重复步骤(b)、(c),直至输出误差低于制定的标准;
(5)利用数据重采样方法对MLP算法进行模型优化,并利用网格搜索结合验证集对模型进行验证和调参,找到模型的最优参数,然后输出优化后的模型;
(6)利用优化后的模型对河流-湖泊岩相测井进行识别,并通过精确度、F1-score和曲线下面积结合测试集评估模型的准确性和性能。
具体地,所述步骤(1)中,测井类型包括卡尺测井、伽马测井、无铀伽马测井、深测双侧向电阻率测井、浅测双侧向电阻率测井、补偿中子测井、密度测井和声波测井。
进一步地,搜集测井数据后,先对其进行标准化处理,处理过程如下:
(e)通过移动测井曲线来匹配标记层的层段,然后利用伽马测井来校准深度;
(f)将不能反映地下岩层真实情况的无效值删除;
(g)采用如下公式,对测井数据进行标准化处理:
式中,
具体地,所述步骤(5)中,数据重采样方法包括过采样和欠采样,其中,过采样流程如下:
(h)对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集
(i)根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,选择的近邻为xn;
(j)对于每一个随机选出的近邻xn,分别与原样本按照如下的公式构建新的样本:
式中,rand(0,1)代表生成一个在(0,1)内的随机实数;
欠采样流程如下:
(k)将数据T拆分成兴趣类C和其他数据O;
(l)使用编辑过的最近邻规则识别O中的噪声数据A
(m)对于O里面的每个类
(n)减少数据
进一步地,所述步骤(6)中,采用如下公式评估模型的准确性和性能:
式中,Accuracy 代表精确度,TP代表真阳性,TN代表真阴性,FP代表假阳性,FN代表假阴性,precession代表准确率,recall代表召回率。
与现有技术相比,本发明具有以下有益效果:
本发明先选择测井类型和搜集测井数据,然后划分岩相,再在此基础上划分出训练集、验证集与测试集,继而采用机器学习的方式构建河流-湖泊岩相测井识别的机器学习模型。构建模型后,本发明采用了MLP算法进行模型训练,本发明设计的MLP神经网络结构中,每个中间隐藏层为100个神经元的深度神经网络,训练后的模型存在不平衡数据集,对此,本发明进一步设计了数据重采样方式,通过过采样和欠采样相互结合,创建了平衡的数据集来消除原始数据集不平衡的影响,然后不断验证,再利用网格搜索的方法寻找模型的最佳超参数,使模型不断优化,最后通过精确度、F1-score和曲线下面积(AUC)对模型进行评估、调整,得到最终输出的最优模型。
本发明输出的识别模型,有效克服了以往岩相识别方法因无法解决真实地下项目数据不平衡而导致的识别精度不高的问题。实验表明,采用本发明优化后的识别模型,在多数岩相(如砂岩岩相、曲流河道砂岩岩相、纵向/横向坝状砂岩相、点坝砂泥岩相)上都表现出了良好、甚至优异的性能,最高准确度可达到0.82,最高 F1分数可达到0.82,相比现有的识别模型来说,识别精度均至少提高了10%以上。此外,本发明中识别模型的训练过程耗时469.98秒,时间相比于其他机器学习算法也更短,展示了本发明在测井河流-湖泊岩相识别中的成功应用,实现了可靠、高效、无偏倚的岩相识别,在地下油气勘探工程中具有巨大的潜力。
附图说明
图1为本发明-实施例的流程示意图。
图2为本发明-实施例中过采样的样例示意图。
图3为本发明-实施例中MLP神经网络和带有过采样的模型示意图。
图4为本发明-实施例中原始MLP分类器和带有重采样算法的分类器的F1得分示意图。
图5为本发明-实施例中原始MLP分类器和带有重采样算法的分类器ROC曲线图。
图6为本发明-实施例中原始MLP分类器和带有重采样算法的分类器的混淆矩阵图。
具体实施方式
下面结合附图说明和实施例对本发明作进一步说明,本发明的方式包括但不仅限于以下实施例。
实施例
本实施例提供了一种基于深度学习和重采样的河流-湖泊岩相测井识别方法,通过建立多层感知器(MLP)岩相识别模型,并利用数据重采样(Resample)算法对MLP模型优化,然后采用网格搜索的方法寻找模型的最佳超参数,从而提供可靠、高效、无偏倚的岩相识别,提高河流-湖泊岩相的识别精度,对油气勘探具有很大的潜力。
本实施例的主要流程如图1所示,主要分为调查测井所在区域地质背景、选择测井类型和搜集测井数据、对测井数据进行数据预处理、解释测井数据的岩相特征并划分岩相类型、划分训练集、验证集与测试集、构建河流-湖相测井识别的机器学习模型并利用MLP算法对模型进行训练、利用数据重采样方法对MLP算法进行模型优化、验证和模型评估几大流程。
下面结合案例对上述流程进行逐一介绍。
一、调查测井所在区域地质背景
本实施例中,所选测井段为上三叠统元坝地区须家河组—下侏罗统自流井组。该井位于四川盆地。四川盆地,面积18万平方公里,是中国最大的含油气盆地之一。四川盆地西为龙门山,北为秦岭造山带,东为雪峰山,南为康甸高地。四川盆地经历了三个主要的构造演化阶段,三叠纪至晚白垩纪为前陆盆地。元坝地区位于四川盆地北部,是一个以须家河组为主的大中型油气田,自流井组沉积于河-湖相体系,是天然气储量在1000×108m
二、选择测井类型和搜集测井数据
本实施例选取了8种测井类型,包括卡尺测井(CAL)、伽马测井(GR)、无铀伽马测井(KTH)、深测双侧向电阻率测井(RD)、浅测双侧向电阻率测井(RS)、补偿中子测井(CNL)、密度测井(DEN)和声波测井(AC)。测井数据则包括卡尺、伽马、无铀伽马、深测双侧向电阻率、浅测双侧向电阻率、补偿中子、密度和声波。
三、对测井数据进行数据预处理
为避免深度偏移、测井探测器失灵、不同测井类型取值范围差异等影响,在识别岩相前可以先进行数据预处理,使其形成标准化数据。本实施例中的数据预处理过程依次包括以下几个步骤:
(1)深度校准。由于测井曲线和岩心/岩屑通常存在深度偏移,因此需要对测井曲线进行深度校正,以获得准确的岩相解释。由于泥岩/页岩比砂岩/砾岩具有更高的伽马值,因此通过移动测井曲线来匹配标记层的层段,利用伽马测井来校准深度。
(2)删除无效值。原始测井数据有注入−999、−9999或0等值。这些数值不能反映地下岩层的真实情况,很可能是由于测井探测器失灵造成的。因此,删除这些无效值。
(3)数据标准化。为了避免测井曲线取值范围差异过大的影响,在进行机器学习模型训练之前,对原始数据集进行标准化处理,采用如下公式进行处理:
其中,
四、解释测井数据的岩相特征并划分岩相类型
本实施例中,我们根据切割描述和测井解释进一步将须家河组和自流井组划分为九个主要岩相。根据岩屑描述得到的岩性、沉积结构和构造、岩性叠加模式对这些岩相进行了解释,在没有岩屑的情况下,根据测井曲线形状对这些岩相进行了解释。分流间河道因其岩性和测井曲线特征相似,被纳入河道亚相;此外,其余三角洲具有向上粗化的岩性特征,合并为河口坝亚相。本实施例中使用的9个亚相为:辫状河道砾岩、砂岩岩相(BCCS)、曲流河道砂岩岩相(MCS)、纵向/横向坝状砂岩相(LTBS)、点坝砂泥岩相(PBSM)、冲积平原砂泥岩相(APSM)、洪泛平原泥岩岩相(FPM)、裂缝展布砂岩和泥岩岩相(CSSM)、口坝砂泥岩岩相(MBSM)、浅湖砂泥岩相(SLSM)。
五、划分训练集、验证集与测试集
根据测井数据和岩相类型划分出训练集、验证集与测试集。其中,训练集用于创建机器学习模型,验证集用于优化超参数,测试集用于评估模型的准确性。本实施例中,我们选择了8口井进行训练,1口井进行验证,2口井进行测试。
六、构建河流-湖相测井识别的机器学习模型并利用MLP算法对模型进行训练
本实施例利用MLP算法对模型进行训练,MLP包含多层节点:输入层,中间隐藏层和输出层。相邻层节点的连接均配有权重。学习的目的是为这些边缘分配正确的权重。通过输入向量,这些权重可以决定输出向量。在监督学习中,训练集是已标注的。这意味着对于一些给定的输入,能够知道期望的输出(标注)。具体地,本实施例中,输入层为标准化的测井数据,即:卡尺、伽马、无铀伽马、深测双侧向电阻率、浅测双侧向电阻率、补偿中子、密度和声波;输出层为岩相类型;中间隐藏层为深度神经网络可调节参数层。在本实施例中,MLP分类器的最佳性能来自5个中间隐藏层,且每个中间隐藏层为100个神经元的深度神经网络。
整个MLP的训练过程如下:
1)所有边的权重随机分配;
2)前向传播:利用训练集中所有样本的输入特征,作为输入层,对于所有训练数据集中的输入,人工神经网络都被激活,然后经过前向传播,得到输出值。
以MLP的BP算法为例,对于输入层有I个单元,对于输入样本(x,z),隐层的输入为:
这里,h代表第h层输入,
计算完输入层向第一个隐层的传导后,剩下的隐层计算方式类似,用
其中,h’代表输入层的单元数,
对于输出层,对于多分类问题,即输出层采用归一化指数函数softmax,假设有K个类别,则输出层的第k层计算过程如下:
其中,
则得到类别k的概率可以写作
同理等价于极小化以下损失:
以上便是softmax的损失函数,这里需要注意的是以上优化目标O均没带正则项,而且logistic与softmax最后得到的损失函数均可以称作交叉熵损失。
3)反向传播:利用输出值和样本值计算总误差,再利用反向传播来更新权重。
对于sigmoid来说,最后一层的计算如下:
其中,
这里
对于单个样本的损失:
可得到如下的链式求导过程:
softmax的log损失函数为:
其中,
ɑ
根据以上分析,可以得到
其中,
其中,
到这一步,softmax与sigmoid的残差均计算完成,可以用符号δ来表示,对于第j层,其形式如下:
这里可以得到softmax层向倒数第二层的残差反向传递公式:
其中
以上公式的δ代表sigmoid层唯一的残差,接下来就是残差从隐层向前传递的过程,一直传递到首个隐藏层即第二层:
其中,
最终得到关于权重的计算公式:
至此完成了反向传播的过程,注意由于计算比较复杂,有必要进行梯度验证。对函数O关于参数
4)重复2)、3),直到输出误差低于制定的标准。
上述过程结束后,就得到了一个学习过的MLP网络,该网络被认为是可以接受新输入的。
七、利用数据重采样方法对MLP算法进行模型优化、验证和模型评估
本实施例中,数据重采样方法包括过采样和欠采样,它们的执行是为了通过创建一个平衡的数据集来消除原始数据集的不平衡的影响。过采样方法创建合成样本以增加稀有样本的比例;而欠采样方法会减少样本以降低丰富样本的比例。本实施例选取SMOTE和NCR分别作为过采样和欠采样方法,具体如下:
SMOTE全称是Synthetic Minority Oversampling Technique,即合成少数类过采样技术,它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,优点是通过随机采样生成的合成样本而非实例的副本,可以缓解过拟合的问题,不会损失有价值信息。如图2、3所示,图2中,(a)是随机过采样过程图,以xi样本为核心,周围k个样本相连接;(b)是过采样之后,黑色方块是新生成样本,具体位置是经过过采样公式计算得出。
本实施例的过采样流程如下:
1)对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集
2)根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,选择的近邻为xn。
3)对于每一个随机选出的近邻xn,分别与原样本按照如下的公式构建新的样本:
式中,rand(0,1)代表生成一个在(0,1)内的随机实数。
简单随机抽样(SRS)是统计学中应用的最基本的抽样方法之一,在SRS中,从原始数据T中随机选择一个样本(子集)S,以便T中的每个示例都有相同的概率被选入S。我们将SRS应用于比感兴趣的类C更大的类,并从每个类中选择一个| C |大小的样本。
不幸的是,类内SRS(SWC)可能会产生有偏差的样本,因为小样本可能具有过度表示的异常值或噪声数据。
单边选择(OSS)通过保留C的所有示例并通过从其余数据中删除示例O = T - C来减少T。首先,应用最近邻规则(CNN)从T中选择一个与T一致的子集A,因为A使用最近邻规则(1-NN)正确分类了T。CNN从S 开始,其中包含C和O中每个类的示例,并将(1-NN)错误分类的示例从O移动到S,直到完成O的完整传递而没有错误分类。其次,从O中删除嘈杂或位于决策边界中的示例。OSS的主要缺点是CNN规则对噪声极其敏感。由于嘈杂的示例很可能被错误分类,因此其中许多示例将被添加到训练集中。此外,嘈杂的训练数据会对随后的几个测试示例进行错误分类。
邻居清理规则Neighborhood Cleaning Rule(NCR)的基本思想与OSS中的相同:保存C中的所有示例而减少O。与OSS相比,NCR更强调数据清洗而不是数据缩减。
欠采样流程如下:
1)将数据T拆分成兴趣类C和其他数据O;
2)使用编辑过的最近邻规则识别O中的噪声数据A
3)对于O里面的每个类
4)减少数据
本实施例采用SMOTE和NCR相结合的办法,对数据集先进行SMOTE过采样技术,然后再进行NCR欠采样技术来平衡数据集,能够显著改善识别模型的准确度。
模型优化的过程中,本实施例还采用了网格搜索的方法寻找模型的最佳超参数,使模型不断优化。网格搜寻算法是一种调参手段,通过遍历给定参数组合来优化模型表现的,下次使用该模型的时候,这一步骤会包括在MLP模型里面,模型会根据新的数据,利用该算法进行调优,不需要重新构建模型。
本实施例采用的网格搜寻超参数表格如表1所示:
表1
优化后,即可将其用于河流-湖泊岩相测井的识别。
此外,为了比较分析模型的性能,本实施例采用精确度、F1-score(F1分数)和曲线下面积(AUC)来评价模型的性能。精确度定义为:
式中,TP代表真阳性,TN代表真阴性,FP代表假阳性,FN代表假阴性。真阳性是样本为正,预测也为正;真阴性就是原始样本为负,预测值也为负;假阳性是预测为正,但是真实值为负的样本;假阴性是预测样本为负,但真实值为正。例如,对于砂岩岩相判别时:真阳性就是对于原始样本是砂岩岩相,预测值也是砂岩岩相;真阴性对于非砂岩岩相的样本预测也为非砂岩样本;假阳性就是对于真实值是非砂岩样本,预测值为砂岩岩相;假阴性是指对于预测为非砂岩岩相的样本,真实值为砂岩岩相。
此外,为了使预测结果可视化,本实施例使用了归一化混淆矩阵。AUC代表测量接收者操作特征(ROC)曲线下的面积,表示预测的正例排在负例前面的概率。其中ROC曲线的x轴是假阳性率(FPR),y轴是真阳性率,计算其与x轴围成面积,可以更好的清晰的说明分类器的效果,AUC数值介于0.5~1之间,AUC数值越大,模型效果越好,AUC图形见图4。
对于混淆矩阵的解释:
如表2所示,0.88即是真实值为BCCS,预测值也为BCCS的概率,0.00是真实值为MCS,预测值为BCCS的概率,其他以此类推,完整混淆矩阵图可见图6,图6中,c是MLP算法训练的混淆矩阵图;d是经过重采样之后的混淆矩阵图,对角线数值越大代表对该岩性预测越准确。
表2
TPR和FPR定义为:
则AUC定义为:
其中x是FPR。
F1-score定义为:
其中,
因此,
准确率precession是对于预测样本而言,即预测为正的样本值中有多少是真正的正样本,召回率recall是对于原始样本而言,即有多少正样本被预测正确了。Accuracy精度和F1-score都是0到1之间的值,F1数值越高,模型越好,F1-score最理想的数值是趋近于1,做法是让precision和recall都有很高的值,F1数值越高,模型越好。
图4、图5展示了本实施例中,MLP分类器获得精度、F1-score和训练数据集的AUC分别为0.78、0.78和0.89,测试数据集的精度、F1-score和AUC分别为0.71、0.71和0.85。MLP分类器在除LTBS 和 SLSM之外的大多数岩相上都具有良好的性能,在这两类数据集的精度低于0.80。此外,MLP分类器的训练过程耗时469.98秒。数据重采样方法也提高了MLP分类器的性能。SMOTE方法在测试数据集上将 MLP 分类器的准确率从0.71提高到 0.80,F1-score从0.71提高到0.80,AUC 从 0.85 提高到0.91。NCR方法将准确度提高到0.79,F1分数提高到 0.78,AUC提高到0.83。采用SMOTE和NCR组合方法的MLP分类器的最高准确度为 0.82,最高F1分数为0.82。通过混淆矩阵(图6)可以看出BCCS、MCS、PBSM、APSM、FPM、CSSM、MBSM的预测准确率都达到了80%以上,通过对数据集进行SMOTE和NCR重采样,也提高了LTBS、APSM、FPM的预测准确率。表3是MLP的评估指标和训练时间,可以看出MLP模型在测试集上的效果AUC都达到了80%以上。
表3
由上可见,本发明在机器学习基础上,利用MLP对模型进行训练,然后结合数据重采样方法(包含过采样和欠采样)以及网格搜索进行模型优化后,大幅提升了模型的识别精度,相比现有技术来说,本发明对河流-湖泊岩相测井的识别精度至少提高了10%以上,更好地实现了精准、高效、可泛用的河流和湖泊岩相测井的识别。
上述实施例仅为本发明的优选实施方式之一,不应当用于限制本发明的保护范围,凡在本发明的主体设计思想和精神上作出的毫无实质意义的改动或润色,其所解决的技术问题仍然与本发明一致的,均应当包含在本发明的保护范围之内。
- 致密砂岩储层成岩相测井识别方法及装置
- 基于成因分析的湖相泥页岩岩相测井识别方法
- 基于成因分析的湖相泥页岩岩相测井识别方法