基于深度强化学习混合动作空间的氧气系统调度优化方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及氧气系统调度优化,具体涉及一种基于深度强化学习混合动作空间的氧气系统调度优化方法。
背景技术
在钢铁制造过程中,氧气是不可缺少的能源消耗原料,用氧量频繁波动以及氧气供需失衡,易造成氧气利用效率低和能源浪费,增加了生产成本,因此氧气系统调度优化对钢铁企业提高经济效益至关重要。
钢铁企业氧气系统调度问题涉及对整个系统设备运行和氧气供需平衡的调度优化,既包含氧气量、时间等连续变量,又涉及机组开启等离散变量。这类离散-连续混合变量调度优化问题,系统复杂度高,问题难度大。其中,空分设备在氧气系统中起到了至关重要的作用,近年来,国内外许多学者对空分设备的生产调度进行了大量的研究。针对多套空分机组频繁变负荷运行的要求,Zhou等人建立了用于过程调度的混合整数线性规划(mixedinteger linear program,MILP)模型,提出了分离模式下的最优调度策略对机组运行模式进行决策,在一定时间段内优化了总利润率。Mitra等人将空分设备运行状态划分为不同模式,利用凸包法建立离散时间下的确定性混合整数线性规划(mixed integer linearprogram,MILP)模型,在模型复杂度较高的情况下具有较高的求解速度。然而空分机组间具有强耦合性和非线性,传统线性规划方法无法解决,因此Zou等人提出了松散耦合模型与控制变量优先级设置相结合的鲁棒控制策略,利用增量负载平衡计算方法来处理非线性,降低生产调度过程中能源消耗。Pattison and Baldea研究了在可变电价下以可变容量运行的空分设备的优化设计,提出了一种新的面向伪瞬态方程的过程建模框架,并将所开发的模型与基于时间松弛的优化算法结合使用。Morgan T.Kelley等人提出了一种数据驱动的方法,以历史闭环运行数据为基础,使用带有额外输入的自回归(autoregressive withextra inputs,ARX)模型,在工业空分装置上进行调度优化。空分机组各设备对整体系统调度也存在影响,研究单独设备的运行方式对系统整体调度具有重要意义。针对空分机组热集成空分塔(HIASC)的非线性行为,Fu和Liu设计了一系列非线性波动模型预测控制方案达到优化调度目标。Cao等人采用粒子群算法对液化器进行调度优化,降低了功耗从而减少了生产成本。
上述研究均围绕空分设备展开,通过空分设备生产方式的改进优化生产调度过程,主要针对离散变量进行调度优化。然而氧气需求量、生产量以及消散量这些连续变量的调度优化对于节能降耗也非常重要,相关学者针对这些连续变量的调度优化问题也开展了相关研究。针对钢铁企业多转炉炼钢阶段的需氧量优化问题,Xu等人建立了以使需氧量波动最小和铸件启动时间偏差惩罚最小为目标的最优生产调度模型。为了求解该模型,采用了一种结合可变邻域搜索的混合遗传算法(hybrid genetic algorithm combiningvariable neighborhood search,HGAVNS)。结合氧气系统生产量与用电量之间的拟合回归关系,Han等人建立了氧气系统调度的非线性规划模型,采用粒子群优化(particle swarmoptimization,PSO)算法对所提出的考虑电力成本的调度模型进行求解。为了解决生产制造过程中不确定性导致的供应和需求之间的关系波动,Jiang等人提出了一个考虑不确定需求的最优氧气分配策略,设计了基于预算的不确定性集的两阶段鲁棒优化(two-stagerobust optimization,TSRO)模型,主要包括基于高斯过程的时间序列模型来预测连续过程的需求区间,产能约束调度模型来生成离散过程的多场景需求。Zhang等人在降低由氧气供需不平衡引起的管网压力波动基础上建立了氧气系统调度的混合整数线性规划模型,提高了系统安全性的同时降低了氧气放散率。上述研究根据实际生产量、需求量进行调度研究,在生产过程中进行调度具有滞后性,为实时解决调度问题,Han等人应用基于粒度计算的模型来预测氧/氮需求,并开发了基于MILP的优化模型来分配氧气。Zhang等人开发一个基于模型的决策支持系统,可以根据短期氧气需求预测来最小化氧气消散量,能够及时提供一个响应性的解决方案,以调整供应方面涉及的所有变量。然而,利用传统方法处理涉及离散变量或连续变量的问题时,仍未有调度方法明确针对变量连续或离散来解决实际调度问题,大多从调度优化目标方面选取调度方法,因而对于钢铁企业氧气系统涉及混合变量的复杂问题,传统求解方法仍然有待进一步改进。
深度强化学习(reinforcement learning,RL)将深度学习的感知能力和强化学习的决策能力相结合,可处理涉及高维变量的复杂调度问题。从时间差分更新方法角度,深度强化学习分为值函数算法和策略梯度算法。值函数算法需要对动作进行采样,用于处理离散动作,深度Q网络(Deep Q-Learning,DQN)是基于值函数的经典深度强化学习算法。BerndWaschneck等人将DQN算法用于工业生产调度,以实现工业4.0,Wu等人提出了基于深度Q学习的混合动力公交车能量管理策略。然而实际调度问题复杂多样,传统DQN算法无法解决所有调度问题,需要对DQN算法进行改进。Luo等人设计了一种新的基于双DQN(double DQN,DDQN)的训练框架,解决具有新任务插入的动态多目标柔性作业车间调度问题,Ren等人采用基于预测的Dueling-DDQN算法,对家庭能源管理系统进行优化,针对工厂可重构制造系统,利用Dueling-DDQN算法可得出调度策略。策略梯度算法直接利用策略网络对动作进行搜索,可以被用于处理连续动作的情况。常用的算法有深度确定性策略梯度(deterministicpolicy gradient,DDPG算法)算法、以及在DDPG算法上进行改进的TD3算法(Twin DelayedDeep Deterministic,TD3)和PPO(Proximal Policy Optimization)算法。针对连续动作空间,有许多学者利用上述算法对不同系统进行调度优化。Wang等人基于DDPG算法对电动汽车集群C-D(charging–discharging)系统电动汽车充放电进行决策,有效降低用户充电成本。对于虚拟电厂,Guo等人利用TD3算法对电动汽车充放电进行调度,而Zhou等人则通过TD3算法来求解混合动力汽车的能源管理策。此外,采用PPO算法来寻找作业车间调度的最优策略和DPPO算法解决热电联产系统经济调度问题。Actor-Critic算法是值函数的算法与策略梯度算法的结合,可以进行单步更新,更具优势。Mao等人提出了一种带有前馈神经网络的Actor-Critic算法解决出租车调度问题,Ying等人则利用Actor-Critic算法解决有限车辆流通的地铁列车调度问题。因此,深度强化学习算法可针对性地对涉及离散变量或连续变量的实际调度问题进行求解,但是针对氧气系统涉及混合变量调度问题,未有特定算法来解决。
综上,在现有研究中,大多学者从关于机组运行特性的离散量考虑,对整个系统设备运行进行优化调度,或者只考虑系统中氧气的生产量或消耗量,对氧气供需平衡进行优化调度。未有学者将设备运行和氧气供需平衡结合起来,进行整体优化调度,制定合理的调度方案同时控制氧气量和设备运行。同时,现有深度强化学习算法不能解决同时包含离散和连续变量的钢铁氧气系统调度问题。因此,本发明设计了一种基于改进深度强化学习算法的钢铁企业氧气系统调度方案。根据氧气系统实际调度需求,同时考虑设备运行状态如设备开停和氧气产量,基于此提出了混合动作评价(HAC)算法。针对混合动作空间特性,在Actor-Critic算法框架下,进行了actor网络扩展,将动作空间细分为离散动作空间和连续动作空间。考虑离散动作和连续动作之间的耦合关系,构建关联矩阵,对整体氧气系统进行调度。
发明内容
本发明提供一种基于深度强化学习混合动作空间的氧气系统调度优化方法,以解决现有技术中的问题。
本发明所解决的技术问题采用以下技术方案来实现:
本发明提供一种基于深度强化学习混合动作空间的氧气系统调度优化方法,包括如下步骤:
步骤一、氧气系统调度优化
1.1确定氧气系统调度优化问题:钢铁企业氧气系统分为三个子系统:氧气发生系统、存储系统和使用系统;安排系统中各设备的运行方式和生产水平,在满足用户氧气需求的同时,提高氧气利用率,实现利益最大化;
1.2优化目标
1.3约束条件
步骤二、基于drl的方法
步骤三、结果和分析
为验证HAC算法用于氧气系统调度优化的有效性与优越性,首先给出了采用HAC算法调度与实际生产的对比实验结果,并对所提出的算法结构进行分析;
3.1算法验证与分析
混合actor-critic算法用神经网络拟合强化学习策略函数和状态动作价值函数,具有3个神经网络,即离散actor网络、连续actor网络和critic网络,将神经网络隐藏层层数设为2层,每层设置200个神经元,隐藏层的激活函数均为负斜率为0.01的ReLU函数,输出层为全连接层;采用深度学习常用思想选取超参数然后根据实际训练数据进行试错调整;
3.2算法结构分析对比
设置了额外奖励函数,考虑峰时谷时设备用电量对整个调度结果的影响;为验证其合理性,将原算法与不设置额外奖励的算法分别对氧气系统进行调度优化,将调度优化后的策略进行分析计算,按所提出的目标函数计算各自经济指标进行比较;不设置额外奖励函数,峰谷时设备用电量差别较小,整体经济效益平稳低于原算法调度结果;然而用原算法调度后,峰时机器消耗电量低于谷时,整体经济效益更高,比不设置额外奖励函数平均经济效益多24%;
此外,混合actor-critic算法建立了关联矩阵D,表明两个actor网络之间的耦合关系;为验证设置关联矩阵的必要性,对HAC算法去掉关联矩阵后进行氧气系统调度策略求解;
3.3不同算法结果对比
将混合actor-critic算法与MP-DQN算法、P-DQN算法以及PADDPG算法进行对比;混合actor-critic算法奖励曲线约在10000回合达到收敛且奖励值最高,MP-DQN算法与P-DQN算法收敛时间较长并且奖励值低于HAC算法,而PADDPG算法虽在收敛时间上较快但平均奖励值过低无法满足调度优化需求。
与现有技术相比,本发明具备以下有益效果:
1、本发明对某钢铁企业氧气系统的调度问题进行了研究,构建了液氧外售收入、设备用电成本和氧气放散损失相结合的综合经济指标。考虑到传统调度方法不能同时对系统设备启停和频繁的氧气需求变化做出合理调度,经济效益不高。本发明以深度强化学习为基础,提出了用于解决氧气系统调度问题的HAC算法,所提出的算法扩展了AC算法的actor网络,根据市场分时电价设计额外分段奖励函数。HAC算法解决了离散变量和连续变量的混合问题,在提高经济效益的同时实现节能减排。实验结果表明,HAC算法将调度问题置于混合的动作空间中,避免导致次优的动作选择的问题。与传统算法相比,HAC算法显著提高了算法的收敛性和准确性,使氧气系统具有更高的氧气利用率和经济效益。
2、钢铁企业氧气系统调度优化问题集中于氧气产出、存储以及使用的调度过程,现有调度策略仅从单一的连续变量或离散变量考虑。然而在实际生产中,需要考虑同时涉及设备启停和氧气产量、消散量等离散变量和连续变量的混合问题。因此本文提出了一种基于深度强化学习的混合动作评价(hybrid actor-critic,HAC)算法,将传统动作空间细分为离散动作空间和连续动作空间,通过改进Q函数实现调度策略精准评价。针对离散动作对应的连续动作在数量上的非唯一性,以及不同离散动作对应的连续动作在维度上的不一致性,构建关联矩阵,使连续actor网络具有独立的动作参数输出,避免采取不同混合动作所获得的Q值依赖不相关的连续动作,产生虚假梯度,导致次优的动作选择。利用钢铁企业实际数据进行实验验证。结果表明,本文所提出的调度算法在改善奖励值的同时,提高了算法收敛速度。相较于传统算法,具备更好的综合性能。
附图说明
为了更清楚地说明本发明实施方案或现有技术中的技术方案,下面将对实施方案或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施方案,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例氧气系统;
图2为本发明实施例强化学习结构图;
图3为本发明实施例hybrid actor-critic结构;
图4为本发明实施例混合actor-critic算法;
图5为本发明实施例训练过程中的奖励曲线;
图6为本发明实施例目标函数优化结果;
图7为本发明实施例液氧外售对比;
图8为本发明实施例用电消耗对比;
图9为本发明实施例放散率对比;
图10为本发明实施例额外奖励函数对比;
图11为本发明实施例设备运行甘特图;
图12为本发明实施例不同设备产量;
图13为本发明实施例不同算法训练过程中奖励曲线对比;
图14为本发明实施例不同算法经济指标对比。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体图示,进一步阐述本发明。
本发明的实施例提供一种技术方案:一种基于深度强化学习混合动作空间的氧气系统调度优化方法,包括如下步骤:
步骤一、问题描述
1.1氧气系统调度优化问题
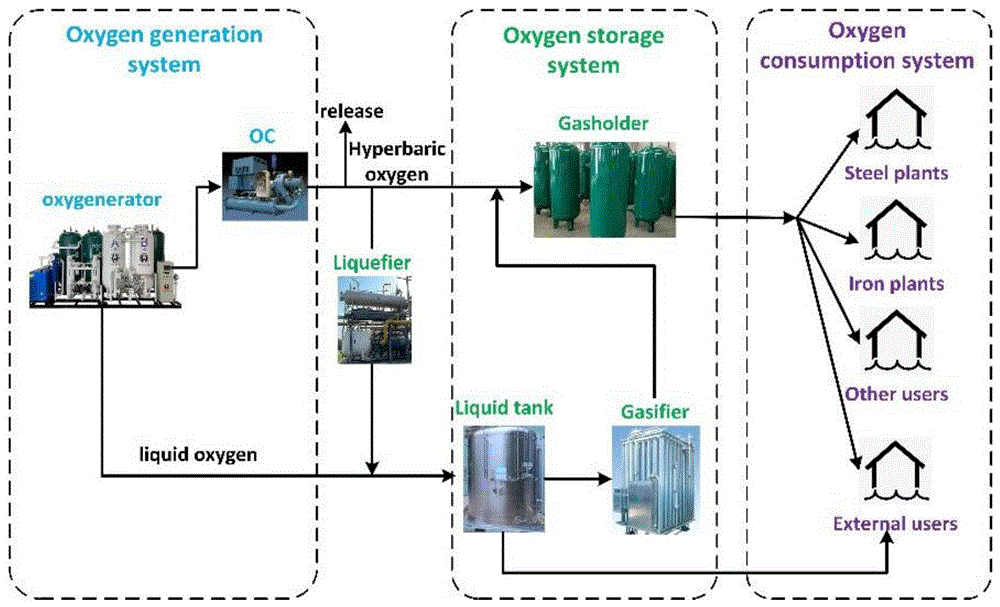
如图1所示,钢铁企业氧气系统可分为三个子系统:氧气发生系统、存储系统和使用系统。
氧气发生系统由制氧机和氧压机组成,空气由空气压缩机压缩至一定压力,然后通过制氧机制氧。产生的气态氧气和液氧通过低温精馏分离,气态氧气由氧压机压缩后通过氧气管网输送至使用系统,而液氧储存在液罐中。当高压氧气过多时,氧气管网和球罐中储存的气体量会逐渐增加,导致管网压力逐渐升高。为了避免因管网压力超过安全范围而造成的安全隐患,可通过液化装置将气态氧液化储存在液罐中,或将多余的气体排出。当高压氧不足时,可利用气化装置将液氧转化为气态氧,以满足氧气使用系统的需要。氧气使用系统包括钢厂、炼铁厂、其他用户和外部用户,其中气态氧进入炼钢厂进行转炉吹炼,进入炼铁厂进行高炉富氧冶炼,液氧主要销售给外部用户以获取外部利润。
在钢铁制造过程中,由于钢铁制品及其相应的生产工艺的不断变化,所需的氧气量频繁波动,易造成生产量和消耗量之间的不平衡。因此对氧气系统进行调度优化解决供需不平衡问题十分必要。在正常情况下,氧气消散量与氧气产量成正比,与调节速度成反比,因而氧气消散量对整个系统供需平衡也会产生影响。另外氧气系统储存装置的存储能力决定了氧气供需不平衡时使用的和储存的氧气量。利用液化器、气化器对液态氧、气态氧进行转化对整个供需平衡也起到了调节作用。因此,氧气系统调度要解决的问题是如何安排系统中各设备的运行方式和生产水平,在满足用户氧气需求的同时,提高氧气利用率,实现利益最大化。
1.2优化目标
通常氧气系统调度优化目标主要包括氧气放散率低和经济效益最大化。本发明从电能消耗、氧气放散率以及经济效益方面考虑,对氧气系统主要设备的运行方式和生产水平进行最优调度决策。
以氧气系统的经济指标F为调度优化目标,考虑外售液氧收入、各设备用电消耗及氧气释放损失,其数学表达式为:
F=J
其中,J
氧气系统液氧外售收入J
其中f液氧单价,
β
设备用电成本E为:
为第i个制氧机在t时刻气态氧产量,/>
氧气系统释放损失J
氧气单价,/>
1.3约束条件
氧气系统调度问题的约束条件包括四个部分,即物料平衡约束、气态氧气与液氧产量比例约束、各设备运行约束以及设备开启约束
(3)物料平衡约束
在t时刻,氧气管网物料平衡与液氧储罐物料平衡可表示为:
其中,
(4)氧气与液氧约束
产生的气态氧与液氧存在如下的关系:
(3)各设备运行约束
氧气系统涉及的各类设备,如制氧机、液化器、气化器、液氧储存装置等均有操作范围。
1)制氧机运行约束
每个制氧机都有其产氧上限和下限,分别约为生产能力的80%和105%。第i台制氧机氧气输出为
和/>
2)液化器运行约束
与制氧机类似,液化装置的负荷范围一般在60%到100%之间。
则液化器运行约束条件为:
分别为第j台液化器液化量下限和上限。
3)气化器运行约束
气化器的气化能力不得超过设备的最大负荷:
为第g台气化装置的气化体积的上下限。
4)液氧储槽容积约束
考虑到设备安全,储液罐的实际容量限制在额定容量的10%~
95%。液罐容积为
S
(4)设备开启约束
在设备空闲时才可执行开启动作且设备开启台数不大于设备总数,即
∑α
∑β
∑ρ
钢铁企业氧气系统调度优化问题涉及离散和连续混合决策变量,调度问题复杂,涉及变量约束多,传统方法无法解决。然而,深度强化学习算法针对具体变量类型,在处理混合变量问题上具有优势。因此,本发明在第三节提出了基于改进强化学习的混合变量优化调度方法,用于解决钢铁企业氧气系统调度优化问题。
步骤二、基于drl的方法
本步骤首先介绍了强化学习的相关知识,并建立了涉及氧气系统具体特征的马尔可夫模型,同时阐述了所提出用于解决调度优化问题的HAC算法的具体内容。
2.1强化学习基本原理
强化学习是智能体在与未知环境持续交互的过程中,采取一定的行动来最大化累积奖励的一种机器学习方法,可用马尔可夫决策过程(MDP)表示。具体形式可用五元组
如图2所示,在t时刻的状态为s
2.2氧气系统调度优化马尔可夫模型
根据上述强化学习理论建立氧气系统调度优化的马尔可夫模型,以经济指标最大化为目标:
6)状态s
观察到的氧气系统状态包括氧气需求、氧气排放、液氧出售、液氧储存、以及所在的调度周期。因而状态s可表示为:
7)动作a
在时刻t,氧气系统的动作包含离散动作和连续动作两部分,其中离散动作是各个制氧机、气化器、液化器开启,连续动作包括各设备的开启时长、氧气发生系统产生的氧气量和液氧量、储存氧气系统中液化器液化的氧气量和各气化器气化量。因此混合动作可以被表示为:
8)奖励r
氧气系统调度决策的目标是使系统的经济指标最大化。该目标与经典的强化学习要使奖励最大化目标一致,因此氧气系统获得的即使奖励可表示为:
r
由于不同时段的电价有差异,而调度目标受电价影响,因此额外增加一个奖励函数,
其中Z
因此奖励函数r可表示为目标函数与额外奖励值得加权求和,即
r=(1-τ)r
其中
9)策略
如上所述,氧气系统会根据自己的状态决定自己的行为。在马尔可夫决策过程中,策略定义为氧气系统从观察状态到动作状态的转移概率,其策略定义为
π(a∣s)=P[a
10)回报
状态动作值函数Q
Qπ(s
Bellman方程表明,当前状态的动作值只与当前的奖惩值和下一个状态的动作值有关,可以通过迭代求解。
求解氧气系统最优策略等价于求解最优状态动作值函数,即:
π
则对应的Bellman方程为:
为了使氧气系统能够感知复杂的环境状态,构建最优的行动策略,提出了深度强化学习方法来解决氧气系统调度优化问题。现有的深度强化学习(DRL)算法大多只考虑离散的动作,或者只考虑连续的动作。然而本发明调度系统既包括离散动作又包括连续动作,在离散-连续混合动作空间场景中,传统强化学习方法通过离散化近似混合空间来解决混合动作问题,或者将其松弛为一个连续集合来处理,往往无法有效解决氧气系统实际问题。
2.3混合演员-评论家体系结构
根据现有的actor-critic算法,本发明针对混合动作空间调度优化问题提出了混合actor-critic算法。如图3所示,混合actor-critic算法框架具有离散actor网络和连续actor网络两个actor网络,利用Q网络充当critic网络对策略优劣进行评价。根据氧气系统当前状态s,离散actor网络给出离散动作k,然后根据一系列离散动作得出关联矩阵D
所提出的HAC算法将混合动作空间参数化,参数化动作空间有一组离散动作A
A={((k,x
由于传统算法将离散动作所对应的连续动作参数化,默认所对应的连续动作参数化后数量唯一。然而涉及实际氧气调度问题时,多个不同离散动作对应的连续动作不同且在数量上不相等,导致参数化后的每个离散变量对应的连续变量为多维变量且维数不相等。为解决上述问题,对算法的critic网络输入进行改进,提高算法的准确率。
根据实际问题,属于离散动作k的连续动作参数x
矩阵D为∑m
以状态s、离散动作k和动作参数矩阵
使用参数为θ
其中y=r+γmax Q(s′,k(s′),x
在离散actor网络中,使用参数为θ
其中
策略梯度为
用策略梯度法更新关于离散动作的网络参数。
而对于连续actor网络,使用参数为θ
由于输入了动作参数矩阵
转变为
因而HAC算法完全抵消了神经网络权值对输入的不相关动作参数影响,解决了参数化后的连续动作与之相对应的离散动作多维不匹配问题。
2.4hac算法步骤
本发明所提出的混合actor-critic算法解决了涉及混合动作空间的实际问题,提高了算法求解速度与准确率,算法流程图如图4所示。
具体算法步骤如下:
11.输入步长
12.初始化神经网络权值
13.For t=1to T do
14.计算连续动作参数向量
15.根据分别从离散动作空间和连续动作空间选择动
16.执行动作后,将(s,a,r,s')存入经验池B
17.按mini-batch大小M从经验池B
18.定义目标y
19.计算随机梯度
20.更新权值
End for
步骤三、结果和分析
为验证本发明提出的HAC算法用于氧气系统调度优化的有效性与优越性,采用图1所示的江苏某钢铁厂氧气系统的数据进行实验。本节首先给出了采用HAC算法调度与实际生产的对比实验结果,并对所提出的算法结构进行分析,最后,将本发明所提出的算法与其他相关算法进行对比,实验细节如下所示。
3.1算法验证与分析
混合actor-critic算法用神经网络拟合强化学习策略函数和状态动作价值函数,具有3个神经网络,即离散actor网络、连续actor网络和critic网络,将神经网络隐藏层层数设为2层,每层设置200个神经元,隐藏层的激活函数均为负斜率为0.01的ReLU函数,输出层为全连接层。采用深度学习常用思想选取超参数然后根据实际训练数据进行试错调整,算法具体训练参数在表1中给出。
表1训练参数
氧气系统设备运行参数见表2。本发明采用的电价为大型电厂峰谷时规定的电价,峰时为8:00-11:00和16:00-21:00,电价为0.7564元/kWh,正常时段为6:00-8:00和21:00-22:00,电价为0.5257元/kWh,谷时为22:00-6:00,电价为03110元/kWh。气态氧和液态氧的单位成本价格固定,分别为0.35元/吨和470元/吨。
表2设备运行参数
首先对算法收敛性进行验证,采用表1所示参数进行训练。如图5所示为氧气系统训练过程中每10000个周期的平均奖励值与最大奖励值曲线。对所提出的算法进行连续测试,从图中可看出,约10000周期后算法达到收敛,得到了最优调度策略。由于氧气系统刚开始对环境不熟悉,在早期阶段获得的奖励值较小。随着训练过程的继续,氧气系统继续与环境交互以获得经验并最终达到收敛。
对算法进行离线训练后,将得到的网络参数保存,用于氧气系统的实时调度。分别从所提出的关于氧气系统的目标函数以及目标函数所涉及的三个子部分,将算法调度结果与实际生产调度结果进行比较。如图6所示为实际生产过程与算法调度后目标函数即经济指标对比结果,关于目标函数中液氧外售量、设备用电量以及气态氧放散量对比如图7、8和9所示。
本发明根据实际生产数据,对所提出的氧气系统目标函数进行计算,将其结果与算法调度后的目标函数进行对比。如图6目标函数优化结果可以看出利用HAC算法进行调度优化后,HAC算法平均经济效益为9274元/h,而实际生产的平均经济效益为7580元/h,因此HAC算法调度后比实际生产经济效益约高2000元/h。
结合图7-9对调度结果进行进一步分析,由于实际生产过程中制氧机一旦开启无意外不关闭,而气化器和液化器执行开启动作次数少,所产生的氧气量相对稳定且较少,而HAC算法对设备启动停止进行合理调度,启动停止动作相较于实际生产更频繁。如图7-8所示,用本发明算法调度后平均液氧外售量明显比实际生产过程多一倍,虽然HAC算法调度后用电量会有大幅起伏变化,在一定时间会超过实际生产过程消耗的电量,但总体低于实际生产过程的耗电量。如图9所示,算法调度最大平均放散率仅为0.34%,比实际生产过程放散率更低,在多个时间段内氧气接近无损耗,在满足调度需求的前提下,能源消耗显著降低。因此,从以上实验结果对比分析可知,利用HAC算法进行氧气系统调度优化,提高了氧气系统经济效益,液氧外售量明显增高,用电成本与氧气放散率也进一步降低,避免了能源浪费。
3.2算法结构分析对比
由于本发明在设计算法奖励函数时,设置了额外奖励函数,考虑峰时谷时设备用电量对整个调度结果的影响。为验证其合理性,如图10所示,将原算法与不设置额外奖励的算法分别对氧气系统进行调度优化,将调度优化后的策略进行分析计算,按所提出的目标函数计算各自经济指标进行比较。由图中可知,不设置额外奖励函数,峰谷时设备用电量差别较小,整体经济效益平稳低于原算法调度结果。然而用原算法调度后,峰时机器消耗电量低于谷时,整体经济效益更高,比不设置额外奖励函数平均经济效益多24%。
此外,混合actor-critic算法建立了关联矩阵D,表明两个actor网络之间的耦合关系。为验证设置关联矩阵的必要性,对HAC算法去掉关联矩阵后进行氧气系统调度策略求解。算法求解结果如图11和图12所示,结合图11设备运行甘特图和图12不同设备产量可看出,在制氧机1进行3次启动停止动作时其产氧量一直不变,且在其未开启时产量不为0,而其余设备也存在设备运行与产量不匹配的问题。因此设置关联矩阵有效提高了算法准确率。
3.3不同算法结果对比
如图13所示,为了进一步验证本发明所提出的算法可行性和优越性,将混合actor-critic算法与MP-DQN算法、P-DQN算法以及PADDPG算法进行对比。混合actor-critic算法奖励曲线约在10000回合达到收敛且奖励值最高,MP-DQN算法与P-DQN算法收敛时间较长并且奖励值低于HAC算法,而PADDPG算法虽在收敛时间上较快但平均奖励值过低无法满足调度优化需求,因此本发明所提出的算法更加稳定,收敛性和准确率较高,更能满足生产调度优化需求。图14中给出了用4种不同算法求解的调度优化策略的每10小时经济指标柱状图,可从图中看出,本发明所提出的算法具有最高的经济效益。
为直观表示MP-DQN、P-DQN、PADDPG和HAC算法这4种调度方法的效果差异,将氧气放散量和经济指标进行统计。如表3所示,基于HAC算法调度后的经济指标为274125元,比MP-DQN算法提高21.5%,比P-DQN调度方法提高45%,比PADDPG算法提高83%。因此,本发明提出的基于HAC算法的调度方法对提高钢铁企业氧气系统的经济效益有显著优势。而从气体放散量方面看,HAC算法调度后气体放散量最低,减少了气体释放损失。
表3不同调度方案氧气放散量与经济效益
本发明所提出的算法作用于混合动作空间,不仅考虑了各设备产量还同时考虑了设备的启停动作,不同设备启停消耗不同。根据表2给出的设备运行参数可知各设备的开启成本,设备频繁启停会增加能源消耗,用合理的调度策略安排设备启停,可降低成本,增加经济效益。如表4所示给出了采用四种不同算法设备总启动成本与总生产成本对比。根据表中给出的数据可知,HAC算法调度成本约为用PADDPG算法的63%,约为MP-DQN算法和P-DQN算法的67%和72%,由此可见,HAC算法调度后用电成本更低,达到了节约成本的目的。
表4不同算法求解的成本对比
根据上述不同算法的对比结果,在相同时间内,利用HAC算法调度奖励值最高且求解速度最快。调度后设备生产成本以及开启成本低于其他求解算法,并且经济效益在一定范围内有显著增加。因而采用本发明所提出算法的氧气系统调度优化方法在提高了经济效益的同时降低了能源消耗。
结论
本发明对某钢铁企业氧气系统的调度问题进行了研究,构建了液氧外售收入、设备用电成本和氧气放散损失相结合的综合经济指标。考虑到传统调度方法不能同时对系统设备启停和频繁的氧气需求变化做出合理调度,经济效益不高。本发明以深度强化学习为基础,提出了用于解决氧气系统调度问题的HAC算法,所提出的算法扩展了AC算法的actor网络,根据市场分时电价设计额外分段奖励函数。HAC算法解决了离散变量和连续变量的混合问题,在提高经济效益的同时实现节能减排。实验结果表明,HAC算法将调度问题置于混合的动作空间中,避免导致次优的动作选择的问题。与传统算法相比,HAC算法显著提高了算法的收敛性和准确性,使氧气系统具有更高的氧气利用率和经济效益。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 一种基于深度强化学习的钢铁企业氧气系统调度方法
- 一种基于拆分动作空间的深度强化学习斗地主游戏方法