一种基于宽度神经网络的广义互相关的声源定位方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及声源定位技术领域,尤其是涉及一种基于宽度神经网络的广义互相关的声源定位方法。
背景技术
随着科学技术的发展,基于语音、图像、文字等模式识别的人机交互成为研究热点。而运用麦克风阵列进行声源定位研究已经成为信号处理领域的一个研究热点。传统声源定位算法大体可分3类:基于到达时延估计(Time Difference ofArrival,TDOA)的声源定位算法、基于最大输出功率的可控波束形成声源定位算法、基于高分辨率谱估计的声源定位算法。其中,第一类算法先估计声源到达不同麦克风之间的时间差,利用所得到的时间差并结合麦克风阵列的结构,进而确定声源的位置;第二类算法利用波束形成技术,但计算复杂度较高耗时较长;第三类算法来源于高分辨率谱估计技术,可以实现多目标定位,但多适用于远场模型。在3类方法中,TDOA算法因其计算复杂度与硬件实现成本较低而受到较多关注。其中应用最广泛的为基于相关分析的广义互相关函数法(Generialized Cross-Correlation,GCC)但GCC算法对于噪声和混响的抗干扰能力不足。
近年来,越来越多的学者开始探索新的算法应用于声源定位中。例如基于压缩感知的声源定位算法。随着神经网络的提出与发展,基于机器学习的声源定位算法被提出。将神经网络模型应用于移动机器人的声源定位,定位精度得到提高,但存在计算量大,计算时间长的问题,其抗干扰能力依旧有待提高。
发明内容
本发明的目的是提供一种基于宽度神经网络的广义互相关的声源定位方法,解决声源定位复杂、费时、抗噪声干扰能力弱的问题。
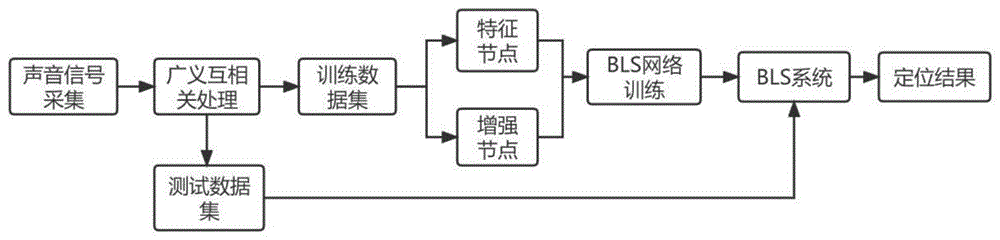
为实现上述目的,本发明提供了种基于宽度神经网络的广义互相关的声源定位方法,包括以下步骤:
S1、采用并下载公开数据集NOIZEUS中的音频,得未经处理过的原始音频数据;
S2、将得到的原始音频数据进行滤波、分帧、加窗、语音活动检测的预处理;
S3、构建麦克风阵列,采用阵列模拟并接收来自不同位置的声源信号;
S4、将选取的基准麦克风和其余麦克风接收到的音频信号两两做广义互相关处理,提取声源特征构建输入数据集train_x、test_x;
S5、根据数据集和实验需求构建BLS神经网络,并将S4中构建的数据集输入到BLS网络模型进行训练,网络的初始权重采用随机赋值,最后得到最优的网络输出以及模型相关参数。
优选的,所述S2中,对原始音频数据预处理的具体方式为:将采集到的语音信号按照实验要求进行分帧、加窗、语音活动检测,采用短时能量和过零率的双门限检测法。
优选的,所述S4中,广义互相关处理的具体方式为:
将一个麦克风作为基准麦克风,与其他麦克风两两做互相关,通过两个信号x1(t),x2(t)之间的互功率谱,并在频域内基于一定的加权,来对信号和噪声进行白化处理,增强信号中信噪比较高的频率成分,从而抑制噪声的影响,再反变换到时域,得到两个信号之间的广义互相关GCC函数;
广义互相关时延估计算法为:
假设两个麦克风接收的信号模型为:
x
x
其中,s(n)为声源信号,d为两个阵源接收到信号之间的时延,n为接收到数字信号的时间采样点,α
x
其中,τ表示平移距离,R
假设信号与噪声、噪声与噪声之间互不相关,
则:
x
R
当τ=d时互相关函数取得最大值,d就是估计值。
优选的,所述S5中构建BLS神经网络的具体方式为:
S51、生成特征节点;利用输入数据(train_x、test_x)映射的特征作为网络的特征节点;
S52、生成增强节点;映射的特征被增强为随机生成权重的增强节点,利用增强节点对随机的特征节点进行补充,增加网络中的非线性因素;
S53、求伪逆;所有映射的特征节点和增强节点直接连接到输出端,一起作为网络的输出,对应的权重系数通过Pseudo伪逆得出;
S54、测试。
优选的,所述S51中生成特征节点的具体步骤为:
S511、对train_x进行z分数标准化,在进行标准化之前,采用mapminmax归一化方法,[y,ps]=mapminmax(x1),将训练集归一化至0-1之间;
S512、对train_x进行增广,即在其最后增加一列1,使维度变为train_x
S513、为每个窗口生成特征节点;
S514、随机生成特征节点系数权重矩阵we,其维度为(f+1)×N1,其中N1表示每个窗口特征节点的个数;
S515、将更新权重矩阵we放入We{i}中,i表示迭代量,迭代次数为N2,其中N2表示特征节点的窗口个数;
S516、A1=H1×we,其中A1表示输入特征进行了一次权值随机的卷积和偏置得到的新的特征矩阵;
S517、对A1进行归一化;
S518、对A1进行稀疏化处理,得到系数权重矩阵beta,beta是一个N1×(f+1)维度的系数权重矩阵;
T1=A1*beta,其中T1为一个窗口的特征矩阵;
将进行归一化后的T1存储到特征节点矩阵y中。
优选的,所述S52中生成增强节点的具体步骤为:
S521、对特征节点矩阵y进行标准化与增广,得到H2;
S522、对增强节点进行激活
S523、生成网络的输入T
优选的,所述S53中,伪逆
优选的,所述S54中,测试的无增量学习,模型训练完成后,使用测试数据test_x、test_y进行声源位置的预测和验证;并根据网络的输出进行参数的调整,直到模型参数符合要求为止。
优选的,所述S54中,测试的增量学习,模型训练完成后,将测试集test_x、test_y输入到有增量学习的BLS网络中进行声源位置的预测。
本发明所述的一种基于宽度神经网络的广义互相关的声源定位方法,将基准麦克风与其他麦克风两两做互相关,并在频域内加权,增强了信号中信噪比较高的频率成分,抑制了噪声的影响,提高了抗干扰能力。通过生成增强节点,增加增量学习,增强节点不需要稀疏表示,不需要进行窗口迭代,缩短了分析时间。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
图1为本发明一种基于宽度神经网络的广义互相关的声源定位方法实施例的流程示意图。
具体实施方式
以下通过附图和实施例对本发明的技术方案作进一步说明。
实施例
一种基于宽度神经网络的广义互相关的声源定位方法,包括以下步骤:
S1、采用并下载公开数据集NOIZEUS中的音频,得未经处理过的原始音频数据。NOIZEUS数据库包含30个IEEE句子,这些句子被不同SNR的八个不同的噪声所破坏。噪音取自AURORA数据库,包括郊区火车噪音、嘟嘟声、汽车、展览厅、餐馆、街道、机场和火车站噪音。
S2、将得到的原始音频数据进行滤波、分帧、加窗、语音活动检测的预处理。对原始音频数据预处理的具体方式为:将采集到的语音信号按照实验要求进行分帧(帧长:320个点,即20ms,帧重叠率50%)、加窗(采用汉明窗)、语音活动检测(VAD),采用短时能量和过零率的双门限检测法。
S3、构建麦克风阵列,采用阵列模拟并接收来自不同位置的声源信号。将提前准备好的音频信号放在指定的位置,实验中,声源的高度与麦克风阵列高度设定为同一高度,因此,声源的俯仰角为0°,方位角的范围选取范围为[-90°,90°],方位角的角度值采用随机生成的90个整数。并设定不同的信噪比(0dB,5dB,10dB,15dB),将同一dB下的音频信号(共30条)分别放置于设定的90个位置,然后通过模拟麦克风阵列对音频信号进行接收和采集,再经过广义互相关处理后,可得到所需的语音特征。
S4、将选取的基准麦克风和其余麦克风接收到的音频信号两两做广义互相关处理,提取声源特征构建输入数据集train_x、test_x。实验采用4个麦克风,将选取的基准麦克风和其余麦克风接收到的音频信号两两采用广义互相关,即每个位置将会得到6组广义互相关值(GCC),以此来构建输入数据集train_x、test_x。
对麦克风阵列接受的语音信号做广义互相关计算的具体方式为:
将一个麦克风作为基准麦克风,与其他麦克风两两做互相关,通过两个信号x1(t),x2(t)之间的互功率谱,并在频域内基于一定的加权,来对信号和噪声进行白化处理,增强信号中信噪比较高的频率成分,从而抑制噪声的影响,再反变换到时域,得到两个信号之间的广义互相关GCC函数。此处采用PHAT加权函数。当噪声之间不相关时,PHAT不会像其他预处理方法使得互相关扩散。
广义互相关时延估计算法为:
假设两个麦克风接收的信号模型为:
x
x
其中,s(n)为声源信号,d为两个阵源接收到信号之间的时延,n为接收到数字信号的时间采样点,α
x
其中,τ表示平移距离,R
假设信号与噪声、噪声与噪声之间互不相关,
则:
x
R
当τ=d时互相关函数取得最大值,d就是估计值。
根据维纳-辛钦定理,互相关函数及其互功率谱之间的关系表示为:
其中,G
引入加权因子后的互相关函数频域表达式为:
其中,
S5、根据数据集和实验需求构建BLS神经网络,并将S4中构建的数据集输入到BLS网络模型进行训练,网络的初始权重采用随机赋值,最后得到最优的网络输出以及模型相关参数。
神经网络的设计思路为:首先,利用输入数据(train_x、test_x)映射的特征作为网络的“特征节点”。映射的特征被增强为随机生成权重的“增强节点”。并将所有映射的特征节点和增强节点直接连接到输出端,一起作为网络的输出,对应的权重系数可以通过Pseudo伪逆得出。最后使用训练好的神经网络模型对声源位置做预测。
S5中构建BLS神经网络的具体方式为:
S51、生成特征节点;利用输入数据(train_x、test_x)映射的特征作为网络的特征节点。宽度学习的核心就是求特征节点和增强节点到目标值的伪逆。其中,特征节点和增强节点相对应的是神经网络的输入,求得的逆矩阵相当于神经网络的权值,那么需要建立输入数据到特征节点的映射。test_x为测试集输入数据集,选取100个样本,每个样本3834个特征维度。
生成特征节点的具体步骤为:
S511、对train_x进行z分数标准化,在进行标准化之前,采用mapminmax归一化方法,[y,ps]=mapminmax(x1),将训练集归一化至0-1之间。
S512、对train_x进行增广,即在其最后增加一列1,使维度变为train_x
S513、为每个窗口生成特征节点。
S514、随机生成特征节点系数权重矩阵we,其维度为(f+1)×N1,其中N1表示每个窗口特征节点的个数,初始值为10。
S515、将更新权重矩阵we放入We{i}中,i表示迭代量,迭代次数为N2,其中N2表示特征节点的窗口个数,初始值为10。
S516、A1=H1×we;其中A1表示输入特征进行了一次权值随机的卷积和偏置得到的新的特征矩阵。
S517、对A1进行归一化。
S518、对A1进行稀疏化处理,得到系数权重矩阵beta,beta是一个N1×(f+1)维度的系数权重矩阵;
T1=A1*beta,其中T1为一个窗口的特征矩阵;
将进行归一化后的T1存储到特征节点矩阵y中。
S52、生成增强节点;映射的特征被增强为随机生成权重的增强节点,利用增强节点对随机的特征节点进行补充,增加网络中的非线性因素。
生成增强节点的具体步骤为:
S521、对特征节点矩阵y进行标准化与增广,得到H2。
此外,增强节点的系数权重矩阵并不是简单的随机矩阵,而是经过正交规范化后的随机矩阵。
S522、对增强节点进行激活
S523、生成网络的输入T
与特征节点相比,增强节点不需要进行性稀疏化处理和循环迭代,虽然在生成过程中需要做正交规范化处理,该过程会耗费一定的计算时间,但增强节点生成所需时间少于生成特征节点所需时间。网络最终的输入T
每个样本的特征维度为N1×N2+N3,其中N3表示增强节点个数,N3初始值为500。
S53、求伪逆;所有映射的特征节点和增强节点直接连接到输出端,一起作为网络的输出,对应的权重系数通过Pseudo伪逆得出。test_y为测试集声源真实位置标签,用于预测值的验证,选取100个样本,每个样本2个特征维度,形式为(x,y)。
神经网络的目的就是要求得输入到输出的映射。假设xx为网络的输出值,即xx=T
S54、测试。
测试的无增量学习,模型训练完成后,使用测试数据test_x、test_y进行声源位置的预测和验证;并根据网络的输出进行参数的调整,直到模型参数符合要求为止。BLS神经网络需要保存的参数其实只有W和ps,所以相比于深度学习,网络参数量很少。
测试的增量学习,模型训练完成后,将测试集test_x、test_y输入到有增量学习的BLS网络中进行声源位置的预测。
增量学习的BLS神经网络设定100个特征节点,300个增强节点,实验中发现:当增强节点个数到达500个时,其训练的精度急剧下降,甚至低于90%,经过多次的重复实验,训练精度并未得到提升,然而当特征节点数增加到450个时,训练的精度最高,故在本实验中选取增强节点为450个时停止动态增长阈值条件。之所以设定增量学习,是由于本文所采用的宽度学习算法,在数据量增加时,可以逐步更新建模系统,而无需从一开始重新训练整个系统。
增量学习的增量方式为:
只动态增长增强节点,设定特征节点数为100,增强节点数为300,每次动态增加50个增强节点,直到增强节点个数为450个时停止增长。每做一轮动态增长,便进行一轮声源位置的预测。
因此,本发明采用上述基于宽度神经网络的广义互相关的声源定位方法,能够在一定程度上解决声源定位复杂、费时、抗噪声干扰能力弱的问题。
最后应说明的是:以上实施例仅用以说明本发明的技术方案而非对其进行限制,尽管参照较佳实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对本发明的技术方案进行修改或者等同替换,而这些修改或者等同替换亦不能使修改后的技术方案脱离本发明技术方案的精神和范围。
- 一种基于卷积神经网络的双耳声源定位方法
- 基于互相关序列和神经网络的任意阵列声源定位方法
- 一种基于深度神经网络和卷积神经网络的双耳声源定位方法和系统