一种动态广义用户NOMA分组CCHN-MEC网络卸载决策优化方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及CCHN-MEC网络资源分配技术领域,具体涉及一种动态广义用户NOMA分组CCHN-MEC网络卸载决策优化方法。
背景技术
物联网(Internet of Things,IoT)已经成为我们日常生活的一部分,由此产生了多种计算密集型和延迟敏感型应用,比如人脸识别、自然语言处理等。为了满足低复杂度设备的延迟敏感型计算需求,学界提出了移动边缘计算(Mobile Edge Computing,MEC)。此外,由于无线频谱有限,研究人员开发支持MEC的新技术,如NOMA(Non-OrthogonalMultiple Access,非正交多址接入)和认知无线电(Cognitive Radio,CR)。然后,MEC和CR的组合,以及MEC和NOMA的组合成为热门的研究课题。
最近,有学者提出了一种新的CR基础设施,即认知容量收割网络(CCHN,Cognitivecapacity harvesting network),以允许无管理/感知能力的手持轻型设备享受CR网络(CRN)的好处。在CCHN中,引入了次级服务提供商(Secondary Server Provider,SSP),它部署了一组CR路由器来监视/检测CR频谱,并购买一小块许可频谱来构建可靠的公共控制信道。通过公共控制信道,SSP收集CR路由器的管理/感知结果,引导CR路由器形成CRN,并分配CR频谱。无管理/感知能力的次等用户(Secondary User,SU)可以通过分配的CR频谱访问附近的CR路由器。事实上,CCHN引入一个新的网络运营商,该运营商负责构建基础设施,从拥有频谱的主要网络运营商那里获取频谱,并在没有管理/感知能力的情况下为SU提供服务。
假设CR路由器已经配备了计算资源,因此CCHN可以提供MEC服务。在CCHN中,为了减少对主网络的干扰,考虑到SU的传输功率的有限性,为了满足SU任务的延迟限制,有必要引入“广义用户分组”提升网络性能,即允许一个SU加入多个NOMA组,并通过不同的传输信道将其不同部分的数据卸载到不同的CR路由器。
然而,现有的研究NOMA-MEC并没有采用广义用户分组传输方式,大大的降低了网络性能。同时,由于传统的优化方案本身无法避免的高复杂度性,无法满足MEC系统的实时性决策需求。因此,在基于广义用户分组NOMA的CCHN-MEC系统中,设计一种支持动态计算卸载决策的优化方案非常重要。目前,可用于广义用户分组NOMA的CCHN-MEC系统的动态卸载决策优化方案主要有TD3算法、纯本地计算(LO)和随机分配(RA)算法。由于TD3算法旨在寻找一个确定性的策略,难以适用于随机变化的NOMA-CCHN-MEC场景,因此能耗可能会大大提高;LO算法没有考虑充分利用MEC服务器的计算资源,在时延要求很高的情况下,能耗上升幅度显著;RA算法并没有考虑系统的变量之间的耦合性,性能较差。
发明内容
针对现有技术存在的问题,本发明的目的在于提供一种动态广义用户NOMA分组CCHN-MEC网络卸载决策优化方法,其能够获得更合理的卸载决策,大幅降低系统能耗。
为实现上述目的,本发明采用的技术方案是:
一种动态广义用户NOMA分组CCHN-MEC网络卸载决策优化方法,CCHN包含一组SU、一组CR路由器和一个SSP;SSP通过已经建立的公共控制信道集中管理SU和CR路由器;CR路由器配备计算资源并充当MEC服务器;相邻小区的上行蜂窝频谱被划分为一系列蜂窝资源块CRB;CRB的分配已经完成,且每个CR路由器都已经分配一个CRB,用于与其相连的SU的数据卸载;
所述决策优化方法采用SAC算法进行求解,SAC智能体包括一个Actor和两个Critic,Actor是一个含有若干层全连接DNN,记为
所述决策优化方法具体如下:
步骤1、设置折扣因子λ,软拷贝因子ι,最大时隙数T,最大轮次Γ;
步骤2、随机初始化Actor的神经网络参数
步骤3、随机生成一个卸载比率动作,以获取一个CCHN-MEC环境中的状态
步骤4、根据状态
步骤5、根据卸载比率决策动作
步骤6、根据卸载比率决策动作
步骤7、根据卸载比率决策动作
步骤8、根据步骤5、6和7,计算系统总能耗E
步骤9、根据步骤8,计算当前系统的奖励r
步骤10、将当前时隙的经验
步骤11、如果在重放经验池
步骤12、t=t+1;如果当前时隙数t>T,则t=1,e=e+1,若e>Γ则进入步骤13;否则,返回步骤3;
步骤13、输出Actor的神经网络最优参数
所述步骤5中,本地能耗最小化问题为:
其中,
所述步骤6中,通过以下公式(7)获得
所述步骤7中,卸载能耗优化问题为:
其中,
约束C1表示NOMA组的传输时间不能超过每个时隙长度,约束C2表示分配给NOMA组内的SU的计算CPU频率不能超过CR路由器的最大CPU频率,约束C3表示每个SU卸载数据的速率要求,约束C4表示每个SU的发射功率的限制,约束C5表示NOMA组内的SU的干扰功率不能超过各个BS的最大容忍干扰值。
所述步骤8中系统总能耗E
其中,
所述步骤9中,利用公式(10)计算当前系统的奖励r
其中,其中
所述步骤11中,依据公式(12)-(15)更新网络参数θ
最小化Bellman残差值通过下式计算:
其中,
Actor的DNN通过最小化KL散度来训练,即最小化
其中
温度参数∈通过最小化如下式子来动态调整
其中
每个Critic中目标DNN的权重参数通过软拷贝法进行更新,即
采用上述方案后,本发明首先在给定计算卸载比率下,推导得到本地能耗最小化问题的最优解,即次级用户(Secondary User,SU)本地的最优CPU频率分配
附图说明
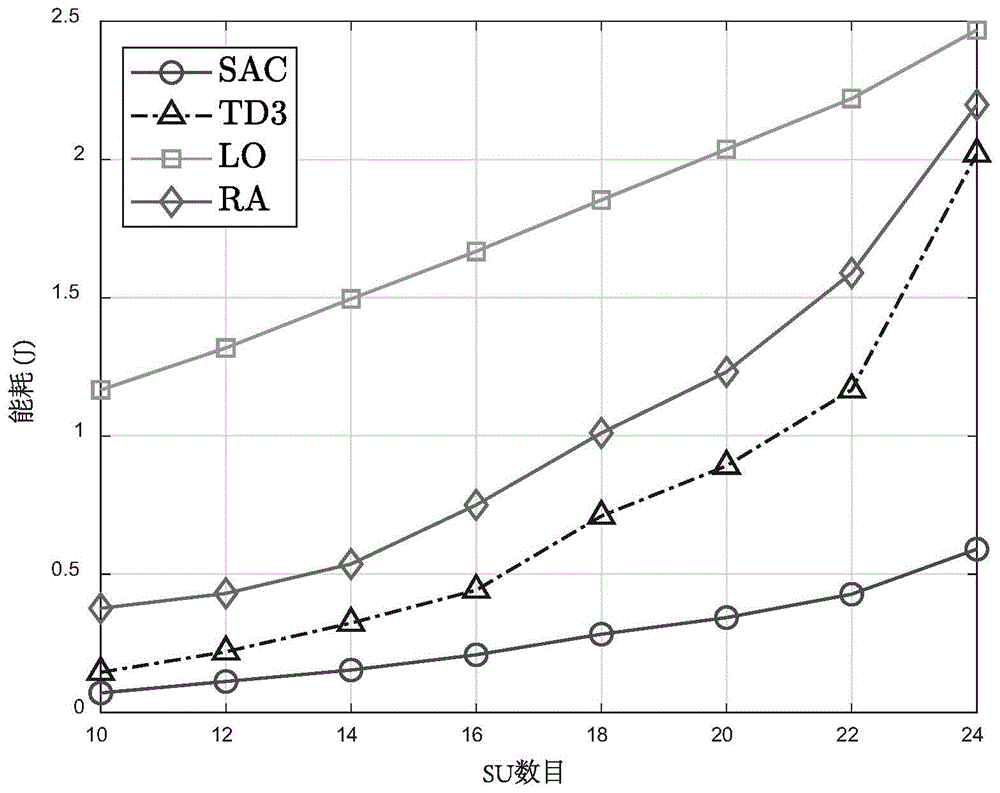
图1为本发明(SAC)与TD3算法、LO算法和随机分配RA算法在SU数目变化下的能耗对比;
图2为本发明(SAC)与TD3算法、LO算法和RA算法在每个SU的卸载数据总量变化下的能耗对比;
图3为本发明(SAC)与TD3算法、LO算法和RA算法在每个时隙的长度变化下的能耗对比。
具体实施方式
本发明揭示了一种动态广义用户NOMA分组CCHN-MEC网络卸载决策优化方法,其所应用的所考虑的CCHN包含一组SU、一组CR路由器和一个SSP。SSP通过已经建立的公共控制信道集中管理SU和CR路由器。CR路由器配备计算资源并充当MEC服务器。考虑CCHN通过在相邻小区中共享上行链路蜂窝频谱为SU提供服务。相邻小区的上行蜂窝频谱被划分为一系列蜂窝资源块(Cellular Resource Block,CRB)。由于采用空间重用技术,根据空间重用因子,每个CRB可在几个相邻小区中供蜂窝用户(Cellular User,CU)使用。为了简化分析,假设CRB的分配已经完成,且每个CR路由器都已经分配一个CRB,用于与其相连的SU的数据卸载。
系统时间时隙化τ={1,2,...,T},其中τ是每个时隙的长度。在每个时隙中,每个SU都有一个计算任务需要完成。假设SU是轻量级的,因此需要将其部分任务卸载到CR路由器。考虑采用NOMA技术,选择同一个CR路由器进行数据卸载的SU形成一个NOMA组。考虑广义用户分组,即每个SU可加入多个NOMA组,并将其不同部分的任务同时卸载到多个CR路由器,以减少对主网络的干扰,同时降低卸载延迟。
为了降低串行干扰消除(Successive Interference Cancellation,SIC)解码的复杂度,设置了一个系统参数来限制与一个CR路由器连接的最大SU数目。此外,与许多现有的MEC工作一样,假设任务计算结果的大小足够小,因此从CR路由器下载任务计算结果到SU的过程所涉及的能耗忽略不计。
令
令β
令L表示与CR路由器h
其中I(y)是y的函数,定义为
为了降低优化复杂度,我们设置了一个参数来限制每个SU允许使用的CRB的数量。也就是,
其中Y是每个SU允许使用的CRB的最大数量。注意Y=1代表没有广义用户分组的情况。
系统中每个时隙t的总能耗E
其中,
(1)当给定SU的卸载比率
其中,
(2)当给定SU的卸载比率
(3)当给定SU的卸载比率
其中,
很显然地,当给定计算卸载比率
1)状态:为了节省状态空间大小,时隙t中的状态,
2)动作:时隙t中智能体的动作通过SU的扩展计算卸载比率定义,
3)奖励:时隙t中DRL智能体的即时奖励定义r
其中,其中
其中,
ρ
考虑到该系统的状态与动作空间都是连续的,为了获得接近最优的卸载比率决策,采用SAC算法来求解。为了处理高维连续状态和动作空间,SAC智能体的Actor和Critic利用深度神经网络(Deep Neural Network,DNN)近似。Actor是一个含有若干层全连接DNN,记为
为了训练每个Critic的主DNN,需要最小化Bellman残差,其值可通过下式计算
/>
其中
Actor的DNN通过最小化KL散度来训练,即最小化
其中
温度参数∈通过最小化如下式子来动态调整
其中,
每个Critic中目标DNN的权重参数通过软拷贝法进行更新,即
本发明的计算卸载比率优化方法具体包括以下步骤:
步骤1、折扣因子λ,软拷贝因子ι,最大时隙数T,最大轮次Γ;
步骤2、随机初始化Actor的神经网络参数
步骤3、随机生成一个动作,以获取一个CCHN-MEC环境中的状态
步骤4、根据状态
步骤5、根据卸载比率决策动作
步骤6、根据卸载比率决策动作
步骤7、根据卸载比率决策动作
步骤8、根据步骤5、6和7,利用式(5)计算系统总能耗E
步骤9、根据步骤8,利用式(10)计算当前系统的奖励r
步骤10、将当前时隙的经验
步骤11、如果在重放经验池
步骤12、t=t+1;如果当前时隙数t>T,则t=1,e=e+1,若e>Γ则进入步骤13;否则,返回步骤3;
步骤13、输出Actor的神经网络最优参数
为了评估本发明性能,进行以下仿真,仿真参数设置为:包含一个中心小区,周围有六个相邻小区,频率重用因子为7。每个小区的半径设置为500m。所考虑的CCHN位于中心小区,并使用六个相邻小区的蜂窝频谱进行数据卸载。在每个相邻小区中,BS位于中心,CU均匀分布。在中心小区中,SU和CR路由器均匀分布。相邻小区的每个CRB随机分配一个活动CU。每个CU的发射功率和速率要求分别设置为23dBm和200knats/s,用于计算每个CR路由器的最大干扰和噪声功率水平以及每个CRB中的最大允许干扰功率。SU和CR路由器的硬件相关计算能量常数κ
表1
图1到图3分别对比了所提的SAC算法与TD3算法、LO算法和RA算法在SU数目,每个SU的卸载数据总量以及每个时隙的长度变化下的能耗。在LO算法中,每个SU的整个计算任务都是在本地计算的。在RA算法中,每个CRB中每个SU的计算卸载比率是随机分配的。在每个点中,计算每个算法在30个实验轮次每个轮次包含100个时隙上的平均能耗。每个SU的卸载数据总量和每个时隙的长度分别设置为160knats和500ms。SU个数和每个时隙长度分别设置为16和500ms。SU的数目和卸载数据总量分别为16和160knats。从图1-3,可得到两个观察结果。首先,所有算法的能耗都随着SU数目和每个SU卸载数据总量的增加,或者每个时隙长度的减小而增加。原因是当SU的总计算需求变大,或者延迟约束越为严格时,需要为每个SU分配更大的计算频率,导致能耗增加。其次,与TD3、LO和RA算法相比,SAC算法平均可分别节省56.3%、88.9%和73.2%的能耗。原因SAC算法采用熵正则化来增加动作选择的随机性,使得SAC算法有更大的概率找到最优动作,获得更为合理的卸载决策,从而大幅降低系统能耗。
以上所述,仅是本发明实施例而已,并非对本发明的技术范围作任何限制,故凡是依据本发明的技术实质对以上实施例所作的任何细微修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 一种基于Lyapunov优化的雾计算动态卸载方法
- 一种上行链路NOMA系统用户分组和功率分配的联合优化方法
- 一种基于NOMA的网络切片动态联合用户关联和功率分配方法