基于深度特征点匹配的空天非合作目标位姿估计方法及装置
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于图像处理、深度学习、航空航天领域,具体涉及一种基于深度特征点匹配的空天非合作目标位姿估计方法及装置。
背景技术
在轨服务的发展和应用是空天科技的重要突破之一,是实现空间抓捕、碎片清理、航天器回收、在轨维修等未来需求的重要保障。近几年全球各国航天器发射快速增加,对空间在轨服务的需求呈爆炸式增长。在轨服务过程中,获取服务卫星和目标卫星间的相对位姿是实现后续制导及控制的重要保障,因此研究空间环境下目标的准确位姿估计显得极为迫切,对加强空间安全和发展国民经济有重要意义。非合作目标由于缺乏目标的运动、表面结构和惯性参数等信息,相对位置和姿态估计问题变得尤为复杂。
在空间抓捕、碎片清理及航天器维修等在轨服务中,空间目标大多属于非合作目标,即不能主动与航天器进行状态信息交互、未安装光学标志器且几何模型未知。对于此类非合作目标,由于缺乏目标的运动、表面结构和惯性参数等信息,相对位置和姿态估计问题变得尤为复杂。同时,星载传感器选型受质量、功耗、体积等的严格约束,单目可见光相机目前依然是实现非合作目标位姿估计的首选手段。同时,不同的非合作目标表面结构差异较大,且目标成像易受复杂空间环境影响,比如逆光导致的空间目标局部遮挡,以及高光导致的空间目标局部暗弱等。这对基于图像的非合作目标位姿估计造成了较大障碍。综上所述,围绕非合作目标位姿估计,需要解决的问题如下:
(1)针对非合作目标的前后景不显著问题,充分挖掘复杂空间环境下非合作目标的泛化性特征,提高深度学习目标识别模型的准确度和泛化能力;
(2)针对非合作目标特征点提取精确度不高问题,提取目标的亚像素关键点特征,降低离散像素点造成的误差,提高目标姿态估计的准确度和鲁棒性。
现有的姿态估计方法往往基于传统特征点匹配算法开展,受到空间环境的光照标变化、目标遮挡等复杂条件影响较大,匹配结果鲁棒性差,难以适应星载位姿估计需求。
发明内容
本发明所要解决的技术问题是:
为有效提升位姿估计模型对于空间非合作目标图像中目标位姿的估计能力,提升模型位姿估计的效能,本发明提出了一种基于特征点回归的非合作目标位姿估计模型,引入多通道特征点配对网络和非迭代不匹配移除模块,提升模型对非合作目标估计的准确性和鲁棒性。
为了解决上述技术问题,本发明采用的技术方案为:
一种基于深度特征点匹配的空天非合作目标位姿估计方法,其特征在于包括:
获取非合作目标的视频数据,按顺序分解为单帧图像;
对单帧图像进行检测定位,截取目标点,删去图像中的无关背景,使得截取后图像中目标位于图像中间位置;
构建目标图像关键点提取模型,从第一帧和后续帧中的RGB图像和深度图像中分别提取亚像素关键点;
构建多维匹配模型,利用三重损失函数,获取体参考系中关键点的配对;
采用非迭代不匹配移除方法从匹配的关键点中提取目标旋转矩阵,获得非合作目标的姿态信息。
本发明进一步的技术方案:还包括对获得的单帧图像数据进行数据增强,以增强原数据集的数据多样性,扩展数据分布范围。
本发明进一步的技术方案:所述目标图像关键点提取模型包括编码器解码器特征提取模块和特征点坐标亚像素化模块,所述编码器解码器特征提取模块将单帧图像分解为匹配分数图和特征描述图;所述特征点坐标亚像素化模块将匹配分数图的像素级关键点转化为亚像素级关键点,利用亚像素级关键点对特征描述图进行双线性插值、正则化,得到亚像素级特征描述图。
本发明进一步的技术方案:所述编码器解码器特征提取模块包括四层卷积层,包括两次下采样层和两次上采样层,卷积核尺寸为3,卷积步长为1。
本发明进一步的技术方案:将匹配分数图的像素级关键点转化为亚像素级关键点具体为:
将关键点和他周围的临近点的特征分数作为特征点的概率,对局部窗口进行积分回归,采用Softargmax方法计算关键点的坐标期望:
其中,i和j分别表示x和y方向的像素偏移量,(x
通过得到Δx和Δy,修改后的亚像素关键点坐标(x′,y′)表示为:
(x′,y′)=(x
本发明进一步的技术方案:所述多维匹配模型包括:
对提取的关键点进行分类和去除重复特征点;
利用相机内参将特征点统一到同一个坐标系中;
采用交叉注意模块和自注意模块提取匹配描述符,采用多维度Sinkhorm选代算法获得权重分配图,权重分配图利用三重损失函数实现迭代更新最终输出匹配分数和匹配对,实现特征点正确匹配对。
本发明进一步的技术方案:所述三重损失函数为:
其中,
本发明进一步的技术方案:所述非迭代不匹配移除方法具体为:
通过最远点采样算法FPS对生成的匹配关键点(M
将两对匹配的关键点生成一个Hessian矩阵H,通过奇异值分解算法生成旋转矩阵R;
通过Rodrigues的旋转公式从旋转矩阵R生成姿态值P;
通过旋转矩阵R从图像i预测图像j的M
一种基于深度特征点匹配的空天非合作目标位姿估计装置,其特征在于包括:
数据获取模块,用于获取非合作目标的视频数据,按顺序分解为单帧图像;
数据处理模块,用于对单帧图像进行检测定位,截取目标点,删去图像中的无关背景,使得截取后图像中目标位于图像中间位置;构建目标图像关键点提取模型,从第一帧和后续帧中的RGB图像和深度图像中分别提取亚像素关键点;构建多维匹配模型,利用三重损失函数,获取体参考系中关键点的配对;
位姿估计模块,用于从匹配的关键点中提取目标旋转矩阵,获得非合作目标的姿态信息。
本发明的有益效果在于:
本发明提供的一种基于深度特征点匹配的空天非合作目标位姿估计方法及装置,提出了一种基于特征点回归的端到端非合作目标姿态估计模型,能够精确地估计物体的姿态。构建了特征点回归提取模块,从RGB图像和深度图像中提取亚像素关键点。设计了一个多通道特征点配对网络,利用三种损失函数,获取体参考系中关键点的配对。提出了一种非迭代不匹配移除方法,进一步提高配对精度,并从匹配的关键点中提取目标旋转矩阵,获得非合作目标的姿态信息。
本发明方法解决了非合作目标的前后景不显著问题和非合作目标特征点提取精确度不高问题,提高了目标姿态估计的准确度和鲁棒性。
附图说明
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
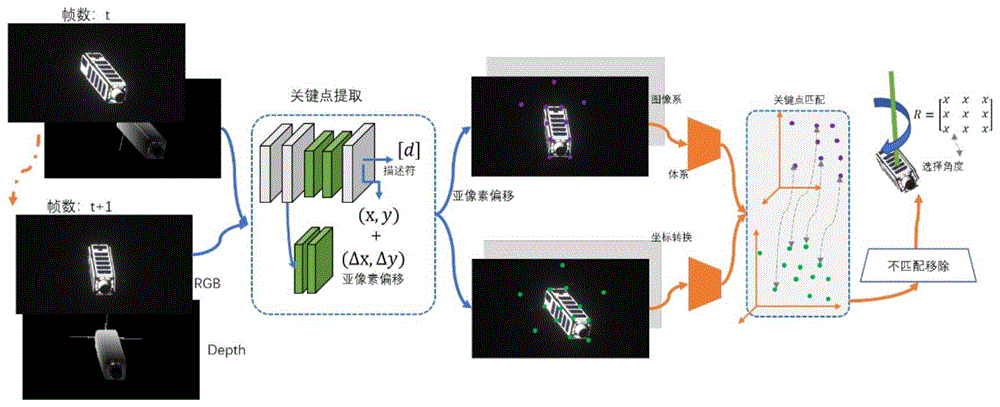
图1为本发明设计的非合作目标位姿估计流程示意图。
图2为本发明设计的目标图像关键点提取模型示意图。
图3为本发明设计的多维匹配模型的流程图。
图4为本发明设计的非迭代法不匹配筛选算法流程图。
图5为不同方法的监督姿态估计ROC。(a)姿态差为0到10度时姿态误差的召回ROC;(b)姿态差异为10至20度时姿态误差的召回ROC;(c)姿态差从20°到30°的姿态误差召回ROC。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明提出一种基于特征点回归的端到端非合作目标姿态估计模型,能够精确地估计物体的姿态。构建了特征点回归提取模块,利用编码器-解码器结构,从RGB图像和深度图像中提取亚像素关键点。设计了一个多通道特征点配对网络,利用三种损失函数,获取体参考系中关键点的配对。提出了一种非迭代不匹配移除方法,进一步提高配对精度,并从匹配的关键点中提取目标旋转矩阵,获得非合作目标的姿态信息。
包括如下步骤:
步骤一:空间飞行器加载了RGBD相机的传感器平台获得废弃卫星、陨石等包含多个非合作目标的视频数据,并将其按帧顺序分解为单帧图像;
步骤二:对于获得的单帧图像数据进行数据增强,包括随机改变图像对比度、亮度、旋转、翻转、平移等操作,以增强原数据集的数据多样性,扩展数据分布范围;
步骤三:利用成熟的目标检测模型(比如FasterRCNN、YOLO系列、Centernet目标检测模型)对图像进行检测定位,截取目标点,删去图像中的无关背景,使得截取后图像中目标位于图像中间位置;
步骤四:构建特征点回归提取模块,利用编码器-解码器结构,从第一帧和后续帧中的RGB图像和深度图像中分别提取亚像素关键点;所述编码器-解码器结构为基于多层卷积神经网络的编码器解码器;
步骤五:设计了一个多通道特征点配对网络,利用三种损失函数,获取体参考系中关键点的配对;
步骤六:提出了一种非迭代不匹配移除方法,进一步提高配对精度,并从匹配的关键点中提取目标旋转矩阵,获得非合作目标的姿态信息;
步骤七:将现有的空间非合作目标姿态估计方法与本发明的姿态估计结果进行对比分析。
由于非合作目标图像的数据集数量有限,为了使数据特征分布的更加全面,因此使用随机对比度、随机亮度、随机翻转、随机旋转等操作对数据集进行增强,以提升模型在多种情况下的鲁棒性,在对数据集进行增强后将其随机分为训练集、验证集和测试集。
图1为本发明设计的非合作目标位姿估计方法,为了使自主机器能够取代当前基于手动建模的估计并最大限度地减少估计误差,这项工作旨在高效准确地估计非合作目标的行为。本发明采用基于深度学习的三部分姿态估计流程来实现准确估计。为了从RGB和深度图像中提取亚像素关键点,首先提出了编码器解码器特征提取模块和亚像素提取模块。之后使用三重损失多通道匹配模块获得体系中匹配的关键点对。最后使用成功匹配的关键点提取目标旋转矩阵,然后使用不匹配去除方法进一步提高匹配精度。
图2为本发明设计的目标图像关键点提取模型,模型的输入是长和宽分别是H和W的单帧图,模型的输出包括一个形状为H×W的匹配分数图和一个形状为H×W×256的描述图。匹配分数图描述了原始图像中每个像素点是一个特征关键点的概率大小。给分数图设定合适的阈值,就可以提取特征点,但此时关键点的坐标为像素级整数坐标,限制了模型对于关键点定位精度的精度。为了解决这个问题,本发明设计了特征点坐标亚像素化模块,将邻域像素特征与原始特征点融合,实现每个特征点的亚像素精度。具体步骤为,将关键点和他周围的临近点的特征分数作为特征点的概率,对局部窗口进行积分回归,计算关键点的坐标期望。此外,为了保持可微分的特性,引入了一种Softargmax方法来计算坐标期望。公式为:
其中,i和j分别表示x和y方向的像素偏移量。它们的值为-2、-1、1、2。(x
(x′,y′)=(x
之后,通过对生成的亚像素关键点进行双线性插值操作。每个关键点都有一个256维向量作为其描述符。然后使用L2函数对这些向量进行正则化,以生成最终的256维描述符。
图3表示多维匹配模型的流程图。首先处理重复位置,对从RGB图像和深度图像中提取的关键点进行分类和处理。通过NMS过程去除重复的特征点,处理后的关键点集变为:
P
其中,P
之后,将关键点集分别引入匹配主干,同时通过交叉注意和自注意模块提取匹配描述符。基于匹配描述符的得分矩阵可用于计算分配图。我们将多维匹配得分设计为匹配描述符的相似性,公式为:
其中,<·>表示内积。λ1和λ2是控制深度得分图和综合得分图权重的超参数。为了从匹配分数中找到正确的匹配对,优化问题被视为与得分为S的两个离散分布a和b相关的最优传输问题。其熵正则化公式自然产生所需的软分配,因此引入Sinkhorn算法进行正确匹配。
在网络训练过程中,为了帮助模型学习正确的匹配分数,本发明设计了一个集成损失函数,它结合了三重损失和负对数似然(nll)损失。损失函数如下:
其中,
图4代表非迭代不匹配移除方法的流程图。由于像素误差和不匹配点,姿态精度通常不能满足估计要求。RANSAC等迭代方法没有针对GPU进行很好的优化,本发明提出了非迭代方法来加速估计过程并提高姿态精度。算法的细节如图4所示。
如图4的算法1所示,匹配对(Mi,Mj)是所提出的匹配模型的输出。并且通过最远点采样算法(FPS)对生成的匹配关键点(M
图5和表1使用本发明提出的方法在构建的空间目标数据集上进行了验证,图5显示了不同图像匹配模型的不同ROC曲线和AP分数。图5(a)、图5(b)和图5(c)分别给出了不同目标旋转速率下的匹配结果。如图5(a)所示,HardNet+Superglue模型获得最高的AUC分数,而提出的模型获得第二名的AUC分数,为0.85。实际上,大多数比较模型在目标旋转率为0-10°时都达到了可以接受的性能。至于目标旋转率从10°到20°,从20°到30°。图5(b)和图5(c)表明,所提出的方法在10°到30°范围内实现了最佳性能。当目标旋转速率在20°到30°范围内时,所提出方法的AUC得分达到0.70。表中的AUC和APE分数。实验验证了所提出的方法实现了竞争性能,特别是在大目标旋转率的情况下。所提出方法的mAPE和mMS分别获得0.011rad和0.767rad。与所提出的方法相比,HardNet-superglue和LoFTR方法获得了第二好的性能。当旋转速度小于10°时。HardNet-superglue和LoFTR方法展示了它们从RGB图像中提取局部特征的效率。当旋转速率较高时,所提出的方法在从RGB图像和深度图像中提取关键点方面具有明显的优势。
表1在测试数据集上使用不同检测模型的监督态度估计结果
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明公开的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。
- 基于深度学习的空间非合作目标姿轨一体化参数估计方法
- 一种空间非合作目标激光点云ICP位姿匹配正确性判别方法及系统
- 一种基于双目立体匹配的空间非合作目标位姿估计与三维重建方法及系统
- 基于模型和点云全局匹配的空间非合作目标位姿估计方法