基于交叉指导和特征级一致性双正则化的半监督医学图像分割方法及系统
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及图像处理技术领域,尤其指一种基于交叉指导和特征级一致性双正则化的半监督医学图像分割方法及系统。
背景技术
目前的一些图像分割工作用Transformer结合或者替换CNN来提高分割模型的性能,如TransFuse,Swin-Unet和GT U-Net,这些方法的成功通常依赖于许多标注的数据集。然而,准确标注的医学图像数据往往是稀缺的,因为注释的获取是复杂而昂贵的。在临床应用中,在少量的标记数据上进行医学图像分割成为一个具有挑战性的问题。考虑到标记数据的缺乏和未标记数据的大量存在,半监督学习成为一种实用的方法。半监督学习可以利用有限的标注数据和大量的未标注数据来加强分割模型的训练,大大降低标注成本。但是,现有的半监督学习方法几乎都存在边界准确率低、分割效果与地面真相相差较大的缺陷。
一致性正则化方法在半监督学习中是成功的,它鼓励从未标记数据的不同视图获得一致的输出。例如,一个时间集合模型考虑了以前训练轮次的网络预测,以获得对未标记的样本更稳定的预测。然而,使用基于CNN的同构模型的两个特征提取器不可避免地耦合,这导致了特征空间中丰富知识的浪费。因此,如何提供多个视图来学习未标记数据的知识是值得研究的。
协同训练是半监督学习中最普遍的技术之一,是一种多视图学习方法。理想情况下,这些视图可以相互补充,生成的模型可以通过协作提高彼此的性能。然而,对于数据有限的医学图像分割任务来说,同时训练不同的网络结构是一个具有挑战性的问题。因此,有必要为图像分割任务进一步研究协同训练方法。
发明内容
本发明的目的之一在于提供一种基于交叉指导和特征级一致性双正则化的半监督医学图像分割方法,以提高图像分割结果的准确性。
为了解决上述技术问题,本发明采用如下技术方案:基于交叉指导和特征级一致性双正则化的半监督医学图像分割方法,包括以下步骤:
(1)将标记数据和未标记数据同时输入到CNN模型和多解码器混合Transformer模型中,通过CNN模型得到标记数据以及未标记数据的分割预测图,通过多解码器混合Transformer模型中的共享编码器输出所有数据的特征图;
(2)在多解码器混合Transformer模型中,通过设置主解码器对所有数据的特征图进行处理,并通过设置多种辅助解码器来对未标记数据的特征图进行处理;
(3)通过主解码器输出得到所有数据的分割预测图;将未标记数据的特征图注入多种不同的扰动,并分别送到对应的辅助解码器中,得到相对应的分割预测图;
(4)对标记数据而言,将通过CNN模型得到的分割预测图和通过主解码器得到的分割预测图分别与真值标签进行监督损失的计算;对未标记数据而言,将通过主解码器得到的分割预测图和通过多种辅助解码器得到的分割预测图之间进行特征级一致性损失的计算;
(5)将CNN模型得到的所有数据的分割预测图拼接起来生成一个伪标签;将多解码器混合Transformer模型得到的所有数据的分割预测图拼接起来生成一个伪标签;用生成的两个伪标签对分割预测进行相互监督来计算交叉指导损失;
(6)通过标记数据的监督损失、标记数据和未标记数据的交叉指导损失、未标记数据的特征级一致性损失得到总损失函数,从而最终得到图像分割结果。
优选地,在步骤(3)中,将未标记数据的特征图注入6种不同的扰动,并分别送到对应的6种辅助解码器中,得到相对应的分割预测图。
更优选地,在步骤(4)中,对于第i个标记的输入图像,将来自CNN模型的预测表示为P
L
其中Y
更优选地,在步骤(4)中,对于第i个未标记的输入图像,将主解码器的预测值表示为
其中,K是辅助解码器的总数,L
更优选地,在步骤(5)中,第i个未标注的图像被送入CNN模型和主解码器,得到两个预测值
其中,cat用于将同一网络对有标签和无标签图像的预测结果拼接起来。
更优选地,在步骤(6)中,总损失函数定义为:
L=L
其中,λ
另外,本发明还提供一种基于交叉指导和特征级一致性双正则化的半监督医学图像分割系统,其包括:
多解码器混合Transformer模型,包括共享编码器、主解码器以及多个辅助解码器,所述共享编码器用于输出所有数据的特征图,所述主解码器用于对所有数据的特征图进行处理,所述辅助解码器来对未标记数据的特征图进行处理;
数据处理模块,用于对标记数据处理,将通过CNN模型得到的分割预测图和通过主解码器得到的分割预测图分别与真值标签进行监督损失的计算;并用于对未标记数据而言,将通过主解码器得到的分割预测图和通过多种辅助解码器得到的分割预测图之间进行特征级一致性损失的计算;
图像拼接处理模块,用于将CNN模型得到的所有数据的分割预测图拼接起来生成一个伪标签,并将多解码器混合Transformer模型得到的所有数据的分割预测图拼接起来生成一个伪标签,用生成的两个伪标签对分割预测进行相互监督来计算交叉指导损失;并用于通过标记数据的监督损失、标记数据和未标记数据的交叉指导损失、未标记数据的特征级一致性损失得到总损失函数,以最终得到图像分割结果。
通过交叉指导的正则化方法,协同CNN模型和多解码器混合Transformer模型,可提供多种视图来学习未标记数据的知识;而通过引入特征级的一致性正则化方法,在多解码器混合Transformer模型中附加辅助解码器,能够更有效地提取全局上下文和局部特征;另外,采用CNN模型和多解码器混合Transformer模型两个不同构架的模型来进行训练,能够提取未标记数据中的部分互补的知识;故通过该方法实现的图像分割效果更加准确。
附图说明
图1为本发明方法的模型结构示意图;
图2为实施例中脾脏数据集中的视觉分割示例;
图3为实施例中心脏数据集中的视觉分割示例;
图4为实施例中细胞核数据集中的视觉分割示例。
具体实施方式
为了便于本领域技术人员的理解,下面结合实施例与附图对本发明作进一步的说明,实施方式提及的内容并非对本发明的限定。
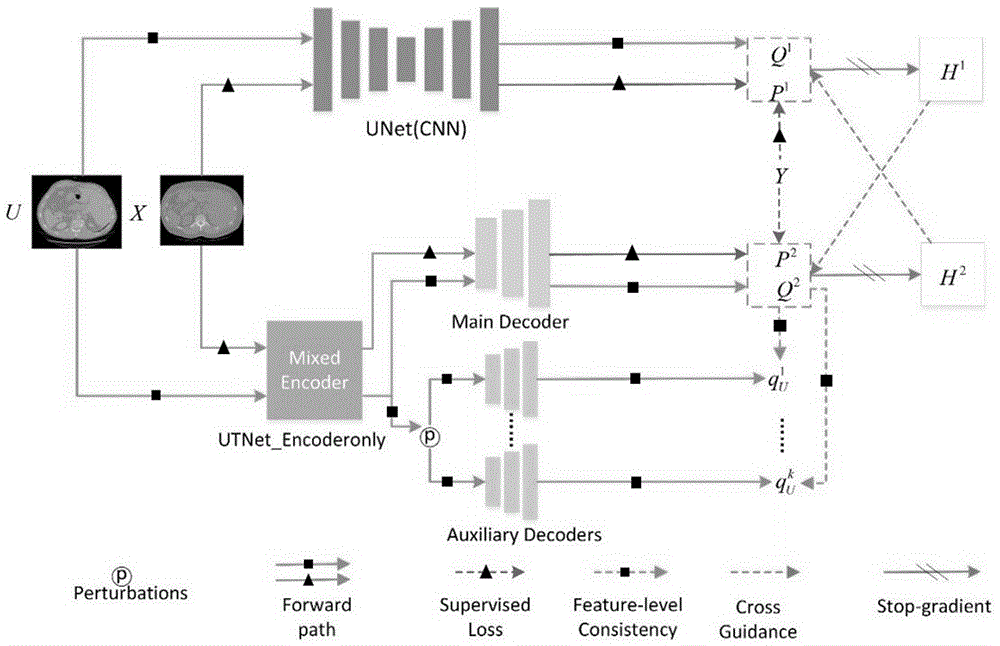
如图1的模型结构所示,由一个CNN模型和一个多解码器混合Transformer模型组成,CNN模型采用了编码器-解码器结构,多解码器混合Transformer模型则包括一个共享编码器、一个主解码器和几个辅助解码器。除了监督损失外,本方法使用交叉指导模块来处理有标签和无标签的数据,并通过特征级一致性模块充分利用无标签的数据。
具体来说,在图1中,交叉指导由两部分组成(虚线和双斜杠实线),一个是由CNN模块的预测P
(1)将标记数据和未标记数据同时输入到CNN模型和多解码器混合Transformer模型中,通过CNN模型得到标记数据以及未标记数据的分割预测图,通过多解码器混合Transformer模型中的共享编码器输出所有数据的特征图。
(2)在多解码器混合Transformer模型中,通过设置主解码器对所有数据的特征图进行处理,并通过设置6种辅助解码器来对未标记数据的特征图进行处理。
(3)通过主解码器输出得到所有数据的分割预测图;将未标记数据的特征图注入6种不同的扰动,并分别送到对应的辅助解码器中,得到相对应的分割预测图;
(4)对标记数据而言,将通过CNN模型得到的分割预测图和通过主解码器得到的分割预测图分别与真值标签进行监督损失的计算;对未标记数据而言,将通过主解码器得到的分割预测图和通过多种辅助解码器得到的分割预测图之间进行特征级一致性损失的计算;其中,对于第i个标记的输入图像,将来自CNN模型的预测表示为P
L
其中Y
通过附加6个辅助解码器,并向共享编码器的输出注入基于特征、预测和随机的扰动。不同的扰动特征图被送入不同的辅助解码器,而未被扰动的特征图被送入主解码器。在辅助解码器和主解码器之间对未标记集的预测保持一致性。共享编码器的表示学习能力通过使用从未标记集中提取的额外训练信号得到加强。
对于第i个未标记的输入图像,将主解码器的预测值表示为
其中,K是辅助解码器的总数,L
(5)将CNN模型得到的所有数据的分割预测图拼接起来生成一个伪标签;将多解码器混合Transformer模型得到的所有数据的分割预测图拼接起来生成一个伪标签;用生成的两个伪标签对分割预测进行相互监督来计算交叉指导损失;CNN模型依赖于局部卷积操作,而多解码器混合Transformer模型可以有效地捕捉全局依赖性和低层次的空间细节。其中,第i个未标注的图像被送入CNN模型和主解码器,得到两个预测值
其中,cat用于将同一网络对有标签和无标签图像的预测结果拼接起来。
(6)通过标记数据的监督损失、标记数据和未标记数据的交叉指导损失、未标记数据的特征级一致性损失得到总损失函数,从而最终得到图像分割结果;总损失函数定义为:
L=L
其中,λ
实验结果
首先评估了脾脏分割的性能。使用5%的训练集作为标记的样本,其余的训练集作为未标记的样本。总的来说,本发明的方法在与其他方法的比较中取得了优异的表现,证明了所提方法的有效性。通过图2(其中两行显示一个病例,并放大显示了虚线框中由于小病变而产生的详细比较)中的这些例子表明,本发明的方法的分割结果与地面真实标签更一致,边界更准确。这些结果验证了本发明的模型采用两种不同的学习方式,即CNN模型和多解码器混合Transformer模型,可以从同一数据中学习相对不同的知识,从而获得比其他方法更好的性能。
其次评估了心脏分割的性能。在图3中给出了心脏数据集的定性比较结果。从图3中可以看出,本发明的方法产生了更好的分割结果,它所呈现的视觉分割效果最接近于地面真相。比较实验确定了交叉指导的有效性,它可以充分地利用CNN模型和多解码器混合Transformer模型的特征学习能力。
为了进一步评估本发明方法的性能,还将其应用于广泛使用的细胞核数据集。通过实验结果可以看出,本发明的方法再次超过了常规的半监督的比较方法,证明了本发明所提出的方法的泛化能力。具体来说,如图4所示,其中显示了一些使用5%的标记数据的视觉分割结果,可以明显观察到,本发明的方法比其他方法保留了更好的边界,并产生了更准确的预测。特征级的一致性增强了多解码器结构的编码器的表示能力,可以更好地捕捉长距离的上下文和局部细节。
为了让本领域普通技术人员更方便地理解本发明相对于现有技术的改进之处,本发明的一些附图和描述已经被简化,并且上述实施例为本发明较佳的实现方案,除此之外,本发明还可以其它方式实现,在不脱离本技术方案构思的前提下任何显而易见的替换均在本发明的保护范围之内。
- 一种基于异构交叉伪监督网络的半监督医学图像分割方法
- 基于K最远交叉一致性正则化的半监督时序行为定位方法