一种基于多特征融合的邮件分类方法、装置及电子设备
文献发布时间:2024-04-18 19:58:30
技术领域
本说明书涉及网络安全技术领域,尤其涉及一种基于多特征融合的邮件分类方法、装置及电子设备。
背景技术
在移动互联网时代,电子邮件是一种非常重要的沟通交流方式。人们使用电子邮件参与诸如商务,聊天,交友,沟通等社会活动。事实上,包括支付确认,重置密码等操作都需要依赖邮箱来进行完成。所以个人或公司邮箱保有着大量的私密敏感数据,通过邮箱可以获取大量利益。这种社会现状致使钓鱼邮件和垃圾邮件有广袤的生存土壤和利益基础。
为了应对钓鱼邮件和垃圾邮件带来的威胁,基于机器学习来识别钓鱼邮件和垃圾邮件的技术被开发出来,包括朴素贝叶斯分类器和支持向量机等技术。
然而,目前用于识别钓鱼邮件和垃圾邮件的机器学习模型往往将待分类邮件中的邮件头、邮件正文等不同构成对象视为独立个体,单独利用某一种构成对象的特征来进行邮件分类,忽略了多个构成对象之间的相关性,导致机器学习模型无法对特征之间的复杂关系和相互作用进行建模,从而影响了机器学习模型的分类性能。
发明内容
为克服相关技术中存在的问题,本说明书提供了一种基于多特征融合的邮件分类方法、装置及电子设备。
根据本说明书实施例的第一方面,提供一种基于多特征融合的邮件分类方法,所述方法包括:
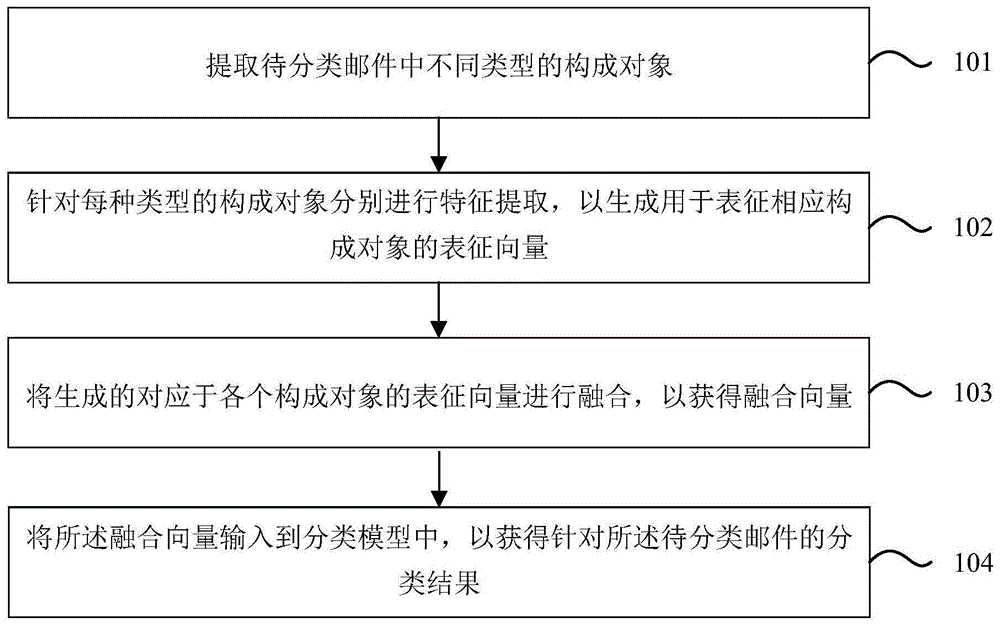
提取待分类邮件中不同类型的构成对象;
针对每种类型的构成对象分别进行特征提取,以生成用于表征相应构成对象的表征向量;
将生成的对应于各个构成对象的表征向量进行融合,以获得融合向量;
将所述融合向量输入到分类模型中,以获得针对所述待分类邮件的分类结果。
根据本说明书实施例的第二方面,提供一种基于多特征融合的邮件分类装置,包括:
提取对象模块,用于提取待分类邮件中不同类型的构成对象;
生成表征向量模块,用于针对每种类型的构成对象分别进行特征提取,以生成用于表征相应构成对象的表征向量;
融合表征向量模块,用于将生成的对应于各个构成对象的表征向量进行融合,以获得融合向量;
分类模块,用于将所述融合向量输入到分类模型中,以获得针对所述待分类邮件的分类结果。
根据本说明书实施例的第三方面,提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如第一方面所述方法的步骤。
根据本说明书实施例的第四方面,提供一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现如第一方面所述方法的步骤。
本说明书的实施例提供的技术方案可以包括以下有益效果:
本说明书实施例中,由于待分类邮件的不同类型的构成对象具有不同的特征表示能力,通过提取待分类邮件中不同类型的构成对象,可以获得能够更加全面反映待分类邮件特性的原始数据,针对每种类型的构成对象进行特征提取,以生成用于表征相应构成对象的表征向量,在将表征向量输入到分类模型前,先将生成的对应于各个构成对象的表征向量进行融合,然后将融合后的向量输入到分类模型中。由于融合后的向量综合了多个构成对象的特征,具有更佳的表达能力,有助于捕捉待分类邮件更丰富的语义和上下文信息。因此,将不同构成对象的表征向量进行融合后再输入到分类模型中,有助于分类模型更好地区分不同类别邮件之间的差别,从而提高模型的分类性能。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本说明书。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本说明书的实施例,并与说明书一起用于解释本说明书的原理。
图1是本说明书根据一示例性实施例示出的一种基于多特征融合的邮件分类方法的流程图。
图2是本说明书根据一示例性实施例示出的一种基于多特征融合的邮件分类方法的示意图。
图3是本说明书根据一示例性实施例示出的一种生成邮件头的第一表征向量的示意图。
图4是本说明书根据一示例性实施例示出的一种生成邮件正文的第二表征向量的示意图。
图5是本说明书根据一示例性实施例示出的一种生成URL的第三表征向量的示意图。
图6是本说明书根据一示例性实施例示出的一种融合第一表征向量、第二表征向量和第三表征向量的示意图。
图7是本说明书根据一示例性实施例示出的一种电子设备的结构示意图。
图8是本说明书根据一示例性实施例示出的一种基于多特征融合的邮件分类装置的框图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本说明书相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本说明书的一些方面相一致的装置和方法的例子。
在本说明书使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本说明书。在本说明书和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
应当理解,尽管在本说明书可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本说明书范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。
在移动互联网时代,电子邮件是一种非常重要的沟通交流方式。人们使用电子邮件参与诸如商务,聊天,交友,沟通等社会活动。事实上,包括支付确认,重置密码等操作都需要依赖邮箱来进行完成。所以个人或公司邮箱保有着大量的私密敏感数据,通过邮箱可以获取大量利益。这种社会现状致使钓鱼邮件和垃圾邮件有广袤的生存土壤和利益基础。
为了应对钓鱼邮件和垃圾邮件带来的威胁,基于机器学习来识别钓鱼邮件和垃圾邮件的技术被开发出来,包括朴素贝叶斯分类器和支持向量机等技术。
然而,目前用于识别钓鱼邮件和垃圾邮件的机器学习模型往往将待分类邮件中邮件头、邮件正文等不同构成对象视为独立个体,单独利用某一种构成对象的特征来进行邮件分类,忽略了多个构成对象之间的相关性,导致机器学习模型无法对特征之间的复杂关系和相互作用进行建模,从而影响了机器学习模型的分类性能。
针对上述技术问题,本申请提出一种基于多特征融合的邮件分类方法,以对待分类邮件中不同类型的特征之间的复杂关系和相互作用进行建模,有助于分类模型更好地区分不同类别邮件之间的差别,从而提高模型的分类性能。
接下来对本说明书实施例进行详细说明。
图1是本说明书根据一示例性实施例示出的一种基于多特征融合的邮件分类方法的流程图。
可以将图1示出的基于多特征融合的邮件分类方法应用到邮件服务端、邮件过滤网关、邮件客户端等不同装置上,以对邮件进行分类,并根据分类结果采取相应的安全措施。本说明书并不对此进行任何限制。
如图1所示,包括以下步骤:
步骤101、提取待分类邮件中不同类型的构成对象。
在本实施例中,待分类邮件是指用户的收件箱或者邮件服务器上新收到的邮件,这些邮件需要经过进一步分析,以确定是否为恶意邮件。例如,恶意邮件可以包括钓鱼邮件和垃圾邮件,针对该类型恶意邮件,可以采取相应的安全措施,例如,对恶意邮件进行过滤或者标记。
如图2所示,待分类邮件201的构成对象可以包括邮件头2011、邮件正文2012和邮件正文中出现的URL2013(Uniform Resource Locator,统一资源定位符)。可以使用支持邮件协议(如POP3、IMAP、SMTP)的编程语言库,如Python的email模块或者Java的JavaMail,获取到邮件的原始数据,然后通过解析得到邮件头2011和邮件正文2012,并从邮件正文中解析得到在该邮件正文中出现的URL2013。
步骤102、针对每种类型的构成对象分别进行特征提取,以生成用于表征相应构成对象的表征向量。
在一实施例中,由于邮件头内容稳定、邮件正文内容不受限制,两种文本特点不同,对于恶意邮件的判断特性不同。因此,如图2所示,在将邮件头2011的第一表征向量202和邮件正文2012的第二表征向量203进行融合前,对邮件头2011和邮件正文2012分开处理,将邮件头2011和邮件正文2012划分为待分类邮件201的两种构成对象,分别生成用于表征邮件头2011的第一表征向量202和用于表征邮件正文2012的第二表征向量203。
虽然,仅利用邮件头和邮件正文的特征信息也可以识别钓鱼邮件和垃圾邮件,但是,为了能够更好地识别出钓鱼邮件,如图2所示,本实施例将反映钓鱼邮件特性的邮件正文2012中的URL2013从邮件正文2012中提取出来,单独作为待分类邮件201的一个构成对象,并生成表征该URL的第三表征向量204。
在本实施例中,综合利用各个构成对象,并生成用于表征相应构成对象的表征向量,能够获得待分类邮件更加全面的特征信息。例如,有些恶意邮件会在邮件正文的文字部分隐藏有欺诈性的内容,在邮件正文中包含有恶意URL,并在邮件头中伪造发件人信息。因此,综合利用邮件头、邮件正文和URL的特征信息,能够更好地识别恶意邮件。
可以采用卷积神经网络、循环神经网络等深度学习模型根据构成对象的内容生成相应的表征向量。本说明书并不限制根据待分类邮件中不同构成对象的内容生成相应的表征向量的方式。
接下来,本说明书分别介绍获取图2中的第一表征向量202、第二表征向量203和第三表征向量204的具体实施方式:
在一实施例中,邮件头2011可以包括邮件发送者、接收者、时间戳、邮件主题等字段。如图3所示,在获取到邮件头2011的所有字段后,对于邮件头2011中缺失的字段,采用有序编码或者热编码等方式来处理缺失值,最终获得完整的字段301,例如,若邮件主题的字段为缺失值,则通过有序编码或者热编码等方式对该缺失值进行填充。当然,除了有序编码或者热编码等处理缺失值的方式,还存在其他处理缺失值的方式,本说明书并不限制对邮件头2011字段的缺失值进行处理的方式。在获得完整的字段301后,可以基于不同的特征提取规则从处理后的邮件头2011的不同字段中提取反映邮件类型的关键特征302。示例性地,可以通过判断邮件头2011中某个特定的字段是否为空确定该字段的特征值,若为空,则将对应字段的特征值设置为1,否则,设置为0,例如,该特定字段可以为邮件ID字段,若邮件ID为空,则将邮件ID的特征值设置为1。示例性地,可以通过统计某个特定字段使用的标签数量作为该字段的特征值,若该特定字段为收件人、发件人或者抄送人字段,则该标签数量为收件人数量、发件人数量或者抄送人数量。示例性地,可以通过从外部服务器查询到的Received字段中包含的被列入黑名单的IP地址数量作为Received字段的特征值。示例性地,可以直接提取某个字段的内容作为该字段的特征值,例如可以将Data字段的时区作为Data字段的特征值。示例性地,可以通过将某个字段是否满足某些条件的判断值作为该字段的特征值,例如,判断ContentType字段中的内容类型是否为“text/html”,若是,则将该字段的特征值设置为1,否则,将该字段的特征值设置为0。示例性地,可以通过对邮件头2011中两个或者多个字段之间的内容进行比较来确定字段的特征值,若符合比较条件,则将对应的特征值设置为1,否则,设置为0。
以上仅是示出从邮件头2011的字段中提取反映邮件类型的关键特征302的示例,当然,也可以采用其他方式提取反映邮件类型的关键特征302,本说明书并不对提取邮件头2011中反映邮件类型的关键特征302的方式进行任何限制。从邮件头的字段中提取到不同的特征值后,可以将特征值进行拼接,以生成用于表征邮件头内容的第一表征向量202。
在一实施例中,如图4所示,可以基于VAE模型403提取用于表征邮件正文2012的第二表征向量203。在将邮件正文2012输入到VAE模型403之前,可以对邮件正文2012进行文本预处理,删除邮件正文2012中的特殊字符、数字和停止词,以获得处理后的邮件正文401,然后,通过特征提取将处理后的邮件正文401中的每个单词转换为特征向量表示,以获得邮件正文的向量表示402,例如,可以采用训练好的词袋模型将处理后的邮件正文401转换为邮件正文的向量表示402。将邮件正文的向量表示402输入到VAE模型403中,通过编码器4031和解码器4023对邮件正文的向量表示402进行重新生成后,可以获得第二表征向量203。同时,利用漂移检测404,根据VAE模型403的识别结果4033,判断VAE模型403的预测性能,如果检测到VAE模型403中的数据分布存在漂移情况,则自适应更新VAE模型403的参数。关于漂移检测的相关技术和VAE模型的网络架构,可以参见相关技术,本说明书对此不再赘述。
在一实施例中,如图5所示,从邮件正文中提取出URL2013,在将URL2013输入到字符级卷积神经网络503和词级卷积神经网络504之前,可以对URL2013做进一步处理,以获得URL的字符级嵌入向量501和URL的词级嵌入向量502。例如,针对URL2013的字符级处理,可以将URL2013中出现频率较低(如在数百万个URL的语料库中出现不到100次)的字符替换为
然后,分别利用字符级卷积神经网络503对URL的字符级嵌入向量501进行处理,利用词级卷积神经网络504对URL的词级嵌入向量502进行处理,以获得字符级表征向量505和词级表征向量506。关于字符级卷积神经网络和词级神经网络的神经网络架构,可以参见相关技术,本说明书在此不再赘述。
最后,利用多尺度通道注意力模型507对字符级表征向量505和词级表征向量506进行融合,以获得第三表征向量204。关于多尺度通道注意力模型507(multi-scalechannel attention module,简称MS-CAM)的神经网络架构,可以参见相关技术,本说明书在此不再赘述。
在本实施例中,由于URL既具有结构化的特点,又包含丰富的语义信息,字符级表征向量可以捕捉到URL中每个字符的信息,可以更细粒度地表示URL的结构,而词级表征向量则更关注URL的语义,因此,综合利用字符级和词级的表征向量,并将它们进行融合,可以提供URL更全面和多角度的特征信息。
接下来介绍本说明书对第一表征向量、第二表征向量和第三表征向量进行融合的具体实施方式:
在一实施例中,如图6所示,可以通过第一多尺度通道注意力模型601对第二表征向量203和第三表征向量204进行融合,以获得多尺度表征向量602,具体融合方式可以采用如下述的公式1:
其中,X,Y分别表示第二特征向量203和第三特征向量204,M
通过第二多尺度通道注意力模型603,将多尺度表征向量602、第二表征向量203和第三表征向量204进行融合,以获得中间表征向量205。具体融合方式可以采用如下述的公式2:
其中,X,Y分别表示第二特征向量203和第三特征向量,M
需要说明的是,第一多尺度通道注意力模型601和第二多尺度通道注意力模型603的神经网络架构可以均为多尺度通道注意力模型(简称MS-CAM),当然,也可以仅采用一个多尺度通道注意力模型对第二表征向量203和第三表征向量204进行一次融合,获得中间表征向量205,本申请并不对此进行任何限制。在本实施例中采用相邻的两个多尺度通道注意力模型对第二表征向量203和第三表征向量204进行两次融合,能够深入捕捉特征之间的关联性。
最后,将中间表征向量205和第一表征向量202进行融合,可以获得融合向量206,融合方式可以采用联立展平的融合模式。
本实施例示出的对不同来源的表征向量进行融合的方式,能够很好的聚合全局和局部上下文信息,从而可以实现全方面对恶意邮件的检测。
步骤104、将所述融合向量输入到分类模型中,以获得针对所述待分类邮件的分类结果。
在本步骤中,分类模型可以为机器学习或者神经网络中常见的分类器,诸如神经网络分类器、支持向量机分类器等,本说明书并不对分类器的结构进行任何限制。
通过将融合向量输入到分类模型中,可以获得对待分类邮件的分类结果,包括垃圾邮件、钓鱼邮件和正常邮件等。
至此,完成了对一种基于多特征融合的邮件分类方法的相关说明。
与前述方法的实施例相对应,本说明书还提供了装置及其所应用的终端的实施例。
如图7所示,图7是本说明书根据一示例性实施例示出的一种电子设备的结构示意图。在硬件层面,该设备包括处理器702、内部总线704、网络接口706、内存708以及非易失性存储器710,当然还可能包括其他业务所需要的硬件。本说明书一个或多个实施例可以基于软件方式来实现,比如由处理器702从非易失性存储器710中读取对应的计算机程序到内存708中然后运行。当然,除了软件实现方式之外,本说明书一个或多个实施例并不排除其他实现方式,比如逻辑器件抑或软硬件结合的方式等等,也就是说以下处理流程的执行主体并不限定于各个逻辑模块,也可以是硬件或逻辑器件。
如图8所示,图8是本说明书根据一示例性实施例示出的基于多特征融合的邮件分类装置的框图。该装置可以应用于如图7所示的电子设备中,以实现本说明书的技术方案。所述装置包括:
提取对象模块802,用于提取待分类邮件中不同类型的构成对象;
生成表征向量模块804,用于针对每种类型的构成对象分别进行特征提取,以生成用于表征相应构成对象的表征向量;
融合表征向量模块806,用于将生成的对应于各个构成对象的表征向量进行融合,以获得融合向量;
分类模块808,用于将所述融合向量输入到分类模型中,以获得针对所述待分类邮件的分类结果。
可选地,所述待分类邮件的构成对象包括邮件头、邮件正文和邮件正文中的URL,所述邮件头对应于第一表征向量、所述邮件正文对应于第二表征向量、所述邮件正文中的URL对应于第三表征向量;所述融合表征向量模块806,具体用于将所述第二表征向量与所述第三表征向量进行融合,以获得中间表征向量;将所述中间表征向量与所述第一表征向量进行融合,以获得融合向量。
可选地,所述生成表征向量模块804,具体用于针对所述邮件头,从所述邮件头中提取反映邮件类型的关键特征;针对所述关键特征,确定用于表征邮件头内容的所述第一表征向量。
可选地,所述生成表征向量模块804,具体用于针对所述邮件正文,基于VAE模型提取用于表征所述邮件正文的所述第二表征向量;对所述VAE模型的输出结果进行漂移检测,若检测到所述输出结果出现漂移情况,则更新所述VAE模型的参数。
可选地,所述生成表征向量模块804,具体用于基于字符级卷积神经网络,确定用于表征所述URL的字符级表征向量;基于词级卷积神经网络,确定用于表征所述URL的词级表征向量;基于多尺度通道注意力模型,将所述字符级表征向量和所述词级表征向量融合为所述第三表征向量。
可选地,所述融合表征向量模块806,具体用于基于多尺度通道注意力模型,对所述第二表征向量与所述第三表征向量进行融合,以获得所述中间表征向量。
可选地,所述融合表征向量模块806,具体用于基于第一多尺度通道注意力模型,将所述第二表征向量和所述第三表征向量进行融合,以获得融合后的多尺度表征向量;基于第二多尺度通道注意力模型,将所述多尺度表征向量、所述第二表征向量和所述第三表征向量进行融合,以获得所述中间表征向量。
上述装置中各个模块的功能和作用的实现过程具体详见上述方法中对应步骤的实现过程,在此不再赘述。
对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的模块可以是或者也可以不是物理上分开的,作为模块显示的部件可以是或者也可以不是物理模块,即可以位于一个地方,或者也可以分布到多个网络模块上。可以根据实际的需要选择其中的部分或者全部模块来实现本说明书方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
本说明书还提供一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现本说明书提供的前述任一种基于多特征融合的邮件分类方法的步骤。
具体的,适合于存储计算机程序指令和数据的计算机可读介质包括所有形式的非易失性存储器、媒介和存储器设备,例如包括半导体存储器设备(例如EPROM、EEPROM和闪存设备)、磁盘(例如内部硬盘或可移动盘)、磁光盘以及CD ROM和DVD-ROM盘。
上述对本说明书特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
本领域技术人员在考虑说明书及实践这里申请的发明后,将容易想到本说明书的其它实施方案。本说明书旨在涵盖本说明书的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本说明书的一般性原理并包括本说明书未申请的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本说明书的真正范围和精神由下面的权利要求指出。
应当理解的是,本说明书并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本说明书的范围仅由所附的权利要求来限制。
以上所述仅为本说明书的较佳实施例而已,并不用以限制本说明书,凡在本说明书的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本说明书保护的范围之内。
- 一种基于时域多维特征融合的膝关节信号特征提取及分类方法与装置
- 一种基于时域多维特征融合的膝关节信号特征提取及分类方法与装置