车辆氛围灯的控制方法、装置、设备及存储介质
文献发布时间:2024-04-18 20:00:50
技术领域
本申请涉及灯光控制技术领域,尤其涉及一种车辆氛围灯的控制方法、装置、设备及存储介质。
背景技术
随着汽车行业的快速发展,驾乘体验成为消费者选择汽车的重要因素之一。在这个背景下,车辆氛围灯作为一种重要的车内装饰元素,已经成为现代汽车中不可或缺的一部分。车辆氛围灯的设计和功能不仅仅是为了提供照明,更重要的是为驾乘者创造一个舒适、愉悦的驾乘环境。相关技术中,根据驾驶员的不同情绪变化设置对应的车辆氛围灯控制参数,使得车辆氛围灯能够根据驾驶员的情绪变化进行联动。但是,设置的情绪种类有限,无法满足不同场景下车辆氛围灯的控制需求。
发明内容
本申请实施例通过提供一种车辆氛围灯的控制方法、装置、设备及存储介质,旨在满足不同场景下车辆氛围灯的控制需求,实现不同场景下的车辆氛围灯与驾驶员的情绪变化的联动,提高车辆氛围灯的控制效果。
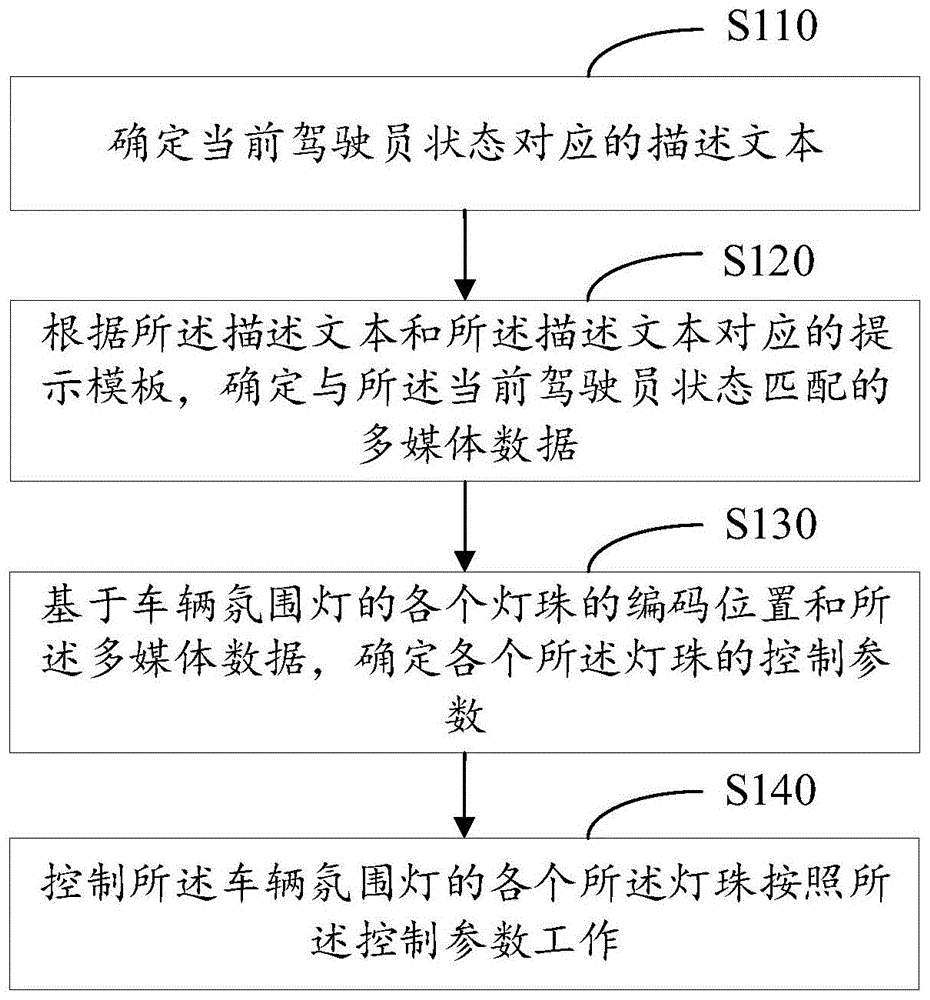
本申请实施例提供了一种车辆氛围灯的控制方法,所述车辆氛围灯的控制方法,包括:
确定当前驾驶员状态对应的描述文本;
根据所述描述文本和所述描述文本对应的提示模板,确定与所述当前驾驶员状态匹配的多媒体数据;
基于车辆氛围灯的各个灯珠的编码位置和所述多媒体数据,确定各个所述灯珠的控制参数;
控制所述车辆氛围灯的各个所述灯珠按照所述控制参数工作。
可选地,所述确定当前驾驶员状态对应的描述文本的步骤包括:
采集驾驶员的图像信息和/或音频信息;
将所述图像信息和/或所述音频信息输入双塔结构模型;
通过所述双塔结构模型的视觉语言分支对所述图像信息进行处理,得到能被大语言模型识别的视觉表示;和/或,通过所述双塔结构模型的音频语言分支对所述音频信息进行处理,得到能被大语言模型识别的音频表示;
基于所述大语言模型、所述视觉表示和/或所述音频表示,得到所述当前驾驶员状态对应的描述文本。
可选地,所述视觉语言分支包括视觉编码器、第一位置嵌入层、第一查询变换器和第一线性层,所述通过所述双塔结构模型的视觉语言分支对所述图像信息进行处理,得到能被大语言模型识别的视觉表示的步骤包括:
通过所述视觉编码器提取所述图像信息中每一图像帧的第一特征;
通过所述第一位置嵌入层,将每一图像帧的第一特征与对应的帧位置嵌入结合,得到每一图像帧的第二特征;
通过所述第一查询变换器聚合每一图像帧的第二特征,得到综合图像特征;
通过所述第一线性层,将所述综合图像特征映射到所述大语言模型的嵌入空间,得到所述能被大语言模型识别的视觉表示。
可选地,所述音频语言分支包括音频编码器、第二位置嵌入层、第二查询变换器和第二线性层,所述通过所述双塔结构模型的音频语言分支对所述音频信息进行处理,得到能被大语言模型识别的音频表示的步骤包括:
通过所述音频编码器提取所述音频信息中每一音频片段的第一特征;
通过所述第二位置嵌入层,将每一音频片段的第一特征与对应的位置嵌入结合,得到每一音频片段的第二特征;
通过所述第二查询变换器融合每一音频片段的第二特征,得到综合音频特征;
通过所述第二线性层,将所述综合音频特征映射到所述大语言模型的嵌入空间,得到所述能被大语言模型识别的音频表示。
可选地,所述基于所述大语言模型、所述视觉表示和/或所述音频表示,得到所述当前驾驶员状态对应的描述文本的步骤之前,还包括:
根据视觉表示样本与对应的描述文本样本之间的映射关系,训练得到所述大语言模型;和/或,根据音频表示样本与对应的描述文本样本之间的映射关系,训练得到所述大语言模型。
可选地,所述根据所述描述文本和所述描述文本对应的提示模板,确定与所述当前驾驶员状态匹配的多媒体数据的步骤包括:
根据所述描述文本和所述描述文本对应的提示模板,生成目标描述文本;
基于扩散模型对所述目标描述文本进行处理,得到与所述当前驾驶员状态匹配的多媒体数据。
可选地,所述根据所述描述文本和所述描述文本对应的提示模板,生成目标描述文本的步骤包括:
提取所述描述文本中的关键词;
确定所述关键词在所述提示模板中对应的填充位置;
采用所述关键词更新对应的填充位置,得到所述目标描述文本。
可选地,所述基于扩散模型对所述目标描述文本进行处理,得到与所述当前驾驶员状态匹配的多媒体数据的步骤包括:
获取车内参考图像,所述车内参考图像中包括车辆氛围灯的各个灯珠;
将所述目标描述文本和所述车内参考图像输入预先训练好的扩散模型,通过所述扩散模型基于所述车内参考图像生成与所述目标描述文本语义匹配的视频帧序列;
根据所述视频帧序列,得到与所述当前驾驶员状态匹配的多媒体数据。
可选地,所述多媒体数据包括视频,所述基于车辆氛围灯的各个灯珠的编码位置和所述多媒体数据,确定各个所述灯珠的控制参数的步骤包括:
获取所述视频的每个视频帧中,各个像素点的像素值;
针对每一视频帧,根据各个像素点的像素值和各个灯珠在该视频帧中预先标定的编码位置,确定该视频帧对应的各个灯珠的颜色值,其中,每个灯珠在不同视频帧中预先标定的编码位置相同或不同;
根据每个视频帧对应的各个灯珠的颜色值,以及颜色值与控制参数之间的映射关系,确定每个视频帧对应的各个所述灯珠的控制参数。
可选地,所述根据各个像素点的像素值和各个灯珠在该视频帧中预先标定的编码位置,确定该视频帧对应的各个灯珠的颜色值的步骤包括:
根据每个灯珠在该视频帧中预先标定的编码位置,确定该视频帧中分别与每个灯珠相邻的像素点;
获取每个所述灯珠相邻的像素点的像素值;
根据每个所述灯珠相邻的像素点的像素值,分别对每个灯珠进行插值运算,得到每个灯珠的颜色值。
可选地,所述根据所述描述文本和所述描述文本对应的提示模板,确定与所述当前驾驶员状态匹配的多媒体数据的步骤之后,还包括:
控制车机播放所述多媒体数据。
此外,为实现上述目的,本申请还提供一种车辆氛围灯的控制装置,所述车辆氛围灯的控制装置包括:
描述文本确定模块,用于确定当前驾驶员状态对应的描述文本;
多媒体数据确定模块,用于根据所述描述文本和所述描述文本对应的提示模板,确定与所述当前驾驶员状态匹配的多媒体数据;
灯珠控制参数确定模块,用于基于车辆氛围灯的各个灯珠的编码位置和所述多媒体数据,确定各个所述灯珠的控制参数;
灯珠控制模块,用于控制所述车辆氛围灯的各个所述灯珠按照所述控制参数工作。
此外,为实现上述目的,本申请还提供了一种车辆氛围灯的控制设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的车辆氛围灯的控制程序,所述车辆氛围灯的控制程序被所述处理器执行时实现上述的车辆氛围灯的控制方法的步骤。
此外,为实现上述目的,本申请还提供了一种计算机可读存储介质,其上存储有车辆氛围灯的控制程序,所述车辆氛围灯的控制程序被处理器执行时实现上述的车辆氛围灯的控制方法的步骤。
本申请实施例中提供的一种车辆氛围灯的控制方法、装置、设备及存储介质的技术方案,通过根据当前驾驶员状态对应的描述文本以及描述文本对应的提示模板,匹配出与当前驾驶员状态匹配的多媒体数据,能够识别出不同场景下的驾驶员状态对应的多媒体数据。为了使得车辆氛围灯能够与驾驶员的当前状态进行联动,基于车辆氛围灯的各个灯珠的编码位置和多媒体数据确定车辆氛围灯各个灯珠的控制参数,使得车辆氛围灯的各个灯珠能够随着多媒体数据的变化而变化,实现不同场景下的车辆氛围灯与驾驶员的情绪变化的联动,提高车辆氛围灯的控制效果。
附图说明
图1为本申请车辆氛围灯的控制方法第一实施例的流程示意图;
图2为本申请车辆氛围灯的控制方法第二实施例的流程示意图;
图3为本申请双塔结构模型和大语言模型的集成示意图;
图4为本申请车辆氛围灯的控制方法第三实施例的流程示意图;
图5为本申请车辆氛围灯的控制方法第四实施例的流程示意图;
图6为本申请实施例方案涉及的硬件运行环境的结构示意图;
图7为本申请车辆氛围灯的控制装置的功能模块图。
本申请目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明,上述附图只是一个实施例图,而不是申请的全部。
具体实施方式
随着汽车行业的快速发展,驾乘体验成为消费者选择汽车的重要因素之一。在这个背景下,车辆氛围灯作为一种重要的车内装饰元素,已经成为现代汽车中不可或缺的一部分。车辆氛围灯的设计和功能不仅仅是为了提供照明,更重要的是为驾乘者创造一个舒适、愉悦的驾乘环境。相关技术中,根据驾驶员的不同情绪变化设置对应的车辆氛围灯控制参数,使得车辆氛围灯能够根据驾驶员的情绪变化进行联动。但是,设置的情绪种类有限,无法满足不同场景下车辆氛围灯的控制需求。
针对上述技术问题,本申请提出了一种车辆氛围灯的控制方法,主要技术方案包括:确定当前驾驶员状态对应的描述文本;根据所述描述文本和所述描述文本对应的提示模板,确定与所述当前驾驶员状态匹配的多媒体数据;基于车辆氛围灯的各个灯珠的编码位置和所述多媒体数据,确定各个所述灯珠的控制参数;控制所述车辆氛围灯的各个所述灯珠按照所述控制参数工作。通过根据当前驾驶员状态对应的描述文本以及描述文本对应的提示模板,匹配出与当前驾驶员状态匹配的多媒体数据,能够识别出不同场景下的驾驶员状态对应的多媒体数据。为了使得车辆氛围灯能够与驾驶员的当前状态进行联动,基于车辆氛围灯的各个灯珠的编码位置和多媒体数据确定车辆氛围灯各个灯珠的控制参数,使得车辆氛围灯的各个灯珠能够随着多媒体数据的变化而变化,实现不同场景下的车辆氛围灯与驾驶员的情绪变化的联动,提高车辆氛围灯的控制效果。
为了更好地理解上述技术方案,下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整地传达给本领域的技术人员。
如图1所示,在本申请的第一实施例中,本申请的车辆氛围灯的控制方法应用于车辆氛围灯的控制设备,所述车辆氛围灯的控制设备可以是车载终端,该车载终端能够直接控制车辆氛围灯,或者通过车辆氛围灯的控制器控制车辆氛围灯。具体地,该车载终端与车辆氛围灯的控制器进行通信连接,通过该车载终端向车辆氛围灯控制器发送控制信号,使得车辆氛围灯控制器在接收到控制信号时,对车辆氛围灯进行控制。可选地,该车辆氛围灯的控制设备还可以是智能手机、智能电脑或者智能手表等,这些设备可以与车辆氛围灯的控制器进行无线连接,从而实现对车辆氛围灯的远程控制。具体地,所述车辆氛围灯的控制方法包括以下步骤:
步骤S110,确定当前驾驶员状态对应的描述文本。
在本实施例中,驾驶员状态是指驾驶者在驾驶过程中的身体和认知状况。它对驾驶安全和行车效果有重要影响。当前驾驶员状态可以包括以下不同种类:情绪状态,例如生气,沮丧,开心等情绪状态;注意力是否集中;疲劳驾驶状态;酒驾或药物影响导致的驾驶者的判断力、反应时间和协调能力降低的状态;分心驾驶例如使用手机、与乘客交谈、调整音乐或导航设备等;还可包括其他类型的驾驶员状态。本申请以当前驾驶员状态为情绪状态为例。
在本实施例中,可通过车内DMS(Driver Monitoring System)摄像头的监控,采集驾驶员的图像信息,通过图像信息分析确定当前驾驶员状态。或者,通过车辆驾驶员侧的麦克风采集驾驶员的音频信息,通过音频信息分析确定当前驾驶员状态。或者,通过车内DMS摄像头采集的驾驶员的图像信息和麦克风采集的驾驶员的音频信息进行综合分析,从而得到当前驾驶员状态。通过结合驾驶员的图像信息和音频信息进行综合分析,提高当前驾驶员状态识别的准确性。
可选地,在采集驾驶员的图像信息之后,可对该驾驶员的图像信息进行特征提取和特征分析,得到驾驶员的面部表情和眼部动态信息,利用计算机视觉和深度学习算法,对这些信息进行分析和处理,以识别驾驶员的情绪状态。常见的情绪识别算法包括基于面部表情的特征提取和分类,以及基于眼部动态的瞳孔大小、眨眼频率等指标的分析。通过这些技术,我们能够准确地识别驾驶员的情绪,包括愉快、焦虑、疲劳等。
可选地,在采集驾驶员的音频信息之后,通过分析音频信息的频率、音高、能量等参数来识别语音中所表现的情感状态。
在本实施例中,不同驾驶员状态对应的描述文本不同。该描述文本通过自然语言的形式表示驾驶员状态,使得机器能够识别当前驾驶员状态,便于后续确定当前驾驶员状态匹配的多媒体数据。例如当识别出驾驶员状态为愤怒生气时,对应的描述文本为“现在比较愤怒生气”;当识别出驾驶员状态为沮丧时,对应的描述文本为“现在比较沮丧”。
步骤S120,根据所述描述文本和所述描述文本对应的提示模板,确定与所述当前驾驶员状态匹配的多媒体数据。
在本实施例中,在确定描述文本之后,确定该描述文本对应的提示模板。该提示模板与描述文本的结合,得到的是一个“指令”,在识别到该指令时响应该指令,能够确定与该当前驾驶员状态匹配的多媒体数据。其中,不同描述文本对应的提示模板可以相同或者不同,且不同描述文本对应的提示模板可以存在一个甚至多个,可以将与描述文本匹配度最高的描述文本确定为提示模板,或者,在车机上显示与描述文本关联的各个提示模板,以供驾驶员选择确定。例如当描述文本为“现在比较愤怒生气”时,对应的提示模板可以是“生成一个视频,能够安抚我比较()状态”,此时生成“指令”即为“生成一个视频,能够安抚我比较愤怒生气的状态”。当描述文本为“现在比较沮丧”时,对应的提示模板可以是“生成一个视频,能够安抚我比较()状态”,此时生成“指令”即为“生成一个视频,能够安抚我比较沮丧的状态”。
在本实施例中,多媒体数据可以是视频、图片或者音乐。本申请以多媒体数据为视频为例。其中,不同“指令”对应的多媒体数据不同,从而能够根据不同驾驶员状态匹配不同的多媒体数据,实现多媒体数据与驾驶员的情绪变化的联动。
在其他实施例中,可以控制车机播放该多媒体数据。本申请利用扩散模型生成与驾驶员情绪相匹配的安抚、鼓励等类似视频,并在车机上进行播放。并且结合可控强的AI大模型,生成带有每个灯珠确定的动效视频,这种视频的生成是基于大规模的训练数据和深度学习技术,能够更好地与驾驶员的情绪产生共鸣,进一步提升驾乘体验,从而实现车机、氛围灯与驾驶员情绪的联动。
步骤S130,基于车辆氛围灯的各个灯珠的编码位置和所述多媒体数据,确定各个所述灯珠的控制参数。
步骤S140,控制所述车辆氛围灯的各个所述灯珠按照所述控制参数工作。
在本实施例中,在车辆氛围灯的各个灯珠的编码位置可预先通过多媒体数据进行预先标定。具体地,当该多媒体数据为视频时,该视频包括多个视频帧,可预先在每个视频帧中预先标定各个灯珠的编码位置。为了生成具有安抚、鼓励等特性的流动灯珠特效,通过根据每个视频帧中预先标定各个灯珠的编码位置在每个视频帧中自动取色,从而得到每个视频帧对应的各个灯珠的控制参数,进而在播放视频时,实现流动灯珠特效,实现与驾驶员情绪的联动。
在本实施例中,灯珠的控制参数可以是亮度、颜色和闪烁频率等,可根据不同的情绪状态,调节车内氛围灯的颜色、亮度和动态效果,LED灯光控制技术可以实现对车内氛围灯的精确控制。通过调节LED灯珠的亮度和颜色,创造出不同的光线效果,如柔和的暖光、明亮的冷光等,甚至氛围灯的动效,以适应不同情绪下驾驶员的需求。
本实施例根据上述技术方案,通过根据当前驾驶员状态对应的描述文本以及描述文本对应的提示模板,匹配出与当前驾驶员状态匹配的多媒体数据,能够识别出不同场景下的驾驶员状态对应的多媒体数据。为了使得车辆氛围灯能够与驾驶员的当前状态进行联动,基于车辆氛围灯的各个灯珠的编码位置和多媒体数据确定车辆氛围灯各个灯珠的控制参数,使得车辆氛围灯的各个灯珠能够随着多媒体数据的变化而变化,实现不同场景下的车辆氛围灯与驾驶员的情绪变化的联动,提高车辆氛围灯的控制效果。
进一步地,参照图2,基于第一实施例,在本申请的第二实施例中,步骤S110包括以下步骤:
步骤S111,采集驾驶员的图像信息和/或音频信息。
在本实施例中,可通过车内DMS(Driver Monitoring System)摄像头的监控,采集驾驶员的图像信息。通过车辆驾驶员侧的麦克风采集驾驶员的音频信息。其中,该图像信息能够用于识别驾驶员的面部信息、驾驶员的肢体动作。该音频信息能够用于识别驾驶员的说话内容。
可选地,该摄像头的位置和数量不限,例如该摄像头可设置在驾驶员前方。还可设置在车辆脚踏板附近,用于采集驾驶员的踏板制动情况,进而分析驾驶员的驾驶行为习惯。将该驾驶行为习惯与上述的驾驶员的目标信息、肢体动作、说话内容进行综合分析,得到驾驶员的驾驶状态。例如,通过车辆脚踏板附近的摄像头分析驾驶员的踏板制动情况,当在预设时段内的急刹次数大于预设次数时,确定驾驶员可能出现愤怒的情绪,此时,获取驾驶员前方的摄像头采集的图像信息以及麦克风采集的音频信息,通过该图像信息和音频信息确定驾驶员的当前驾驶状态。
在本实施例中,可定时获取驾驶员的图像信息和/或音频信息,或者,每个预设时间间隔获取驾驶员的图像信息和/或音频信息。且图像信息和音频信息可以同时采集,也可以只采集其中之一进行分析。
除此之外,还可以采集驾驶员的视频信息进行分析。
步骤S112,将所述图像信息和/或所述音频信息输入双塔结构模型。
步骤S113,通过所述双塔结构模型的视觉语言分支对所述图像信息进行处理,得到能被大语言模型识别的视觉表示;和/或,通过所述双塔结构模型的音频语言分支对所述音频信息进行处理,得到能被大语言模型识别的音频表示;
在本实施例中,要实现图像信息和音频信息能够被大语言模型识别,那么关键在于如何实现视觉特征的空间和文本特征的空间的对齐,以及如何实现音频特征的空间和文本特征的空间的对齐。本申请采用了双塔结构模型,本申请的双塔结构模型参照图3,该双塔结构模型包括两个分支,分别为视觉语言分支和音频语言分支。其中,视觉语言分支用于将图像信息处理为能被大语言模型识别的视觉表示,即将图像表征对齐到大语言模型的嵌入空间。音频语音分支用于将音频信息处理为能被大语言模型识别的音频表示,即将音频表征对齐到大语言模型的嵌入空间。
步骤S114,基于所述大语言模型、所述视觉表示和/或所述音频表示,得到所述当前驾驶员状态对应的描述文本。
在本实施例中,双塔结构模型能够提供高质量的视觉表示和音频标识。在得到视觉表示和音频表示之后,将视觉表示和音频表示输入图3中的大语言模型。本申请的大语言模型为LLMs(Large Language Models),大语言模型提供了强大的语言生成和零样本迁移能力,本申请的大语言模型能够识别视觉表示和/或音频表示,从而得到当前驾驶状态对应的描述文本。
本实施例根据上述技术方案,由于采用了双塔结构模型的视觉语言分支将图像信息处理为能被大语言模型识别的视觉表示,采用了双塔结构模型的音频语音分支将音频信息处理为能被大语言模型识别的音频表示,使得大语言模型能够基于视觉表示和音频标识得到驾驶员当前驾驶状态对应的描述文本,能够准确识别不同驾驶状态对应的描述文本。且本实施例根据上述技术方案,通过DMS摄像头对于驾驶员的状态、情绪进行分析,通过驾驶员侧的麦克风进行语音收集和文本转换;通过DMS摄像头和驾驶员侧的麦克风,能够全面了解驾驶员的状态、情绪和行为,为驾驶安全和驾驶体验提供更加精准和高效的支持,通过双塔结构的语音和图像编码器,将理解结果通过大语言模型,进行理解,输出理解后的描述文本。
可选地,所述视觉语言分支包括视觉编码器、第一位置嵌入层、第一查询变换器和第一线性层,通过所述双塔结构模型的视觉语言分支对所述图像信息进行处理,得到能被大语言模型识别的视觉表示包括以下步骤:
步骤S1131,通过所述视觉编码器提取所述图像信息中每一图像帧的第一特征。
在本实施例中,图像信息包括多个图像帧。通过视觉编码器提取每一图像帧的第一特征。视觉编码器是深度学习中的一种模型,用于提取图像中的特征表示。它通常由卷积神经网络(CNN)构成,可以将输入的图像转换为高维的第一特征。视觉编码器的主要任务是通过多个卷积层和池化层来逐步提取图像的局部特征和全局特征。这些卷积层可以捕捉到图像中的边缘、纹理和颜色等低级特征,而更深的卷积层可以提取更加抽象和语义化的高级特征。
步骤S1132,通过所述第一位置嵌入层,将每一图像帧的第一特征与对应的帧位置嵌入结合,得到每一图像帧的第二特征。
在本实施例中,第一位置嵌入层用于将时间信息注入图像帧的位置嵌入层,使得每一图像帧的第一特征与对应的帧位置嵌入结合,使得模型可以根据位置嵌入来学习到每个单词在描述文本中的位置信息,以及不同位置之间的关系,能够更好地理解上下文关系。
步骤S1133,通过所述第一查询变换器聚合每一图像帧的第二特征,得到综合图像特征。
在本实施例中,第一查询变换器(Querying Transformer,简称Q-Former)是一个轻量级变换器,它使用一组可学习的查询向量从冻结的视觉编码器中提取视觉特征,并充当视觉编码器和文本编码器之间的瓶颈。第一查询变换器把关键的视觉信息传递给大语言模型。
其中,第一查询变换器包括两个预训练阶段:第一个预训练阶段,强制第一查询变换器学习与文本最相关的视觉表示。第二个预训练阶段,通过将Q-Former的输出连接到冻结的大语言模型来执行视觉语言生成学习,使其输出的视觉表征可以直接由大语言模型解释。这样一来,第一查询变换器就可以有效地利用冻结的预训练图像模型和语言模型。
其中,第一查询变换器是由2个转换器子模块构成,其中,自注意力机制是共享的,可以理解为自注意力机制的输入有2个,即:“询问”和“文本”。其中,第1个转换器子模块是图像转换器,它与视觉编码器交互,用于视觉特征提取。它的输入是可学习的“询问”,它们先通过自注意力机制建模互相之间的依赖关系,再通过跨注意力机制建模“询问”和图片特征的依赖关系。因为两个转换器的子模块是共享参数的,所以“询问”也可以与文本输入做交互。第2个转换器子模块是文本转换器,它既可以作为文本编码器,也可以充当文本解码器。
在本实施例中,通过第一查询变换器将每一图像帧的第二特征进行聚合或融合,得到综合图像特征。
步骤S1134,通过所述第一线性层,将所述综合图像特征映射到所述大语言模型的嵌入空间,得到所述能被大语言模型识别的视觉表示。
在本实施例中,线性层的作用是对综合图像特征进行线性变换和投影,并通过权重矩阵和偏置项对综合图像特征进行线性组合,从而生成输出的特征向量。通过调整权重矩阵和偏置项的数值,线性层可以对综合图像特征进行不同程度的缩放、平移和旋转等线性变换操作,从而将综合图像特征映射到所述大语言模型的嵌入空间,得到能被大语言模型识别的视觉表示。
本实施例根据上述技术方案,通过视觉语言分支的视觉编码器、第一位置嵌入层、第一查询变换器和第一线性层依次对图像信息进行处理,最终将图像信息与大语言模型的嵌入空间对齐,将图像信息转换为能被大语言模型识别的视觉表示。
可选地,所述音频语言分支包括音频编码器、第二位置嵌入层、第二查询变换器和第二线性层,通过所述双塔结构模型的音频语言分支对所述音频信息进行处理,得到能被大语言模型识别的音频表示包括以下步骤:
步骤S1135,通过所述音频编码器提取所述音频信息中每一音频片段的第一特征。
在本实施例中,可将音频信息划分为多个音频片段,通过音频编码器提取每一音频片段的第一特征,其中,第一特征可以是声谱图、梅尔频谱系数、短时能量和短时过零率、频谱质心、频谱带宽、音调、色度、过渡边界强度等。其中,声谱图是将声音信号在时间和频率上进行可视化的二维表示。它展示了随时间变化的频谱信息,可以揭示声音的频率成分和时域特征。梅尔频谱系数是一种常用的音频特征,基于人听觉系统对音频频率的感知方式设计。它们捕捉了音频信号的梅尔频率刻度的能量分布,通常用于语音识别和音频分类任务。短时能量表示在短时间内声音信号的能量大小,短时过零率表示在短时间内声音信号穿过零点的次数。这些特征常用于声音的起止边界检测和语音活动检测。频谱质心表示声音信号频谱的重心位置,用于描述声音的明亮度或暗淡程度。频谱带宽表示声音信号频谱在频率上的展宽程度,用于描述声音的宽窄程度。音调是声音的基本频率,用于衡量声音的高低音调。色度描述声音的音色特征,包括其噪音成分、谐波结构和音色质地等。过渡边界强度用于描述声音信号中快速变化的部分,常用于音频分割和事件检测任务。
步骤S1136,通过所述第二位置嵌入层,将每一音频片段的第一特征与对应的位置嵌入结合,得到每一音频片段的第二特征。
在本实施例中,第二位置嵌入层用于将时间信息注入音频片段的位置嵌入层,使得每一音频片段的第一特征与对应的位置嵌入结合,使得模型可以根据位置嵌入来学习到每个音频在描述文本中的位置信息,以及不同位置之间的关系,能够更好地理解上下文关系。
步骤S1137,通过所述第二查询变换器融合每一音频片段的第二特征,得到综合音频特征。
在本实施例中,第二查询变换器与第一查询变换器类似,但是第二查询变换器用于从冻结的音频编码器中提取音频特征,并充当音频编码器和文本编码器之间的瓶颈。第二查询变换器把关键的音频信息传递给大语言模型。
其中,第二查询变换器包括两个预训练阶段:第一个预训练阶段,强制第二查询变换器学习与文本最相关的音频表示。第二个预训练阶段,通过将第二查询变换器的输出连接到冻结的大语言模型来执行音频语言生成学习,使其输出的音频表征可以直接由大语言模型解释。这样一来,第二查询变换器就可以有效地利用冻结的预训练音频模型和语言模型。
其中,第二查询变换器是由2个转换器子模块构成,其中,自注意力机制是共享的,可以理解为自注意力机制的输入有2个,即:“询问”和“文本”。其中,第1个转换器子模块是音频转换器,它与音频编码器交互,用于音频特征提取。它的输入是可学习的“询问”,它们先通过自注意力机制建模互相之间的依赖关系,再通过跨注意力机制建模“询问”和音频特征的依赖关系。因为两个转换器的子模块是共享参数的,所以“询问”也可以与文本输入做交互。第2个转换器子模块是文本转换器,它既可以作为文本编码器,也可以充当文本解码器。
在本实施例中,通过第二查询变换器将每一音频片段的第二特征进行聚合或融合,得到综合音频特征。
步骤S1138,通过所述第二线性层,将所述综合音频特征映射到所述大语言模型的嵌入空间,得到所述能被大语言模型识别的音频表示。
在本实施例中,线性层的作用是对综合音频特征进行线性变换和投影,并通过权重矩阵和偏置项对综合音频特征进行线性组合,从而生成输出的特征向量。通过调整权重矩阵和偏置项的数值,线性层可以对综合音频特征进行不同程度的缩放、平移和旋转等线性变换操作,从而将综合音频特征映射到所述大语言模型的嵌入空间,得到能被大语言模型识别的音频表示。
本实施例根据上述技术方案,通过音频语言分支包括音频编码器、第二位置嵌入层、第二查询变换器和第二线性层依次对音频信息进行处理,最终将音频信息与大语言模型的嵌入空间对齐,将音频信息转换为能被大语言模型识别的音频表示。
可选地,在基于大语言模型、视觉表示和/或音频表示,得到驾驶员当前驾驶状态对应的描述文本之前,需要训练得到大语言模型。可根据视觉表示样本与对应的描述文本样本之间的映射关系,训练得到所述大语言模型;和/或,根据音频表示样本与对应的描述文本样本之间的映射关系,训练得到所述大语言模型。在得到大语言模型之后,当向该大语言模型输入对应的视觉表示时,能根据视觉表示样本与对应的描述文本样本之间的映射关系输出对应的描述文本。当向该大语言模型输入对应的音频表示时,能根据音频表示样本与对应的描述文本样本之间的映射关系输出对应的描述文本,从而使得大语言模型能够识别不同视觉表示和不同音频表示对应的描述文本,提高大语言模型的识别精度。
进一步地,参照图4,基于第一实施例或第二实施例,在本申请的第三实施例中,步骤S120包括以下步骤:
步骤S121,根据所述描述文本和所述描述文本对应的提示模板,生成目标描述文本。
在本实施例中,在确定描述文本之后,确定该描述文本对应的提示模板。该提示模板与描述文本的结合,得到目标描述文本,该目标描述文本相当于一个“指令”,且该目标描述文本能够被扩散模型识别,进而使得扩散模型能够根据该目标描述文本确定与该当前驾驶员状态匹配的多媒体数据。
步骤S122,基于扩散模型对所述目标描述文本进行处理,得到与所述当前驾驶员状态匹配的多媒体数据。
在本实施例中,多媒体数据可以是视频、图片或者音乐。本申请以多媒体数据为视频为例。其中,不同目标描述文本对应的多媒体数据不同,从而能够根据不同驾驶员状态匹配不同的多媒体数据,实现多媒体数据与驾驶员的情绪变化的联动。
在本实施例中,扩散模型用于生成高质量的视频。其采用稳定噪声替换高斯噪声,并使用类似于U-Net的结构来生成视频。而且,扩散模型还可以通过目标描述文本的输入来控制生成的视频内容。具体来说,扩散模型在生成视频时需要以下步骤:
(1)文本编码:将输入的目标描述文本编码为一个向量表示。
(2)初始帧生成:从随机噪声中采样得到初始图像或视频帧,并使用文本编码作为条件输入。
(3)迭代更新:通过迭代更新像素值来逐步生成图像。迭代更新包括以下两个步骤:a.扩散步骤:在每个扩散步骤中,使用对流方程对像素值进行更新。这个方程会引入噪声,使像素值逐渐变得模糊和不确定。b.可逆步骤:在每个可逆步骤中,利用逆对流方程来还原像素值。这个逆操作将逐渐去除噪声,使像素值恢复清晰度和稳定性。
(4)输出视频:重复执行扩散步骤和可逆步骤,直到生成完整的视频序列。生成的视频可以以视频文件的形式保存。
其中,迭代更新是关键步骤,在每次迭代过程中,扩散模型会从稳定噪声中采样得到噪声序列,并将其应用于像素值的逐步更新。同时,它还会使用U-Net结构从相邻帧中提取特征,并利用文本编码来指导生成过程。通过这种方式,扩散模型能够根据输入的目标描述文本控制生成的视频内容,并生成高质量、多样化的视频序列。
可选地,步骤S121包括以下步骤:
步骤S1211,提取所述描述文本中的关键词。
在本实施例中,可预先建立描述文本样本与描述文本样本中的关键词之间的映射关系,并基于该映射关系训练得到描述文本的关键词的提取模型。在后续使用时,基于该提取模型提取描述文本中的关键词。例如,当描述文本为“现在比较愤怒生气”时,对应的关键词可以是“愤怒生气”。当描述文本为“现在比较沮丧”时,对应的关键词可以是“沮丧”。其中,关键词的数量可以为一个甚至多个,可根据描述文本的内容或长度进行确定,不同描述文本的关键词的数量不同。
步骤S1212,确定所述关键词在所述提示模板中对应的填充位置。
步骤S1213,采用所述关键词更新对应的填充位置,得到所述目标描述文本。
在本实施例中,每个关键词在提示模板中均存在对应的填充位置。采用该关键词更新对应的填充位置,即将关键词填充至提示模板中对应的填充位置,能够得到目标描述文本。例如当描述文本为“现在比较愤怒生气”时,对应的提示模板可以是“生成一个视频,能够安抚我比较()状态”,括号处即为填充位置。关键词为“愤怒生气”,那么生成的目标描述文本为“生成一个视频,能够安抚我比较愤怒生气的状态”。
可选地,在生成目标描述文本之后,可将该目标描述文本输入扩散模型,该目标描述文本相当于一个“指令”,能够使得扩散模型生成一个与当前驾驶员状态匹配的多媒体数据。但是,由于需要根据媒体数据控制氛围灯,生成的多媒体数据必须为高度可控的内容,如果不是高度可控的内容,对于氛围灯的控制难度增加,且无法指定到固定的LED灯珠的颜色和动效;所以,需要额外增加(适应参数)对于扩散模型进行风格、内容控制,即通过大量的额外参数(训练好的)对扩散模型进行引导控制,生成特定的舱内带有灯珠位置编码的多媒体数据。而生成特定的舱内带有灯珠位置编码的多媒体数据的过程如下,即步骤S122包括以下步骤:
步骤S1221,获取车内参考图像,所述车内参考图像中包括车辆氛围灯的各个灯珠。
步骤S1222,将所述目标描述文本和所述车内参考图像输入预先训练好的扩散模型,通过所述扩散模型基于所述车内参考图像生成与所述目标描述文本语义匹配的视频帧序列。
步骤S1223,根据所述视频帧序列,得到与所述当前驾驶员状态匹配的多媒体数据。
在本实施例中,车内参考图像中包括车内的车辆氛围灯的各个灯珠的排布情况和位置。扩散模型以该车内参考图像作为引导,进行多次图像去噪处理,生成与目标描述文本相匹配的视频帧序列。进而将各个视频帧序列按照时间顺序进行组合,得到与所述当前驾驶员状态匹配的多媒体数据。
本实施例根据上述技术方案,将车内参考图像作为引导,采用扩散模型基于所述车内参考图像生成与所述目标描述文本语义匹配的视频帧序列,从而生成特定的舱内带有灯珠位置编码的多媒体数据。
进一步地,参照图5,基于以上任意实施例,在本申请的第四实施例中,所述多媒体数据包括视频时,步骤S130包括以下步骤:
步骤S131,获取所述视频的每个视频帧中,各个像素点的像素值。
在本实施例中,每个视频帧中各个像素点的像素值可直接获取。具体地,每个视频帧存在对应的像素值矩阵,该像素值矩阵包括该视频帧下各个像素点的像素值。其中,像素值指的是视频帧中每个像素对应的数值,它代表了该像素在视频帧中的亮度或颜色信息。在彩色视频帧中,每个像素通常由3个颜色通道(红、绿、蓝)的值组成,也称为RGB格式。每个颜色通道的像素值都可以用0~255的整数表示,例如(255,0,0)表示红色,(0,255,0)表示绿色,(0,0,255)表示蓝色。通过这三个通道的组合,可以表示出数百万种不同的颜色。
步骤S132,针对每一视频帧,根据各个像素点的像素值和各个灯珠在该视频帧中预先标定的编码位置,确定该视频帧对应的各个灯珠的颜色值,其中,每个灯珠在不同视频帧中预先标定的编码位置相同或不同。
在本实施例中,根据每个灯珠在该视频帧中预先标定的编码位置,确定该视频帧中分别与每个灯珠相邻的像素点;获取每个所述灯珠相邻的像素点的像素值;根据每个所述灯珠相邻的像素点的像素值,分别对每个灯珠进行插值运算,得到每个灯珠的颜色值。其中,每个所述灯珠相邻的像素点的像素值可以是每个灯珠四周相邻的像素点的像素值。对于每个视频帧,每几个像素位置都通过标定计算代表了不同的LED灯珠的编码位置,例如将当前视频帧中序号为1-5的像素点确定为灯珠的编码位置,通过位置的双线性插值计算,结合最邻近的上下左右四个像素的像素值,进行插值计算,获得这个灯珠的颜色值。
步骤S133,根据每个视频帧对应的各个灯珠的颜色值,以及颜色值与控制参数之间的映射关系,确定每个视频帧对应的各个所述灯珠的控制参数。
在本实施例中,根据每个视频帧对应的各个灯珠的颜色值构成一个所有灯珠的不同时间下的颜色分布矩阵,然后根据控制代码结合颜色分布矩阵,形成每个视频帧对应的各个所述灯珠的控制参数。
本实施例根据上述技术方案,通过根据每个视频帧中预先标定各个灯珠的编码位置在每个视频帧中自动取色,从而得到每个视频帧对应的各个灯珠的控制参数,进而在播放视频时,实现流动灯珠特效,实现与驾驶员情绪的联动。
在其他实施例中,当多媒体数据包括音频时,可基于车辆氛围灯的各个灯珠的编码位置和所述音频数据,确定各个灯珠的控制参数,进而控制车辆氛围灯的各个所述灯珠按照所述控制参数工作。可使用音频分析算法,通过将音频传送给计算机或控制器进行实时分析。这些算法可以提取音频中的频率、强度和节奏等信息。根据分析结果,可以调整氛围灯的亮度、颜色、闪烁速度或呼吸效果等参数来与音乐同步。实现车辆氛围灯能够随着驾驶员的情绪变化以及音乐的变化而变化。
本申请实施例提供了车辆氛围灯的控制方法的实施例,需要说明的是,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
如图6所示,图6为本申请实施例方案涉及的车辆氛围灯的控制设备的硬件运行环境的结构示意图。该车辆氛围灯的控制设备可以包括:处理器1001,例如CPU,存储器1005,用户接口1003,网络接口1004,通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏、输入单元比如键盘,可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如WI-FI接口)。存储器1005可以是高速RAM存储器,也可以是稳定的存储器,例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
本领域技术人员可以理解,图6中示出的车辆氛围灯的控制设备结构并不构成对车辆氛围灯的控制设备限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图6所示,作为一种存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及车辆氛围灯的控制程序。其中,操作系统是管理和控制车辆氛围灯的控制设备硬件和软件资源的程序,车辆氛围灯的控制程序以及其它软件或程序的运行。
在图6所示的车辆氛围灯的控制设备中,用户接口1003主要用于连接终端,与终端进行数据通信;网络接口1004主要用于后台服务器,与后台服务器进行数据通信;处理器1001可以用于调用存储器1005中存储的车辆氛围灯的控制程序。
在本实施例中,车辆氛围灯的控制设备包括:存储器1005、处理器1001及存储在所述存储器上并可在所述处理器上运行的车辆氛围灯的控制程序,其中:
处理器1001调用存储器1005中存储的车辆氛围灯的控制程序时,执行以下操作:
确定当前驾驶员状态对应的描述文本;
根据所述描述文本和所述描述文本对应的提示模板,确定与所述当前驾驶员状态匹配的多媒体数据;
基于车辆氛围灯的各个灯珠的编码位置和所述多媒体数据,确定各个所述灯珠的控制参数;
控制所述车辆氛围灯的各个所述灯珠按照所述控制参数工作。
基于同一发明构思,本申请实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有车辆氛围灯的控制程序,所述车辆氛围灯的控制程序被处理器执行时实现如上所述的车辆氛围灯的控制方法的各个步骤,且能达到相同的技术效果,为避免重复,这里不再赘述。
由于本申请实施例提供的存储介质,为实施本申请实施例的方法所采用的存储介质,故而基于本申请实施例所介绍的方法,本领域所属人员能够了解该存储介质的具体结构及变形,故而在此不再赘述。凡是本申请实施例的方法所采用的存储介质都属于本申请所欲保护的范围。
如图7所示,本申请提供的一种车辆氛围灯的控制装置,所述车辆氛围灯的控制装置包括:
描述文本确定模块10,用于确定当前驾驶员状态对应的描述文本;
多媒体数据确定模块20,用于根据所述描述文本和所述描述文本对应的提示模板,确定与所述当前驾驶员状态匹配的多媒体数据;
灯珠控制参数确定模块30,用于基于车辆氛围灯的各个灯珠的编码位置和所述多媒体数据,确定各个所述灯珠的控制参数;
灯珠控制模块40,用于控制所述车辆氛围灯的各个所述灯珠按照所述控制参数工作。
本申请车辆氛围灯的控制装置具体实施方式与上述车辆氛围灯的控制方法各实施例基本相同,在此不再赘述。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本申请实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,电视,或者网络设备等)执行本申请各个实施例所述的方法。
以上仅为本申请的优选实施例,并非因此限制本申请的专利范围,凡是利用本申请说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本申请的专利保护范围内。
- 一种基于自动化操作台的立体库系统及其物品分拣方法
- 一种基于多向穿梭车的立体库系统及穿梭车的出入库方法
- 一种基于多向穿梭车的立体库系统及穿梭车的出入库方法