用于数据掩码的硬件加速的系统和方法
文献发布时间:2024-07-23 01:35:21
背景技术
现场可编程门阵列(FPGA)是包括逻辑块阵列以及那些逻辑块之间的可重新配置互连的硬件设备。在
与由通用处理器执行的软件实现相比,FPGA带来在低级别(例如,在电路级别)实现计算的更高性能和更低功耗的益处。这类似于使用诸如专用协处理器的专用集成电路(ASIC)的益处,专用协处理器为诸如图形处理单元(GPU)或神经加速器,其分别用以加速特定于计算机图形和人工神经网络的操作。然而,ASIC的设计和制造是具有高的前期固定成本的漫长而昂贵的过程。
因此,FPGA的一些应用包括,例如,最终可能在ASIC中实现的硬件设计的原型,以及在设计和制造ASIC可能(例如,由于计算的低数量或高度专业化)不合理的情况下的计算的硬件加速。此外,FPGA还提供了底层硬件(在“现场”)的重新配置的灵活性,而无需锁定到固定硬件配置中,就像在ASIC的情况下,其中逻辑直接在制造时间在电路的布局中实现,并且因此具有很少甚至没有的可重新配置性。一些云计算提供商提供对包括连接的FPGA的硬件实例(例如,服务器)的访问,从而允许用户定制FPGA以执行计算操作的硬件加速。
关于这些和其他考虑因素已经给出了示例。另外,虽然已经讨论了相对具体的问题,但是应当理解,示例不应限于解决背景技术中识别的具体问题。
发明内容
提供本发明内容从而以简化形式介绍一系列概念,这些概念将在下面的详细描述部分中进一步描述。本发明内容不旨在识别所要求保护的主题的关键特征或基本特征,其也不旨在帮助确定所要求保护的主题的范围。
本技术的各方面涉及数据掩码的硬件加速,其是机器学习的领域中通常执行的操作。作为一个示例,经常应用于自然语言处理的机器学习模型中的自回归变换器(transformer)模型将掩码应用于输入数据,以便确保变换器模型学习仅基于序列中较早出现的标记并且不基于序列中较晚出现的标记对标记的序列中的给定标记做出预测。对数据应用掩码以通过隐藏(例如清零)在训练过程期间不应考虑的值来强制执行此自回归约束。
因此,根据本技术的各个方面的数据掩码的硬件加速改进了包括数据掩码操作的机器学习模型训练过程的性能。性能的改进涉及计算时间(例如,处理器时间)的减少、数据存储和带宽(例如,存储器使用和通过通信总线传送的数据)的减少、能源消耗的减少,并且在一些示例中,减少了在现场可编程门阵列(FPGA)上的某些实现中使用的物理硬件量。
一个或多个方面的细节在附图和下面的描述中阐述。通过阅读以下详细描述和审查相关联的附图,其他特征和优点将是显而易见的。应理解,以下详细描述仅是解释性的并且不是对所要求保护的本发明的限制。
附图说明
并入本公开并构成本公开的一部分的附图示出了本发明的各个方面。在附图中:
图1描绘了根据一个示例的由通过现场可编程门阵列(FPGA)实现的数据掩码电路对输入数据掩码以生成所掩码的数据的高级示图。
图2描绘了被配置为对数据掩码的示例比较系统。
图3A是根据一个示例的包括被配置为接收掩码数据的数据掩码电路的加速器的框图。
图3B是根据一个示例的用于使用数据掩码电路和接收到的掩码数据对数据掩码的方法的流程图。
图4A是根据一个示例的包括被配置为生成掩码数据的数据掩码电路的加速器的框图。
图4B是根据一个示例的用于使用数据掩码电路和生成的掩码数据对数据掩码的方法的流程图。
图4C是根据一个示例的包括被配置为生成掩码数据的数据掩码电路的加速器的框图。
图5A是根据一个示例的包括混合数据掩码电路的加速器的框图,该混合数据掩码电路被配置为选择性地基于生成的掩码数据或基于接收到的掩码数据对数据掩码。
图5B是根据一个示例的用于使用混合数据掩码电路对数据掩码的方法的流程图,该混合数据掩码电路被配置为选择性地基于生成的掩码数据或基于接收到的掩码数据对数据掩码。
图6A是根据一个示例的被配置为生成三角掩码的掩码生成电路的框图。
图6B是示出根据一个示例的被配置为生成三角掩码的掩码生成电路的输入和输出的时序图。
图6C是根据一个示例的用于基于索引来生成三角掩码的方法的流程图。
图7是描绘根据本公开的一个示例的用于使用加速数据掩码电路来训练诸如变换器模型的机器学习模型的方法的流程图。
图8是示出可以用来实践本发明的各方面的计算设备的示例物理组件的框图。
图9A和图9B是可以用来实践本发明的各方面的移动计算设备的简化框图。
具体实施方式
以下详细描述参考附图。只要可能,在附图和以下描述中使用相同的附图标记来指代相同或相似的元件。虽然可以描述本发明的各方面,但是修改、适应和其他实现是可能的。例如,可以对附图中示出的元件做出替换、添加或修改,并且可以通过对所公开的方法替换、重新排序或添加阶段来修改本文描述的方法。因此,下面的详细描述并不限制本发明,而是本发明的适当范围由所附权利要求限定。示例可以采用硬件实现、或完全软件实现、或组合软件和硬件方面的实现的形式。因此,下面的详细描述不应被理解为具有限制意义。
本技术涉及用于使用诸如现场可编程门阵列(FPGA)的硬件来加速数据的掩码的系统和方法。FPGA的一种用例是与机器学习任务相关联的计算的加速,机器学习任务为诸如计算机视觉(例如,图像分类、实例分割等)、自然语言处理(例如,变换器模型)等。训练诸如深度神经网络(DNN)的机器学习模型针对小型模型可能需要数小时的计算时间,而针对大型模型可能需要数周或数月的计算时间。将计算上昂贵的操作从运行在相对较慢的通用处理器(例如,CPU)上的程序或运行在图形处理单元(GPU)上的着色器转移到专门配置为执行那些昂贵的数学运算的FPGA上可以提供在总计算时间上显著的减少以及功率消耗的减少。
在训练一些类型的机器学习模型时,掩码用于在训练过程期间隐藏或移除一些值。图1描绘了根据一个示例的由通过现场可编程门阵列(FPGA)20实现的数据掩码电路100对输入数据10掩码以生成所掩码的数据30的高级示图。具体地,数据掩码电路100可以将掩码40应用于输入数据,以隐藏或移除输入数据10中的值,或者用其他值(诸如常数值或来自另一数据源的值)替换输入数据10中的值。在机器学习模型中,使用掩码以便改进所得到的训练后的模型的性能,诸如通过确保这些模型不会学习基于未来数据做出预测。
例如,变换器模型已经广泛采用于诸如机器翻译、问答等的自然语言处理(NLP)应用中。大部分变换器模型是自回归的,意味着在位置[i]处的标记无法基于在位置[i+1]或以后位置处的标记的信息来计算。变换器模型中的所有层都沿着隐藏维度运行(并且可以忽略此约束),除了沿着序列维度运行的自注意力头之外。为了强制执行自回归约束,使用掩码来掩蔽在大于或等于[i+1]的位置处的标记。图1描绘了作为输入数据10提供的注意力分数矩阵的示例,其中行以从上到下(例如,索引i从0到7)和从左到右(例如,索引j从0到7)递增的索引来标记。掩码40在图1中被示出为上三角掩码,以掩蔽注意力分数矩阵的右上三角以产生所掩码的数据30,其对应于位置j大于或等于[i+1]的位置。
针对最大序列长度为L的变换器模型,注意力掩码的尺寸为L×L,对应于存储开销的L
x_masked(i,j)=x(i,j)-10000.0·[1.0-mask(i,j)],
其中mask(i,j)∈{0.0,1.0}(1)
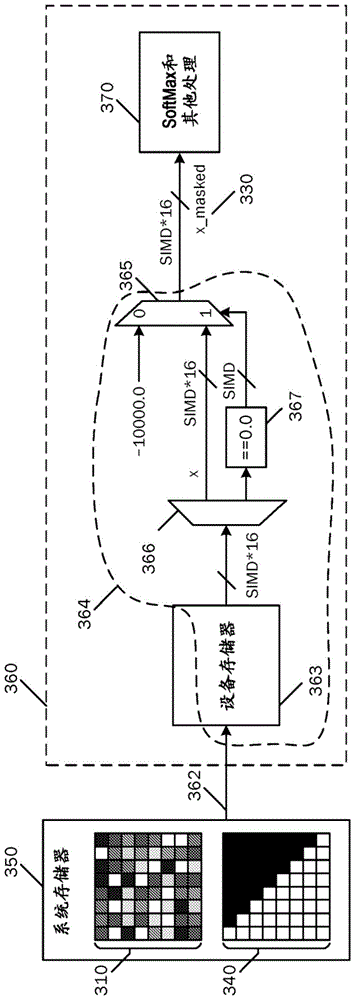
更详细地,在图2中所示的系统中,解多路复用器(DEMUX)265用于沿着不同的数据路径路由训练示例输入数据210和注意力掩码240,其中第一浮点减法电路266、浮点乘法器267和第二浮点减法电路268用于实现方程(1)。虽然注意力掩码存储和逻辑264在图2中被示出为离散功能块的集合,但是还可以使用例如控制向量处理器或图形处理单元的操作的软件代码(例如,程序或着色器)来实现这种比较加速器260。结果,训练示例输入数据210的原始值被保留在位置(i,j)处,其中在(i,j)处的掩码数据为1.0f,并且原始数据被替换为在位置(i,j)处的值x-10,000,其中在(i,j)处的掩码数据为0.0f。
在图2中所示的比较系统中,掩码的训练示例输入数据(x_masked)230被提供给实现SoftMax函数和其他处理270的电路。SoftMax函数σ通常根据下式对值的输入向量z的第i个值z
如以上所看到的,SoftMax函数的分子是
在图2中所示的示例系统示出了由被配置为对输入数据应用掩码的比较加速器表现出的一些局限性。这些局限性包括:存储器存储开销、存储器带宽开销和算术开销。
关于存储器存储开销,掩码具有与输入训练示例数据相同的维度,并且通常使用与输入训练示例数据相同的数据类型来指定。例如,如果输入训练示例数据是16位浮点值的L×L矩阵(例如BFLoat16或FP16),则输入训练示例数据和掩码各自的大小为16L
关于存储器带宽开销,如图2中所看到的,存储在存储器中的注意力掩码240通过通信总线262从系统存储器250提取或发送到向量处理器/加速器260,并且消耗与提取训练示例输入数据210一样多的带宽。训练大型机器学习模型(诸如变换器)通常涉及多个处理器/加速器260通过共享通信总线262同时或并发地从系统存储器250的多个存储器组提取数据,并且因此受益于存储器带宽的高效使用。然而,在图2中所示的布置中,通过该共享通信总线262提取注意力掩码240强加了附加的1×存储器带宽并且可能成为系统性能瓶颈。
关于算术开销,在图2中所示的系统中,根据方程(1)执行的每个注意力掩码操作需要一次浮点乘法和两次浮点减法,这消耗了向量处理器的浮点计算资源的相当一部分和/或FPGA的相当数量逻辑块。
根据本技术的各种示例,表现出上述特性中的一个或多个的加速器设计的这三个局限性提供了增加能量效率、存储效率、带宽效率和计算速度的机会,这使得具有小存储器占用空间的注意力掩码能够生成和具有较少浮点运算的掩码能够操作。这样的改进使得本技术的示例能够用于训练大型机器学习模型(诸如最先进的自回归变换器模型)提供成本效益的解决方案。
本技术的示例的各方面涉及用于加速机器学习模型的训练过程的系统和方法,该训练过程包括包含对数据的掩码的过程。示例的一些方面涉及通过使用多路复用器并且不执行任何浮点算术来应用掩码(例如,在自回归变换器模型的情况下的注意力掩码)。实施例的一些方面涉及一种电路,该电路还被配置为在设备上生成常用掩码,从而避免使用存储资源和通信带宽来通过通信总线将掩码传送到加速器。实施例的一些另外的方面涉及混合电路,其可配置为生成并应用设备上的掩码或者应用通过通信总线从系统存储器接收到的掩码(例如,针对不太常用的掩码或专用的掩码)。将上述在没有浮点算术的情况下将掩码应用于数据(或掩码数据)和在设备上生成掩码的技术组合减少了与掩码相关联的存储器开销(例如,存储和带宽)并减少了计算开销,而不损失为了专用的目的而支持的不同或任意掩码的灵活性,这些掩码无法在片上生成或在片上生成将是低效的。
图3A是根据一个示例的包括被配置为接收掩码数据的数据掩码电路的加速器的框图。图3B是根据一个示例的用于使用数据掩码电路和接收到的掩码数据对数据掩码的方法390的流程图。如图3A中所示,训练示例输入数据310和掩码数据340被存储在系统存储器350中,其经由通信总线362提供给加速器360并且存储在加速器360的设备存储器363中(例如,在加速器的FPGA实现的情况下为块存储器或BRAM)。因此,在一些示例中,在操作391中,加速器接收包括在多个索引处的数据值的输入数据。在图3A中所示的示例中,输入数据被布置在数据值的二维数组(或矩阵)中,其中每个数据值位于矩阵的二维索引(例如,行和列坐标对)处。虽然图3A示出了二维数组,但本技术的实施例不限于此,并且包括输入数据值被布置在数据值的一维数组(或向量)中的情况,在这种情况下,每个数据值的索引是单个值,以及输入数据值被布置成n维数组(或张量)的情况,其中n大于2,其中每个值的索引可以被表示为n维坐标元组。
在操作393中,加速器还接收包括在多个索引处的掩码值的掩码数据,其中掩码值的索引对应于在操作391中接收的输入数据的索引。
注意力掩码存储和生成逻辑或数据掩码电路364被配置为通过将掩码数据340应用于训练示例输入数据310而基于训练示例输入数据310和掩码数据340来计算所掩码的数据330。更详细地,在图3A中所示的示例中,解多路复用器366将训练示例输入数据310与掩码数据340分离,并沿着不同的数据路径引导数据。数据值(标记为x)被提供给掩码多路复用器365的输入之一,并且掩码数据340用于控制掩码多路复用器365。掩码多路复用器365的另一输入被提供有替代值,在图3A中示出为-10,000.0,但是本公开的实施例不限于此。
在图3中所示的布置中,在解多路复用器366的掩码输出和掩码多路复用器365的控制输入之间还包括比较器367。该比较器367用于将掩码数据340从其内部格式(例如,浮点表示)转换为二进制表示(例如,对应的0或1值),以便控制掩码多路复用器365。
在操作395中,加速器360在输入数据310的数据值(x)和替代值(-10000.0)之间选择以生成所掩码的数据330,其在操作397中被输出(例如,到加速器360的其他部分,诸如如图3A中所示的SoftMax和其他处理370)。如以上所讨论的,被提供作为示例的替代值-10000.0在图3A中仅作为大负数的示例,使用该大负数使得计算这些大负数的SoftMaxσ结果是接近0或四舍五入到0的值,从而隐藏或移除或掩码这样的数据值。然而,本技术的示例不限于此。如上所述,在此示例中,基于数据值x的规模不大于1000.0的假设来选择值-10000.0,并且因此应用于对数据掩码的替代值取决于要被掩码的数据值x的范围。例如,如果数据值x的规模不大于10,000,则在掩码中应用的替代值可以是-100,000。作为另一示例,替代值可以是不同的值,诸如固定值0.0,诸如在SoftMax函数之后应用掩码的情况下或者在将掩码应用于后面不直接跟随有SoftMax函数或其他指数函数的神经网络架构的其他层之间的激活的情况下(例如,当对神经网络层的激活掩码以实现用于利用随机失活正则化训练的随机失活层时)。
在图3A中所示的实施例中,加速器360实现向量处理器,该向量处理器被配置为对数据执行单指令多数据向量操作,其中对向量中的多个值并行执行相同的操作。在图3A中,加速器通过SIMD的因子执行这些并行操作(例如,在长度SIMD的向量上,其中SIMD是诸如8的值,或者通常是2的幂的另一值)。因此,各种数据路径被标记为“SIMD”,指示这些数据路径是SIMD通道宽,或者“SIMD*16”,指示这些数据路径是“SIMD*16”位宽(例如,在SIMD 16位值的向量的情况下为SIMD 16位通道)。作为具体示例,图3A中所示的掩码多路复用器365是SIMD宽多路复用器,其被提供有SIMD*16输入(x)并由表示掩码的SIMD宽信号控制。因此,掩码多路复用器365输出基于SIMD宽掩码值从对应数据值x或替代值(-10000.0)并行选择的SIMD 16位值的向量。为了处理完整的训练示例输入数据310,加速器360将训练示例输入数据310划分为SIMD大小的块,并且将一次一个SIMD大小的块提供给数据掩码电路364。
因此,本技术的一些方面涉及基于掩码来加速对输入数据的掩码,而不使用浮点算术,诸如两个浮点减法和浮点乘法(例如,参见图2),并且相反的,使用多路复用器执行掩码以基于掩码数据在数据值和替代值之间进行选择。
图4A是根据一个示例的包括被配置为生成掩码数据的数据掩码电路的加速器的框图。如图4A中所示,根据一个示例,训练示例输入数据410被存储在系统存储器450中,系统存储器450与加速器460通信。训练示例输入数据410被发送到加速器460,其中他可以例如被存储在加速器460的设备存储器463中(例如,在FPGA中实现的加速器460的情况下为块存储器或BRAM)。与图2和图3中所示的布置相反,加速器460不通过通信总线462从系统存储器450(其可以不存储掩码数据)提取掩码数据。相反,根据一些示例的加速器460包括掩码生成电路480,掩码生成电路480被配置为生成应用于接收到的输入数据410的掩码。
图4B是根据一个示例的用于使用数据掩码电路和生成的掩码数据对数据掩码的方法的流程图。在操作491中,加速器460接收包括在多个索引处的数据值的输入数据。如上关于图3A所述,在图4A中所示的示例中,输入数据被布置在数据值的二维数组(或矩阵)中,其中每个数据值位于矩阵的二维索引(例如,行和列坐标对)处,但本技术不限于此,并且包括输入数据值被布置在其他n维数组中的情况,其中n大于0并且由n维索引来索引。
在操作493处,加速器460生成用于输入数据的掩码,其中掩码包括在与数据值的索引相对应的多个索引处的掩码值。在图4A中所示的实施例中,掩码生成电路480基于从另一电路组件(在图4A中示出为SoftMax和其他处理470)接收的索引(示出为列计数器col_cnt和行计数器row_cnt)来生成掩码值。更详细地,掩码生成电路480针对掩码内的每个索引或位置生成二进制值,其中二进制值是0或1(例如,其中1指示原始数据应当出现在所掩码的数据中,并且其中0指示原始数据应当被移除或掩蔽)。
在一些示例中,掩码生成电路480被配置为基于可以使用闭合形式方程或公式来表达的重复或反复模式来生成掩码。如上所述,一个这样的例子是在变换器模型中通常使用的三角掩码。
其中i是列索引并且j是行索引,其中方程(2)指定上三角掩码,该上三角掩码掩蔽输入数据矩阵的右上部分中的元素并选择输入数据矩阵的左下三角部分中的元素,并且其中方程(3)指定下三角掩码,该下三角掩码掩蔽输入数据矩阵的左下部分中的元素并选择输入数据矩阵的右上三角部分中的元素。
因此,掩码生成电路480根据掩码生成电路480中编码的公式(例如,方程(2)或方程(3))基于给定索引(例如,(i,j)坐标对)来自动生成掩码值(例如,0和1)。虽然方程(2)和(3)的上三角掩码和下三角掩码提供了掩码的两个示例,但本技术的示例不限于此,并且还包括其他形状的其他类型的掩码,诸如交替模式(例如,基于索引值的奇偶校验)、可以基于提供给掩码生成电路480的附加参数(例如,标识矩形区域的拐角的坐标对)而固定或定义的矩形区域等。下面将更详细地描述实现根据本技术的掩码生成电路480的电路的示例。
在操作495处,在每个索引处,加速器460在来自原始输入数据的数据值和基于掩码的在该索引处的掩码值的替代值之间选择。如图4A中所示,从掩码生成电路输出的掩码值被提供给掩码多路复用器或掩码多路复用器465,其中掩码多路复用器465用于在从设备存储器463接收的输入数据和替代值之间选择,其中替代值的示例在图4A中被示出为-10,000.0。如以上所讨论的,被提供作为示例的替代值-10000.0在图4A中仅作为大负数的示例,使用该大负数使得计算这些大负数的SoftMaxσ结果是接近0或四舍五入到0的值,从而隐藏或移除或掩码这样的数据值。然而,本技术的示例不限于此,并且可以根据掩码数据选择其他替代值来针对代替输入数据值的输出。
在操作497处,加速器460的数据掩码电路464输出如通过在操作495中选择掩码而产生的所掩码的数据430。然后输出所掩码的数据430,例如用于由加速器460的其他部分,诸如用于SoftMax和其他处理470的电路,进一步处理。
以与上面关于图3A描述的方式类似的方式,图4A中所示的数据掩码电路464被示出为向量处理器,其被配置为以SIMD值块(例如,用于SIMD*16位的数据路径的SIMD 16位值)处理输入数据410,其中掩码生成电路480被配置为以SIMD位宽的块生成掩码。
使用存储器来存储规则或重复模式二进制掩码的所有元素具有大量空间冗余,因为仅要存储两个可能值:{0.0,1.0},但每个掩码值可能使用远多于单个位来表示(例如,每个值可以以诸如BFloat16或FP16的16位浮点值数据格式表示)。因此,代替将掩码模式存储在片外存储器(例如,图2的系统存储器250)中并在掩码过程期间提取到片上存储器(例如,图2的设备存储器263),如上面关于图4A和图4B所描述的本技术的示例的一些方面使用加速器460内的逻辑(例如,FPGA软逻辑)来构建掩码生成电路480以即时创建掩码。
图4C是根据一个示例的包括被配置为生成掩码数据的数据掩码电路464'的加速器460'的框图。图4C中所示的框图基本上类似于图4A中所示的框图,其中训练示例输入数据410'被存储在系统存储器450'中,系统存储器450'通过通信总线462'与加速器460'通信。输入训练示例数据410'被发送到加速器460',其中他可以例如被存储在加速器460的设备存储器463中。类似于图4A的加速器460,根据一些示例的加速器460'包括掩码生成电路480',掩码生成电路480'被配置为生成应用于接收到的输入数据410'的掩码。
与图4A中所示的框图相反,掩码生成电路480'输出控制掩码多路复用器465'选择性地输出0.0f或1.0f的浮点值的掩码值(例如,SIMD长度的位向量),使得通过掩码生成电路480'和掩码多路复用器465'的组合生成的掩码的格式类似于图2中所示的浮点注意力掩码240的数据格式。以实现方程(1)的公式的方式,沿着数据路径(例如,在掩码值的16位浮点表示的情况下为SIMD*16宽数据路径)将掩码的浮点值提供给第一加法器466,第一加法器466被配置为从常数值1.0f减去掩码值并将结果值乘以常数大负值(在图4C中被示出为-10000.0f),然后将该值提供给第二加法器468来从数据x减去该值。
因此,图4C中所示的布置描绘了使用片上或加速器上掩码生成电路480来生成掩码,从而避免与存储掩码和通过通信总线462'发送掩码相关联的带宽和存储消耗,同时以类似于比较技术(例如,使用浮点乘法器和浮点加法器)的方式将内部生成的掩码应用于输入训练示例数据x。
因此,上面关于图4A和图4C描述的数据掩码电路464和数据掩码电路464'是被配置为将由掩码生成电路480内部生成的掩码应用于从外部源接收的数据的电路的示例。
本技术的一些示例涉及数据掩码电路,该数据掩码电路可配置为基于附加输入来使用掩码生成电路选择性地在内部生成掩码(“内部掩码”)、应用通过通信总线接收的外部提供的掩码(“外部掩码”),或者不对数据应用掩码。这使得本技术的一些示例能够维持应用掩码的灵活性,这些掩码可能具有掩码生成电路不支持的不规则模式,或者针对掩码生成电路在内部生成而言将是低效(例如,因为对应的表示掩码的闭合形式方程是复杂的)。
图5A是根据一个示例的包括混合数据掩码电路的加速器的框图,该混合数据掩码电路被配置为选择性地基于生成的掩码数据或基于接收到的掩码数据对数据掩码。更详细地,图5A提供了针对加速器560的混合掩码架构的示例,其包括用于应用基于存储器的外部掩码(例如,通过通信总线从外部源接收)的数据路径和用于应用内部生成的掩码(例如,由加速器内的掩码生成电路生成)的数据路径两者。更详细地,根据图5A中所示的一个示例的数据掩码电路564基本上类似于图3A的数据掩码电路364和图4A的数据掩码电路464,并且组合来自图3A的数据掩码电路364和图4A的数据掩码电路464的组件,图3A的数据掩码电路364被配置为基于从系统存储器350接收的外部掩码340对数据掩码,图4A的数据掩码电路464被配置为基于由数据掩码电路464的掩码生成电路480生成的内部掩码对数据掩码。
图5B是根据一个示例的用于使用混合数据掩码电路对数据掩码的方法590的流程图,该混合数据掩码电路被配置为选择性地基于生成的掩码数据或基于接收到的掩码数据对数据掩码。在操作591中,加速器560接收包括在多个索引处的数据值的输入数据。如上关于图3A和图4A所述,在图5A中所示的示例中,输入数据被布置在数据值的二维数组(或矩阵)中,其中每个数据值位于矩阵的二维索引(例如,行和列坐标对)处,但本技术不限于此,并且包括输入数据值被布置在其他n维数组中的情况,其中n大于0并且由n维索引来索引。
在一些示例中,由1位掩码选择输入(“mask_sel”)控制的掩码选择多路复用器(mux)568用于选择是从存储器(例如,系统存储器550或设备存储器563)还是片上掩码生成电路580提供掩码。因此,如图5B中所示,在操作592中,数据掩码电路564选择数据掩码电路564将从其应用掩码的数据路径,在对应于从系统存储器550接收的外部掩码540的数据路径和对应于在加速器560内生成的掩码的数据路径之间选择。
更详细地,用于应用来自系统存储器550的外部掩码540的数据路径包括存储在操作593中从系统存储器接收的外部掩码540的设备存储器563的一部分、被配置为将输入训练示例数据510与外部掩码数据540分离的解多路复用器566以及被配置为将掩码数据从掩码值的浮点表示转换为二进制值(例如,单个位值)的可选的比较器567。然后将所得的二进制掩码作为输入之一提供给掩码选择多路复用器568。
在图5A中所示的示例中,用于应用生成的掩码的数据路径包括掩码生成电路580。在一些示例中,1位掩码启用输入(“mask_en”)被提供作为掩码参数,其用以在操作594中选择是将掩码一直应用于数据,诸如通过控制掩码生成电路580以在操作595中生成使得所有输入数据流经输出的掩码(从而对输入数据执行恒等函数,或将恒等掩码应用到输入数据),还是应用根据特定模式生成的掩码(例如,上三角掩码、下三角掩码、块上三角掩码、块下三角掩码、交替掩码等),其中掩码生成电路580被配置为基于在不同的可能掩码之间选择的附加输入来生成特定掩码。
更详细地,以与上面关于图4A和图4B的掩码生成电路480描述的方式类似的方式,掩码生成电路580接收指示要生成的掩码的一部分的索引(例如,从SoftMax和其他处理电路570接收的列计数器col_cnt和行计数器row_cnt),并且根据掩码生成电路580被配置为(例如,基于来自预编程的掩码的集合的选择)生成的掩码的模式生成掩码并将掩码值输出到掩码选择多路复用器568。
如图5A中所示,对应于由掩码选择输入(mask_sel)选择的掩码的掩码选择多路复用器568的输出被提供给掩码多路复用器565,掩码多路复用器565被配置为在操作596中在输入数据(x)和替代值(在图5A中被示出为-10000.0)之间选择以生成表示根据所选择的掩码而掩码的输入数据的所掩码的数据(x_masked)530。数据掩码电路564在操作597中输出所掩码的数据530,例如针对由加速器560的其他部分,诸如针对SoftMax的电路和其他处理电路570,进一步处理。
图6A是根据一个示例的被配置为生成上三角掩码(诸如根据方程(2)定义的掩码)的掩码生成电路600的框图。掩码生成电路的该示例可以被应用为例如图5A中所示的掩码生成电路580的组件。图6A中所示的掩码生成电路600采用三个输入:“mask_en”作为从外部(例如,从管理加速器在加速机器学习模型的训练中的使用的软件程序)接收的控制寄存器信号的掩码启用信号,以及行计数器“row_cnt”和列计数器“col_cnt”,他们是可以从数据掩码电路之后的电路(诸如图5A中所示的SoftMax和其他处理电路570)接收的两个计数器值。作为另一示例,如果使用向量处理器来执行SoftMax,则在运行固件时可以通过寄存器文件值来提供计数器。
在图6A中所示的示例中,掩码生成电路被配置为以加速器的SIMD大小的块生成掩码值,该加速器被配置为以SIMD大小的块并行地跨多个值执行操作。例如,考虑图5A中所示的布置,其中输入训练示例数据510被布置在二维数组(矩阵)中并且其中对应的掩码具有与输入训练示例数据510具有相同维度的二维矩阵的结构,可以逐行地处理二维数组,其中二维数组的每行被划分为SIMD大小的块(还假设每行中的值的数量是加速器的SIMD数据宽度的整数倍,或者填充到大于二维数组的列维度的下一个SIMD整数倍)。
列计数器“col_cnt”指定沿着在其上SoftMax操作将应用于所掩码的数据的张量行提取的数据向量的当前位置。由于数据的每行都是单独处理的并且被分解成SIMD大小的块,因此在输入数据是正方形(例如,输入数据的维度为L×L)的情况下,行计数器“row_cnt”从0计数到L-1且列计数器“col_cnt”从0计数到(L/SIMD)-1。因此,行计数器“row_cnt”比“col_cnt”具有更多log2(SIMD)位。
图6B是示出根据一个示例的被配置为生成三角掩码的掩码生成电路的输入和输出的时序图。在图6B中所示的示例中,输入张量的维度为128×128,并且SIMD宽度为16个值。结果,行计数器row_cnt从0计数到127,这需要7位(2
如上所述,示例掩码生成电路600被配置为生成上三角掩码,并且因此这些可能性包括:SIMD 1的块{SIMD{1'b1}}、SIMD 0的块{SIMD{1'b0}},或者一些数量的1后跟有一些数量的0。如图1中所示的示例掩码40中所看到的,上三角掩码在左下三角(示出为白色正方形)中具有值1,并且在三角的右上部分(示出为阴影正方形)中具有值0。
如图6B中所示,当行计数器在附图标记660处为0时,则仅第一掩码值具有值1并且行0中的剩余掩码值s具有值0。因此,针对第一SIMD大小的值块(其中SIMD为16)为位串1'b1000000000000000,其等于十六进制的8000,如图6B的attn_mask对应值中所示。第一行的剩余七个块在col_cnt 1至7处全部为零。同样,当考虑上三角掩码的行1时,前两个掩码值的值为1,并且剩余掩码值的值为0。因此,当row_cnt在附图标记661处为1时,第一SIMD大小的值块是位串1'b1100000000000000,其等于十六进制的c000,如图6的attn_mask的对应值中所示,并且第一行的剩余七个块在col_cnt 1至7处全部为零。
图6B还提供了当row_cnt在附图标记675处为15时并且当row_cnt在附图标记676处为16时的示例。具体地,在行15中,该行的前十六个值是1,并且因此16个值的完整第一块是1,其等于十六进制的ffff,并且第一行的剩余7个块在col_cnt 1至7处全部为零,如图6的attn_mask的对应值中所示。在行16中,前十七个掩码值是1,所以在col_cnt 0处的第一个块全部为1(ffff),并且在col_cnt 1处的第一个值为1,后跟有十五个0,其等于十六进制的8000。在col_cnt 2至7处的行的剩余块全部为0,如图6B中的attn_mask的对应值中所示。
作为另一示例,在图6B的附图标记687处生成的上三角掩码的最后一行全部为1(参见,例如,图1的掩码40),并且因此attn_mask在行中的所有块期间(例如,针对col_cnt0至7)都是ffff。
因此,掩码的每个生成的SIMD大小的块可以:当SIMD大小的块完全在1的左下三角内时全部为1;当SIMD大小的块完全在0的右上三角中时全部为0;或者在块跨越1的左下三角和0的右上三角之间的边界的情况下一些数量的1后跟有剩余数量的0。
如图6A所示,最终注意力掩码输出att_mask是与由多路复用器640基于选择信号{sel0、sel1、sel2}的组合选择的三种可能性之一相对应的SIMD位向量。特别地,当块的输出全部为1时,第一选择信号sel0被断言,当输出全部为0时,第三选择信号sel2被断言,并且当输出跨越1的左下三角和0的右上三角之间的对角线边界(1后跟有0的序列)时,第二选择信号sel1被断言。
图6C是根据一个示例的用于基于索引来生成三角掩码的方法690的流程图。在操作691中,掩码生成电路600使用小于或等于比较器612将当前“row_cnt”值与(通过第一一填充电路610)用log
选择信号sel0、sel1和sel2被提供给包括第一多路复用器641、第二多路复用器642和第三多路复用器643的多路复用器640,以分别将输出控制为全部1、1和0的混合、以及全部0的情况。
图6A中所示的掩码生成电路600的示例基于行计数器来生成1和0的混合,如下文更详细地描述的。在操作695中,掩码生成电路600使用移位器650移位SIMD+1个1和SIMD-1个0的2*SIMD长向量或{{(SIMD+1){1'b1}},{(SIMD-1){1'b0}}}(例如,当SIMD为16时为1'b11111111111111111000000000000000),其中移位后的输出的SIMD LSB被提供给与sel1为1’b1的情况相对应的第二多路复用器642。移位器650将固定向量移位通过取row_cnt的log
在操作696中,掩码生成电路使用第三多路复用器643以在由移位器650输出的移位的向量和0的向量之间选择以生成第一输出,其中基于第三选择信号sel2选择。在操作697中,掩码生成电路使用第二多路复用器642以在第一输出和由移位器650输出的移位的向量之间选择以生成第二输出,其中基于第二选择信号sel1选择。在操作698中,掩码生成电路使用第一多路复用器641以基于第一选择信号sel0在第二输出和1的向量({SIMD{1'b1}})之间选择,以生成输出掩码(attn_mask)。
如上所述,在一些示例中,控制输入“mask_en”用于启用或禁用掩码。当掩码被启用时(例如,当mask_en为1时),则输出三角掩码(例如,在左下三角中具有1并且在右上三角中具有0),且当掩码被禁用时(例如,当mask_en为0时),则整个掩码可以被输出为具有值1,使得原始数据在没有修改的情况下通过数据掩码电路(例如,不对数据掩码)。
因此,在图6A中所示的示例中,控制输入“mask_en”用以生成在最高有效位(MSB){{(SIMD+1){1'b1}},{(SIMD-1){!mask_en}}}填充1的2*SIMD位常数向量。在图6B中所示的示例中,其中SIMD为16,当mask_en为1时(当启用掩码时),该向量为1'b11111111111111111000000000000000,并且当mask_en为0时,该向量为32个1{32{1'b1}}。
同样地,针对第三选择信号sel2为1'b0的情况,到第三多路复用器643的输入被示出为{SIMD{!mask_en}}(而不是0的向量),使得当mask_en为1时,到第三多路复用器643的输入是{SIMD{1'b0}}(0的向量)并且当mask_en为0(掩码禁用)时,到第三多路复用器的输入是{SIMD{1'b1}}(1的向量)。
根据上面关于图6A描述的示例的掩码生成电路还可以适用于在掩码生成电路480内(例如,没有掩码使能信号)使用,诸如通过将到移位器650的输入固定为{{(SIMD+1){1'b1}},{(SIMD-1){1'b0}}}并将到第三多路复用器643的输入固定为0的向量{SIMD{1'b0}}。
另外,虽然图6A、图6B和图6C描述被配置为生成上三角掩码的掩码生成电路的一个示例,但本技术不限于此。
例如,上面关于图6A、图6B和图6C描述的示例可以被修改以通过对例如提供给第一多路复用器641和第三多路复用器643的固定输入以及作为输入提供给移位器650的2*SIMD长向量的适当修改来生成下三角掩码。在一些示例中,这由提供给掩码生成电路600的附加控制信号来控制。作为具体示例,upper_mask信号可以当要生成上三角掩码时被设置为1'b1并且当要生成下三角掩码时可以被设置为1'b0。因此,在该示例中到第一多路复用器641的固定输入可以是{SIMD{upper_mask}}||SIMD{!mask_en}而不是{SIMD{1'b}},并且到第三多路复用器643的固定输入可以是{SIMD{!upper_mask}}||SIMD{!mask_en}。输入到移位器650的向量可以类似地被修改为:{{(SIMD-1){upper_mask}},{(2){1'b1}},{(SIMD-1){!upper_mask}}}||{(2*SIMD){!mask_en}}。
在一些示例中,掩码生成电路被配置为输出块三角掩码,其中该掩码与每行的SIMD块对齐,并且不存在掩码生成电路生成1和0的混合的块的情况。该方法可以简化掩码生成电路,诸如通过省略相等比较器630、移位器650和第二多路复用器642,因为不再需要针对块三角掩码生成具有1和0的混合的块。可以以与以上所描述的方式类似的方式,以上三角或下三角模式来生成块三角掩码。
在根据本技术的掩码生成电路的一些示例中,掩码生成电路600还可以基于如图4A和图5A中所示的掩码参数来配置。例如,可以将掩码参数提供给一个或多个附加多路复用器的控制引脚,以在掩码生成电路内的不同配置的掩码模式之间选择,诸如以启用或禁用用以生成三角掩码与块三角掩码的电路元件,或者选择完全不同的掩码生成电路(例如,以基于row_cnt和/或col_cnt坐标或索引的奇偶校验来生成掩码模式)。
在根据本技术的掩码生成电路的一些附加示例中,可以基于掩码参数来参数化由掩码生成的底层模式,诸如其中掩码参数指定与要掩码的矩形区域的拐角相对应(或定义未掩码的区域)的索引或坐标,诸如其中基于参数来控制块三角掩码的每步的长度(以SIMD为单位)。
图7是描绘根据本公开的一个示例的用于使用加速的数据掩码电路来训练诸如变换器模型的机器学习模型的方法的流程图。在图7中所示的示例中,机器学习模型训练应用(参见,例如,在包括FPGA的计算设备上运行的机器学习训练应用852,如图8中所示)执行监督学习算法以基于标记的输入数据的集合来训练机器学习模型,诸如变换器模型。在图7中所示的示例中,机器学习模型训练应用在操作710中接收标记的训练数据,并将训练数据(例如,一批训练数据)提供给当前机器学习模型以计算激活(例如,将来自训练数据的数据样本的值的输入向量提供到深度神经网络,其中深度神经网络的层生成激活)。
在操作730中,机器学习模型训练应用对输入激活或训练示例数据掩码。这可以包括将掩码应用于训练示例数据,无论是从系统存储器接收的外部掩码还是在加速器上生成的内部掩码,以根据上面关于图1、图2、图3A、图3B、图4A、图4B、图5A、图5B、图6A、图6B和图6C描述的技术,诸如通过应用方法390、490或590,来计算所掩码的数据。在操作734中,机器学习模型训练应用基于掩码的激活或数据来计算机器学习模型的输出分数(例如,因为使用数据的掩码的硬件加速的计算而计算出的掩码的激活在通过机器学习模型的数据的前向传播中被使用)。可以使用例如SoftMax函数来计算归一化输出分数以归一化由深度神经网络或变换器模型的输出层生成的激活。
在操作740中,机器学习模型训练应用基于机器学习模型的输出的归一化分数来更新机器学习模型(其中输出是基于使用根据本技术的技术在深度神经网络的隐藏层或输出层中计算的激活来计算的)以生成更新后的机器学习模型(例如,在深度神经网络中,通过将归一化分数与训练数据的标签比较,并通过梯度下降和反向传播更新神经元之间的连接的权重)。在操作750中,机器学习模型训练应用确定训练是否完成(例如,最大数量的训练间隔或训练时期是否已经完成或者机器学习模型的性能是否已经收敛),并且如果没有,则训练过程可以通过使用更新后的机器学习模型返回到操作720来继续。如果训练过程完成,则将更新后的机器学习模型作为训练后的机器学习模型输出并存储,并且训练过程结束。然后,可以部署存储的、训练后的机器学习模型,用于在基于与训练数据(例如,自然语言输入数据、图像等)类似的实时数据通过利用训练后的机器学习模型处理实时数据以生成输出(例如,输入实时数据的分类或序列中的预测的下一项)来执行推理任务(例如,做出预测或估计)中使用。
本技术的各方面还涉及在不使用任何浮点运算时的零运算掩码方法。一般来说,变换器模型中的注意力掩码的目的是为掩蔽的位置分配大负值,使得机器学习模型中的后续SoftMax层在作为输入提供给SoftMax层的低精度指数函数(exp(x))时将掩蔽的位置衰减到零。在大多数变换器模型(例如,来自变换器或BERT的双向编码器表示,参见Devlin、Jacob等人的“Bert:Pre-training of deep bidirectional transformers for languageunderstanding(Bert:针对语言理解的深度双向变换器的预训练).”arXiv preprintarXiv:1810.04805(2018))中,-10000.0用以作为掩码的输出值。
如上所述,当掩码位为0时不是做出-10000.0的向量减法,然后是浮点向量乘法,而是直接使用具有一个常数输入-10000.0的2选1多路复用器执行相同的功能:y=mask?x:-10000.0(其中?是三元if或条件运算符)。换句话说,当使用诸如BFloat16的低精度浮点表示时,exp(x–10000)=exp(-10000.0)=0。
因此,本技术的各方面使得多路复用器能够执行先前由一个浮点乘法器和两个加法器执行的相同功能,从而显著减少硬件资源需求(例如,FPGA中的更少逻辑块)。例如,当使用BFloat16并且SIMD=16时,使用两个加法器和一个浮点乘法器的比较掩码操作逻辑需要1344个逻辑块(ALM)和11个DSP。相比之下,同样使用BFloat16和SIMD=16的本技术的示例仅需要128个ALM,其对应于91%的ALM节省和100%的DSP节省。此外,适当地重新定位加速器内部的掩码逻辑(例如,在加速器内部实现掩码生成电路)可以通过将2选1多路复用器与未充分利用ALM的其他多路复用器(例如,每个ALM可以支持1个8选1查找或2个4选1查找)打包来进一步减少128个ALM。在一个示例实现中,在具有SIMD=16的FPGA上实现的三角掩码生成电路仅消耗44个ALM,考虑到在FPGA上实现机器学习加速器的总体系统预算(例如,实现用于加速机器学习(诸如加速的SoftMax函数)的附加电路),其基本上可忽略。
因此,本技术的各方面提供了用于加速机器学习架构内的数据的掩码、增加训练机器学习模型的性能的系统和方法,诸如通过减少总体计算(训练)时间、减少带宽和存储需求,和/或减少能源消耗。
图8、图9A和图9B相关联的描述提供了可以在其中实践本技术的示例的各种操作环境的讨论。然而,关于图8、图9A和图9B示出和讨论的设备和系统是出于示例和说明的目的,并且不限制可以用于实践本文描述的本发明的各方面的大量计算设备配置。
图8是示出可以用来实践本公开的示例的计算设备800的物理组件(即,硬件)的框图。下面描述的计算设备组件可以适合于运行用于机器学习模型的训练过程或者适合于使用训练后的机器学习模型来执行推理,如以上所描述的。在基本配置中,计算设备800可以包括至少一个处理单元802、现场可编程门阵列(FPGA)803和系统存储器804。在一些示例中,处理单元802包括FPGA 803(例如,处理单元802可以包括可通过设置互连来重新配置的逻辑块阵列)。在一些示例中,处理单元802被集成或嵌入到FPGA 803中(例如,在一个或多个嵌入式“硬IP”CPU核直接连接到FPGA 803的互连或结构和/或一个或多个嵌入式“软IP”CPU核使用FPGA 803的逻辑块实现的情况下)。取决于计算设备的配置和类型,系统存储器804可以包括但不限于易失性存储器(例如,随机存取存储器)、非易失性存储器(例如,只读存储器)、闪存或这样的存储器的任何组合。系统存储器804可以包括操作系统805和一个或多个程序模块806,其适合于运行软件应用850,诸如机器学习模型训练应用852或客户端应用854。操作系统805例如可以适合于控制计算设备800的操作。此外,本发明的各方面可以结合图形库、其他操作系统或任何其他应用程序来实践,并且不限于任何特定应用或系统。该基本配置在图8中由虚线808内的那些组件示出。计算设备800可以具有附加特征或功能。例如,计算设备800还可以包括附加数据存储设备(可移除和/或不可移除),诸如,例如,磁盘、光盘或磁带。这种附加存储在图8中由可移除存储设备809和不可移除存储设备810示出。
如以上所陈述的,多个程序模块和数据文件可以存储在系统存储器804中。当在处理单元802上执行时,程序模块806可以执行将计算任务卸载到FPGA 803的过程。FPGA 803可以包括被配置为加速各种数学函数的计算的数据路径,各种数学函数的计算包括但不限于如上文关于图1、图2、图3A、图3B、图4A、图4B、图5A、图5B、图6A、图6B和图6C所描述的对数据掩码。FPGA 803可以被配置为包括用于实现根据本发明的示例的其他数学函数的其他数据路径,诸如计算softmax函数、指数函数、倒数平方根函数等。
此外,本发明的示例可以在包括分立电子元件的电路、包含逻辑门的封装或集成电子芯片、利用微处理器的电路中、或者在包含电子元件或微处理器的单个芯片上实践。例如,本发明的示例可以经由片上系统(SOC)来实践,其中图8中示出的组件中的每个或许多可以被集成到单个集成电路上。这样的SOC设备可以包括一个或多个处理单元、现场可编程门阵列、图形单元、通信单元、系统虚拟化单元和各种应用功能,所有这些都作为单个集成电路集成(或“烧写”)到芯片衬底上。当经由SOC操作时,本文描述的关于训练机器学习模型(例如,深度神经网络)或执行涉及数据的掩码的计算的一些功能可以经由在单个集成电路(芯片)上与计算设备800的其他组件集成的应用特定逻辑来操作。本公开的示例还可以使用能够执行逻辑运算(诸如,例如,AND、OR和NOT)的其他技术来实践,包括但不限于机械、光学、流体和量子技术。另外,本发明的各方面可以在通用计算机内或者在任何其他电路或系统中实践。
计算设备800还可以具有一个或多个(多个)输入设备812,诸如键盘、鼠标、笔、声音输入设备、触摸输入设备等。还可以包括诸如显示器、扬声器、打印机等的(多个)输出设备814。上述设备是示例并且可以使用其他设备。在计算设备800是服务器的情况下,这样的用户输入设备和用户输出设备通常不存在或者不直接连接到计算设备800。计算设备800可以包括允许与其他计算设备818通信的一个或多个通信连接816。合适的通信连接816的示例包括但不限于RF发射器、接收器和/或收发器电路;通用串行总线(USB)、并行和/或串行端口。
如本文所使用的术语计算机可读介质可以包括计算机存储介质。计算机存储介质可以包括以用于存储信息的任何方法或技术实现的易失性和非易失性、可移除和不可移除介质,该信息为诸如计算机可读指令、数据结构、程序模块或指定FPGA的配置以实现特定功能的配置文件(“位文件”)。系统存储器804、可移除存储设备809和不可移除存储设备810全部是计算机存储介质示例(即,存储器存储)。计算机存储介质可以包括RAM、ROM、电可擦除可编程只读存储器(EEPROM)、闪存或其他存储器技术、CD-ROM、数字多功能光盘(DVD)或其他光存储、盒式磁带、磁带、磁盘存储或其他磁存储设备、或可以用于存储信息并且可以由计算设备800访问的任何其他制品。任何这样的计算机存储介质可以是计算设备800的一部分。计算机存储介质不包括载波或其他传播的数据信号。
通信介质可以由计算机可读指令、数据结构、程序模块或调制的数据信号中的其他数据(诸如载波或其他传输机制)来体现,并且包括任何信息递送介质。术语“调制的数据信号”可以描述具有以对信号中的信息编码的方式设置或改变的一个或多个特性的信号。作为示例而非限制,通信介质可以包括诸如有线网络或直接线连接的有线介质,以及诸如声学、射频(RF)、红外和其他无线介质的无线介质。
图9A和图9B示出了可以用来实践本发明的各方面的移动计算设备900,诸如移动电话、智能电话、平板个人计算机、膝上型计算机等。参考图9A,示出了用于实现这些方面的移动计算设备900的示例。在基本配置中,移动计算设备900是具有输入元件和输出元件两者的手持计算机。移动计算设备900通常包括显示器905和一个或多个输入按钮910,该输入按钮910允许用户将信息输入到移动计算设备900中。移动计算设备900的显示器905还可以用作输入设备(例如,触摸屏显示器)。如果包括的话,可选的侧面输入元件915允许进一步的用户输入。侧面输入元件915可以是旋转开关、按钮或任何其他类型的手动输入元件。在替代示例中,移动计算设备900可以并入更多或更少的输入元件。例如,在一些示例中,显示器905可以不是触摸屏。在替代示例中,移动计算设备900是便携式电话系统,诸如蜂窝电话。移动计算设备900还可以包括可选的按键935。可选的按键935可以是物理键盘或在触摸屏显示器上生成的“软”键盘。在各个方面中,输出元件包括用于示出图形用户界面(GUI)的显示器905、视觉指示器920(例如,发光二极管)和/或音频换能器925(例如,扬声器)。在一些示例中,移动计算设备900并入用于向用户提供触觉反馈的振动换能器。在又一示例中,移动计算设备900并入输入和/或输出端口,诸如音频输入(例如,麦克风插孔)、音频输出(例如,耳机插孔)和视频输出(例如,HDMI端口)用于向外部设备发送信号或从外部设备接收信号。
图9B是示出移动计算设备的一个示例的架构的框图。也就是说,移动计算设备900可以并入系统(即,架构)902来实现一些示例。在一个示例中,系统902被实现为能够运行一个或多个应用(例如,浏览器、电子邮件、日历、联系人管理器、消息收发客户端、游戏和媒体客户端/播放器)的“智能电话”。在一些示例中,系统902被集成为计算设备,诸如集成个人数字助理(PDA)和无线电话。如图9B中所示,系统902还包括处理器960、存储可以由处理器960执行的操作系统964的存储器962。系统902还可以包括FPGA 963,其可以(使用配置文件或位文件)被配置以实现用于加速数学运算的数据路径,诸如根据本公开的各种示例的如以上所描述的对输入数据掩码的数据路径。
一个或多个应用程序950可以被加载到存储器962中并在操作系统964上运行或与操作系统964相关联地运行。应用程序的示例包括电话拨号程序、电子邮件程序、个人信息管理(PIM)程序、文字处理程序、电子表格程序、互联网浏览器程序、消息收发程序、机器学习软件(例如,用于再训练模型和/或联合机器学习)等等。系统902还包括存储器962内的非易失性存储区域968。非易失性存储区域968可以用于存储在系统902断电时不应当丢失的持久信息。应用程序950可以使用信息并将其存储在非易失性存储区域968中,诸如电子邮件或由电子邮件应用使用的其他消息等。同步应用(未示出)也驻留在系统902上,并且被编程为与驻留在主计算机上的相对应的同步应用交互,以保持存储在非易失性存储区域968中的信息与存储在主计算机处的相对应的信息同步。如应当认识到的,其他应用可以被加载到存储器962中并且在移动计算设备900上运行。
系统902具有电源970,其可以被实现为一个或多个电池。电源970还可以包括外部电源,诸如AC适配器或对电池补充或再充电的供电对接支架。
系统902还可以包括执行发送和接收射频通信的功能的无线电972。无线电972促进经由通信运营商或服务提供商在系统902与“外部世界”之间的无线连接。往来于无线电972的传输被操作系统964控制。换言之,由无线电972接收到的通信可以经由操作系统964传播到应用程序950,反之亦然。
视觉指示器920可以用于提供视觉通知,和/或音频接口974可以用于经由音频换能器925产生可听通知。在示出的示例中,视觉指示器920是发光二极管(LED)并且音频换能器925是扬声器。这些设备可以直接耦合到电源970,使得当被激活时,他们在针对由通知机制指示的持续时间内保持开启,即使处理器960和其他组件可能关闭以节省电池电力。LED可以被编程为无限期地保持开启,直到用户采取行动来指示设备的通电状态。音频接口974用于向用户提供可听信号并从用户接收可听信号。例如,除了耦合到音频换能器925之外,音频接口974还可以耦合到麦克风以接收可听输入,诸如以便于电话交谈。系统902还可以包括视频接口976,其实现机载相机930记录静止图像、视频流等的操作。
实现系统902的移动计算设备900可以具有附加特征或功能。例如,移动计算设备900还可以包括附加数据存储设备(可移除和/或不可移除),诸如,磁盘、光盘或磁带。这种附加存储在图9B中由非易失性存储区域968示出。
由移动计算设备900生成或捕获并经由系统902存储的数据/信息可以本地存储在移动计算设备900上,如以上所描述的,或者数据可以存储在可以任何数量的存储介质上,该存储介质可以由该设备经由无线电972或经由移动计算设备900和与移动计算设备900相关联的单独计算设备(例如,诸如互联网的分布式计算网络中的服务器计算机)之间的有线连接来访问。如应当认识到的,这样的数据/信息可以经由移动计算设备900经由无线电972或者经由分布式计算网络来访问。类似地,根据公知的数据/信息传送和存储部件,包括电子邮件和协作数据/信息共享系统,这样的数据/信息可以容易地在计算设备之间传送以针对存储和使用。
如从前述公开内容将理解的,本技术的一个方面涉及一种现场可编程门阵列(FPGA),其包括连接多个逻辑块的可配置互连结构,该可配置互连结构和逻辑块被配置为实现数据掩码电路,该数据掩码电路被配置为:接收输入数据,该输入数据包括输入数据在多个索引处的数据值;使用掩码多路复用器在数据值中的数据值和替代值之间进行选择以生成所掩码的数据,掩码多路复用器由在与输入数据的索引相对应的索引处的多个掩码值中的掩码值控制;以及输出所掩码的数据。
在示例中,可配置互连结构和逻辑块还被配置为实现掩码生成电路,该掩码生成电路被配置为基于输入数据的对应的索引来生成掩码值。
在另一示例中,可配置互连结构和逻辑块还被配置为实现掩码选择多路复用器,该掩码选择多路复用器被配置为输出掩码值以控制掩码多路复用器,其中掩码选择多路复用器被配置为基于掩码选择输入向掩码多路复用器输出:从掩码生成电路接收到的掩码值;或者被存储在FPGA的设备存储器中的外部掩码数据。
在一些示例中,掩码生成电路可以被配置为根据三角掩码模式来生成掩码值。在一些示例中,掩码生成电路被配置为根据被选自以下各项中的至少一个的掩码模式来生成掩码值:上三角掩码;下三角掩码;块上三角掩码;块下三角掩码;或者交替掩码。
在一些示例中,掩码生成电路可以被配置为接收一个或多个掩码参数,以及掩码生成电路被配置为基于该一个或多个掩码参数来选择掩码模式。
在一些示例中,数据掩码电路的可配置互连结构和逻辑块还被配置为将所掩码的数据提供给SoftMax函数,其中数据值和替代值是浮点数据格式,以及其中替代值是大负数,该大负数足够大使得将大负数提供给SoftMax函数的结果在浮点数据格式中舍入到零。
在本技术的一些示例中,FPGA连接到计算机系统,该计算机系统被配置为基于多个训练数据来训练机器学习模型,以及数据掩码电路被配置为对作为输入数据而被提供给数据掩码电路的训练数据来掩码以加速训练机器学习模型。
在一个方面中,本技术涉及一种计算机存储介质,其存储配置文件,该配置文件指定包括可配置互连结构和多个逻辑块的现场可编程门阵列(FPGA)的配置,其中基于配置文件配置的FPGA包括由可配置互连结构连接的实现数据掩码电路的逻辑块,该数据掩码电路被配置为:接收输入数据,该输入数据包括输入数据在多个索引处的数据值;使用掩码多路复用器在数据值中的数据值和替代值之间进行选择以生成所掩码的数据,掩码多路复用器由在与输入数据的索引相对应的索引处的多个掩码值中的掩码值控制;以及输出所掩码的数据。
在一个示例中,配置文件还指定FPGA的可配置互连结构和逻辑块的配置以实现掩码生成电路,该掩码生成电路被配置为基于输入数据的对应的索引来生成掩码值。
在一些示例中,配置文件还指定FPGA的可配置互连结构和逻辑块的配置以实现掩码选择多路复用器,该掩码选择多路复用器被配置为输出掩码值以控制掩码多路复用器,其中掩码选择多路复用器被配置为基于掩码选择输入来输出:从掩码生成电路接收到的掩码值;或者被存储在FPGA的设备存储器中的外部掩码数据。
在一些示例中,配置文件还指定FPGA的可配置互连结构和逻辑块的配置以将掩码生成电路配置为根据三角掩码模式来生成掩码值。
在一些示例中,配置文件还指定FPGA的可配置互连结构和逻辑块的配置以将掩码生成电路配置为根据被选自以下各项中的至少一个的掩码模式来生成掩码值:上三角掩码;下三角掩码;块上三角掩码;块下三角掩码;或者交替掩码。
在一些示例中,配置文件还指定FPGA的可配置互连结构和逻辑块的配置以将掩码生成电路配置为接收一个或多个掩码参数以及使掩码生成电路基于该一个或多个掩码参数来选择掩码模式。
根据权利要求9所述的计算机存储介质,其中该配置文件还指定该FPGA的可配置互连结构和逻辑块的配置以将该数据掩码电路配置为将所掩码的数据提供给SoftMax函数,其中数据值和替代值是浮点数据格式,以及其中替代值是大负数,大负数足够大使得将大负数提供给SoftMax函数的结果在浮点数据格式中舍入到零。
在一个方面中,本技术涉及一种用于在包括连接多个逻辑块的可配置互连结构的现场可编程门阵列(FPGA)中加速计算的方法,该方法包括:在FPGA的逻辑块和可配置互连结构中实现的数据掩码电路处接收输入数据,该输入数据包括输入数据在多个索引处的数据值;由数据掩码电路的掩码多路复用器在数据值中的数据值和替代值之间进行选择以生成所掩码的数据,该掩码多路复用器由在与输入数据的索引相对应的索引处的多个掩码值中的掩码值控制;以及输出所掩码的数据。
在一个示例中,可配置互连结构和逻辑块还被配置为实现掩码生成电路,该方法还包括:基于输入数据的相对应的索引在FPGA的掩码生成电路内生成掩码值。
在一些示例中,可配置互连结构和逻辑块还被配置为实现掩码选择多路复用器,该掩码选择多路复用器被配置为输出掩码值以控制掩码多路复用器,其中该方法还包括由掩码选择多路复用器基于掩码选择输入向掩码多路复用器输出:从掩码生成电路接收到的掩码值;或者被存储在FPGA的设备存储器中的外部掩码数据。
在一些示例中,可配置互连结构和逻辑块还被配置为将来自数据掩码电路的所掩码的数据提供给SoftMax函数,其中数据值和替代值是浮点数据格式,以及其中替代值是大负数,该大负数足够大使得将大负数提供给SoftMax函数的结果在浮点数据格式中舍入到零。
在一些示例中,该方法还包括训练机器学习模型,包括由包括处理器、存储器和FPGA的计算设备执行的机器学习模型训练应用接收标记的训练数据;由机器学习模型训练应用将标记的训练数据提供给机器学习模型以生成输入数据;由机器学习模型训练应用将输入数据提供给在FPGA中实现的数据掩码电路以生成所掩码的数据;基于由机器学习模型响应于标记的训练数据计算的所掩码的数据来计算机器学习模型的多个输出分数;基于输出分数来更新机器学习模型;以及将更新后的机器学习模型输出为训练后的机器学习模型。
例如,上面参考根据本发明的各方面的方法、系统和计算机程序产品的框图和/或操作图示描述了本发明的各方面。框中标注的功能/动作可以不按如任何流程图所示的顺序发生。例如,取决于所涉及的功能/动作,连续示出的两个框实际上可以基本上同时执行,或者这些框有时可以以相反的顺序执行。此外,如本文和权利要求中所使用的,短语“元素A、元素B或元素C中的至少一个”旨在传达以下各项中的任一种:元素A、元素B、元素C、元素A和B、元素A和C、元素B和C、以及元素A、B和C。
本申请中提供的一个或多个示例的描述和说明并不旨在以任何方式限制或约束如要求保护的本发明的范围。
本申请中提供的方面、示例和细节被认为足以传达所有权并使得其他人能够制造和使用要求保护的发明的最佳模式。所要求保护的发明不应被解释为限制于本申请中提供的任何方面、示例或细节。无论是以组合还是单独地示出和描述,不同的特征(结构和方法两者)旨在被选择性地包括或省略以产生具有特定特征集的示例。已经提供了本申请的描述和说明,本领域技术人员可以设想不偏离要求保护的发明的更宽泛范围的本申请中体现的总体发明构思的更宽泛方面的精神内的变化、修改和替代示例。
- 一种用于确定大数据存储系统的数据平衡性的方法及系统
- 用于水下密度采集设备的数据处理系统及其数据处理方法
- 用于区块链网络系统的数据处理方法和数据处理装置
- 用于经由数据传输系统传输视设备而定的数据的方法
- 用于带内数据掩码比特传输的系统、方法和装置
- 用于带内数据掩码比特传输的系统、方法和装置