一种主题门户网站爬虫方法
文献发布时间:2023-06-19 10:51:07
技术领域
本发明涉及网络信息抓取技术领域,具体为一种主题门户网站爬虫方法。
背景技术
在互联网的开放环境下,共享的网络信息爆发式增长,给人们提供了大量的信息资源,然而这也带来了巨大的挑战,信息的种类非常多,有效地搜集和利用好这些信息显得越来越困难。此时,搜索引擎开始诞生,通过关键词搜索网络信息,极大地方便了人们有效地搜索信息,能够满足大部分的信息需求。然而,搜索引擎大部分以水平搜索为主,这种方式的主要缺点是返回的搜索结果准确率低下,并且含有大量的干扰信息。随着信息多元化进程的发展,这种搜索策略已不能满足用户的特定需求。
为此,网络主题爬虫应运而生,网络主题爬虫只针对所需求的信息进行抓取,不仅可以极大地降低时间消耗,还能够及时获取到更新的内容,并且所获取的信息会更加精确和全面,大大地减少了干扰信息,但现在网络主题爬虫系统需要解决的一个重要问题是防止包含同样内容的网页被多次下载,避免浪费大量cpu资源,减轻数据库存取带来的负荷。
发明内容
为解决上述现在网络主题爬虫系统一次抓取包含同样内容的网页被多次下载,浪费大量cpu资源,对数据库存取会增加负荷的问题,本发明针对主题门户网站爬虫系统中的内容抓取和增量更新两个环节的进行去重,提出了一种高效的去重策略,在性能以及可扩展性上优于传统方法。
本发明为实现上述目的所采用的技术方案是:一种主题门户网站爬虫方法,包括
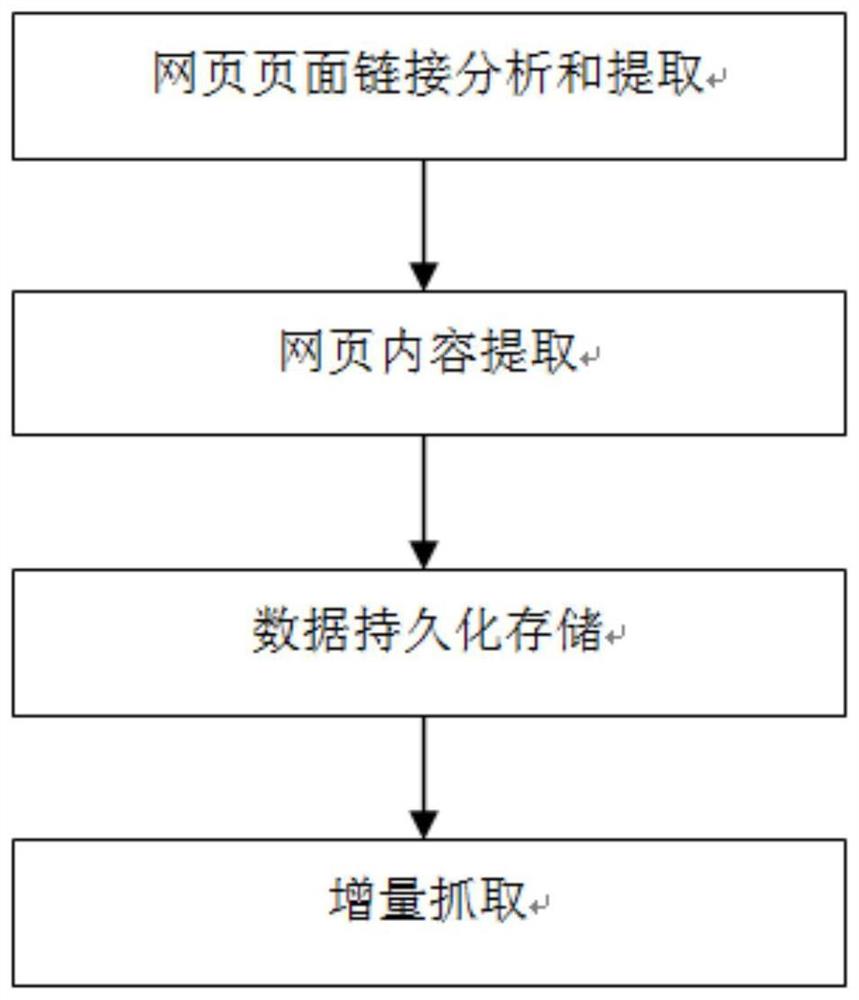
网页页面链接分析和提取:根据主题网站设计正则表达式以识别出父页和子页链接,并且判断该页面是否属于主题网站内的链接,只对主题网站内的链接进行处理,若识别出为父页,则对父页中的子页链接进行提取,若识别出为子页,则对子页的正文内容进行提取;
网页内容提取:对子页链接下的正文内容进行提取,并将提取的正文内容存储到一个静态类中,成功抽取后即退出;
数据持久化存储:用于存储从每个子页链接中提取的正文内容;
增量抓取:针对主题网站中的更新内容进行抓取,每次增量更新时,重新提取主题网站首页的链接,只对新链接进行处理。
进一步的,所述网页内容提取中,对于网页下找到的所有正文格式,先找到一种格式,从所有页面提取到正文,再存入数据库中,此时不同格式的正文字段在数据库中即为空,再反向从空正文字符的链接中查看其格式,编写对应的提取代码,再循环多次,即可找到所有的格式,从而设计对应的xpath语法,将所有xpath格式保存在一个list中,通过遍历list进行正文内容提取,成功提取后即退出循环,并将该提取过程定义为一个静态类。
进一步的,所述增量抓取中,通过输入种子链接,判断该种子链接是否为父页,如果是父页,则从父页中提取新的子页链接放入待抓取队列中,程序结束,之后进行网页内容抓取;如果不是父页,则是子页,此时判断子页链接的正文内容是否已经提取,如果已经提取,则结束程序,如果没有提取,则将链接放入待抓取队列中,对链接下的正文内容进行提取,提取后的内容进行数据持久化存储,程序结束。
进一步的,所述增量抓取中,通过布隆过滤器来筛选判断增量更新的网址链接。
进一步的,所述布隆过滤器中采用BitSet函数和hash函数配合使用对增量更新的网址链接进行判断,其中将BitSet函数定义为静态私有变量。
进一步的,所述BitSet函数中,将Path作为BitSet加载保存的路径;getBitSet方法从Path路径中加载并反序列化得到BitSet对象,若没有可以加载的对象,则返回false,重新生成新的实例,最后直接调用对象流将其序列化保存;hash函数针对网页链接中的每个字符都进行计算,对每个结果进行相加后,再与BitSet的长度进行取模,可以使hash分布更均匀。
进一步的,所述hash函数先选择一个种子,种子选择为质数,布隆过滤器中一共设置8个hash值,传入8个不同的hash种子,就能获取不同的hash值;当一个链接传入,调用布隆过滤器的add(String value)方法,先判断value值是否为空,非空则再调用addValue(String value)方法,并将addValue定义为静态变量。
进一步的,所述布隆过滤器中采用contains方法判断是否存在相同的网址链接,传入一个链接时,调用所有的hash方法进行判断,如果有一个hash算法的值不为false,则可以确定此url没有重复,再进行内容的提取。
进一步的,所述数据持久化存储中,网页信息抽取结束后,根据需要,可以持久化保存在数据库中,也可以保存成不同的格式,利用page.putFiled(String key,Objectfield)方法来对提取到的正文内容进行存储。
进一步的,所述网页页面链接分析和提取的正则表达式中,用来判断提取的链接是父页还是子页的正则表达式为:http://www\\.(.*\\.)?agri\\.cn/.*(htm)$;用来提取包含所有父页和子页的正则表达式为:http://www\\.(.*\\.)?agri\\.cn/.+,并可以根据此正则表达式判断是否属于主题网站内的链接。
本发明的技术效果和优点:
(1)针对某一主题或者网站采用父页和子页的链接进行提取的方式,实现对信息进行垂直搜索;
(2)能够持续快速感知到网站的更新,并进行下载处理;
(3)只提取有效的信息如图片、网页内容进行整理、保存,方便对信息进行分析;
(4)在网页内容提取中,对于网页下找到的所有正文格式,先找到一种格式,从所有页面提取到正文,再存入数据库中,此时不同格式的正文字段在数据库中即为空,再反向从空正文字符的链接中查看其格式,编写对应的提取代码,再循环多次,即可找到所有的格式,从而设计对应的xpath语法,将所有xpath格式保存在一个list中,通过遍历list进行正文内容提取,成功提取后即退出循环,并将该提取过程定义为一个静态类,相比以往常用的方法更加高效、简便,而且获取的内容几乎无重复;
(5)在增量抓取中,通过输入种子链接,判断该种子链接是否为父页,如果是父页,则从父页中提取新的子页链接放入待抓取队列中,程序结束,之后进行网页内容抓取;如果不是父页,则是子页,此时判断子页链接的正文内容是否已经提取,如果已经提取,则结束程序,如果没有提取,则将链接放入待抓取队列中,对链接下的正文内容进行提取,提取后的内容进行数据持久化存储,程序结束,通过此方法可以快速对增量更新进行提取,并且可以有效防止重复提取;
(6)本发明将两种Heritrix框架与Webmagic框架进行结合使用,为了便于部署和使用,采用了Spring与Hibernate技术相结合,Spring中主要使用了其IOC模块和MVC模块,通过与Hibernate进行整合,使系统具备一定的灵活性;
(7)通过布隆过滤器中的hash函数对链接的每个字符都进行计算,然后对结果进行相加后,再与BitSet的长度进行取模,这样可以使hash分布更均匀,并且选取的hash种子能够判断url是否重复,实现高效去重;
通过本爬虫程序获取的页面,几乎无重复,并且能够精确获取到所需的主题,并且可有效防止包含同样内容的网页被多次下载,避免浪费大量cpu资源,减轻数据库存取带来的负荷。
附图说明
图1为本发明的网页内容抓取流程图;
图2为本发明的增量抓取方法流程图;
图3为本发明的一个实施例中网页内容抓取结果展示;
图4为本发明的一个实施例中进行网页查询展示;
图5为本发明的一个实施例中通过输入的网址抓取到的内容显示。
具体实施方式
下面结合附图与实施例对本发明进行详细说明。
实施例:
如图1-5所示,一种主题门户网站爬虫方法,包括
网页页面链接分析和提取:根据主题网站设计正则表达式以识别出父页和子页链接,并且判断该页面是否属于主题网站内的链接,只对主题网站内的链接进行处理,若识别出为父页,则对父页中的子页链接进行提取,若识别出为子页,则对子页的正文内容进行提取,用来判断提取的链接是父页还是子页的正则表达式为:http://www\\.(.*\\.)?agri\\.cn/.*(htm)$;用来提取包含所有父页和子页的正则表达式为:http://www\\.(.*\\.)?agri\\.cn/.+,并可以根据此正则表达式判断是否属于主题网站内的链接;
网页内容提取:对子页链接下的正文内容进行提取,并将提取的正文内容存储到一个静态类中,成功抽取后即退出,网页内容提取中,对于网页下找到的所有正文格式,先找到一种格式,从所有页面提取到正文,再存入数据库中,此时不同格式的正文字段在数据库中即为空,再反向从空正文字符的链接中查看其格式,编写对应的提取代码,再循环多次,即可找到所有的格式,从而设计对应的xpath语法,将所有xpath格式保存在一个list中,通过遍历list进行正文内容提取,成功提取后即退出循环,并将该提取过程定义为一个静态类;
数据持久化存储:用于存储从每个子页链接中提取的正文内容,网页信息抽取结束后,根据需要,可以持久化保存在数据库中,也可以保存成不同的格式,利用page.putFiled(String key,Object field)方法来对提取到的正文内容进行存储;
增量抓取:针对主题网站中的更新内容进行抓取,每次增量更新时,重新提取主题网站首页的链接,只对新链接进行处理,增量抓取中,通过输入种子链接,判断该种子链接是否为父页,如果是父页,则从父页中提取新的子页链接放入待抓取队列中,程序结束,之后进行网页内容抓取;如果不是父页,则是子页,此时判断子页链接的正文内容是否已经提取,如果已经提取,则结束程序,如果没有提取,则将链接放入待抓取队列中,对链接下的正文内容进行提取,提取后的内容进行数据持久化存储,程序结束;通过布隆过滤器来筛选判断增量更新的网址链接,布隆过滤器中采用BitSet函数和hash函数配合使用对增量更新的网址链接进行判断,其中将BitSet函数定义为静态私有变量,BitSet函数中,将Path作为BitSet加载保存的路径;getBitSet方法从Path路径中加载并反序列化得到BitSet对象,若没有可以加载的对象,则返回false,重新生成新的实例,最后直接调用对象流将其序列化保存;hash函数针对网页链接中的每个字符都进行计算,对每个结果进行相加后,再与BitSet的长度进行取模,可以使hash分布更均匀,hash函数先选择一个种子,种子选择为质数,布隆过滤器中一共设置8个hash值,传入8个不同的hash种子,就能获取不同的hash值;当一个链接传入,调用布隆过滤器的add(String value)方法,先判断value值是否为空,非空则再调用addValue(String value)方法,并将addValue定义为静态变量,布隆过滤器中采用contains方法判断是否存在相同的网址链接,传入一个链接时,调用所有的hash方法进行判断,如果有一个hash算法的值不为false,则可以确定此url没有重复,再进行内容的提取。
以爬取“中国农业信息网”为例,这是一个农业综合门户网站,网站分类众多,本爬虫针对三个板块爬取了数据,经过文本聚类聚成了三类,准确率较高,证明本爬虫能够对大型门户网站爬取到较为干净的数据。
(1)父页和子页区分
中国农业信息网父页的链接命名以英文字母加“/”,如市场分类的链接为http://www.agri.cn/V20/SC/,而子页的链接则是数字加“.htm”后缀。
链接命名规则确定后,可以通过正则表达式识别出父页和子页链接,由于Webmagic运用多线程抓取,因此正则表达式应该用final修饰,保证线程安全。
下面是匹配链接的正则表达式:
public static final String URL_POST="http://www\\.(.*\\.)?agri\\.cn/.*(htm)$";
public static final String URL="http://www\\.(.*\\.)?agri\\.cn/.+";
URL_POST表示匹配以“http://www.agri.cn/”开头,以“htm”为后缀的代码,其中的“(.*\\.)?”,是为了匹配“http://www.flower.agri.cn/”类似的链接。
URL则是提取所有属于中国农业信息网的链接,包含父页和子页,可以根据此正则表达式准确地判断是否属于站内链接,防止爬虫程序抓取到不相关的网页,陷入互联网的黑洞中。
AgriInfoTest实现PageProcessor接口,实现了public void process(Pagepage){}方法,Page对象包含了html页面代码,用于从中提取有效信息;Page.getUrl()方法返回页面的链接,此时需要判断页面是父页还是子页,调用java正则表达式:
page.getUrl().regex(URL_POST).match();
若是子页,则可以进行内容提取,对于父页将所有链接提取出来后,不需要提取信息直接跳过即过,调用page.setSkip(true),可以将当前页面跳过,不进行持久化处理。
(2)网页内容提取
获取网页的所有格式后,发现中国农业信息网里面的正文格式一共有8类,其中的xpath语法如下:
①//div[@id=\"TRS_AUTOADD\"]/allText()
②//div[@class=\"nr_m16\"]/allText()
③//td[@class=\"hui_14-1\"]/text()
④//div[@class=\"TRS_Editor\"]/allText()
⑤//td[@class=\"hui_14-1\"]/p/allText()
⑥//div[@class=\"de_tag_con\"]/p/allText()
⑦//div[@class=\"TRS_PreAppend\"]/p/allText()
⑧//table/allText()
由于里面的文本格式有重叠,有可能同时匹配到两段xpath语法,如格式③和⑤,若调用xpath的或运算,抓取的正文即会重复成两段;此时需要调用算法去判断正文是否重复,重复了几次,然后将正文的重复部分去除。
为了避免多次判断提取结果,在当前格式没有匹配成功才进入一下个格式,而不是每次都判断所有格式有没有抓取成功,因此可以运用多重嵌套if来判断。由于xpath提取后,返回List
因此,将所有的xpath格式事先保存在一个list中,通过遍历list进行正文提取,成功抽取时即退出循环,思路非常简单,性能和扩展性都非常高。处理代码如下:
static静态语句块是在加载类时候,将contentList进行初始化,静态语句块只会在类加载时执行一次,可以避免每次使用都要初始化contentList。contentList设计为static对象,可以给类的所有的实例共用,里面的String对象可以一直保存,不用在每次调用时都重新分配,节省了空间和时间;getContent方法传入page对象,由于前七种格式类型一样,因此可以直接在循环中遍历提取正文,一旦提取成功,立即返回,当前七种格式都不对时,需要调用第8种格式进行相应的处理,再返回结果,性能上升,重复率一直下降到0。
(3)数据持久化存储
网页所有信息提取完毕后,在page调用putFiled(key,value)保存相关数据,其结构相当于一个map,之后可以通过ResultItems在pipeline中获取,进行持久化保存。
(4)增量抓取
由于网站的内容是不断地在更新,为了能及时获取到更新的数据,需要设计好增量抓取策略。本爬虫的增量抓取要求,即使在程序关闭后,再次爬取数据时,也能够判断出哪些已经抓取,哪些还未抓取,对一般的网站进行爬虫时,通过计算首页的MD5(MessageDigest Algorithm)值有没有变化,即可判断网页是否有更新,但是对于大型综合网站,不适合该方法,单纯计算首页MD5只能判断首页是否有变化,但是中国农业信息网下的分类网站下是否有更新,却不能感知到,只能计算所有的分类页的MD5再进行比对,此时需要将所有的首页和其MD5值单独保存起来,数据量大,非常耗时,有效的策略应该是,将所有的子页面保存起来,每次增量更新时,重新提取首页的链接,只对新链接进行处理即可。
基于url去重策略的分析,采用布隆过滤器来过滤url,布隆过滤器的核心是其中的位数组以及相应的hash函数,java的BitSet是一个很典型的位数组,它可以按需申请所需的位向量,每一个位都是一个boolean值,默认情况下,所有的位值都为false。针对农业信息网,它必须有一个专有的BitSet,不允许替换,能够提供保存和加载的方法,以便多次使用,此时需要使用单例模式来保证系统只有一个该实例存在。
单例模式有多种实现方式,懒汉式通过使用双重if判断,可以保证线程安全以及高效率,饿汉式通过静态语句块直接获取,在类加载的时候直接拿到类的实例,可以保证只有一个实例,代码结构简洁,相比懒汉式加载,它的缺点是在一开始还没使用时会占用系统内存,而在爬虫系统上,布隆过滤器是在程序启动时就会用到的,所以饿汉式和懒汉式就没有太多的区别,为了方便,直接采用懒汉式加载。
BitSet设计为静态私有变量,不提供对外的getter和setter方法,可以保证不被外部类修改,确保唯一性;Path是BitSet加载保存的路径,在web项目启动时,必须能够获取到项目的部署路径,才能根据需要保存在相应的位置;Spring框架允许在web.xml中配置webAppRootKey,指定相应的key,便可以调用System.getProperty(key)方法中获取到项目路径,再选取保存的位置;getBitSet方法从path路径中加载并反序列化得到BitSet对象,若没有可以加载的对象,则返回false,重新生成新的实例,其保存方法简单,直接调用java的对象流将其序列化保存即可。
url在java中以String形式呈现,因此hash函数针对其中的每个字符都进行计算,然后对结果进行相加后,再与BitSet的长度进行取模,这样可以使hash分布更均匀。
hash函数先选择一个种子seed,这个种子通常为质数,此布隆过滤器选择用8个hash值,只需传入8个不同的hash种子,就能获取不同的hash值,随机选择的种子为3,5,7,11,13,31,37,61。因为位数组的长度为2^25,是2的整数次幂,cpa即为长度,“(cap-1)&result”此表达式通过与运算,能够快速对result与cap取模。
当一个链接传入,调用过滤器的add(String value)方法,它先判断value是否为空,非空则调用addValue(String value)方法,其实现如下:
方法声明为static,可以在不实例对象的情况下进行调用,方便作为工具类使用;func是hash算法的数组,对象SimpleHash包含了hash算法和hash种子,封装成类方便统一管理,使得代码清晰整洁;过滤器的contains方法则是判断是否有相同的url存在,传入一个链接时,调用所有的hash方法进行判断,如果有一个hash算法的值不为false,则可以确定此url没有重复。
如图3-图5所示,经过程序运行抓取,数据库的网页已达数十万条,图3是其中的一些展示,每个段落包含一个网页的主要内容,鼠标经过会显示相应的标题以及作者,点击段落会跳转到原链接。
参照下表1,将爬取的网页利用K-means方法进行聚类,发现通过本爬虫程序获取的页面,几乎无重复,并且能够精确获取到所需的主题。
表1:对抓取内容进行文本聚类的内容显示
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 一种主题门户网站爬虫方法
- 一种主题网页爬取方法及主题爬虫系统