基于自监督跨模态感知损失的乐队指挥动作生成方法
文献发布时间:2023-06-19 13:45:04
技术领域
本发明基于自监督跨模态感知损失的乐队指挥动作生成方法涉 及乐队指挥动作生成方法,特别是涉及以音乐为条件控制信号、生成 与之节奏同步且语义相关的指挥动作的乐队指挥动作生成方法,属于 人体动作条件生成领域。
背景技术
指挥是交响乐团的灵魂。自中世纪欧洲教堂唱诗班到二十一世纪 的现代音乐,指挥技术与艺术不断发展,已经成为一门内容丰富的学 科。指挥的肢体语言复杂多变,需要在乐团演奏时实时地传达节拍、 力度、情感、演奏法等多种信息,且同时保持一定的风格与美感。近 年来,随着深度学习算法理论的发展与计算性能的飞速提升,人工智 能领域的学者已经成功地对多种人类艺术进行建模与学习。深度学习 已经能生成包括诗歌艺术、绘画艺术、音乐艺术、舞蹈艺术在内的多 种人类艺术形式。
然而,学界对于指挥艺术的建模研究还比较初步,且主要面向判 别类的任务,例如节拍跟踪、拍式识别、演奏法识别、情感识别等。 对于生成式任务,即音乐驱动的指挥动作生成任务,Wang等人(T. Wang,N.Zheng,Y.Li,Y.-Q.Xu,and H.-Y.Shum,“Learningkernel-based HMMs for dynamic sequence synthesis,”Graph.Model.,vol.65,no.4,Art.no.4,2003.)在2003年提出了首个指挥动作生成方法。随后,几 种基于规则的生成方法陆续被提出,但这些方法无法灵活地学习真实 指挥动作的内在规律,导致生成动作重复性强,多样性差。Dansereau 等人(D.G.Dansereau,N.Brock,and J.R.Cooperstock,“Predicting an Orchestral Conductor’s Baton Movements Using MachineLearning,” Comput.Music.J.,vol.37,no.2,Art.no.2,2013.)在2013年提出了一 种基于机器学习的指挥动作预测方法以应对云合奏中的网络延迟问 题,但该方法仅能向前预测很短的时间,目前,尚没有基于深度学习 的指挥动作生成方法被提出。
感知损失于2016年被Johnson等人提出(J.Johnson,A.Alahi,and L.Fei-Fei,“Perceptual Losses for Real-Time Style Transfer and Super-Resolution,”inComputer Vision–ECCV 2016,Cham,2016,pp. 694–711.),是面向生成任务的一种损失函数。与传统的在样本空间 进行欧式距离度量的或损失不同,感知损失度量的是生成样本与真实 样本在特征空间中的距离。这一特征空间是通过预训练的卷积神经网 络所得到的,该网络也被称为感知损失网络。但是,现有的感知损失 网络都有着各自的局限性。有学者指出,在使用传统的基于ImageNet 预训练VGGNet的感知损失进行图像超分辨率时,会导致出现不自然 的图像细节。类似地,面向低剂量CT去噪问题,在自然场景的图像 分类数据集ImageNet上训练的网络不适合提取CT图像中的语义信息, 因此,也有学者在CT数据集上训练了一个自编码器作为感知损失网 络。本发明与传统的分类任务、判别任务、重建任务不同,将跨模态 的自监督学习任务作为感知损失网络的预训练任务。
发明内容
本发明所要解决的技术问题是:以音乐为条件作为控制信号,如 何生成与之节奏同步且语义相关的乐队指挥动作生成方法的问题。
本发明为解决上述技术问题采用以下技术方案:
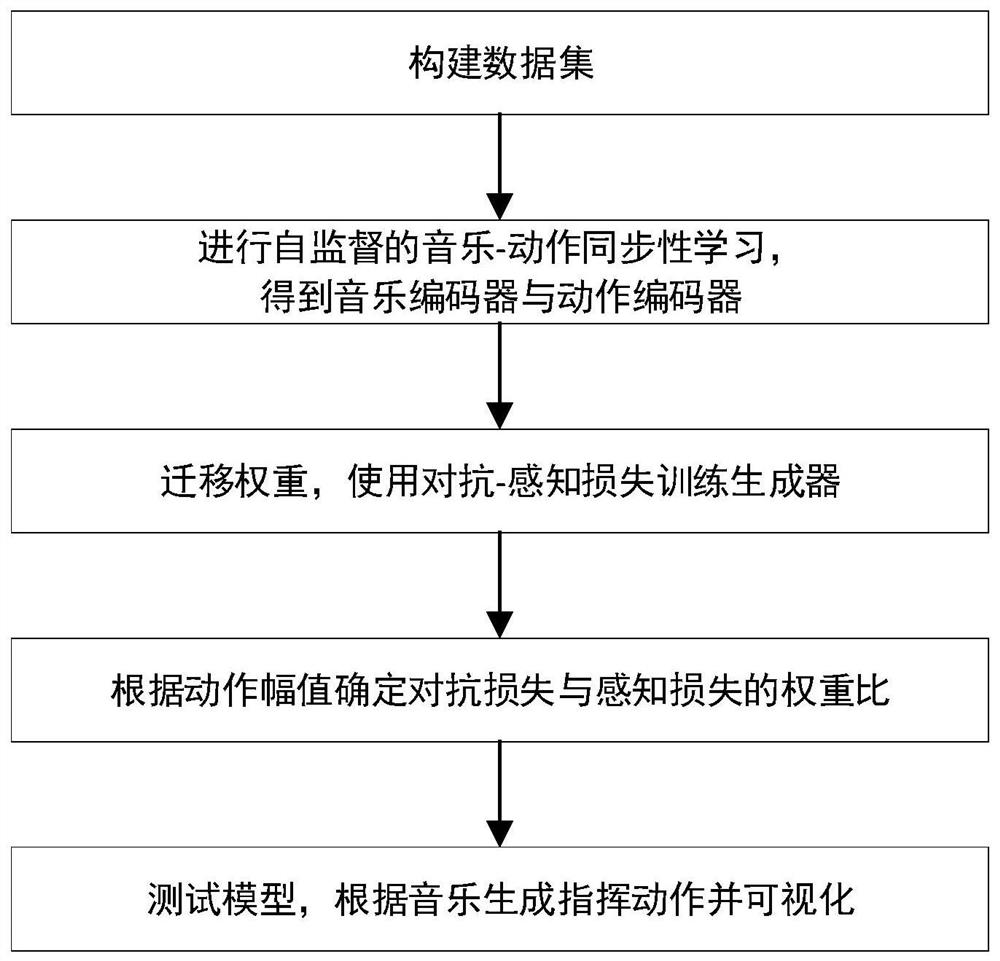
一种基于自监督跨模态感知损失的乐队指挥动作生成方法,包括 如下步骤:
步骤1,构建数据集,提取音乐会演出录像视频中的指挥动作, 并计算对应音乐的梅尔频谱图;
步骤2,进行自监督的音乐-动作同步性学习,训练时自动地采样 同步的正样本对与错位的负样本对,训练带有一个音乐编码器与一个 动作编码器的两分支神经网络模型;
步骤3,将步骤2得到的音乐编码器与动作编码器分别用于为生 成器提取语义特征与计算生成动作的感知损失,使用对抗-感知损失 训练生成器;
步骤4,在开发集上根据生成结果的平均标准差大小确定两项损 失的最佳权重比;
步骤5,使用步骤4中得到的最佳权重比下训练的模型进行实际 应用,从给定音乐中生成指挥动作并可视化。
作为本发明的一种优选方案,所述步骤1的具体过程为:
1-1、指挥动作提取,从网络视频平台中收集音乐会的指挥视角 演出录像指挥动作的视频,在收集到的视频上进行基于迁移学习的指 挥检测,并提取检测到的指挥的2维动作序列。
1-2、音频特征提取,提取视频中对应的梅尔频谱图。
1-3、数据集准备,将提取到的指挥动作与音频特征归一化并处 理成一个N个样本的数据集
作为本发明的一种优选方案,所述步骤2的具体过程为:
2-1、构建神经网络结构。使用一个基于卷积神经网络的音乐编码 器E
2-2、采样正样本对和负样本对。正样本对是同步的音乐和动作序 列,负样本对是不匹配的音乐和动作序列。从同一乐曲中选取负样本, 其错位距离至少为10秒。
2-3、计算交叉熵损失L
2-4、训练模型,使用交叉熵损失与对比损失之和L=L
作为本发明的一种优选方案,所述步骤3的具体过程为:
3-1、构建网络结构,构建一个带有四个模块的网络结构,包括 生成器G,判别器D,以及步骤2中构建的两分支网络中的音乐编码 器E
3-2、初始化网络参数,对生成器G与判别器D进行随机初始化, 将步骤2中训练好的两分支网络的参数迁移至音乐编码器E
3-3、计算对抗-感知损失函数,对抗-感知损失函数包括一项对抗 损失与一项感知损失,其具体定义如下,其中,
3-4、计算判别器的损失函数。其定义如下,其中,第二项为梯 度惩罚(GradientPenalty,GP)项,ω
3-5、训练模型,固定E 作为本发明的一种优选方案,所述步骤4的具体过程为: 4-1、使用不同的权重比λ 4-2、在开发集上测试不同权重比λ 4-3、绘制权重比-标准差曲线,找到生成动作标准差恰好升至真 实动作标准差时的权重比,确定为最佳权重比。 作为本发明的一种优选方案,所述步骤5的具体过程为: 5-1、模型测试,使用步骤5中确定的最佳权重比训练步骤4中 的生成器G,得到生成器G的参数,将音频特征序列输入至生成器G, 得到预测的指挥动作序列。 5-2、可视化,将生成的指挥动作序列可视化,作为本发明的最 终输出结果。 本发明采用以上技术方案与现有的基于规则的生成方法相比,具 有以下技术效果: 1、本发明可以学习音乐与指挥动作之间的内在的高层的语义性 关联,从而生成更加自然、美观、多样、且与音乐同步的指挥动作; 2、本发明提出的自监督跨模态感知损失,可以为生成器提供合 理有效的音乐同步性监督信息,从而避免了传统回归损失过度平滑 (over-smooth)的缺点; 3、本发明将经过跨模态自监督学习的音乐编码器用作为生成器 提供语义特征,可以有效的加快生成器的收敛速度。 附图说明 图1是本发明基于自监督跨模态感知损失的乐队指挥动作生成 方法的算法流程图。 图2是本发明中步骤2与步骤3中设计的网络结构图。 图3是本发明的最终可视化输出效果图。 具体实施方式 下面详细描述本发明的实施方式,所述实施方式的示例在附图中 示出。下面通过参考附图描述的实施方式是示例性的,仅用于解释本 发明,而不能解释为对本发明的限制。 近年来,有许多学者意识到互联网中广泛存在的多模态数据的巨 大价值,并提出了许多跨模态的自监督学习方法。与单模态自监督学 习不同,跨模态的自监督学习中两个模态的特征表示互相指导对方的 学习,能从数据中挖掘到更丰富的信息。感知损失于2016年被 Johnson等人提出,是面向生成任务的一种损失函数。与传统的在样 本空间进行欧式距离度量的或损失不同,感知损失度量的是生成样本 与真实样本在特征空间中的距离。这一特征空间是通过预训练的卷积 神经网络所得到的,该网络也被称为感知损失网络(perceptual loss network)。但是,现有的感知损失网络都有着各自的局限性。因此, 有必要探寻一种新的感知损失网络预训练方式,提取高质量的特征以 完成准确的监督约束。基于这一想法,本发明提出一种基于自监督跨 模态感知损失的乐队指挥动作生成方法。 结合图1所示,本发明基于自监督跨模态感知损失的乐队指挥动 作生成方法,包括以下步骤: 步骤1,构建数据集,提取音乐会演出录像视频中的指挥动作, 并计算对应音乐的梅尔频谱图; 步骤2,进行自监督的音乐-动作同步性学习,训练时自动地采样 同步的正样本对与错位的负样本对,训练带有一个音乐编码器与一个 动作编码器的两分支神经网络模型; 步骤3,将步骤2得到的音乐编码器与动作编码器分别用于为生 成器提取语义特征与计算生成动作的感知损失,使用对抗-感知损失 训练生成器; 步骤4,在开发集上根据生成结果的平均标准差大小确定两项损 失的最佳权重比; 步骤5,使用步骤4中得到的最佳权重比下训练的模型进行实际 应用,从给定音乐中生成指挥动作并可视化。 1-1、指挥动作提取。从网络视频平台中收集音乐会的指挥视角演 出录像指挥动作的视频,在收集到的视频上进行基于迁移学习的指挥 检测,并提取检测到的指挥的2维动作序列。 1-2、音频特征提取。提取视频中对应的梅尔频谱图。 1-3、数据集准备。将提取到的指挥动作与音频特征归一化并处理 成一个N个样本的数据集 2-1、构建神经网络结构。结合图2所示,使用一个基于卷积神经 网络的音乐编码器E 2-2、采样正样本对和负样本对。正样本对是同步的音乐和动作序 列,负样本对是不匹配的音乐和动作序列。从同一乐曲中选取负样本, 其错位距离至少为10秒。 2-3、计算交叉熵损失L
2-4、训练模型。使用交叉熵损失与对比损失之和L=L 3-1、构建网络结构。结合图2所示,构建一个带有四个模块的 网络结构,包括生成器G,判别器D,以及步骤2中构建的两分支网 络中的音乐编码器E 3-2、初始化网络参数。对生成器G与判别器D进行随机初始化, 结合图2所示,将步骤2中训练好的两分支网络的参数迁移至音乐编 码器E 3-3、计算对抗-感知损失函数。对抗-感知损失函数包括一项对抗 损失与一项感知损失,其具体定义如下,其中,
3-4、计算判别器的损失函数。其定义如下,其中,第二项为梯 度惩罚(GradientPenalty,GP)项,ω
3-5、训练模型。固定E 4-1、使用不同的权重比λ 4-2、在开发集上测试不同权重比λ 4-3、绘制权重比-标准差曲线,找到生成动作标准差恰好升至真 实动作标准差时的权重比,确定为最佳权重比。 5-1、模型测试。使用步骤5中确定的最佳权重比训练步骤4中 的生成器G,得到生成器G的参数,将音频特征序列输入至生成器G, 得到预测的指挥动作序列。 5-2、可视化。结合图3所示,将生成的指挥动作序列可视化, 作为本发明的最终输出结果。与现有的基于规则的生成方法相比,本 发明专利生成的方法更加灵活,多样,美观。 以上实施例仅为说明本发明的技术思想,不能以此限定本发明的 保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做 的任何改动,均落入本发明保护范围之内。