一种基于自监督对比学习的车辆信息识别方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及车辆图像识别技术领域,尤其是涉及一种基于自监督对比学习的车辆信息识别方法。
背景技术
随着人们生活水平的提高,极大地提高了家庭以及个人汽车拥有量,也使得交通事故、车辆违法等问题日益突出。如何实现在多个镜头下对统一车辆实施精准识别、定位成为了当下急需解决的一类型问题。通过深度学习算法的训练识别是一种解决方式,但是在训练目标检测模型时,由人工标注数据的方法具有成本高、耗时长等缺点,相较于不断产生的庞大数据,由人工对数据进行注释进而利用某类监督学习算法进行训练的方式显得尤为奢侈。在这种情况下自监督学习算法具有明显优势,利用自监督学习算法,可以在保证一定准确率的前提下,免去繁琐而又昂贵的人工标注数据阶段。在现有的自监督学习中,对比学习方法框架已经成为主流。通过对源进行数据增强,形成近似源,在两种源目标之间进行比对,通过缩小相似目标,扩大相异目标之间的距离,从而学得数据的表征。这种表征往往自带监督特征,可以达到标签数据监督学习的效果。但是对比学习对数据进行增强形成新的数据对时,会出现不可避免的竞争性数据对。例如对一张图片进行裁剪等常见操作,当背景被裁剪下来后,会与包含目标对象的图像形成竞争性关系。这会极大地影响算法的识别结果的准确性。
在中国专利文献上公开的“一种基于对比学习的文本识别方法与系统”,其公开号为CN113920296B,公开日期为2022-07-15,包括无标签的文本图像样本,对其中每个样本进行数据增强输入卷积网络进行识别训练生成识别模型,再基于所述识别模型构建基本编码器来计算并输出特征序列;将所述特征序列输入实例映射函数生成对应的实例再映射为多个子实例,将所有的子实例作为对比损失函数中的子元素进行对比学习,将结果反馈到所述卷积网络用于更新所述卷积网络;获取包含文本信息的有标签的文本图像样本输入所述基本编码器,对所述卷积网络的参数进行调节直到所述识别模型收敛。该技术基于自监督对比学习的方法进行建模,但是在操作过程中是指单纯地对数据进行增强形成数据对,无法避免竞争性数据对的出现,影响最终识别结果效果和准确性。
发明内容
本发明是为了克服现有技术采用自监督对比学习的识别方法中进行数据增强形成新数据对时,会出现竞争性数据对影响最终识别结果的准确性的问题,提供了一种基于自监督对比学习的车辆信息识别方法,在识别模型中的特征空间内增加了进行数据增强后的图片特征融合过程,将竞争性特征关联到一起,用于形成新的特征,从而避免了竞争性数据对的出现,提高了识别效果和准确性。
为了实现上述目的,本发明采用以下技术方案:
一种基于自监督对比学习的车辆信息识别方法,包括:
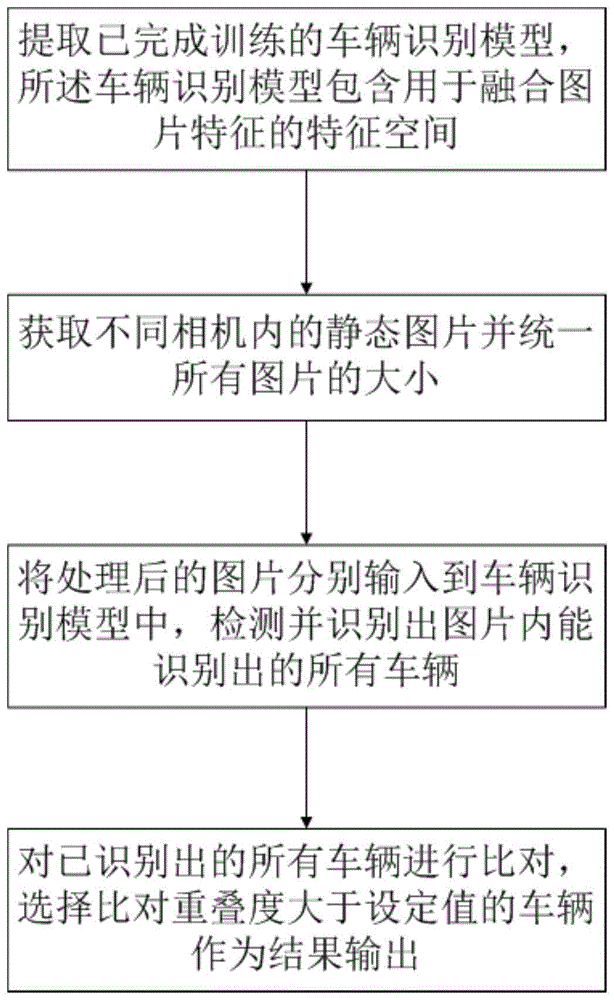
提取已完成训练的车辆识别模型,所述车辆识别模型包含用于融合图片特征的特征空间;
获取不同相机内的静态图片并统一所有图片的大小;
将处理后的图片分别输入到车辆识别模型中,检测并识别出图片内能识别出的所有车辆;对已识别出的所有车辆进行比对,选择比对重叠度大于设定值的车辆作为结果输出。
本发明中自监督学习是深度学习训练模型的一种方式,自监督学习在处理下游任务的时候,可以不需要数据辅助标签的作用,分为生成式模型和判别式模型两种,其中对比学习是最经典的判别式模型;对比学习通过数据增强技术,对同出一源的图片对进行比对,学习到图片中包含的特征;其分为两个阶段,第一阶段叫做pretext,是人为手工设计的,用来学习到数据中包含的监督性信息,本发明中使分类任务作为pretext,数据集采用ImageNet1K;第二阶段是下游任务阶段,在本发明中用来实现对车辆的目标检测等功能;在实际的车辆照片获取中,车辆行驶过程中多个路口的不同相机获取的是针对同一车辆的不同角度的照片,同时照片中也会包含不止一辆车,将这些照片都输入模型中进行识别,将识别后对比的重叠度大于设定值的车辆认为是同一辆车,从而完成车辆的识别。
作为优选,所述车辆识别模型的训练过程包括:
构建包括像素空间、特征空间和损失函数的backbone骨干网络;
利用ImageNet1K数据集中的图片对backbone进行预训练;
选择图片img在像素空间内进行正相关增强处理,得到正图片对img1和img2;
对正图片对的两张图片分别进行编码得到隐向量表示latent
在特征空间内对图片特征latent
利用历史数据集对backbone+FasterRCNN模型进行迭代训练,得到最终的车辆识别模型,FasterRCNN为检测头。
本发明中的识别模型中将前半部分分类网络迁移用作特征提取器(即backbone骨干网络),后半部分的网络做为检测头(即FasterRCNN),从提取的特征中检测出目标的位置和类别;模型采用自监督学习下的对比学习方式进行训练,不需要额外的标注数据,节省了数据标注和存储成本;同时增加了解码器,用于辅助模型更好地辨别出小物体;ImageNet1K数据集是现有的,包括有1000个不同图像类别,共有1500万张带有类别标注的高质量数据集;历史数据集则是根据实际的车辆识别需求,对视频进行帧提取后形成的包含车辆信息的图片数据集,FasterRCNN作为检测头是现有技术,可以通过Detectron2这个库进行调用。
作为优选,所述在像素空间内进行正相关增强处理的过程包括随机裁剪、颜色抖动、灰度缩放、高斯干扰和随机水平翻转中的至少三种。
本发明中对图片进行正相关增强处理的目的在于增加数据的多样性,还可以有平移变换、对比度变换和旋转或反射变换等方式,从而得到两张正图片对进行后续的特征提取和融合操作。
作为优选,所述对图片特征latent
高斯熔断混合为latent
随机替换融合为latent
交叉融合为new=rate
其中latent
本发明中对数据进行增强形成新的数据对时,会出现竞争性数据对影响算法的最终结果,因此在特征空间中有选择的混合增强后图片对形成的特征,将竞争性特征关联到一起,用于形成新的特征来避免该问题的出现;高斯熔断混合是在原有基础上添加一个包含熔断系数的高斯偏移量;随机替换融合中random
作为优选,所述对正图片对的两张图片分别进行编码的过程为:
将图片分割成图像块,构建16×16的序列化子图序列,经过位置编码后,得到图片的序列化令牌;对该令牌根据位置进行随机掩码,保存被掩码到的位置作为掩码令牌,将未被掩码的序列化令牌输入到编码器中,对令牌进行编码,得到隐向量表示。
本发明中在backbone骨干网络中设置有两个编码器,第一编码器对图片img1进行编码得到latent
作为优选,在特征空间中对图片特征latent
本发明中将编码过程中保存的掩码令牌和经过融合后的特征new进行结合恢复图片的令牌,以此作为解码器的输入得到最终的输出结果;相比于现有技术中的对比学习很容易忽略小物体形成的表征特征的问题,通过解码器将特征空间中的特征重新还原成像素空间中的特征,可以更好地识别出小物体。
作为优选,所述车辆识别模型的训练过程还包括根据损失函数对模型进行优化的过程,所述损失函数包括对比损失和重建损失,
对比损失为:
重建损失为:
/>
其中q
本发明中对于损失函数是通过重建损失和对比损失相结合的方式进行构建的,相比于现有的对比学习过程中只用到了对比损失用来最小化相似图片对、最大化相异图片对,从而容易注重大目标而忽略小目标的问题;本发明不仅通过对比损失不断更新模型的参数使得模型收敛,同时也采用了重建损失,对于解码器中的计算过程也进行损失计算,通过最小化重建损失来优化模型。
作为优选,对于已识别出的所有车辆在像素空间中进行比对,通过计算任意两车辆之间的PSNR峰值信噪比进行相似度比较,选择重叠度大于百分之九十的车辆作为识别结果输出。
本发明中通过解码器已经将特征空间中的特征都还原为像素空间中的特征,因此对于包含有车辆的图片的比对也是在像素空间中进行比对,在图片中通过FasterRCNN检测头检测并圈出目标车辆后,利用opencv计算任意两辆车的PSNR峰值信噪比作为比对标准,重叠度越高说明两者之间越相似,因此可以设定阈值为百分之九十,当重叠度高于百分之九十后认定为是同一辆车,从而完成对多张不同图片中的同一辆车的识别。
本发明具有如下有益效果:在识别模型中的特征空间内增加了进行数据增强后的图片特征融合过程,将竞争性特征关联到一起,用于形成新的特征,从而避免了竞争性数据对的出现,提高了识别效果和准确性;在识别模型中增加了解码器将特征空间中的特征还原为像素空间中的特征的过程,提高对图片中的小物体的识别效果,避免小物体的表征特征被忽略;在编码器方面使用了掩码编码器,可以减轻计算的压力,并且可以适当的对相似性的图片特征进行掩码,增加特征多样性,得到更具一般化的特征表示。
附图说明
图1是本发明中车辆信息识别方法的流程图;
图2是本发明中车辆识别模型的框架示意图。
具体实施方式
下面结合附图与具体实施方式对本发明做进一步的描述。
如图1所示,一种基于自监督对比学习的车辆信息识别方法,包括:
提取已完成训练的车辆识别模型,车辆识别模型包含用于融合图片特征的特征空间;
获取不同相机内的静态图片并统一所有图片的大小;
将处理后的图片分别输入到车辆识别模型中,检测并识别出图片内能识别出的所有车辆;对已识别出的所有车辆进行比对,选择比对重叠度大于设定值的车辆作为结果输出。
车辆识别模型的框架如图2所示,其训练过程包括:
构建包括像素空间、特征空间和损失函数的backbone骨干网络以及FasterRCNN检测头。
利用ImageNet1K数据集中的图片对backbone进行预训练得到数据的表征,即为特征空间中图片特征new:
选择图片img在像素空间内进行正相关增强处理,得到正图片对img1和img2;在像素空间内进行正相关增强处理的过程包括随机裁剪、颜色抖动、灰度缩放、高斯干扰和随机水平翻转中的至少三种。
对正图片对的两张图片分别进行编码得到隐向量表示latent
将图片分割成图像块,构建16×16的序列化子图序列,经过位置编码后,得到图片的序列化令牌;对该令牌根据位置进行随机掩码,保存被掩码到的位置作为掩码令牌,将未被掩码的序列化令牌输入到编码器中,对令牌进行编码,得到隐向量表示。
在特征空间内对图片特征latent
对图片特征latent
高斯熔断混合为latent
随机替换融合为latent
交叉融合为new=rate
其中latent
在特征空间中对图片特征latent
利用历史数据集对backbone+FasterRCNN模型进行迭代训练,得到最终的车辆识别模型,FasterRCNN为检测头进行目标车辆的识别,数据集无训练标签。
车辆识别模型的训练过程还包括根据损失函数对模型进行优化的过程,损失函数包括对比损失和重建损失,对比损失为:
重建损失为:
其中q
本发明中自监督学习是深度学习训练模型的一种方式,自监督学习在处理下游任务的时候,可以不需要数据辅助标签的作用,分为生成式模型和判别式模型两种,其中对比学习是最经典的判别式模型;对比学习通过数据增强技术,对同出一源的图片对进行比对,学习到图片中包含的特征;其分为两个阶段,第一阶段叫做pretext,是人为手工设计的,用来学习到数据中包含的监督性信息,本发明中使分类任务作为pretext,数据集采用ImageNet1K;第二阶段是下游任务阶段,在本发明中用来实现对车辆的目标检测等功能;在实际的车辆照片获取中,车辆行驶过程中多个路口的不同相机获取的是针对同一车辆的不同角度的照片,同时照片中也会包含不止一辆车,将这些照片都输入模型中进行识别,将识别后对比的重叠度大于设定值的车辆认为是同一辆车,从而完成车辆的识别。
本发明中的识别模型中将前半部分分类网络迁移用作特征提取器(即backbone骨干网络),后半部分的网络做为检测头(即FasterRCNN),从提取的特征中检测出目标的位置和类别;模型采用自监督学习下的对比学习方式进行训练,不需要额外的标注数据,节省了数据标注和存储成本;同时增加了解码器,用于辅助模型更好地辨别出小物体;ImageNet1K数据集是现有的,包括有1000个不同图像类别,共有1500万张带有类别标注的高质量数据集;历史数据集则是根据实际的车辆识别需求,对视频进行帧提取后形成的包含车辆信息的图片数据集,FasterRCNN作为检测头是现有技术,可以通过Detectron2这个库进行调用。
本发明中对图片进行正相关增强处理的目的在于增加数据的多样性,还可以有平移变换、对比度变换和旋转或反射变换等方式,从而得到两张正图片对进行后续的特征提取和融合操作。
本发明中对数据进行增强形成新的数据对时,会出现竞争性数据对影响算法的最终结果,因此在特征空间中有选择的混合增强后图片对形成的特征,将竞争性特征关联到一起,用于形成新的特征来避免该问题的出现;高斯熔断混合是在原有基础上添加一个包含熔断系数的高斯偏移量(Gaussian offsets);随机替换融合中random
本发明中在backbone骨干网络中设置有两个编码器,第一编码器对图片img1进行编码得到latent
本发明中将编码过程中保存的掩码令牌和经过融合后的特征new进行结合恢复图片的令牌,以此作为解码器的输入得到最终的输出结果;相比于现有技术中的对比学习很容易忽略小物体形成的表征特征的问题,通过解码器将特征空间中的特征重新还原成像素空间中的特征,可以更好地识别出小物体。
本发明中对于损失函数是通过重建损失和对比损失相结合的方式进行构建的,相比于现有的对比学习过程中只用到了对比损失用来最小化相似图片对、最大化相异图片对,从而容易注重大目标而忽略小目标的问题;本发明不仅通过对比损失不断更新模型的参数使得模型收敛,同时也采用了重建损失,对于解码器中的计算过程也进行损失计算,通过最小化重建损失来优化模型。
本发明中通过解码器已经将特征空间中的特征都还原为像素空间中的特征,因此对于包含有车辆的图片的比对也是在像素空间中进行比对,在图片中通过FasterRCNN检测头检测并圈出目标车辆后,利用opencv计算任意两辆车的PSNR峰值信噪比作为比对标准,重叠度越高说明两者之间越相似,因此可以设定阈值为百分之九十,当重叠度高于百分之九十后认定为是同一辆车,从而完成对多张不同图片中的同一辆车的识别。
在本发明的实施例中经过训练后最终得到完成的pth模型文件,在需要进行多个图片的同一车辆识别时,先将pth模型文件转换成onnx模型,并在在TensorRT中加载onnx模型。然后获取多个相机中的静态图片,将图片统一成640*640的大小,并将不同相机内的图片分别输入到TensorRT中的onnx模型内,识别出图片中所有能识别的车辆。
对于已识别出的所有车辆在像素空间中进行比对,通过计算任意两车辆之间的PSNR峰值信噪比进行相似度比较,选择重叠度大于百分之九十的车辆作为识别结果输出。在本发明中对于模型的格式以及运行环境并没有特定要求,采用现有的格式类型和运行环境都能实现本发明的效果。
上述实施例是对本发明的进一步阐述和说明,以便于理解,并不是对本发明的任何限制,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种基于半监督学习的激光诱导击穿光谱分类识别方法
- 一种基于时空对比无监督学习的车辆再识别方法
- 基于对比估计自监督学习的车辆失效模式识别方法及装置