一种智能分类的水文预报方法
文献发布时间:2024-04-18 20:01:30
技术领域
本发明属于水文预报预测领域,具体涉及一种智能分类的水文预报方法。
背景技术
受人类活动和气候变化的影响,极端水文气象灾害频繁发生并不断加剧,径流序列呈现强非线性、高复杂性和非平稳的特征,这对传统水文预报模型提出了严峻的挑战。随着机器学习和人工智能理论的发展,智能数据驱动模型在水文领域得到了广泛应用,并被证明具有良好的适应性和泛化能力。然而在水文过程的不同阶段,产汇流机制不尽相同,预报因子与预报值之间的映射关系也不尽相同,仅靠单一模型描述不同水文阶段预报因子与预报值之间的高维非线性关系,难以实现精确的径流预报,极大限制了模型预报结果精度。如何考虑水文过程不同阶段的径流特性、如何将水文过程不同阶段的产汇流特点与智能预报模型相融合、如何实现分阶段分类精细化预报、如何开发出更高精度的水文预报模型,一直是水文预报领域研究的热点和难点,这对水资源的可持续利用具有重要意义和应用价值。
发明内容
本发明针对现有技术中在水文过程的不同阶段,产汇流机制不尽相同,预报因子与预报值之间的映射关系也不尽相同,单一模型描述不同水文阶段预报因子与预报值之间的高维非线性关系,难以实现精确的径流预报,模型预报结果精度低的问题,提供了一种智能分类的水文预报方法方法,更好地实现分阶段分类精细化预报。
为解决以上技术问题,本发明提供如下技术方案:一种智能分类的水文预报方法,包括如下步骤:
S1、构建水文预报样本数据集并进行预处理,所述水文预报样本数据集包括:若干影响因子构成的预报因子数据集、以及当前时刻流量数据集;将预报因子数据集作为模型输入数据集、当前时刻流量数据集作为模型输出数据集;
S2、确定聚类类别数K,采用k-means聚类算法对预报因子数据集进行聚类,使用自适应合作搜索算法确定最优初始聚类中心,得到预报因子数据集中每个样本所述的类别、以及最终聚类中心;划分训练集和测试集;
S3、以训练集中预报因子、以及当前时刻流量分别构建K个智能预报模型,以各类别预报结果纳什系数相反数为目标函数,采用自适应合作搜索算法对模型进行参数选取,获得K个类别对应的最优智能预报模型;
S4、以测试集中预报因子为输入,利用最优智能预报模型进行水文预报,获得当前时刻的预报流量值。
进一步地,前述的步骤S1中,基于长序列径流数据,利用皮尔逊相关系数法,选取D
进一步地,前述的步骤S1中,所述预报因子数据集、以及当前时刻流量数据集按如下方式获得:
对输入数据集
式中,p
进一步地,前述的步骤S2包括如下子步骤:
S2.0:令迭代次数为t=1,在团队建设阶段,采用式(2)随机生成包含I个个体的初始个体;
x
式中,x
每个个体代表k-means的K个初始聚类中心
式中,
S2.1:对于第i个个体x
S2.2:采用式(3)计算N个样本的归属类别C;
式中,
统计第k个类别所包含的样本
式中,B
S2.3:令iter=iter+1,若iter小于等于最大聚类迭代次数iter
S2.4:对于更新后的聚类中心
式中,F(·)为适应度函数,
S2.5:采用式(6)-(7)更新I个个体的历史最优决策与团队的历史最优决策;
gbest
式中,pbest
S2.6:采用式(8)-(11)计算团队沟通算子
式中,k∈{1,2,...K}为聚类类别,d∈[1,D]为第k个初始聚类中心的第d个维度,
S2.7:采用式(12)-(15),计算团队反思算子
S2.8:采用式(16),计算内部竞争算子
S2.9:令迭代次数t=t+1,若t小于最大迭代次数T,转至步骤2.5;否则将最后一次迭代得到的团队最优决策作为k-means的最优初始聚类中心
S2.10:设置聚类迭代次数iter=1,执行步骤S2.2对最优初始聚类中心A
S2.11:将模型输入数据集-输出数据集,采用a∶b且a+b=1的比例划分为模型输入-输出训练集和测试集,
进一步地,前述的,步骤S3包括如下子步骤:
S3.0统计训练集中第k类样本
S3.1:设置当前模型优选类别k=1,确定预报模型需优化的超参数;
S3.2:使用
其中,p
S3.3:保存第k类样本的最优模型
S3.4:令k=k+1,若k≤K,则转入步骤3.2进行最优模型优选,否则结束迭代,得到最优预报模型
进一步地,前述的步骤S4具体为:令k∈{1,2,...,K},
针对测试集中第k类样本
本发明另一方面提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本发明所述方法的步骤。
本发明还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现本发明所述方法的步骤。
相较于现有技术,本发明采用以上技术方案的有益技术效果如下:①本发明同时考虑降雨、径流、蒸发等相关影响因子,能够切实保障预报模型的物理意义;②本发明在进化过程中引入随机项,并对团队反思算子中心点进行小幅度扰动计算,有效提高了算法寻找全局最优解的能力;③本发明采用k-means算法基于预报因子将样本划分为不同类别,并使用自适应合作搜索算法(ICSA)进行初始聚类中心选取,有效提高了聚类效果,避免了因初始聚类中心选取不当导致聚类迭代过程陷入局部最优解;④本发明选用人工智能模型进行径流分类预报,并采用自适应合作搜索算法进行模型参数优选,可充分挖掘不同类别样本集的输入-输出高维非线性映射关系,同时获取更优越的模型参数,使得模型预报效果实现进一步提升。⑤本发明有效结合了分类方法、智能算法与人工智能模型的优势,具有理论完备性和实践通用性,可获得比传统预报方法更高精度的径流预报效果,有利于流域洪涝灾害预报预警技术创新发展和水资源高效利用。
附图说明
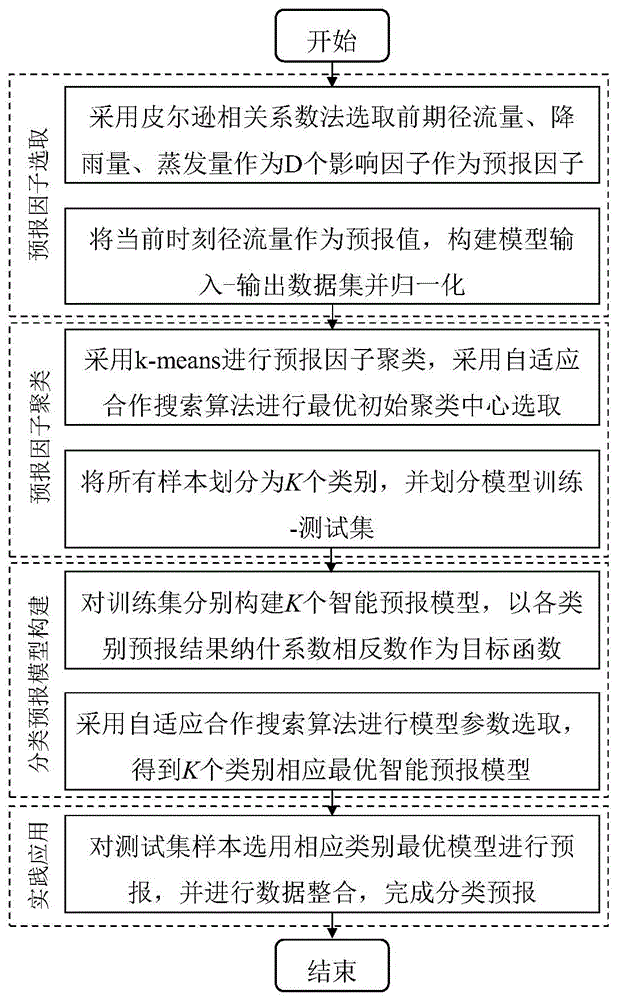
图1为本发明的总体框架图。
图2为本发明预报结果对比图,图中(a)为本发明和单一预报方法预报流量过程图,(b)为单一预报方法预报结果散点图,(c)为本发明预报结果散点图。
具体实施方式
为了更了解本发明的技术内容,特举具体实施例并配合所附图式说明如下。
在本发明中参照附图来描述本发明的各方面,附图中示出了许多说明性实施例。本发明的实施例不局限于附图所述。应当理解,本发明通过上面介绍的多种构思和实施例,以及下面详细描述的构思和实施方式中的任意一种来实现,这是因为本发明所公开的构思和实施例并不限于任何实施方式。另外,本发明公开的一些方面可以单独使用,或者与本发明公开的其他方面的任何适当组合来使用。
参考图1,本发明提供一种智能分类的水文预报方法,包括如下步骤:S1、构建水文预报样本数据集并进行预处理,所述水文预报样本数据集包括:若干影响因子构成的预报因子数据集、以及当前时刻流量数据集;将预报因子数据集作为模型输入数据集、当前时刻流量数据集作为模型输出数据集。
其中,基于长序列径流数据,利用皮尔逊相关系数法,选取D
所述预报因子数据集、以及当前时刻流量数据集按如下方式获得:
对输入数据集
式中,p
S2、确定聚类类别数K,采用k-means聚类算法对预报因子数据集进行聚类,使用自适应合作搜索算法确定最优初始聚类中心,得到预报因子数据集中每个样本所述的类别、以及最终聚类中心;划分训练集和测试集;所述自适应合作搜索算法简称为ICSA(ImprovedCooperation Search Algorithm)。
步骤S2包括如下子步骤:
S2.0:令迭代次数为t=1,在团队建设阶段,采用式(2)随机生成包含I个个体的初始个体;
x
式中,x
每个个体代表k-means的K个初始聚类中心
式中,
S2.1:对于第i个个体x
S2.2:采用式(3)计算N个样本的归属类别C;
式中,
统计第k个类别所包含的样本
式中,B
S2.3:令iter=iter+1,若iter小于等于最大聚类迭代次数iter
S2.4:对于更新后的聚类中心
式中,F(·)为适应度函数,
S2.5:采用式(6)-(7)更新I个个体的历史最优决策与团队的历史最优决策;
gbest
式中,pbest
S2.6:采用式(8)-(11)计算团队沟通算子
式中,k∈{1,2,...K}为聚类类别,d∈[1,D]为第k个初始聚类中心的第d个维度,
S2.7:采用式(12)-(15),计算团队反思算子
/>
S2.8:采用式(16),计算内部竞争算子
S2.9:令迭代次数t=t+1,若t小于最大迭代次数T,转至步骤2.5;否则将最后一次迭代得到的团队最优决策作为k-means的最优初始聚类中心
S2.10:设置聚类迭代次数iter=1,执行步骤S2.2对最优初始聚类中心A
S2.11:将模型输入数据集-输出数据集,采用a∶b且a+b=1的比例划分为模型输入-输出训练集和测试集,
S3、以训练集中预报因子、以及当前时刻流量分别构建K个智能预报模型,以各类别预报结果纳什系数相反数为目标函数,采用自适应合作搜索算法对模型进行参数选取,获得K个类别对应的最优智能预报模型;
S3.0:统计训练集中第k类样本
S3.1:设置当前模型优选类别k=1,确定预报模型需优化的超参数;
S3.2:使用
其中,p
S3.3:保存第k类样本的最优模型
S3.4:令k=k+1,若k≤K,则转入步骤3.2进行最优模型优选,否则结束迭代,得到最优预报模型
针对测试集中第k类样本
以某水文站作为研究对象,进行方法性能测试,分别使用本发明所提出的分类智能预报方法和传统单一智能预报方法进行径流预报,进行预报结果比较,其中智能预报模型选用支持向量回归机模型。表1是分类预报方法和单一预报方法在预见期为1时测试集预报结果统计指标,C-SVM表示传统CSA优化SVM的单一预报方法,K-IC-SVM表示本发明所提方法。其中,RMSE表示均方根误差,是应用最广泛的误差统计之一,可有效地反映模拟值与观测值之间的差异;MAE是平均绝对值误差,表示预测值和观测值之间绝对误差的平均值;MAPE表示平均绝对百分比误差,是一种无偏统计量,通过比较模拟数据和观测数据来计算相对误差,通常对高幅值不敏感,但对低幅值敏感;R是相关系数,可以有效地评价预测数据与观测数据之间的线性关系。NSE表示确定性系数,是一种归一化统计量,用于计算预测数据和观测数据之间的总体偏差。
图2为本发明和单一预报方法预报结果图,其中(a)为本发明和单一预报方法预报流量过程图,(b)为单一预报方法预报结果散点图,(c)为本发明预报结果散点图。由表1和图2可以得到,本发明能够有效提高径流预报精度,相比于单一预报模型,本发明可以更准确刻画径流的起涨过程,对高流量值的预报效果更优。
表1不同方法预报结果统计指标
虽然本发明已以较佳实施例阐述如上,然其并非用以限定本发明。本发明所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当视权利要求书所界定者为准。
- 一种堵瘘补片及其编织方法
- 一种盆底补片及其编织方法