用于基于阵列的PCR的图像驱动质量控制
文献发布时间:2023-06-19 11:35:49
背景技术
深度学习是用大量数据训练以直接从非结构化原始数据中学习复杂和抽象化图案的大型深度神经网络。传统机器学习算法很大程度上依赖于手工制作特征,这是特定于任务的且由具有广泛域专门知识的工程师设计。相比之下,深度学习具有直接从原始数据发现有效特征且通过组合更简单的特征来学习复杂特征的强大能力。深度学习已经在例如图像分类、计算机视觉、语音识别、自然语言处理(natural language processing;NLP)和医疗图像诊断等等各种领域中展现目前先进技术性能。例如,谷歌(Google)和微软(Microsoft)已经对ImageNet图像分类任务应用卷积神经网络(Convolution NeuralNetwork;CNN),且报告4.9%和4.6%错误率,这在图像分类上击败了人类。
目前,测定反应板(例如,用于进行聚合酶链反应(Polymerase Chain Reaction;PCR)的那些板)的制造质量控制对重新格式化和质量控制(quality control;QC)图像执行手动目视检查以识别问题并且确定在制造测定反应板中故障的根本原因。然而,对于人类来说,在制造过程期间对图像进行目视检查是费时、易出错且繁琐的工作。这也限制了生产能力,且通常延迟向客户交付反应板阵列产品。
一些PCR系统被设计用于最大吞吐量,其可在约四小时内同时运行多达四个3,072反应板。此类系统和反应板通常利用仅仅纳升的样品体积,需要具有复杂工作流程的专用仪器将样品和测定物装载到板阵列上。复杂的工作流程和具有挑战性的消耗品使用可通过降低灵敏度和准确性来影响阵列反应质量。此复杂性的另一副作用是较低的阵列制造成品率。与薄板涂层,重新格式化或样品装载有关的阵列制造故障很常见。例如,运行PCR的阵列板可具有某些与装载有关的伪影,包含但不限于:
1.桥接-其中流体在一些相邻的反应单元周围溢出并在它们之间形成桥,从而损害反应的完整性;
2.泄漏-用于反应板的密封单元可能破裂,导致流体逸出到外腔中;以及
3.测定物点样问题-对于预先点样的测定物格式,一些反应单元可能未装载所述测定物。
这些薄板涂层、重新格式化或样品装载问题可以通过目视检查重新格式化和质量控制(QC)图像来检测。因此,从QC图像中自动识别问题并快速确定制造过程中故障的根本原因是非常重要的。由于PCR反应可能显示异常行为,例如在运行OpenArray或其它基于阵列的PCR平台的PCR之前、期间或之后拍摄的图像中出现的样品装载问题,因此期望在面向客户的软件中自动检测这些类型的故障模式,且使故障排除步骤更加有效,客户也更轻松。
发明内容
本系统利用诸如卷积神经网络(CNN)之类的深度神经网络来检测阵列板重新格式化和QC图像中的异常以识别故障模式。从制造数据服务器检索QC图像,包含在设定的时间段内合格和不合格的薄板两者。基于合格或不同的故障模式对数据进行分类。由于每个QC图像可能具有与一个或多个子阵列相关联的多于一个故障模式,因此将QC图像划分为(例如48个)子阵列图像,并将每个子阵列注释为合格或五个故障模式,包含:亮Rox、Rox点样、Rox剥离、停止点桥接和重新格式化错误。带注释的子阵列图像用于训练、评估和测试CNN模型。然后,经过训练和检验的模型可用于辨识阵列板重新格式化和QC图像中的故障及其模式。
卷积神经网络(CNN)特别适合对以二维或三维建模的数据集中的特征进行分类。这使CNN在图像分类中很受欢迎,因为图像可以三个维度呈现于计算机存储器中(两个维度表示宽度和高度,以及第三维度表示例如颜色分量和强度等像素特征)。例如,可使用480×480×3的阵列在计算机存储器中对大小为480×480像素的有色JEG图像进行建模,其中第三维度的每个值都是范围在0到255的像素的红色、绿色或蓝色颜色分量强度。将此数字阵列输入到经过训练的CNN中将生成输出,所述输出描述了图像属于特定类别的概率(猫为0.80,狗为0.15,鸟为0.05等)。图像分类是拍摄输入图像并输出类别(猫、狗等)或最能描述所述图像的类别概率的任务。
从根本上说,CNN输入数据集,使其通过一系列卷积变换、非线性激活函数(例如RELU)和池化操作(下采样,例如最大池化)以及输出层(例如softmax)来生成分类。
附图说明
为了易于识别对任何特定元件或动作的讨论,附图标记中的一个或多个最高有效数字是指其中首次引入所述元件的附图编号。
图1绘示根据一个实施例的qPCR系统100。
图2绘示根据一个实施例的过程200。
图3绘示根据一个实施例的板制备300。
图4绘示根据一个实施例的QC图像状况400。
图5绘示根据一个实施例的卷积神经网络500。
图6绘示根据一个实施例的卷积神经网络层600。
图7绘示根据一个实施例的神经网络700。
图8绘示根据一个实施例的PCR质量控制系统800。
图9绘示根据一个实施例的PCR质量控制系统900。
图10绘示根据一个实施例的验证结果1000。
图11绘示根据一个实施例的验证结果1100。
图12绘示根据一个实施例的PCR质量控制系统1200。
图13绘示根据一个实施例的递归神经网络1300。
图14绘示根据一个实施例的PCR质量控制系统1400。
图15绘示根据一个实施例的PCR质量控制系统1500。
图16绘示根据一个实施例的云学习和控制系统1600。
图17是可以并有本发明实施例的计算装置1700的实例框图。
具体实施方式
可以通过对在PCR反应运行之前、期间或之后拍摄的图像进行评估来检测在PCR测定阵列的背景中讨论的装载问题。卷积神经网络(CNN)经过训练,且应用于辨识故障模式并基于使用用于PCR运行无异常的数据进行训练来识别未知的(未分类的)故障模式。
与传统的故障排除方法(依靠人工识别指示故障模式的特征)相比,CNN提供改进的灵敏度和特异性,并且可以学习辨识先前未分类的问题。单个或多个CNN可以串联或并联应用。在一些实施例中,递归神经网络(recurrent neural network;RNN)可以与CNN结合应用。
根据一个实施例,可以利用深度神经网络,更具体地说是卷积神经网络(CNN)来检测
在一个实施例中,操作深度学习神经网络以识别故障模式的过程可涉及:
4.从制造数据服务器下载合格和不合格板的阵列质量控制(QC)图像。
5.对于每个QC图像,使用寻点算法找到阵列中的所有通孔(反应单元)中心,且基于所识别的通孔中心将整个阵列图像划分为48个子阵列图像。
6.将所有48个子阵列图像装载到注释工具中,且对其进行目视检查并将其标记为合格或五个故障模式,包含:亮Rox、Rox点样、Rox剥离、停止点桥接和重新格式化错误。
7.对所有QC图像重复2)和3)以构建带注释的训练和验证数据集。
8.使用具有一个或多个隐藏层的卷积神经网络作为待训练的网络。
9.使用完全连接层作为输出层以输出对输入子阵列图像的预测。
10.应用Softmax交叉熵代价函数来计算预测与带注释的标记之间的损失。
11.在每个训练步骤中,使用Adam优化器或其它梯度下降优化器来更新上述网络的权重,以最小化针对从训练数据集中随机选择的少量训练样品的损失。
12.继续训练过程直到达到预定数量的训练步骤为止,并为每个特定训练步骤保存经过训练的网络。
13.通过验证数据集中的子阵列图像的独立子集来评估训练过程期间保存的经训练模型,所述子阵列图像不包含在训练过程中。选择具有最小评估损失或错误率的经训练模型作为最佳经训练模型。
14.对于具有所识别的通孔中心的新QC图像,将整个阵列图像划分为一些数量个(例如48个)子阵列图像。将所选择的经训练模型应用于那些子阵列图像上以预测合格或不合格。如果所有子阵列图像都良好,则阵列QC合格,否则阵列QC不合格。系统还可以预测哪个或哪些子阵列不合格以及处于哪种故障模式。
15.诸如增加噪声、旋转、平移偏移、亮度或对比度变化之类的数据扩增技术或通过生成对抗网络(Generative Adversarial Net;GAN)模拟的子阵列图像可用于提高经训练模型的鲁棒性。
16.在训练期间,诸如压差或权重衰减之类的技术可用于提高经训练模型的通用性。
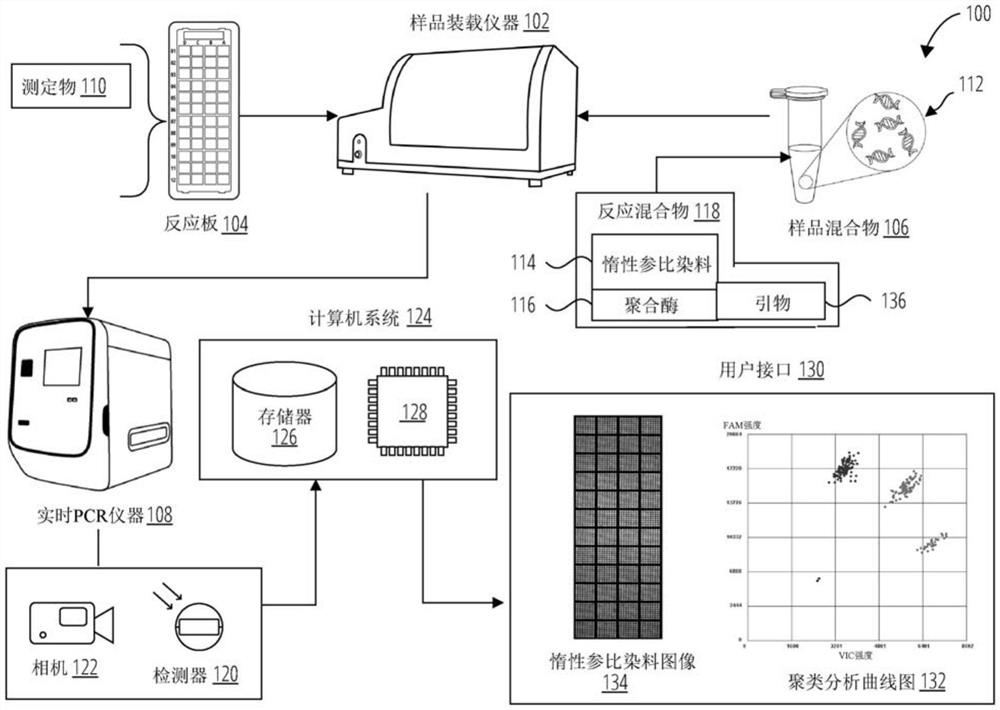
图1绘示qPCR系统100,所述系统包括反应板104、样品装载仪器102、实时PCR仪器108、样品混合物106、计算机系统124和用户接口130。反应板104包括多个子阵列,每个子阵列包括用作qPCR实验的反应位置的多个通孔。每个通孔可以涂布有测定物110。在一些配置中,测定物110是专门以样品DNA中的核苷酸序列为目标的探针。在扩增样品DNA期间,探针通过释放由实时PCR仪器108检测到的报告染料来指示其存在目标序列。将反应板104与目标多核苷酸序列112在样品装载仪器102中组合。在将反应板104与目标多核苷酸序列112组合之前,在包括反应混合物118的样品混合物106中制备目标多核苷酸序列112。反应混合物118包括至少聚合酶116、引物136和惰性参比染料114。聚合酶116在PCR反应期间扩增双链DNA。样品装载仪器102将特定体积的样品混合物106装载到反应板104中的每个预期通孔中。样品装载仪器102已完成制备反应板104之后,反应板104被装载到实时PCR仪器108中。实时PCR仪器108包含在不同温度范围内循环的热循环仪,其触发DNA复制的具体阶段。第一阶段是使双链DNA变性的高温阶段。下一个阶段将引物和聚合酶退火到目标多核苷酸序列112附近的位置,并且允许测定物110与目标多核苷酸序列112杂交。第三阶段是其中聚合酶开始复制DNA链的延伸/复制阶段。在复制阶段期间,聚合酶116可遇到杂交的测定物110和目标多核苷酸序列112。当聚合酶116遇到测定物110时,测定物110的报告染料裂解,从而产生在通孔中观察到的荧光信号。实时PCR仪器108包括检测器120,所述检测器在复制过程期间从每个通孔中检测报告染料。将检测到的信号报告给计算机系统124,所述计算机系统包括存储器126和处理器128,所述处理器存储并处理信息以生成聚类分析曲线图132,所述聚类分析曲线图展示样品混合物106中的目标序列的副本数量和例子。实时PCR仪器108另外包括可捕获惰性参比染料图像134的相机122。惰性参比染料图像134可以用作样品装载仪器102成功装载反应板104的定性指示,还可以洞悉聚类分析曲线图132中的任何异常结果。聚类分析曲线图132和惰性参比染料图像134均可以通过用户接口130显示。
如所属领域的普通技术人员所知,在热循环仪器上执行PCR分析,所述仪器具有用于循环通过多个热循环以扩增基因目标的各种方案。在本教示内容的各种实施例中,针对扩增执行的循环数量可以在约20至40个循环之间。对于本教示内容的各种实施例,为扩增执行的循环数量可以大于40个循环。为了扩增基因目标,热循环仪器可以在一定的循环时间内执行PCR实验的第一热循环,所述循环时间可以与第一热循环数量相关联。
在基因分型分析的各种实施例中,用第一探针和第二探针探测两个或更多个DNA样品。处理器可以基于用于数据收集的多种方案中的任一个从qPCR仪器接收在第一时间的第一数据集,所述第一数据集包含两个或更多个DNA样品中的每一个在所述第一时间的第一探针强度和第二探针强度。处理器可以基于用于数据收集的多种方案中的任一个从qPCR仪器接收在第二时间的第二数据集,所述第二数据集包含两个或更多个DNA样品中的每一个在所述第二时间的第一探针强度和第二探针强度。
根据本教示内容的各种实施例,用户接口可以向终端用户呈现用于分析第一时间和第二时间接收到的数据集的可视化工具。如先前所提及,可以处理多个样品以进行批量基因分型分析,从而产生数据密集的数据集。根据本教示内容的系统和方法的各种实施例提供了可视化工具的实施例,所述可视化工具可以帮助终端用户评估并分析此类数据密集的数据集。对于根据本教示内容的系统和方法的各种实施例,响应于来自终端用户的输入,处理器可以使用第一数据集来生成第一探针强度与第二探针强度的第一曲线图。此外,处理器可以响应于来自终端用户的输入而使用第二数据集来生成第一探针强度作为第二探针强度的函数的第二曲线图。根据本教示内容的系统和方法的各种实施例,处理器可以响应于来自终端用户的输入而显示第一曲线图和第二曲线图。在各种实施例中,输入可以是具有用户接口以逐步方式显示数据的交互式过程。在此类实施例中,终端用户可以按任何次序选择任何数据集以供显示。
在各种实施例中,处理器可以在PCR实验的运行时间期间接收数据。例如,处理器可以在收集第一数据集之后并且在收集第二数据集之前从qPCR仪器接收第一数据集。此外,此方案可以延伸遍布整个运行时间,使得例如处理器可以在收集第二数据集之后并且在收集后续数据集之前从qPCR仪器接收第二数据集。
在一些实施例中,在热循环完成之后,处理器可以从qPCR仪器接收第一数据集和第二数据集。例如,在第一数据集和第二数据集已经被存储在计算机可读介质上之后,处理器可以接收所述第一数据集和第二数据集。
在一些配置中,可视化工具可以帮助终端用户显示基因分型数据集的各个方面,从而促进基因分型数据的分析。在各种实施例中,处理器可以显示展示了第二数据集与第一数据集之间的轨迹线的曲线图。在各种实施例中,处理器可以在第一数据集的第一曲线图质量值上显示,并且在第二数据集的第二曲线图质量值上显示。根据各种实施例,用户接口提供在样品表上做出的选择与在基因分型数据的曲线图上动态显示的选择之间的交互。在各种实施例中,终端用户从可视化工具的用户接口中进行的选择可以例如但不限于提供动态分析,以使终端用户能够例如但不限于对模棱两可的端点数据进行故障排除、作出手动呼叫、使用轨迹线帮助可视化聚类以增强基因分型分配、优化测定条件(即标记探针、测定缓冲器等)以及优化分析条件。
在各种实施例中,系统利用可以例如但不限于根据聚类分析曲线图132中描绘的图式来表示的数据集。此类表示可产生于利用具有不同波长下的发射的两种染料进行的分析,所述染料可以与导向生物样品中基因座的两个等位基因中的一个的每个标记探针相关联。在此类双工反应中,针对三种可能的基因型中的每一个而产生离散的信号集。在信号2与信号1的笛卡尔坐标系中,如聚类分析曲线图中所展示,在此类图形表示上展示的每个数据点可具有给定的三个离散信号集中的一个信号集中的坐标。因此,对于每个数据点,可以将用于多个样品的离散信号集作为数据点存储在数据集中。此类数据集可以存储在多种计算机可读介质中,并且可以在分析期间或分析后动态地分析,如随后将更详细地论述。
用于展现基因分型数据可视化的方法和系统的实施例的特征的一种此类型的测定可以利用
根据各种实施例,术语“标记探针”通常是指在扩增反应中使用的分子,通常用于定量或qPCR分析以及端点分析。此类标记探针可用于监测目标多核苷酸的扩增。在一些实施例中,扩增反应中所存在的寡核苷酸标记探针适用于监测随时间产生的扩增子的量。此类寡核苷酸标记探针包含但不限于本文所述的5'-核酸外切酶测定
如本文所使用,术语“核酸样品”是指根据本教示内容在生物样品中发现的核酸。预期可以侵入性或非侵入性地收集样品。样品可以在以下各者之上、之中、之内、来自以下各者或结合以下各者发现:纤维、织物、香烟、口香糖、粘合材料、土壤或无生命物体。如本文所使用,“样品”以其最广泛的含义进行使用,并且是指含有可衍生基因目标或目标多核苷酸的核酸的样品。样品可以包括细胞、从细胞分离的染色体(例如,中期染色体的扩散)、基因组DNA、RNA、cDNA等。样品可以是动物或植物来源,涵盖含有核酸的任何生物体,包含但不限于植物、家畜、家养宠物以及人类样品,并且可以源自多个来源。这些来源可以包含但不限于全血、毛发、血液、尿液、组织活检、淋巴、骨头、骨髓、牙齿、羊水、毛发、皮肤、精液、肛门分泌物、阴道分泌物、汗液、唾液、口腔拭子、各种环境样品(例如,农业、水和土壤)、研究样品、经纯化样品以及溶解细胞。应当理解,可以使用所属领域已知的多种样品制备程序中的任一种从样品中分离含有目标多核苷酸序列的核酸样品,例如包含使用诸如机械力、超声处理、限制性核酸内切酶裂解或所属领域已知的任何方法之类的此类程序。
如本文所使用,术语“目标多核苷酸”、“基因目标”等在本文中可互换地使用并且是指特定所关注的核酸序列。“目标”可以是试图扩增并且可以在存在其它核酸分子的情况下存在或存在于较大核酸分子内的多核苷酸序列。目标多核苷酸可以从任何来源获得,并且可以包括任何数量的不同组成性组分。例如,目标可以是核酸(例如,DNA或RNA)。目标可以进行甲基化、非甲基化或两者兼有。此外,将了解,在所关注的特定核酸序列的上下文中使用的“目标”另外是指其替代物,例如扩增产物和天然序列。在一些实施例中,所关注的特定核酸序列是源自降解来源的短DNA分子,例如可发现于例如但不限于法医学样品中。如上所述,本教示内容的所关注的特定核酸序列可以源自多种生物体和来源中的任一种。
如本文所使用,“DNA”是指如所属领域中所了解呈其各种形式的脱氧核糖核酸,例如基因组DNA、cDNA、经分离核酸分子、载体DNA以及染色体DNA。“核酸”是指呈任何形式的DNA或RNA。经分离核酸分子的实例包含但不限于载体中所含的重组DNA分子、维持在异源宿主细胞中的重组DNA分子、部分地或基本上纯化的核酸分子以及合成的DNA分子。通常,“经分离”核酸不含天然侧接衍生核酸的生物体的基因组DNA中的核酸(即,位于核酸的5′和3′末端的序列)的序列。此外,“经分离”核酸分子(例如cDNA分子)在通过重组技术产生时一般基本上不含其它细胞材料或培养基,或者在以化学方式合成时不含化学前体或其它化学物质。
在一些实施例中,PCR扩增产物可以通过结合到PCR扩增引物的荧光染料来检测,例如,如PCT专利申请WO 2009/059049中所描述。PCR扩增产物也可以通过其它技术检测,包含但不限于扩增产物的染色,例如银染色等。
在一些实施例中,检测包括仪器,即使用自动或半自动检测构件,其可以但不必包括计算机算法。在一些实施例中,所述仪器是便携式的、可运输的或包括便携式组件,所述便携式组件可以插入到移动性较小或运输性较小的组件中,例如位于进行扩增产物检测的实验室、医院或其它环境中。在某些实施例中,检测步骤与以下各者组合或是以下各者的延续部分:至少一个扩增步骤、一个测序步骤、一个隔离步骤、一个分离步骤,例如但不限于毛细管电泳仪器,其包括至少一个荧光扫描仪和至少一个绘图、记录或读出组件;色谱柱,其与吸光度监测器或荧光扫描仪和图形记录器耦合;色谱柱,其与包括记录和/或检测组件的质谱仪耦合;分光光度计仪器,其包括至少一个UV/可见光扫描仪和至少一个绘图、记录或读出组件;微阵列,其具有例如扫描仪或CCD相机之类的数据记录装置;或测序仪器,其具有选自以下的检测组件:包括至少一个荧光扫描仪和至少一个绘图、记录或读出组件的测序仪器、通过包括荧光标记的、可逆终止子核苷酸的合成仪器进行的测序、包括在DNA聚合酶并入核苷酸之后检测焦磷酸(PPi)释放的焦磷酸测序方法、配对端测序、聚合酶克隆测序、单分子测序、纳米孔测序以及通过杂交或通过连接测序,如Lin,B.等在《生物医学工程的最新专利(Recent Patents on Biomedical Engineering)》(2008)1(1)60-67中所论述,其以引用的方式并入本文中。
在某些实施例中,检测步骤与扩增步骤组合,例如但不限于实时分析,例如Q-PCR。用于执行检测步骤的示范性方法包含
在一些实施例中,可以基于至少一部分扩增子的质荷比(m/z)来检测并定量扩增产物。例如,在一些实施例中,引物包括质谱兼容的报告基团,包含但不限于并入扩增产物中并可用于质谱检测的质量标签、电荷标签、可裂解部分或同位素(参见例如Haff和Smirnov,“核酸调研(Nucleic Acids Research)”25:3749-50,1997年;以及Sauer等,“核酸调研(Nucleic Acids Research)”31:e63,2003年)。扩增产物可以通过质谱进行检测。在一些实施例中,引物包括限制酶位点、可裂解部分等,以促进释放一部分扩增产物以进行检测。在某些实施例中,多种扩增产物通过液相色谱或毛细管电泳进行分离、经历ESI或MALDI并通过质谱进行检测。对质谱的描述可以在2003年MCC出版社发表的Gary Siuzdak的《质谱在生物技术中的扩展作用(The Expanding Role of Mass Spectrometry inBiotechnology)》中以及其它地方找到。
在一些实施例中,检测包括手动或视觉读出或评估,或其组合。在一些实施例中,检测包括自动或半自动数字或模拟读出。在一些实施例中,检测包括实时或端点分析。在一些实施例中,检测包括微流体装置,其包含但不限于
术语“扩增反应混合物”和/或“主混合物”可以指包括用于扩增目标核酸的各种(一些或所有)反应剂的水性溶液。此类反应还可以使用固体支撑物或半固体支撑物(例如,阵列)来执行。所述反应还可以根据用户的期望以单一或多工形式执行。这些反应通常包含酶、水性缓冲剂、盐、扩增引物、目标核酸以及核苷三磷酸。在一些实施例中,扩增反应混合物和/或主混合物可以包含以下各者中的一个或多个:例如缓冲剂(例如,Tris)、一种或多种盐(例如,MgC、KCl)、甘油、dNTP(dA、dT、dG、dC、dU)、重组BSA(牛血清白蛋白)、染料(例如,ROX惰性参比染料)、一种或多种清洁剂、聚乙二醇(PEG)、聚乙烯吡咯烷酮(PVP)和/或明胶(例如,鱼源或牛源)和/或消泡剂。根据上下文,所述混合物可以是完全或不完全扩增反应混合物。在一些实施例中,主混合物在用于扩增反应之前不包含扩增引物。在一些实施例中,主混合物在用于扩增反应之前不包含目标核酸。在一些实施例中,在与扩增引物接触之前,将扩增主混合物与目标核酸样品混合。
在一些实施例中,扩增反应混合物包括扩增引物和主混合物。在一些实施例中,扩增反应混合物包括扩增引物、可检测标记的探针和主混合物。
在一些实施例中,扩增引物和主混合物或扩增引物、探针和主混合物的反应混合物在储存容器或反应容器中干燥。在一些实施例中,将扩增引物和主混合物或扩增引物、探针和主混合物的反应混合物在存储容器或反应容器中冻干。在一些实施例中,本公开一般涉及扩增来自单个对照核酸分子的多个目标特异性序列。例如,在一些实施例中,单个对照核酸分子可以包含RNA,并且在其它实施例中,单个对照核酸分子可以包含DNA。在一些实施例中,目标特异性引物和引物对是可以扩增核酸分子(例如,对照核酸分子)的特定区域的目标特异性序列。在一些实施例中,目标特异性引物可以引发RNA的反转录以生成目标特异性cDNA。在一些实施例中,目标特异性引物可以扩增目标DNA或cDNA。在一些实施例中,选择性扩增所需的DNA量可为约1ng至1微克。在一些实施例中,选择性扩增一种或多种目标序列所需的DNA量可为约1ng、约5ng或约10ng。在一些实施例中,选择性扩增目标序列所需的DNA量为约10ng至约200ng。
如本文所使用,术语“反应容器”一般是指根据本教示内容可以在其中发生反应的任何器皿、腔、装置或组合件。在一些实施例中,反应容器可以是微管,例如但不限于0.2mL或0.5mL反应管,如Micro AmpTM光学管(加利福尼亚州卡尔斯巴德的生命技术公司(LifeTechnologies Corp.))或微离心管,或在分子生物学实验室的惯例中的那类其它器皿。在一些实施例中,反应容器包括多孔板(例如48孔、96孔或384孔微量滴定板)的孔、载玻片上的点、TaqManTM阵列卡中的孔或微流体装置的通道或腔,包含但不限于TaqManTM低密度阵列或TaqManTMOpenArrayTM实时PCR板的通孔(应用生物系统,赛默飞世尔科技(ThermoFisher Scientific))。例如但不限于,可以在同一支撑物上存在多个反应容器。例如,OpenArray
术语“退火(annealing)”和“杂交(hybridizing)”(包含但不限于词根“杂交(hybridize)”和“退火(anneal)”的变型)可互换地使用并且意指一个核酸与另一个核酸的核苷酸碱基配对相互作用,所述相互作用导致形成双链体、三链体或其它更高阶结构。初级相互相用通常是通过Watson-Crick和Hoogsteen型氢键结合的核苷酸碱基特异的,例如A:T、A:U和G:C。在某些实施例中,碱基堆积和疏水性相互作用也可以促成双链体稳定性。引物和探针退火到互补序列的条件在所属领域中是众所周知的,例如如在以下各者中所描述:《核酸杂交,实用方法(Nucleic Acid Hybridization,A Practical Approach)》,由Hames和Higgins编写,IRL出版社,华盛顿哥伦比亚特区(1985年);以及Wetmur和Davidson,《分子生物学(Mol.Biol.)》31:349(1968年)。
一般来说,除了其它方面之外,所述退火是否进行受以下各项影响:引物的互补部分的互补部分和其在目标侧接序列和/或扩增子中的对应结合位点的长度,或报告探针的对应互补部分和其结合位点的长度;pH;温度;一价和二价阳离子的存在情况;杂交区域中G和C核苷酸的比例;培养基的粘度;以及变性剂的存在情况。此类变量影响杂交所需的时间。因此,优选退火条件将取决于特定应用。然而,此类条件可以由所属领域的普通技术人员常规地确定,而无需过度实验。优选地,选择退火条件以允许引物和/或探针与对应的目标侧接序列或扩增子中的互补序列选择性地杂交,但在第二反应温度下不与反应组合物中的不同目标核酸或非目标序列以任何显著程度进行杂交。
图2绘示根据一个实施例的用于PCR扩增的过程200,具体地说,用于PCR扩增的5′核酸酶测定。过程200展示了此测定过程的四个阶段,其在每个循环中发生并且不干扰产物的指数累积。所述四个阶段包含聚合阶段202、链置换阶段204、裂解阶段206和完成阶段208。在聚合阶段202期间,正向引物和反向引物开始在目标序列210附近复制双链DNA 214的区段。正向引物(5'至>3')包括热启动聚合酶224(Taq聚合酶),所述热启动聚合酶在DNA聚合酶不活跃以避免不必要复制的温度下起作用。探针212包括报告染料218、互补序列226、非荧光猝灭剂220和小沟结合剂222。探针212通过互补序列226与目标序列210杂交。非荧光猝灭剂220和小沟结合剂222充当分子附接到探针212的3′末端。当探针完好无损时,非荧光猝灭剂220(non-fluorescent quencher;NFQ)可防止报告染料218发出荧光信号。因为非荧光猝灭剂220不发荧光,所以它产生较低的背景信号,从而提高了定量精度。小沟结合剂222(minor groove binder;MGB)在不增加探针长度的情况下增加了探针的熔融温度(Tm),从而允许设计出更短的探针。在聚合阶段202期间,热启动聚合酶224朝向探针212移动,其中报告染料218附接到探针212的5'侧。
在链置换阶段204中,热启动聚合酶224与置换报告染料218的经杂交探针212相互作用。在裂解阶段206中,热启动聚合酶224使报告染料218从探针212裂解。裂解使报告染料与猝灭剂染料分离;其中非荧光猝灭剂220不再阻碍报告染料218,分离的报告染料216增加了其荧光。仅当目标序列与探针互补并在PCR期间被扩增时,荧光才会增加。仪器检测到报告染料发出的荧光,所述荧光表明双链DNA 214上存在目标序列。由于探针212与目标序列210杂交,热启动聚合酶224在互补序列226处终止,指示完成阶段208。
图3绘示在将反应板104装载到rtPCR仪器中之前对所述反应板的板制备300。反应板104包括多个子阵列,每个子阵列308包括多个贯通阵列通孔304。每个通孔可以用作测定物110的反应位置。在一些配置中,反应板104包括48个子阵列,其中每个子阵列包括64个通孔,每个通孔能够容纳33-nL的反应体积。在前述配置中,反应板104包括3072个通孔。
取决于反应板104的配置,一些阵列通孔304将包含点样在其中的测定物110。每个通孔包括亲水性内部,在所述内部可以点样测定物110。亲水性通孔也被疏水性表面包围,从而使反应得以控制。
为了将设定的体积准确地装载到每个期望的阵列通孔304中,使用了样品装载仪器102。样品装载仪器102将设定体积的样品混合物106等分到反应板104中的每个期望通孔中。在一些配置中,样品装载仪器102利用尖端块310将样品混合物分配到反应板104的通孔中。
当操作样品装载仪器102时,尖端块310可以横越反应板104移动,以允许将设定体积的样品混合物106输送到特定的阵列通孔304。当样品装载仪器102完成其运行时,反应板104被转换为装载的反应板306,其中多个子阵列(例如子阵列312)包括装载的通孔302,所述通孔包括目标多核苷酸序列112。
参考图4,QC图像条件400绘示惰性参比染料图像,所述惰性参比染料图像展示了导致不良数据收集的特征缺陷。当将点样的样品板装载到rtPCR仪器中时,在荧光灯下拍摄点样的板的图像。荧光灯使惰性参比染料发出荧光,表明存在样品混合物(即,目标多核苷酸和反应混合物)。惰性参比染料图像由与仪器相关联的计算机系统来收集并存储。可以在质量控制过程的早期对惰性参比染料图像进行分析,以确定是否存在与将样品点样到阵列板上相关联的任何错误。
图像402绘示合格图像,其展示了以网格图案布置的明亮地被照亮的圆点。每个圆点表示通孔,并且合格图像展示具有在均匀背景下的类似亮度的所有通孔。
图像404、图像406、图像408、图像410和图像412表示与阵列板的点样相关联的五个常见故障状况。图像404表示发生故障的状况中的一个,被称为亮rox。亮ROX指示与其它通孔相比,在一些通孔中存在可见的亮点416。亮点416可指示在较亮的通孔中更高程度地存在惰性参比染料,这可指示板的不当点样。图像406表示ROX点样,其中随机通孔显得比其它通孔暗,并且分布在整个阵列板上。在一些情况下,较暗的通孔可指示部分装载的通孔。图像408表示ROX剥离,其中一些较暗的观察通孔以几乎线性的图案布置在阵列板上。在一些情况下,ROX剥离可指示板没有紧紧靠在板固持器右侧的挡块上、自动装载器未对准,或者自动装载器的尖端有太多气泡和/或泡沫。在图像404、图像406和图像408中,如果存在至少七个受影响的通孔,则所述图像被认为是不合格的,但是由于某些不合格识别是主观的,因此没有绝对界限,因为确定是基于通孔的相对亮度的。
图像410表示故障状况,被称为点点桥接。点点桥接414在连接几个(两个或四个)相邻通孔的背景区域中显示为灰色“桥”。点点桥接414可由于自动装载器尖端块的拆卸不当引起的,这导致一些样品混合物从通孔中溢出。图像412表示重新格式化错误,并且其特征在于至少一个随机的空通孔。重新格式化错误可指示阵列板有问题或者自动装载器中阵列配置有问题。
图5绘示了示范性卷积神经网络500。卷积神经网络500按三个维度(宽度、高度、深度)布置其神经元,如在卷积层504中所显示。卷积神经网络500的每一层将3D输入体积转换为神经元激活的3D输出体积。在此实例中,输入层502对图像进行编码,因此其宽度和高度将是所述图像的尺寸,并且深度将为3(红色、绿色、蓝色通道)。卷积层504进一步变换输入层502的输出,并且输出层506将卷积层504的输出变换成图像内容的一种或多种分类。在一个实施例中,卷积神经网络500可以利用一个输入层502、六个隐藏层(一个或多个可以是卷积层504)和一个输出层506。除了一个或多个卷积层504之外,卷积神经网络500可以利用池化层和完全连接层。
图6更详细地绘示了示范性卷积神经网络层600。图像的输入层区域602区域的输入层区域604的实例子区域通过卷积层606中的一组卷积层子区域608来分析。输入层区域602的长度和宽度是32×32个神经元(例如32×32像素),而深度是三个神经元(例如每像素三个颜色通道)。卷积层606中的每个神经元仅在空间上(在高度和宽度上)连接到输入层区域602中的局部区域,但是连接到整个深度(即,如果输入是图像,则连接到所有颜色通道)。注意,沿着卷积层子区域608的深度存在多个神经元(在此实例中为5个),所述卷积层子区域分析输入层区域602的输入层区域604的子区域,其中卷积层子区域608的每个神经元可从输入层区域604的子区域的每一神经元接收输入。
参考图7,神经网络700包括输入层702、第一卷积层704、第一池化层706、第二卷积层708、第二池化层710、第一完全连接层712和第二完全连接层714。
输入层702可以是54×54阵列。54×54阵列可以是阵列板的子阵列。例如,阵列板可以被布置成子阵列的4×12阵列。因此,每个阵列板可以被分成48个子阵列,每个子阵列被发送到神经网络700以确定其是合格还是不合格。阵列中的每个值均可以表示颜色通道,例如R、G、B颜色通道或黑色/白色颜色标度。然后,将输入层702卷积到第一卷积层704中。第一卷积层704包括32个阵列,每个阵列为54×54。第一卷积层704被池化到第一池化层706中。池化功能可以是在第一卷积层704的3×3区域上操作的最大池化功能。然后,第一池化层706可以包括32个阵列,每个阵列为18×18。然后将第一池化层706卷积到第二卷积层708中。第二卷积层708可以具有64个阵列,每个阵列为18×18。第二卷积层708被池化到第二池化层710中。池化功能可以是在第二卷积层708的3×3区域上操作的最大池化功能。然后,第二池化层710可以包括64个阵列,每个阵列为6×6。64个6×6阵列中的每个阵列都被发送到可具有192个节点的第一完全连接层712。然后,第一完全连接层712完全连接到可具有48个节点的第二完全连接层714。然后,输出层716具有合格或不合格两种状态,并且完全连接到第二完全连接层714。输出层716还可以预测不合格的类型(类别)。
可以通过首先从制造数据服务器检索合格和不合格板的历史QC图像来训练并操作神经网络700。对于每个图像,通过寻点算法找到阵列中的通孔(反应单元)中心,且基于所识别的通孔中心将整个阵列图像划分为48个子阵列图像。将48个子阵列图像装载到注释工具中,且对其进行检查并将其标记为合格或不合格,所述不合格具有五个故障模式,包含:亮Rox、Rox点样、Rox剥离、停止点桥接和重新格式化错误。对QC图像重复前两个步骤,以构建带注释的训练和验证数据集。对具有一个或多个隐藏层的卷积神经网络进行初始化以用作待训练的网络。利用完全连接层作为输出层以输出对输入子阵列图像的预测。应用Softmax交叉熵代价函数来计算预测与带注释的标记之间的损失。在每个训练步骤中,利用Adam优化器或其它梯度下降优化器来更新上述网络的权重,以最小化针对从训练数据集中随机选择的少量训练样品的损失。继续训练过程直到达到预定数量的训练步骤为止,并为每个特定训练步骤保存经过训练的网络。通过验证数据集中的子阵列图像的独立子集来评估训练过程期间保存的经训练模型,所述子阵列图像不包含在训练过程中。然后选择具有最小评估损失或错误率的经训练模型作为最佳经训练模型。在训练期间,诸如压差或权重衰减之类的技术可用于提高经训练模型的通用性。
在操作期间,新QC图像具有识别的通孔中心,整个阵列图像被划分为48个子阵列图像。将所选择的经训练模型应用于那些子阵列图像上以预测合格或不合格。如果所有子阵列图像都良好,则阵列QC可为合格的,否则阵列QC不合格。神经网络700还可以预测哪个子阵列不合格以及处于哪种故障模式。
诸如增加噪声、旋转、平移偏移、亮度或对比度变化之类的进一步数据扩增技术或通过生成对抗网络(GAN)模拟的子阵列图像可用于提高经训练模型的鲁棒性。
转移学习是充分利用多个数据源以克服数据稀缺问题的技术。通过使用转移学习,修改了已经针对类似问题进行训练的网络,然后使用一部分标记数据进行重新训练。此处,神经网络700可以使用从其它图像数据集(例如ImageNet数据)中习得的模型,并用新完全连接层替换最终分类层以预测基于阵列的PCR数据的合格和故障模式。
参考图8,PCR质量控制系统800包括PCR系统802、CNN 804和计算机系统806。PCR系统802生成QC图像并将所述图像发送到CNN 804。CNN 804可以是上文描述的神经网络700的实施例。CNN 804确定QC图像是合格还是不合格。结果被发送到计算机系统806。结果可包含QC图像是合格还是不合格、哪个子阵列不合格以及是哪种故障模式。计算机系统806可以向用户显示结果、存储结果、执行结果的额外变换,以及控制PCR系统802或设置过程参数以改善反应板阵列的制造。计算机系统806还可以基于结果来更改PCR系统802,例如停止操作提供不合格结果的PCR系统802,或者在出现不合格的情况时校正PCR系统802。PCR系统802可以生成一系列QC图像,每个QC图像处于不同时间。这些QC图像可以串联发送到CNN 804。对于每个图像,CNN 804将结果提供给计算机系统806。
参考图9,PCR质量控制系统900包括PCR系统802、计算机系统806、CNN 902和CNN904。PCR质量控制系统900可以类似于PCR质量控制系统800来进行操作。然而,PCR质量控制系统900可以初始化多个CNN(CNN 902、CNN 904等)。然后,将每个CNN用于子阵列中的一个。一些QC图像包括48个子阵列,并且可以操作48个CNN。然后,计算机系统806可以组合来自每个CNN的结果。结果可包含一个子阵列是否出现故障状况、哪些子阵列出现故障状况以及每个子阵列处于哪个故障状况。
参考图10,描绘了验证结果1000。行表示带注释的分类,并且列表示来自所选网络的预测。左上方的框是带注释的标记合格且预测的分类合格。对于给定的测试,有1166个这样的结果。右上方的框是带注释的标记合格且预测的分类不合格。对于给定的测试,有73个这样的结果。左下方的框是带注释的标记不合格且预测的分类合格时。对于给定的测试,有70个这样的结果。右下方的框是带注释的标记不合格且预测的分类不合格。对于给定的测试,有1196个这样的结果。所得灵敏度(真阳性/注释的阳性)为94.1%。所得特异性(真阴性/注释的阴性)为94.5%。所得准确性((真阳性+真阴性)/总数)为94.3%。
参考图11,描绘了验证结果1100。验证结果1100将注释的分类与预测的分类进行比较。分类包含合格和五个故障模式:亮ROX、ROX点样、ROX剥离、停止点桥接和重新格式化。
参考图12,PCR质量控制系统1200包括PCR系统802、计算机系统806、完全连接网络1202和CNN 1204。PCR系统802生成QC图像并将所述图像发送到完全连接网络1202。完全连接网络1202可以包括具有一个或多个隐藏层的完全连接层。可以在QC图像上应用无监督学习(例如自动编码器)来学习简单或复杂的特征,然后将所述特征用作CNN 1204或其它完全连接网络的输入,以将QC图像分类成合格和不同的故障模式。CNN 1204可以是上文描述的神经网络700的实施例。CNN 1204确定QC图像是合格还是不合格。结果被发送到计算机系统806。结果可包含QC图像是合格还是不合格、哪个子阵列不合格以及是哪种故障模式。计算机系统806可以向用户显示结果、存储结果、执行结果的额外变换、调整反应板阵列的未来制造参数,以及控制PCR系统802。计算机系统806还可以基于结果来更改PCR系统802,例如停止操作提供不合格结果的PCR系统802,或者在出现不合格的情况时校正PCR系统802。PCR系统802可以生成一系列QC图像,每个QC图像处于不同时间。这些QC图像可以串联发送到CNN 1204。对于每个图像,CNN 1204将结果提供给计算机系统806。PCR质量控制系统1200还可以利用多个CNN 1204,类似于图9所描绘,每个CNN 1204接收子阵列。此外,可以初始化多个完全连接网络1202,每个完全连接网络接收子阵列。每个子阵列的完全连接网络1202的输出可以被发送到CNN 1204。
图13绘示递归神经网络1300(RNN)。变量x[t]是在阶段t的输入。例如,x[1]可以是选择序列中特定元素的独热向量。变量s[t]是在阶段t的隐藏状态。这是网络的“存储器”。基于先前的隐藏状态和目前阶段的输入来计算变量s[t]:s[t]=f(Ux[t]+Ws[t-1])。激活函数f通常是非线性,例如tanh或ReLU。计算第一隐藏状态所需的输入s(-1)通常被初始化为全零。变量o[t]是在阶段t的输出。例如,预测可以是整个词汇表上概率的向量:o[t]=softmax(Vs[t])。递归神经网络1300可以用于查看在PCR反应过程中QC图像的演进。一个或多个CNN可以输入到递归神经网络1300(或者可以是多个RNN,例如每CNN一个RNN),并且递归神经网络1300基于CNN图像分类随时间演进的方式而输出分类预测。CNN可具有经修改输出层,使得CNN不会预测合格/不合格,而是将一组分类特征作为输入发送到递归神经网络1300。这些特征可以例如是第二完全连接层的结果。如果使用多个RNN(例如,每CNN一个RNN),则分析系统可以利用多层感知机(通用ANN)将RNN预测组合为对故障模式的最终预测。
参考图14,PCR质量控制系统1400包括PCR系统802、计算机系统806、CNN 902和RNN1402。PCR系统802将一系列QC图像发送到CNN 902。所述系列基于对反应板的周期性采样。然后,每个图像均会应用CNN 902来确定分类或特征(例如,不应用最终的完全连接输出层)。然后将其发送到RNN 1402。RNN 1402接收所述系列的分类或特征。然后,RNN 1402确定输出,例如由于RNN 1402确定QC图像中的变化,PCR系统802已经故障或者PCR系统802可能故障。RNN 1402还可以确定故障模式。计算机系统806可以向用户显示结果、存储结果、执行结果的额外变换,以及控制PCR系统802。计算机系统806还可以基于结果来更改PCR系统802,例如停止操作提供不合格结果的PCR系统802,或者在出现不合格的情况时校正PCR系统802。
参考图15,PCR质量控制系统1500包括PCR系统802、计算机系统806、CNN 902、CNN904和RNN 1502。PCR系统802将一系列QC图像发送到CNN 902和CNN 904。CNN 902、CNN 904和其它CNN可以串联接收QC图像的子阵列。所述系列基于对反应板的周期性采样。然后,每个图像均会应用CNN来确定子阵列的分类或特征(例如,不应用最终的完全连接输出层)。然后将其发送到RNN 1502。RNN 1502也可以是并联的多个RNN,每个子阵列一个RNN。RNN 1502接收所述系列的分类或特征。然后,RNN 1502确定输出,例如由于RNN 1502确定QC图像中的变化,PCR系统802已经故障或者PCR系统802可能故障。RNN 1502还可以确定故障模式。计算机系统806可以向用户显示结果、存储结果、执行结果的额外变换,以及控制PCR系统802。计算机系统806还可以基于结果来更改PCR系统802,例如停止操作提供不合格结果的PCR系统802,或者在出现不合格的情况时校正PCR系统802。
图16绘示根据一个实施例的云学习和控制系统1600。云学习和控制系统1600包括云分析系统1610,所述云分析系统包括学习系统1612,例如本文公开的实施例中的一个或多个。通过云分析系统1610经由因特网1602或其它网络监测来自多个PCR运行或其它实验(例如,PCR实验室仪器1604、PCR实验室仪器1606和PCR实验室仪器1608)的实验数据。云分析系统1610处理实验数据并提供习得的配置参数作为反馈,以针对目前或未来的实验调整PCR仪器的配置设置。
图17是可以并有本发明实施例的计算装置1700的实例框图。图17仅说明进行本文中所描述的技术过程的方面的机器系统且不限制权利要求书的范围。本领域的技术人员将认识到其它变化、修改以及替代方案。在一个实施例中,计算装置1700通常包含监测器或图形用户接口1702、数据处理系统1720、通信网络接口1712、一个或多个输入装置1708、一个或多个输出装置1706等。
如图17所描绘,数据处理系统1720可以包含一个或多个处理器1704,它们经由总线子系统1718与许多外围装置进行通信。这些外围装置可以包含一个或多个输入装置1708、一个或多个输出装置1706、通信网络接口1712以及存储子系统如易失性存储器1710和非易失性存储器1714。
易失性存储器1710和/或非易失性存储器1714可以存储计算机可执行指令,和因此的形成逻辑1722,该逻辑在应用于一个或多个处理器1704并由其执行时实施本文公开的过程和神经网络的实施例。
一个或多个输入装置1708包含用于将信息输入到数据处理系统1720的装置和机构。这些可以包含键盘、小键盘、并入监测器或图形用户接口1702中的触摸屏、音频输入装置如语音识别系统、麦克风和其它类型的输入装置。在各种实施例中,一个或多个输入装置1708可以被实现为计算机鼠标、轨迹球、轨迹板、操纵杆、无线遥控器、绘图板、语音命令系统、眼睛跟踪系统等。一个或多个输入装置1708通常允许用户经由命令如单击按钮等来选择出现在监测器或图形用户接口1702上的对象、图标、控制区域、文本等。
一个或多个输出装置1706包含用于从数据处理系统1720输出信息的装置和机构。这些可以包含在所属领域中是众所周知的监测器或图形用户接口1702、扬声器、打印机、红外LED等。
通信网络接口1712提供到数据处理系统1720外部的通信网络(例如,通信网络1716)和装置的接口。通信网络接口1712可充当用于从其它系统接收数据且将数据传输到其它系统的接口。通信网络接口1712的实施例可以包含以太网接口、调制解调器(电话、卫星、电缆、ISDN)、(异步)数字订户线(digital subscriber line;DSL)、火线、USB、无线通信接口(例如蓝牙或WiFi)、近场通信无线接口、蜂窝接口等。
通信网络接口1712可经由天线、电缆等耦合到通信网络1716。在一些实施例中,通信网络接口1712可以物理地集成在数据处理系统1720的电路板上,或在一些情况下可在软件或固件如“软调制解调器”等中实施。
计算装置1700可以包含允许使用方案如HTTP、TCP/IP、RTP/RTSP、IPX、UDP等通过网络通信的逻辑。
易失性存储器1710和非易失性存储器1714是有形介质的实例,所述有形介质被配置成存储计算机可读数据和指令以实施本文描述的过程的各种实施例。其它类型的有形介质包含可移动存储器(例如,可插拔USB存储器装置、移动装置SIM卡)、光学存储介质(例如,CD-ROM)、DVD、半导体存储器(例如,快闪存储器)、非暂时性只读存储器(ROM)、具有备用电池的易失性存储器、联网存储装置等。易失性存储器1710和非易失性存储器1714可以被配置成存储基本编程和数据构造,其提供所公开的过程及其在本发明范围内的其它实施例的功能。
实施本发明的实施例的逻辑1722可以由易失性存储器1710和/或非易失性存储器1714来实现。所述逻辑1722的指令可以从易失性存储器1710和/或非易失性存储器1714中读取,并由一个或多个处理器1704执行。易失性存储器1710和非易失性存储器1714还可提供用于存储由逻辑1722所使用的数据的存储库。
易失性存储器1710和非易失性存储器1714可以包含多个存储器,包含用于在程序执行期间存储指令和数据的主随机存取存储器(RAM)以及其中存储只读非暂时性指令的只读存储器(ROM)。易失性存储器1710和非易失性存储器1714可以包含文件存储子系统,其为程序和数据文件提供永久性(非易失性)存储。易失性存储器1710和非易失性存储器1714可以包含可移动存储系统,如可移动闪速存储器。
总线子系统1718提供用于允许数据处理系统1720的各种组件和子系统根据需要彼此通信的机构。虽然将通信网络接口1712示意性地描绘为单个总线,但总线子系统1718的一些实施例可以利用多个相异的总线。
本领域的技术人员将容易地显而易见,计算装置1700可以是装置,如智能电话、台式计算机、膝上型计算机、机架安装式计算机系统、计算机服务器或平板计算机装置。如本领域中通常已知的,计算装置1700可以被实施为一系列多个联网计算装置。另外,计算装置1700将通常包含操作系统逻辑(未示出),其类型和性质在所属领域中是众所周知的。
额外术语和解释
本文中所使用的术语应被赋予相关领域中的普通含义,或由其在上下文中的使用所指示的含义,但如果提供明确的定义,则以所述含义为准。
“支持向量机器”是指具有相关联学习算法的监督学习模型,所述学习算法分析用于分类和回归分析的数据。给定一组训练实例,每个训练实例均标记为属于两个类别中的一个或另一个,则SVM训练算法构建模型,所述模型将新实例分配给一个类别或另一个类别,使其成为非概率二进制线性分类器。SVM模型将实例表示为空间中的点,并进行映射,使得单独类别的实例以尽可能宽的明显间隙划分。然后,将新实例映射到相同的空间,并根据它们落在间隙的哪一侧来预测所属的类别。除了执行线性分类外,SVM还可以使用所谓的内核策略有效地执行非线性分类,将其输入隐式地映射到高维特征空间。
“内核”是指内核函数,其在高维隐式特征空间中操作,而无需计算所述空间中数据的坐标,而是通过简单地计算特征空间中所有数据对的投影之间的内积。此操作通常在计算上比坐标的显式计算更便宜。当与SVM一起使用时,此方法被称作“内核策略”。
“ReLU”是指整流函数,即被定义为其输入的正部分的激活函数。它也被称为斜坡函数,并且类似于电信号理论中的半波整流。ReLU是深度神经网络中常用的激活函数。
“损失函数”,也被称作代价函数或误差函数(不要与高斯误差函数混淆),是将一个或多个变量的值映射到直观地表示与那些值相关联的某种“代价”的实数上的函数。
“双曲正切函数”是指形式为tanh(x)=sinh(x)/cosh(x)的函数。tanh函数是人工神经网络中常用的激活函数。像S形一样,tanh函数也是S形的(“s”形),但是输出范围为(-1,1)的值。因此,对tanh的强烈负输入将映射为负输出。此外,只有零值输入映射到近零输出。这些特性使得网络在训练期间不太可能“卡住”。
“S型函数”是指形式为f(x)=1/(exp(-x))的函数。S型函数用作人工神经网络中的激活函数。它具有将宽范围的输入值映射到范围为0至1或有时为-1至1的特性。
“反向传播”是指在人工神经网络中使用的算法,用于计算待用于网络中的权重计算中所需的梯度。它通常用于训练深度神经网络,术语是指具有多于一个隐藏层的神经网络。对于反向传播,在事例通过网络进行传播之后,损失函数计算网络输出与其预期输出之间的差值。
“Softmax函数”是指形式为f(xi)=exp(xi)/sum(exp(x))的函数,其中在一组x上取得总和。Softmax在人工神经网络的不同层(通常在输出层)处使用,以预测输入到这些层的分类。Softmax函数计算事件xi在‘n’个不同的事件中的概率分布。一般来说,此函数计算每个目标类别在所有可能的目标类别中的概率。计算出的概率有助于预测目标类别在输入中表示。使用Softmax的主要优点是输出概率范围。范围将从0到1,并且所有概率的总和将等于一。如果将Softmax函数用于多分类模型,它将返回每个类别的概率,并且目标类别将具有高概率。该公式计算给定输入值的指数(幂)和输入中所有值的指数值之和。然后,输入值的指数与指数值之和的比就是Softmax函数的输出。
“CTC损失函数”是指连接性时间分类、一种类型的神经网络输出和相关联的评分功能,用于训练诸如LSTM网络之类的递归神经网络(RNN)以解决时序可变的序列问题。CTC网络具有连续输出(例如Softmax),其可通过训练拟合以对标记的概率进行建模。CTC不会尝试去学习边界和时序:如果标签序列仅在对齐方式上有所不同,忽略空白,则认为它们是等效的。等效的标记序列可以通过多种方式发生-使得评分成为一项艰巨的任务。幸运的是,有一种有效的向前-向后算法。然后,可以将CTC分数与反向传播算法一起使用以更新神经网络权重。适合CTC的神经网络的替代方法包含隐式马尔可夫模型(hidden Markovmodel;HMM)。
“门控递归单元(Gated Recurrent Unit;GRU)”是指递归神经网络中的门控机制。与LSTM相比,GRU可在较小数据集上展现更好的性能。与LSTM相比,GRU具有较少的参数,因为它们没有输出门。
“波束搜索”是指启发式搜索算法,所述算法通过扩展有限集中最有希望的节点来探索图式。波束搜索是最佳优先搜索的优化,减少了其存储器需求。最佳优先搜索是图形搜索,根据某种启发式算法对所有部分解(状态)进行排序。但是在波束搜索中,仅保留预定数量的最佳局部解作为候选。因此,这是贪婪算法。波束搜索使用广度优先搜索来构建其搜索树。在树的每个级别,它都会生成当前级别的状态的所有后继者,并按启发式成本的升序对其进行排序。但是,它仅在每个级别上存储预定数量β的最佳状态(称为波束宽度)。接下来仅扩展那些状态。波束宽度越大,删除的状态越少。对于无限的波束宽度,不会删除任何状态,并且波束搜索与广度优先搜索相同。波束宽度限制了执行搜索所需的存储器。由于可能会删除目标状态,因此波束搜索会牺牲完整性(保证算法将以解终止(如果存在的话))。波束搜索不是最佳的(也就是说,无法保证它将找到最佳解)。通常,波束搜索返回找到的第一解。用于机器平移的波束搜索是另一种情况:一旦达到配置的最大搜索深度(即平移长度),所述算法将评估在各种深度的搜索期间找到的解,并返回最佳解(概率最大的解)。波束宽度可以是固定的或可变的。一种使用可变波束宽度的方法以最小宽度开始。如果找不到解,则将波束加宽并重复所述程序。
“Adam优化器”是指优化算法,所述算法可以代替经典的随机梯度下降程序来使用以基于训练数据更新网络权重迭代。随机梯度下降可为所有权重更新保持单一学习率(称为α),并且训练期间学习率不会改变。对于每个网络权重(参数),都将维持学习率,并随着学习的发展而分别进行调整。Adam结合了随机梯度下降的其它两个扩展的优点。具体而言,自适应梯度算法(AdaGrad)可以保持每参数的学习率,从而改进稀疏梯度问题(例如自然语言和计算机视觉问题)的性能,而均方根传播(RMSProp)也可以保持每参数的学习率,所述学习率根据最近的权重梯度幅度的平均值(例如,改变速度有多快)进行调整。这意味着所述算法在在线和非静态问题(例如嘈杂)上效果很好。Adam认识到AdaGrad和RMSProp两者的好处。Adam并没有像RMSProp中那样根据平均第一力矩(均值)调整参数学习率,而是利用了梯度第二力矩(无中心方差)的平均值。具体来说,所述算法计算梯度和平方梯度的指数移动平均值,并且参数β1和β2控制这些移动平均值的衰减率。移动平均值的初始值以及β1和β2值都接近1.0(建议)会导致力矩估算值偏向零。通过首先计算偏差估计值,然后再计算偏差校正的估计值,可以克服此偏差。
“测定物”是指在PCR反应混合物中,两个目标特异性引物或两个引物以及用于扩增目标的探针。
“正向引物”是指与扩增子的5′末端侧接的寡核苷酸。反向引物和正向引物在PCR反应中一起使用以扩增目标。
“稀释剂”是指在将样品或标准品加入PCR反应之前用于对其进行稀释的反应剂。
“数据收集”是指在仪器运行期间,仪器从反应板的每个孔中检测荧光数据的过程。仪器将信号转换为电子数据,并将数据保存在实验文件中。
“ROX染料”是指惰性染料,其荧光在反应过程中不会改变,并且可以添加到定量实时PCR反应中,以归一化由于伪影(例如移液错误或仪器限制)而可能发生的孔间差异。ROX惰性参比染料由5-羧基-X-若丹明在10mM Tris-HCl(pH 8.6)、0.1mM EDTA和0.01%TweenTM-20中的25μM溶液构成。尽管许多仪器要求使用最终浓度为500nM的染料,但是具有优化过滤器设置的新型仪器要求使用50nM的染料。
“参比染料”是指参见ROX染料。
“惰性参比”是指产生与PCR扩增无关的荧光信号的染料,并且所述染料以恒定的浓度添加到每个反应中。因为惰性参考信号在所有孔中都应该是一致的,所以它用于对报告染料信号进行归一化,以解决由于孔间体积微小差异而引起的非PCR相关的荧光波动。对惰性参考信号的归一化通常会在技术复制中产生具有非常高的精度的数据。
“报告”是指用于检测扩增的荧光染料。通过
“反向引物”是指与扩增子的3′末端侧接的寡核苷酸。反向引物和正向引物在PCR反应中一起使用以扩增目标。
本文中“电路系统”是指具有至少一个分立电路的电路系统;具有至少一个集成电路的电路系统;具有至少一个专用集成电路的电路系统;形成通用计算装置的电路系统,所述通用计算装置由计算机程序(例如,由至少部分地执行本文中所描述的过程或装置的计算机程序配置的通用计算机,或由至少部分地执行本文中所描述的过程或装置的计算机程序配置的微处理器)配置;形成存储器装置(例如,多种形式的随机存取存储器)的电路系统;或形成通信装置(例如,调制解调器、通信开关或光电设备)的电路系统。
本文中“固件”是指体现为存储于只读存储器或介质中的处理器可执行指令的软件逻辑。
本文中“硬件”是指体现为模拟或数字电路系统的逻辑。
本文中“逻辑”是指机器存储器电路、非暂时性机器可读介质和/或借助于其材料和/或材料能量配置包括可以被应用以影响装置操作的控制和/或程序信号和/或设置和值(例如电阻、阻抗、电容、电感、电流/电压等级等)的电路系统。磁性介质、电子电路、电气和光学存储器(易失性和非易失性两者)以及固件是逻辑的实例。逻辑专门排除纯信号或软件本身(然而,不排除包括软件且由此形成物质的配置的机器存储器)。
本文中“软件”是指实施为机器存储器(例如,读取/写入易失性或非易失性存储器或介质)中的处理器可执行指令的逻辑。
本文中,对“一个实施例”或“实施例”的引用未必指代同一实施例,但它们可以指相同的实施例。除非上下文清楚地另外要求,否则在整个说明书和权利要求书中,词语“包括(comprise/comprising)”等应在包含性意义上而不是排他性或穷举性意义上解释;也就是说,在“包含但不限于”的意义上解释。除非明确限制为单个或多个,否则使用单数或复数的词也分别包含复数或单数。此外,词语“本文”、“上文”、“下文”和类似意义的词语,当在本申请中使用时,应指本申请整体,而不是指本申请的任何特定部分。当权利要求书在提及两个或更多个项目的列表时使用词语“或”时,所述词语涵盖所述词语的以下所有解释:列表中项目的任一个、列表中的所有项目,以及列表中的项目的任何组合,除非明确限制为某一个或另一个。本文中未明确定义的任何术语具有如相关领域的技术人员通常理解的常规含义。
本文描述的各种逻辑功能操作可以使用反映所述操作或功能的名词或名词短语引用的逻辑来实施。例如,关联操作可以由“关联器”或“相关器”实行。同样地,可以通过“开关”进行通断,通过“选择器”进行选择等。
虽然前述公开内容论述说明性方面和/或实施例,但应注意,可在不脱离如所附权利要求书限定的所描述方面和/或实施例的范围的情况下在本文中进行各种改变和修改。此外,尽管可以单数形式描述或要求所描述的方面和/或实施例的元件,但除非明确陈述限于单数,否则涵盖复数形式。另外,除非另外说明,否则任何方面和/或实施例的全部或一部分可与任何其它方面和/或实施例的全部或一部分一起利用。
- 用于基于阵列的PCR的图像驱动质量控制
- 一种基于数字PCR平台的miRNA检测质量控制试剂盒及其使用方法