一种不受语意影响的语音信号情感识别方法及系统
文献发布时间:2023-06-19 19:14:59
技术领域
本发明属于语音信号处理技术领域,具体地涉及一种不受语意影响的语音信号情感识别方法及系统。
背景技术
语音信号处理中,语音识别作为一个重要的研究领域,已经有很长的研究历史,其中语音特征提取与情感识别又是其中的一个重要方面。
现阶段已有的语音情感识别方法和应用繁多,在1972年,Williams发现人的情感变化对语音的基音轮廓有很大的影响,这是最早开展的语音情感方面的研究之一。1990年,麻省理工学院多媒体实验室构造了一个“情感编辑器”对外界各种情感信号进行采样,如人的语音信号、脸部表情信号等来识别各种情感。1996年日本东京Seikei大学提出情感空间的概念并建立了语音情感模型。2000年,Maribor大学的Vladimir Hozjan研究了基于多种语言的语音情感识别。在国内,语音情感识别的研究起步较晚。2001年,东南大学赵力等人提出语音信号中的情感识别研究。2003年,北京科技大学等人将BDI Agent技术应用与情感机器人的语音识别技术研究中。
近几年来发表的语音情感识别专利也有很多,中国专利CN112151071B公开了一种基于混合小波包特征深度学习的语音情感识别方法,该方法使用了深度学习,有效的提高了识别的准确率。中国专利公开号CN115050395A提供了一种多领域统计特征和改进CNN的含噪语音情感识别方法,该方法对语音信号进行了增强,同时加入了去除噪音等步骤,在实际使用中有着很好的性能。
上述的这些种类的语音情感识别方法各有优点,应用于各个领域,但是目前语音情感识别方法都没有排除语意对情感识别的影响,具有的代表性较小。如何排除语意对情感识别的影响,一直是难以解决的难题。
发明内容
基于现有技术存在的问题,本发明提供一种不受语意影响的语音信号情感识别方法及系统,其本发明解决传统语音信号情感识别训练方式中语意影响因素较大的问题;本发明提出的一种不受语意影响的用于直接识别语音自身所带有的情感特征的方法,其采用了无语意的语音情感数据库进行特征提取以及分类识别训练,同时该方法也可以和其他语意识别方法相结合,大大提高最终的情感识别率。
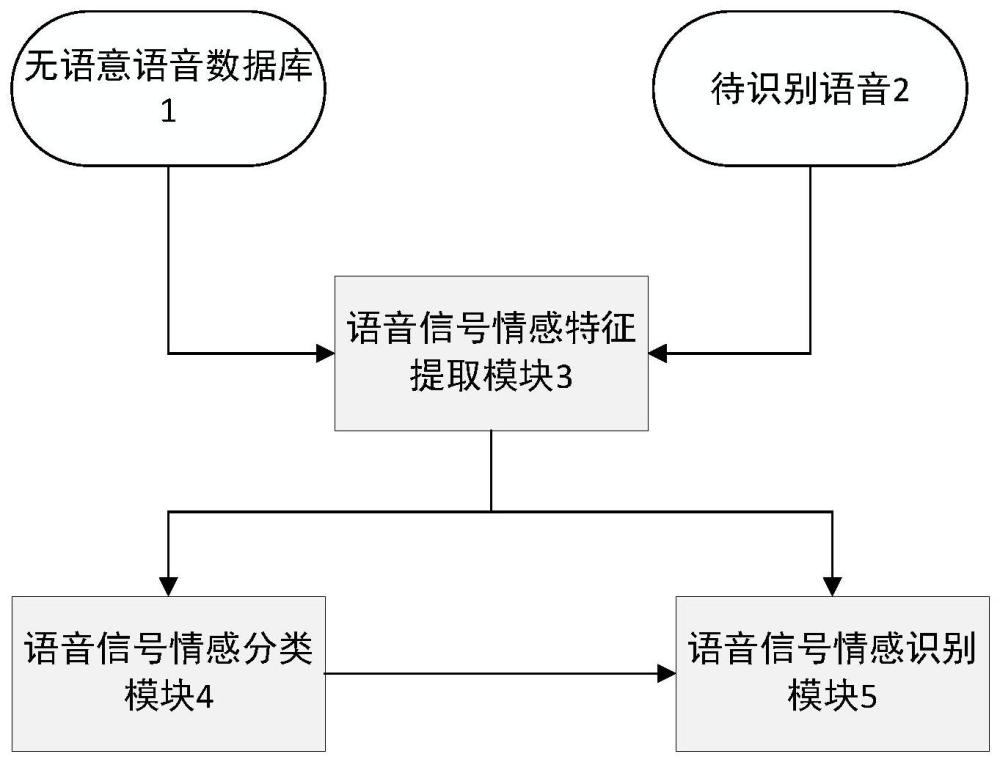
依据本发明技术方案的第一方面,本发明提出一种不受语意影响的语音信号情感识别系统,所述不受语意影响的语音信号情感识别系统包括无语意语音数据库、待识别语音、语音信号情感特征提取模块、语音信号情感分类模块和语音信号情感识别模块,无语意语音数据库和待识别语音分别与语音信号情感特征提取模块连接,语音信号情感特征提取模块分别连接了语音信号情感分类模块和语音信号情感识别模块,语音信号情感分类模块和语音信号情感识别模块相连接。
其中,所述的无语意语音数据库、待识别语音构成了整个系统最开始的语音信号输入模块,所述的语音信号情感分类模块、语音信号情感识别模块构成了整个系统最末端的语音信号情感分类识别模块,所述的语音信号情感特征提取模块置于语音信号输入模块和语音信号情感分类识别模块之间。
进一步地,所述的语音信号情感分类模块和语音信号情感识别模块相连接,使得语音信号情感分类模块中得到的分类标准可以输入并存储在语音信号情感识别模块中。
优选地,无语意语音数据库用于提供无语意的语音信号进行分类训练,分类训练过程为采用SVM算法对带有标签的语音信号进行处理。
优选地,待识别语音为等待识别的语音且用于最终语音情感识别测试。
更优选地,语音信号情感特征提取模块用于将输入的语音信号转化为分类识别所需的多个特征数值。
进一步地,语音信号情感分类模块用于训练情感特征数据并得出分类标准。
更进一步地,语音信号情感识别模块用于保存分类标准以及对待识别语音信号进行情感识别分类。
依据本发明技术方案的第二方面,本发明提出一种不受语意影响的语音信号情感识别方法,其使用上述不受语意影响的语音信号情感识别系统,其包括以下步骤:
步骤S1,判断语音数据库是否具备语音信号情感分类标准,如果语音数据库具备语音信号情感分类标准,再跳转到步骤S2识别语音步骤;
步骤S2,识别语音步骤,针对步骤S1判断得到的语音数据库进行语音识别,按照语音信号情感识别系统的分类标准对语音数据库中的语音进行语音分类;
步骤S3,情感特征提取步骤,针对步骤S2中得到的分类后的语音数据库中的语音进行情感特征提取;
步骤S4,语音信号情感识别步骤,对提取情感特征的语音数据库中的语音进行识别,判断是否属于具有情感的语音信号;
步骤S5,判断语音识别是否结束,对语音数据库中的语音逐一进行识别,全部语音识别完成时结束识别程序;未完成全部语音识别时,返回到步骤S1进行新一轮次语音识别。
进一步地,在步骤S1的判断语音数据库是否具备语音信号情感分类标准中,如果语音数据库不具备语音信号情感分类标准,再跳转到步骤S11无语意语音数据库训练步骤。
与现有技术相比,本发明不受语意影响的语音信号情感识别方法及系统的有益技术效果如下:
1:采用的无语意的语音数据库,可以和其他识别方法有效结合;
2:使用改进EMD算法处理信号,自适应能力强;
3:分类模块对数据多次分析,使识别效果达到最好;
4:信号处理采取的最佳分帧方法,提高了系统的识别率。
附图说明
图1是依据本发明不受语意影响的语音信号情感识别系统的结构示意图。
图2是依据本发明不受语意影响的语音信号情感识别系统的运行示意图。
附图1中的序号和结构及名称如下:
1为无语意语音数据库、2为待识别语音、3为语音信号情感特征提取模块、4为语音信号情感分类模块、5为语音信号情感识别模块。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
需要注意,本发明中提及的“第一”、“第二”等概念仅用于对不同的装置、模块或单元进行区分,并非用于限定这些装置、模块或单元所执行的功能的顺序或者相互依存关系。
需要注意,本发明中提及的“一个”、“多个”的修饰是示意性而非限制性的,本领域技术人员应当理解,除非在上下文另有明确指出,否则应该理解为“一个或多个”。
本发明提供一种不受语意影响的语音信号情感识别方法及系统,其中,该语音信号情感识别系统由语音信号输入模块、语音信号情感特征提取模块、语音信号情感分类模块和语音信号情感识别模块四个部分组成。语音数据库提供无语意的语音信号进行分类训练,首先将数据库中的语音信号样本代入情感特征提取模块当中进行特征提取,之后将所有样本提取出的语音信号情感特征输入进语音信号情感分类模块进行分类,最后通过语音信号情感识别模块保存分类标准。当得到分类标准后,就可以对待识别语音信号进行情感识别,待识别语音信号经过预处理后输入进情感特征提取模块提取出情感特征,然后将情感特征代入语音信号情感识别模块,根据分类标准进行识别分类。
本发明一种不受语意影响的语音信号情感识别方法及系统适用于中文语音信号情感识别,其中排除了语音信号中语意的影响因素,可以和其他语音识别系统进行融合,大大提高识别率,在实际应用中有着很大的作用。本发明解决了现在人机交互应用场景上的情感识别等问题。
本发明利用希尔伯特黄变换实现了语音处理平稳以及非线性信号的处理,同时利用EMD改进算法去除语意影响的情况下,找到语音本身所带有的情感特征,并通过这种情感特征进行语音情感识别。本发明基于希尔伯特黄变换原理改进出来的算法,相较于傅里叶变换以及小波变换等方法,其自适应能力更强,且更能体现出原始信号的特征。
下面根据附图1,本发明提供一种不受语意影响的语音信号情感识别系统,所述的不受语意影响的语音信号情感识别系统包括无语意语音数据库1、待识别语音2、语音信号情感特征提取模块3、语音信号情感分类模块4和语音信号情感识别模块5,无语意语音数据库1和待识别语音2分别与语音信号情感特征提取模块3连接,语音信号情感特征提取模块3分别连接了语音信号情感分类模块4和语音信号情感识别模块5,语音信号情感分类模块4和语音信号情感识别模块5相连接。
所述的无语意语音数据库1、待识别语音2构成了整个系统最开始的语音信号输入模块,所述的语音信号情感分类模块4、语音信号情感识别模块5构成了整个系统最末端的语音信号情感分类识别模块,所述的语音信号情感特征提取模块3置于语音信号输入模块和语音信号情感分类识别模块之间。
所述的语音信号情感分类模块4和语音信号情感识别模块5相连接,使得语音信号情感分类模块4中得到的分类标准可以输入并存储在语音信号情感识别模块5中。
无语意语音数据库1,其用于提供无语意的语音信号进行分类训练,分类训练过程为采用SVM算法对带有标签的语音信号进行处理;
待识别语音2,其为等待识别的语音且用于最终语音情感识别测试;
语音信号情感特征提取模块3,其用于将输入的语音信号转化为分类识别所需的多个特征数值;优选为转化为分类识别所需的九个特征数值;特征数值分别为:大能量的中心频率放在第一组、中能量的放在第二组、小能量的放在第三组,并计算出每组的最大、最小、平均中心频率,共九个特征数值。
语音信号情感分类模块4,其用于训练情感特征数据并得出分类标准;
语音信号情感识别模块5,其用于保存分类标准以及对待识别语音信号进行情感识别分类。
不受语意影响的语音信号情感识别系统中,语音信号情感特征提取模块是整个不受语意影响的语音信号情感识别系统的核心,所有的语音信号都需要通过语音信号情感特征提取模块处理成可进行分类识别的特征数据,因此信号处理至关重要。在一个实施例中,信号处理采用以下处理手段:
(1)语音信号情感特征提取模块需要先对语音信号进行分帧处理,即将一个完整的语音信号分割成多个30ms的帧信号,每个帧信号之间采用7.5ms帧移平滑过渡,相当于将语音信号的最基础的特征信息分解。
(2)将一个样本语音信号的所有分帧信号使用ICEEMDAN进行处理,即将每个帧信号分解成多个IMF分量,提取出三个能量最大的IMF分量并记录其中心频率。
(3)将每个帧信号提取出的三个中心频率根据能量大小进行分组,即将每个帧信号大能量的中心频率放在一组、中能量的放在一组、小能量的放在一组,并计算出每组的最大、最小、平均中心频率,共九个特征数值。所述“大能量”、“中能量”和“小能量”是指每个帧信号中提取出的三个能量最大的IMF分量按照能量大小进行排序,并依次做为“大能量”、“中能量”和“小能量”。
语音信号情感分类模块和语音信号情感识别模块是实现情感识别的关键模块,其训练分类部分和应用识别部分是整个语音信号识别系统的最终处理输出环节。
根据本发明提供的语音信号情感识别系统,将语音信号情感分类模块和语音信号情感识别模块置于特征提取模块之后。
进一步地,无语意语音数据库将无语意的语音信号输入特征提取模块,并按照上述特征提取模块内处理信号的方法处理后,将得到的九个特征数值输入进语音信号情感分类模块。
进一步地,语音信号情感分类模块将带有情感标签的特征数据按照七比三划分训练集与测试集,并使用改进后的多分类支持向量机算法对训练集进行训练,训练后采用测试集测试得到识别率,并且划分出语音情感的分类标准,重复上述步骤十次,记录其中测试集识别率最大的分类标准,将其输入进语音信号情感识别模块并保存。进一步地,“七比三划分”具体的操作是将数据库中每种情感类型的语句随机选取70%为训练集,30%为测试集。
进一步地,将需要进行情感识别的语音信号输入特征提取模块,得到其特征数据并代入语音信号情感识别模块,并将其与保存的分类标准进行对比分类,从而完成语音信号情感识别。所述的分类标准为SVM算法对训练集训练完成后得到的内部标准,对比分类即通过将特征数据代入训练后SVM算法中并得到识别结果的方法。
根据实际使用环境和所需进行情感识别的语音的变化,可以在特征提取模块前加入一些去噪、滤波等信号处理过程,从而提高识别准确度。
下面结合附图1和图2,详细描述本发明的一种不受语意影响的语音信号情感识别方法,不受语意影响的语音信号情感识别方法采用不受语意影响的语音信号情感识别系统对待识别语音信号进行情感识别,不受语意影响的语音信号情感识别系统为上述实例中的语音信号情感识别系统,不受语意影响的语音信号情感识别方法的实施过程如下,其包括以下步骤:
步骤S1,判断语音数据库是否具备语音信号情感分类标准,如果语音数据库具备语音信号情感分类标准,再跳转到步骤S2识别语音步骤;
步骤S2,识别语音步骤,针对步骤S1判断得到的语音数据库进行语音识别,按照语音信号情感识别系统的分类标准对语音数据库中的语音进行语音分类;
步骤S3,情感特征提取步骤,针对步骤S2中得到的分类后的语音数据库中的语音进行情感特征提取;
步骤S4,语音信号情感识别步骤,对提取情感特征的语音数据库中的语音进行识别,判断是否属于具有情感的语音信号;
步骤S5,判断语音识别是否结束,对语音数据库中的语音逐一进行识别,全部语音识别完成时结束识别程序;未完成全部语音识别时,返回到步骤S1进行新一轮次语音识别。
在步骤S1的判断语音数据库是否具备语音信号情感分类标准中,如果语音数据库不具备语音信号情感分类标准,再跳转到步骤S11无语意语音数据库训练步骤。
步骤S11无语意语音数据库训练步骤,其针对不具备语音信号情感分类标准的语音数据库进行训练,直至语音数据库具备语音信号情感分类标准;
步骤S12,第二情感特征提取步骤,针对步骤S11中得到的训练后的语音数据库中的语音进行情感特征提取;
步骤S13,语音信号情感分类步骤;针对经过第二情感特征提取步骤之后的语音数据库中的语音进行语音信号情感分类,将带有情感标签的特征数据按照七比三划分训练集与测试集,并使用SVM算法对训练集进行训练,训练后采用测试集测试得到识别率,并且划分出语音情感的分类标准。所述的分类标准为SVM算法对训练集训练完成后得到的内部标准,之后通过将语音信号的特征数据代入训练后的SVM算法划分出情感类别;
步骤S4,语音信号情感识别步骤,对语音信号情感分类的语音数据库中的语音进行识别,判断是否属于具有情感的语音信号;
步骤S5,判断语音识别是否结束,对语音数据库中的语音逐一进行识别,全部语音识别完成时结束识别程序;未完成全部语音识别时,返回到步骤S1进行新一轮次语音识别。
在本发明的优选实施例中,在得出分类标准的过程中,无语意语音数据库先将语音信号输入进情感特征提取模块,然后通过语音信号情感分类模块对特征数据进行处理得到一个分类标准,并在分类达到十次之后,根据比对测试集的识别率,选择识别率最高的作为最佳分类标准,将效果最好的分类标准输入语音信号情感识别模块并保存。此时判断是否结束识别,当判断不结束时返回系统最开始。
在判断具有分类标准后,就可以开始对待识别语音信号进行情感识别,在此过程中,语音信号通过特征提取模块后,将情感特征数据输入语音信号情感识别模块,并与保存的分类标准进行比对分类
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 一种中国民族五声调式情感识别方法及系统
- 一种基于局部惩罚随机谱回归的语音信号情感识别方法
- 一种基于局部惩罚随机谱回归的语音信号情感识别方法