一种面向分布式机器学习的数据划分方法
文献发布时间:2023-06-19 10:48:02
技术领域
本发明属于分布式机器学习领域,具体涉及混布负载场景下分布式机器学习模型训练的数据划分方法。
背景技术
随着互联网行业的发展,互联网及相关产业拥有的数据中心(Datacenter)在数量、规模上得到了迅猛发展。数据中心是互联网及相关产业的信息化基础设施,为互联网业务的运营提供计算、存储和网络等软硬件资源。近些年,虚拟化技术、容器化技术以及服务器整合技术在数据中心得到普遍应用,在提高了数据中心弹性扩增能力的同时,还提高了数据中心整体资源利用率。传统数据中心将在线负载和离线负载隔离部署,离线负载属于延迟非敏感型负载,其重要目标是为了追求对数据处理的高吞吐量。在线负载属于延迟敏感型负载对数据处理请求的响应延迟要求较高,在运行当中具有较强的波动性。因此,这使得传统数据中心的资源利用率较低。混布负载技术为了进一步提升资源利用率将延迟敏感型负载和延迟非敏感型负载部署到同一台计算设备共享资源。混布负载场景下为了保证延迟敏感的在线服务的服务质量(Quality of Service)所以使得离线批处理负载可使用的计算资源处于差异化的状态。
分布式机器学习(Distributed Machine Learning)就是一种在混布负载场景下的离线批处理负载,随着数据规模的扩大,机器学习逐渐从集中式向分布式发展。通常情况下分布式机器学习采用参数服务器架构在同步模式下进行训练,在训练期间,每个worker使用分配的数据计算模型训练,并将模型参数发送到相应的参数服务器。然后,worker从参数服务器获取新的模型参数,以便使用最新的模型参数值。同时,参数服务器从workers收到的模型参数,并通过参数更新将最新的模型参数值发送回workers。这个过程在分布式机器学习模型训练的过程中迭代发生,直到全局模型收敛。此时数据样本依据批尺寸被静态、对称的分配给每一个计算节点,使得分布式机器学习模型训练时间大大延长。当前分布式机器学习领域数据划分的方法主要有随机采样发,置乱切分法等,他们均是将数据行随机打乱然后划分。另外一些数据划分策略是关于特殊负载的数据划分即将存在依赖关系的数据划分在一起。还有一些数据划分策略,基于Hadoop集群,在任务开始前根据每个节点的计算能力为每个节点分配数据。现有方法存在以下问题:(1)混布负载场景下无法有效解决分布式机器学习模型训练计算效率低下问题。
分布式机器学习领域现有的数据划分方法,在模型训练前将数据样本依据批尺寸静态、对称的分配给每一个计算节点。在混布负载场景中由于物理节点间存在性能差异,或者物理节点上剩余可用资源存在差异以及并发执行的多个应用之间存在共享资源竞争等原因,造成worker在节点间获得的计算能力非对称的情况。在这种情况下,拥有计算能力相对较强的节点势必会率先处理完成本地分布的数据,然后等待其他节点完成数据处理,节点间数据处理时间的非对称性无疑会增加作业的总体执行时间。
(2)无法保证分布式机器学习训练模型的最终精度。
分布式机器学习模型训练的一个重要目标就是要保证模型训练的精度值,现有的方法有以负载在节点中响应时间为度量,然后按照响应时间分配数据对数据划分。有的在任务开始前根据每个节点的计算能力为每个节点分配数据,并且该策略可以动态地调整和重新分配数据。然后,现有方法没有考虑到数据划分结果会对模型最终精度产生影响,使得模型精度不能达到我们期望的精度值。
发明内容
针对上述问题,本发明提出了一种分布式机器学习数据划分方法。本发明首先进行了验证实验,观察到每个任务使用的资源量不同时,在BSP模式下,整个系统一轮完成时间总是取决于资源使用量最少的那个任务。这无疑浪费了大量的资源,严重拖慢整个系统的完成时间;然后根据量化分析结果,定义了问题模型和优化目标,即在保证分布式机器学习模型训练精度值的前提下,提高整个分布式机器学习模型训练作业的计算效率;最后本发明提出一种基于强化学习的分布式机器学习数据划分算法-DQ-DPS算法,实验测试表明,与现在有的传统数据划分策略相比DQ-DPS算法使整个分布式机器学习模型训练的每轮计算效率显著提高。
本发明提出一种基于Q-Learning算法改进的DQ-DPS算法,使用经验回放,即用一个经验回放内存来存储经历过的数据,每次更新参数的时候从经验回放内存中抽取一部分的数据来用于更新,以此来打破数据间的关联。DQ-DPS存在两个结构完全相同但是参数却不同的网络,预测Q估计的网络MainNet使用的是最新的参数,而预测Q现实的神经网络TargetNet参数使用的是之前的参数,Q(s,a|θ)表示当前网络MainNet的输出,用来评估当前状态动作对的值函数;maxQ(s,a|θ′)表示TargetNet的输出,可以解出target Q,因此当对环境采取动作a时就可以根据上述公式计算出Q并根据LossFunction更新MainNet的参数,每经过一定次数的迭代,将MainNet的参数复制给TargetNet。
结合以上过程,我们目的是要进行批尺寸参数优化的选取工作。本发明所述的机器学习数据划分方法主要分为四个步骤:初始化、神经网络训练、状态选取、数据划分。在本方法中,有七个基本参数:用于经验回放的内存M,容量为N,Q值网络权重θ,目标Q值网络权重θ′,模型精度阈值ACC,模型训练总时间阈值T
上述方法按以下步骤实现:
(1)初始化。始化经验回放内存M,它的容量为N,初始化Q网络,随机生成权重θ,初始化目标Q值网络,权重为θ′=θ,初始化模型精度阈值ACC与训练总时间限制阈值T
(2)神经网络训练。
首先定义训练次数K,初始化状态队列Ф(S)。从t时刻开始,每次从状态队列取出状态S
(3)状态选取
对于每一个存在队列Ф(S)中的状态S
(4)数据划分
执行完上述步骤选择出最佳的状态S,将状态S中的批尺寸设置应用到整个集群当中直到训练完成。
(5)结束:终止对分布式机器学习的数据划分功能。
附图说明
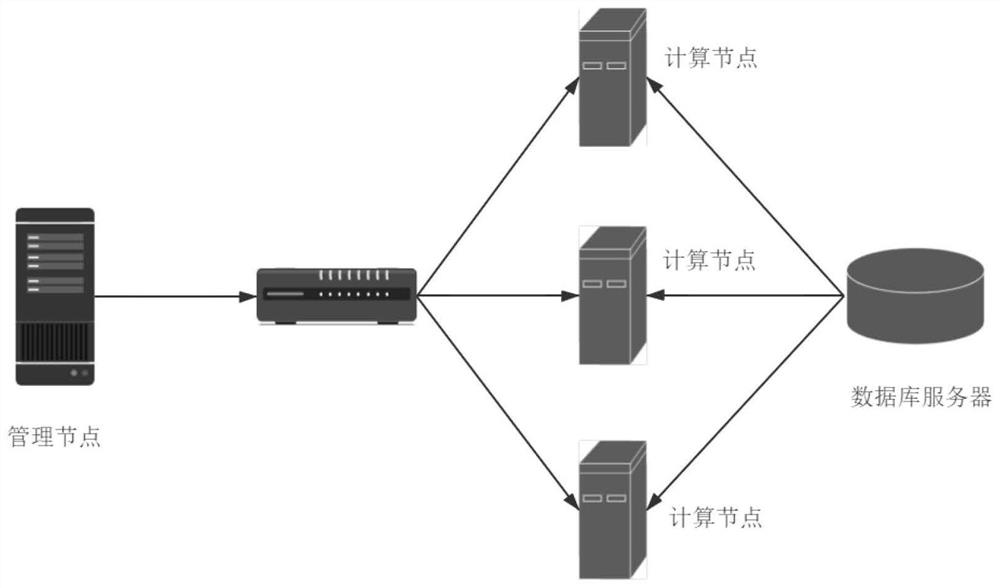
图1为本发明的依附的集群平台。
图2为本发明的主架构图。
图3为本发明的主网络和目标网络的学习过程。
图4为本发明的主神经网络架构图。
图5为本发明的数据划分流程图。
具体实施方式
下面结合附图和具体实施方式对本发明加以说明。
本发明所提出的分布式机器学习数据划分方法可依附于现有TensorFlow平台,通过修改和新增相应的功能模块实现。图1是本方法所依附的TensorFlow平台的部署图。该平台由多个计算机服务器(平台节点)组成,服务器间通过以太网连接。平台节点分为两类:包括一个管理节点和多个计算节点(Worker)。
图二为本发明方法依附TensorFlow平台的主架构图,其包含三个核心软件模块:批尺寸管理器(Batch Size Manager)包含:精度预测模块(AccuracyPrediction)、批尺寸选取模块(BatchSizeSelectionModule),参数服务器模块(Parameter Server)。其中,Batch Size Manager负责收集各个计算节点的环境状态信息S和批尺寸管理,仅在管理节点上部署;AccuracyPrediction负责计算当前状态下模型最终能达到的精度值情况。BatchSizeSelectionModule负责批尺寸数据的构建,根据当前计算节点的资源情况划分数据。Parameter Server负责梯度计算,在迭代开始时,批尺寸管理器根据环境状态信息S计算出每个worker应配置的批尺寸大小,每个worker从批尺寸管理器拉取相应批尺寸大小的数据进行本地训练,将各自的梯度参数发送给参数服务器,参数服务器进行梯度聚合后各个worker拉取相应的参数进行下一次迭代计算。
图3为本发明的主网络和目标网络的学习过程,在有监督学习中,数据之间都是独立的。因此本发明使用经验回放,即用一个内存来存储经历过的数据,每次更新参数的时候从经验回放内存中抽取一部分的数据来用于更新,以此来打破数据间的关联。本发明存在两个结构完全相同但是参数却不同的网络,预测Q估计的网络MainNet使用的是最新的参数,而预测Q现实的神经网络TargetNet参数使用的是之前的参数,Q(s,a|θ)表示当前网络MainNet的输出,用来评估当前状态动作对的值函数;maxQ(s,a|θ′)表示TargetNet的输出,可以解出target Q,因此当用户对环境采取动作a时就可以根据上述公式计算出Q并根据LossFunction更新MainNet的参数,每经过一定次数的迭代,将MainNet的参数复制给TargetNet,这样就完成了学习过程。本算法利用奖励r和Q计算出来的目标Q值作为标签,训练目标就是让Q值趋近于目标Q值,损失函数为均方误差如公式(1)所示,
L(θ)=E[(TargetQ-Q(s,a;θ))
在本发明中将模型训练作业的执行时间和模型精度是否满足:条件一:最小化任务进行一轮模型训练的最大执行时间与任务进行一轮模型训练的最小执行时间的差。条件二:最大化模型的最终精度作为环境奖励。在本性能模型中将模型训练作业的耗时和所得精度是否满足条件一和条件二作为奖赏评价。因此,设计公式(2)作为参数组合分配过程的奖励函数,其中奖励函数r定义如:
式中由于时间和精度不在一个数值量化级别上,我们需要进行归一化操作,准确率的数值范围在[0-1]范围内,不需要进行归一化操作。对于执行时间T我们采用min-max标准化方法,对执行时间进行线性变换,使其结果落到[0,1]区间内。具体归一化公式如公式(3)所示,式中T
同时为了表明执行时间和精度值之间所占的不同比重,我们在公式(3)中执行时间和精度之前分别乘上权重w
下面结合图4说明本发明的主神经网络架构设计。对于主神经网络,其解决的是一个回归问题,我们设计了一个双目标神经网络,输入状态S的特征向量和动作a,输出对应的动作价值Q(s,a),以及当前状态S下模型最终达到的精度值。对于预测精度的神经网络,由量化观测实验可知,影响模型精度的主要因素主要是批尺寸B和迭代轮次E决定,我们采用了一个三层全连接神经网络,利用梯度下降算法进行求解。为了能够更好的提取数据特征,Q值主神经采用卷积神经网络进行构建和训练,卷积层Conv1,卷积层Conv2,卷积层Conv3所采用的的激活函数(Activation)分别是ReLU,ReLU,ReLU。全连接层FC1所采用的激活函数为ReLU,全连接层FC2所采用的激活函数为Linear。卷积层的功能是对输入数据进行特征提取,其内部包含多个卷积核,组成卷积核的每个元素都对应一个权重系数和一个偏差量,类似于一个前馈神经网络的神经元。通常来讲卷积层后面通常会跟随一层池化层,池化层的作用主要是进行特征选择和信息过滤。这一操作会使得信息丢失,状态S的信息对于Q值计算至关重要,为了丢失这些信息,同时为了尽可能更多地保留数据原本信息,本发明除去了池化层的设计。
下面结合图5本发明的DQ-DPS算法流程图说明本发明方法的具体实施方法。在本实施方法中,基本参数设置如下:用于经验回放的内存符号是M,容量为M=10G,Q值网络权重θ采用随机初始化方式,目标Q值网络权重θ′=θ,模型精度阈值ACC=0.93,模型训练总时间阈值T
(1)初始化。
1.1)始化经验回放内存M=10G。
1.2)初始化Q网络,随机生成权重θ,初始化目标Q值网络,权重为θ′=θ。
1.3)初始化模型精度阈值ACC=0.93与训练总时间限制阈值T
(2)神经网络训练。
2.1)定义训练次数K,初始化状态队列Ф(S),采用有监督学习方法进行模型训练,开始时,训练数据批尺寸管理器从每个worker进行获取和收集。
2.2)定义神经网络模型,双目标神经网络中精度预测网络采用三层全连接层,Q值网络采用三个卷积层和两个全连接层。神经网络的输入为环境状态S、动作a,神经网络的输出为对应的动作价值Q(s,a)。
2.3)从t时刻开始,每次从状态队列取出状态S
2.4)此时状态队列Ф
2.5)循环终止在j+1轮,则令y
2.6)对网络参数θ执行梯度下降步骤即LossFunction:(y
(3)根据精度预测模块进行状态选取
3.1)对于每一个存在队列Ф(S)中的状态S
3.2)在3.1)基础上对于每一个存在队列Ф(S)中的状态S
3.3)更新状态表,每次进行状态记录时与之前状态的执行时间进行比较,如果当前状态的执行时间小于之前状态的执行时间,那么就将当前状态记录到状态表中。
(4)批尺寸选择模块进行数据划分
4.1)选择出最佳的状态S。
4.2)批尺寸选择模块将状态S中的批尺寸B设置应用到整个集群当中,具体操作是根据步骤4.1)选择出的最优批尺寸数值,将每个worker里神经网络参数定义模块中的批尺寸参数进行更新替换,操作完成后转到步骤(5)。
(5)结束:终止对分布式机器学习的数据划分功能。
为了充分说明本发明的DQ-DPS算法能够具有很好的性能表现,发明人进行了相关的性能测试。测试结果表明,本发明方法可适用于典型的分布式机器学习模型训练。相比于传统数据划分策略DQ-DPS算法使得分布式机器学习模型训练每一轮的计算效率显著提高,并且大大缩短各任务执行时间的差异。
性能测试将依据既有的,发明人将本发明的性能模型DQ-DPS分别与随机采样法、置乱切分法、Data Placement Strategy(下文简称为DPS)以及数据放置策略DDP进行比较。性能测试选取每轮执行时间、总执行时间时间作为性能指标,以体现本发明提出的方法在提升分布式机器学习模型训练计算效率以及缩短任务间执行时间差异的优势。
本性能评估的实验环境为模拟服务器集群环境,由4台物理机组成。实验环境配置如表3-3所示。其中1个节点作为参数服务器,3个节点作为计算节点。CPU型号为Intel(R)Xeon(R)E5-26600@2.20GHZ。运行内存为32GB,磁盘大小为1TB,带宽为千兆以太网,分布式机器学习框架为Tensorflow-1.15.0。训练VGG-16神经网络的worker1,worker2,worker3分别运行在三台计算节点上,可用的资源配置调整方案如表1所示:
表1资源配置
性能评估本发明选取机器学习领域极具代表性的数据集CIFAR-10数据集训练VGG-16神经网络。每个worker的初始批处理大小设置为64,学习率等超参数都是TensorFlow官方GitHub存储库中的默认设置。性能测试结果如表2,表3和表4所示。
表2性能测试结果(每一轮执行时间)
表3性能测试结果(总执行时间)
表2和表3显示了在不同数据划分方案下的性能。3个worker可以使用的CPU资源情况分别为:worker1可使用2个CPU,worker2可使用3个CPU,worker3可使用4个CPU。从每一轮执行时间和收敛时间上来看本发明方法表现得最好,使用本发明方法训练过程的收敛速度优于其他方案,在所有方案中,本发明方法是最佳方案,并且其优越性随着数据集的扩增而提高。
表4各个worker执行时间(s)
表4所示,集群中3个worker可以使用的CPU资源情况分别为:worker1可使用1个CPU,worker2可使用2个CPU,worker3可使用3个CPU。在应用DQ-DPS算法前,各个worker每一轮执行时间差异较大,每次都要等待最慢的worker1执行完毕后才进行下一次迭代更新计算,浪费了大量的计算资源。在应用DQ-DPS算法之后,我们根据不同的worker可利用的资源情况,选取了不同的数据大小,使得各个worker每一轮执行时间的差异大大缩短,进而从整体上提高了整个集群的计算效率。
最后应说明的是:以上示例仅用以说明本发明而并非限制本发明所描述的技术,而一切不脱离发明的精神和范围的技术方案及其改进,其均应涵盖在本发明的权利要求范围当中。
- 一种面向分布式机器学习的数据划分方法
- 一种面向分布式机器学习参数同步差异化数据传输方法