用于表面识别的原子力显微镜
文献发布时间:2023-06-19 12:14:58
相关申请的交叉引用
本申请要求优先权日期为2018年11月7日的美国临时申请62/756,958以及优先权日期为2018年11月28日的美国临时申请62/772,327的权益,上述申请的内容通过引用合并于本文。
技术领域
本发明涉及结合使用表面的特征来对该表面进行分类或识别的原子力显微镜和机器学习的用途,尤其涉及使用特征来对生物细胞进行识别或分类。
背景技术
在原子力显微镜中,附接至悬臂的尖端的探针会扫描样本的表面。在一种操作模式下,探针在其扫描时轻敲表面。当探针扫描样本时,可以控制与探针施加在样本上的加载力相关联的力向量的大小和方向。
悬臂从其平衡位置的偏转提供了信号,可以从该信号提取大量信息。例如,通过保持加载力或悬臂的偏转恒定,可以在样本上的各个点处获取样本的拓扑结构。然后,将在每个点处收集的值组织成阵列,在该阵列中,行和列识别点在二维坐标系中的位置,并且行和列处的值表示在该点处测量的属性。因此,所得到的数字阵列可以被视为图。这使得可以制作样本的图,其中,图上的每个点都指示样本表面在该点处的一些属性。在一些示例中,属性是在某一参考平面上方或某一参考平面下方的表面高度。
然而,并非只有表面高度的图像可以在扫描时被记录下来。悬臂的偏转可以用于收集样本表面的多个图像,其中,每个图像是该表面的不同属性的图。这些属性中的一些属性的示例包括探针与表面之间的粘附力、表面的刚度和粘弹性能量损失。
发明内容
本发明提供了一种用于使用由原子力显微镜获取的多维图像来识别表面,并且使用来自那些图像的信息来将表面分类到若干类别之一的方法。根据本发明,可以获取表面的多维图像,其中两个维度对应于空间维度,并且附加维度对应于在由两个空间维度识别的坐标处存在的不同物理属性和空间属性。在一些实施例中,维度是横向维度。
出现的问题是如何选择和使用这些不同的物理属性和空间属性来对表面进行识别和分类。根据本发明,将用于表面的识别和分类的属性不是预先确定的。它们是基于应用于图像数据库的机器学习的结果以及它们相应的类别来计算的。它们是被学习的。具体地,它们是通过机器学习来学习的。
在本发明的实施例之中,包括使用原子力显微镜来采集与表面的不同属性相对应的不同图,以及使用这些图或从那些图导出的参数的组合来识别或分类样本表面的那些实施例。这种方法包括:记录属于明确定义的类别的表面的示例的原子力显微镜图像;形成数据库,在该数据库中此类原子力显微镜图与它们所属的类别相关联;使用如此获取的原子力显微镜图及它们的组合,通过将该数据库拆分为训练数据和测试数据来学习如何对表面进行分类;其中,例如通过构建决策树或神经网络或它们的组合,该训练数据被用于学习如何分类;以及使用测试数据来验证由此学习的分类足够有效以超过给定的有效性阈值。
另一实施例包括将由原子力显微镜提供的图缩减到表面参数的集合,该表面参数的集合中的值由使用这些属性作为其输入的数学函数或算法定义。在优选的实践中,每个图或图像产生表面参数,然后该表面参数可以与其他表面参数一起被用来对该表面进行分类或识别。在这样的实施例中,存在基于这些表面参数进行分类的分类器。然而,分类器本身不是预定的。分类器是通过如上所述的机器学习程序来学习的。
该方法与表面的性质无关。例如,可以使用该方法对绘画作品或货币或安全文件(诸如出生证明或护照)的表面进行分类以便发现伪造物。但是还可以使用相同的方法对活体的细胞或其他部分的表面进行分类以便识别各种疾病。例如,各种癌症具有拥有特定表面特征的细胞。因此,该方法可以用于检测各种癌症。
出现的困难是实际获取要检查的细胞。在一些情况下,需要侵入性程序。然而,存在某些种类的细胞,这些细胞自然地从身体脱落或可以仅以最小的侵入力从身体中提取。示例是在巴氏涂片测试中轻轻地刮擦宫颈表面的示例。在自然脱落的细胞中,有来自泌尿道(包括膀胱)的细胞。因此,该方法可以用于检查这些细胞并且检测膀胱癌,而不需要侵入性的并且昂贵的程序,诸如膀胱镜检查。
本发明的特征在于使用原子力显微镜,该原子力显微镜可以例如在使用亚共振轻敲模式时产生物理属性的多维阵列。在一些实践中,采集图像的集合包括:在模式下使用原子力显微镜对已经从体液收集的细胞的表面执行纳米级分辨率扫描,以及将从原子力显微镜扫描程序获取的数据提供给机器学习系统;该机器学习系统提供了样本来自具有癌症的患者(此后称为“患有癌症的患者”)的概率的指示。该方法总体上适用于基于细胞的表面属性对细胞进行分类。
尽管在膀胱癌的背景下进行了描述,但是本文公开的方法和系统适用于检测其他癌症,其中,细胞或体液可用于分析而无需侵入性活检。示例包括:上尿道癌、尿道癌、结肠直肠癌和其他胃肠道癌;宫颈癌;呼吸消化道癌;以及具有类似属性的其他癌症。
此外,本文描述的方法适用于检测除癌症之外的细胞异常以及监测细胞对各种药物的反应。另外,本文中所描述的方法可用于分类及识别无论是从活体导出还是从非活体物质导出的任何类型的表面。所有这些必要的是该表面是易于被原子力显微镜扫描的表面。
例如,本文描述的方法可以用于检测伪造物,包括货币、股票证书、身份证件或艺术品(诸如绘画作品)的伪造物。
在一个方面,本发明的特征在于:使用原子力显微镜来采集从患者获取的多个细胞中的每个的图像的集合;对这些图像进行处理以获取表面参数图;以及使用应用于图像的机器学习算法,将细胞分类为源自患有癌症或无癌症患者。
在这些实施例中是以亚共振轻敲模式使用显微镜的那些实施例。在其他实施例中,以振铃模式使用显微镜。
在另一方面,本发明的特征在于:使用原子力显微镜,采集与表面相关联的图像的集合;对图像进行处理以获取表面参数图;以及使用应用于图像的机器学习算法,对表面进行分类。
在这些实践中,包括选择膀胱细胞的表面作为表面并且将表面分类为源自患有癌症或无癌症患者的细胞的表面。
在另一方面,本发明的特征在于一种方法,该方法包括:使用原子力显微镜来采集与表面相关联的图像的集合;对图像进行组合;以及使用应用于组合后的图像的机器学习方法对表面进行分类。
该方法无法在有或没有铅笔和纸的情况下在人脑中执行,因为它需要执行原子力显微镜,并且因为人脑不是机器,所以人脑无法执行机器学习方法。该方法也以非抽象的方式执行,以达到技术效果,即基于表面的技术属性对表面进行分类。已经有目的地省略了关于如何以抽象和/或非技术方式执行该方法的描述,以避免将权利要求误解为覆盖除了非抽象和技术实施方式以外的任何事物。
在一些实践中,图像是细胞的图像。这些实践中,还包括自动地检测细胞的图像具有伪影,并且排除该图像,而不用于对表面进行分类的实践以及包括将样本的图像分成分区,获取每个分区的表面参数,以及将细胞的表面参数定义为针对每个分区的表面参数的中位数的实践。
一些实践还包括:处理图像以获取表面参数,以及使用机器学习至少部分地基于表面参数对表面进行分类。在这些实践中,还包括定义表面参数的子集以及基于子集生成数据库。在此类实践中,定义表面参数的子集包括:确定表面参数之间的相关性,将相关性与阈值进行比较以识别相关参数的集合,以及将相关参数的集合的子集包括在表面参数的子集中。此外,在这些实践中,还包括定义表面参数的子集以及基于该子集生成数据库。在这些实践中,定义表面参数的子集包括:确定表面参数之间的相关性矩阵;其中确定相关性矩阵包括:生成模拟表面。在这些实践中,还有包括定义表面参数的子集以及基于该子集生成数据库的那些实践。在这些实践中,定义表面参数的子集包括:对来自同一样本的相同种类的不同表面参数进行组合。
实践还包括以下实践,其中采集图像的集合包括:在振铃模式下使用多通道原子力显微镜,其中,原子力显微镜的每个通道提供指示表面的对应表面属性的信息。
在本发明的实践中还包括将从受试者的尿样中收集的细胞的表面选择为表面以及将细胞分类为指示癌症或不指示癌症的那些实践。
在不脱离本发明的范围的情况下,使用显微镜的各种方式是可用的。这些包括:使用多通道原子力显微镜,其中,每个通道对应于该表面的表面属性;以亚共振轻敲模式使用原子力显微镜;以及使用原子力显微镜来结合采集多通道的信息,多通道中的每个对应于该表面的不同的表面属性;压缩由通道提供的信息并且根据该压缩信息构造压缩数据库。
在依赖于多通道原子力显微镜的本发明的实践中,进一步包括基于由通道提供的信息形成第一数据库并且以多种方式中的任一种执行压缩数据库的构造的那些实践。在这些实践中,将第一数据库投影到维度低于第一数据库的维度的子空间,该投影定义压缩数据库,压缩数据库的维度小于第一数据库的维度。在这些实践中,还包括来自第一数据库的压缩数据库,该压缩数据库具有比第一数据库更少的指标。这可以例如通过执行张量加法以生成张量和,以及使用张量和形成压缩数据库来执行,其中张量和将来自第一数据库的信息沿着与第一数据库的一个或更多个指标对应的一个或更多个片段进行组合。
在本发明的一些实践中,从第一数据库导出压缩数据库包括:定义来自第一数据库的值的子集,值中的每个表示第一数据库中的对应元素;从值的子集中的值导出压缩值;以及用压缩值表示来自第一数据库的对应元素;其中,导出压缩值包括:对值的子集中的值进行求和。该求和可以以各种方式执行,包括:通过执行张量加法以生成张量和,以及使用张量和形成压缩数据库;其中该张量和将来自第一数据库的值沿着与第一数据库的对应指标对应的一个或更多个片段进行组合。
本发明的实践还包括以下实践,其中,通过定义来自第一数据库的值的子集,值中的每个表示第一数据库中的对应元素;从值的子集中的值导出压缩值;以及用压缩值表示来自第一数据库的对应元素,来从第一数据库导出压缩数据库;其中,导出压缩值包括:例如通过获取算术平均数或几何平均数对值的子集中的值进行求平均。
在本发明的实践中,还有以下实践,其中,从第一数据库导出压缩数据库包括:定义来自第一数据库的值的子集,值中的每个表示第一数据库中的对应元素;从值的子集中的值导出压缩值;以及用压缩值表示来自第一数据库的对应元素;其中,压缩值是值的子集中的值的最大值或最小值之一。
在其他实施例中,从该第一数据库导出压缩数据库包括:定义来自该第一数据库的值的子集,值中的每个表示第一数据库中的对应元素;从值的子集中的值导出压缩值;以及用压缩值表示来自第一数据库的对应元素;其中,导出压缩值包括:使来自述第一数据库的信息通过表面参数提取器来获取表面参数集合。在这些实践中,包括将表示表面参数集合的表面参数归一化以不依赖从中导出表面参数的图像的表面面积的实践,以及包括将表面参数除以相同维度的另一参数的实践。
其他实践包括:自动地检测样本的图像具有伪影,以及自动地排除该图像,而不用于对表面进行分类。
又一些其他实践包括:将样本的图像分成分区,获取每个分区的表面参数;以及将细胞的表面参数定义为针对每个分区的表面参数的中位数。
本发明的一些实践包括:处理图像以获取表面参数,以及使用机器学习至少部分地基于表面参数和根据外部导出的参数对表面进行分类。在这些实践中,表面是已经从所收集的样本中导出的身体的表面,样本中的至少一个是无身体样本,无身体样本意味着它没有身体。在这些实践中,该方法进一步包括:选择外部导出的参数以包括指示无身体样本中不存在身体的数据。在包括无身体样本的实践中,包括向无身体样本分配人工表面参数的那些实践。在一些实践中,表面是从获取自患者的样本中导出的细胞的表面。在这些实践中,包括:选择外部导出的参数以包括指示患者患有特定疾病的概率的数据。指示概率的这种数据的示例包括:患者的年龄、患者的吸烟习惯和患者的家族史。
可以使用各种机器学习方法。这些包括随机森林方法、极端随机森林方法、梯度提升树方法、使用神经网络、决策树方法以及它们的组合。
在一些实施例中,表面是来自患者的第一多个细胞的表面,第二多个细胞已经被分类为来自患有癌症的患者,并且第三多个细胞已经被分类为来自无癌症的患者。这些方法包括:如果该第二多个与该第一多个的比率超过预定阈值,则诊断患者患有癌症。
在一些实践中,原子力显微镜包括:悬臂和设置在悬臂的末端处的探针。悬臂具有共振频率。在这些实践中,使用原子力显微镜包括:使探针与表面之间的距离以小于共振频率的频率振荡。
在一些实践中,使用原子力显微镜包括:使用显微镜,该显微镜已经被配置为输出与样本表面的不同物理属性对应的多个通道的信息。
其他实践包括:处理图像以获取表面参数,以及使用机器学习至少部分地基于表面参数和根据外部导出的参数对表面进行分类。在这些实施例中,表面是从获取自患者的样本中导出的细胞的表面,样本中的至少一个是不具有来自该患者的细胞的无细胞样本。在此类实践中,该方法进一步包括:选择外部导出的参数以包括指示无细胞样本中不存在细胞的数据。在这些实践中,还包括将人工表面参数分配给无细胞样本的那些实践。
在另一方面,本发明的特征在于一种包括原子力显微镜和处理系统的设备。原子力显微镜采集与表面相关联的图像。处理系统从原子力显微镜接收表示图像的信号并组合图像。该处理系统包括机器学习模块和分类器,该分类器在已经从该机器学习模块学习了用于分类的基础之后对未知样本进行分类。
在一些实施例中,该处理系统被配置为处理图像以获取表面参数,并且使用该机器学习模块至少部分地基于表面参数对表面进行分类。在这些实施例中,原子力显微镜包括多通道原子力显微镜,该多通道原子力显微镜的每个通道对应于表面的表面属性。在这些实施例中,还包括压缩器,该压缩器压缩由通道提供的信息并且根据压缩信息构造压缩数据库。
包括压缩数据库的实施例还包括分类器基于压缩数据库对未知样本进行分类的那些实施例。
各种压缩器可用于构造压缩数据库。其中,压缩器通过将第一数据库投影到维度低于第一数据库的维度的子空间来构造压缩数据库。该投影定义压缩数据库,压缩数据库具有小于第一数据库的维度的维度。
如本文所使用的,“原子力显微镜”、“AFM”、“扫描探针显微镜”以及“SPM”被认为是同义的。
本说明书中描述的唯一方法是非抽象方法。因此,权利要求仅能涉及非抽象实施方式。如本文所使用的,“非抽象”被认为是指自本申请提交时符合35USC 101的要求。
通过以下详细描述和附图,本发明的这些和其他特征将变得显而易见,其中:
附图说明
图1示出了原子力显微镜的一个示例的简化图;
图2示出了来自图1的处理系统的附加细节;
图3示出了由原子力显微镜以及在图1和图2中示出的处理系统执行的诊断方法;
图4示出了通过内置到图1中所示的原子力显微镜中的光学显微镜的视图;
图5示出了由图1的原子力显微镜采集的膀胱细胞的图;
图6示出了图2的处理系统中的数据库与机器学习模块之间的交互的细节;
图7示出了将初始大数据库压缩成较小维度的压缩数据库的细节,并且示出了图2的处理系统中的压缩数据库与机器学习模块之间的交互的细节;
图8示出了结合评估不同表面参数之间的相关性而使用的模拟表面的示例;
图9示出了两个表面参数的重要性系数的直方图;
图10示出了二叉树;
图11示出了适合于分类所需的数据结构的机器学习方法;
图12示出了可能由于细胞表面的污染引起的伪影的表示示例;
图13示出了表面参数的数量对相关性阈值的依赖性;
图14示出了在随机森林方法内计算的高度和粘附力属性的表面参数的重要性的层级;
图15示出了如针对高度和粘附力的组合通道使用随机森林方法所计算的、在训练和测试数据库中的不同数量的表面参数以及不同的数据分配的准确度;
图16示出了针对高度和粘附力的组合通道、使用随机森林方法的接收器操作特性;
图17示出了类似于图16中所示的图,但人工数据用于确认用于生成图16中的数据的程序的可靠性;
图18示出了在图17的接收器操作特性下的面积;
图19示出了当使用每个患者5个细胞以及需要被识别为来自患有癌症的患者的两个细胞时(N=5,M=2),针对高度和粘附力的组合通道,使用随机森林方法在训练数据与测试数据之间、不同数量的表面参数以及分配数据的不同方式的准确度;
图20示出了当使用每个患者5个细胞以及需要被识别为来自患有癌症的患者的两个细胞时(N=5,M=2),针对高度和粘附力的组合通道使用随机森林方法计算的接收器操作特性;以及
图21是示出了针对两个单独通道,与癌症诊断相关联的混淆矩阵的统计的表,其中,一个通道用于高度并且另一个通道用于粘附力。
具体实施方式
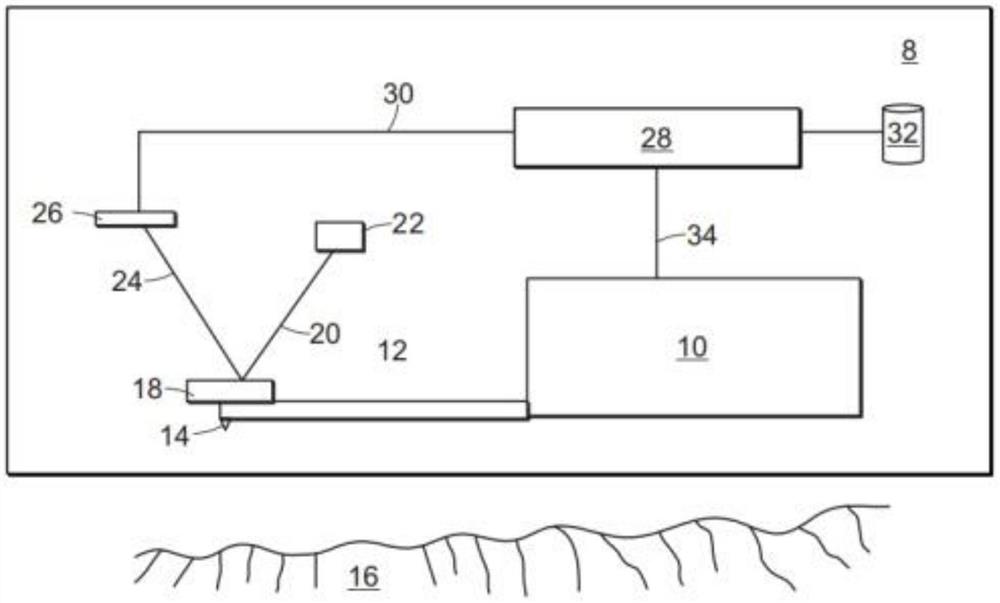
图1示出了具有扫描仪10的原子力显微镜8,该扫描仪10支撑悬臂12,探针14附接至该悬臂12。因此,探针14从扫描仪10悬臂伸出。扫描仪10沿着与样本表面16的参考平面平行的扫描方向移动探针14。在这样做时,扫描仪10扫描样本表面16的区。当扫描仪在扫描方向上正在移动探针14时,扫描仪也在垂直于样本表面16的参考平面的竖直方向上移动探针14。这使得从探针14到表面16的距离发生变化。
探针14通常耦接到悬臂12的反射部分。该反射部分反射由激光器22提供的照明光束20。悬臂12的反射部分在本文中将被称为反射镜18。反射光束24从反射镜18行进到光电探测器26,光电探测器26的输出连接到处理器28。在一些实施例中,处理器28包括FPGA电子器件以允许基于表面的物理或几何属性来实时计算表面参数。
探针14的移动转换成反射镜18的移动,这随后导致光电探测器26的不同部件被反射光束24照射。这导致指示探针移动的探针信号30。处理器28使用下面描述的方法基于探针信号30计算某些表面参数,并将结果33输出到存储介质32。这些结果33包括表示本文所描述的任何表面参数的数据。
扫描仪10连接至处理器28并且向处理器28,并提供指示扫描仪位置的扫描仪信号34。该扫描仪信号34还可用于计算表面参数。
图2详细示出了处理系统28。处理系统28的特征在于电源58,电源58具有连接到逆变器62的AC电源60。电源58提供用于操作下面描述的各种组件的功率。处理系统还包括散热器64。
在优选实施例中,处理系统28进一步包括用户接口66以使得人能够控制其操作。
处理系统28进一步包括第一和第二A/D转换器68、70,第一和第二A/D转换器68、70用于接收探针信号和扫描仪信号并将它们放置在总线72上。程序存储装置部74、工作存储器76和CPU寄存器78也连接到总线72。用于执行来自程序存储装置74的指令75的CPU 80连接到寄存器78和ALU 82两者。非暂时性计算机可读介质存储这些指令75。当执行指令75时,指令75使得处理系统28基于通过第一和第二A/D转换器68、70接收的输入来计算任何前述参数。
处理系统28进一步包括机器学习模块84和数据库86,该数据库86包括训练数据87和测试数据89,如图6所示。机器学习模块84使用训练数据87和测试数据89来实现本文描述的方法。
处理系统28的具体示例可以包括FPGA电子设备,该FPGA电子设备包括被配置成用于确定上述成像服务的属性值和/或表面参数的电路。
图3示出了使用原子力显微镜8来采集图像并且将图像提供至机器学习模块84以使用图像来表征样本的过程。图3中所示的过程包括从患者采集尿样88以及制备已脱落到尿样88中的细胞90。在已经对它们进行扫描之后,原子力显微镜8提供膀胱细胞90的图像以便存储在数据库86中。
每个图像是阵列,其中该阵列的每个元素表示表面16的属性。阵列中的位置对应于样本表面16上的空间位置。因此,图像定义了与该属性对应的图。这样的图以与土壤图示出的在地球表面上的不同位置处的不同土壤属性大致相同的方式,示出了在样本表面16上的不同位置处的属性值。这种属性将被称为“映射属性”。
在一些情况下,映射属性是物理属性。在其他情况下,属性是几何属性。几何属性的示例是表面16的高度。物理属性的示例包括表面粘附力、自身刚度以及与接触表面16相关联的能量损失。
多通道原子力显微镜8具有同时映射不同属性的能力。每个映射属性对应于显微镜8的不同“通道”。因此,图像可被视为多维图像阵列M
当多通道原子力显微镜8在亚共振轻敲模式中使用时,多通道原子力显微镜8可以映射以下属性:高度、粘附力、变形、刚度、粘弹性损失、反馈误差。这导致六个通道,每个通道对应于六个映射属性之一。当多通道原子力显微镜8在振铃模式中使用时,原子力显微镜8可以映射例如除了先前的六个属性之外的以下附加属性中的一个或更多个:恢复的粘附力、粘附力高度、断开高度、拉拔颈部高度(pull-offneck height)、断开距离、断开能量损失、动态蠕变相移和零力高度(zero-force height)。在该示例中,这导致总共14个通道,每个通道对应于14个映射属性中的一个。
扫描仪10在参考平面上定义离散像素。显微镜的探针14在每个像素处进行测量。为了方便起见,可以由笛卡尔坐标(x
M
其中,“i”和“j”分别是区间[1,Ni]和区间[1,Nj]中的整数,其中,Ni和Nj分别是可用于在x和y方向上记录图像的像素的数量。Ni和Nj的值可以不同。然而,本文中描述的方法不显著取决于这种差异。因此,为了讨论的目的,Ni=Nj=N。
样本图像阵列中的元素数量将是通道数量与像素数量的乘积。对于相对均质的表面16,仅需要扫描表面16的一个区。然而,对于更异质的表面16,优选扫描表面16上的多于一个的区。通过类推,如果希望检查港口中水的表面,则最可能仅需要扫描一个区,因为其他区可能无论如何都是相似的。另一方面,如果希望检查港口服务的城市的表面,则扫描多个区将是明智的。
考虑到这一点,阵列采集另一指数以识别正被扫描的特定区。这增加了阵列的维度。因此,图像阵列的形式表示为:
M
其中,扫描区指数s是识别样本内的特定扫描区的区间[1,S]中的整数。注意,这使得特定样本的图像阵列中的元素数量增加了等于扫描区数量的倍数。
优选地,这样的扫描区的数量足够大以表示整个的样本。会聚在适当数量的扫描区上的一种方式是比较两个这样的扫描区之间的偏差分布。如果增加扫描区的数量并不以统计上显著的方式改变这一点,那么扫描区的数量可能足以表示整个的表面。另一种方式是将被认为是合理的测试时间除以扫描每个扫描区所需的时间量,并使用该商作为区域数量。
在一些情况下,将扫描区中的每个区拆分为分区是有用的。对于在每个扫描区中存在P个这样的分区的情况,阵列可被定义为:
M
其中,分区指数p是区间[1,P]中的整数。在正方形扫描区域的情况下,方便的是将正方形划分为四个正方形分区,从而将P设置为等于4。
将扫描区划分为分区的能力提供了排除图像伪影的有用方式。这对于检查生物细胞90是特别重要的。这是因为制备用于检查的细胞90的过程可以容易地引入伪影。这些伪影应该从任何分析中排除。这使得可以将一个分区与其他分区进行比较,以识别哪个分区(如果有的话)显著偏离而被排除。
另一方面,新指数的添加进一步增加了阵列的维度。
为了基于由原子力显微镜8采集的图像阵列M
D
其中,k为表示属性或通道的通道指数,s为识别特定扫描区的扫描区指数,p为表示第s个扫描区的特定分区的分区指数,n为识别特定样本的样本指数,以及l为识别来自L个类别的集合的特定类别的类别指数。因此,阵列的总大小是类别数量、样本数量、扫描区数量、每个扫描区的分区数量和通道数量的乘积。
图3示出了诊断方法10,该诊断方法10的特征在于使用原子力显微镜8和机器学习模块84,该原子力显微镜8使用亚共振轻敲来操作,使用该机器学习模块84以检查已经从尿样88中回收的生物细胞90的表面,以努力将患者分类为以下两个类别中的一种:患有癌症和无癌症。由于有两个类别,则L=2。
优选的实践包括使用离心分离、重力沉淀或过滤来收集细胞90,随后固定并冷冻干燥或亚临界干燥细胞90。
在所示的示例中,原子力显微镜8使用亚共振轻敲模式和振铃模式两者进行操作,亚共振轻敲模式诸如由Bruker,Inc.(布鲁克股份有限公司)实施的PeakForce(峰值力)QMN,振铃模式例如由NanoScience Solutions,LLC(纳米科学解决方案有限责任公司)实施。两种模式允许记录高度和粘附力通道。然而,振铃模式是图像收集的基本上更快的模式。如上所述,这些模式允许许多通道同时记录。然而,本文描述的实验仅使用两个通道。
图4示出了原子力显微镜的悬臂12以及如上所述从患者获取并且制备的细胞90。该视图是通过与原子力显微镜8耦接的光学显微镜拍摄的。
图5示出了第一和第二图对92、94。第一图对92示出了来自无癌症患者的细胞90的图。第二图对94示出了来自患有癌症的患者的细胞90的图。所示的图是边为10微米、在两个维度上具有512个像素的分辨率的正方形扫描区域的图。当以(诸如PeakForce QMN模式的)亚共振轻敲模式扫描时,扫描速度为0.1Hz,并且当以振铃模式扫描时,扫描速度为0.4Hz。扫描期间的峰值力为5纳牛顿(nano-newton)。
现在参见图6,机器学习模块84基于数据库86训练候选分类器100。可以从机器学习方法的族中选择特定的机器学习方法,例如,决策树、神经网络或它们的组合。
图6和图7中所示的方法开始于将数据库86拆分为训练数据87和测试数据89。这提出了以下问题:数据库86中的多少数据应当进入训练数据87,以及数据库86中的多少数据应当进入测试数据89。
在一些实施例中,数据库86中50%的数据进入训练数据87,而剩余50%的数据进入测试数据89。在其他实施例中,数据库86中60%的数据进入训练数据87,而剩余40%的数据进入测试数据89。在其他实施例中,数据库86中70%的数据进入训练数据87,而剩余30%的数据进入测试数据89。在其他实施例中,数据库86中80%的数据进入训练数据87,而剩余20%的数据进入测试数据89。候选分类器100应最终独立于拆分中所使用的比率。
在图3所示的示例中,每个患者收集10个膀胱细胞90。使用标准临床方法(包括侵入性活组织检查和组织病理学)来识别癌症的存在。这些方法足够可靠,以便可以很好的定义两个类别。因此,图6所示的数据库86可以表示为:
其中,N
当在训练数据87与测试数据89之间拆分数据库86时,重要的是要避免在训练和测试数据87、89之间划分来自同一样本{M
机器学习模块84使用训练数据87来构建候选分类器100。取决于分类器100的类型,训练数据87可以是学习树、决策树、树的自展(bootstrap)、神经网络或它们的组合。以下被表示为“AI”的分类器100输出特定样本n属于特定类别l的概率:
Prob
其中,Prob
在已经构建之后,验证模块102使用测试数据89来验证候选分类器100实际上是足够有效的。在本文所描述的实施例中,验证模块102至少部分地基于接收器的操作特性和混淆矩阵来评估有效性。通过重复数据库86的随机拆分从而生成不同的测试数据89和训练数据87并且然后执行分类程序以查看是否有任何差异,来验证候选分类器100的鲁棒性。
如果结果证明候选分类器100不够有效,则机器学习模块84会改变训练过程的参数并且生成新的候选分类器100。该循环继续,直到机器学习模块84最后提供达到期望的有效性阈值的候选分类器100。
当存在与样本n相关联的一个以上概率值时出现的计算量,某种程度上阻碍了构建合适的分类器100的过程。实际上,由于图像阵列的多维性质,对于任何一个样本,都会有K·S·P概率Prob
处理这种大数据阵列的另一瓶颈是用于提供分类器的合理训练的大量样本。当构建决策树时,经验法则要求样本数量至少是数据库的维度的六倍。因为原子力显微镜是一种相对慢的技术,因此获取足够的样本来构建任何合理的分类器将是不切实际的。
如图7中所示的压缩器104解决了前述困难。压缩器104将由特定通道提供的信息压缩到体现关于该通道的信息的表面参数的空间中。压缩器104接收数据库86并生成压缩数据库106。实际上,这相当于将相当高维空间中的多维矩阵投影到维度小得多的矩阵中。
压缩器104执行各种数据库缩减程序中的任一种。在这些程序中有结合本文描述的一个或更多个数据库缩减程序的程序。这些共同地从数据集导出表面参数,该表面参数体现了在该集合中体现的信息中的至少一些。
在一些实践中,压缩器104执行第一数据库缩减程序。该第一数据库缩减程序依赖于以下观察:每个图像最终都是阵列,该阵列可以与其他此类阵列组合,使得产生对象,该对象保留了组合产生该对象的阵列的信息的足够方面,以便在对样本进行分类时是有用的。例如,张量加法
在一个具体实施方式中,片段对应于指数k。在这种情况下,图像的张量总和由下式给出:
因此,用于机器学习的压缩数据库106的每个元素变为以下:
该特定示例将数据库86的维度减少了K倍。因此,分类器100定义概率如下:
还可以针对剩余的指标执行类似的程序。最终,
其中
在其他实践中,压缩器104替代地执行第二数据库缩减程序。该第二数据库缩减程序依赖于分别对指数k、s、p中的每个或其组合进行几何或代数平均。执行第二程序的特定方式的示例包括在所有指标k、s、p上的以下平均程序:
在其他实践中,压缩器104替代地执行第三数据库缩减程序。该第三数据库缩减程序依赖于将整个系列的最高或最低概率分配给特定指数。例如,考虑扫描区指数s,可以使用以下关系之一:
最终,如果以这种方式缩减了所有指数
在一些实践中,压缩器104通过使每个图像通过表面参数提取器Am来缩减数据库D
P
其中,表面参数指数m为[1,M]中的整数,通道指数k识别图是否表示高度、粘附力、刚度、或一些其他物理或几何参数,样本指数n识别样本,扫描区指数s识别样本中的特定扫描区,以及分区指数p识别扫描区内的特定分区。该程序提供了将多维张量M
表面参数向量包括与通道相关的足够的残差信息,该表面参数向量从该通道导出以用作分类的基础。然而,它比通道提供的图像小得多。这样,依赖于表面参数向量的分类程序维持低得多的计算量,却没有相应的准确度损失。
可以从通道中提取各种表面参数。这些参数包括粗糙度平均数、均方根、表面偏斜、表面峰度、峰峰值、十点高度、最大谷区深度、最大峰值高度、平均值、平均顶点曲率、纹理指数、均方根梯度、面积均方根斜率、表面面积比、投影面积、表面面积、表面支承指数、核心区液体滞留指数、谷区液体滞留指数(valley fluid retention index)、缩减的顶点高度、核心粗糙度深度、缩减的谷区深度、支承曲线的1-h%高度间隔、顶点密度、纹理方向、纹理方向指数、主径向波长、径向波指数、平均半波长、分形维度、20%的相关长度、37%的相关长度、20%的纹理长宽比、以及37%的纹理长宽比。
可通过引入算法或数学公式来进一步扩展表面参数的列表。例如,可以通过例如将每个参数除以表面面积的函数,来将表面参数归一化(normalize)为图像的表面面积,该表面面积对于不同的细胞可以是不同的。
本文描述的示例依赖于三个表面参数:谷区液体滞留指数(“Svi”)、表面面积比(“Sdr”)、以及表面面积(“S3A”)。
谷区液体滞留指数是指示谷区中存在大空隙的表面参数。它由以下定义:
其中,N为x方向上的像素数量,M为y方向上的像素数量,V(hx)为支承面积比曲线之上和水平线hx之下的空隙面积,以及Sq为均方根(RMS),Sq由以下表达式定义:
表面面积比(“Sdr”)是表达界面表面面积相对于投影的x、y平面的面积的增量的表面参数。该表面参数由下式定义:
其中,N为x方向上的像素数量,以及M为y方向上的像素数量。
表面面积(“S3A”)由以下定义:
为了根据由原子力显微镜8提供的图像计算上述三个表面参数中的每个,细胞的每个图像首先被拆分为4个分区,在这种情况下,4个分区是具有5微米边的正方形的象限。因此,每个细胞产生4个表面参数集合,每个象限一个。
可以用三种不同方式中的任何一种来解决细胞中伪影的存在。
第一种方式是使操作员检查细胞的伪影,并且根据进一步地处理将具有一个或更多个这种伪影的任何细胞排除。这需要人为干预来识别伪影。
第二种方式是提供伪影识别模块,该伪影识别模块能够识别伪影并且自动排除包含该伪影的细胞。这使得该程序更加不依赖操作员。
第三种方式是使用每个细胞的参数的中值而不是平均值。当使用中值而不是平均值时,本文描述的结果几乎不变。
使用仅两个类别的相同示例,压缩数据库106将如下所示:
在其他实施例中,即使附加参数与原子力显微镜的图像不直接相关,也可以分配附加参数来帮助在不同类别之间进行区分。
例如,当尝试检测膀胱癌时,尿样88的一个或更多个样本非常可能不具有任何细胞90。考虑这种结果的一种方便的方式是添加新的“无细胞”参数,该参数为真或假。为了避免必须更改数据结构以适应这种参数,具有设置为“真”的“无细胞”的样本接收表面参数的人工值,该表面参数被选择来避免使统计结果失真。
作为另一个示例,存在与表面参数无关但仍然与分类相关的其他因素。这些因素包括患者的特性,如年龄、吸烟和家族史,所有这些都可能与该患者患有膀胱癌的概率有关。可以以类似于“无细胞”参数的方式来包括这些参数,从而避免必须修改数据结构。
还存在使用表面参数来缩减数据库86的大小的其他方式。
一个这样的程序是排除彼此充分相关的表面参数。一些表面参数强烈地取决于各种其他表面参数。所以,通过包括彼此相关的表面参数,来提供很少的附加信息。这些冗余表面参数可以被移除而几乎没有损失。
找到表面参数之间的相关矩阵的一种方式是生成模拟表面,其示例在图8中示出。用原子力显微镜8成像的各种样本表面也可用于识别不同表面参数之间的相关性。
机器学习模块84与其输入的性质无关。因此,虽然它被示为在图像阵列上操作,但是它完全能够在表面参数向量上操作。因此,同一机器学习模块84可用于确定特定表面参数向量属于特定类别的概率,即,用于评估Prob
因此,在将多维图像阵列M
因为某些表面参数彼此相关,所以可以进一步缩减维度。这可以在没有张量求和的情况下进行。相反,通过直接操纵来自不同图像的相同参数来执行这种缩减。
除了依赖于以上识别为(3-1)至(3-9)的数据库缩减程序的方法之外,还有可能使用分类器100,该分类器100将来自同一样本的同一种类的不同表面参数进行组合。在形式上,这种类型的分类器100可以在形式上表示为:
Prob
其中,P
相关分类器100是将来自相同属性的图像的同一样本n的同一种类m的不同表面参数进行组合的分类器。这样的分类器100可以在形式上表示为:
Prob
其中,P
又一分类器100是不组合所有参数而是仅通过一个指数来组合表面参数的分类器。一个这样的分类器100将一个表面参数分配给同一图像内的整个分区p的系列。这样的分类器100在形式上表示为:
Prob
其中,P
和中位数(median):
P
当与来自每个患者的多个细胞的膀胱癌成像检测结合使用时,分类器100依赖于平均数或中位数。然而,优选的是,分类器100依赖于中位数而不是平均数,因为介质对伪影不太敏感。
在本文中所描述的特定实施例中,机器学习模块84实现各种机器学习方法中的任一种。然而,当面对多个参数时,机器学习模块84可以容易地变得过度训练。因此,使用三种最不容易过度训练的方法即随机森林方法(Random Forest method)、极端随机森林方法(Extremely Randomized Forest method)和梯度提升树方法(method ofGradientBoosting Trees)是有用的。
随机森林方法和极端随机森林方法是自展无监督方法。梯度提升树方法是构建树的监督方法。使用来自SCIKIT-LEARN Python机器学习包(版本0.17.1)的适当的分类器函数,来执行可变分级、分类器训练和验证。
随机森林方法和极端随机森林方法都是基于生长许多分类树。每个分类树都预测一些分类。然而,所有树的投票决定最终分类。在训练数据87上生长树。在典型的数据库86中,所有数据的70%在训练数据87中,而剩余数据在测试数据89中。在本文描述的实验中,训练数据87与测试数据89之间的拆分是随机的并且重复多次,以确认分类器100对数据库86的拆分方式不敏感。
每个分支节点都依赖于原始表面参数的随机选择的子集。在本文所描述的方法中,原始表面参数的选定子集中的元素数量是原始提供的表面参数的数量的平方根。
然后学习过程通过在给定随机选择的表面参数子集的情况下识别树分支的最佳拆分而继续进行。机器学习模块84以拆分阈值基于分类误差的估计为基础。每个参数被分配给关于训练数据87的最常见出现的类别的参数区。在这些实践中,机器学习模块84将分类误差定义为该区中不属于最常见类别的训练数据87的一部分:
其中,p
基尼指数(其为跨所有K个类别的方差的测量)定义如下:
当p
交叉熵也提供对节点纯度进行度量,交叉熵被定义为:
如同基尼指数,当p
基尼指数还提供了一种获取指示每个表面参数的重要性的“重要性系数”的方式。一个这样的测量来自在树节点处针对每个变量添加基尼指数的减小的所有值并且对所有树求平均。
图9中所示的直方图采用误差条表示重要性系数的平均值,以示出它们偏离均值的一个标准偏差的程度。这些重要性系数对应于可以从特定通道导出的各种表面参数。因此,第一行中的直方图表示可以从测量特征“高度”的通道中导出的表面参数,而第二行中的表面参数表示可以从测量特征“粘附力”的通道中导出的表面参数。注意,已经使用助记手段来命名特征,从“高度”通道导出的所有表面参数以“h”开头,并且从“粘附力”通道导出的所有表面参数以“a”开头。
因此,在第一行中,第一列中的面板示出了当机器学习模块84使用随机森林方法时从“高度”通道导出的那些表面参数的重要性系数;第二列中的面板示出了当机器学习模块84使用极端随机森林方法时从“高度”通道导出的那些表面参数的重要性系数;并且第三列中的面板示出了当机器学习模块84使用梯度提升树方法时从“高度”通道导出的那些表面参数的重要性系数。
类似地,在第二行中,第一列中的面板示出了当机器学习模块84使用随机森林方法时从“粘附力”通道导出的那些表面参数的重要性系数;第二列中的面板示出了当机器学习模块84使用极端随机森林方法时从“粘附力”通道导出的那些表面参数的重要性系数;并且第三列中的面板示出了当机器学习模块84使用梯度提升树方法时从“粘附力”通道导出的那些表面参数的重要性系数。
图9中的直方图提供了智能的方式,来选择在正确地分类样本方面最有帮助的那些表面参数。例如,如果机器学习模块84被迫仅从测量高度的通道中选择两个表面参数,则将可能避免选择“h_Sy”和“h_Std”,而是可能愿意选择“h_Ssc”和“h_Sfd”。
图9中的重要性系数是使用一百棵树和三百棵树之间获得的。原始表面参数的所选子集中的元素的最大数量是原始提供的表面参数的数量的平方根,并且基尼指数提供了用于评估分类误差的基础。通过比较同一行中的直方图,很明显,机器学习程序的选择不会对特定表面参数的重要性造成很大的差异。
图10示出了在自展法中使用的来自一百至三百棵树的全体的二叉树的示例。在第一次拆分中,选择拆分值为15.0001的第四变量“X[4]”。这产生了0.4992的基尼指数,并且将73个样本拆分成分别具有30个样本和43个样本的两个仓(bin)。
在第二级拆分处,查看左手侧节点,选择拆分值为14.8059的第六变量“X[6]”,这产生了0.2778的基尼指数,并且将30个样本(类别1中的5个和类别2中的25个)拆分成分别具有27个样本和3个样本的两个仓。拆分继续,直到树节点的基尼指数为零,从而指示仅存在两个类别中的一个。
极端随机树方法与随机森林方法在其拆分选择上有所不同。与使用随机森林方法的情况不同,不是使用基尼指数来计算最佳参数和拆分组合,而是使用极端随机树方法的机器学习模块84从参数经验范围中随机地选择每个参数值。为了确保这些随机选择最终收敛到基尼指数为零的纯节点,机器学习模块84仅在为其选择了当前树的所选变量集合中的随机均匀拆分中选择最佳拆分。
在一些实践中,机器学习模块84实施了梯度提升树方法。在这种情况下,机器学习模块84构建一系列树,每棵树相对于一些成本函数收敛。机器学习模块84构建每棵后续树,以例如通过最小化均方误差来最小化与精确预测的偏差。在一些情况下,机器学习模块84依赖于弗里德曼过程以用于这种类型的回归。可以使用如在“SCIKIT-LEARN PYTHON”包中实施的例程“TREEBOOST”来执行这种回归过程的适当实施方式。
因为梯度提升树的方法缺少纯节点的标准,所以机器学习模块84预定义树的大小。可替代地,机器学习模块84限制个体回归的数量,从而限制树的最大深度。
困难在于以预定义的大小构建的树可以容易地被过度拟合。为了最小化该困难的影响,优选地,机器学习模块84例如通过使用无量纲学习率参数来对诸如提升迭代次数之类的量施加约束条件或者削弱迭代率。在可替代实践中,机器学习模块84限制树上的终端节点或叶子的最小数量。
在本文所述的依赖于SCIKIT-LEARN PYTHON包的实施方式中,机器学习模块84将叶子的最小数量设为一致的并且将最大深度设置为3。在本文描述的将从人类受试者收集的膀胱细胞进行分类的应用中,机器学习模块84通过故意选择非常低的学习率0.01来扼制其学习能力。所得的缓慢学习程序减少了由于具有少量人类受试者并且因此具有少量样本而产生的方差。
在创建训练数据87和测试数据89时,重要的是避免在训练数据87与测试数据89之间划分集合{M
在对膀胱细胞90进行分类的特定实施方式中,每个患者提供若干细胞,其中,每个细胞90的图像被划分成4个分区。人类观察者视觉检查分区以努力发现伪影,在图12中可看到其中的两个。如果发现分区中存在伪影,则检查图像的任何人都将把该分区标记为要被忽略的分区。
当涉及许多细胞90时,该过程可能变得冗长。通过使用等式(10)中所示的分类器100并且取4个分区的中位数,可以使该过程自动化。这显著地稀释了伪影的贡献。
机器学习模块84随机拆分数据库86,使得其数据的S%在训练数据87中而其数据的100-S%在测试数据98中。用设置为50%、60%和70%的S来执行实验。机器学习模块84以这样的方式拆分数据库86:将来自同一个体的数据全部保存在训练数据87或测试数据98中,以避免可能由于同一个体的不同细胞90之间的相关性而导致的人工过度训练。
然后,机器学习模块84使压缩器104进一步缩小分类要依赖的表面参数的数量。在一些实践中,压缩器104通过基于特定通道内的表面参数的相应的基尼指标对表面参数进行排序并且保持该通道的最优参数的一些数量M
图13示出了改变相关系数的阈值会如何影响使用随机森林方法选择的表面参数的数量,其中,最左边的面板对应于可从高度通道获得的表面参数,并且中间的面板对应于可从粘附力通道获得的表面参数。如从竖直比例的改变显而易见的,最右侧的面板表示高度通道和粘附力通道的组合。尽管图13针对随机森林方法,但其他方法具有类似的曲线。
一旦已经训练了树,就适于测试它们正确地分类测试数据98的能力,或可替代地,测试使用它们对未知样本进行分类的能力。分类过程包括获取树投票的结果,并且使用该结果作为指示样本所属类别的概率的基础。然后,将该结果与基于可容忍的误差而设置的分类器阈值进行比较。该分类器阈值通常作为构建接收器操作特性的一部分而变化。
在一个实验中,从25个患有癌症的患者和43个无癌症的患者中收集尿样88的样本。如通过TURBT定义的,在患有癌症的患者中,有14位为低等级,11位为高等级。无癌症患者是健康的或过去患有癌症的。使用耦接到原子力显微镜8上的光学显微镜,人类观察者随机地选择看起来是细胞的圆形对象。
通过使用在等式(14)中提到的数据缩减过程来进一步减小数据库。因此,可能得到的发生器100为P
每个患者至少成像5个细胞。为了简单起见,仅考虑两个属性:高度和粘附力。
图14示出了在随机森林方法内计算的高度和粘附力属性的表面参数的重要性的层级。该图示出了重要性系数的平均数,以及指示关于平均数的一个标准偏差的误差条。数据库86被随机地数千次拆分为训练数据87和测试数据89。
通过张量加法将高度和粘附力的映射属性进行组合,该张量加法基本上是适合于表面参数的向量的数据缩减方法(3-1)。相关的张量加法运算表示为:
与图9中的情况一样,图14中的每个表面参数具有表面参数的标准名称,前面附有指示该表面参数从其中导出的映射属性的字母来作为其名称。例如,“a_Sds”是指从粘附力属性的图像导出的“Sds”参数。
用于随机森林方法的合适的统计性能度量来自检查接收器操作特性和混淆矩阵。接收器操作特性允许定义灵敏度(sensitivity)和特异性(specificity)的范围。当将细胞分类为来自患有癌症的患者时,灵敏度的范围对应于“准确度(accuracy)”,而当将细胞分类为来自无癌症人时,特异性对应于“准确度”。接收器操作特性使得可以使用接收器操作特性来定义特异性范围和灵敏度范围,如下所示:
sensitivity=TP/(TP+FN);
specificity=TN/(TN+FP);
accuracy=(TN+TP)/(TP+FN+TN+FP), (19)
其中,TN、TP、FP、FN分别代表真阴性、真阳性、假阳性和假阴性。
图15示出了三条不同的曲线,每条曲线示出了通过考虑不同数量的表面参数而实现的准确度,其中,基于选择如上所述的不同的自相关阈值和重要性系数来选择表面参数。
通过训练数据87与测试数据89之间的数千次随机拆分,来获得图15中的三条不同曲线中的每条。曲线在对每个集合的数据分配方面是不同的。第一曲线对应于70%的数据被分配给训练数据87而30%的数据被分配给测试数据89。第二曲线对应于仅60%的数据被分配给训练数据87,以及40%的数据被分配给测试数据89。以及第三曲线对应于训练数据87与测试数据89之间的均匀拆分。
从图15的检查明显看出,实际上不存在对特定阈值拆分的依赖性。这指示由机器学习模块84执行的过程的鲁棒性。
图16示出了接收器操作特性的族。图16中所示的特性的族中的各个接收器操作特性源自数据库86到训练数据87和测试数据89中的两百个不同的随机拆分。
当尝试在两个类别之间进行分类时,每个接收器操作特性示出了针对不同阈值的灵敏度和特异性。将图16中的图二等分的对角线相当于通过抛硬币进行分类的分类器。因此,接收器操作特性越接近图16中所示的对角线,其分类器在分类时越差。曲线远离该对角线聚集、各个曲线之间的变化很小的事实表明了分类器的有效性和其对训练数据87和测试数据89的具体选择的不灵敏度。
在构造接收器操作特性时,定义特定概率值对应于一个类别还是另一类别的阈值是自由参数。该参数的选择控制着特异性和敏感度。对于每个接收器操作特性,存在对应于将应处于第一类别中的样本分类为第二类别的最小误差的点,反之亦然。这在图21中针对当使用单个通道时使用的三种机器学习方法中的每种被示出。
在图21中所示的表中的每一行表征所收集的细胞的特定数量(N)和用作诊断阈值的较小数量(M)。对于每行,考虑两个通道:高度和粘附力。对于所使用的三种机器学习方法中的每种,该表示出了针对数据库到训练数据和测试数据的数千次随机拆分的平均AUC和准确度,其中,数据库中70%的数据被分配给训练数据。准确度是与分类中的最小误差相关联的准确度。图21中的每行也示出了灵敏度和特异性。
原则上,灵敏度和特异性还可以围绕其中灵敏度和特异性相等的平衡点来定义。因为人类受试者的数量有限,所以难以精确地定义该平衡点将位于何处。因此,在图21中,放宽了对等式的要求,并且限定了平衡范围,其中,灵敏度和特异性之间的差的大小必须小于所选值,对于图21,该值是5%。
仅使用10个表面参数来计算接收器操作特性。从图15中可以明显看出,存在收益递减的点,在该点处添加更多的表面参数并不会显著提高准确度。根据图15,显然仅使用8到10个明智选择的表面参数就足以达到80%的相对高的准确度。考虑使用前10个表面参数来表征接收器操作特性和混淆矩阵的统计行为,包括分类器100的特异性、灵敏度和准确度。
将细胞分类为来自无癌症的患者或患有癌症的患者的过程依赖于在用于获取该概率的程序的所有重复次数上对针对该细胞获取的概率进行求平均。这在形式上表示为:
其中,使用在训练数据库87上开发的机器学习方法来开发分类器AI。根据此程序,并且假设类别1表示癌细胞,如果Prob
为了确认图18和图19中所示数据的真实性,用与图19和图20所用相同的程序进行对照实验,但待分类的样本在癌细胞和健康细胞之间均匀拆分。图17和图18示出了分类的数千次随机选择的结果。显然,准确度已经下降到53%±10%,这与预期相一致。这表明图19和图20所示的数据的可靠性以及分类器对过度训练的抵抗性,过度训练是当使机器学习方法处理太多参数时出现的常见问题。
一种替代性分类方法依赖于多于一个的细胞来建立患者的诊断。这避免了基于高采样误差的鲁棒性的缺乏。此外,这避免了因为不能确保在尿样88中发现的细胞实际上来自膀胱本身而引起的误差。泌尿道的其他部分完全能够脱落细胞。此外,尿样88可以含有各类其他细胞,例如来自泌尿道其他部分的剥落的上皮细胞。一种这样的分类方法包括:如果在分类为患有癌症的患者的细胞总数量N中被分类为来自患有癌症的患者的细胞的数量M大于或等于预定义值,则诊断患者患有癌症。这是先前讨论的N=M=1的情况的概括。
可以使用算法(3-2)-(3-9)或(10)-(14)针对N个细胞来分配基于概率的患有癌症的概率。作为定义将N个测试细胞分类为来自癌症患者(类别1)的概率的优选方法如下:
其中,根据训练数据库87开发分类器AI。
图19和图20示出了与图15和图16中的那些类似的鲁棒性的准确度和接收器操作特性,但是是针对N=5和M=2的情况。可以看到,这种方法的准确度可以达到94%。上述随机测试示出了在接收器操作特征曲线下的面积为50±22%(诊断集合的数千次随机选择的结果)。这些意味着缺乏过度训练。
针对多个N和M的混淆矩阵的计算结果示出在针对两个单通道(高度和粘附力)示例的图20的表中。与基于单通道的诊断相比,组合通道的鲁棒性更好。
也可以应用上述程序来分类无癌症患者。在这种情况下,以上讨论的概率是细胞属于无癌症患者的概率。
已经描述了本发明及其优选实施例,由专利证书保护的新的权利要参见权利要求书部分。
- 用于表面识别的原子力显微镜
- 用于标识表面区域的位置标记和基于所标记的表面区域来识别/认证的方法