一种采用限制词典进行语义拒识的方法
文献发布时间:2023-06-19 18:34:06
技术领域
本发明涉及自然语言语义框架技术领域,具体的说,是一种采用限制词典进行语义拒识的方法。
背景技术
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining) 的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
目前,语义算法模型部分是基于文本相似度来计算语义相似度,当领域错误下发后,可能会因为该错误领域内与用户说法的相似数据,而发生误识别的情况。
发明内容
本发明的目的在于提供一种采用限制词典进行语义拒识的方法,用于解决现有技术中语义算法模型中由于领域错误导致的语义错误下发的问题。
本发明通过下述技术方案解决上述问题:
一种采用限制词典进行语义拒识的方法,具体步骤包括:
步骤A.将用户语料库和语义语料库中提取文本数据,采用自定义词典库对提取的文本数据进行分词,得到意图-词汇库;
步骤B.对意图-词汇库进行数据清洗,得到意图-限制词典库;
采用TF-IDF算法将意图-词汇库中的词组进行重要程度打分,在给定阈值情况下,将得分大于或等于阈值的词组选出,再进行口语化人工评审;通过人工评审的词组视为通过数据清洗,将通过数据清洗的词组存入意图-限制词典库;
步骤C.将意图-限制词典库运用于语义算法模型进行语义预测后,对语义算法模型预测结果做后置据识判断。
作为本发明的进一步改进,所述步骤C中,据识判断方法为:
步骤C1.语义算法模型根据用户文本预测出意图结果;
步骤C2.根据语义算法模型预测出的意图结果,获取意图-限制词典库中意图结果所对应的限制词典库;
步骤C3.判断用户文本与所获取的限制词典库是否有交集,若有,判断为符合语境,进行语义算法模型的后续阶段;若无,判断为不符合语境,做拒识处理。
作为本发明的进一步改进,所述步骤C3中,判断用户文本与所获取的限制词典库是否有交集的方法为:
将用户文本进行分词,判断各个分词是否存在于限制词典库中,有则认为没有交集,没有则认为有交集。
作为本发明的进一步改进,所述步骤A中,自定义词典库为:jieba分词词组库与语义常用词组库的结合。
本发明与现有技术相比,具有以下优点及有益效果:
本发明不影响当前语义和领域整体流程,并且无需对当前语义和领域的语义算法模型进行改进,直接在进行领域识别后引入一个接入清洗后的意图-限制词典库的步骤,通过利用用户数据库和语料库的大量数据生成意图-限制词典库,可有效对文本进行误识别拦截;通过该方法放在语义算法模型后进行最后兜底,并且优化为可配置项目,大大降低误识别率、并不影响识别效率。
附图说明
图1为本发明实施例中意图-限制词典库的构建流程图;
图2为本发明实施例中判断用户文本与所获取的限制词典库是否有交集的流程图;
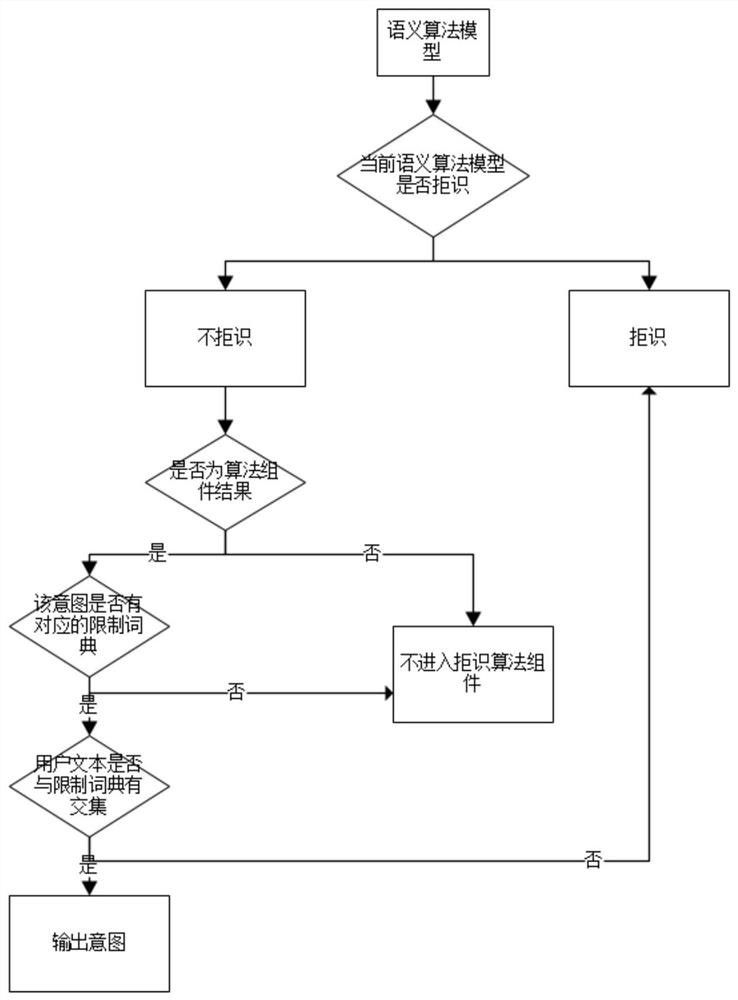
图3为本发明实施例中一种采用限制词典进行语义拒识的方法流程图;
图4为本发明实施例中根据误识别的意图获取意图-限制词典库,得到切换主页意图的限制词典库词组的示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例:
在一个实施例中,参照附图1-3,一种采用限制词典进行语义拒识的方法, 具体步骤包括:
步骤A.将用户语料库和语义语料库中提取文本数据,采用自定义词典库对提取的文本数据进行分词,得到完整的意图-词汇库;作为优选,自定义词典库为:jieba分词词组库与语义常用词组库的结合。
步骤B.对意图-词汇库进行数据清洗,得到意图-限制词典库;
采用TF-IDF算法将意图-词汇库中的词组进行重要程度打分,在给定阈值情况下,给定的阈值采用业界通用的阈值,将得分大于或等于阈值的词组选出,再进行口语化人工评审,并丢弃得分小于阈值的词组;通过人工评审的词组视为通过数据清洗,将通过数据清洗的词组存入意图-限制词典库,该意图-限制词典库为对意图-词汇库进行数据清洗完毕后的库。
具体的,采用TF-IDF算法将意图-词汇库中的词组进行重要程度打分,TF:词频TF(x)=出现次数/总词数,IDF:词汇出现频率IDF(x)=logN+1N(x)+1+1,且TF-IDF(x)=TF(x)*IDF(x)。
步骤C.将意图-限制词典库运用于语义算法模型进行语义预测后,对语义算法模型预测结果做后置据识判断。
本实施例中,步骤C中,据识判断方法包括:
步骤C1.语义算法模型根据用户文本预测出意图结果;
步骤C2.根据语义算法模型预测出的意图结果,获取意图-限制词典库中意图结果所对应的限制词典库;
步骤C3.判断用户文本与所获取的限制词典库是否有交集,若有,判断为符合语境,进行语义算法模型的后续阶段;若无,判断为不符合语境,做拒识处理。
具体的,判断用户文本与所获取的限制词典库是否有交集的方法为:
将用户文本进行分词,判断各个分词是否存在于限制词典库中,有则认为有交集,没有则认为没有交集。
在一个具体的实施例中,
假设语义:“打开切水果”因语义算法模型领域误识别,在错误领域里与“切换主页”相近,易被误识别为切换主页意图,导致语义结果错误,现期望在不修改领域结果和语义模型的情况下,对其进行拒识。
5-1、收到错误语义结果后,根据误识别的意图获取意图-限制词典库,得到切换主页意图的限制词典库词组如图4所示;
5-2、根据得到的限制词典库词组,判断与文本“打开切水果”是否有交集,如果有则认为意图识别正确,继续后续组件;如果没有,做拒识处理,认为“打开切水果”和“切换主页”意图无文本相关性。
本发明可在语义算法模型中增加一个后置限制组件,以实现一种采用限制词典进行语义拒识的方法,通过后置限制组件根据预测结果和用户文本判断是否做拒识处理。通过用户说法+语料库数据对语义意图进行字面上的判断,可拦截一些算法角度错误的语义结果,同时可结合需求的变动,修改限制词典,达到无需重新训练语义算法模型的效果,当领域识别错误后,语义框架能及时兜底、对误识别文本拒识,大大降低了误识别率。
尽管这里参照本发明的解释性实施例对本发明进行了描述,上述实施例仅为本发明较佳的实施方式,本发明的实施方式并不受上述实施例的限制,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。
- 一种基于图谱匹配进行设备维修记录语义搜索的方法
- 语义拒识方法、语义拒识装置、交通工具及介质
- 语义拒识方法、语义拒识装置、交通工具及介质