一种基于帧对齐和注意力机制的深度学习视频去雾方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明属于数字图像处理领域,适用于有雾视频应用的前期预处理,更具体地说为一种基于帧对齐和注意力机制的深度学习视频去雾方法。
背景技术
雾霾天气是一种常见的自然现象。在雾霾天气条件下,空气中存在大量能够散射光线的微小颗粒,通过散射太阳光和物体反射的光线,造成可见光图像采集设备获取的图像质量大幅下滑,对高级计算机视觉任务产生恶劣的影响。为了改善图像的质量,提高图像的清晰度,对图像进行去雾处理很有必要。
视频去雾的输入通常为一个包含大量连续帧图片的视频序列,且不同视频帧之间存在一定相关性。视频去雾技术除了需要能够对单帧图像进行去雾之外,还需要考虑视频帧之间的一致性以及算法的实时性,所以直接将单幅图像去雾算法应用于视频去雾通常不可行。大量实验表明,如果直接将单幅图像去雾网络对视频单帧进行去雾处理,得到的去雾视频往往存在闪烁、色差等现象,既影响视频观感,又会造成信息损失。
基于传统方法的视频去雾算法,通常在基于物理模型的去雾算法基础之上,为视频帧添加时空一致性约束,减少帧间色彩差异,从而最终抑制去雾后的闪烁和色差现象。基于深度学习的方法,通常是在单幅图像去雾网络的基础之上,调整网络输入接口的数量,实现多个相邻帧同时输入,并利用网络的学习能力自动学习帧之间的相关性。尽管有各种方法能够抑制不良现象,但仍然存在一定局限性,需要进一步改进和提高。
发明内容
本发明提供了一种基于帧对齐和注意力机制的深度学习视频去雾方法,可以通过单幅图像去雾网络结合,实现端到端的视频去雾。
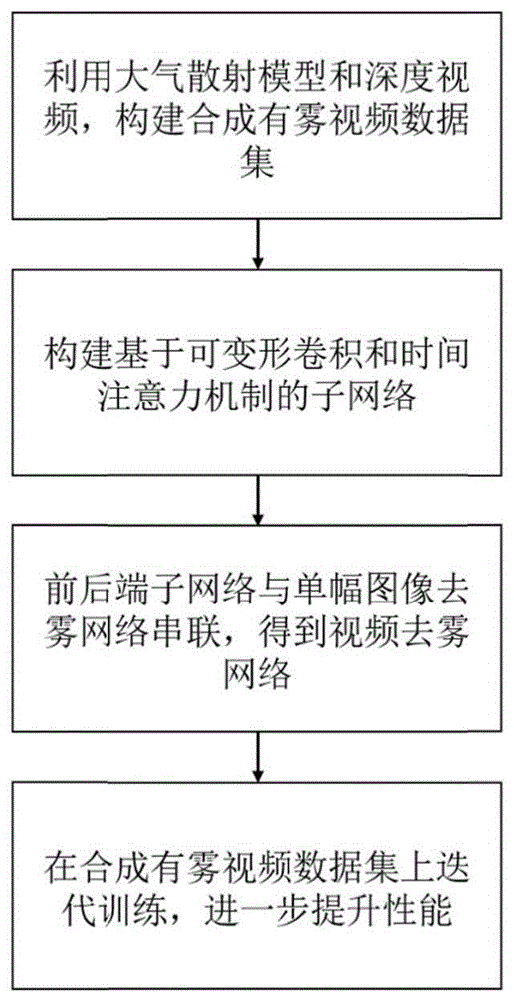
一种基于帧对齐和注意力机制的深度学习视频去雾方法,包括:
步骤1):利用大气散射模型对附带深度信息的原始无雾视频数据集进行加雾处理,获得合成视频去雾数据集;
步骤2):基于可变形卷积和时间注意力机制,构造前后端对齐子网络,并构成去雾网络模型,包括前端网络pre-net、单幅去雾网络以及后端网络after-net;
前端网络pre-net中,输入视频序列假设为5张大小为(1,3,h,w)的连续视频帧,在输入网络之前,先将其拼接成(1,15,h,w)维的输入特征并经过卷积得到初步处理的特征;
之后,经过两次连续尺度缩小一半的下采样,得到另外两个不同尺度的特征;第一次下采样后得到尺度和通道数缩小到一半的数据;
对于第二次下采样后尺度和通道数缩小到1/4的数据,通过一个可变形卷积Dconv进一步提取特征的信息,然后再进行上采样,得到缩小到原始数据一半的数据,将其与第一次下采样后尺度缩小一半、通道数翻倍的数据进行拼接后,再通过一个可变形卷积Dconv进一步提取特征的信息,最后再通过一次上采样,将数据恢复到原始大小;
将经过卷积得到初步处理的特征与上述恢复到原始大小的数据进行拼接后,再通过可变形卷积Dconv可以融合下采样前的特征信息弥补采样过程中的信息损失;当经过两次上采样和可变形卷积,特征经过两层卷积构成的Lastconv层,与最开始输入的中心帧图片I
单幅去雾网络接收连续视频帧(I
后端网络after-net的输入为经过单幅去雾网络处理后的去雾视频帧;去雾后得到5张连续的去雾图片
整理后的张量输入网络,首先通过一个预卷积层preconv对每张图片进行一次卷积,得到维度为(b,5,f,h,w)的特征F
将其中心帧特征保存起来,额外经过一个卷积层conv-ref,得到大小为(b,f,h,w)的中间特征F
同时,使用一个权值共享的卷积层对特征F
之后,将中心帧特征帧F
增添注意力后的特征通过两层卷积Fusion+Conv还原成单幅图像的尺度(b,c,h,w),再与中心帧去雾图片
步骤3):将合成有雾视频数据集输入到去雾网络模型中,在训练过程中通过新的损失函数计算损失,不断迭代更新网络参数,最终得到优化的去雾网络模型;
步骤4)、对于接收的带雾视频数据,输入到优化后的去雾网络模型中,得到去雾后的无图图像。
较佳的,所述步骤1)中,假设原始无雾的视频帧为J,生成的有雾视频帧为I,对应的图像深度为d,则生成有雾视频的公式如下:
I=(1-e
其中,β为随机选取的大气散射系数,其范围为β∈[0.2,0.8];A为随机选取的大气光照系数,范围为A∈[0.7,0.95];对于RGB图像三个颜色通道,其β和A相同;在同一场景的一组视频序列中,选取的β和A应保持一致。
较佳的,所述步骤3)中,所述损失函数由L
其中,
SSIM损失L
本发明具有如下有益效果:
本发明提出的模型可以实现端到端的视频去雾,通过为单幅图像增添前后端两个子网络,对有雾和去雾视频进行对齐处理,能够在不需要较大训练的情况下实现单幅去雾网络到视频去雾网络的切换,抑制单幅去雾网络应用于视频去雾中产生的闪烁和色差现象。
附图说明
图1是本发明的方法流程图;
图2是本发明的pre-net结构图;
图3是本发明的after-net结构图;
图4是本发明的视频去雾网络模型结构图。
具体实施方式
结合图1~图4,进一步详细说明本发明。
图1为发明的方法流程图,包括以下步骤:
步骤1):利用大气散射模型对附带深度信息的原始无雾视频数据集进行加雾处理,获得合成视频去雾数据集。
其中,假设原始无雾的视频帧为J,生成的有雾视频帧为I,对应的图像深度为d,则生成有雾视频的公式如下:
I=(1-e
其中,β为随机选取的大气散射系数,其范围为β∈[0.2,0.8]。A为随机选取的大气光照系数,范围为A∈[0.7,0.95]。对于RGB图像三个颜色通道,其β和A相同;在同一场景的一组视频序列中,选取的β和A应保持一致。在整个网络训练的过程中,选取5帧相邻帧,即(I
步骤2):基于可变形卷积和时间注意力机制,构造前后端对齐子网络,并构成去雾网络模型,如图4所示,包括前端网络pre-net、单幅去雾网络以及后端网络after-net。
本实例的前端网络pre-net结构如图2所示。前端网络pre-net由多层下采样和上采样所组成,最后网络将输入中心帧通过一个跳跃连接加到最后一个卷积层输出的特征之上,形成了一个类ResNet结构。
输入视频序列假设为5张大小为(1,3,h,w)的连续视频帧,在输入网络之前,先将其拼接成(1,15,h,w)维的输入特征并经过卷积得到初步处理的特征。
之后,经过两次连续尺度缩小一半的下采样,得到另外两个不同尺度的特征,以此构成一个特征梯度。第一次下采样后得到尺度和通道数缩小到一半的数据;
对于第二次下采样后尺度和通道数缩小到1/4的数据,通过一个可变形卷积Dconv进一步提取特征的信息,然后再进行上采样,得到缩小到原始数据一半的数据,将其与第一次下采样后尺度缩小到一半、通道数翻倍的数据进行拼接后,再通过一个可变形卷积Dconv进一步提取特征的信息,最后再通过一次上采样,将数据恢复到原始大小;
将经过卷积得到初步处理的特征与上述恢复到原始大小的数据进行拼接后,再通过可变形卷积Dconv可以融合下采样前的特征信息弥补采样过程中的信息损失。通过对每一尺度内可变形卷积层输出通道数进行设置,可以使得后续上采样得到的输出张量维度与同一层级下采样前的张量维度相同。当经过两次上采样和可变形卷积,特征经过两层卷积构成的Lastconv层,与最开始输入的中心帧图片I
其中的单幅去雾网络指预训练的,能实现端到端去雾的单幅图像去雾网络。单幅去雾网络接收连续视频帧(I
本实例的后端网络after-net结构如图3所示。after-net的输入为经过单幅去雾网络处理后的去雾视频帧。去雾后得到5张连续的去雾图片
整理后的张量输入网络,首先通过一个预卷积层preconv对每张图片进行一次卷积,得到维度为(b,5,f,h,w)的特征F
将其中心帧特征保存起来,额外经过一个卷积层conv-ref,得到大小为(b,f,h,w)的中间特征F
同时,使用一个权值共享的卷积层对特征F
之后,将中心帧特征帧F
增添注意力后的特征通过两层卷积Fusion+Conv还原成单幅图像的尺度(b,c,h,w),再与中心帧去雾图片
步骤3):将合成有雾视频数据集输入到去雾网络模型中,在训练过程中通过新的损失函数计算损失,不断迭代更新网络参数,最终得到优化的去雾网络模型。
本实例中使用的损失函数由L1损失和SSIM损失两个部分组成。其中L1损失公式为:
其中,
为了保证复原图像有良好观感,引入SSIM损失。SSIM损失是根据结构相似性指标SSIM设计的损失函数,希望去雾图片的SSIM指标更高。L
综合上述损失函数,最终损失函数为:
L=L
步骤4)、对于接收的带雾视频数据,输入到优化后的去雾网络模型中,得到去雾后的无图图像。
本发明提出的模型可以实现端到端的视频去雾。通过前后两个子网络对单幅图像去雾网络进行改进,通过帧对齐和时间注意力机制,抑制其直接用于视频去雾时的闪烁和色差现象,从而在较少样本的人造数据集上训练后,可以实现视频去雾的功能。
综上所述,以上仅为本发明的实例,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于多模态特征结合多层注意力机制的结合视频描述方法
- 一种基于深度学习和二维注意力机制的多帧微表情情感识别方法
- 一种基于帧注意力机制的视频人脸情绪识别方法