一种基于图空洞卷积编码器解码器的3D姿态估计方法
文献发布时间:2023-06-19 12:13:22
技术领域
本发明涉及计算机视觉领域,具体是指一种基于图空洞卷积编码器解码器的3D姿态估计方法。
背景技术
几十年来,人体姿态估计(Human Pose Estimation)在计算机视觉界备受关注,它是理解图像和视频中人物行为的关键一步,人体姿态估计包括2D姿态估计和3D姿态估计,其中2D姿态估计主要从图像估计出2D人体关节点坐标,而3D姿态估计旨在从2D关节点坐标(或2D图像)回归到3D姿态估计,3D姿态估计现在吸引了越来越多的注意力在很多计算机视觉领域,比如智能监控,人机交互,视频理解以及VR等等,在这个任务中,使用的数据是骨架数据,一系列人体关节点2D坐标,相较于RGB数据,骨架数据在动作识别中具有很好的鲁棒性和灵活性,因为在基于RGB数据的姿态估计中,预测过程容易受到图片帧中背景的干扰,从而在一定程度上降低准确率,另外骨架数据相比RGB数据,数据规模要小很多,从而减少了模型计算效率。
随着深度学习的发展,在3D姿态估计里面主要有两类方法,基于卷积神经网络(卷积神经网络)的和基于图神经网络(图神经网络)的,在之前,大部分方法习惯直接用卷积神经网络从图像回归出3D姿态坐标,而它们往往伴随有很大的计算量,后来随着2D姿态估计的成熟,一些模型开始图像先预处理得到2D姿态坐标,而后在进行回归得到3D姿态,把核心工作转移到2D姿态到3D姿态上,这一过程中,基于人体物理结构,2D和3D姿态都可以很自然的表示为一张图,这也是随后基于成为主流的图神经网络的模型所采取的数据表示形式,将人体关节点作为点,将基于身体物理连接的骨骼作为边,建立图,这样就可以利用强大的图神经网络来更好地融合骨架信息,来促进预测性能,在基于图神经网络的方法中,图卷积网络被频繁使用,图卷积网络可以看作卷积神经网络在非欧式空间数据上的推广,非常适合在像图一样的拓扑结构上提取信息。
存在的众多方法中,时空图卷积网络首先通过图卷积网络取关节信息,取得了比较好的性能和效率,但在双流自适应图卷积网络中,长范围信息没有被很好提取,受非局部网络的启发,加入了自适应图卷积模块,另外也是利用了双流架构,语义图卷积网络同时提取局部和非局部信息,在最新的半动态超图网络中,将人体骨架看作是一个超图,并且基于人体动力学建立静态和动态超图,从而提出了半动态超图网络来进行3D姿态估计。
然而,在存在的基于图神经网络的方法中,它们通常采用了受限的卷积核并且仅在单一关节尺度,这样忽略了丰富的多尺度上下文信息,事实上,这些多尺度上下文信息对促进预测性能是至关重要的,另外,先前的一些方法尝试提取非局部信息,但却忽略了带有丰富语义信息的位置编码信息(比如:关节类型)。
发明内容
基于以上问题,本发明提供了一种基于图空洞卷积编码器解码器的3D姿态估计方法,解决了在存在的基于图神经网络的方法中忽略多尺度上下文信息和语义信息问题以及提取非局部信息时忽略了带有丰富语义信息的位置编码信息的问题。
为解决以上技术问题,本发明采用的技术方案如下:
一种基于图空洞卷积编码器解码器的3D姿态估计方法,包括如下步骤:
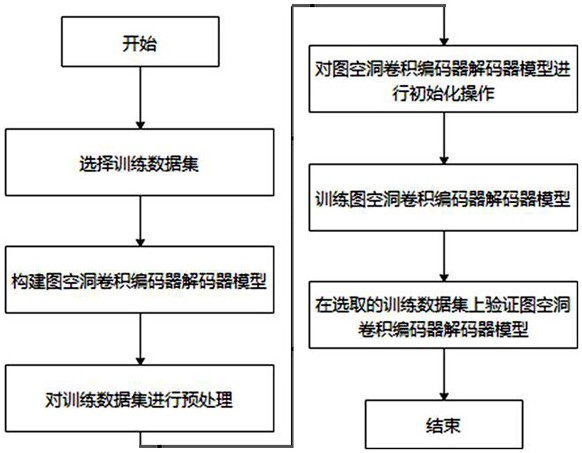
步骤S1:选择训练数据集;
步骤S2:构建图空洞卷积编码器解码器模型;
步骤S3:对训练数据集进行预处理;
步骤S4:对图空洞卷积编码器解码器模型进行初始化操作;
步骤S5:训练步骤S4的图空洞卷积编码器解码器模型;
步骤S6:用步骤S1选取的训练数据集验证步骤S5的图空洞卷积编码器解码器模型。
进一步,所述图空洞卷积编码器解码器模型由图空洞卷积和图转换器组合并堆叠形成一个编码器解码器的网络结构,所述图空洞卷积编码器解码器模型在训练时需要对损失函数和学习率的更新方式进行设置。
进一步,所述图空洞卷积包括多个并行卷积,每个并行卷积都包括根节点和k-邻居的邻接矩阵。
进一步,所述图空洞卷积并行计算公式如下:
其中,
进一步,所述步骤S2中的图转换器是将视觉转换器应用在表示人体骨架的图结构上,并结合位置编码和一个全局注意力矩阵形成的网络层。
进一步,所述步骤S2中利用图转换器得到全局的注意力矩阵的公式如下:
其中,
进一步,所述步骤S5中,图空洞卷积编码器解码器模型的损失函数设置为:
其中,
进一步,学习率的更新方式设置为:
其中,
与现有技术相比,有益效果为:
(1)本发明重新设计了一种能有效提取骨架多尺度上下文信息的图空洞卷积,它可以扩大图卷积核的感受野,并能学习到深层的多尺度上下文;
(2)本发明在图结构上使用转换器操作来更好地提取全局长范围连接并补充了先前方法忽略的包含语义信息的位置编码信息;
(3)本发明将图空洞卷积和图转换器组装并堆叠形成图空洞卷积编码器解码器模型,大大提高了3D姿态估计的预测性能;
(4)本发明提出的是端到端的模型,可以方便地被迁移到其它下游任务上。
附图说明
图1为本实施例的流程图。
具体实施方式
下面结合附图对本发明作进一步的说明。本发明的实施方式包括但不限于下列实施例。
本实施例中,一种基于图空洞卷积编码器解码器的3D姿态估计方法,包括图空洞卷积编码器解码器模型,该图空洞卷积编码器解码器模型由图空洞卷积GAC和图转换器GTL组合并堆叠形成一个编码器解码器的网络结构,此网络结构可以有效地提取姿态中的局部多尺度上下文和全局长范围连接,并能大幅提升3D姿态估计的性能,其中:
图空洞卷积关注于扩大卷积核感受野并学习到局部多尺度上下文,用于提取骨架中的多尺度上下文信息,在图空洞卷积中,扩张因子被定义为到根节点的距离,以这种方式,图空洞卷积被表示为并行卷积,单个并行卷积包括根节点和k-邻居的邻接矩阵(1-邻居、2-邻居和3-邻居等),k-邻居指到根节点距离为k的邻居,本实施例中,首先给出k-邻居的邻接矩阵
其中,
其中,
图空洞卷积并行计算公式表示每个并行分支所采用的图卷积操作,作用为促进全局上下文信息;全局池化后的骨架特征和并行图空洞卷积的输出相互拼接,然后输入至两个嵌入函数来获得高级别特征,以此来计算注意力矩阵,具体过程如下:
其中,Cat表示拼接操作,Avgpool为平均池化,
另外,本实施例中引入图转换器层来更好地捕捉长范围信息,因为姿态骨架中的关节点仅根据输入坐标不能唯一标识定位它们的类型(比如:左手、右手),这一位置编码信息是很关键的,例如,两个关节可能在不同的时间空间中坐标相同,但表示的类型含义可能不同,为此采用了正弦、余弦函数对位置序列进行编码来补充丢失掉的位置信息如下:
其中,pos为关节点在序列中的位置,i表示关节点特征的维度,Cin表示输入特征的总维度,PE表示经过位置编码后的特征。
在图转换器层中,原始输入首先和位置编码相加,然后分别被喂给两个嵌入函数来获得高级别特征;点乘被用来测量嵌入空间中两个关节的相似性,然后基于此来计算注意力矩阵(表示节点之间的关系强度):
其中,
为了获得基于人体动力学的多尺度特征,图池化和上采样操作需要被采用来有效捕捉多尺度信息的交互,以下是本实施例中所采用的图池化和图上采样操作:
其中,Cat表示拼接操作,Avgpool为平均池化,
本实施例提出的图空洞卷积编码器解码器模型堆叠了五个图空洞卷积和五个图转化器层在不同尺度,两个图卷积层被用于输入编码和输出解码;每一层后面都接上一个批量归一化和ReLU激活层。
另外,图空洞卷积编码器解码器模型的损失函数设置为:
其中,
基于以上,如图1所示,一种基于图空洞卷积编码器解码器的3D姿态估计方法,包括如下步骤:
步骤S1:选择训练数据集;
其中,本实施例选取了两个主流的3D姿态估计基准数据集进行实验,包括Human3.6M、MPI-INF-3DHP;
2D真实数据和3D真实数据对于监督3D姿态估计均可用,本实施例中使用五个主体(S1、S5、S6、S7和S8)来训练,使用另外两个主体(S9和S11)来测试,为了减少冗余,原始视频针对训练和测试分别采用了50fps和10fps的下采样;MPI-INF-3DHP是使用MoCap系统获得的数据集,测试集包含2929帧的图像,主要是来自6个主体的7个动作;
选择以上两个数据集是为了验证图空洞卷积编码器解码器模型对于不同类型数据集的适应性和鲁棒性,图空洞卷积编码器解码器模型在Human3.6M数据集上训练测试,仅在MPI-INF-3DHP上测试。
步骤S2:构建图空洞卷积编码器解码器模型;
本实施例中设计的图空洞卷积编码器解码器模型包含三个部分:图空洞卷积、图转换器、编码器解码器的网络结构,其中,图空洞卷积由包含根节点、1-邻居、2-邻居以及3-邻居组成的并行卷积,是一种高级的多尺度图卷积,专注于扩大图卷积核的感受野和提取骨架中的多尺度上下文信息;图转化器主要是为了补充语义位置编码信息并捕捉全局长范围连接;图空洞卷积和图转换器组合并堆叠,然后使用图池化和上采样形成编码器解码器的网络结构。
步骤S3:对训练数据集进行预处理;
其中,在图空洞卷积编码器解码器模型训练的过程中,需要将所有姿态估计坐标进行一定的预处理,根据数据的需要可以适当使用随机旋转,归一化,去噪等操作。
步骤S4:对图空洞卷积编码器解码器模型进行初始化操作;
其中,对图空洞卷积编码器解码器模型所有参数进行合适的随机初始化操作,以便模型能够快速收敛。
步骤S5:训练步骤S4的图空洞卷积编码器解码器模型;
其中,在训练过程中,由于主要使用Human3.6M和MPI-INF-3DHP两个数据集,其输入网络的骨架关节点数目大小都是16,网络通道数都设置为128,除了图转换器的中间通道为32以便降低模型参数量,多尺度中不同尺度的关节点分别是关节尺度16个关节、部位尺度10个关节、身体尺度5个关节,并且批量大小都是256,学习率设定0.001,使用Adam优化器进行学习,总的迭代数目设置为50,每隔25000次迭代学习率乘以0.96,实验均是在PyTorch深度学习框架下开展;
另外,图空洞卷积编码器解码器模型的损失函数设置为:
其中,
步骤S6:用步骤S1选取的训练数据集验证步骤S5的图空洞卷积编码器解码器模型
对于不同数据集评估指标也不同,对于Human3.6M数据集,平均关节位置误差MPJPE和经过刚性变换后的关节位置误差P-MPJPE被当作主要评估指标;而对于MPI-INF-3DHP数据集,正确关节点百分比PCK和位于ROC曲线下面积AUC两个指标被采用来进行测试评估;
本实施例分别在Human3.6M和MPI-INF-3DHP两个数据集测试了模型的性能,两个数据集上的四个不同指标都达到了极好的结果,如下表所示:
(在Human3.6M数据集上图空洞卷积编码器解码器模型性能(MPJPE)对比表格)
(在Human3.6M数据集上图空洞卷积编码器解码器模型性能(P-MPJPE)对比表格)
从上面两个表格可以看出,本实施例在Human3.6M数据集的大部分动作类别以及平均结果上均优于现有方法,本实施例在MPJPE和P-MPJPE上的最终Avg误差分别改善到了38.2mm和29.4mm,分别提升了1.7mm和2.7mm,如下表所示:
(在MPI-INF-3DHP数据集上图空洞卷积编码器解码器模型性能(PCK&AUC)对比图)
从上表可以看出,本实施例在MPI-INF-3DHP数据集上性能得到了巨大的提升,并且在最终的PCK和AUC分数达到了76.4%和39.3%,分别较之前方法提升了1.5%和1.8%,基于此本实施例提出的基于图空洞卷积编码器解码器模型对于3D姿态估计任务能够有效地提取到多尺度上下文信息和全局长范围连接,这对于3D姿态估计是非常有帮助的,能极大地弥补当前方法所存在的缺点。
本实施例分别在Human3.6M和MPI-INF-3DHP两个数据集测试了模型的性能,两个数据集上的四个不同指标都达到了极好的结果,从表1、表2可以看出,本实施例在Human3.6M数据集的大部分动作类别以及平均结果上均优于现有方法,本实施例在MPJPE和P-MPJPE上的最终平均误差分别改善到了38.2mm和29.4mm,分别提升了1.7mm和2.7mm,从表3可以看出,本实施例在MPI-INF-3DHP数据集上性能得到了巨大的提升,并且在最终的PCK和AUC分数达到了76.4%和39.3%,分别较之前方法提升了1.5%和1.8%,基于此本实施例提出的基于图空洞卷积编码器解码器模型对于3D姿态估计任务能够有效地提取到多尺度上下文信息和全局长范围连接,这对于3D姿态估计是非常有帮助的,能极大地弥补当前方法所存在的缺点。
如上即为本发明的实施例。上述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
- 一种基于图空洞卷积编码器解码器的3D姿态估计方法
- 一种基于图空洞卷积编码器解码器的3D姿态估计方法