条目抽取方法、装置、电子设备及存储介质
文献发布时间:2023-06-19 19:28:50
技术领域
本申请涉及数据处理技术领域,尤其涉及一种条目抽取方法、装置、电子设备及存储介质。
背景技术
随着人工智能技术的不断发展,基于人工智能的信息抽取技术的应用越来越广泛。在信息抽取领域,现有技术依赖于通过序列化文本进行实体识别,提取各实体的关键字段,无法对文档中的结构化层次信息进行捕捉,关系匹配效果较差。
发明内容
有鉴于此,本申请提供一种条目抽取方法、装置、电子设备及存储介质,旨在提升字段信息之间的关系匹配效果,解决现有字段信息之间的关系匹配效率较差的技术问题。
本申请提供一种条目抽取方法,包括以下步骤:
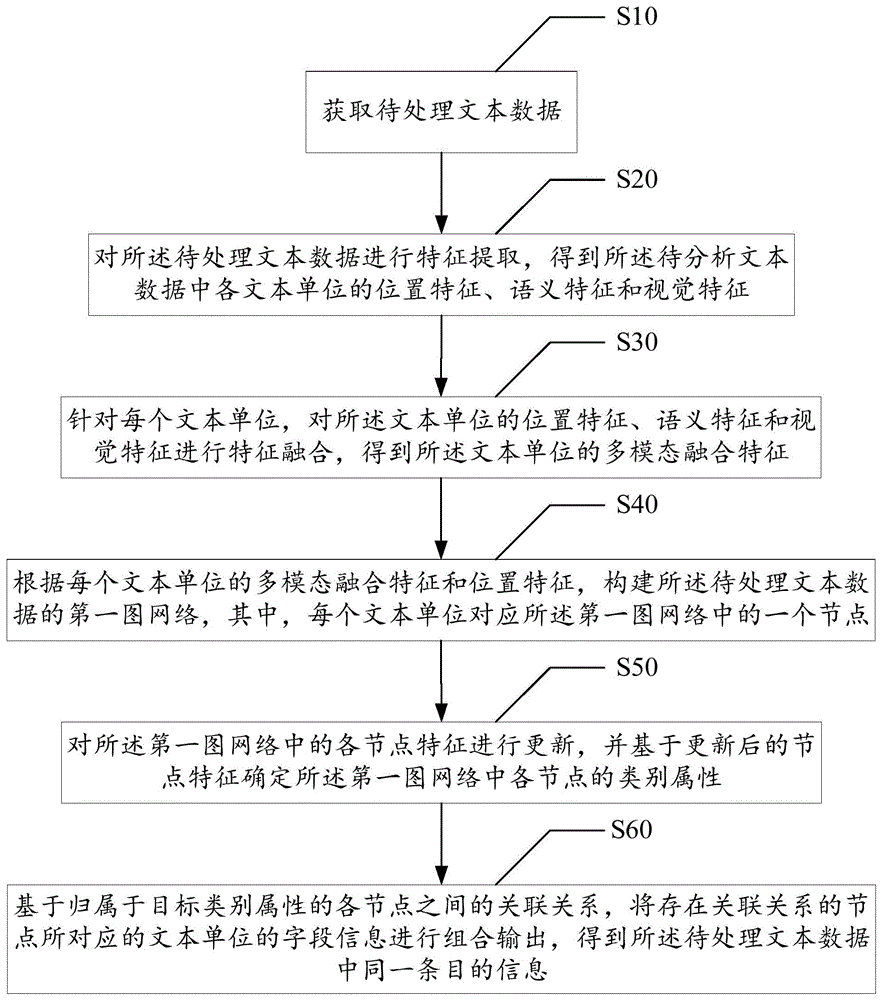
获取待处理文本数据;
对所述待处理文本数据进行特征提取,得到所述待分析文本数据中各文本单位的位置特征、语义特征和视觉特征;
针对每个文本单位,对所述文本单位的位置特征、语义特征和视觉特征进行特征融合,得到所述文本单位的多模态融合特征;
根据每个文本单位的多模态融合特征和位置特征,构建所述待处理文本数据的图网络,其中,每个文本单位对应所述图网络中的一个节点;
对所述第一图网络中的各节点特征进行更新,并基于更新后的节点特征确定所述第一图网络中各节点的类别属性;
基于归属于目标类别属性的各节点之间的关联关系,存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息。
在本申请的一种可能的实施方式中,所述对所述待处理文本数据进行特征提取,得到所述待分析文本数据中各文本单位的位置特征、语义特征和视觉特征的步骤,包括:
对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息;
针对每个文本单位,基于所述文本单位的文本信息,确定所述文本单位的文本语义特征;
针对每个文本单位,基于所述文本单位的文本语义特征,利用预设语义模型确定所述文本单位的上下文语义特征;
针对每个文本单位,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行加权融合,得到所述文本单位的语义特征;
针对每个文本单位,基于所文本单位的位置信息,确定所述文本单位的位置特征;
针对每个文本单位,基于所述文本单位的位置信息,通过RoIAlign方法对所述位置信息对应的特征图进行池化操作,得到所述文本单位的视觉特征。
在本申请的一种可能的实施方式中,所述针对每个文本单位,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行加权融合,得到所述文本单位的语义特征的步骤,包括:
针对每个文本单位,基于预设门控函数,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行计算,得到门控特征;
基于预设激活函数,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行计算,得到原始特征;
对所述门控特征和所述原始特征进行点乘操作,并将点乘操作后得到的结果特征与所述文本语义特征相加,得到所述文本单位的语义特征。
在本申请的一种可能的实施方式中,所述待处理文本数据为图片格式;
对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息的步骤,包括:
利用预设OCR算法对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息;
所述待处理文本数据为PDF;
对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息的步骤,包括:
利用预设PDF解析工具对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息。
在本申请的一种可能的实施方式中,所述针对每个文本单位,对所述文本单位的位置特征、语义特征和视觉特征进行特征融合,得到所述文本单位的多模态融合特征的步骤,包括:
针对每个文本单位,对所述文本单位的语义特征和视觉特征进行预处理,得到与所述位置特征相同维度的语义特征和视觉特征;
将相同维度的位置特征、语义特征和视觉特征进行相加,并归一化处理,得到所述文本单元的多模态融合特征。
在本申请的一种可能的实施方式中,所述对所述第一图网络中的各节点特征进行更新的步骤,包括:
基于多头自注意力机制,利用节点特征和边特征,对所述第一图网络中的节点特征进行迭代更新,直至迭代次数满足预设次数;
其中,第一次迭代所利用的节点特征为所述多模态融合特征,第i+1次迭代更新所利用的节点特征为第i次迭代更新所生成的节点特征,所有次迭代更新所利用的边特征是基于所述第一图网络中各节点的位置特征所确定的。
在本申请的一种可能的实施方式中,所述基于更新后的节点特征确定所述第一图网络中各节点的类别属性的步骤,包括:
针对每个节点,将更新后的节点特征与所述节点所对应的上下文语义特征进行拼接,并对拼接结果进行更新,得到上下文特征;
基于所述上下文特征的与所述节点所对应的文本语义特征,进行信息抽取,确定所述节点的类别属性。
在本申请的一种可能的实施方式中,所述基于归属于目标类别属性的各节点之间的关联关系,将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息的步骤,包括:
根据所述第一图网络中各节点的类别属性,从所述第一图网络中获取归属于目标类别属性的节点;
根据所述归属于目标类别属性的各节点,建立第二图网络;
对所述第二图网络的边特征进行sigmod操作,得到邻接矩阵,其中,所述邻近矩阵中的参数用于表征节点之间的关联关系;
若所述邻近矩阵中的参数为1,则该参数对应的节点之间存在关联关系;
若所述邻近矩阵中的参数为0,则该参数对应的节点之间不存在关联关系;
将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息。
本申请还提供一种条目抽取装置,所述装置包括:
获取模块,用于获取待处理文本数据;
特征提取模块,用于对所述待处理文本数据进行特征提取,得到所述待分析文本数据中各文本单位的位置特征、语义特征和视觉特征;
特征融合模块,用于针对每个文本单位,对所述文本单位的位置特征、语义特征和视觉特征进行特征融合,得到所述文本单位的多模态融合特征;
图网络构建模块,用于根据每个文本单位的多模态融合特征和位置特征,构建所述待处理文本数据的第一图网络,其中,每个文本单位对应所述第一图网络中的一个节点;
特征更新模块,用于对所述第一图网络中的各节点特征进行更新;
信息抽取模块,用于基于更新后的节点特征确定所述第一图网络中各节点的类别属性;
条目抽取模块,用于基于归属于目标类别属性的各节点之间的关联关系,将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息。
在本申请的一种可能的实施方式中,所述特征提取模块包括:
文本单位识别单元,用于对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息;文本语义特征提取单元,用于针对每个文本单位,基于所述文本单位的文本信息,确定所述文本单位的文本语义特征;上下文语义特征提取单元,用于针对每个文本单位,基于所述文本单位的文本语义特征,利用预设语义模型确定所述文本单位的上下文语义特征;语义特征融合单元,用于针对每个文本单位,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行加权融合,得到所述文本单位的语义特征;位置特征提取单元,用于针对每个文本单位,基于所文本单位的位置信息,确定所述文本单位的位置特征;视觉特征提取单元,用于针对每个文本单位,基于所述文本单位的位置信息,通过RoIAlign方法对所述位置信息对应的特征图进行池化操作,得到所述文本单位的视觉特征;
和/或者所述语义特征融合单元,具体用于:针对每个文本单位,基于预设门控函数,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行计算,得到门控特征;基于预设激活函数,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行计算,得到原始特征;对所述门控特征和所述原始特征进行点乘操作,并将点乘操作后得到的结果特征与所述文本语义特征相加,得到所述文本单位的语义特征;
和/或者所述待处理文本数据为图片格式,所述文本单位识别单元,具体用于:利用预设OCR算法对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息;所述待处理文本数据为PDF,所述文本单位识别单元,具体用于:利用预设PDF解析工具对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息;
和/或者所述特征融合模块,具体用于:针对每个文本单位,对所述文本单位的语义特征和视觉特征进行预处理,得到与所述位置特征相同维度的语义特征和视觉特征;将相同维度的位置特征、语义特征和视觉特征进行相加,并归一化处理,得到所述文本单元的多模态融合特征;
和/或者所述特征更新模块,具体用于:基于多头自注意力机制,利用节点特征和边特征,对所述第一图网络中的节点特征进行迭代更新,直至迭代次数满足预设次数;
其中,第一次迭代所利用的节点特征为所述多模态融合特征,第i+1次迭代更新所利用的节点特征为第i次迭代更新所生成的节点特征,所有次迭代更新所利用的边特征是基于所述第一图网络中各节点的位置特征所确定的;
和/或者所述信息抽取模块,具体用于:针对每个节点,将更新后的节点特征与所述节点所对应的上下文语义特征进行拼接,并对拼接结果进行更新,得到上下文特征;基于所述上下文特征的与所述节点所对应的文本语义特征,进行信息抽取,确定所述节点的类别属性;
和/或者所述条目抽取模块,具体用于:根据所述第一图网络中各节点的类别属性,从所述第一图网络中获取归属于目标类别属性的节点;根据所述归属于目标类别属性的各节点,建立第二图网络;对所述第二图网络的边特征进行sigmod操作,得到邻接矩阵,其中,所述邻近矩阵中的参数用于表征节点之间的关联关系;若所述邻近矩阵中的参数为1,则该参数对应的节点之间存在关联关系;若所述邻近矩阵中的参数为0,则该参数对应的节点之间不存在关联关系;将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息。
本申请还提供一种电子设备,所述设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的条目抽取程序,所述条目抽取程序配置为实现如上所述的条目抽取方法的步骤。
本申请还提供一种存储介质,所述存储介质上存储有条目抽取程序,所述条目抽取程序被处理器执行时实现如上所述的条目抽取方法的步骤。
本申请提供一种条目抽取方法、装置、电子设备及存储介质,与现有技术中,通过序列化文本进行实体识别,提取各实体的关键字段,无法对文档中的结构化层次信息进行捕捉,关系匹配效果较差相比,在本申请中,获取待处理文本数据;对所述待处理文本数据进行特征提取,得到所述待分析文本数据中各文本单位的位置特征、语义特征和视觉特征;针对每个文本单位,对所述文本单位的位置特征、语义特征和视觉特征进行特征融合,得到所述文本单位的多模态融合特征;根据每个文本单位的多模态融合特征和位置特征,构建所述待处理文本数据的第一图网络,其中,每个文本单位对应所述第一图网络中的一个节点;对所述第一图网络中的各节点特征进行更新,并基于更新后的节点特征确定所述第一图网络中各节点的类别属性;基于归属于目标类别属性的各节点之间的关联关系,将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息,从而提升了字段信息之间的关系匹配效果。
附图说明
图1为本申请条目抽取方法一实施例的流程示意图;
图2为本申请条目抽取方法一实施例的的原理示意图;
图3为本申请语义特征融合的原理示意图;
图4是本申请实施例方案涉及的硬件运行环境的电子设备的结构示意图。
本申请目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
本申请实施例提供一种条目抽取方法,如图1所示,在本申请条目抽取方法的一实施例中,所述方法包括:
步骤S10、获取待处理文本数据;
步骤S20、对所述待处理文本数据进行特征提取,得到所述待分析文本数据中各文本单位的位置特征、语义特征和视觉特征;
步骤S30、针对每个文本单位,对所述文本单位的位置特征、语义特征和视觉特征进行特征融合,得到所述文本单位的多模态融合特征;
步骤S40、根据每个文本单位的多模态融合特征和位置特征,构建所述待处理文本数据的第一图网络,其中,每个文本单位对应所述第一图网络中的一个节点;
步骤S50、对所述第一图网络中的各节点特征进行更新,并基于更新后的节点特征确定所述第一图网络中各节点的类别属性;
步骤S60、基于归属于目标类别属性的各节点之间的关联关系,将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息。
本实施例旨在:提升字段信息之间的关系匹配效果。
具体地,在本申请中,将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到待处理文本数据中同一条目的信息,从而提升了字段信息之间的关系匹配效果。
具体地,在本申请中,对文本单位的文本语义特征和上下文语义特征进行加权融合,进而得到文本单位的语义特征,丰富了文本单位的语义特征。
具体地,在本申请中,待处理文本数据可以为图片格式,也可以为PDF,支持对各种行形式的待处理文本数据进行条目抽取,使得适用范围提升,具有很高的鲁棒性和泛化能力。
具体地,在本申请中,使用了语义特征、视觉特征和语义特征融合得到的多模态融合特征来构建图网络,对于各种复杂的文档都能够适用,使得适用范围和性能大辐射提升。
具体地,在本申请中,利用多头自注意力机制对图网络中各节点的节点特征进行更新,即对多模态融合特征进行更新,进而保证充分融合不同的模态特征之间的互补信息,进而提高了信息抽取的准确性。
具体地,在本申请中,基于归属于目标类别属性的各节点之间的关联关系,将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到待处理文本数据中同一条目的信息。可以理解的是,本申请能同时实现信息抽取和条目抽取,功能全面。且本申请从归属于目标类别属性的各节点中选取存在关联关系的节点,进行条目抽取,提高了条目抽取的效率。
如图2所示,具体步骤如下:
步骤S10、获取待处理文本数据;
作为一种示例,待处理文本数据可以是图片格式,也可以是PDF。
步骤S20、对所述待处理文本数据进行特征提取,得到所述待分析文本数据中各文本单位的位置特征、语义特征和视觉特征。
作为一种示例,文本单位的粒度包括:字符、句子、段落、版面等。可以理解的是,在本实施例中,条目抽取的粒度包括字符级别(文本单位的粒度为字符),还包括文本块级别(文本单位的粒度为句子、段落和版面),能覆盖各个力度,具有很好的鲁棒性和泛化能力。
作为一种示例,所述对所述待处理文本数据进行特征提取,得到所述待分析文本数据中各文本单位的位置特征、语义特征和视觉特征的步骤,包括以下步骤S201-S206:
步骤S201、对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息。
作为一种示例,当待处理文本数据为图片格式时,利用预设OCR算法对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息。
作为一种示例,根据卷积神经网络,对待处理文本数据进行特征提取,得到第一特征图;利用区域生成网络,在第一特征图上生成多个目标候选框,作为RoIAlign层的输入;RoIAlign层根据目标候选框的位置坐标,在所第一特征图中将相应的区域池化为固定尺寸的第二特征图,作为文本检测网络和文本识别网络的输入;文本检测网络输出文本检测框及其位置坐标,文本检测框的位置坐标即为各文本单位的位置信息;文本识别网络输出文本检测框区域的识别结果作为各文本单位的文本信息。
作为一种示例,卷积神经网络可以为ResNet网络,区域生成网络可以为RPN网络,文本检测网络可以为Mask RCNN网络,文本识别网络可以为CRNN网络。
在本申请实施例中,将文本单位的位置信息和文本信息置于同一网络框架下,共享同一特征共享层,可以整体的进行端到端的优化,不需要繁琐的后处理和参数调节,不依赖于太多的人工干预。
作为一种示例,当待处理文本数据为PDF时,利用预设PDF解析工具对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息。
步骤S202、针对每个文本单位,基于所述文本单位的文本信息,确定所述文本单位的文本语义特征。
作为一种示例,利用CNN网络对文本单位的文本信息进行语义提取,得到文本单位的文本语义特征。具体地,给定文本单位的逐字符特征,通过CNN网络对逐字符特征进行汇聚,得到文本语义特征。
步骤S203、针对每个文本单位,基于所述文本单位的文本语义特征,利用预设语义模型确定所述文本单位的上下文语义特征。
如图3所示,作为一种示例,对文本单位的文本语义特征依次进行线性处理和argmax操作,利用预训练模型(BERT、BART等),将操作得到的特征转换为上下文语义特征。
步骤S204、针对每个文本单位,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行加权融合,得到所述文本单位的语义特征。
如图3所示,作为一种示例,所述针对每个文本单位,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行加权融合,得到所述文本单位的语义特征的步骤,包括以下步骤A1-A3:
步骤A1、针对每个文本单位,基于预设门控函数,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行计算,得到门控特征。
作为一种示例,预设门控函数如下所示:
g′=σ(W
其中,g′表征门控特征,a表征上下文语义特征,z表征文本语义特征,W
步骤A2、基于预设激活函数,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行计算,得到原始特征。
作为一种示例,预设激活函数如下所示:
r′=δ(W
其中,r′表征原始特征,a表征上下文语义特征,z表征文本语义特征,W
步骤A3、对所述门控特征和所述原始特征进行点乘操作,并将点乘操作后得到的结果特征与所述文本语义特征相加,得到所述文本单位的语义特征。
作为一种示例,对所述门控特征和所述原始特征进行点乘操作,并将点乘操作后得到的结果特征与所述文本语义特征相加的计算公式如下:
o=g′⊙r′+W
其中,o表征原始特征,g′表征门控特征,r′表征原始特征,z表征文本语义特征,W
步骤S205、针对每个文本单位,基于所文本单位的位置信息,确定所述文本单位的位置特征。
作为一种示例,文本单位的位置信息为文本检测框的位置坐标B
P
步骤S206、针对每个文本单位,基于所述文本单位的位置信息,通过RoIAlign方法对所述位置信息对应的特征图进行池化操作,得到所述文本单位的视觉特征。
作为一种示例,为根据文本单位的位置信息,在根据卷积神经网络,对待处理文本数据进行特征提取所得到的第一特征图中截取该位置信息对应的图像,作为特征图。
步骤S30、针对每个文本单位,对所述文本单位的位置特征、语义特征和视觉特征进行特征融合,得到所述文本单位的多模态融合特征。
作为一种示例,针对每个文本单位,对所述文本单位的位置特征、语义特征和视觉特征进行特征融合,得到所述文本单位的多模态融合特征的步骤,包括以下步骤S301-S302:
步骤S301、针对每个文本单位,对所述文本单位的语义特征和视觉特征进行预处理,得到与所述位置特征相同维度的语义特征和视觉特征。
作为一种示例,对所述文本单位的语义特征和视觉特征进行预处理的步骤,包括:通过卷积神经网络层,将视觉特征和语义特征映射到位置特征的相同维度。进而得到与所述位置特征相同维度的语义特征和视觉特征。
步骤S302、将相同维度的位置特征、语义特征和视觉特征进行相加,并归一化处理,得到所述文本单元的多模态融合特征。
作为一种示例,通过预设多模态融合特征获取公式,将相同维度的位置特征、语义特征和视觉特征进行相加,并归一化处理,得到所述文本单元的多模态融合特征。其中,预设多模态融合特征获取公式如下所示:
F
其中,F
步骤S40、根据每个文本单位的多模态融合特征和位置特征,构建所述待处理文本数据的第一图网络,其中,每个文本单位对应所述第一图网络中的一个节点。
作为一种示例,根据每个文本单位的多模态融合特征和位置特征,构建所述待处理文本数据的第一图网络的步骤,包括:
步骤S41、根据每个文本单位的多模态融合特征,建立第一图网络中各节点的节点特征;
步骤S42、根据每个文本单位的位置特征,建立所述第一图网络中各节点的边特征。
可以理解的是,在本申请实施例中,将文本单位的多模态融合特征作为节点特征;根据文本单位的位置特征,构建位置之间存在关联的节点之间的边。
步骤S50、对所述第一图网络中的各节点特征进行更新,并基于更新后的节点特征确定所述第一图网络中各节点的类别属性。
作为一种示例,对所述第一图网络中的各节点特征进行更新的步骤,包括:
基于多头自注意力机制,利用节点特征和边特征,对所述第一图网络中的节点特征进行迭代更新,直至迭代次数满足预设次数。
其中,第一次迭代所利用的节点特征为所述多模态融合特征,第i+1次迭代更新所利用的节点特征为第i次迭代更新所生成的节点特征,所有次迭代更新所利用的边特征是基于所述第一图网络中各节点的位置特征所确定的。
作为一种示例,根据第一图网络中各节点的位置特征,确定节点之间的相对位置特征作为边特征。在实际应用过程中,可以根据第一图网络中各节点的位置信息,确定节点之间的相对位置信息,对相对位置信息进行编码,得到相对位置特征作为边特征。其中,对相对位置信息进行编码得到相对位置特征的过程,与对位置信息进行编码得到位置特征的过程相同,在此不再赘述。
作为一种示例,每一次迭代更新,得到更新后的节点特征的计算公式如下:
其中,
其中,W
为两两文本单位所对应的文本检测框之间的相对坐标关系;Q、K、V三个矩阵是基于对输入至网络层的节点特征和边特征进行相加操作,将相加后的特征分别与三个系数相乘所得到的。
作为一种示例,预设次数本申请实施例不作具体限定。例如,预设次数可以为2次。
可以理解的是,第一图网络中的各节点特征即为各文本单位的多模态融合特征。在本申请中,相比于对位置特征、语义特征和视觉特征直接拼接或相加所得到的多模态融合特征无法充分融合不同的模态特征的互补信息,利用多头自注意力机制对第一图网络中的各节点特征进行更新,更新后的各节点特征(多模态融合特征)充分融合了不同的模态特征的互补信息,进而可以提高信息抽取的准确性。
作为一种示例,基于更新后的节点特征确定所述第一图网络中各节点的类别属性的步骤,包括:
针对每个节点,将更新后的节点特征与所述节点所对应的上下文语义特征进行拼接,并对拼接结果进行更新,得到上下文特征;
基于所述上下文特征的与所述节点所对应的文本语义特征,进行信息抽取,确定所述节点的类别属性。
作为一种示例,使用卷积神经网络对拼接结果进行更新,得到上下文特征。
作为一种示例,基于文本语义特征和上下文特征,利用双向LSTM进行信息抽取,得到节点的类别属性。其中,节点的类别属性是由用户自定义的,在本实施例中不作具体限定。
步骤S60、基于归属于目标类别属性的各节点之间的关联关系,将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息。
作为一种示例,基于归属于目标类别属性的各节点之间的关联关系,将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息的步骤,包括以下步骤步骤S601-步骤S504:
步骤S601、根据所述第一图网络中各节点的类别属性,从所述第一图网络中获取归属于目标类别属性的节点。
步骤S602、根据所述归属于目标类别属性的各节点,建立第二图网络。
步骤S603、对所述第二图网络的边特征进行sigmod操作,得到邻接矩阵,其中,所述邻近矩阵中的参数用于表征节点之间的关联关系;
作为一种示例,第二图网络中每个节点的节点特征为
其中,
步骤S604、若所述邻近矩阵中的参数为1,则该参数对应的节点之间存在关联关系;
步骤S605、若所述邻近矩阵中的参数为0,则该参数对应的节点之间不存在关联关系。
举例说明,若邻近矩阵中第一行第n列的参数为1,在该参数对应的节点(第一节点和第n节点)之间存在关联关系;若邻近矩阵中第一行第n列的参数为0,在该参数对应的节点(第一节点和第n节点)之间不存在关联关系。
步骤S606、将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息。
参照图4,图4为本申请实施例方案涉及的硬件运行环境的电子设备结构示意图。
如图4所示,该电子设备可以包括:处理器1001,例如中央处理器(CentralProcessing Unit,CPU),通信总线1002、用户接口1003,网络接口1004,存储器1005。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(Display)、输入单元比如键盘(Keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如无线保真(WIreless-FIdelity,WI-FI)接口)。存储器1005可以是高速的随机存取存储器(RandomAccess Memory,RAM)存储器,也可以是稳定的非易失性存储器(Non-Volatile Memory,NVM),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
本领域技术人员可以理解,图4中示出的结构并不构成对电子设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图4所示,作为一种存储介质的存储器1005中可以包括操作系统、数据存储模块、网络通信模块、用户接口模块以及条目抽取程序。
在图4所示的电子设备中,网络接口1004主要用于与其他设备进行数据通信;用户接口1003主要用于与用户进行数据交互;本申请电子设备中的处理器1001、存储器1005可以设置在电子设备中,所述电子设备通过处理器1001调用存储器1005中存储的条目抽取程序,并执行上述任一项所述的条目抽取方法的步骤。
本申请实施例电子设备具体实施方式与上述条目抽取方法各实施例基本相同,在此不再赘述。
本申请实施例还提供一种条目抽取装置,所述装置包括:
获取模块,用于获取待处理文本数据;
特征提取模块,用于对所述待处理文本数据进行特征提取,得到所述待分析文本数据中各文本单位的位置特征、语义特征和视觉特征;
特征融合模块,用于针对每个文本单位,对所述文本单位的位置特征、语义特征和视觉特征进行特征融合,得到所述文本单位的多模态融合特征;
图网络构建模块,用于根据每个文本单位的多模态融合特征和位置特征,构建所述待处理文本数据的第一图网络,其中,每个文本单位对应所述第一图网络中的一个节点;
特征更新模块,用于对所述第一图网络中的各节点特征进行更新;
信息抽取模块,用于基于更新后的节点特征确定所述第一图网络中各节点的类别属性;
条目抽取模块,用于基于归属于目标类别属性的各节点之间的关联关系,将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息。
在本申请的一种可能的实施方式中,所述特征提取模块包括:
文本单位识别单元,用于对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息;文本语义特征提取单元,用于针对每个文本单位,基于所述文本单位的文本信息,确定所述文本单位的文本语义特征;上下文语义特征提取单元,用于针对每个文本单位,基于所述文本单位的文本语义特征,利用预设语义模型确定所述文本单位的上下文语义特征;语义特征融合单元,用于针对每个文本单位,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行加权融合,得到所述文本单位的语义特征;位置特征提取单元,用于针对每个文本单位,基于所文本单位的位置信息,确定所述文本单位的位置特征;视觉特征提取单元,用于针对每个文本单位,基于所述文本单位的位置信息,通过RoIAlign方法对所述位置信息对应的特征图进行池化操作,得到所述文本单位的视觉特征;
和/或者所述语义特征融合单元,具体用于:针对每个文本单位,基于预设门控函数,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行计算,得到门控特征;基于预设激活函数,对所述文本单位的文本语义特征和所述文本单位的上下文语义特征进行计算,得到原始特征;对所述门控特征和所述原始特征进行点乘操作,并将点乘操作后得到的结果特征与所述文本语义特征相加,得到所述文本单位的语义特征;
和/或者所述待处理文本数据为图片格式,所述文本单位识别单元,具体用于:利用预设OCR算法对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息;所述待处理文本数据为PDF,所述文本单位识别单元,具体用于:利用预设PDF解析工具对所述待处理文本数据进行文本单位的识别,得到所述待处理文本数据中各文本单位的位置信息和文本信息;
和/或者所述特征融合模块,具体用于:针对每个文本单位,对所述文本单位的语义特征和视觉特征进行预处理,得到与所述位置特征相同维度的语义特征和视觉特征;将相同维度的位置特征、语义特征和视觉特征进行相加,并归一化处理,得到所述文本单元的多模态融合特征;
和/或者所述特征更新模块,具体用于:基于多头自注意力机制,利用节点特征和边特征,对所述第一图网络中的节点特征进行迭代更新,直至迭代次数满足预设次数。
其中,第一次迭代所利用的节点特征为所述多模态融合特征,第i+1次迭代更新所利用的节点特征为第i次迭代更新所生成的节点特征,所有次迭代更新所利用的边特征是基于所述第一图网络中各节点的位置特征所确定的;
和/或者所述信息抽取模块,具体用于:针对每个节点,将更新后的节点特征与所述节点所对应的上下文语义特征进行拼接,并对拼接结果进行更新,得到上下文特征;基于所述上下文特征的与所述节点所对应的文本语义特征,进行信息抽取,确定所述节点的类别属性;
和/或者所述条目抽取模块,具体用于:根据所述第一图网络中各节点的类别属性,从所述第一图网络中获取归属于目标类别属性的节点;根据所述归属于目标类别属性的各节点,建立第二图网络;对所述第二图网络的边特征进行sigmod操作,得到邻接矩阵,其中,所述邻近矩阵中的参数用于表征节点之间的关联关系;若所述邻近矩阵中的参数为1,则该参数对应的节点之间存在关联关系;若所述邻近矩阵中的参数为0,则该参数对应的节点之间不存在关联关系;将存在关联关系的节点所对应的文本单位的字段信息进行组合输出,得到所述待处理文本数据中同一条目的信息。
本申请实施例条目抽取装置的具体实施方式与上述条目抽取方法各实施例基本相同,在此不再赘述。
本申请实施例还提供了一种存储介质,且所述存储介质存储有一个或者一个以上程序,所述一个或者一个以上程序还可被一个或者一个以上的处理器执行以用于实现上述任一项所述的条目抽取方法的步骤。
本申请实施例存储介质具体实施方式与上述条目抽取方法各实施例基本相同,在此不再赘述。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本申请实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本申请各个实施例所述的方法。
以上仅为本申请的优选实施例,并非因此限制本申请的专利范围,凡是利用本申请说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本申请的专利保护范围内。
- 语句条目交互方法与装置、电子设备、存储介质
- 数据抽取方法、装置、存储介质及电子设备
- 文本中的实体关系抽取方法及系统、存储介质、电子设备
- 电子设备的显示控制方法、装置、电子设备和存储介质
- 电子设备控制方法及装置、电子设备及存储介质
- 一种文档条目入库方法及装置、存储介质及电子设备
- 一种条目选择方法、选择装置、电子设备及存储介质