一种新的基于多尺度排列熵诊断齿轮箱故障的机器学习方法
文献发布时间:2023-06-19 11:02:01
技术领域
本发明涉及齿轮箱预测性维护技术领域,更具体地说是用于精确诊断齿轮箱故障的一种分类方法,尤其涉及一种新的基于多尺度排列熵诊断齿轮箱故障的机器学习方法。
背景技术
大型机组齿轮箱,比如风电齿轮箱是旋转机械系统,长时间运行容易发生齿轮断齿、点蚀、磨损等故障,其故障诊断主要包括经典谱分析方法,故障模式识别等。风电齿轮箱输入是时变的,导致他们的振动信号不平稳,并且伴有强大的背景噪音导致这些振动信号容易被噪音淹没。多数齿轮箱结构较为复杂,容易同时发生多处故障,这些故障信号可能互相耦合,导致故障诊断变得进一步困难。
经典谱分析方法,不管是时域分析法还是频域分析法,都难有较强的实用性,并且这类方法需要有驱动轴齿轮,和被驱动轴齿轮齿数以及转速,所以也较难普及;基于深度学习方法因受限于故障数据量也很难训练出精准模型;目前业界更倾向于使用机器学习方法,比如基于支持向量机SVM和特征提取的方法有较好的效果及适用性;为此,我们提出一种新的基于多尺度排列熵诊断齿轮箱故障的机器学习方法。
发明内容
为了克服现有技术不足,本发明目的在于提供一种新的基于多尺度排列熵诊断齿轮箱故障的机器学习方法,它的优势是基于Adaboost分类模型提高了诊断精度,无需大量标定故障数据,并且解决了排列熵多尺度参数难选的问题,最后通过多数投票法融合多个数据可以进一步提升准确率。
为实现上述目的,本发明提供如下技术方案:一种新的基于多尺度排列熵诊断齿轮箱故障的机器学习方法,包括如下步骤:
S1、准备齿轮箱训练数据,标定0位正常齿轮,1为磨损故障齿轮;
S2、选择多尺度排列熵的参数,对数据训练数据进行特征提取,用PCA进行特征维度压缩;
S3、用Adaboost进行分类模型训练,确定下分类模型参数;
S4、用测试集进行Adaboost模型验证;
S5、实际使用中采集多段数据,单个数据进行Adaboost模型预测,用多数投票法进行模型结果融合;
S6、输出最终诊断结果并记录。
优选的,使用的振动传感器的采样率一般高于12000赫兹,齿轮的早期故障频率一般在30K到40K赫兹之间,如果用于齿轮箱早期故障诊断,需要准备振动数据的采样率一般要高于100K赫兹。
优选的,多尺度排列熵的参数选择具体包含了数据点N、嵌入维度m、时间延迟t和多尺度s等参数。
优选的,模型验证使用OPENEI的齿轮箱数据进行训练和验证。
优选的,齿轮箱的振动数据采集可以是分成n段1秒的数据,然后对单个1秒数据做以上的故障分类判断,并且用多数投票法进行融合。
本发明的技术效果和优点:
本发明简化了多尺度排列熵的关键尺度参数的选择,通过PCA对特征维度进行了压缩,不仅精简了维度而且让分类器更易于学习,接着结合Adaboost多分类器和多数投票法融合让齿轮箱故障分类变得更加精准,实用性更强,鉴于Adaboost模型的大小,有效的实现了非常适用于边缘端的嵌入式运用,能让硬件赋能齿轮箱边缘异常检测,免除大量数据传回服务器。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
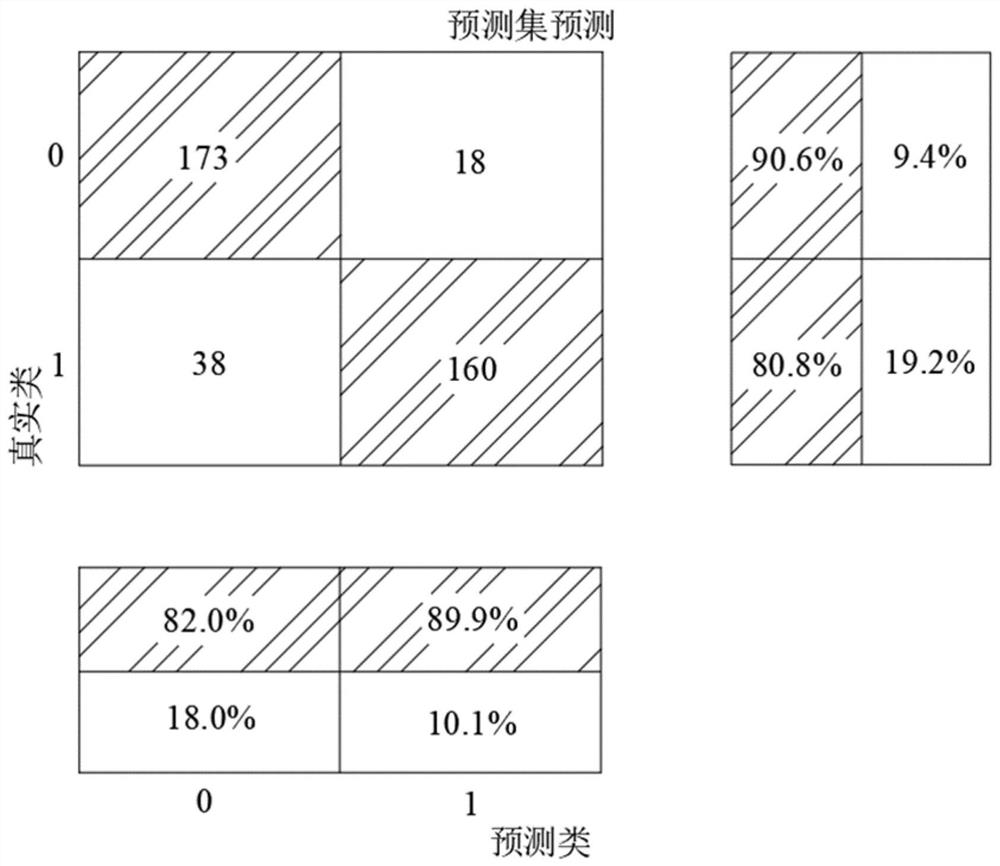
图1为本发明的模型验证结果示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合具体实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
一种新的基于多尺度排列熵诊断齿轮箱故障的机器学习方法,包括下列数量的数据:正常齿轮箱振动数据30-50份,齿轮箱齿轮磨损的振动数据100-200份。
进一步的,包括如下步骤:
S1、准备齿轮箱训练数据,标定0位正常齿轮,1为磨损故障齿轮;训练至Adaboost收敛后输出一个二分类模型,权重系数通过训练确定后之后,输入一个长度为N振动数据,输出为它的分类结果和置信度。
S2、选择多尺度排列熵的参数,对数据训练数据进行特征提取,用PCA进行特征维度压缩;
S3、用Adaboost进行分类模型训练,确定下分类模型参数;
S4、用测试集进行Adaboost模型验证;
S5、实际使用中采集多段数据,单个数据进行Adaboost模型预测,用多少投票法进行模型结果融合;
S6、输出最终诊断结果并记录。
进一步的,使用的振动传感器的采样率一般高于12000赫兹,齿轮的早期故障频率一般在30K到40K赫兹之间,如果用于齿轮箱早期故障诊断,需要准备振动数据的采样率一般要高于100K赫兹。
进一步的,多尺度排列熵的参数选择具体包含了数据点N、嵌入维度m、时间延迟t和多尺度s等参数;
(1)数据点N,这个是每次计算一个特征向量使用的数据点个数,这个参数选择可以是根据振动数据的采样率,如果采样率是12000赫兹,那可以使用比如1秒时间窗口,那N就等于12000;
(2)嵌入维度m,也就是计算某个时间点排列熵的维度,由于要计算出m所有的排列组合,所以计算量和维度之间的关系是指数级的,一般选择范围是4到8,维度高于8对于准确率没有太多的提升;
(3)时间延迟t,就是使用数据点之间的间隔,这个变量对于齿轮箱诊断结果不敏感,可以选择为1,就是使用的是连续数据,中间没有间隔;
(4)多尺度s,这个变量是对原始数据做了s次降采样,然后每次降采样后计算一个排列熵的特征,这个变量在表现多尺度排列熵的特征中起到了关键作用,目前也没有很好的选择规则,本发明中使用了PCA对s维的特征向量进行主成分提取,这样的好处是可以剔除多余维度,对特征进行压缩并且主成分特征向量是相互正交的,这样的特征让机器学习分类器更加容易训练,本发明中使用了s=32,然后主成分分析之后使用了前面8个主成分变量。
进一步的,模型验证使用OPENEI的齿轮箱数据进行训练和验证,它包含了风机齿轮箱30赫兹转速情况下负载从0到90%的故障数据和正常数据,本发明使用了一半数据进行训练和一半数据进行模型验证,验证结果参见图1。
进一步的,齿轮箱的振动数据采集可以是分成n段1秒的数据,然后对单个1秒数据做以上的故障分类判断;假设单次故障分类的成功率是p,然后n段中至少一半预测正确的准确率是1-binocdf(n/2,n,p),binocdf是二项式累积分布函数,在OPENEI的试验数据中齿轮箱诊断为正常的准确率为p=0.82,当n=10,至少一半预测正确的准确率是97.87%,所以通过采集多段数据进行预测结果融合到达一个很高的准确率,概况的讲基于一个比较高的p和一个比较大的n,通过多数投票法准确率会明显提升。
综上所述:本发明提供的一种新的基于多尺度排列熵诊断齿轮箱故障的机器学习方法,首先准备齿轮箱振动数据,再准备齿轮箱训练数据,标定0位正常齿轮,1为磨损故障齿轮,接着选择多尺度排列熵的参数,对数据训练数据进行特征提取,用PCA进行特征维度压缩,再用Adaboost进行分类模型训练,确定下分类模型参数,随后用测试集进行Adaboost模型验证,再在实际使用中采集多段数据,单个数据进行Adaboost模型预测,用多少投票法进行模型结果融合,随后输出最终诊断结果并记录,综上简化了多尺度排列熵的关键尺度参数的选择,通过PCA对特征维度进行了压缩,不仅精简了维度而且让分类器更易于学习,接着结合Adaboost多分类器和多数投票法融合让齿轮箱故障分类变得更加精准,实用性更强,鉴于Adaboost模型的大小,有效的实现了非常适用于边缘端的嵌入式运用,能让硬件赋能齿轮箱边缘异常检测,免除大量数据传回服务器。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种新的基于多尺度排列熵诊断齿轮箱故障的机器学习方法
- 一种新的基于多尺度排列熵的诊断电机轴承故障机器学习方法