顺序编码方法和相关试剂盒
文献发布时间:2024-01-17 01:28:27
本申请要求于2020年8月19日提交的美国临时专利申请第63/067,744号的优先权,所述美国临时专利申请的公开内容出于所有目的通过引用整体并入本文。
本专利或申请文件包含一个以计算机可读ASCII文本格式提交的序列表(文件名:4614-2002540_SeqList_ST25.txt,记录日期:2021年7月27日,大小:2,469字节)。序列表文件的内容通过引用整体并入本文。
技术领域
本公开涉及用于分析大分子的方法和试剂盒。在一些实施方式中,本公开涉及采用对分子识别事件的条形编码和核酸编码的大分子分析方法。本文中还提供了用于使用多种酶传递信息,包含用于对与供分析的大分子缔合的核酸分子进行连接、延伸和切割反应的方法和相关试剂盒。在一些实施方式中,所述供分析的大分子包括肽、多肽或蛋白质。
背景技术
如蛋白质等大分子的高度平行表征和识别仍然是一个挑战。在蛋白质组学中,一个目标是标识和定量样品中的多种蛋白质,这是以高通量方式完成的艰巨任务。已经使用了如免疫测定和基于质谱的方法等测定,但在样品和分析物水平上都受到限制,具有有限的灵敏度和动态范围,具有交叉反应性和背景信号的潜在问题。例如使用具有可检测标记的亲和剂,将亲和剂的集合的读出多路复用到同源大分子的集合仍然是具有挑战性的。仍然需要与应用于蛋白质测序和/或分析的大分子分析,以及用于实现所述大分子分析的产品、方法和试剂盒相关的改进技术。需要用于进行大分子分析的有效、高度并行化、准确、灵敏和高通量的蛋白质组学技术。本公开满足了这些和其它相关需求。
参考以下详细描述,本发明的这些和其它方面将显而易见。为此,本文列出了各种参考文献,其更详细地描述了某些背景信息、程序、化合物和/或组成,并且各自通过引用整体并入本文。
发明内容
本概述不旨在用于限制要求保护的主题的范围。从详细描述、包括在附图和所附权利要求中公开的那些方面中,要求保护的主题的其它特征、细节、效用和优点将是显而易见的。
本文提供了用于分析大分子的方法,所述方法包含以下步骤:提供大分子和与载体接合的所缔合记录标签;使所述大分子与能够与所述大分子结合的结合剂接触,其中所述结合剂包括具有关于所述结合剂的标识信息的编码标签,以允许所述大分子与所述结合剂之间的结合;使用核酸接合试剂将所述记录标签的5'端与所述编码标签的3'端接合;使用所述编码标签作为模板通过聚合酶延伸所述记录标签,从而产生双链经延伸记录标签;以及用双链核酸切割试剂切割所述双链经延伸记录标签,以产生经延伸记录标签中的3'突出端;由此信息从所述编码标签传递到所述记录标签,从而产生所述经延伸记录标签。
本文提供了试剂盒,所述试剂盒包含结合剂,所述结合剂包括编码标签,所述编码标签包括关于所述结合剂的标识信息;核酸接合试剂;聚合酶;以及双链核酸切割试剂;其中所述结合剂被配置成与和记录标签缔合的大分子结合,并且来自所述编码标签的所述标识信息被配置成从所述编码标签传递到与所述大分子缔合的所述记录标签。在一些实施方式中,所述试剂盒包括多种结合剂。在一些实施方式中,将所述核酸接合试剂、聚合酶和双链核酸切割试剂以混合物的形式提供。
附图说明
本发明的非限制性实施方式将参考附图为例进行描述,附图是示意性的并且不打算按比例绘制。为了说明的目的,并非在每幅图中都标明了每种组分,在对于本领域普通技术人员理解本发明来说不必要说明的情况下,也没有显示本发明的每个实施方式的每种组分。
图1A-图1B描绘了涉及使用本文所提供的方法的信息传递的示例性大分子分析测定。
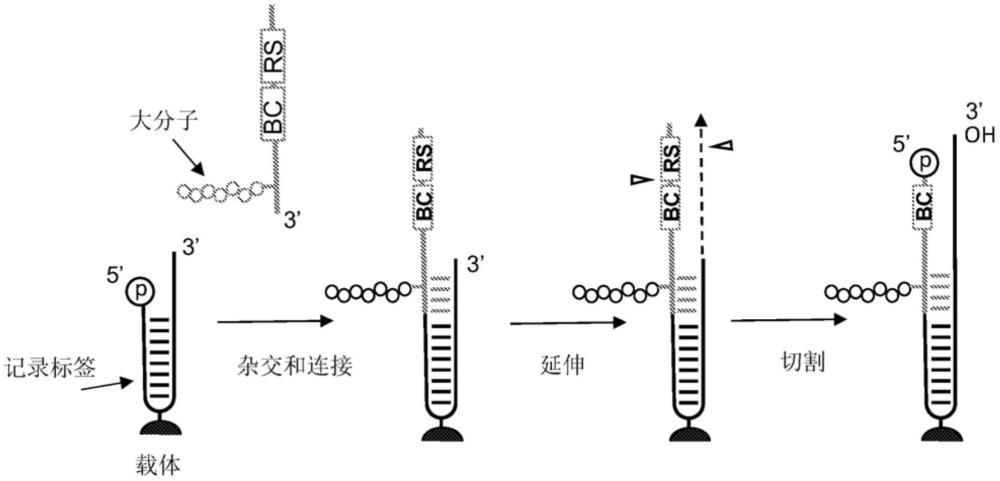
在图1A中,使用连接反应将待分析的大分子(例如,肽)与固定在载体上的记录标签发夹接合,并且切割结构用于后续步骤。图1A的第一幅(最左侧)图示出了具有凹陷的5'磷酸化末端的捕获核酸发夹。图1A的第二幅图示出了待分析的肽附着于诱饵核酸上,所述诱饵核酸(通过反应性偶联部分)与固定在载体上的捕获核酸发夹杂交。将诱饵核酸与捕获核酸连接。将记录标签与发夹连接。封闭物标记的条形码(BC)指示可以附着于大分子上并且掺入记录标签上的任何任选的条形码,例如,样品特异性条形码和/或UMI。封闭物标记的限制酶识别位点(RS)位点表示供IIS型限制酶识别和切割的掺入序列。图1A的第三幅图示出了聚合酶延伸,以产生附有肽的双链DNA(dsDNA)构建体。图1A的第四幅图示出了用IISRE型消化产生3'突出端(2-碱基对序列)后得到的具有凹陷的5'磷酸化末端的dsDNA构建体。以这种方式,含有一个或多个条形码的记录标签被准备并且可用于从编码标签进行的信息传递。
图1B示出了用图1A中产生的结构进行编码的循环。图1B的左图示出了与肽结合的结合剂,使附着于结合剂的编码标签与记录标签接近。在一些实施方式中,结合剂可以在除了所描绘位置之外的位置(例如,在编码标签的环区域或其它位置处)附着于编码标签或与编码标签接合。所示出的结合剂通过接头附着于编码标签上。编码标签含有结合剂特异性条形码(BBC)、2bp间隔区和IIS型限制酶位点(RS)。图1B的中间图示出了前两个酶促反应的产物。在将记录标签的5'端与编码标签的3'端连接时,聚合酶延伸记录标签的3'(未连接)端以产生含有邻近其相应的IIS RE型位点的2-碱基对间隔区的dsDNA分子。在形成双链之后,IIS RE型邻近其识别位点结合并切割。图1B的右图展示了所有3个酶促步骤之后的最终产物,其中dsDNA现在含有结合剂特异性条形码和用作间隔区序列的2nt 3'突出端(OH)。在一些实施方式中,在信息传递的循环之后,可以从多肽去除用于分析的多肽的一部分。图1B中示出的步骤的循环可以用另外的结合剂和编码标签重复一次或多次,以进一步延伸记录标签。
图2.通过图1A-图1B中示出的编码方法产生的示例性编码结果。将两种测试多肽(F肽:SEQ ID NO:6和L肽:SEQ ID NO:7)与固定的珠粒附着的核酸记录标签接合。使用附着于对应编码标签上的两种结合剂(F-结合剂和L-结合剂)来接触测试多肽。对于连接步骤,对3种不同浓度的T4 DNA连接酶进行测试。连接后,添加Klenow片段用于延伸步骤,并且添加BtsI-V2酶用于切割步骤。通过NGS测序评估经编码的记录标签的级分,并且示出了两种结合剂的特异性编码结果。使用相对于平均值的1个标准误差来构建每个误差条。
具体实施方式
本文提供了用于分析大分子的方法和试剂盒。在一些实施方式中,所述分析采用对分子识别事件条形编码和核酸编码。所提供的方法包括:(a)提供大分子和与载体接合的所缔合记录标签;(b)使所述大分子与能够与所述大分子结合的结合剂接触,其中所述结合剂包括具有关于所述结合剂的标识信息的编码标签,以允许所述大分子与所述结合剂之间的结合;(c)使用核酸接合试剂将所述记录标签的5'端与所述编码标签的3'端接合;(d)使用所述编码标签作为模板通过聚合酶延伸所述记录标签,从而产生双链经延伸记录标签;以及(e)用双链核酸切割试剂切割所述双链经延伸记录标签,以产生经延伸记录标签中的3'突出端。执行这些步骤,将信息从编码标签传递到记录标签,以产生经延伸记录标签。还提供了含有组分和/或试剂的试剂盒,其用于执行所提供的用于大分子测序和/或分析的方法。在一些实施方式中,所述试剂盒还包含用于使用试剂盒执行本文所提供的方法中的任何方法的说明书。
如蛋白质等大分子的高度平行表征和识别仍然是一个挑战。在蛋白质组学中,一个目标是标识和定量样品中的多种蛋白质,这是以高通量方式完成的艰巨任务。已经使用了如免疫测定和基于质谱的方法等测定,但是在样品和分析物水平、有限的灵敏度和动态范围以及交叉反应性和背景信号上都受到限制。例如使用具有可检测标记的亲和剂,将亲和剂的集合的读出多路复用到同源大分子的集合仍然是具有挑战性的。仍然需要与应用于蛋白质测序和/或分析的大分子分析,以及用于实现所述大分子分析的产品、方法和试剂盒相关的改进技术。需要用于进行大分子分析的有效、高度并行化、准确、灵敏和高通量的蛋白质组学技术。本公开满足了这些和其它相关需求。
在一些实施方式中,本公开部分地提供了用于分析大分子的方法,所述方法包含信息传递,其中直接应用于蛋白质和肽表征、定量和/或测序。在一些示例中,所传递的信息包括关于被配置成与大分子结合的结合剂的标识信息。在一些实施方式中,分析从样品获得的多个大分子。在一些实施方式中,样品从受试者获得。在一些实施方式中,大分子测序或分析方法包含使用与编码标签缔合的多种结合剂来检测待分析的多个大分子。
本文所提供的信息传递方法利用多种酶与核酸分子进行连接、延伸和切割反应。在一些实施方式中,所提供的方法包含寡核苷酸,所述寡核苷酸包括发夹结构和限制酶位点(或其部分)。在一些实施方式中,所述方法包含使用反应系统,其中向反应提供混合酶。例如,为聚合酶、核酸接合试剂和双链核酸切割试剂的活性提供合适的条件,从而将信息从编码标签传递到记录标签,以产生经延伸记录标签。在所提供的方法中,所使用的记录标签包括至少部分双链DNA结构。使用所描述的方法的一些优点包含高信息传递(编码)成功率、逐步反应的简单设计、在单个步骤中/作为单锅反应进行的选择、减少对间隔区的需要或减少小间隔区长度和/或使系统中的DNA-DNA相互作用最小化。
为了提供对本公开的透彻理解,在以下描述中阐述了许多具体细节。这些细节是出于示例的目的而提供的,而所要求保护的主题可以根据权利要求来进行实践,而无需一些或全部的这些具体细节。要理解,在不背离所要求保护的主题的范围的情况下,可以使用其它实施方式并且可以进行结构改变。应该理解,在一个或多个单独的实施方式中描述的各种特征和功能不限于其对描述了它们的特定实施方式的适用性。相反,它们可以单独或以某种组合应用于本公开的一个或多个其它实施方式,无论这样的实施方式是否被描述,以及无论这样的特征是否被呈现为所描述的实施方式的一部分。为了清楚起见,未详细描述与要求保护的主题相关的技术领域中已知的技术材料,以便不会不必要地混淆要求保护的主题。.
本申请中提及的所有出版物,包括专利文件、科学论文和数据库,均出于所有目的通过引用整体并入,其程度与每个单独的出版物个别通过引用并入相同。引用这些出版物或文件并不意欲承认它们中的任何是相关的现有技术,也不构成对这些出版物或文件的内容或日期的任何承认。
所有标题都是为了方便读者阅读,不应用来限制标题后面的文本的含义,除非被如此规定。
定义
除非另有定义,否则本文中使用的所有技术和科学术语具有与本公开所属领域的普通技术人员通常所理解的相同的含义。如果本节阐述的定义与通过引用并入本文的专利、申请、已公布的申请和其它出版物中阐述的定义相反或不一致,则本节阐述的定义优先于通过引用并入本文的定义。
如本文所用的不带数量指示的指称物包括复数指称物,除非上下文另有明确规定。因此,例如,提及“肽”包括一种或多种肽,或肽的混合物。此外,除非特别说明或从上下文中显而易见,如本文所用的术语“或”被理解为是包含性并且涵盖“或”与“和”两者。
如本文所用的术语“约”是指本技术领域的技术人员容易知道的各个值的通常误差范围。本文中提到“约”某个值或参数包括(并描述了)针对该值或参数本身的实施方式。例如,关于“约X”的描述包括对“X”的描述。
本文中的术语“抗体”以最广义使用,包括多克隆和单克隆抗体,其包括完整抗体和功能性(抗原结合性)抗体片段,所述抗体片段包括片段抗原结合性(Fab)片段、F(ab')2片段、Fab'片段、Fv片段、重组IgG(rIgG)片段、单链抗体片段,单链抗体片段包括单链可变片段(scFv)和单域抗体(例如sdAb、sdFv、纳米抗体(nanobody))片段。该术语涵盖免疫球蛋白的基因工程和/或以其它方式修饰的形式,例如胞内抗体、肽体、嵌合抗体、完全人抗体、人源化抗体和异种偶联抗体(heteroconjugate antibodies),多特异性例如双特异性的抗体、双体、三体和四体、串联二聚scFv、串联三聚scFv。除非另有说明,否则术语“抗体”应理解为涵盖其功能性抗体片段。该术语也涵盖完整或全长抗体,包括任何类别或亚类的抗体,包括IgG及其亚类、IgM、IgE、IgA和IgD。
“个体”或“对象”包括哺乳动物。哺乳动物包括但不限于驯养动物(例如牛、羊、猫、狗和马)、灵长类动物(例如,人类和非人灵长类动物例如猴子)、兔子、和啮齿动物(例如小鼠和大鼠)。“个体”或“对象”可包括禽类例如鸡、脊椎动物例如鱼和哺乳动物例如小鼠、大鼠、兔子、猫、狗、猪、奶牛、牛、绵羊、山羊、马、猴子和其它非人灵长类动物。在某些实施方式中,个体或对象是人类。
如本文所用的术语“样品”是指可能含有希望进行分析物测定的分析物的任何东西。如本文所用的“样品”可以是溶液、悬浮液、液体、粉末、糊剂、水性的、非水性的或其任何组合。所述样品可以是生物样品,例如生物体液或生物组织。生物流体的例子包括尿液、血液、血浆、血清、唾液、精液、粪便、痰液、脑脊液、泪液、粘液、羊水等。生物组织是细胞、通常是特定种类的细胞与其胞间物质一起形成人类、动物、植物、细菌、真菌或病毒结构的结构材料之一的集合体,包括结缔组织、上皮组织、肌肉组织和神经组织。生物组织的例子也包括器官、肿瘤、淋巴结、动脉和单个细胞。
在一些实施方式中,样品是生物样品。本公开的生物样品包括溶液、悬浮液、液体、粉末、糊剂、水性样品或非水性样品形式的样品。如本文所用的“生物样品”包括从活体或病毒性(或朊病毒)来源或其它来源获得的大分子和生物分子的任何样品,并且包括对象中可以获得核酸、蛋白质和/或其它大分子的任何细胞类型或组织。生物样品可以是直接从生物来源获得的样品或经过处理的样品。例如,经扩增的分离核酸构成生物样品。生物样品包括但不限于来自动物和植物的体液例如血液、血浆、血清、脑脊液、滑液、尿液和汗液、组织和器官样品,以及由此衍生的加工样品。在一些实施方式中,样品可以来源于组织或体液,例如结缔组织、上皮组织、肌肉组织或神经组织;选自由以下组成的组的组织:脑、肺、肝、脾、骨髓、胸腺、心脏、淋巴、血液、骨、软骨、胰腺、肾、胆囊、胃、肠、睾丸、卵巢、子宫、直肠、神经系统、腺体和内部血管;或选自由以下组成的组的体液:血液、尿液、唾液、骨髓、精液、腹水及其亚级分例如血清或血浆。
术语“水平”用于指靶标、例如作为疾病或病症病因学的一部分并且可以定性或定量确定的物质或生物体的存在和/或量。靶标水平的“定性”变化是指在从正常对照获得的样品中检测不到或存在于其中的靶标的出现或消失。一个或多个靶标水平的“定量”变化是指当与健康对照相比时,靶标水平的可测量的增加或减少。
如本文所用的术语“大分子”包括由较小的亚基构成的大分子。大分子的例子包含但不限于肽、多肽、蛋白质、核酸、碳水化合物、脂质、大环或其组合或复合体。大分子还包括由两种或多种类型的大分子的组合以共价键连接在一起构成的嵌合大分子(例如,与核酸连接的肽)。大分子还可包括“大分子组装体”,它由两个或多个大分子的非共价复合体构成。大分子组装体可以由相同类型的大分子(例如,蛋白质-蛋白质)或由两种或更多种不同类型的大分子(例如,蛋白质-DNA)构成。
如本文所用的术语“多肽”包括肽和蛋白质,并且是指包含两个或更多个通过肽键接合的氨基酸的链的分子。在一些实施方式中,多肽包含2至50个氨基酸,例如具有多于20-30个氨基酸。在一些实施方式中,肽不包含二级、三级或更高级结构。在一些实施方式中,多肽是蛋白质。在一些实施方式中,蛋白质包含30或更多个氨基酸,例如具有多于50个氨基酸。在一些实施方式中,除了一级结构外,蛋白质还包含二级、三级或更高级结构。多肽的氨基酸最典型的是L-氨基酸,但也可以是D-氨基酸、修饰的氨基酸、氨基酸类似物、氨基酸模拟物或其任何组合。多肽可以是天然存在的、合成产生的或重组表达的。多肽可以合成产生的、分离的、重组表达的、或通过上述方法的组合产生的。多肽还可以包含修饰氨基酸链的其它基团,例如通过翻译后修饰添加的官能团。所述聚合物可以是直链或支链的,它可包含修饰的氨基酸,并且它可被非氨基酸打断。所述术语还涵盖已天然或通过干预修饰的氨基酸聚合物;例如,二硫键形成、糖基化、脂化、乙酰化、磷酸化或任何其它操作或修饰,如与标记组分缀合。
如本文所用的术语“氨基酸”是指包含胺基、羧酸基和各氨基酸特定侧链的有机化合物,其作为肽的单体亚基。氨基酸包括20种标准天然存在或经典氨基酸以及非标准氨基酸。标准天然存在氨基酸包括丙氨酸(A或Ala)、半胱氨酸(C或Cys)、天冬氨酸(D或Asp)、谷氨酸(E或Glu)、苯丙氨酸(F或Phe)、甘氨酸(G或Gly)、组氨酸(H或His)、异亮氨酸(I或Ile)、赖氨酸(K或Lys)、亮氨酸(L或Leu)、甲硫氨酸(M或Met)、天冬酰胺(N或Asn)、脯氨酸(P或Pro)、谷氨酰胺(Q或Gln)、精氨酸(R或Arg)、丝氨酸(S或Ser)、苏氨酸(T或Thr)、缬氨酸(V或Val)、色氨酸(W或Trp)、和酪氨酸(Y或Tyr)。氨基酸可以是L-氨基酸或D-氨基酸。非标准氨基酸可以是天然存在或化学合成的修饰氨基酸、氨基酸类似物、氨基酸模拟物、非标准蛋白质氨基酸或非蛋白质氨基酸。非标准氨基酸的例子包括但不限于硒半胱氨酸、吡咯赖氨酸和N-甲酰甲硫氨酸、β-氨基酸、高氨基酸、脯氨酸和丙酮酸衍生物、3-取代丙氨酸衍生物、甘氨酸衍生物、环-取代的苯丙氨酸和酪氨酸衍生物、线性核心氨基酸、N-甲基氨基酸。
如本文所用的术语“翻译后修饰”是指在肽翻译(例如,通过核糖体翻译)完成之后在肽上发生的修饰。翻译后修饰可以是共价化学修饰或酶促修饰。翻译后修饰的例子包括但不限于酰化、乙酰化、烷基化(包括甲基化)、生物素化、丁酰化、氨甲酰化、羰基化、脱酰胺化、脱亚胺化、白喉酰胺形成、二硫桥键形成、消去化、黄素连接、甲酰化、γ-羧基化、谷氨酰化、甘氨酰化、糖基化、糖基磷脂酰肌醇化、血红素C连接、羟基化、羟腐氨酸(hypusine)形成、碘化、异戊二烯化、脂化、脂酰化、丙二酰化、甲基化、肉豆蔻酰化、氧化、棕榈酰化、PEG化、磷酸泛酰巯基乙胺化(phosphopantetheinylation)、磷酸化、异戊二烯化、丙酰化、亚视黄亚基席夫碱形成、S-谷胱甘肽化、S-亚硝基化、S-亚磺酰化、硒化、琥珀酰化、亚磺化、泛素化和C末端酰胺化。翻译后修饰包括肽的氨基末端和/或羧基末端的修饰。末端氨基的修饰包括但不限于脱氨基、N-低级烷基、N-二低级烷基和N-酰基修饰。末端羧基的修饰包含但不限于酰胺、低级烷基酰胺、二烷基酰胺和低级烷基酯修饰(例如,其中低级烷基是C
如本文所用的术语“结合剂”是指与结合靶标(例如,多肽或多肽的组分或特征)结合、缔合、联合、识别所述结合靶标或与其组合的核酸分子、肽、多肽、蛋白质、碳水化合物或小分子。结合剂可以与多肽或多肽的组分或特征形成共价缔合或非共价缔合。结合剂也可以是由两种或更多种类型的分子构成的嵌合结合剂,例如核酸分子-肽嵌合结合剂或碳水化合物-肽嵌合结合剂。结合剂可以是天然存在的、合成产生的或重组表达的分子。结合剂可以与多肽的单个单体或亚基(例如,多肽的单个氨基酸)结合或与多肽的多个相连的亚基(例如,较长肽、多肽或蛋白质分子的二肽、三肽或更高级肽)结合。结合剂可与线性分子或具有三维结构(也称为构象)的分子结合。例如,抗体结合剂可与线性的肽、多肽或蛋白质结合,或与构象的肽、多肽或蛋白质结合。结合剂可与肽、多肽或蛋白质分子的N末端肽、C末端肽或中间肽结合。结合剂可与肽分子的N末端氨基酸、C末端氨基酸或中间氨基酸结合。结合剂可以优选地与经化学修饰或经标记的氨基酸(例如,已被化学试剂标记的氨基酸)而非未修饰或未标记的氨基酸结合。例如,结合剂可以优选地与已被标记或修饰的氨基酸而非未标记或未修饰的氨基酸结合。结合剂可与翻译后修饰的肽分子结合。结合剂可以表现出与多肽的组分或特征的选择性结合(例如,结合剂可以与20个可能的天然氨基酸残基之一选择性结合,并且以非常低的亲和力结合或根本不与其它19个天然氨基酸残基结合)。结合剂可以表现出较低的选择性结合,其中结合剂能够结合或被配置成与多肽的多个组分或特征结合(例如,结合剂可以以相似的亲和力与两个或更多个不同的氨基酸残基结合)。结合剂可包含编码标签,编码标签可通过接头与结合剂接合。
如本文所用的术语“接头”是指用于接合两个分子的核苷酸、核苷酸类似物、氨基酸、肽、多肽、聚合物或非核苷酸化学部分中的一种或多种。接头可以用于将结合剂与编码标签、记录标签与多肽、多肽与载体、记录标签与固体载体等接合。在某些实施方式中,接头通过酶促反应或化学反应(例如,点击化学)接合两个分子。
如本文所用的术语“配体”是指与本文所描述的化合物连接的任何分子或部分。“配体”可以指附着于化合物的一种或多种配体。在一些实施方式中,配体是侧基或结合位点(例如,结合剂所结合的位点)。
如本文所用的术语“蛋白质组”可以包括由任何生物体的基因组、细胞、组织或生物体在特定时间表达的整组蛋白质、多肽或肽(包括其缀合物或复合体)。在一个方面,它是给定类型的细胞或生物体、在给定的时间、在给定的条件下表达的该组蛋白质。蛋白质组学是对蛋白质组的研究。例如,“细胞蛋白质组”可包括在特定环境条件设置下,例如暴露于激素刺激下,在特定细胞类型中发现的蛋白质的集合。生物体的完整蛋白质组可包括来自所有的各种细胞蛋白质组的整套蛋白质。蛋白质组也可包括某些亚细胞生物系统中的蛋白质的集合。例如,病毒中的所有蛋白质可以称为病毒蛋白质组。如本文所用的术语“蛋白质组”包括蛋白质组的子集,包括但不限于激酶组;分泌组;受体组(例如,GPCRome);免疫蛋白质组;营养蛋白质组;由翻译后修饰(例如,磷酸化、泛素化、甲基化、乙酰化、糖基化、氧化、脂化和/或亚硝基化)定义的蛋白质组子集,例如磷酸化蛋白质组(例如,磷酸酪氨酸-蛋白质组、酪氨酸-激酶组和酪氨酸-磷酸酶组)、糖蛋白组等;与组织或器官、发育阶段、或生理或病理状况相关的蛋白质组子集;与细胞过程例如细胞周期、分化(或去分化)、细胞死亡、衰老、细胞迁移、转化或转移相关的蛋白质组子集;或其任何组合。如本文所用的术语“蛋白质组学”是指定量分析细胞、组织和体液内的蛋白质组,以及蛋白质组在细胞内和组织内的相应空间分布。此外,蛋白质组学研究包括蛋白质组随着生物学和限定的生物或化学刺激而随时间连续变化的动态状态。
在具有游离氨基的肽链或多肽链一端的末端氨基酸在本文中称为“N末端氨基酸”(NTAA)。在具有游离羧基的肽链一端的末端氨基酸在本文中称为“C末端氨基酸”(CTAA)。构成肽的氨基酸可以按顺序编号,肽的长度为“n”个氨基酸。如本文所用的NTAA被认为是第n个氨基酸(在本文中也称为“n NTAA”)。使用该命名法,沿着从N末端到C末端的肽长度,下一个氨基酸是n-1氨基酸,然后是n-2氨基酸,依此类推。在某些实施方式中,NTAA、CTAA或两者都可以用部分或化学部分修饰或标记。
如本文所用的术语“条形码”是指约2至约30个碱基(例如,2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个碱基)的核酸分子,其为多肽、结合剂、来自结合循环的一组结合剂、样品多肽、一组样品、区室(例如液滴、珠粒或单独的位置)内的多肽、一组区室内的多肽、多肽级分、一组多肽级分、空间区域或一组空间区域、多肽文库、或结合剂文库提供唯一标识符标签或来源信息。条形码可以是人工序列或天然存在的序列。在某些实施方式中,条形码群内的每个条形码都是不同的。在其它实施方式中,条形码群中的一部分条形码是不同的,例如,条形码群中的至少约10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、97%或99%的条形码是不同的。条形码群可随机生成或非随机生成。在某些实施方式中,条形码群是纠错或容错条形码。条形码可以用于对多重测序数据进行计算去卷积,并且标识源自于单个多肽、样品、文库等的序列读段。条形码还可以用于对已分布到小区室中的多肽集合进行去卷积以增强映射。例如,不是将肽映射回蛋白质组,而是将肽映射回其原始蛋白质分子或蛋白质复合体。
如本文所用的术语“编码标签”是指具有任何合适长度的多核苷酸,例如约2个碱基至约100个碱基的核酸分子,包括含2和100以及之间的任何整数,其包含其相关结合剂的标识信息。“编码标签”也可以由“可测序的聚合物”构成(例如,参见Niu等人,2013,Nat.Chem.5:282-292;Roy等人,2015,Nat.Commun.6:7237;Lutz,2015,Macromolecules48:4759-4767;它们各自通过引用整体并入)。编码标签可包含编码区序列(encodersequence),其任选在一侧侧接一个间隔区或任选在每侧侧接间隔区。编码标签还可包含任选的UMI和/或任选的结合循环特异性条形码。编码标签可以是单链的或双链的。双链编码标签可包含平端、突出端或二者。编码标签可以指直接附着于结合剂的编码标签、与直接附着于结合剂的编码标签杂交的互补序列(例如,对于双链编码标签)、或经延伸记录标签中存在的编码标签信息。在某些实施方式中,编码标签还可包含结合循环特异性的间隔区或条形码、唯一分子标识符、通用引发位点或其任何组合。
如本文所用的术语“间隔区”(Sp)是指存在于记录标签或编码标签的末端、长度为约1个碱基至约20个碱基(例如,1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个碱基)的核酸分子。在某些实施方式中,间隔区序列在一端或两端侧接编码标签的编码区序列。在结合剂与多肽结合后,分别在其缔合的编码标签和记录标签上的互补间隔区序列之间进行退火允许通过引物延伸反应或与记录标签、编码标签或双标签构建体的连接来传递结合信息。Sp'是指与Sp互补的间隔区序列。优选地,结合剂文库内的间隔区序列具有相同数量的碱基。在结合剂文库中可使用共同的(共享或相同的)间隔区。间隔区序列可具有“循环特异性”序列,以便追踪在特定结合循环中所使用的结合剂。间隔区序列(Sp)可以在所有结合循环中不变、对特定的多肽类别具有特异性、或是结合循环数特异性的。多肽类别特异性间隔区允许将来自已完成的结合/延伸循环的经延伸记录标签中存在的同源结合剂的编码标签信息退火到在后续结合循环中通过所述类别特异性间隔区标识相同多肽类别的另一个结合剂的编码标签上。只有顺序结合正确的同源对才能导致相互作用的间隔区元件和有效的引物延伸。间隔区序列可包含足够的碱基数量以退火到记录标签中的互补间隔区序列上,从而启动引物延伸(也称为聚合酶延伸)反应、或为连接反应提供“夹板(splint)”、或介导“粘性末端”连接反应。间隔区序列可包含比编码标签内的编码区序列更少数量的碱基。.
如本文所用的术语“记录标签”是指部分,例如化学偶联部分、核酸分子或可测序的聚合物分子(例如,参见Niu等人,2013,Nat.Chem.5:282-292;Roy等人,2015,Nat.Commun.6:7237;Lutz,2015,Macromolecules 48:4759-4767;它们各自通过引用整体并入),可以向其传递编码标签的标识信息、或关于与所述记录标签缔合的大分子的标识信息(例如,UMI信息)可以从其传递到编码标签上。标识信息可以包括表征分子的任何信息,例如与样品、级分、分区、空间位置、相互作用的相邻分子、循环数等有关的信息。此外,存在的UMI信息也可以被归类为标识信息。在某些实施方式中,在结合剂与多肽结合后,来自与结合剂连接的编码标签的信息可以在结合剂与多肽结合的同时传递到与该多肽缔合的记录标签。在其它实施方式中,在结合剂与多肽结合后,来自与多肽缔合的记录标签的信息可以在结合剂与多肽结合的同时传递到与该结合剂连接的编码标签。记录标签可以直接与多肽连接,可以通过多功能接头与多肽连接,或者凭借其在载体上的邻近性(proximity)(或共定位)而与多肽缔合。记录标签可通过其5'端或3'端或内部位点连接,只要该连接与用于将编码标签信息传递到记录标签或反之的方法相容即可。记录标签还可包含其它功能组分,例如,通用引发位点、唯一分子标识符、条形码(例如,样品条形码、级分条形码、空间条形码、区室标签等)、与编码标签的间隔区序列互补的间隔区序列、或其任何组合。在使用聚合酶延伸将编码标签信息传递到记录标签的实施方式中,记录标签的间隔区序列优选位于记录标签的3'末端。
如本文所用的术语“引物延伸”,也称为“聚合酶延伸”,是指由核酸聚合酶(例如,DNA聚合酶)催化的反应,由此退火到互补链上的核酸分子(例如,寡核苷酸引物、间隔区序列)被聚合酶使用该互补链作为模板进行延伸。
如本文所用的术语“唯一分子标识符”或“UMI”是指长度为约3至约40个碱基(3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39或40个碱基)的核酸分子,为UMI所连接的每个大分子、多肽或结合剂提供唯一标识符标签。多肽UMI可以用于对来自多个经延伸记录标签的测序数据进行计算去卷积,以标识源自单个多肽的经延伸记录标签。多肽UMI可以通过将NGS读段折叠为唯一的UMI而用于精确计数起源多肽分子。结合剂UMI可以用于标识与特定多肽结合的每个单独分子结合剂。例如,UMI可以用于标识针对特定肽分子出现的单个氨基酸有特异性的结合剂的单独结合事件的数量。应当理解,当UMI和条形码两者都在结合剂或多肽的上下文中被提及时,条形码指的是除了单个结合剂或多肽的UMI之外的标识信息(例如,样品条形码、隔室条形码、结合循环条形码)。
如本文所用的术语“通用引发位点”或“通用引物”或“通用引发序列”是指可用于文库扩增和/或测序反应的核酸分子。通用引发位点可包括但不限于,PCR扩增引发位点(引物序列)、退火到流动细胞表面上的互补寡核苷酸从而在一些下一代测序平台中实现桥式扩增的流动细胞适配序列、测序引发位点、或其组合。通用引发位点可以用于其它类型的扩增,包括通常与下一代数字测序结合使用的扩增。例如,可将经延伸记录标签分子进行环化,并使用通用引发位点进行滚环扩增,以形成可以用作测序模板的DNA纳米球(Drmanac等人,2009,Science 327:78-81)。可替代地,记录标签分子可通过从通用引发位点的聚合酶延伸来直接环化和测序(Korlach等人,2008,Proc.Natl.Acad.Sci.105:1176-1181)。当在关于“通用引发位点”或“通用引物”的语境中使用时,术语“正向”也可称为“5'”或“有义”。当在关于“通用引发位点”或“通用引物”的语境中使用时,术语“反向”也可称为“3'”或“反义”。
如本文所用的术语“经延伸记录标签”是指在结合剂与多肽结合后,已将至少一种结合剂编码标签(或其互补序列)的信息传递给它的记录标签。编码标签的信息可直接(例如,连接)或间接(例如,引物延伸)地传递给记录标签。编码标签的信息可通过酶法或化学方式传递给记录标签。经延伸记录标签可包含1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、45、50、55、60、65、70、75、80、85、90、95、100、125、150、175、200个或更多的编码标签的结合剂信息。经延伸记录标签的碱基序列可反映由其编码标签标识的结合剂的结合的时间次序和顺序次序、可反映由编码标签标识的结合剂的结合的部分顺序次序、或可不反映由编码标签标识的结合剂的结合的任何次序。在某些实施方式中,经延伸记录标签中存在的编码标签信息以至少25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性代表正被分析的多肽序列。在经延伸记录标签没有以100%同一性代表被分析的多肽序列的某些实施方式中,错误可能是由于结合剂的脱靶结合、或“遗漏”结合循环(例如,因为结合剂在结合循环期间未能与多肽结合、因为引物延伸反应失败)、或二者兼而有之。
如本文所用的术语“固体载体”、“固体表面”或“固体基体”或“测序基体”或“基体”是指可以通过本领域已知的任何手段、包括共价和非共价相互作用或其任何组合,直接或间接地与多肽缔合的任何固体材料,包括多孔和无孔材料。固体载体可以是二维的(例如,平面表面)或三维的(例如,凝胶基质或珠粒)。固体载体可以是任何载体表面,包含但不限于珠粒、微珠、阵列、玻璃表面、硅表面、塑料表面、过滤器、膜、PTFE膜、PTFE膜、硝化纤维素膜、基于硝化纤维素的聚合物表面、尼龙、硅晶圆芯片、流通芯片、流动池、包含信号转导电子装置的生物芯片、通道、微量滴定孔、ELISA板、干涉测量转盘、硝化纤维素膜、基于硝化纤维素的聚合物表面、聚合物基质、纳米颗粒或微球。固体载体的材料包括但不限于丙烯酰胺、琼脂糖、纤维素、葡聚糖、硝化纤维素、玻璃、金、石英、聚苯乙烯、聚乙烯乙酸乙烯酯、聚丙烯、聚酯、聚甲基丙烯酸酯、聚丙烯酸酯、聚乙烯、聚环氧乙烷、聚硅酸盐、聚碳酸酯、聚乙烯醇(PVA)、特氟隆、氟碳化合物、尼龙、硅橡胶、聚酐、聚乙醇酸、聚氯乙烯、聚乳酸、聚原酸酯、官能化硅烷、聚富马酸丙酯、胶原蛋白、糖胺聚糖、聚氨基酸、葡聚糖或其任何组合。固体载体还包括薄膜、膜、瓶子、碟、纤维、编织纤维、成型聚合物如管子、颗粒、珠粒、微球、微粒或其任何组合。例如,当固体表面是珠粒时,珠粒可以包括但不限于陶瓷珠、聚苯乙烯珠、聚合物珠、聚丙烯酸酯珠、甲基苯乙烯珠、琼脂糖珠、纤维素珠、葡聚糖珠、丙烯酰胺珠、实心珠、多孔珠、顺磁珠、玻璃珠、可控孔度珠、基于二氧化硅的珠、或其任何组合。珠粒可以是球形或不规则形状的。珠粒或载体可以是多孔的。珠粒的大小可以在纳米(例如,100nm)至毫米(例如,1mm)的范围内。在某些实施方式中,珠粒的大小在约0.2微米至约200微米或约0.5微米至约5微米的范围内。在一些实施方式中,珠粒的直径可以为约1、1.5、2、2.5、2.8、3、3.5、4、4.5、5、5.5、6、6.5、7、7.5、8、8.5、9、9.5、10、10.5、15或20μm。在某些实施方式中,“珠粒”固体载体可指单个珠粒或多个珠粒。在一些实施方式中,所述固体表面是纳米颗粒。在某些实施方式中,纳米颗粒的尺寸范围从直径约1nm至约500nm,例如,直径在约1nm和约20nm之间、约1nm和约50nm之间、约1nm和约100nm之间、约10nm和约50nm之间、约10nm和约100nm之间、约10nm和约200nm之间、约50nm和约100nm之间、约50nm和约150之间、约50nm和约200nm之间、约100nm和约200nm之间、或约200nm和约500之间。在一些实施方式中,纳米颗粒的直径可以为约10nm、约50nm、约100nm、约150nm、约200nm、约300nm或约500nm。在一些实施方式中,纳米颗粒的直径小于约200nm。
如本文所用的术语“核酸分子”或“多核苷酸”是指含有通过3'-5'磷酸二酯键连接的脱氧核糖核苷酸或核糖核苷酸的单链或双链多核苷酸、以及多核苷酸类似物。核酸分子包括但不限于DNA、RNA和cDNA。多核苷酸类似物可具有不同于天然多核苷酸中发现的标准磷酸二酯键的主链,并且任选地,具有核糖或脱氧核糖之外的修饰的糖部分。多核苷酸类似物含有能够通过Watson-Crick碱基配对与标准多核苷酸碱基进行氢键合的碱基,其中所述类似物主链以允许在寡核苷酸类似物分子和标准多核苷酸碱基之间以序列特异性方式进行这样的氢键合的方式呈递所述碱基。多核苷酸类似物的例子包括但不限于异种核酸(XNA)、桥接核酸(BNA)、乙二醇核酸(GNA)、肽核酸(PNA)、γPNA、吗啉代多核苷酸、锁核酸(LNA)、苏糖核酸(TNA)、2'-O-甲基多核苷酸、2'-O-烷基核糖基取代的多核苷酸、硫代磷酸多核苷酸和硼代磷酸多核苷酸。多核苷酸类似物可具有嘌呤或嘧啶类似物,包括例如,7-脱氮嘌呤类似物,8-卤代嘌呤类似物,5-卤代嘧啶类似物,或可以与任何碱基配对的通用碱基类似物,包括次黄嘌呤、硝基唑、异喹诺酮(isocarbostyril)类似物、唑羧酰胺和芳族三唑类似物,或具有附加官能性、例如用于亲和结合的生物素部分的碱基类似物。在一些实施方式中,所述核酸分子或寡核苷酸是修饰的寡核苷酸。在一些实施方式中,核酸分子或寡核苷酸是具有假互补碱基的DNA、具有受保护碱基的DNA、RNA分子、BNA分子、XNA分子、LNA分子、PNA分子、γPNA分子或吗啉代DNA,或其组合。在一些实施方式中,核酸分子或寡核苷酸是主链修饰、糖修饰或核碱基修饰的。在一些实施方式中,核酸分子或寡核苷酸具有核碱基保护基团如Alloc、亲电子保护基团如thiranes、乙酰基保护基团、硝基苄基保护基团、磺酸酯保护基团、或传统的碱不稳定性保护基团。
如本文所用的“核酸测序”是指确定核酸分子或核酸分子样品中的核苷酸顺序。
如本文所用的“下一代测序”是指允许岁数百万至数十亿个分子进行并行测序的高通量测序方法。下一代测序方法的例子包括合成测序、连接测序、杂交测序、聚合酶克隆测序、离子半导体测序和焦磷酸测序。通过将引物连接到固体基体上并将互补序列连接到核酸分子上,核酸分子可以通过引物与固体基体杂交,然后利用聚合酶在固体基体上的分立区域中产生多个拷贝以进行扩增(这些集群有时称为聚合酶克隆)。因此,在测序过程期间,特定位置处的核苷酸可以被多次测序(例如,数百或数千次)——这种覆盖深度被称为“深度测序”。高通量核酸测序技术的例子包括由Illumina、BGI、Qiagen、Thermo-Fisher和Roche提供的平台,包括例如平行珠阵列、合成测序、连接测序、毛细管电泳、电子微芯片、“生物芯片”、微阵列、平行微芯片和单分子阵列的格式(参见例如Service,Science(2006)311:1544-1546)。
如本文所用的“单分子测序”或“第三代测序”是指其中来自单分子测序仪器的读段是通过对单个DNA分子进行测序而产生的下一代测序方法。与依靠扩增而以分阶段的方式并行克隆许多DNA分子进行测序的下一代测序方法不同,单分子测序询问单分子的DNA,不需要扩增或同步。单分子测序包括在每个碱基并入后需要暂停测序反应的方法(“洗涤和扫描”循环)和在读取步骤之间不需要暂停的方法。单分子测序方法的例子包括单分子实时测序(Pacific Biosciences)、基于纳米孔的测序(Oxford Nanopore)、双链体中断(duplexinterrupted)的纳米孔测序、以及使用先进显微镜术的DNA直接成像。
如本文所用的“分析”多肽意指对多肽的全部或部分组分进行鉴定、检测、定量、表征、区分或其组合。例如,分析肽、多肽或蛋白质包括确定肽的全部或部分氨基酸序列(连续或非连续的氨基酸序列)。分析多肽还包括部分标识多肽的组分。例如,部分标识多肽蛋白质序列中的氨基酸可以将蛋白质中的氨基酸标识为属于可能的氨基酸的子集。分析通常从分析n NTAA开始,然后进行到肽的下一个氨基酸(即,n-1、n-2、n-3等等)。这是通过消除nNTAA,由此将肽的n-1氨基酸转化为N末端氨基酸(在本文中称为“n-1NTAA”)来实现的。肽的分析还可包括确定肽上的翻译后修饰的存在和频率,这可包括或可不包括关于肽上的翻译后修饰的依次顺序的信息。肽的分析还可包括确定肽中表位的存在和频率,这可包括或可不包括关于肽内表位的依次顺序或位置的信息。肽的分析可包括不同类型分析的组合,例如获得表位信息、氨基酸序列信息、翻译后修饰信息或其任何组合。
应理解,本文描述的本发明的方面和实施方式包括“由方面和实施方式组成”和/或“基本上由方面和实施方式组成”。
在整个本公开中,本发明的各个方面以范围的格式呈现。应当理解,以范围格式进行描述仅仅是为了方便和简洁,不应理解为对本发明范围的刻板的限制。因此,范围的描述应该被认为已经具体公开了所有可能的子范围以及该范围内的个体数值。例如,对例如从1到6的范围的描述应视为已具体公开了例如从1到3、1到4、1到5、2到4、2到6、3到6等的子范围,以及该范围内的单个数字,例如1、2、3、4、5和6。无论范围的广度如何,这都适用。
本发明的其它目的、优点和特征将从以下结合附图的说明中变得显而易见。
I.
本文提供了用于分析大分子(例如,肽、多肽和蛋白质)的方法和试剂盒,所述方法和试剂盒包含将信息传递到记录标签的步骤。分析采用分子识别事件的核酸编码。在一些方面,所传递的信息包括关于被配置成与大分子结合的结合剂的标识信息。所提供的用于信息传递的方法包含:(a)提供大分子和与载体接合的所缔合记录标签;(b)使所述大分子与能够与所述大分子结合的结合剂接触,其中所述结合剂包括具有关于所述结合剂的标识信息的编码标签,以允许所述大分子与所述结合剂之间的结合;(c)通过核酸接合试剂将所述记录标签的5'端与所述编码标签的3'端接合;(d)使用所述编码标签作为模板通过聚合酶延伸所述记录标签,从而产生双链经延伸记录标签;以及(e)用双链核酸切割试剂切割所述双链经延伸记录标签,以产生经延伸记录标签中的3'突出端。执行这些步骤,将信息从编码标签传递到记录标签,以产生经延伸记录标签。在一些实施方式中,将聚合酶、核酸接合试剂和双链核酸切割试剂以混合物的形式提供或同时提供。在一些方面,将步骤(c)、(d)和(e)作为一锅反应(one-pot reaction)进行。在一些其它方面中,步骤(c)、(d)和(e)按顺序且单独地进行。在一些情况下,可以单独提供每种试剂,或者同时提供三种酶试剂中的两种酶试剂。在一些情况下,所提供的方法的记录标签和编码标签包括核酸。
可以重复步骤(b)至(e)的一个或多个循环,以产生包含从多个编码标签传递的信息的经延伸记录标签。例如,步骤(b)、(c)、(d)和(e)可以以循环方式按顺序重复一次或多次。在一些实施方式中,所产生的经延伸记录标签包括核酸发夹。本文所提供的方法可以包含提供多种结合剂和多个大分子,并且允许结合剂和大分子相互作用。在一些实施方式中,在每个循环中以混合物的形式提供多种结合剂。在一些实施方式中,本发明的方法包括使单个大分子与一种结合剂接触,使多个大分子与一种结合剂接触,或使多个大分子与多种结合剂接触。
在一些实施方式中,本公开部分地提供了用于分析大分子的方法,所述方法包含信息传递,其中直接应用于蛋白质和肽表征、定量和/或测序。在一些特定实施方式中,供分析的大分子不是核酸。在一些特定实施方式中,结合剂不是核酸。本文提供了用于将信息从与结合剂缔合或接合的编码标签传递到与待分析的大分子(例如,多肽)缔合的记录标签的方法。使用三部分反应进行信息传递,所述三部分反应包含连接、延伸和通过双链核酸切割试剂(例如,限制酶)的切割。从编码标签传递的信息包含关于结合剂的身份的标识信息,由此提供关于被结合剂结合的大分子或其部分的信息。例如,如果蛋白质/多肽/肽大分子被结合剂结合,则标识信息可以包括关于被结合剂结合的一个或多个氨基酸的身份的信息。在一些实施方式中,关于被结合剂结合的大分子(或其部分)的身份的信息来自与所述结合剂缔合的编码标签,并且被传递到记录标签。大分子分析测定可以包含将结合剂的标识信息从编码标签传递到与待分析的大分子缔合的记录标签的一个或多个循环。与供分析的大分子缔合的最终经延伸记录标签可以包括来自一个或多个编码标签的信息。如果进行多个循环,则所生成的经延伸记录标签含有由一系列结合事件和来自编码标签的多个信息传递事件构建的信息。通常,使用涉及核酸接合试剂、聚合酶和双链核酸切割试剂的活性的所描述的方法对信息传递的改进可以为大分子分析测定提供某些益处。
在一些方面,所提供的用于分析大分子的方法中使用的顺序编码系统为测定的总体设计提供某些优点。具体地,通过由核酸接合试剂、聚合酶和双链核酸切割试剂进行的顺序步骤提供了一些优点。在一些实施方式中,所述方法包含或使用反应系统,其中向反应提供混合酶,使得其在一个步骤中进行和/或反应在一锅反应中进行。通过设计系统,步骤(c)、(d)和(e)的连接、延伸和切割分别以逐步或顺序的方式进行。在一些其它实施方式中,步骤的逐步性质可以通过使用封闭基团或通过引入另外的要求来引入,使得连接、延伸和/或切割以前一步骤的完成为条件的方式进行。为聚合酶、核酸接合试剂和双链核酸切割试剂的活性提供合适的条件,以便将信息从编码标签传递到记录标签,以产生经延伸记录标签。使用所描述的方法的一些优点包含高信息传递(编码)成功率、逐步反应的简单设计、在单个步骤中/作为单锅反应进行的选择、减少对间隔区或间隔区的长度的需要、使系统中的DNA-DNA相互作用最小化和/或使系统中的DNA-蛋白质相互作用最小化。例如,与可以是柔性的并且提供用于相互作用的暴露碱基的单链核酸分子相比,本文所提供的双链记录标签可以表现出较少的DNA与系统中的其它组分(例如,核酸、肽、结合剂等)相互作用的相互作用。
在一些实施方式中,所提供的用于使用顺序编码传递信息的方法允许与所使用的核酸组分的格式相关的某些益处。例如,在取决于形成聚合酶引发位点的间隔区元件的基于延伸的信息传递方法中,间隔区的大小可能需要为一定长度,如至少6个碱基对。较短的间隔区可以具有如在测定中避免非特异性相互作用等优点。在一些情况下,如果重复元件被最小化或消除,则序列富集将更加简单。在一些情况下,与基于延伸的方法相比,所提供的方法避免了特异性、偏差、稳定性和效率方面的某些问题。在用于信息传递的基于连接的方法中,接合核酸的合适末端的效率和用于传递信息的其它所需步骤的复杂性可能是个问题。在一些实施方式中,所提供的采用聚合酶、核酸接合试剂和双链核酸切割试剂的方法提供了优于仅基于延伸或基于连接的系统的益处。通过采用在聚合酶步骤之后发生的切割步骤,可以避免聚合酶留下“A”突出端的A加尾问题。双链DNA的使用使可能在利用单链DNA组分的其它系统中发生的DNA-DNA相互作用最小化。在一些情况下,可以减少在所提供的方法中可以采用的较短间隔区的长度,如减少至2bp间隔区,并且在一些情况中,可以完全消除间隔区的使用。在一些方面,顺序编码方法在信息传递的一个循环之后由于不兼容的突出端而自终止。
在一些实施方式中,记录标签和编码标签两者都包含间隔区序列。例如,间隔区是小于或等于10个碱基、小于或等于9个碱基、小于或等于8个碱基、小于或等于7个碱基、小于或等于6个碱基、小于或等于5个碱基、小于或等于4个碱基、小于或等于3个碱基或小于或等于2个碱基的核酸分子。间隔区可以是循环特异性间隔区或循环交替间隔区。用于传递信息的系统的特定设计可以利用间隔区,使得如果由先前编码标签添加的间隔区与第二编码标签的间隔区的至少一部分相匹配,则信息仅从第二编码标签传递到经延伸记录标签。以这种方式,后续编码事件取决于先前编码事件并且以先前编码事件为条件。在一些其它实施方式中,记录标签和编码标签都不包含间隔区序列。
在一些实施方式中,可以任选地重复循环中的一些步骤。例如,在提供结合剂和从编码标签传递信息的一个循环之后,可以去除结合剂,并且可以再次提供结合剂以允许结合剂的再结合并且例如在不发生第一信息传递的情况下,允许发生信息传递的另一机会。在一些方面,所提供的使用交替间隔区的方法适于这种重复以允许信息传递的第二机会。如果第一结合和信息传递事件成功,则与成功的编码标签信息一起传递的间隔区将不允许重复的信息传递事件发生(即使结合剂识别供分析的大分子)。相反,如果第一信息传递事件不成功,则再结合将引入具有与现有记录标签上的间隔区相匹配的间隔区的编码标签,并且第二结合将允许信息传递事件在再结合步骤之后发生,由此提供弥补第一丢失事件的机制。
所提供的方法使用聚合酶、核酸接合试剂和双链核酸切割试剂。可以使用用于延伸、连接和切割双链核酸的任何合适的酶(参见例如,专利公开第CN104212791B号、第CN101560538A号和第CN100510069C号)。
在所提供的方法中,从编码标签到记录标签的信息传递开始于连接步骤。记录标签的5'端通过核酸接合试剂与编码标签的3'端接合(例如,连接)。在一些实施方式中,在记录标签通过核酸接合试剂与编码标签接合之后,结合剂不保持与大分子结合或不需要保持与大分子结合。
在一些示例中,核酸接合试剂是化学连接试剂或酶连接试剂。连接步骤可以通过化学连接或酶促连接(例如,粘性末端连接、单链(ss)连接(如ssDNA连接)或其任何组合)来进行。在一些设计中,连接可以是平端连接和/或粘性末端连接。所提供的顺序编码方法被设计成产生包括从编码标签传递的信息的双链结构,并且可以应用实现此目的的任何接合方法。连接酶的例子包含但不限于CV DNA连接酶、CircLigase、CircLigaseII、T4 DNA连接酶、T7 DNA连接酶、T3 DNA连接酶、Taq DNA连接酶、大肠杆菌(E.coli)DNA连接酶、9°N DNA连接酶(例如参见,美国专利公开第US 2014/0378315 A1号或美国专利第10,494,671B2号)。在一些优选实施方式中,核酸接合试剂是指接合两个DNA片段的酶(例如,连接酶),如T4DNA连接酶。
接合或连接步骤之后是延伸步骤,所述延伸步骤可以包含聚合酶介导的反应(例如,单链核酸或双链核酸的引物延伸)。使用连接的编码标签作为模板,延伸记录标签(或已经延伸的记录标签)的3'端。通过延伸步骤,从编码标签引入并连接的限制酶/核酸内切酶位点在经延伸记录标签上变成双链。在一些实施方式中,用于引物延伸的DNA聚合酶具有链置换活性,并且3'-5外切核酸酶活性有限或缺乏。许多这样的聚合酶的例子中的几个包括Klenowexo-(DNA Pol 1的Klenow片段)、T4 DNA聚合酶exo-、T7 DNA聚合酶exo(Sequenase2.0)、Pfu exo-、Vent exo-、Deep Vent exo-、Bst DNA聚合酶大片段exo-、Bca Pol、9°NPol和Phi29 Pol exo-。在一优选实施方式中,DNA聚合酶在室温和至多45℃下具有活性。在另一个实施方式中,采用嗜热聚合酶的“热启动”形式,使得聚合酶被激活并在约40℃-50℃下使用。示例性热启动聚合酶是Bst 2.0热启动DNA聚合酶(New England Biolabs)。还可以提供用于延伸反应的合适条件,包含用于反应的任何添加剂和缓冲液。
在延伸步骤后,产生含有能够被双链核酸切割试剂识别的识别序列的双链经延伸记录标签。切割双链经延伸记录标签在记录标签上产生3'突出端。在一些方面,当重复步骤(b)时,经延伸记录标签的通过双链核酸切割试剂产生的3'突出端可用于与第二编码标签杂交。在一些方面,切割双链经延伸记录标签使结合剂与经延伸记录标签不拴系或不连接。在一些具体情况下,切割双链记录标签从经延伸记录标签释放结合剂。在一些情况下,切割使结合剂可从被分析的大分子释放。双链核酸切割试剂可以是限制酶或限制性核酸内切酶。在一些实施方式中,限制酶是IIS型限制酶。使用IIS型限制酶的优点包含,与经典回文限制酶相比,所述IIS型限制酶可以在切割反应之后产生较少单链核苷酸,如图1B和实例2(仅2nt间隔区)所示。在一些优选实施方式中,被切割试剂切割之后的序列留下3'突出端。例如,切割试剂可以是酶BtsI、Mva1269I、BsaI、BsmBI等。IIS型限制酶可以识别包括以下的碱基序列:5'…GCAGTGNN…3'/3'…CGTCACNN…5'。在一些特定情况下,限制酶是Nb.BtsI或BtsI-v2或其衍生物。
在一些其它实施方式中,双链核酸切割试剂是具有回文特异性并在其识别序列内切割的IIP型限制酶。为了避免在将编码标签与记录标签连接之后在连接位点中潜在重建限制酶切割位点(参见例如,图1B,第一步),邻近连接位点的编码标签序列应不同于酶切割位点。在一些优选实施方式中,IIP型限制酶在切割之后在记录标签上产生3'突出端,如图1B所示。在一些其它实施方式中,产生平端的IIP型限制酶可以适用于所公开的方法。在这些实施方式中,编码标签的3'端应与在限制酶切割之后产生的记录标签的平端连接,并且邻近连接位点的编码标签序列应不同于限制酶剪切位点。
在一些其它实施方式中,酶或核酸内切酶的组合可以用于实现经延伸记录标签的两条链的切割。例如,如果使用切口酶或核酸内切酶来切割经延伸记录标签的第一链,则可以采用次要机制来切割第二链。在一些具体实施方式中,不使用切口酶或切口核酸内切酶。可以基于对优选的切割位点、消化位置与识别位置之间的距离、消化位置的精度以及产生所述方法的其它步骤的所需核酸末端的能力的考虑来选择适当的限制酶。
在一些实施方式中,核酸接合试剂和聚合酶是同时提供的。在一些实施方式中,聚合酶和双链核酸切割试剂是同时提供的。
在所提供实施方式中的一些实施方式中,步骤(a)、(b)、(c)、(d)和(e)按顺序进行。在某些实施方式中,结合剂与大分子(例如,肽)的结合事件信息以循环方式从编码标签传递到与固定的大分子缔合的记录标签。在一些实施方式中,重复一次或多次的步骤包含:(b)使所述大分子与能够与所述大分子结合的结合剂接触,其中所述结合剂包括具有关于所述结合剂的标识信息的编码标签,以允许所述大分子与所述结合剂之间的结合;(c)通过核酸接合试剂将所述记录标签的5'端与所述编码标签的3'端接合;(d)使用所述编码标签作为模板通过聚合酶延伸所述记录标签,从而产生双链经延伸记录标签;以及(e)用双链核酸切割试剂切割所述双链经延伸记录标签,以产生经延伸记录标签中的3'突出端。
在一些实施方式中,所述方法进一步包含去除结合剂。例如,可以在将编码标签的信息传递到记录标签之后去除结合剂。一旦进行编码循环,就可以在重复步骤(b)之前去除结合剂。可以通过在洗涤期间提供适当的条件(例如,试剂和温度)来去除或释放结合剂。
在一些实施方式中,所述方法进一步包含在重复步骤(b)之前去除大分子的一部分。例如,如果多肽正在被分析,则所述方法可以包含在重复步骤(b)之前(例如,从末端)去除多肽的一个或多个氨基酸。在一些情况下,在重复步骤(b)之前,从多肽去除N末端氨基酸(NTAA)多肽以暴露多肽的新NTAA。在一些实施方式中,大分子的所去除部分是用化学剂或酶剂处理的或已经用化学剂或酶剂修饰。在一些情况下,用修饰多肽的末端氨基酸的试剂处理多肽。多肽的修饰,如NTAA,可以在步骤(b)之前进行。在一些情况下,多肽的修饰,如NTAA,可以在步骤(e)之后进行。
在一些情况下,所述方法进一步包含在这些步骤中的任何一个或多个步骤之前、之间或之后的一个或更多个洗涤步骤。例如,在步骤(b)中提供结合剂之后,可以在引入酶试剂(例如,核酸接合试剂、聚合酶、双链核酸切割试剂)中的任何酶试剂之前进行洗涤步骤。此类洗涤步骤可以去除非特异性结合的结合剂。取决于结合剂的亲和性,可以调节洗涤步骤的严格性。在一些情况下,优选的是在步骤(c)、(d)与(e)之间不需要洗涤步骤。在一些其它方面,在步骤(c)的连接之后进行洗涤步骤。在连接和洗涤之后,可以在一个步骤中提供涉及聚合酶和双链核酸切割试剂的后续步骤。在一些其它方面,在步骤(d)的延伸之后进行洗涤步骤。在一些情况下,洗涤步骤在步骤(c)、步骤(d)和/或步骤(e)之前进行。在一个步骤中发生连接和延伸之后,可以在提供双链核酸切割试剂之前进行洗涤步骤。在一些情况下,所述方法进一步包含在将信息传递到记录标签之后,如在步骤(e)之后和/或在后续循环中重复步骤(b)之前,去除结合剂。
在一些实施方式中,进行最终信息传递循环以向经延伸记录标签提供加帽序列,其中任选地,加帽序列包括用于扩增、测序或两者的通用引发位点。加帽序列可以通过被配置成与大分子的通用特征结合的结合剂被提供给经延伸记录标签。以这种方式,用于递送加帽序列的结合剂被配置成与样品中的所有或许多大分子所含有的靶部分结合。在一些示例中,通用特征是多肽的化学修饰。加帽序列可以包含可用于分析经延伸记录标签的序列,如通用反向引发位点。
A.记录标签
供分析的大分子(例如,蛋白质或多肽)可以用包括核酸分子或寡核苷酸的记录标签进行标记。在一些方面,样品中的多个大分子配有记录标签。记录标签可以使用任何合适的手段直接或间接地与大分子缔合或附着。在一些实施方式中,大分子可与一个或多个记录标签缔合。在一些方面,在与结合剂接触之前,记录标签可以直接或间接地与大分子缔合或附着。
在一些实施方式中,至少一个记录标签与大分子(例如,多肽)直接或间接缔合或共定位。在步骤(a)中提供大分子和所缔合记录标签可以包含处理记录标签和任何相关核酸,以接合、切割或以其它方式制备用于测定的记录标签。在一些实施方式中,步骤(a)包含使用连接和/或延伸以向记录标签提供条形码和/或UMI。在一些方面,步骤(a)包含使用限制酶切割记录标签以产生3'突出端。例如,通过使用聚合酶延伸和/或通过双链核酸切割试剂切割来产生记录标签的3'突出端。用于制备和提供记录标签的示例性工作流程在图1A中示出。
在一个特定实施方式中,单个记录标签例如通过附着于N或C末端氨基酸而附着于多肽。在另一个实施方式中,多个记录标签附着于多肽上,例如附着于赖氨酸残基或肽主链上。在一些实施方式中,用多个记录标签标记的多肽被片段化或消化成较小的肽,每个肽平均标记有一个记录标签。
记录标签可包含DNA、RNA或多核苷酸类似物,包括PNA、gPNA、GNA、HNA、BNA、XNA、TNA或其组合。记录标签可以是单链的,或部分或完全双链的。在一些特定实施方式中,某些优点伴随包括双链区域的记录标签。例如,优点可以是减少DNA-DNA与系统的其它核酸组分的相互作用。在一些情况下,记录标签包含核酸发夹。记录标签可具有平端或突出端。在一些特定实施方式中,对与大分子缔合的记录标签进行加工或处理(例如,通过消化),使得所述记录标签具有3'突出端。在某些实施方式中,样品内的所有或可观量的大分子(例如,至少50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或100%)用记录标签标记。在其它实施方式中,样品内大分子的子集用记录标签标记。在一个特定实施方式中,样品中大分子的子集用记录标签进行靶向(分析物特异性)标记。例如,可使用靶蛋白特异性结合剂(例如抗体、适配体等)实现对蛋白质的靶向记录标签标记。在一些实施方式中,将样品提供到载体上之前,将记录标签(或其部分)附着于大分子上。在一些实施方式中,将样品提供到载体上之后,将记录标签附着在大分子上。
在一些实施方式中,记录标签可包含其它核酸组分。在一些实施方式中,记录标签可包含唯一分子标识符、区室标签、分区条形码、样品条形码、级分条形码、间隔区序列、通用引发位点或其任何组合。在一些实施方式中,记录标签可包含封闭基团,例如在记录标签的3'端处。在一些情况下,封闭记录标签的3'端以防止聚合酶延伸所述记录标签。
在一些实施方式中,记录标签可以包括样品标识条形码。样品条形码可用于对单个反应容器中或固定在单个固体基体或固体基体集合(例如,平面载玻片,单个管或容器中所含的珠群等)上的一组样品进行多重分析。例如,来自许多不同样品的大分子可以用带有样品特异性条形码的记录标签进行标记,然后将所有样品汇集在一起,然后固定到载体上、循环结合结合剂并分析记录标签。可替代地,可以保持样品分开,直到创建DNA编码文库后,并在DNA编码文库的PCR扩增期间附着样品条形码,然后在测序前混合在一起。在测定不同丰度类别的分析物(例如,蛋白质)时,这种方法可能有用。
在某些实施方式中,记录标签包含任选的唯一分子标识符(UMI),它为与该UMI缔合的每个大分子(例如,多肽)提供唯一标识符标签。UMI可以为约3至约40个碱基、约3至约30个碱基、约3至约20个碱基、或约3至约10个碱基、或约3至约8个碱基。在一些实施方式中,UMI的长度为约3个碱基、4个碱基、5个碱基、6个碱基、7个碱基、8个碱基、9个碱基、10个碱基、11个碱基、12个碱基、13个碱基、14个碱基、15个碱基、16个碱基、17个碱基、18个碱基碱基、19个碱基、20个碱基、25个碱基、30个碱基、35个碱基、或40个碱基。UMI可以用于对来自多个经延伸记录标签的测序数据进行去卷积,以标识来自单个大分子的序列读段。在一些实施方式中,在大分子的文库内,每个大分子都与单个记录标签缔合,每个记录标签包含唯一的UMI。在其它实施方式中,记录标签的多个副本与单个大分子缔合,每个记录标签副本包含相同的UMI。在一些实施方式中,UMI具有与间隔区或编码标签不同的碱基序列,以便于在序列分析期间区分这些组分。在一些实施方式中,UMI可提供作为位置标识符的功能,还可在大分子分析测定中提供信息。例如,UMI可用于标识传承上相同的分子,因此起源于相同的初始分子。在一些方面,此信息可以用于校正扩增中的变化,并且用于在分析期间检测和校正测序错误。
在一些实施方式中,记录标签包含间隔区聚合物。在某些实施方式中,记录标签在其末端、例如3'端包含间隔区。如本文所用,在记录标签的上下文中提及的间隔区序列包括与关联结合剂相关的间隔区序列相同的间隔区序列,或与关联结合剂相关的间隔区序列互补的间隔区序列。记录标签上的末端(例如,3')间隔区允许在第一结合循环期间将同源结合剂的标识信息从编码标签传递到记录标签(例如,通过用于引物延伸或粘性末端连接的互补间隔区序列的退火)。在一个实施方式中,间隔区序列的长度约1-20个碱基、长度约2-12个碱基、或长度5-10个碱基。在一些情况下,间隔区序列的长度为约为2至5个碱基。间隔区的长度可以取决于如用于将编码标签信息传递到记录标签的温度和反应条件等因素。
在使用间隔区序列的一些实施方式中,与多肽文库相关的记录标签共享共同的间隔区序列。在其它实施方式中,与多肽文库相关的记录标签具有与衔接分子的结合循环特异性间隔区序列互补的结合循环特异性间隔区序列。在一些方面,记录标签中的间隔区序列被设计成与记录标签中的其它区域具有最小互补性。在一些情况下,记录标签的间隔区序列应与存在于记录标签或编码标签中的如唯一分子标识符、条形码(例如,区室、分区、样品、空间位置)、通用引物序列、编码标签序列、循环特异性序列等组分具有最小序列互补性。在一些实施方式中,基于选择使用的双链核酸切割试剂(例如,限制酶)设计间隔区。
在某些实施方式中,记录标签包含通用引发位点,例如,正向或5'通用引发位点。通用引发位点是可用于引发文库扩增反应和/或测序的核酸序列。通用引发位点可包括但不限于,PCR扩增引发位点、退火到流动细胞表面上的互补寡核苷酸的流动细胞适配序列(例如Illumina下一代测序)、测序引发位点、或其组合。通用引发位点可以为约10个碱基至约60个碱基。在一些实施方式中,通用引发位点包括Illumina P5引物(AATGATACGGCGACCACCGA;SEQ ID NO:1)或Illumina P7引物(CAAGCAGAAGACGGCATACGAGAT;SEQ ID NO:2)。
在某些实施方式中,记录标签包含区室标签。在一些实施方式中,区室标签是记录标签内的组分。在一些实施方式中,记录标签还可以包括代表区室标签的条形码,其中区室例如载体上的液滴、微孔、物理区域等被分配唯一条形码。区室与特定条形码的联合可以通过多种方式实现,例如通过将单个条形码珠包封在区室中,例如,通过直接合并或向区室添加条形码液滴,通过直接打印或向区室注入条形码试剂等。区室内的条形码试剂用于向区室内的大分子或其片段加上区室特异性条形码。应用于将蛋白质划分到区室中,所述条形码可以用于将分析的肽映射回到其在区室中的起源蛋白质分子。这可以极大地促进蛋白质标识。区室条形码也可以用于标识蛋白质复合体。在其它实施方式中,可以为代表区室群的子集的多个区室分配代表该子集的唯一条形码。在一些实施方式中,记录标签包含级分条形码,其含有级分内大分子的标识信息。
在一些实施方式中,所述标签(例如,区室标签、分区条形码、样品条形码、级分条形码等)中的一个或多个还包含能够与多个蛋白质复合体、蛋白质或多肽上的内部氨基酸、肽主链或N末端氨基酸反应的官能部分。在一些实施方式中,所述官能部分是点击化学部分、醛、叠氮化物/炔烃、或马来酰亚胺/硫醇、或环氧化物/亲核试剂、逆电子需求Diels-Alder(iEDDA)基团、或用于Staudinger反应的部分。在一些具体实施方式中,多个区室标签通过将区室标签印刷、点样、喷墨到区室中或其组合而形成。在一些实施方式中,所述标签附着于多肽以通过多肽-多肽连键将所述标签与大分子连接。在一些实施方式中,附有标签的多肽包含蛋白质连接酶识别序列。
在某些实施方式中,肽或多肽大分子可以通过亲和捕获试剂固定在载体上(并任选共价交联),其中记录标签直接与亲和捕获试剂缔合,或可替代地,大分子可以直接固定在带有记录标签的载体上。
在一些实施方式中,大分子附着于诱饵核酸以形成核酸-大分子嵌合体。固定方法可以包括通过将诱饵核酸与附着于载体上的捕获核酸杂交而使核酸-大分子嵌合体接近载体,并且将核酸-大分子嵌合体与固体载体共价偶联。在一些情况下,核酸-大分子嵌合体与固体载体间接偶联,例如通过接头偶联。在一些实施方式中,多个核酸-大分子嵌合体偶联在固体载体上,并且任何相邻偶联的核酸-大分子嵌合体以约50nm或更大的平均距离彼此间隔开。在一些情况下,诱饵核酸包含通用引发位点或其一部分。
如图1A中的示例性格式所示,待分析的肽附着于诱饵核酸上,所述诱饵核酸与固定在载体上的捕获核酸发夹杂交。将诱饵核酸与捕获核酸连接,所述捕获核酸包括用于附着于载体上的反应性偶联部分。在一些示例中,诱饵核酸或捕获核酸或经接合的诱饵核酸和捕获核酸可以充当记录标签,关于多肽的信息可以从编码标签传递到所述记录标签。
图1A示出了用于制备记录标签的示例性步骤,所述记录标签使用包括或是具有凹陷的5'磷酸化末端的核酸发夹的捕获核酸。在图1A的第二幅图中,具有所附着的肽的诱饵核酸与捕获核酸发夹杂交并与捕获核酸发夹连接。诱饵核酸可以包括一个或多个所示的条形码,并且还可以含有限制酶位点(或部分限制酶位点)。在图1A的第三幅图中,使用聚合酶反应来延伸捕获核酸发夹的3'端,从而产生附着有肽的双链记录标签构建体。一旦使用诱饵核酸作为模板进行延伸,消化位点是双链的并且能够被IIS型限制酶识别以供切割,并且切割产生具有带有凹陷的5'磷酸化末端的3'突出端(2-碱基对序列)的记录标签。含有一个或多个条形码的此记录标签可用于从编码标签传递信息。在一些实施方式中,可以使用如在国际专利申请第PCT/US2020/27840号中描述的方法中的任何方法来用记录标签制备供分析的大分子并且将其固定在载体上。大分子的制备和/或固定可以在信息传递步骤之前和/或与信息传递步骤分开进行。
在一些实施方式中,控制或滴定带有记录标签的大分子的密度或数量。在一些示例中,可通过提供稀释或受控的记录标签数量来滴定样品中记录标签的期望的间距、密度和/或量。在一些示例中,记录标签的期望的间距、密度和/或量可通过当提供、缔合和/或附着记录标签时掺入竞争分子或“假”竞争分子来实现。在一些情况下,“假”竞争分子以与缔合或附着于样品中大分子的记录标签相同的方式进行反应,但竞争分子不充当记录标签。在一些具体示例中,如果期望的密度是样品中每1,000个用于连接的可用位点1个功能记录标签的话,则采用每1,000个“假”竞争分子掺入1个功能记录标签来达到期望的间距。在一些示例中,基于功能记录标签的反应速率与竞争分子的反应速率的比较来调整功能记录标签的比率。
在一些示例中,使用标准胺偶联化学方法对带有记录标签的大分子进行标记。例如,取决于反应的pH,e-氨基(例如,赖氨酸残基的氨基)和N末端氨基可能易于被胺反应性偶联剂标记(Mendoza等人,Mass Spectrom Rev(2009)28(5):785-815)。在一特定实施方式中,记录标签包括反应性部分(例如,用于与固体表面、多功能接头或大分子缀合)、接头、通用引发序列、条形码(例如,区室标签、分区条形码、样品条形码、级分条形码或其任何组合)、任选的UMI以及用于促进信息传递的间隔区(Sp)序列。在另一个实施方式中,可以先用通用DNA标签标记蛋白质,然后通过酶促或化学偶联步骤将条形码-Sp序列(表示样品、区室、载玻片上的物理位置等)附着在所述蛋白质上。通用DNA标签包含用于标记蛋白质或多肽大分子并且可以用作条形码(例如区室标签、记录标签等)的附着点的短核苷酸序列。例如,记录标签可在其末端包含与通用DNA标签互补的序列。在某些实施方式中,通用DNA标签是通用引发序列。在标记的蛋白质上的通用DNA标签与记录标签(例如与珠粒结合的记录标签)中的互补序列杂交后,退火的通用DNA标签可通过引物延伸进行延伸,将记录标签信息传递给带有DNA标签的蛋白质。在一个特定实施方式中,蛋白质在被蛋白酶消化成肽之前用通用DNA标签标记。然后可以将来自消化的标记肽上的通用DNA标签转化为信息性的且有效的记录标签。
记录标签可以包括针对存在于大分子(例如,蛋白质)上的同源反应性部分的反应性部分(例如,点击化学标记、光亲和标记)。例如,记录标签可以包括用于与炔烃衍生的蛋白质相互作用的叠氮化物部分,或者记录标签可以包括用于与天然蛋白质相互作用的二苯甲酮等。在靶蛋白被靶蛋白特异性结合剂结合后,记录标签和靶蛋白通过其对应的反应性部分偶联。在靶蛋白被记录标签标记后,可通过消化与靶蛋白特异性结合剂连接的DNA捕获探针来去除靶蛋白特异性结合剂。例如,DNA捕获探针可设计成含有尿嘧啶碱基,然后用尿嘧啶特异性切除试剂(例如USER
将来自一个或多个编码标签的信息传递到记录标签,以产生经延伸记录标签。在一些实施方式中,经延伸记录标签包括通用正向(或5')引发序列、从一个或多个编码标签传递的信息以及间隔区序列。在一些实施方式中,经延伸记录标签包括通用正向(或5')引发序列、任何任选的条形码和/或UMI(例如,样品条形码、分区条形码、区室条形码或其任何组合)、从一个或多个编码标签传递的信息、间隔区序列和通用反向(或3')引发序列。
B.结合剂
本文所描述的方法使用被配置成与待分析的大分子(例如,多肽、肽、蛋白质)相互作用的结合剂。测定可以包含使多种结合剂与多个大分子接触。在一些实施方式中,本发明的方法包括使单个大分子与一种结合剂接触,使多个大分子与一种结合剂接触,或使多个大分子与多种结合剂接触。在一些实施方式中,所述多种结合剂包含配置成与不同靶部分结合的结合剂的混合物。
结合剂可以是能够与多肽的组分或特征结合的任何分子(例如,肽、多肽、蛋白质、核酸、碳水化合物、小分子等)。结合剂可以是天然存在的、合成产生的或重组表达的分子。在一些实施方式中,用于工程改造结合剂的支架可以来自任何物种,例如人类、非人类、转基因。结合剂可以与靶大分子或基序的一部分结合。结合剂可与多肽的单个单体或亚基(例如,单个氨基酸)结合,或与多肽的多个相连的亚基(例如,较长的多肽分子的二肽、三肽或更高级肽)结合。
在一些示例中,结合剂包括抗体、抗原结合抗体片段、单结构域抗体(sdAb)、重组仅重链抗体(VHH)、单链抗体(scFv)、鲨鱼源性可变结构域(vNAR)、Fv、Fab、Fab'、F(ab')2、线性抗体、双功能抗体、适配体、肽模拟分子、融合蛋白、反应性或非反应性小分子或合成分子。
在某些实施方式中,结合剂可被设计成共价结合。共价结合可被设计成有条件的或有利于与正确的部分结合。例如,靶标及其同源结合剂可以各自用反应性基团进行修饰,使得一旦靶标特异性结合剂与靶标结合,就会进行偶联反应以在两者之间产生共价连接。结合剂与缺乏关联反应性基团的其它位置的非特异性结合不会导致共价连接。在一些实施方式中,靶包含能够与结合剂形成共价键的配体。在一些实施方式中,靶标包括能够与结合剂共价结合的配体基团。结合剂与其靶标之间的共价结合可允许使用更严格的洗涤来去除非特异性结合的结合剂,从而增加所述测定的特异性。在一些实施方式中,所述方法包含在使结合剂与大分子接触以去除非特异性结合的结合剂之后的洗涤步骤。取决于结合剂对靶标的亲和力和/或所形成的复合体的强度和稳定性,可以调节洗涤步骤的严格性。
在一些实施方式中,结合剂被配置成提供针对结合剂与大分子的结合的特异性。在某些实施方式中,结合剂可以是选择性结合剂。如本文所用,选择性结合是指相对于与不同配体(例如氨基酸或氨基酸类别)的结合而言,结合剂优先结合特异性配体(例如氨基酸或氨基酸类别)的能力。选择性通常被称为在与结合剂的复合体中一种配体被另一种配体置换的反应的平衡常数。通常,这样的选择性与配体的空间几何形态和/或配体与结合剂结合的方式和程度例如通过氢键合、疏水结合和范德华力(非共价相互作用)或通过与结合剂的可逆或不可逆共价连接有关。还应该理解,选择性可能是相对的,并且与绝对的相反,不同的因素可以影响它,包括配体浓度。因此,在一个示例中,结合剂选择性地结合二十种标准氨基酸之一。在一些示例中,结合剂与N末端氨基酸残基、C末端氨基酸残基或内部氨基酸残基结合。
在一些实施方式中,结合剂是部分特异性或选择性的。在一些方面,结合剂优先结合一种或多种氨基酸。在一些示例中,结合剂可结合或能够结合二十种标准氨基酸中的两种或更多种。例如,结合剂可优先结合氨基酸A、C和G胜过其它氨基酸。在一些其它示例中,结合剂可以选择性地或特异性地结合多于一种氨基酸。在一些方面,结合剂还可偏好从末端氨基酸起第二、第三、第四、第五位等处的一种或多种氨基酸。在一些情况下,结合剂优先结合特定末端氨基酸和倒数第二个氨基酸。例如,结合剂可优先结合AA、AC和AG,或者结合剂可优先结合AA、CA和GA。在一些实施方式中,结合剂可在靶标的一些或所有位置中表现出靶标结合偏好的灵活性和可变性。在一些示例中,结合剂可对一种或多种特定的靶末端氨基酸具有偏好,并且对倒数第二位的靶标具有灵活的偏好。在一些其它示例中,结合剂可对倒数第二个氨基酸位置的一种或多种特定靶氨基酸具有偏好,并且对末端氨基酸位置的靶标具有灵活的偏好。在一些实施方式中,结合剂对包含大分子的末端氨基酸和其它组分的靶标具有选择性。在一些示例中,结合剂对包含肽主链的末端氨基酸和至少一部分肽主链的靶标具有选择性。在一些特定示例中,结合剂对包含末端氨基酸和酰胺肽主链的靶标具有选择性。在一些情况下,肽主链包含天然肽主链或翻译后修饰。在一些实施方式中,结合剂表现出变构结合。
在一些实施方式中,所述方法包括使结合剂的混合物与大分子的混合物接触,并且选择性仅需要是相对于靶标所暴露的其它结合剂而言的。还应该理解,结合剂的选择性不必对特异性分子是绝对的,而是可以对分子的一部分是绝对的。在一些例子中,结合剂的选择性不必是对特定氨基酸绝对的,而可以是对一类氨基酸的选择性,例如对具有极性或非极性侧链、或带有(正或负)电荷的侧链、或带有芳族侧链、或带有某些特定类别或大小的侧链的氨基酸等。在一些实施方式中,结合剂选择性结合大分子的特征或组分的能力通过比较结合剂的结合能力来表征。例如,可以将结合剂对靶标的结合能力与结合不同靶标的结合剂的结合能力进行比较,例如,将对一类氨基酸具有选择性的结合剂与对不同类别的氨基酸具有选择性的结合剂进行比较。在一些示例中,将对非极性侧链具有选择性的结合剂与对极性侧链具有选择性的结合剂进行比较。在一些实施方式中,对肽的特征、组分或一种或多种氨基酸具有选择性的结合剂,与对不同的肽特征、组分或一种或多种氨基酸具有选择性的结合剂相比,表现出至少1X、至少2X、至少5X、至少10X、至少50X、至少100X、或至少500X更高的结合。
在一个特定实施方式中,结合剂对目的大分子、例如多肽具有高亲和力和高选择性。具体地,具有低解离速率的高结合亲和力对于衔接分子与编码标签的杂交可能是有效的。在某些实施方式中,结合剂的Kd为约<500nM、<200nM、<100nM、<50nM、<10nM、<5nM、<1nM、<0.5nM、或<0.1nM。在一个特定实施方式中,结合剂以>1X、>5X、>10X、>100X或>1000X其Kd的浓度添加到多肽中以驱动结合完成。例如,抗体与单一蛋白质分子的结合动力学在Chang等人,J Immunol Methods(2012)378(1-2):102-115中描述。
在某些实施方式中,结合剂可以与肽的末端氨基酸、中间氨基酸、二肽(两个氨基酸的序列)、三肽(三个氨基酸的序列)或肽分子的更高级肽结合。在一些实施方式中,结合剂文库中的每种结合剂选择性地结合特定氨基酸,例如二十种标准天然存在的氨基酸中的一种。标准天然存在氨基酸包括丙氨酸(A或Ala)、半胱氨酸(C或Cys)、天冬氨酸(D或Asp)、谷氨酸(E或Glu)、苯丙氨酸(F或Phe)、甘氨酸(G或Gly)、组氨酸(H或His)、异亮氨酸(I或Ile)、赖氨酸(K或Lys)、亮氨酸(L或Leu)、甲硫氨酸(M或Met)、天冬酰胺(N或Asn)、脯氨酸(P或Pro)、谷氨酰胺(Q或Gln)、精氨酸(R或Arg)、丝氨酸(S或Ser)、苏氨酸(T或Thr)、缬氨酸(V或Val)、色氨酸(W或Trp)、和酪氨酸(Y或Tyr)。在一些实施方式中,结合剂与未修饰的或天然的(例如,自然的)氨基酸结合。在一些示例中,结合剂与肽分子的未修饰或天然二肽(二氨基酸序列)、三肽(三氨基酸序列)或更高级的肽结合。可以对结合剂进行工程改造,使其对天然或未修饰的N末端氨基酸(NTAA)具有高亲和力、对天然或未修饰的NTAA具有高特异性或两者兼而有之。在一些实施方式中,可以通过使用噬菌体展示,定向进化有希望的亲和支架来开发结合剂。
在某些实施方式中,结合剂可结合氨基酸的翻译后修饰。在一些实施方式中,肽包含一个或多个可相同或不同的翻译后修饰。肽的NTAA、CTAA、中间氨基酸或其组合可被翻译后修饰。对氨基酸的翻译后修饰包括酰化、乙酰化、烷基化(包括甲基化)、生物素化、丁酰化、氨甲酰化、羰基化、脱酰胺化、脱亚胺化、白喉酰胺形成、二硫桥键形成、消去化、黄素连接、甲酰化、γ-羧基化、谷氨酰化、甘氨酰化、糖基化、糖基磷脂酰肌醇化、血红素C连接、羟基化、羟腐氨酸形成、碘化、异戊二烯化、脂化、脂酰化、丙二酰化、甲基化、肉豆蔻酰化、氧化、棕榈酰化、PEG化、磷酸泛酰巯基乙胺化、磷酸化、异戊二烯化、丙酰化、亚视黄亚基席夫碱形成、S-谷胱甘肽化、S-亚硝基化、S-亚磺酰化、硒化、琥珀酰化、亚磺化、泛素化和C-末端酰胺化。(也参见,Seo和Lee,2004,J.Biochem.Mol.Biol.37:35-44)。
在某些实施方式中,凝集素用作检测蛋白质、多肽或肽的糖基化状态的结合剂。凝集素是碳水化合物结合蛋白,可以选择性识别游离碳水化合物或糖蛋白的聚糖表位。识别各种糖基化状态(例如,核心岩藻糖、唾液酸、N-乙酰基-D-乳糖胺、甘露糖、N-乙酰基-葡糖胺)的凝集素的列表包含:A、AAA、AAL、ABA、ACA、ACG、ACL、AOL、ASA、BanLec、BC2L-A、BC2LCN、BPA、BPL、Calsepa、CGL2、CNL、Con、ConA、DBA、网柄菌凝素(Discoidin)、DSA、ECA、EEL、F17AG、Gal1、Gal1-S、Gal2、Gal3、Gal3C-S、Gal7-S、Gal9、GNA、GRFT、GS-I、GS-II、GSL-I、GSL-II、HHL、HIHA、HPA、I、II、木菠萝素(Jacalin)、LBA、LCA、LEA、LEL、Lentil、Lotus、LSL-N、LTL、MAA、MAH、MAL_I、Malectin、MOA、MPA、MPL、NPA、Orysata、PA-IIL、PA-IL、PALa、PHA-E、PHA-L、PHA-P、PHAE、PHAL、PNA、PPL、PSA、PSL1a、PTL、PTL-I、PWM、RCA120、RS-Fuc、SAMB、SBA、SJA、SNA、SNA-I、SNA-II、SSA、STL、TJA-I、TJA-II、TxLCI、UDA、UEA-I、UEA-II、VFA、VVA、WFA、WGA(参见,Zhang等人,2016,MABS 8:524-535)。
在一些实施方式中,结合剂可结合天然的或未修饰的或未标记的或天然的末端氨基酸。在一些示例中,结合剂与肽分子的未修饰或天然二肽(二氨基酸序列)、三肽(三氨基酸序列)或更高级的肽结合。可以对结合剂进行工程改造,使其对修饰的NTAA具有高亲和力、对修饰的NTAA具有高特异性、或二者兼而有之。在一些实施方式中,可以通过使用噬菌体展示,定向进化有希望的亲和支架来开发结合剂。
蛋白质/酶支架的定向进化可以用于生成在N末端标记的环境下识别N末端氨基酸的更高亲和力、更高特异性结合剂。在一示例中,Havranak等人(美国专利公开第US2014/0273004号)描述了工程化氨酰基tRNA合成酶(aaRS)作为特异性NTAA结合剂。aaRSs的氨基酸结合袋具有结合关联氨基酸的内在能力,但通常表现出结合亲和力和特异性差。而且,这些天然氨基酸结合剂不识别N末端标记。aaRS支架的定向进化可以用于生成在N末端标记的环境下识别N末端氨基酸的更高亲和力、更高特异性结合剂。
在某些实施方式中,结合剂可结合修饰或标记的末端氨基酸(例如,已被官能化或修饰的NTAA)。在一些实施方式中,结合剂可结合化学或酶促修饰的末端氨基酸。经修饰或经标记的NTAA可以是用下列进行官能化的NTAA:异硫氰酸苯酯,PITC,1-氟-2,4-二硝基苯(Sanger试剂,DNFB),苄氧羰基氯或羧基苯甲酰氯(Cbz-Cl),N-(苄氧羰氧基)琥珀酰亚胺(Cbz-OSu或Cbz-O-NHS),丹磺酰氯(DNS-Cl,或1-二甲氨基萘-5-磺酰氯),4-磺酰-2-硝基氟苯(SNFB),N-乙酰基-衣托酸酐,衣托酸酐,2-吡啶甲醛,2-甲酰基苯基硼酸,2-乙酰苯基硼酸,1-氟-2,4-二硝基苯,琥珀酸酐,4-氯-7-硝基苯并呋咱,五氟苯基异硫氰酸酯,4-(三氟甲氧基)-苯基异硫氰酸酯,4-(三氟甲基)-苯基异硫氰酸酯,3-(羧酸)-苯基异硫氰酸酯,3-(三氟甲基)-苯基异硫氰酸酯,1-萘基异硫氰酸酯,N-硝基咪唑-1-甲脒,
结合剂可与肽、多肽或蛋白质分子的N末端肽、C末端肽或中间肽结合。结合剂可与肽分子的N末端氨基酸、C末端氨基酸或中间氨基酸结合。结合剂可与N末端或C末端二氨基酸部分结合。N末端二氨基酸包含所述N末端氨基酸和倒数第二个N末端氨基酸。C末端二氨基酸是对C末端的类似定义。在一些实施方式中,结合剂结合化学修饰的N末端氨基酸残基或化学修饰的C末端氨基酸残基。为了增加结合剂对肽的N末端氨基酸(NTAA)的亲和力,可用“免疫原性”半抗原、例如二硝基苯酚(DNP)修饰NTAA。这可以使用将DNP基团附着到NTAA的胺基团上的Sanger试剂,即二硝基氟苯(DNFB),以循环测序方法实现。商业的抗DNP抗体具有在低nM范围(约8nM,LO-DNP-2)的亲和力(Bilgicer等人,J Am Chem Soc(2009)131(26):9361-9367);因此,有理由认为,应该有可能将高亲和力的NTAA结合剂工程改造到用DNP(通过DNFB)修饰的许多NTAA,并且同时实现针对特定NTAA的良好结合选择性。在另一个示例中,可使用4-磺酰基-2-硝基氟苯(SNFB)用磺酰基硝基苯酚(SNP)修饰NTAA。用替代性NTAA修饰剂,例如乙酰基或脒基(胍基)基团,也可实现类似的亲和力增强。
在某些实施方式中,结合剂可以是适配体(例如,肽适配体、DNA适配体或RNA适配体)、拟肽、抗体或其特异性结合片段、氨基酸结合蛋白或酶、抗体结合片段、抗体模拟物、肽、肽模拟物、蛋白质或多核苷酸(例如,DNA、RNA、肽核酸(PNA)、gPNA、桥连核酸(BNA)、异种核酸(XNA)、甘油核酸(GNA)、或苏糖核酸(TNA)、或其变体。
如本文所用的术语抗体以广义使用,不仅包括完整的抗体分子,例如但不限于免疫球蛋白A、免疫球蛋白G、免疫球蛋白D、免疫球蛋白E和免疫球蛋白M,还包括抗体分子或其部分的与至少一个表位免疫特异性结合的任何免疫反应性组分。抗体可以是天然存在的、合成产生的或重组表达的。抗体可以是融合蛋白。抗体可以是抗体模拟物。抗体的例子包括但不限于,Fab片段、Fab'片段、F(ab')2片段、单链抗体片段(scFv)、微型抗体、纳米抗体、双抗体、交联抗体片段、Affibody
与抗体一样,特异性识别大分子、例如肽或多肽的核酸和肽适配体可以使用已知的方法产生。适配体以高度特异性、构象依赖性方式结合靶分子,通常具有非常高的亲和力,但如果希望,可以选择结合亲和力较低的适配体。已显示适配体基于非常小的结构差异、例如甲基或羟基基团的存在与否来区分靶标,并且某些适配体可以区分D-和L-对映异构体。已获得结合小分子靶标的适配体,小分子靶标包括药物、金属离子和有机染料、肽、生物素和蛋白质,蛋白质包括但不限于链霉亲和素、VEGF和病毒蛋白质。已经显示适配体在生物素化、荧光素标记后以及在附着于玻璃表面和微球时仍具有功能活性。(参见例如,Jayasena,1999,Clin Chem 45:1628-50;Kusser2000,J.Biotechnol.74:27-39;Colas,2000,CurrOpin Chem Biol 4:54-9)。特异性结合精氨酸和AMP的适配体也有描述(参见,Patel和Suri,2000,J.Biotech.74:39-60)。在以下文献中已经公开了与特异性氨基酸结合的寡核苷酸适配体:Gold等人(1995,Ann.Rev.Biochem.64:763-97)。还描述了与氨基酸结合的RNA适配体(Ames和Breaker,2011,RNA Biol.8;82-89;Mannironi等人,2000,RNA 6:520-27;Famulok,1994,J.Am.Chem.Soc.116:1698-1706)。
可以通过基因工程修饰天然或合成产生的蛋白质以在氨基酸序列中引入一个或多个突变从而产生与多肽的特定组分或特征(例如,NTAA、CTAA、或翻译后修饰的氨基酸或肽)结合的工程化蛋白质,来制造结合剂。例如,可以修饰外肽酶(例如,氨肽酶、羧肽酶、二肽基肽酶、二肽基氨肽酶)、外切蛋白酶、突变的外切蛋白酶、突变的anticalin、突变的ClpS、抗体或tRNA合成酶以产生与特定NTAA选择性结合的结合剂。在另一个示例中,可以修饰羧肽酶以产生选择性结合特定CTAA的结合剂。还可以设计或修饰和利用结合剂以特异性结合修饰的NTAA或修饰的CTAA,例如具有翻译后修饰的(例如磷酸化NTAA或磷酸化CTAA),或用标记(例如,PTC、1-氟-2,4-二硝基苯(使用Sanger试剂,DNFB)、丹磺酰氯(使用DNS-Cl、或1-二甲氨基萘-5-磺酰氯)、或使用硫代酰化试剂、硫代乙酰化试剂、乙酰化试剂、酰胺化(胍基化)试剂或硫代苄基化试剂)修饰的。用于蛋白质定向进化的策略是本领域已知的(例如,Yuan等人,2005,Microbiol.Mol.Biol.Rev.69:373-392),并且包含噬菌体展示、核糖体展示、mRNA展示、CIS展示、CAD展示、乳液、细胞表面展示方法、酵母表面展示、细菌表面展示等。
在另一个示例中,文献中也描述了高度选择性的工程化ClpS。Emili等人描述了通过噬菌体展示来定向进化大肠杆菌ClpS蛋白,从而产生了四种能够与天冬氨酸、精氨酸、色氨酸和亮氨酸残基的NTAA选择性结合的不同变体(美国专利第9,566,335号,所述美国专利通过引用整体并入)。在一个实施方式中,结合剂的结合部分包括参与天然N末端蛋白质识别和结合的衔接蛋白的进化保守的ClpS家族的成员或其变体。(参见例如,Schuenemann等人,(2009)EMBO Reports 10(5);Roman-Hernandez等人,(2009)PNAS 106(22):8888-93;Guo等人,(2002)JBC 277(48):46753-62;Wang等人,(2008)Molecular Cell 32:406-414)。在一些实施方式中,修饰Schuenemann等人鉴定的ClpS疏水结合袋的对应氨基酸残基,以产生具有期望的选择性的结合部分。
在一个实施方式中,结合部分包含UBR框识别序列家族的成员,或UBR框识别序列家族的变体。在以下文献中描述了UBR识别框:Tasaki等人,(2009),JBC 284(3):1884-95。例如,结合部分可包含UBR1、UBR2或其突变体、变体或同源物。
在某些实施方式中,除结合部分之外,结合剂还包含一种或多种可检测标记,例如荧光标记。在一些实施方式中,结合剂不包含多核苷酸,例如编码标签。任选地,结合剂包含合成或天然抗体。在一些实施方式中,结合剂包含适配体。在一个实施方式中,结合剂包含多肽例如ClpS衔接蛋白家族的修饰成员、例如大肠杆菌ClpS结合多肽的变体,和可检测标记。在一个实施方式中,可检测标记是光学可检测的。在一些实施方式中,可检测标记包括荧光部分、颜色编码的纳米颗粒、量子点或其任何组合。在一个实施方式中,标记包括包含型芯染料分子的聚苯乙烯染料,所述型芯染料例如FluoSphere
在一个特定实施方式中,对anticalin进行工程改造以对标记的NTAA(例如PTC、修饰的PTC、Cbz、DNP、SNP、乙酰基、胍基、氨基胍基、杂环甲亚胺等标记)具有高亲和力和高特异性。某些种类的anticalin支架由于其β桶状结构而具有适合结合单个氨基酸的形状。N末端氨基酸(无论有或没有修饰)都可能适合这个“β桶状”桶并被其识别。具有工程化新结合活性的高亲和力anticalin已有描述(Skerra,2008,FEBS J.275:2677-2683中的综述)。例如,已经工程改造了对荧光素和洋地黄毒苷具有高亲和力结合(低nM)的anticalin(Gebauer等人,2012,Methods Enzymol 503:157-188.)。用于新结合功能的替代支架的工程也已由Banta等人综述(2013,Annu.Rev.Biomed.Eng.15:93-113)。
在一些实施方式中,结合剂直接或间接地与多聚化结构域联接。因此,本文提供了包含一种或多种结合剂的单体、二聚和更高级(例如,3、4、5或更多)多聚多肽。在一些具体实施方式中,结合剂是二聚的。在一些示例中,本发明的两个多肽可以共价或非共价地彼此相连以形成二聚体。
在一些实施方式中,结合剂源自于生物的、天然存在的、非天然存在的或合成的来源。在一些示例中,结合剂源自于从头蛋白质设计(Huang等人,(2016)537(7620):320-327)。在一些示例中,结合剂具有根据第一原理设计的结构、序列和/或活性。
在一些实施方式中,可以采用选择性结合修饰的C末端氨基酸(CTAA)的结合剂。羧肽酶是切割/消除含有游离羧基基团的末端氨基酸的蛋白酶。许多羧肽酶表现出氨基酸偏好,例如,羧肽酶B优先在碱性氨基酸、例如精氨酸和赖氨酸处切割。可以修饰羧肽酶以产生选择性结合特定氨基酸的结合剂。在一些实施方式中,羧肽酶可以被工程改造以选择性地结合修饰部分以及CTAA的α-碳R基团二者。因此,工程化的羧肽酶可特异性识别20种代表C末端标记环境中的标准氨基酸的不同CTAA。通过使用仅在标记存在下才具有活性(例如,结合活性或催化活性)的工程化羧肽酶,实现了对从肽的C末端起逐步降解的控制。在一个示例中,CTAA可被对硝基苯胺或7-氨基-4-甲基香豆素基基团修饰。
可以被工程改造以产生在本文所描述的方法中使用的结合剂的其它潜在支架包含:anticalin、脂质运载蛋白、氨基酸tRNA合成酶(aaRS)、ClpS、
在一些情况下,结合剂可结合翻译后修饰的氨基酸。在一些实施方式中,内部翻译后修饰的氨基酸(例如,磷酸化、糖基化、琥珀酰化、泛素化、S-亚硝基化、甲基化、N-乙酰化、脂化等)的检测在检测和消除末端氨基酸(例如,NTAA或CTAA)之前完成。在一个示例中,将肽与针对PTM修饰的结合剂接触,并且将来自对应编码标签的信息传递到与固定的肽缔合的记录标签上。一旦与氨基酸修饰相关的信息的检测和传递完成,就可以在使用N末端或C末端降解方法检测和传递初级氨基酸序列的编码标签信息之前去除PTM修饰基团。因此,所生成的延伸核酸指示肽序列中存在的翻译后修饰,尽管不是依次顺序,以及一级氨基酸序列信息。
在一些实施方式中,内部翻译后修饰氨基酸的检测可与一级氨基酸序列的检测同时发生。在一个示例中,NTAA(或CTAA)与对翻译后修饰的氨基酸特异性的结合剂接触,所述结合剂是单独的或作为结合剂文库(例如,由20种标准氨基酸和选定的翻译后修饰的氨基酸的结合剂组成的文库)的一部分。接下来是末端氨基酸消除和与结合剂(或结合剂文库)接触的接连循环。因此,与固定的肽缔合的记录标签上生成的延伸核酸表明在一级氨基酸序列的环境下翻译后修饰的存在和顺序。
在某些实施方式中,大分子,例如多肽,也与非关联结合剂接触。如本文所用的非同源结合剂是指对与所考虑的特定靶标不同的靶标(例如,多肽特征或组分)具有选择性的结合剂。例如,如果n NTAA是苯丙氨酸,并且肽分别与对苯丙氨酸、酪氨酸和天冬酰胺具有选择性的三种结合剂接触,则对苯丙氨酸有选择性的结合剂将是能够选择性结合第n位NTAA(即苯丙氨酸)的第一结合剂,而其它两种结合剂将是该肽的非关联结合剂(因为它们对苯丙氨酸以外的NTAA有选择性)。然而,酪氨酸和天冬酰胺结合剂可以是对样品中其它肽的关联结合剂。如果然后从肽中切割出n NTAA(苯丙氨酸),从而将肽的n-1氨基酸转化为n-1NTAA(例如,酪氨酸),然后将肽与相同的三种结合剂接触,则对酪氨酸有选择性的结合剂是能够选择性结合n-1NTAA(即酪氨酸)的第二结合剂,而另外两种结合剂将是非关联结合剂(因为它们对酪氨酸以外的NTAA有选择性)。
因此,应当理解,剂是结合剂还是非关联结合剂将取决于当前可用于结合的特定多肽特征或组分的性质。此外,如果在多重反应中分析多种多肽,则一种多肽的结合剂可以是另一种多肽的非关联结合剂,反之亦然。因此,应当理解,以下关于结合剂的描述适用于本文所述的任何类型的结合剂(即关联和非关联结合剂二者)。
在某些实施方式中,控制溶液中结合剂的浓度以减少测定的背景和/或假阳性结果。在一些实施方式中,结合剂的浓度可以是任何合适的浓度,例如,为约0.0001nM、约0.001nM、约0.01nM、约0.1nM、约1nM、约2nM、约5nM、约10nM、约20nM、约50nM、约100nM、约200nM、约500nM,或约1,000nM。在其它实施方式中,所述测定中使用的可溶性缀合物的浓度在约0.0001nM和约0.001nM之间、约0.001nM和约0.01nM之间、约0.01nM和约0.1nM之间、约0.1nM和约1nM之间、约1nM和约2nM之间、约2nM和约5nM之间、约5nM和约10nM之间、约10nM和约20nM之间、约20nM和约50nM之间、约50nM和约100nM之间、约100nM和约200nM之间、约200nM和约500nM之间、约500nM和约1000nM之间,或大于约1,000nM。
在一些实施方式中,可溶性结合剂分子与固定的大分子(例如,多肽)之间的比率可以在任何合适的范围内,例如,为约0.00001:1、约0.0001:1、约0.001:1、约0.01:1、约0.1:1、约1:1、约2:1、约5:1、约10:1、约15:1、约20:1、约25:1、约30:1、约35:1、约40:1、约45:1、约50:1、约55:1、约60:1、约65:1、约70:1、约75:1、约80:1、约85:1、约90:1、约95:1、约100:1、约10
C.编码标签
所描述的结合剂包括编码标签或与编码标签相关,所述编码标签含有关于结合剂(例如,表示结合剂或与结合剂相关)的标识信息。在一些实施方式中,来自编码标签的标识信息包括关于被结合剂结合的靶标的身份的信息。在一些实施方式中,来自编码标签的标识信息包括关于被结合剂结合的肽上的一个或多个氨基酸的身份的信息或与其相关。在一些情况下,编码标签包含用于切割步骤的部分限制酶识别序列。例如,编码标签可以包含可以被双链核酸切割试剂(例如,限制酶)识别的序列(或其部分)。在一些情况下,编码标签可以包含单链序列,一旦所述单链序列是双链的,所述单链序列就可以被双链核酸切割试剂(例如,限制酶)识别。
与结合剂缔合的编码标签是或包含任何合适长度的多核苷酸,例如约2个碱基至约100个碱基的核酸分子,包括含2和100之间以及其间的任何整数,其包含其缔合的结合剂的标识信息。“编码标签”也可以由“可测序的聚合物”构成(参见例如,Niu等人,2013,Nat.Chem.5:282-292;Roy等人,2015,Nat.Commun.6:7237;Lutz,2015,Macromolecules48:4759-4767;它们各自通过引用整体并入)。编码标签可包含编码区序列或带有标识信息的序列,其任选在一侧侧接一个间隔区或任选在每侧侧接间隔区。编码标签还可包含任选的UMI和/或任选的结合循环特异性条形码。编码标签可以指直接附着于结合剂的编码标签、与直接附着于结合剂的编码标签杂交的互补序列(例如,对于双链编码标签)、或存在于记录标签上的延伸核酸中的编码标签信息。在某些实施方式中,编码标签还可包含结合循环特异性的间隔区或条形码、唯一分子标识符、通用引发位点或其任何组合。
编码标签可以是单链分子、双链分子或部分双链的。编码标签可包含平端、突出端或各一个。在一些实施方式中,编码标签是部分双链的,这防止编码标签退火到增长中的经延伸记录标签中的内部编码区和间隔区序列上。在一些实施方式中,编码标签可包括发夹结构。在某些实施方式中,发夹结构包含通过核酸链连接的相互互补的核酸区域。在一些实施方式中,核酸发夹结构也可以进一步包含从双链的茎段延伸的3'和/或5'单链区域。在一些示例中,发夹结构包含单链核酸。
在一些实施方式中,所描述的结合剂包括含有关于结合剂的标识信息的编码标签。在一些实施方式中,来自编码标签的标识信息包括关于被结合剂结合的靶标的身份的信息。在一些实施方式中,来自编码标签的标识信息包含关于结合剂结合的肽上的所述一个或多个氨基酸的身份的信息。
编码标签是约3个碱基至约100个碱基的核酸分子,其为其相关结合剂提供唯一标识信息。编码标签可包含约3至约90个碱基、约3至约80个碱基、约3至约70个碱基、约3至约60个碱基、约3个碱基至约50个碱基、约3个碱基至约40个碱基、约3个碱基至约30个碱基、约3个碱基至约20个碱基、约3个碱基至约10个碱基、或约3个碱基至约8个碱基。在一些实施方式中,编码标签的长度为约3个碱基、4个碱基、5个碱基、6个碱基、7个碱基、8个碱基、9个碱基、10个碱基、11个碱基、12个碱基、13个碱基、14个碱基、15个碱基、16个碱基、17个碱基、18个碱基、19个碱基、20个碱基、25个碱基、30个碱基、35个碱基、40个碱基、55个碱基、60个碱基、65个碱基、70个碱基、75个碱基、80个碱基、85个碱基、90个碱基、95个碱基或100个碱基。编码标签可由DNA、RNA、多核苷酸类似物或其组合构成。多核苷酸类似物包括PNA、gPNA、BNA、GNA、TNA、LNA、吗啉代多核苷酸、2'-O-甲基多核苷酸、烷基核糖基取代的多核苷酸、硫代磷酸酯多核苷酸和7-脱氮嘌呤类似物。
结合剂可以以任何合适的方式和位置附着于编码标签上,使得其不破坏所提供的方法的酶促反应(例如,核酸接合试剂、聚合酶和双链核酸切割试剂的功能)。例如,结合剂可以以任何合适的方式附着于编码标签上,只要编码标签以编码标签具有可用的3'端的方式附着。在一些特定实施方式中,编码标签具有作为3'突出端的间隔区。在一些实施方式中,结合剂在编码标签的5'端处附着于编码标签上。在一些实施方式中,结合剂在环区域处附着于编码标签上。在一些实施方式中,结合剂在位于编码标签的5'端的环附近的位置处附着于编码标签上。编码标签可以通过本领域已知的任何手段,包含共价和非共价相互作用,直接或间接地(例如,通过接头)与结合剂接合。在一些实施方式中,编码标签可以酶促或化学方式与结合剂接合。在一些实施方式中,编码标签可以通过连接法与结合剂连接合。在其它实施方式中,编码标签通过亲和结合对(例如,生物素和链霉亲和素)与结合剂接合。在一些情况下,编码标签可以与非天然氨基酸的结合剂接合,例如通过与非天然氨基酸的共价相互作用接合。
在一些实施方式中,结合剂通过SpyCatcher-SpyTag相互作用与编码标签接合。SpyTag肽通过自发的异肽键与SpyCatcher蛋白形成不可逆的共价键,从而提供了一种基因编码方式来产生抵抗力和苛刻条件的肽相互作用(Zakeri等人,2012,Proc.Natl.Acad.Sci.109:E690-697;Li等人,2014,J.Mol.Biol.426:309-317)。结合剂可表达为包含SpyCatcher蛋白的融合蛋白。在一些实施方式中,SpyCatcher蛋白附加在结合剂的N末端或C末端。SpyTag肽可以使用标准缀合化学与编码标签偶联(Hermanson,Bioconjugate Techniques,(2013)学术出版社(Academic Press))。
在一些实施方式中,使用基于酶的策略将结合剂与编码标签接合。例如,可以使用甲酰甘氨酸(FGly)生成酶(FGE)将结合剂与编码标签接合。在一个示例中,使用蛋白质、例如SpyLigase将结合剂与编码标签接合(Fierer等人,Proc Natl Acad Sci U S A.2014;111(13):E1176–E1181)。
在其它实施方式中,结合剂通过SnoopTag-SnoopCatcher肽-蛋白质相互作用与编码标签接合。SnoopTag肽与SnoopCatcher蛋白形成异肽键(Veggiani等人,Proc.Natl.Acad.Sci.USA,2016,113:1202-1207)。结合剂可表达为包含SnoopCatcher蛋白的融合蛋白。在一些实施方式中,SnoopCatcher蛋白附加在结合剂的N末端或C末端。SnoopTag肽可以使用标准缀合化学与编码标签偶联
在别的其它实施方式中,结合剂通过
在一些情况下,结合剂通过使用酶、例如分选酶介导的标记进行附着(缀合)而与编码标签接合(例如,参见Antos等人,CurrProtoc Protein Sci.(2009)第15章:15.3单元;国际专利公布第WO2013003555号)。分选酶催化转肽反应(例如,参见Falck等人,Antibodies(2018)7(4):1-19)。在一些方面,结合剂用一个或多个N末端或C末端甘氨酸残基修饰或与所述残基相连。
在一些实施方式中,使用半胱氨酸生物缀合方法将结合剂与编码标签接合。在一些实施方式中,使用π-钳介导法半胱氨酸生物缀合将结合剂与编码标签接合。(例如,参见Zhang等人,Nat Chem.(2016)8(2):120-128)。在一些情况下,使用3-芳基丙腈(APN)介导的加标签将结合剂与编码标签接合(例如Koniev等人,Bioconjug Chem.2014;25(2):202-206)。
在一些实施方式中,在结合和信息传递的循环中使用的一组编码标签可以包含循环信息,如使用循环特异性序列。在一个实施方式中,编码标签包括结合循环特异性序列。在一些实施方式中,结合剂的集合内的编码标签共有用于测定的共同间隔区序列(例如多结合循环方法中使用的整个结合剂文库在其编码标签中具有共同的间隔区)。在另一个实施方式中,编码标签包含标识特定结合循环的结合循环标记。在其它实施方式中,结合剂文库内的编码标签具有结合循环特异性的间隔区序列。在一些实施方式中,编码标签包含一个结合循环特异性间隔区序列。例如,用于第一个结合循环中的结合剂的编码标签包含“循环1”特异性间隔区序列,用于第二个结合循环中的结合剂的编码标签包含“循环2”特异性间隔区序列,依此类推直至“n”个结合循环。在其它实施方式中,用于第一个结合循环中的结合剂的编码标签包含“循环1”特异性间隔区序列和“循环2”特异性间隔区序列,用于第二个结合循环中的结合剂的编码标签包含“循环2”特异性间隔区序列和“循环3”特异性间隔区序列,依此类推直至“n”个结合循环。此实施方式可用于非串联经延伸记录标签在结合循环完成后的后续PCR组装。在一些实施方式中,间隔区序列包含足够数量的碱基以退火到记录标签或经延伸记录标签中的互补间隔区序列上,以启动引物延伸反应或粘性末端连接反应。
还可以设计循环特异性间隔区序列,使得信息传递在有条件的基础上发生。在一个示例中,第一结合循环将信息从编码标签传递到记录标签,并且后续结合循环可以以依赖于先前添加的间隔区序列的方式进行。更具体地说,用于第一个结合循环中的结合剂的编码标签包含“循环1”特异性间隔区序列和“循环2”特异性间隔区序列,用于第二个结合循环中的结合剂的编码标签包含“循环2”特异性间隔区序列和“循环3”特异性间隔区序列,依此类推直至“n”个结合循环。来自第一个结合循环的结合剂的编码标签能够通过互补的循环1特异性间隔区序列退火到记录标签上。在将编码标签信息传递到记录标签后,循环2特异性间隔区序列在结合循环1完成时位于经延伸记录标签的3'端。来自第二个结合循环的结合剂的编码标签能够通过互补的循环2特异性间隔区序列退火到经延伸记录标签上。在将编码标签信息传递到经延伸记录标签后,循环3特异性间隔区序列在结合循环2完成时位于所述经延伸记录标签的3'端,以此类推直至“n个”结合循环。该实施方式提供了在多个结合循环之中的特定结合循环中的结合信息传递将仅发生在已经历了之前结合循环的(延伸的)记录标签上。在一些情况下,如果由先前编码标签添加的间隔区与第二编码标签的间隔区的至少一部分相匹配,则信息从第二(或更高级)编码标签传递到经延伸记录标签。
在一些实施方式中,结合剂可能未能与同源大分子结合。在每个结合循环之后作为“追赶(chase)”步骤的包含结合循环特异性间隔区的寡核苷酸可以用于保持结合循环同步,即使在结合循环失败事件的情况下也是如此。例如,如果关联结合剂在结合循环1期间未能与大分子结合,则在结合循环1之后使用包含循环1特异性间隔区、循环2特异性间隔区和“无效”编码区序列的寡核苷酸来添加追赶步骤。“无效”编码区序列可以是编码区序列不存在,或优选地,正确标识“无效”结合循环的特异性条形码。“无效”寡核苷酸能够通过循环1特异性间隔区退火到记录标签上,并将循环2特异性间隔区转移到记录标签上。因此,尽管结合循环1事件失败,来自结合循环2的结合剂仍能够通过循环2特异性间隔区退火到经延伸记录标签上。“无效”寡核苷酸在经延伸记录标签内将结合循环1标记为失败结合事件。
在优选实施方式中,编码标签中使用结合循环特异性编码区序列。结合循环特异性编码区序列可通过使用完全唯一的分析物(例如,NTAA)结合循环编码区条形码或通过组合使用接合到循环特异性条形码的分析物(例如,NTAA)编码区序列来实现。使用组合方法的优点是需要设计的条形码总数较少。对于在10个循环中使用的一组20种分析物结合剂,只需要设计20个分析物编码区序列条形码和10个结合循环特异性条形码。相反,如果将结合循环直接嵌入到结合剂编码区序列中,则可能需要设计总共200个独立的编码区条形码。将结合循环信息直接嵌入编码区序列的优点是,当在纳米孔读出上采用纠错条形码时可以使编码标签的总长度最小化。使用容错条形码允许使用更容易出错的测序平台和方法进行高准确度的条形码标识,而且具有其它优点,例如分析速度快、成本较低和/或更便携的仪器。一个这样的示例是基于纳米孔的测序读出。
II.
所提供的用于分析大分子(例如,肽、多肽和蛋白质)的方法(包含使用所描述的顺序编码方法将信息传递到记录标签的步骤)可以包含另外的步骤、处理和反应。在一些实施方式中,大分子是多肽,并且进行多肽分析测定。在一些实施方式中,使用多肽分析测定来确定蛋白质的序列(或其序列的一部分)和/或同一性。在一些示例中,多肽分析测定包括使用合适的技术或程序来评估多肽的至少部分序列或同一性。例如,可以通过N末端氨基酸分析或C末端氨基酸分析来评估多肽的至少部分序列。在一些实施方式中,可以使用ProteoCode测定来评估多肽的至少部分序列。在一些示例中,可以通过应用在美国专利公开第US 20190145982 A1号、第US 20200348308 A1号、第US 20200348307A1号、第US20210208150 A1号中公开和/或要求保护的技术或程序中的一些技术或程序来评估多肽的至少部分序列。
在与分析肽或多肽的方法相关的实施方式中,所述方法通常包含使结合剂与多肽、蛋白质或肽中的至少末端氨基酸(例如,NTAA或CTAA)接触,并且在接触时,将信息从编码标签传递到与多肽、蛋白或肽缔合的记录标签,由此产生一级经延伸记录标签(编码循环)。根据本文所描述的方法的示例性编码循环示出于图1B中。如图1B中示出的结合剂通过接头附着于包括关于结合剂的标识信息(结合剂条形码,BBC)的编码标签。在一些实施方式中,结合剂可以在除了所描绘位置之外的位置(例如,在编码标签的环区域或其它位置处)附着于编码标签或与编码标签接合。为了传递BBC信息,提供了聚合酶、核酸接合试剂(如DNA连接酶)和双链核酸切割试剂(如限制酶)。这些试剂可以随后添加(一次添加一种酶,或两种酶(聚合酶和DNA连接酶),随后添加限制酶),或者作为三种酶的混合物的形式添加。在将记录标签的5'端与编码标签的3'端连接时,聚合酶延伸记录标签的3'(未连接)端以产生含有邻近其相应的限制酶位点的2-碱基对间隔区的dsDNA分子。在双链产生之后,限制酶邻近其识别位点结合和切割。切割后,记录标签上的dsDNA现在含有结合剂特异性条形码(BBC)和2nt 3'突出端,其在下一轮编码中充当间隔区序列。在一些实施方式中,在信息传递(编码)的循环之后,可以从多肽(例如,末端氨基酸或末端二肽)去除供分析的多肽的一部分。图1B中示出的步骤的循环可以用另外的结合剂和对应编码标签重复一次或多次,以进一步延伸记录标签。
在一些另外的实施方式中,所述方法包括在大分子与结合剂接触之前或之后标记或修饰大分子(例如,肽)。例如,被结合剂结合的多肽、蛋白质或肽的末端氨基酸可以是经化学标记或修饰的末端氨基酸。在一些另外的实施方式中,所述方法进一步包含在信息传递步骤之后从多肽、蛋白质或肽去除或消除末端氨基酸(例如,NTAA或CTAA)。消除的末端氨基酸可以是经化学标记或修饰的末端氨基酸。通过与酶或化学试剂接触去除NTAA将多肽、蛋白质或肽的倒数第二个氨基酸转化为末端氨基酸。多肽分析可以包含一个或多个下述循环:用另外的结合剂与末端氨基酸结合;以及将信息从编码标签传递到延伸核酸,由此产生含有关于两种或更多种结合剂的信息的更高级经延伸记录标签;以及以循环方式消除末端氨基酸。可以如上所述对n个氨基酸进行另外的结合、传递信息和去除,以产生第n级延伸核酸,所述核酸共同表示多肽、蛋白质或肽。记录标签用于记录从一种或多种结合剂与待分析的大分子之间的一个或多个结合事件收集的信息。
在任何所提供的实施方式中的一些实施方式中,在所描述的示例性方法中包含NTAA的步骤可以用C末端氨基酸(CTAA)代替进行。
在一些实施方式中,基于降解的肽或多肽测序测定过程中的步骤次序可以颠倒或以各种次序进行。例如,在一些实施方式中,末端氨基酸标记可以在多肽与结合剂结合之前和/或之后进行。
本文提供了一种用于分析大分子的方法,所述方法包括以下步骤:(a)提供大分子和与载体接合的所缔合记录标签;(b)使所述大分子与能够与所述大分子结合的结合剂接触,其中所述结合剂包括具有关于所述结合剂的标识信息的编码标签,以允许所述大分子与所述结合剂之间的结合;(c)通过核酸接合试剂将所述记录标签的5'端与所述编码标签的3'端接合;(d)使用所述编码标签作为模板通过聚合酶延伸所述记录标签,从而产生双链经延伸记录标签;以及(e)用双链核酸切割试剂切割所述双链经延伸记录标签,以产生经延伸记录标签中的3'突出端。在一些情况下,在步骤(e)之后去除结合剂。在一些实施方式中,所述方法进一步包含分析经延伸记录标签。在一些方面,所述方法进一步包含在分析经延伸记录标签之前,将通用引发位点添加到经延伸记录标签。
在一些示例中,步骤(a)在步骤(b)、(c)、(d)和(e)之前进行。步骤(c)、(d)和(e)可以根据设计的性质以逐步方式进行,但是试剂可以以混合物的形式提供。在一些实施方式中,步骤(b)在步骤(c)和步骤(d)之前进行,例如,通过首先提供核酸接合试剂,然后一起提供聚合酶和双链核酸切割试剂。在一些情况下,步骤按顺序(c)、(d)和(e)进行。在一些特定实施方式中,步骤按以下顺序进行:(a)、(b)、(c)、(d)和(e),任选地将步骤(b)、(c)、(d)和(e)重复一次或多次。
在一些实施方式中,所述方法进一步包含以下步骤:去除多肽的一部分,如多肽、蛋白质或肽的末端氨基酸(例如,N末端氨基酸(NTAA)),以暴露多肽、蛋白质或肽的新末端氨基酸。在一些情况下,在步骤(b)、(c)、(d)、(e)的第一循环之后,在去除多肽的至少一部分之后,重复步骤(b)、(c)、(d)、(e)的第二循环。
在一些实施方式中,所述方法包含用用于修饰多肽、蛋白质或肽的末端氨基酸的试剂处理靶多肽、蛋白质和肽。在一些方面中,用于修饰多肽的末端氨基酸的试剂包括化学剂或酶剂。在一些实施方式中,在步骤(b)之前,使靶多肽、蛋白质或肽与用于修饰末端氨基酸的试剂接触。在一些实施方式中,在去除末端氨基酸之前,使靶多肽、蛋白质或肽与用于修饰末端氨基酸的试剂接触。
在一些实施方式中,所述方法进一步包含在将信息从编码标签传递到记录标签之后去除结合剂。在一些方面,在步骤(e)之后去除结合剂。在一些方面,在重复步骤(b)之前去除结合剂。在一些方面,在将信息从编码标签传递到与大分子缔合的记录标签以供分析之后去除结合剂。
A.样品和大分子
在一些实施方式中,对从样品中获得的一个或多个具有未知身份的大分子进行分析测定。在一些情况下,大分子来自从样品中获得的分子的混合物。大分子可以是由较小亚基构成的大分子。在某些实施方式中,大分子是蛋白质、蛋白质复合体、多肽、肽、核酸分子、碳水化合物、脂质、大环或嵌合大分子。本文所公开的方法中的大分子(例如,蛋白质、多肽、肽)可以从任何合适的来源或样品中获得。
本文所公开的方法可以用于同时(多路复用)分析多个大分子,包含检测、鉴定、定量和/或测序。如本文所用的多路复用是指在同一测定中分析多个大分子(例如多肽)。多个大分子可以源自于相同的样品或不同的样品。多个大分子可以源自于相同的对象或不同的对象。被分析的多个大分子可以是不同的大分子,或源自于不同样品的相同大分子。多个大分子包括2或更多个大分子、5或更多个大分子、10或更多个大分子、50或更多个大分子、100或更多个大分子、500或更多个大分子、1000或更多个大分子、5,000或更多个大分子、10,000或更多个大分子、50,000或更多个大分子、100,000或更多个大分子、500,000或更多个大分子、或1,000,000或更多个大分子。
在一些实施方式中,大分子(例如,蛋白质、多肽或肽)是从作为生物样品的样品中获得的。在一些实施方式中,样品包括但不限于哺乳动物或人类细胞、酵母细胞和/或细菌细胞。在一些实施方式中,样品含有来自从多细胞生物体获得的样品中的细胞。例如,样品可以从个体中分离。在一些实施方式中,样品可包含一种细胞类型或多种细胞类型。在一些实施方式中,样品可从哺乳动物生物体或人类获得,例如通过穿刺或其它收集或取样程序获得。在一些实施方式中,样品包含两种或更多种细胞。
在一些实施方式中,生物样品可含有全细胞和/或活细胞和/或细胞碎片。在一些示例中,合适的来源或样品,可包括但不限于:生物样品,例如活检样品、细胞培养物、细胞(原代细胞和培养的细胞系)、包含细胞器或囊泡、组织和组织提取物的样品;几乎任何生物体的。例如,合适的来源或样品,可以包含但不限于:活检;粪便物;体液(如血液、全血、血清、血浆、尿液、淋巴液、胆汁、房水、母乳、耵聍(耳垢)、乳糜、食糜、内淋巴、外淋巴、渗出液、脑脊液、间质液、房水或玻璃体液、初乳、痰液、羊水、唾液、肛门和阴道分泌物、胃酸、胃液、淋巴液、粘液(包含鼻引流物和痰液)、心包液、腹膜液、胸膜液、脓液、稀粘液、唾液、皮脂(皮肤油)、痰、滑液、汗液和精液、漏出液、呕吐物及其一种或多种的混合物、渗出液(例如,从脓肿或任何其它感染或炎症位点获得的流体)或从几乎任何生物体的关节(正常关节或受疾病如类风湿性关节炎、骨关节炎、痛风或化脓性关节炎影响的关节)获得的流体,其中哺乳动物来源的样品,包含含微生物组的样品是优选的,而人类来源的样品、包含含微生物组的样品是特别优选的;环境样品(如空气、农业、水和土壤样品);微生物样品,包含源自于微生物生物膜和/或群落以及微生物孢子的样品;组织样品,包含组织切片;研究样品,包含细胞外液、来自细胞培养物的细胞外上清液、细菌中的包涵体、细胞组分,包含线粒体和细胞周质。在一些实施方式中,生物样品包含体液或来源于体液,其中体液从哺乳动物或人类获得。在一些实施方式中,样品包括体液,或来自体液的细胞培养物。
在一些实施方式中,可以从一种细胞类型或多种细胞类型获得和制备大分子(例如,多肽和蛋白质)。在一些实施方式中,样品包含细胞群。在一些实施方式中,大分子(例如,蛋白质、多肽或肽)来自细胞或亚细胞组分、细胞外囊泡、细胞器或其有组织的亚组分。大分子(例如蛋白质、多肽或肽)可来自细胞器,例如线粒体、细胞核或细胞囊泡。在一个实施方式中,可分离一种或多种特定类型的单细胞或其亚型。在一些实施方式中,样品可包括但不限于细胞器(例如,细胞核、高尔基体、核糖体、线粒体、内质网、叶绿体、细胞膜、囊泡等)。
在某些实施方式中,大分子是或包括蛋白质、蛋白质复合体、多肽或肽。肽、多肽或蛋白质的氨基酸序列信息和翻译后修饰被转导到核酸编码文库中,可以通过下一代测序方法对所述文库进行分析。肽可包含L-氨基酸、D-氨基酸或两者。肽、多肽、蛋白质或蛋白质复合体可包含标准的、天然存在的氨基酸、修饰的氨基酸(例如,翻译后修饰)、氨基酸类似物、氨基酸模拟物或其任何组合。在一些实施方式中,肽、多肽或蛋白质是天然存在的、合成产生的或重组表达的。在任何前述的肽实施方式中,肽、多肽、蛋白质或蛋白质复合体可进一步包含翻译后修饰。标准的天然存在氨基酸包括丙氨酸(A或Ala)、半胱氨酸(C或Cys)、天冬氨酸(D或Asp)、谷氨酸(E或Glu)、苯丙氨酸(F或Phe)、甘氨酸(G或Gly)、组氨酸(H或His)、异亮氨酸(I或Ile)、赖氨酸(K或Lys)、亮氨酸(L或Leu)、甲硫氨酸(M或Met)、天冬酰胺(N或Asn)、脯氨酸(P或Pro)、谷氨酰胺(Q或Gln)、精氨酸(R或Arg)、丝氨酸(S或Ser)、苏氨酸(T或Thr)、缬氨酸(V或Val)、色氨酸(W或Trp)、和酪氨酸(Y或Tyr)。非标准氨基酸包括硒半胱氨酸、吡咯赖氨酸和N-甲酰甲硫氨酸、β-氨基酸、高氨基酸、脯氨酸和丙酮酸衍生物、3-取代丙氨酸衍生物、甘氨酸衍生物、环-取代的苯丙氨酸和酪氨酸衍生物、线性核心氨基酸、N-甲基氨基酸。
肽、多肽或蛋白质的翻译后修饰(PTM)可以是共价修饰或酶促修饰。翻译后修饰的例子包括但不限于酰化、乙酰化、烷基化(包括甲基化)、生物素化、丁酰化、氨甲酰化、羰基化、脱酰胺化、脱亚胺化、白喉酰胺形成、二硫桥键形成、消去化、黄素连接、甲酰化、γ-羧基化、谷氨酰化、甘氨酰化、糖基化(例如,N-连接,O-连接的糖基化、C-连接的糖基化、磷酸糖基化)、糖基磷脂酰肌醇化、血红素C连接、羟基化、羟腐氨酸形成、碘化、异戊二烯化、脂化、脂酰化、丙二酰化、甲基化、肉豆蔻酰化、氧化、棕榈酰化、PEG化、磷酸泛酰巯基乙胺化、磷酸化、异戊二烯化、丙酰化、亚视黄亚基席夫碱形成、S-谷胱甘肽化、S-亚硝基化、S-亚磺酰化、硒化、琥珀酰化、亚磺化、泛素化和C末端酰胺化。翻译后修饰包括肽、多肽或蛋白质的氨基端和/或羧基端的修饰。末端氨基的修饰包括但不限于脱氨基、N-低级烷基、N-二低级烷基和N-酰基修饰。末端羧基的修饰包含但不限于酰胺、低级烷基酰胺、二烷基酰胺和低级烷基酯修饰(例如,其中低级烷基是C
在某些实施方式中,肽、多肽或蛋白质可以是片段化的。肽、多肽或蛋白质可以通过本领域已知的任何手段进行片段化,包括通过蛋白酶或内肽酶进行片段化。在一些实施方式中,通过使用特异性蛋白酶或内肽酶来靶向肽、多肽或蛋白质的片段化。特异性蛋白酶或内肽酶结合并在特定共有序列处切割(例如,TEV蛋白酶)。在其它实施方式中,通过使用非特异性蛋白酶或内肽酶,肽、多肽或蛋白质的片段化是非靶向的或随机的。非特异性蛋白酶可在特定的氨基酸残基而不是共有序列处结合和切割(例如,蛋白酶K是非特异性丝氨酸蛋白酶)。在一些实施方式中,蛋白酶和内肽酶,例如本领域已知的那些,可以用于将蛋白质或多肽切割成较小的肽片段,所述酶包括蛋白酶K、胰蛋白酶、胰凝乳蛋白酶、胃蛋白酶、嗜热菌蛋白酶、凝血酶、因子Xa、弗林蛋白酶、内肽酶、木瓜蛋白酶、胃蛋白酶、枯草杆菌蛋白酶、弹性蛋白酶、肠激酶、Genenase
化学试剂也可以用于将蛋白质消化成肽片段。化学试剂可在特定的氨基酸残基处切割(例如,溴化氰水解蛋氨酸残基C末端的肽键)。用于将多肽或蛋白质片段化成较小的肽的化学试剂包括溴化氰(CNBr)、羟胺、肼、甲酸、BNPS-粪臭素[2-(2-硝基苯基亚硫基)-3-甲基吲哚]、碘代苯甲酸、NTCB+Ni(2-硝基-5-硫氰基苯甲酸)等。
在某些实施方式中,在酶促或化学切割之后,所生成的肽片段具有大致相同的期望长度,例如,约10个氨基酸至约70个氨基酸、约10个氨基酸至约60个氨基酸、约10个氨基酸至约50个氨基酸、约10至约40个氨基酸、约10至约30个氨基酸、约20个氨基酸至约70个氨基酸、约20个氨基酸至约60个氨基酸、约20个氨基酸至约50个氨基酸、约20至约40个氨基酸、约20至约30个氨基酸、约30个氨基酸至约70个氨基酸、约30个氨基酸至约60个氨基酸、约30个氨基酸至约50个氨基酸、或约30个氨基酸至约40个氨基酸。可通过向蛋白质或多肽样品掺入包含含有蛋白酶或内肽酶切割位点的肽序列的短测试FRET(荧光共振能量传递)肽来监测、优选实时监测切割反应。在完好的FRET肽中,荧光基团和猝灭基团附着在所述含有切割位点的肽序列的任一端,并且猝灭剂和荧光团之间的荧光共振能量传递导致低荧光。在蛋白酶或内肽酶切割测试肽后,猝灭剂和荧光团分离,使荧光大大增加。当达到一定的荧光强度时可以停止切割反应,从而实现可重现的切割终点。
在一些方面,大分子(例如,肽、多肽或蛋白质)的样品可以经历蛋白质分级分离方法,其中通过一种或多种性质(如细胞位置、分子量、疏水性、等电点或蛋白质富集方法)来分离蛋白质或肽。在一些实施方式中,对样品内的大分子子集(例如蛋白质)进行分级分离,使得从样品的其余部分中分选出大分子子集。例如,样品可以在附着到载体之前经历分级分离方法。可替代地或另外,可以使用蛋白质富集方法来选择特定的蛋白质或肽(参见例如,Whiteaker等人,2007,Anal.Biochem.362:44-54,所述文献通过引用整体并入)或选择特定的翻译后修饰(参见例如,Huang等人,2014.J.Chromatogr.A 1372:1-17,所述文献通过引用整体并入)。可替代地,特定类别的蛋白质例如免疫球蛋白、或免疫球蛋白(Ig)同种型例如IgG可以被亲和富集或选择用于分析。在免疫球蛋白分子的情况下,对参与亲和结合的高变序列的序列和丰度或频度的分析是特别令人感兴趣的,特别是因为它们响应疾病进展而变化或与健康、免疫和/或疾病表型相关。也可以使用标准免疫亲和方法从样品中去除过度丰富的蛋白质。对于超过80%的蛋白质成分是白蛋白和免疫球蛋白的血浆样品,去除丰富的蛋白质可能是有用的。有几种商业产品可用于去除血浆样品的过度丰富的蛋白质,包括去除前2-20种血浆蛋白的去除离心柱(Pierce,Agilent),或PROTIA和PROT20(Sigma-Aldrich)。
在某些实施方式中,可以通过使用标准分级方法(包含电泳和液相色谱)分级分离蛋白质样品(Zhou等人,2012,Anal Chem 84(2):720-734)或将级分分区到装载有有限容量的蛋白质结合珠粒/树脂(例如,羟基化二氧化硅颗粒)的区室(例如,液滴)(McCormick,1989,Anal Biochem 181(1):66-74)和洗脱结合蛋白来调节蛋白质样品动态范围。每个被区室化的级分中的过量蛋白质被洗掉。电泳方法的例子包括毛细管电泳(CE)、毛细管等电聚焦(CIEF)、毛细管等速电泳(CITP)、自由流动电泳、凝胶洗脱液体级分截留电泳(GELFrEE)。液相色谱蛋白质分离方法的例子包含反相(RP)、离子交换(IE)、尺寸排阻(SE)、亲水相互作用等。区室分区的例子包含乳液、液滴、微孔、平坦基体上的物理分离的区域等。示例性蛋白质结合珠粒/树脂包含用酚基或羟基衍生的二氧化硅纳米颗粒(例如,来自安捷伦科技公司(Agilent Technologies)的StrataClean树脂、来自LabTech公司(LabTech)的RapidClean等)。通过限制珠/树脂的结合容量,在给定级分中洗脱的高度丰富的蛋白质将仅部分结合到珠粒上,多余的蛋白质被去除。
在一些实施方式中,使用分区条形码,包括将唯一条形码分配给来自样品内的大分子群体二次取样的大分子。该分区条形码可包含通过分隔标有相同条形码的区室(例如带有条形码的珠群,其中多个珠粒共用相同的条形码)内的大分子而产生的相同条形码。物理区室的使用有效地对原始样品进行二次取样,以提供分区条形码的分配。例如,提供一组标有10,000个不同区室条形码的珠粒。此外,假设在给定的测定中,共100万个珠粒用于该测定。平均而言,每个区室条形码有100个珠粒(泊松分布)。进一步假设所述珠粒捕获了总共1000万个大分子。平均而言,每个珠粒有10个大分子,每个区室条形码有100个区室,每个分区条形码有效地有1,000个大分子(包含100个不同物理区室的100个区室条形码)。
在另一个实施方式中,对多肽的单分子进行分区和加分区条形码是通过在N或C末端或两端用可扩增的DNA UMI标签(例如,记录标签)(化学或酶法)标记多肽来实现的。DNADNA标签通过对反应性氨基酸如赖氨酸的非特异性光标记或特异性化学附着而附着在多肽的主体(内部氨基酸)上。来自附着于肽末端的记录标签的信息通过酶乳液PCR或乳液体外转录/逆转录(IVT/RT)步骤传递到DNA标签(Williams等人,Nat Methods,(2006)3(7):545-550;Schutze等人,Anal Biochem.(2011)410(1):155-157)。在优选的实施方式中,使用纳米乳液,使得平均而言,每个尺寸为50nm-1000nm的乳液微滴有少于单个多肽(Nishikawa等人,J Nucleic Acids.(2012)2012:923214;Gupta等人,Soft Matter.(2016)12(11):2826-41;Sole等人,Langmuir(2006,22(20):8326-8332)。此外,PCR的所有组分都包含在包括引物、dNTP、Mg2+、聚合酶和PCR缓冲液的水性乳液混合物。如果使用IVT/RT,则设计记录标签具有T7/SP6 RNA聚合酶启动子序列,以产生与附着于多肽主体上的DNA标签杂交的转录本(Ryckelynck等人,RNA.(2015)21(3):458-469)。逆转录酶(RT)将信息从所述杂交的RNA分子复制到所述DNA标签上。以这种方式,乳液PCR或IVT/RT可以用于有效地将信息从末端记录标签传递到附着于多肽主体上的多个DNA标签上。
在一些实施方式中,大分子靶标(例如,肽、多肽或蛋白质)的样品可以被处理到物理区域或体积中,例如,处理到区室中。可以对样品进行各种处理和/或标记步骤。在一些实施方式中,区室从大分子样品中隔离或分离出大分子的子集。在一些示例中,区室可以是水性区室(例如,微流体液滴)、固体区室(例如,板、管、小瓶、珠粒上的皮克量滴定孔或微量滴定孔)或表面上的分离区域。在一些情况下,区室可包括一个或多个可固定大分子的珠粒。在一些实施方式中,区室中的大分子用区室标签包括条形码进行标记。例如,一个区室中的大分子可以用相同的条形码标记,或多个区室中的大分子可以用相同的条形码标记。例如,参见Valihrach等人,Int J Mol Sci.2018Mar 11;19(3).pii:E807。通过在珠粒中的凝胶化来封装细胞内容物是对单细胞分析的有用方法(Tamminen等人,Front Microbiol(2015)6:195;Spencer等人,ISME J(2016)10(2):427-436)。单细胞液滴标条形码使来自单个细胞中的所有组分都能够用相同的标识符进行标记(Klein等人,Cell(2015)161(5):1187-1201;Zilionis等人,Nat Protoc(2017)12(1):44-73;国际专利公布第WO 2016/130704号)。区室标条形码可以通过多种方式完成,包括通过液滴接合将唯一条形码直接并入每个液滴中(Bio-Rad Laboratories)、通过将带条形码的珠粒引入液滴中(10X Genomics)、或通过如Gunderson等人所述使用并标记split-pool组合条形码对液滴封装和凝胶化后的组分标组合条形码(国际专利公布No.WO 2016/130704,通过引用整体并入)。类似的组合标记方案也可以应用于细胞核(Vitak等人,Nat Methods(2017)14(3):302-308)。
在一些实施方式中,大分子在与结合剂接触之前与载体接合。在一些情况下,令人期望的是,使用具有大承载能力的载体来固定样品中的大量大分子。在一些实施方式中,优选使用三维载体(例如,多孔基质或珠粒)来固定大分子。在一些示例中,制备包含在固定大分子之前或之后,将大分子与核酸分子或寡核苷酸接合。在一些实施方式中,多个大分子在与结合剂接触之前附着于载体上。
载体可以是任何固体或多孔载体,包括但不限于珠粒、微珠、阵列、玻璃表面、硅表面、塑料表面、过滤器、膜、PTFE膜、尼龙、微量滴定孔、ELISA板、干涉测量转盘、硝化纤维素膜、基于硝化纤维素的聚合物表面、纳米颗粒或微球。载体的材料包括但不限于丙烯酰胺、琼脂糖、纤维素、葡聚糖、硝化纤维素、玻璃、金、石英、聚苯乙烯、聚乙烯乙酸乙烯酯、聚丙烯、聚酯、聚甲基丙烯酸酯、聚丙烯酸酯、聚乙烯、聚环氧乙烷、聚硅酸盐、聚碳酸酯、聚乙烯醇(PVA)、特氟隆、氟碳化合物、尼龙、硅橡胶、二氧化硅、聚酐、聚乙醇酸、聚氯乙烯、聚乳酸、聚原酸酯、官能化硅烷、聚富马酸丙酯、胶原蛋白、糖胺聚糖、聚氨基酸或其任何组合。在某些实施方式中,载体是珠粒,例如聚苯乙烯珠、聚合物珠、聚丙烯酸酯珠、琼脂糖珠、纤维素珠、葡聚糖珠、丙烯酰胺珠、实心珠、多孔珠、顺磁珠、玻璃珠、基于二氧化硅的珠或可控孔度珠,或其任何组合。在一些具体实施方式中,载体是多孔琼脂糖珠。
在一些实施方式中,所述载体可包含任何合适的固体材料,包括多孔和无孔材料,大分子例如多肽可以通过本领域已知的任何手段、包括共价和非共价相互作用或其任何组合直接或间接地与其缔合。载体可以是二维的(例如,平面表面)或三维的(例如,凝胶基质或珠粒)。载体可以是任何载体表面,包括但不限于珠粒、微珠、阵列、玻璃表面、硅表面、塑料表面、过滤器、膜、PTFE膜、PTFE膜、硝化纤维素膜、基于硝化纤维素的聚合物表面、尼龙、微量滴定孔、ELISA板、干涉测量转盘、聚合物基质、纳米颗粒或微球。载体的材料包括但不限于丙烯酰胺、琼脂糖、纤维素、葡聚糖、硝化纤维素、玻璃、金、石英、聚苯乙烯、聚乙烯乙酸乙烯酯、聚丙烯、聚酯、聚甲基丙烯酸酯、聚丙烯酸酯、聚乙烯、聚环氧乙烷、聚硅酸盐、聚碳酸酯、聚乙烯醇(PVA)、特氟隆、氟碳化合物、尼龙、硅橡胶、聚酐、聚乙醇酸、聚氯乙烯、聚乳酸、聚原酸酯、官能化硅烷、聚富马酸丙酯、胶原蛋白、糖胺聚糖、聚氨基酸、葡聚糖或其任何组合。载体还包括薄膜、膜、瓶子、碟、纤维、编织纤维、成型聚合物如管子、颗粒、珠粒、微球、微粒或其任何组合。例如,当固体表面是珠粒时,珠粒可以包括但不限于陶瓷珠、聚苯乙烯珠、聚合物珠、聚丙烯酸酯珠、甲基苯乙烯珠、琼脂糖珠、纤维素珠、葡聚糖珠、丙烯酰胺珠、实心珠、多孔珠、顺磁珠、玻璃珠或可控孔度珠、基于二氧化硅发珠、或其任何组合。珠粒可以是球形或不规则形状的。珠粒或载体可以是多孔的。珠粒的大小可以在纳米(例如,100nm)至毫米(例如,1mm)的范围内。在某些实施方式中,珠粒的大小在约0.2微米至约200微米或约0.5微米至约5微米的范围内。在一些实施方式中,珠粒的直径可以为约1、1.5、2、2.5、2.8、3、3.5、4、4.5、5、5.5、6、6.5、7、7.5、8、8.5、9、9.5、10、10.5、15或20μm。在某些实施方式中,“珠粒”载体可指单个珠粒或多个珠粒。在一些实施方式中,所述固体表面是纳米颗粒。在某些实施方式中,纳米颗粒的尺寸范围从直径约1nm至约500nm,例如,直径在约1nm和约20nm之间、约1nm和约50nm之间、约1nm和约100nm之间、约10nm和约50nm之间、约10nm和约100nm之间、约10nm和约200nm之间、约50nm和约100nm之间、约50nm和约150之间、约50nm和约200nm之间、约100nm和约200nm之间、或约200nm和约500之间。在一些实施方式中,纳米颗粒的直径可以为约10nm、约50nm、约100nm、约150nm、约200nm、约300nm或约500nm。在一些实施方式中,纳米颗粒的直径小于约200nm。
可以使用各种反应来将大分子附着于载体(例如,固体或多孔载体)上。大分子可以直接或间接地附着于载体上。在一些情况下,大分子通过核酸附着于载体上。示例性的反应包括叠氮化物和炔烃形成三唑的铜催化反应(Huisgen 1,3-偶极环加成)、应变促进的叠氮化物炔烃环加成(SPAAC)、二烯和亲双烯体的反应(Diels-Alder)、应变促进的炔烃-硝酮环加成、应变烯烃与叠氮化物、四嗪或四唑的反应、烯烃和叠氮化物[3+2]环加成、烯烃和四嗪逆电子需求(inverse electron demand)Diels-Alder(IEDDA)反应(例如,间四嗪(mTet)或苯基四嗪(pTet)和反式环辛烯(TCO);或pTet和烯烃)、烯烃和四唑的光致反应、叠氮化物和膦的Staudinger连接、以及各种置换反应,例如通过亲核攻击置换亲电原子上的离去基团(Horisawa 2014,Knall,Hollauf等人2014)。示例性的置换反应包括胺与以下物质的反应:活化酯;N-羟基琥珀酰亚胺酯;异氰酸酯;异硫氰酸酯、醛、环氧化物等。在一些实施方式中,iEDDA点击化学用于将大分子(例如,多肽)固定到载体上,因为它快速并且在低输入浓度下提供高产率。在另一个实施方式中,iEDDA点击化学反应中使用间四嗪而不是四嗪,因为间四嗪具有改善的键稳定性。在另一个实施方式中,在iEDDA点击化学反应中使用苯基四嗪(pTet)。在一种情况下,用双官能的点击化学试剂、例如炔烃-NHS酯(乙炔-PEG-NHS酯)试剂或炔烃-二苯甲酮标记多肽,生成炔烃标记的多肽。在一些实施方式中,炔烃也可以是应变炔烃,如环辛炔,包括二苯并环辛基(DBCO)等。
在多个大分子固定在同一载体上的某些实施方式中,大分子可以被适当地间隔开以适应待用于评估靶标的分析步骤。例如,最佳地间隔开大分子对于使用于评估和测序蛋白质的基于核酸的方法进行可能是有利的。在一些情况下,载体上的大分子的间距是基于以下考虑来确定的:从与和一个固定的大分子结合的结合剂的编码标签杂交的衔接分子的信息传递可以到达相邻大分子。
在一些实施方式中,载体的表面被钝化(封闭)。“钝化的”表面是指已经用外材料层处理过的表面。钝化表面的方法包含来自荧光单分子分析文献的标准方法,所述方法包含用以下聚合物使表面钝化:如聚乙二醇(PEG)(Pan等人,2015,Phys.Biol.12:045006)、聚硅氧烷(例如,Pluronic F-127)、星形聚合物(例如,星形PEG)(Groll等人,2010,MethodsEnzymol.472:1-18)、疏水性二氯二甲基硅烷(DDS)+自组装Tween-20(Hua等人,2014,Nat.Methods 11:1233-1236)、类金刚石碳(DLC)、DLC+PEG(Stavis等人,2011,Proc.Natl.Acad.Sci.USA 108:983-988)和两性离子部分(例如,美国专利申请公开US2006/0183863)。除共价表面改性外,也可以使用许多钝化剂,包括表面活性剂如Tween-20、溶液中的聚硅氧烷(Pluronic系列)、聚乙烯醇(PVA)以及蛋白质如BSA和酪蛋白。可替代地,当将蛋白质、多肽或肽固定到固体基体上时,可以通过掺入竞争剂或“假”反应分子,来滴定固体基体的表面上或体积内大分子(例如,蛋白质、多肽或肽)的密度。
为了控制载体上固定的靶标的间距,可以在基体表面上滴定用于附着靶标的官能偶联基团(例如,TCO或羧基(COOH))的密度。在一些实施方式中,多个靶分子(例如,大分子)在载体的表面上或体积(例如,多孔载体)内间隔开,使得相邻分子以以下距离间隔开:约50nm至约500nm或约50nm至约400nm或约50nm至约300nm或约50nm至约200nm或约50nm至约100nm。在一些实施方式中,多个分子在载体表面上间隔的平均距离为至少50nm、至少60nm、至少70nm、至少80nm、至少90nm、至少100nm、至少150nm、至少200nm、至少250nm、至少300nm、至少350nm、至少400nm、至少450nm、或至少500nm。在一些实施方式中,多个分子在载体表面上间隔的平均距离为至少50nm。在一些实施方式中,分子在载体的表面上或体积内间隔开,使得根据经验,分子间事件比分子内事件(例如信息传递)的相对频率<1:10;<1:100;<1:1,000;或<1:10,000。
在一些实施方式中,多个大分子偶联在载体上,两个相邻分子之间间隔的平均距离范围为约50至100nm、约50至250nm、约50至500nm、约50至750nm、约50至1,000nm、约50至1,500nm、约50至2,000nm、约100至250nm、约100至500nm、约200至500nm、约300至500nm、约100至1000nm、约500至600nm、约500至700nm、约500至800nm、约500至900nm、约500至1,000nm、约500至2,000nm、约500至5,000nm、约1,000至5,000nm、或约3,000至5,000nm。
在一些实施方式中,载体上大分子的适当间距是通过滴定基体表面上可用的附着分子的比率来实现的。在一些示例中,基体表面(例如,珠粒表面)用羧基基团(COOH)官能化,然后用活化剂(例如,活化剂是EDC和Sulfo-NHS)处理。在一些示例中,基体表面(例如,珠粒表面)包含NHS部分。在一些实施方式中,向活化的珠粒添加mPEG
B.切割
在一些实施方式中,所提供的方法进一步包含在信息传递后去除大分子的一部分。大分子的一部分的去除暴露了供分析的大分子的新部分,例如,可用于通过在下一个分析循环中提供的结合剂结合。如果多肽正在被分析,则所述方法可以包含去除包含一个或多个氨基酸(例如,末端氨基酸)的多肽的一部分。在与使用基于降解的方法分析肽或多肽的方法相关的实施方式中,在第一结合剂与具有n个氨基酸的肽的n NTAA接触并结合,并且将编码标签信息传递到与肽缔合的核酸,由此产生一级延伸核酸(例如,在记录标签上)后,n NTAA被消除。通过与酶或化学试剂接触去除n标记的NTAA,将肽的n-1氨基酸转化为N末端氨基酸,其在本文中称为n-1NTAA。第二结合剂与肽或多肽接触并与n-1NTAA结合,并且将第二结合剂的信息从编码标签传递到一级延伸核酸,由此产生二级延伸核酸(例如,用于产生表示肽的串联的第n级延伸核酸)。消除n-1标记的NTAA将肽或多肽的n-2氨基酸转化为N末端氨基酸,其在本文中称为n-2NTAA。可以如上所述对至多n个氨基酸进行另外的结合、传递信息和去除,以产生第n
在与分析肽或多肽相关的某些实施方式中,从肽或多肽去除或切割末端氨基酸以暴露新末端氨基酸。用于去除的多肽的一部分可以是多肽的标记的(例如,经化学标记或修饰的)部分。在一些实施方式中,末端氨基酸是NTAA。在其它实施方式中,末端氨基酸是CTAA。末端氨基酸的切割可以通过许多已知的技术、包括化学切割和酶切割来完成。在一些实施方式中,使用催化对经标记的(例如,经化学标记或修饰的)N末端氨基酸的去除的经工程化的酶或促进所述去除的试剂。在一些实施方式中,使用如在国际专利公开第WO 2019/089846号和国际专利申请第PCT/US2020/29969号和第PCT/US2020/24521号中描述的方法中的任何方法来去除或消除末端氨基酸。
在一些实施方式中,用于去除末端氨基酸的试剂包含羧肽酶或氨肽酶或其变体、突变体或经修饰的蛋白质;水解酶或其变体、突变体或经修饰的蛋白质;温和Edman降解试剂;Edmanase酶;无水TFA,碱;或其任何组合。在一些实施方式中,温和Edman降解使用二氯或一氯酸;温和Edman降解使用TFA、TCA或DCA;或温和Edman降解使用三乙胺、三乙醇胺或三乙基乙酸铵(Et
在一些情况下,去除氨基酸的试剂包括碱。在一些实施方式中,碱是氢氧化物、烷基化胺、环胺、碳酸盐缓冲液、磷酸三钠缓冲液或金属盐。在一些示例中,氢氧化物是氢氧化钠;烷基化胺选自甲胺、乙胺、丙胺、二甲胺、二乙胺、二丙胺、三甲胺、三乙胺、三丙胺、环己胺、苄胺、苯胺、二苯胺、N,N-二异丙基乙胺(DIPEA)、和二异丙基氨基锂(LDA);环胺选自吡啶、嘧啶、咪唑、吡咯、吲哚、哌啶、吡咯烷、1,8-二氮杂双环[5.4.0]十一碳-7-烯(DBU)、和1,5-二氮杂双环[4.3.0]壬-5-烯(DBN);碳酸盐缓冲液包括碳酸钠、碳酸钾、碳酸钙、碳酸氢钠、碳酸氢钾或碳酸氢钙;金属盐包括银;或金属盐是AgClO
在一些实施方式中,如果N末端氨基酸被如PTC、经修饰的PTC、Cbz、DNP、SNP、乙酰基、胍基、二杂环甲亚胺等基团修饰,则所提供的方法包含对N末端氨基酸进行切割。NTAA的酶促切割可以通过氨肽酶或其它肽酶来完成。氨肽酶天然作为单体和多聚体酶存在,并且可以是金属或ATP依赖性的。天然氨肽酶具有非常有限的特异性,并且通常以连续方式切割N末端氨基酸,一个接一个地切割氨基酸。对于在此描述的方法,氨肽酶(例如,金属酶氨肽酶)可被工程改造成只有在用N末端标记修饰时才具有对NTAA的特异性结合或催化活性。以这种方式,氨肽酶一次只从N末端切割单个氨基酸,并允许控制降解循环。在一些实施方式中,修饰的氨肽酶对氨基酸残基身份没有选择性,而对N末端标记是选择性的。在其它实施方式中,修饰的氨肽酶对氨基酸残基身份和N末端标记均有选择性。结合并切割单个标记的(生物素化)NTAA或其小基团的工程化氨肽酶突变体已有描述(参见,PCT公布第WO2010/065322号)。
已经描述了结合并切割单个或一小组标记的(生物素化)NTAA的工程化氨肽酶突变体(参见PCT公开第WO2010/065322号,所述文献通过引用整体并入)。氨肽酶是从蛋白质或肽的N末端切割氨基酸的酶。天然氨肽酶具有非常有限的特异性,并且通常以连续方式消除N末端氨基酸,一个接一个地切割氨基酸(Kishor等人,2015,Anal.Biochem.488:6-8)。然而,已鉴定了残基特异性氨肽酶(Eriquez等人,J.Clin.Microbiol.1980,12:667-71;Wilce等人,1998,Proc.Natl.Acad.Sci.USA 95:3472-3477;Liao等人,2004,Prot.Sci.13:1802-10)。通过使用仅在标记存在下才具有活性(例如,结合活性或催化活性)的工程化氨肽酶,可实现对肽的N末端的逐步降解的控制。在某些实施方式中,氨肽酶可被工程改造为非特异性的,使其不会选择性识别一种特定的氨基酸胜过其它,而是只识别标记的N末端。在又一个实施方式中,循环切割是通过使用工程化酰基肽水解酶(APH)切割乙酰化NTAA而达成的。在又一个实施方式中,采用NTAA的酰胺化(胍基化)来实现使用NaOH温和切割标记的NTAA(Hamada,(2016)Bioorg MedChem Lett 26(7):1690-1695)。
在一些实施方式中,所述方法进一步包括在步骤(b)之前,在适合切割N末端脯氨酸的条件下使多肽与脯氨酸氨肽酶接触。在一些示例中,脯氨酸氨肽酶(PAP)是能够从多肽中特异性切割N末端脯氨酸的酶。切割N末端脯氨酸的PAP酶也被称为脯氨酸亚氨肽酶(PIP)。已知的单体PAP包含来自凝结芽孢杆菌(B.coagulans)、德氏乳杆菌(L.delbrueckii)、脑膜炎奈瑟菌(N.gonorrhoeae)、脑膜炎黄杆菌(F.meningosepticum)、粘质沙雷氏菌(S.marcescens)、嗜酸热原体菌(T.acidophilum)、植物乳杆菌(L.plantarum)的家族成员(MEROPS S33.001)(Nakajima等人,J Bacteriol.(2006)188(4):1599-606;Kitazono等人,Bacteriol(1992)174(24):7919-7925)。已知的多聚体PAP包含汉斯德巴氏酵母菌(D.hansenii)(Bolumar等人,(2003)86(1-2):141-151)和来自其它物种的类似同源物(Basten等人,Mol Genet Genomics(2005)272(6):673-679)。可以采用PAP的天然或工程化变体/突变体。
对于涉及CTAA结合剂的实施方式,从肽或多肽中切割CTAA的方法也是本领域已知的。例如,美国专利6,046,053公开了一种将肽或蛋白质与烷基酸酐反应以将羧基端转化为恶唑酮、通过与酸和醇或与酯反应释放C末端氨基酸的方法。CTAA的酶切割也可通过羧肽酶完成。几种羧肽酶表现出氨基酸偏好,例如,羧肽酶B优先在碱性氨基酸、例如精氨酸和赖氨酸处切割。如上所述,羧肽酶也可按与氨肽酶相同的方式进行修饰,以工程改造与具有C末端标记的CTAA特异性结合的羧肽酶。以这种方式,羧肽酶一次只从C末端切割单个氨基酸,并允许控制降解循环。在一些实施方式中,修饰的羧肽酶对氨基酸残基身份没有选择性,而对N末端标记是选择性的。在其它实施方式中,修饰的羧肽酶对氨基酸残基身份和C标记均有选择性。
C.分析
在一些实施方式中,通过执行所提供的方法产生的经延伸记录标签包括从一个或多个编码标签传递的信息。在一些实施方式中,经延伸记录标签包括从多个编码标签传递的指示结合剂的结合顺序的一系列信息。此经延伸记录标签可以通过任何合适的方法来分析。在一些实施方式中,在确定经延伸记录标签中的编码标签的至少序列之前,扩增经延伸记录标签(或其一部分)。在一些实施方式中,在确定经延伸记录标签中的编码标签的至少序列之前,释放经延伸记录标签(或其一部分)。
通过本文所描述的方法产生的最终经延伸记录标签的长度取决于多种因素,包含编码标签(例如,条形码和间隔区)的长度、核酸的长度(例如,任选地包含任何唯一分子标识符、间隔区、通用引发位点、条形码或其组合)。在将最终标签信息传递到延伸核酸(例如,来自任何编码标签)之后,可以通过经由连接、引物延伸或本领域已知的其它方法添加通用反向引发位点来对标签进行加帽。在一些实施方式中,核酸中的通用正向引发位点(例如,在记录标签上)与附加到最终的延伸核酸的通用反向引发位点相容。在一些实施方式中,通用反向引发位点是Illumina P7引物和Illumina P5引物。取决于来自编码标签的标识信息被传递到的核酸的链意义,可附加正义或反义P7。延伸核酸文库可以直接从载体(例如,珠粒)上切割或扩增,并且用于传统的下一代测序测定和方案。
在一些实施方式中,对单链延伸核酸(例如,在记录标签上延伸)的文库进行引物延伸反应以复制其互补链。在一些实施方式中,肽测序测定(例如,ProteoCode测定),以循环的进程包括几个化学和酶促步骤。
延伸核酸记录标签可以使用各种核酸测序方法进行处理和分析。在一些实施方式中,处理和分析含有来自一个或多个编码标签和任何其它核酸组分的信息的经延伸记录标签。在一些实施方式中,经延伸记录标签的集合可以串联。在一些实施方式中,经延伸记录标签可以在确定序列之前扩增。
测序方法的例子包括但不限于:链终止测序(Sanger测序);下一代测序方法,例如合成测序、连接测序、杂交测序、聚合酶克隆测序、离子半导体测序和焦磷酸测序;和第三代测序方法,例如单分子实时测序、基于纳米孔的测序、双链体中断测序、以及使用先进显微镜对DNA直接成像。
供本发明使用的合适的测序方法包括但不限于:杂交测序、合成技术测序(例如,HiSeq
核酸(例如,延伸核酸)的文库可用多种方式扩增。核酸(例如,包含来自一个或多个编码标签的信息的记录标签)的文库经历指数式扩增,例如,通过PCR或乳液PCR。已知乳液PCR产生更一致的扩增(Hori,Fukano等人,BiochemBiophys Res Commun(2007)352(2):323-328)。可替代地,核酸(例如,延伸核酸)的文库可经历进行线性扩增,例如,通过使用T7RNA聚合酶对模板DNA进行体外转录。核酸(例如,延伸的核酸)的文库可以使用与其中所含的通用正向引发位点和通用反向引发位点相容的引物进行扩增。核酸(例如,记录标签)的文库也可以使用加尾引物进行扩增,以向延伸核酸的5'-末端、3'-末端或两端添加序列。可以添加到延伸核酸的末端的序列包括允许在单次测序运行中对多个文库的文库特异性标记序列、接头序列、读取引物序列或用于使延伸核酸的文库与测序平台相容的任何其它序列多路复用。为下一代测序准备的文库扩增的例子如下:使用从~1mg珠粒洗脱的延伸核酸文库(~10ng)、200μM dNTP、正向和反向扩增引物各1μM、0.5μl(1U)的Phusion Hot Start酶(New England Biolabs)建立20μl PCR反应体积并经受以下循环条件:98℃下30秒,随后是20个循环的98℃下10秒、60℃下30秒、72℃下30秒,随后是72℃下7分钟,然后保持在4℃。
在某些实施方式中,在扩增之前、期间或之后,核酸(例如,延伸的核酸)的文库可以进行靶标富集。在一些实施方式中,靶标富集可以用于在测序前从延伸核酸的文库中选择性捕获或扩增表示目的大分子(例如多肽)的延伸核酸。在一些方面,用于蛋白质测序的靶标富集具有挑战性,因为成本高并且难以产生靶蛋白的高特异性结合剂。在一些情况下,众所周知,抗体是非特异性的并且难以在数千种蛋白质中大规模产生。在一些实施方式中,本公开的方法通过将蛋白质代码转换成核酸代码来规避这个问题,核酸代码则可以使用各种各样可用于DNA文库的靶向DNA富集策略。在一些情况下,目的肽可以通过富集其相应的延伸核酸而在样品中富集。靶向富集方法是本领域已知的,并且包括杂交捕获测定、基于PCR的测定例如TruSeq custom Amplicon(Illumina)、锁式探针(也称为分子倒置探针)等(参见,Mamanova等人,(2010)Nature Methods 7:111-118;Bodi等人,J.Biomol.Tech.(2013)24:73-86;Ballester等人,(2016)Expert Reviewof Molecular Diagnostics 357-372;Mertes等人,(2011)Brief Funct.Genomics 10:374-386;Nilsson等人,(1994)Science 265:2085-8;它们各自通过引用整体并入本文)。
在一个实施方式中,核酸(例如,经延伸记录标签)的文库通过基于杂交捕获的测定进行富集。在基于杂交捕获的测定中,延伸核酸的文库与标有亲和标签(例如生物素)的靶标特异性寡核苷酸杂交。与靶标特异性寡核苷酸杂交的延伸核酸通过它们的使用亲和配体的亲和标签(例如链霉亲和素包被的珠粒)被“拉下”,并且背景(非特异性)延伸核酸被洗掉。然后获得富集的延伸核酸(例如,延伸核酸)用于正富集(例如,从珠粒上洗脱)。在一些实施方式中,与目的肽的相应延伸核酸文库表示互补的寡核苷酸可以用于杂交捕获测定。在一些实施方式中,也可以用相同或不同的诱饵组进行连续轮次或其富集。
在另一个实施方式中,基于引物延伸和连接介导的扩增富集(AmpliSeq、PCR、TruSeqTSCA等)可以用于选择和模块化富含表示多肽子集的文库元件的比例。竞争性寡核苷酸也可以用于调整引物延伸、连接或扩增的程度。在最简单的实施中,这可以通过具有包含通用引物尾部的靶标特异性引物和缺乏5'通用引物尾部的竞争引物的混合物来实现。初始引物延伸后,只有出具有5'通用引物序列的引物才可以扩增。有和没有通用引物序列的引物的比率控制扩增的靶标的比例。在其它实施方式中,包含杂交性但非延伸性引物可以用于调整经历引物延伸、连接或扩增的文库元件的比例。
靶向富集方法也可用于负选择模式,以在测序前选择性地从文库中去除延伸核酸。可以去除的不合需要的延伸核酸的例子是那些代表过于丰富的多肽种类例如蛋白质、白蛋白、免疫球蛋白等的核酸。
与靶标杂交但缺少生物素部分的竞争寡核苷酸诱饵也可以用于杂交捕获步骤,以调整所富集的任何特定基因座的比例。竞争寡核苷酸诱饵与标准生物素化诱饵竞争与靶标的杂交,从而有效地调整富集期间拉下的靶标的比例。使用这种竞争性抑制方法,蛋白质表达的十级动态范围可以压缩几级,尤其是对于过于丰富的物种例如白蛋白。因此,对于给定基因座捕获的文库元件相对于标准杂交捕获的比例可以从100%调整到0%富集。
另外,可以使用文库规范化(library normalization)技术从延伸核酸文库中去除过度丰富的物种。这种方法最适合于限定长度的文库,所述文库来源于通过位点特异性蛋白酶消化产生的肽,如胰蛋白酶、LysC、GluC等。在一个示例中,可以通过使双链文库变性并允许文库元件再退火来实现归一化。由于双分子杂交动力学的二级速率常数,丰富的文库元件比不太丰富的元件更迅速地再退火(Bochman,Paeschke等人2012)。可以使用本领域已知的方法,例如在羟磷灰石柱上的色谱法(VanderNoot等人,2012,Biotechniques 53:373-380)或用来自堪察加(Kamchatka)蟹的破坏dsDNA文库元件的双链体特异性核酸酶(DSN)处理文库(Shagin等人,(2002)Genome Res.12:1935-42),将ssDNA文库元件与丰富的dsDNA文库元件分离。
多肽在附着到载体之前和/或所生成的延伸核酸文库的分级分离、富集和扣除方法的任何组合可以节省测序读段并改善低丰度物种的测量。
在一些实施方式中,核酸(例如,延伸核酸)的文库通过连接或末端互补PCR进行串联,以产生分别包括多个不同的经延伸记录标签、延伸编码标签或双标签的长DNA分子(Du等人,(2003)BioTechniques 35:66-72;Muecke等人,(2008)Structure 16:837-841;美国专利第5,834,252号,所述文献中的每个文献通过引用整体并入)。该实施方式对于通过纳米孔测序装置来分析长链DNA的纳米孔测序是优选的。
在一些实施方式中,对核酸(例如,延伸核酸)进行直接单分子分析(例如,参见Harris等人,(2008)Science 320:106-109)。核酸(例如,延伸核酸)可以在载体、例如流动池或与加载到流动池表面(任选图案化的微型池)相容的珠粒上直接分析,其中流动池或珠粒可以与用单分子测序仪或单分子解码仪整合。对于单分子解码,几轮汇集的荧光标记的解码寡核苷酸的杂交(Gunderson等人,(2004)Genome Res.14:970-7)可以用于确定延伸核酸内(例如,记录标签上)的编码标签的身份和顺序两者。在一些实施方式中,结合剂可用如上所述的循环特异性编码标签进行标记(也参见,Gunderson等人,(2004)Genome Res.14:970-7)。
在一些情况下,在对核酸文库(例如,延伸核酸的文库)进行测序后,所生成的序列可以通过它们的UMI(如果使用的话)折拢,并且然后与它们对应多肽相关并且与整个蛋白质组比对。所生成的序列也可以通过它们的区室标签折拢并与其相应的区室蛋白质组相关,所述蛋白质组在一个特定的实施方式中仅包含单个或数量非常有限的蛋白质分子。蛋白质鉴定和定量都可以很容易地根据所述数字肽信息得出。
本文所公开的方法可以用于同时(多路复用)分析多个大分子,包含检测、定量和/或测序。如本文所用的多路复用是指在同一测定中分析多个大分子(例如多肽)。多个大分子可以源自于相同的样品或不同的样品。多个大分子可以源自于相同的对象或不同的对象。被分析的多个大分子可以是不同的大分子,或源自于不同样品的相同大分子。多个大分子包括2或更多个大分子、5或更多个大分子、10或更多个大分子、50或更多个大分子、100或更多个大分子、500或更多个大分子、1,000或更多个大分子、5,000或更多个大分子、10,000或更多个大分子、50,000或更多个大分子、100,000或更多个大分子、500,000或更多个大分子、或1,000,000或更多个大分子。
III.
本文提供了包括用于进行大分子分析测定的组分的试剂盒和制品。在一些实施方式中,所述试剂盒包含结合剂,所述结合剂包括编码标签,所述编码标签包括关于所述结合剂的标识信息。在一些方面,所述试剂盒包含多个或一组结合剂,所述多个或一组结合剂各自包括编码标签。在一些实施方式中,结合剂被配置成与和记录标签缔合的大分子结合,并且还提供了用于将信息从编码标签传递到记录标签的试剂。试剂盒中还提供了核酸接合试剂、聚合酶和双链核酸切割试剂。在一些方面,将核酸接合试剂、聚合酶和双链核酸切割试剂以混合物的形式提供。例如,核酸接合试剂是化学连接试剂或酶连接试剂。在一些情况下,双链核酸切割试剂是限制酶。
在一些实施方式中,试剂盒进一步含有用于处理和分析靶大分子(例如,蛋白质、多肽或肽)的其它试剂。试剂盒和制品可以包含在章节I和II中描述的方法中使用的任何一种或多种试剂和组分。在一些实施方式中,试剂盒包括用于制备样品的试剂,如用于从样品制备大分子并且与载体接合的试剂。在一些实施方式中,试剂盒任选地包含用于进行大分子分析测定的说明书。在一些实施方式中,试剂盒包括以下组分中的一种或多种:结合剂、核酸接合试剂、聚合酶、双链核酸切割试剂、固体载体、记录标签、用于传递信息的试剂、测序试剂和/或任何所需的缓冲液等。记录标签、结合剂和编码标签可以分别具有如在章节IA、IB和IC中描述的特定结构和特征。
在一方面,本文提供了用于制备反应混合物的组分。在一些优选实施方式中,反应混合物是溶液。在优选实施方式中,反应混合物包含以下中的一种或多种:结合剂和相关编码标签、固体载体、记录标签、用于传递信息的试剂(包含核酸接合试剂)、聚合酶、双链核酸切割试剂、测序试剂、缓冲液和/或其它添加剂。
在另一方面,本文公开了一种用于进行大分子分析测定的试剂盒,所述试剂盒包括结合剂文库,其中每种结合剂包括编码标签或与编码标签缔合。在一些方面,编码标签包括关于结合剂的结合部分的标识信息。在一些示例中,结合部分能够与靶肽或多肽的一个或多个N末端氨基酸、内部氨基酸或C末端氨基酸结合,或能够与由官能化/修饰试剂修饰的肽的一个或多个N末端氨基酸、内部氨基酸或C末端氨基酸结合。
在一些实施方式中,试剂盒和制品进一步包括多个核酸分子或寡核苷酸。在一些实施方式中,试剂盒包含多个条形码。条形码可以包含区室条形码、分区条形码、样品条形码、级分条形码或其任何组合。在一些情况下,条形码包括唯一分子标识符(UMI)。在一些示例中,条形码包括DNA分子、具有假互补碱基的DNA、RNA分子、BNA分子、XNA分子、LNA分子、PNA分子、γPNA分子、非核酸可测序的聚合物,例如,多糖、多肽、肽或聚酰胺或其组合。在一些实施方式中,条形码被配置成附着样品中的供分析的大分子(例如,蛋白质)或附着于与大分子缔合的核组分。
在一些实施方式中,试剂盒进一步包括用于处理大分子(例如,蛋白质)的试剂。可以进行蛋白质的分级分离、富集和扣除方法的任何组合。例如,试剂可以用于片段化或消化蛋白质。在一些情况下,试剂盒包括对蛋白质进行分级分离、分离、扣除、富集的试剂和组分。在一些示例中,试剂盒进一步包括蛋白酶,如胰蛋白酶、LysN或LysC。在一些实施方式中,试剂盒包括用于固定一个或多个靶标的载体和用于将靶标固定在载体上的试剂。在一些实施方式中,试剂盒进一步包含用于去除多肽的N末端氨基酸(NTAA)的试剂,如化学剂或酶剂。在一些实施方式中,试剂盒进一步包含用于修饰多肽的末端氨基酸的试剂,如化学剂或酶剂。
在一些实施方式中,试剂盒还包括进行大分子分析测定的步骤中的任何步骤所必需的一种或多种缓冲液或反应流体。包含洗涤缓冲液、反应缓冲液和结合缓冲液、洗脱缓冲液等在内的缓冲液是本领域技术人员或普通技术人员已知的。在一些实施方式中,试剂盒进一步包含缓冲液和其它组分以伴随本文所描述的其它试剂。试剂、缓冲液和其它组分可以提供在小瓶(如密封小瓶)、器皿、安瓿、瓶子、广口瓶、软包装(例如,密封聚酯薄膜或塑料袋)等中。试剂盒的任何组分都可以被消毒和/或密封。
在一些实施方式中,试剂盒包含用于核酸序列分析的一种或多种试剂。在一些示例中,用于序列分析的试剂用于合成测序、连接测序、单分子测序、单分子荧光测序、杂交测序、聚合酶克隆测序、离子半导体测序、焦磷酸测序、单分子实时测序、基于纳米孔的测序测序或使用先进显微镜对DNA直接成像或其任何组合。
除了上述组分之外,主题试剂盒可以进一步包含使用试剂盒的组分实践主题方法的说明,即,用于样品制备、处理和/或分析的说明。本文所描述的试剂盒还可以包含从商业和用户的角度来看令人期望的其它材料,包含其它缓冲液、稀释剂、过滤器、注射器和具有本文所描述的任何方法的执行说明的包装插页。
任何上述试剂盒组分,以及任何分子、分子复合体或缀合物、试剂(例如,化学试剂或生物试剂)、药剂、结构(例如,载体、表面、颗粒或珠粒)、反应中间体、反应产物、结合复合体或在示例性试剂盒和方法中公开和/或使用的任何其它制品可以单独提供或以任何合适的组合提供以形成试剂盒。
IV.
所提供的实施方式包括:
1.一种用于分析大分子的方法,所述方法包括以下步骤:
(a)提供大分子和与载体接合的所缔合记录标签;
(b)使所述大分子与能够与所述大分子结合的结合剂接触,其中所述结合剂包括具有关于所述结合剂的标识信息的编码标签,以允许所述大分子与所述结合剂之间的结合;
(c)通过核酸接合试剂将所述记录标签的5'端与所述编码标签的3'端接合;
(d)使用所述编码标签作为模板通过聚合酶延伸所述记录标签,从而产生双链经延伸记录标签;以及
(e)用双链核酸切割试剂切割所述双链经延伸记录标签,以产生经延伸记录标签中的3'突出端;
由此信息从所述编码标签传递到所述记录标签,从而产生所述经延伸记录标签。
2.根据实施方式1所述的方法,其中在步骤(d)中,所述双链经延伸记录标签包括能够被所述双链核酸切割试剂识别的识别序列。
3.根据实施方式1或实施方式2所述的方法,其中步骤(e)中的所述切割将所述结合剂从所述大分子释放。
4.根据实施方式1至3中任一项所述的方法,其中所述记录标签和编码标签包括核酸。
5.根据实施方式1至4中任一项所述的方法,其中所述经延伸记录标签包括核酸发夹。
6.根据实施方式1至5中任一项所述的方法,其中步骤(a)、(b)、(c)、(d)和(e)按顺序进行。
7.根据实施方式1至6中任一项所述的方法,其中步骤(b)、(c)、(d)和(e)以循环方式按顺序重复一次或多次。
8.根据实施方式1至7中任一项所述的方法,其中所述大分子是脂质、碳水化合物、蛋白质、多肽或肽。
9.根据实施方式8所述的方法,其中所述肽是通过将来自生物样品的蛋白质片段化来获得的。
10.根据实施方式1至9中任一项所述的方法,其中所述供分析的大分子不是核酸。
11.根据实施方式7至10中任一项所述的方法,其进一步包括在重复步骤(b)之前去除所述大分子的一部分。
12.根据实施方式8至11中任一项所述的方法,其进一步包括在重复步骤(b)之前去除所述多肽的N末端氨基酸(NTAA)以暴露所述多肽的新NTAA。
13.根据实施方式7至12中任一项所述的方法,其中当重复步骤(b)时,所述经延伸记录标签的在步骤(e)中通过所述双链核酸切割试剂产生的所述3'突出端能够用于与第二编码标签杂交。
14.根据实施方式1至13中任一项所述的方法,其进一步包括去除所述结合剂。
15.根据实施方式14所述的方法,其中在将所述编码标签的信息传递到所述记录标签之后去除所述结合剂。
16.根据实施方式14或实施方式15所述的方法,其中在重复步骤(b)之前去除所述结合剂。
17.根据实施方式1至16中任一项所述的方法,其中所述方法包括在步骤(b)中使多个大分子与一种结合剂或多种结合剂接触。
18.根据实施方式8至17中任一项所述的方法,其进一步包括用用于修饰所述多肽的末端氨基酸的试剂处理所述多肽。
19.根据实施方式18所述的方法,其中所述用于修饰所述多肽的末端氨基酸的试剂包括化学剂或酶剂。
20.根据实施方式18或实施方式19所述的方法,其中在步骤(b)之前用所述用于修饰所述多肽的末端氨基酸的试剂处理所述多肽。
21.根据实施方式1至20中任一项所述的方法,其中与所述大分子缔合的所述记录标签包括双链区域。
22.根据实施方式21所述的方法,其中与所述大分子缔合的所述记录标签包括核酸发夹。
23.根据实施方式1至22中任一项所述的方法,其中与所述大分子缔合的所述记录标签具有3'突出端。
24.根据实施方式1至23中任一项所述的方法,其中所述记录标签包括条形码。
25.根据实施方式1至24中任一项所述的方法,其中所述记录标签包括唯一分子标识符(UMI)。
26.根据实施方式24或实施方式25所述的方法,其中步骤(a)包括向所述记录标签提供所述条形码和/或所述UMI。
27.根据实施方式24或实施方式26所述的方法,其中所述条形码是样品条形码、级分条形码、空间条形码和/或区室标签。
28.根据实施方式24或实施方式25所述的方法,其中步骤(a)包括使用连接和/或延伸以向所述记录标签提供所述条形码和/或所述UMI。
29.根据实施方式23至28中任一项所述的方法,其中步骤(a)包括切割所述记录标签以产生3'突出端。
30.根据实施方式23至29中任一项所述的方法,其中通过延伸和/或通过双链核酸切割试剂进行的切割来产生所述记录标签的所述3突出端。
31.根据实施方式1至30中任一项所述的方法,其中所述记录标签包括通用引发位点。
32.根据实施方式31所述的方法,其中所述通用引发位点包括用于扩增、测序或两者的引发位点。
33.根据实施方式1至32中任一项所述的方法,其中步骤(c)、(d)和(e)作为一锅反应进行。
34.根据实施方式33所述的方法,其中步骤(c)、(d)和(e)的所述核酸接合试剂、所述聚合酶和所述双链核酸切割试剂分别以混合物的形式提供。
35.根据实施方式1至32中任一项所述的方法,其中步骤(c)、(d)和(e)按顺序且单独地进行。
36.根据实施方式1至32中任一项所述的方法,其中步骤(c)的所述核酸接合试剂和步骤(d)的所述聚合酶是同时提供的。
37.根据实施方式1至32中任一项所述的方法,其中步骤(d)的所述聚合酶和步骤(e)的所述双链核酸切割试剂是同时提供的。
38.根据实施方式1至37中任一项所述的方法,其中所述编码标签包括部分限制酶识别序列。
39.根据实施方式38所述的方法,其中所述编码标签的所述部分限制酶识别序列是单链的。
40.根据实施方式1至39中任一项所述的方法,其中所述编码标签包括条形码和/或唯一分子标识符(UMI)。
41.根据实施方式1至40中任一项所述的方法,其中所述记录标签和编码标签各自包括间隔区。
42.根据实施方式41所述的方法,其中所述间隔区是小于或等于10个碱基、小于或等于9个碱基、小于或等于8个碱基、小于或等于7个碱基、小于或等于6个碱基、小于或等于5个碱基、小于或等于4个碱基、小于或等于3个碱基或小于或等于2个碱基的核酸分子。
43.根据实施方式41或实施方式42所述的方法,其中所述记录标签或经延伸记录标签包括间隔区,所述间隔区是由所述双链核酸切割试剂产生的切割位点突出端。
44.根据实施方式41至43中任一项所述的方法,其中所述间隔区是循环特异性间隔区或循环交替间隔区。
45.根据实施方式44所述的方法,其中所述方法在信息传递的一个循环之后由于不兼容的突出端而自终止。
46.根据实施方式41至45中任一项所述的方法,其中如果由先前编码标签添加的间隔区与第二编码标签的间隔区的至少一部分相匹配,则信息从所述第二编码标签传递到所述经延伸记录标签。
47.根据实施方式1至47中任一项所述的方法,其中所述记录标签和编码标签不包括间隔区。
48.根据实施方式1至47中任一项所述的方法,其中所述编码标签具有可用于反应的3'端。
49.根据实施方式48所述的方法,其中所述结合剂附着于所述编码标签的5'端上。
50.根据实施方式1至49中任一项所述的方法,其中所述方法包括一个或多个洗涤步骤。
51.根据实施方式50所述的方法,其中洗涤步骤在步骤(c)之前进行。
52.根据实施方式50所述的方法,其中洗涤步骤在步骤(d)之前进行。
53.根据实施方式50所述的方法,其中洗涤步骤在步骤(e)之前进行。
54.根据实施方式1至53中任一项所述的方法,其中所述核酸接合试剂是化学连接试剂或酶连接试剂。
55.根据实施方式54所述的方法,其中所述酶核酸接合试剂是连接酶。
56.根据实施方式1至55中任一项所述的方法,其中所述双链核酸切割试剂是限制酶。
57.根据实施方式55所述的方法,其中所述限制酶是IIS型限制酶。
58.根据实施方式57所述的方法,其中所述IIS型限制酶识别包括以下的碱基序列:
5'…GCAGTGNN…3'
3'…CGTCACNN…5'。
59.根据实施方式57或实施方式58所述的方法,其中所述限制酶是Nb.BtsI或BtsI-v2或其衍生物。
60.根据实施方式1至59中任一项所述的方法,其中步骤(c)、(d)和(e)的连接、延伸和切割分别以逐步的方式进行。
61.根据实施方式1至60中任一项所述的方法,其中在所述记录标签通过所述核酸接合试剂与所述编码标签接合之后,所述结合剂不保持与所述大分子结合。
62.根据实施方式1至61中任一项所述的方法,其中进行最终信息传递循环以向所述经延伸记录标签提供加帽序列,其中任选地,所述加帽序列包括用于扩增、测序或两者的通用引发位点。
63.根据实施方式62所述的方法,其中所述加帽序列提供在与能够与所述大分子的通用特征结合的结合剂缔合的编码标签中。
64.根据实施方式63所述的方法,其中所述通用特征是所述多肽的所述N末端氨基酸的化学修饰。
65.根据实施方式8至64中任一项所述的方法,其中所述经延伸记录标签包括从多个编码标签传递的一系列信息。
66.根据实施方式1至65中任一项所述的方法,其进一步包括分析所述经延伸记录标签中的一个或多个经延伸记录标签。
67.根据实施方式66所述的方法,其中在分析之前,扩增所述经延伸记录标签中的所述一个或多个经延伸记录标签。
68.根据实施方式66或实施方式67所述的方法,其中分析所述经延伸记录标签包括核酸测序方法。
69.根据实施方式68所述的方法,其中所述核酸测序方法是合成测序、连接测序、杂交测序、聚合酶克隆测序、离子半导体测序、焦磷酸测序、单分子实时测序、基于纳米孔的测序或使用先进显微镜对DNA直接成像。
70.根据实施方式1至69中任一项所述的方法,其中所述结合剂是多肽或蛋白质。
71.根据实施方式70所述的方法,其中所述结合剂是氨肽酶或其变体、突变体或经修饰的蛋白质;氨酰基tRNA合成酶或其变体、突变体或经修饰的蛋白质;anticalin或其变体、突变体或经修饰的蛋白质;ClpS、ClpS2或其变体、突变体或经修饰的蛋白质;UBR盒蛋白或其变体、突变体或经修饰的蛋白质;或与氨基酸结合的经修饰的小分子,即,万古霉素(vancomycin)或其变体、突变体或经修饰的分子;或其抗体或结合片段;或其任何组合。
72.根据实施方式8至71中任一项所述的方法,其中所述结合剂与单个氨基酸残基、二肽、三肽或多肽大分子的翻译后修饰结合。
73.根据实施方式72所述的方法,其中所述结合剂被配置成与所述多肽的N末端氨基酸残基结合。
74.根据实施方式73所述的方法,其中所述结合剂被配置成与所述多肽的经化学修饰或经标记的N末端氨基酸残基结合。
75.一种用于大分子分析的试剂盒,所述试剂盒包括:
结合剂,所述结合剂包括编码标签,所述编码标签包括关于所述结合剂的标识信息;
核酸接合试剂;
聚合酶;以及
双链核酸切割试剂;
其中所述结合剂被配置成与和记录标签缔合的大分子结合,并且来自所述编码标签的所述标识信息被配置成从所述编码标签传递到与所述大分子缔合的所述记录标签。
76.根据实施方式75所述的试剂盒,其中所述大分子是脂质或碳水化合物。
77.根据实施方式75所述的试剂盒,其中所述大分子是蛋白质、多肽或肽。
78.根据实施方式77所述的试剂盒,其进一步包括用于去除所述多肽的N末端氨基酸(NTAA)的试剂。
79.根据实施方式78所述的试剂盒,其中所述用于去除所述多肽的所述末端氨基酸的试剂包括化学剂或酶剂。
80.根据实施方式77至79中任一项所述的试剂盒,其进一步包括用于修饰所述多肽的所述末端氨基酸的试剂。
81.根据实施方式80所述的试剂盒,其中所述用于修饰所述多肽的所述末端氨基酸的试剂包括化学剂或酶剂。
82.根据实施方式75至81中任一项所述的试剂盒,其中与所述大分子缔合的所述记录标签包括双链区域。
83.根据实施方式82所述的试剂盒,其中与所述大分子缔合的所述记录标签包括核酸发夹。
84.根据实施方式75至83中任一项所述的试剂盒,其中与所述大分子缔合的所述记录标签具有3'突出端。
85.根据实施方式75至84中任一项所述的试剂盒,其中所述记录标签包括条形码。
86.根据实施方式85所述的试剂盒,其中所述条形码是样品条形码、级分条形码、空间条形码和/或区室标签。
87.根据实施方式75至86中任一项所述的试剂盒,其中所述记录标签包括唯一分子标识符(UMI)。
88.根据实施方式75至87中任一项所述的试剂盒,其中所述记录标签包括通用引发位点。
89.根据实施方式88所述的试剂盒,其中所述通用引发位点包括用于扩增、测序或两者的引发位点。
90.根据实施方式75至89中任一项所述的试剂盒,其中所述试剂盒包括混合物,所述混合物包括所述核酸接合试剂、所述聚合酶和所述双链核酸切割试剂。
91.根据实施方式75至90中任一项所述的试剂盒,其中所述编码标签包括部分限制酶识别序列。
92.根据实施方式91所述的试剂盒,其中所述编码标签的所述部分限制酶识别序列是单链的。
93.根据实施方式75至92中任一项所述的试剂盒,其中所述编码标签包括条形码和/或唯一分子标识符(UMI)。
94.根据实施方式75至93中任一项所述的试剂盒,其中所述记录标签和编码标签各自包括间隔区。
95.根据实施方式94所述的试剂盒,其中所述间隔区是小于或等于10个碱基、小于或等于9个碱基、小于或等于8个碱基、小于或等于7个碱基、小于或等于6个碱基、小于或等于5个碱基、小于或等于4个碱基、小于或等于3个碱基或小于或等于2个碱基的核酸分子。
96.根据实施方式94或实施方式95所述的试剂盒,其中所述间隔区是循环特异性间隔区或循环交替间隔区。
97.根据实施方式75至93中任一项所述的试剂盒,其中所述记录标签和编码标签不包括间隔区。
98.根据实施方式75至97中任一项所述的试剂盒,其中所述编码标签具有可用于反应的3'端。
99.根据实施方式75至98中任一项所述的试剂盒,其中所述酶核酸接合试剂是连接酶。
100.根据实施方式75至99中任一项所述的试剂盒,其中所述双链核酸切割试剂是限制酶。
101.根据实施方式100所述的试剂盒,其中所述限制酶是IIS型限制酶。
102.根据实施方式101所述的试剂盒,其中所述IIS型限制酶识别包括以下的碱基序列:
5'…GCAGTGNN…3'
3'…CGTCACNN…5'。
103.根据实施方式101或实施方式102所述的试剂盒,其中所述限制酶是Nb.BtsI或BtsI-v2或其衍生物。
104.根据实施方式75至103中任一项所述的试剂盒,其进一步包括能够与所述大分子的通用特征结合的结合剂,其中所述结合剂包括加帽序列。
105.根据实施方式75至104中任一项所述的试剂盒,其中所述试剂盒包括混合物,所述混合物包括多种结合剂。
106.根据实施方式75至105中任一项所述的试剂盒,其中所述结合剂是多肽或蛋白质。
107.根据实施方式106所述的试剂盒,其中所述结合剂是氨肽酶或其变体、突变体或经修饰的蛋白质;氨酰基tRNA合成酶或其变体、突变体或经修饰的蛋白质;anticalin或其变体、突变体或经修饰的蛋白质;ClpS、ClpS2或其变体、突变体或经修饰的蛋白质;UBR盒蛋白或其变体、突变体或经修饰的蛋白质;或与氨基酸结合的经修饰的小分子,即,万古霉素或其变体、突变体或经修饰的分子;或其抗体或结合片段;或其任何组合。
108.根据实施方式77至107中任一项所述的试剂盒,其中所述结合剂与单个氨基酸残基、二肽、三肽或多肽大分子的翻译后修饰结合。
109.根据实施方式108所述的试剂盒,其中所述结合剂被配置成与所述多肽的N末端氨基酸残基结合。
110.根据实施方式80至109中任一项所述的试剂盒,其中所述结合剂被配置成与所述多肽的N末端氨基酸残基结合,所述氨基酸残基由所述用于修饰所述多肽的所述末端氨基酸的试剂修饰。
111.根据实施方式75至110中任一项所述的试剂盒,其包括一种或多种洗涤缓冲液。
112.根据实施方式75至111中任一项所述的试剂盒,其进一步包括用于固定所述大分子和/或所述记录标签的载体。
113.根据实施方式112所述的试剂盒,其中所述载体是三维载体(例如,多孔基质或珠粒)。
114.根据实施方式113所述的试剂盒,其中所述载体包括聚苯乙烯珠、聚丙烯酸酯珠、聚合物珠、琼脂糖珠、纤维素珠、葡聚糖珠、丙烯酰胺珠、实心珠、多孔珠、顺磁珠、玻璃珠、可控孔度珠、基于二氧化硅的珠或其任何组合。
V.
提供以下实例是为了说明而不是限制本文所提供的方法、组成和用途。在较早公开的申请US 2019/0145982 A1、US 2020/0348308 A1、US 2020/0348307 A1、US 2021/0208150 A1、WO 2020/223000中公开了本发明的某些方面,包含但不限于用于Proteocode
实例1:使用核酸杂交和与固体载体接合来评估分析物固定。
本实例描述了用于将核酸-多肽缀合物与固体载体接合(固定)的示例性方法。
在基于杂交的固定方法中,将核酸-多肽缀合物杂交并且与化学固定在磁珠上的发夹捕获DNA连接。使用基于反式环辛烯(TCO)和甲基四嗪(mTet)的点击化学将捕获核酸与珠粒缀合。将经TCO修饰的短发夹捕获核酸(16个碱基对茎、5个碱基环、24个碱基5'突出端)与mTet包被的磁珠反应。将磷酸化核酸-多肽缀合物(10nM)在5x SSC、0.02%SDS中退火到附着于珠粒的发夹DNA,并且在37℃下温育30分钟。将珠粒用PBST洗涤一次,并且用T4 DNA连接酶重悬于1x快速连接溶液(New England Biolabs,USA)中。在25℃下温育30分钟后,将珠粒用PBST洗涤两次,并且重悬于50μL PBST中。使用特异性引物组,通过qPCR定量包含氨基FA端肽(FAGVAMPGAEDDVVGSGSK;SEQ ID NO:3)、氨基AFA端肽(AFAGVAMPGAEDDVVGSGSK;SEQ ID NO:4)和氨基AA端肽(AAGVAMPGAEDDVVGSGSK;SEQ ID NO:5)的总固定的核酸-多肽缀合物。为了进行比较,使用不涉及连接步骤的基于非杂交的方法将肽固定到珠粒上。通过将30μM经TCO修饰的DNA标记肽(包含氨基FA端肽、氨基AFA端肽和氨基AA端肽)与mTet包被的磁珠在25℃下一起温育过夜来进行基于非杂交的方法。
如表1所示,在具有1:100,000接枝密度的非杂交制备方法和具有1:10,000接枝密度的基于杂交的制备方法中观察到相似的Ct值。与非杂交制备方法的负载量相比,基于杂交的制备方法的DNA标记肽的负载量为1/3000。通常,观察到基于杂交的固定方法需要较少的起始材料。
实例2:示例性顺序编码测定。
在本实例中,使用两种示例性结合剂来与固定在固体载体上的核酸-多肽缀合物特异性结合。一种结合剂与多肽的N末端苯丙氨酸残基(F-结合剂;31-F)结合,并且另一种结合剂与多肽的N末端亮氨酸残基(L-结合剂;44-L)结合。通过定向进化来从脂质运载蛋白支架工程改造两种结合剂,具体地如在US 2021/0208150 A1的实例1中所描述的。将结合剂与对应核酸编码标签缀合,所述核酸编码标签包括具有关于结合剂的标识信息的条形码。将对每种结合剂具有特异性的编码标签通过PEG接头附着于SpyTag上,并且将所生成的融合物通过SpyTag-SpyCatcher相互作用与结合剂-SpyCatcher融合蛋白反应,基本上如在US2021/0208150 A1中所描述的。
对于编码测定,两个测试大分子(FSGVARGDVRGGK(叠氮化物);此后称为F-肽;SEQID NO:6和LAESAFSGVARGDVRGGK(叠氮化物);此后称为L-肽;SEQ ID NO:7)通过炔-叠氮化物反应(基本上如在实例1中所描述的)与固定的珠粒附着的捕获DNA(SEQ ID NO:8)接合。将DNA-多肽缀合物(20nM)在5x SSC、0.02%SDS中退火到附着于珠粒的捕获DNA,并且在37℃下温育30分钟。将珠粒用PBST洗涤一次,并且用T4 DNA连接酶重悬于1x快速连接溶液(New England Biolabs,USA)中。在25℃下温育30分钟后,并且将珠粒用PBST洗涤,用0.1MNaOH+0.1%Tween 20洗涤两次并用PBST洗涤两次。缀合物中的记录标签含有大分子的条形码、2nt突出端互补区域、II型限制酶结合区域和侧接区域。在杂交和连接后,在25℃下,将样品与Klenow片段(3'->5'exo-)(MCLAB,USA)、BtsI-V2(0.5U/uL,New England Biolabs,USA)、dNTP(各自在125uM下)和CutSmart缓冲液(50mM乙酸钾、20mM Tris-乙酸盐、10mM乙酸镁、100μg/ml BSA,pH 7.9,New England Biolabs,USA)一起温育30分钟,并且用PBST洗涤,用0.1M NaOH+0.1%Tween 20洗涤两次并用PBST洗涤两次。因此,在3'处产生了2nt突出端(参见图1A)。
将珠粒在25℃下用含18mM PMI试剂(吡唑甲亚胺,4-三氟甲基-1H-吡唑)的DMA和MOPS混合物(60%DMA和40%MOPS,pH 7.6)处理30分钟以修饰固定的肽的N末端,并且用PBST洗涤3次。附着于F-结合剂和L-结合剂的编码标签各自形成具有8bp双链体和3'处的2nt突出端的环,所述突出端与珠粒上记录标签的3'突出端互补。编码标签含有用于标识结合剂的唯一条形码,并且还具有用于下一个结合循环的BtsI-V2结合序列和2nt互补突出端区域。在25℃下,在存在0.125U/uLKlenow片段(3'->5'exo-)(MCLAB,USA)、dNTP混合物(各125uM)、0.5U/uL BtsI-V2以及含不同浓度的T4 DNA连接酶(New England Biolabs,USA)的快速连接酶缓冲液(66mM Tris-HCl、10mM MgCl2、1mM二硫苏糖醇、1mM ATP、7.5%聚乙二醇(PEG6000),pH为7.6)的情况下将两种结合剂(各100nM)与珠粒一起温育15分钟,随后用PBST洗涤一次、用0.1M NaOH+0.1%Tween 20洗涤两次并用PBST洗涤两次。在结合期间,发生了记录标签的延伸,这导致条形码信息从编码标签传递到记录标签,从而形成经延伸记录标签(参见图1B)。
在结合循环之后,进行加帽以引入用于下游PCR的引物位点,所述引物位点将扩增经延伸记录标签以供分析。引入含有具有与延伸或未延伸的记录标签的3'突出端互补的2nt 3'突出端的环DNA的加帽寡核苷酸。代替进行单独的加帽步骤,可以使用含有互补引物序列的较长编码标签在延伸反应期间引入用于下游PCR的引物位点。在25℃下,在存在含12.5U/uL T4 DNA连接酶的快速连接酶缓冲液(66mM Tris-HCl、10mM MgCl
通过所描述的编码方法产生的示例性编码结果示出于图2中。对于连接步骤,对3种不同浓度的T4 DNA连接酶(0.125单位/ul、1.25单位/ul、12.5单位/ul)进行测试。连接后,添加Klenow片段用于延伸步骤,并且添加BtsI-V2酶用于切割步骤。通过NGS测序评估经编码的记录标签的级分(经延伸记录标签占珠粒上记录标签总量的百分比(延伸和未延伸)),并且示出了两种结合剂的特异性编码结果。
实例3:用于其它类型的大分子的编码测定。
图2中示出的数据表示对经延伸记录标签的分析,并且确认在F-结合剂或L-结合剂与肽大分子结合之后,条形码信息从编码标签成功传递到记录标签。所描述的技术可以适用于其它类型的大分子,如脂质、碳水化合物或大环。为了进行编码测定,需要将此类大分子固定在固体载体(如珠粒)上并与核酸记录标签缔合。无论所固定的大分子的类型如何,编码步骤都保持相同。与记录标签的缔合可以是直接的(如共价连接)或间接的(如通过固体载体的缔合)。在后一种情况下,记录标签应在编码测定期间与大分子共定位或紧密接近。可以选择结合剂以与大分子的组分特异性结合。每种结合剂都需要与对应核酸编码标签结合,所述核酸编码标签含有具有关于结合剂的标识信息的条形码。在编码期间,将条形码信息传递到与大分子缔合的记录标签,从而产生经延伸记录标签,使得将大分子的结合历史记录到经延伸记录标签中。结合循环可以使用与大分子相互作用的不同结合剂(单独地或以混合物的形式)重复多次。下文公开了本领域已知的代表性方法,所述方法可以用于使所公开的编码测定适用于不同类型的大分子,如碳水化合物、脂质或大环。
首先,可以与碳水化合物、脂质或大环的组分特异性结合的示例性结合剂是已知的。例如,凝集素是可以选择性地识别游离碳水化合物或糖蛋白的聚糖表位的碳水化合物结合蛋白,并且可以用作含有碳水化合物的大分子的特异性结合剂。重要的是,已知有识别碳水化合物的不同组分的凝集素,如甘露糖结合凝集素、半乳糖/N-乙酰葡糖胺结合凝集素、唾液酸/N-乙酰葡糖胺结合凝集素、岩藻糖结合凝集素(例如,在WO 2012/049285 A1中所公开的)。此外,脂质结合蛋白是熟知的并且可以用作结合剂(参见例如,Bernlohr DA等人,细胞内脂质结合蛋白和其基因(Intracellular lipid-binding proteins and theirgenes.)Annu Rev Nutr.1997;17:277-303)。脂质结合抗体通常是已知的并且可以用作含有脂质的大分子的结合剂(例如参见,Alving CR.脂质和脂质体的抗体:免疫学和安全性(Antibodies to lipids and liposomes:immunology and safety.)J LiposomeRes.2006;16(3):157-66)。此外,与大环特异性结合的蛋白质也是已知的(参见例如,Villar EA等人,蛋白质如何与大环结合(How proteins bind macrocycles.)Nat ChemBiol.2014Sep;10(9):723-31;Hunter TM等人,大环的蛋白质识别:抗HIV金属环拉胺与溶菌酶的结合(Protein recognition of macrocycles:binding of anti-HIVmetallocyclams to lysozyme.)Proc Natl Acad Sci U S A.2005Feb 15;102(7):2288-92)。
其次,可以利用本领域已知的方法如下进行示例性碳水化合物检测编码测定。
方法I:还原胺化(基于Yang SJ,Zhang H.通过与酰肼珠的可逆反应和质谱的聚糖分析(Glycan analysis by reversible reaction to hydrazide beads and massspectrometry.)Anal Chem.2012;84(5):2232-2238)。
(a)产生固定的记录标签附着的碳水化合物缀合物。
用高碘酸钠氧化碳水化合物以产生醛。缀合胺封端的DNA记录标签并使用氰基硼氢化钠还原所生成的亚胺以产生碳水化合物记录标签缀合物。优选地,可以采用酰肼、烷氧基胺或相似反应性DNA来产生不需要还原剂的更稳定的反应产物(例如,腙)。如实例2中所描述的,通过DNA记录标签将DNA偶联的碳水化合物固定到固体载体上。
(b)通过利用如之前所描述的SpyCatcher-伴刀豆球蛋白A(ConA)融合产生凝集素-DNA编码标签(结合剂-编码标签)缀合物。编码标签含有具有关于ConA的标识信息的条形码。
(c)如实例2中所描述的,将条形码信息从凝集素相关编码标签传递到记录标签,从而分析碳水化合物是否含有与ConA结合的组分。
方法II:重氮偶联(基于Matsuura K等人,通过重氮偶联容易合成稳定的和凝集素可识别的DNA-碳水化合物缀合物(Facile synthesis of stable and lectin-recognizable DNA-carbohydrate conjugates via diazo coupling.)BioconjugChem.2000Mar-Apr;11(2):202-11)。在方法II中,步骤(a)(记录标签附着的碳水化合物缀合物的固定)可以如下进行。1)用碳酸氢铵在水中将碳水化合物胺化以产生β-糖基胺;2)用具有携带硝基苯基官能团的羧酸酯衍生物将胺转化为酰胺。在钯催化剂上氢化硝基并用NaNO
步骤(b)和(c)与方法I中的步骤相同。
第三,可以利用本领域已知的方法如下进行示例性脂质检测编码测定。
方法I:脂肪酸(基于Hiroshi Miwa,在生物材料中游离脂肪酸和酯化脂肪酸作为它们的2-硝基苯基肼的高效液相色谱测定(High-performance liquid chromatographicdetermination of free fatty acids and esterified fatty acids in biologicalmaterials as their 2-nitrophenylhydrazides),Analytica Chimica Acta,第465卷,第1–2期,2002,第237-255页,ISSN 0003-2670)。
(a)从生物来源中提取脂肪酸并且用EDC/CDI化学方法活化羧酸。将胺或酰肼封端的DNA记录标签偶联,以产生记录标签附着的脂质缀合物。如实例2中所描述的,通过DNA记录标签将DNA偶联的脂质固定到固体载体上。
方法II:反应性脂质(基于X.Wei和H.Yin(2015),通过源自于脂质过氧化的α,β-不饱和醛对DNA进行共价修饰:最近的进展和挑战(Covalent modification of DNA byα,β-unsaturated aldehydes derived from lipid peroxidation:Recent progress andchallenges),Free Radical Research,49:7,905-917)。
(a)获得反应性脂质基体,如丙二醛(MDA)或4-羟基壬烯醛(HNE);将酰肼封端的DNA记录标签与反应性脂质物种偶联。可替代地,将胺封端的DNA记录标签与反应性脂质上的醛偶联并用氰基硼氢化钠还原所生成的亚胺。
在针对这两种方法的下一个步骤中,通过利用如之前所描述的SpyCatcher结合剂融合产生结合剂-DNA编码标签缀合物。编码标签含有具有关于结合剂的标识信息的条形码。脂肪酸结合蛋白(FABP)、其它脂质结合蛋白或脂质结合抗体可以用作结合剂。最后,如在本申请的实例2中所描述的,将条形码信息从结合剂相关编码标签传递到记录标签,从而分析脂质是否含有与结合剂结合的组分。
第四,可以使用本领域已知的方法如下进行示例性大环(微囊藻毒素)检测编码测定,基于McElhiney J等人,通过噬菌体展示快速分离针对蓝藻毒素微囊藻毒素-LR的单链抗体及其在水中免疫亲和浓缩微囊藻毒素中的用途(Rapid isolation of a single-chain antibody against the cyanobacterial toxin microcystin-LR by phagedisplay and its use in the immunoaffinity concentration of microcystins fromwater.)Appl Environ Microbiol.2002Nov;68(11):5288-95。
(a)通过使微囊藻毒素的脱氢丙氨酸与2-巯基乙胺反应,以产生伯胺,随后使用胺反应性DNA记录标签(例如,NHS-DNA衍生物)将DNA记录标签与伯胺偶联来产生DNA记录标签偶联的微囊藻毒素。
(b)产生识别微囊藻毒素的单链抗体-SpyCatcher结合剂。单链抗体产生描述于McElhiney J等人2002。将DNA编码标签与SpyTag偶联(编码标签含有具有关于单链抗体的标识信息的条形码),随后与SpyCatcher反应以产生如之前所描述的结合剂编码标签缀合物。
(c)如实例2中所描述的,将条形码信息从单链抗体相关编码标签传递到记录标签,从而分析大分子是否含有微囊藻毒素。
序列表
序列表
<110> Encodia公司(Encodia, Inc.)
<120> 顺序编码方法和相关试剂盒
<130> 4614-2002540
<150> 63/067,744
<151> 2020-08-19
<160> 8
<170> PatentIn 3.5版
<210> 1
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> P5引物
<400> 1
aatgatacgg cgaccaccga 20
<210> 2
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> P7引物
<400> 2
caagcagaag acggcatacg agat 24
<210> 3
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> 测试肽
<400> 3
Phe Ala Gly Val Ala Met Pro Gly Ala Glu Asp Asp Val Val Gly Ser
1 5 10 15
Gly Ser Lys
<210> 4
<211> 20
<212> PRT
<213> 人工序列
<220>
<223> 测试肽
<400> 4
Ala Phe Ala Gly Val Ala Met Pro Gly Ala Glu Asp Asp Val Val Gly
1 5 10 15
Ser Gly Ser Lys
20
<210> 5
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> 测试肽
<400> 5
Ala Ala Gly Val Ala Met Pro Gly Ala Glu Asp Asp Val Val Gly Ser
1 5 10 15
Gly Ser Lys
<210> 6
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> F-肽
<220>
<221> MISC_FEATURE
<222> (13)..(13)
<223> 赖氨酸侧链上的叠氮基取代基
<400> 6
Phe Ser Gly Val Ala Arg Gly Asp Val Arg Gly Gly Lys
1 5 10
<210> 7
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> L-肽
<220>
<221> MISC_FEATURE
<222> (18)..(18)
<223> 赖氨酸侧链上的叠氮基取代基
<400> 7
Leu Ala Glu Ser Ala Phe Ser Gly Val Ala Arg Gly Asp Val Arg Gly
1 5 10 15
Gly Lys
<210> 8
<211> 53
<212> DNA
<213> 人工序列
<220>
<223> 捕获DNA
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'-磷酸化
<220>
<221> misc_feature
<222> (19)..(19)
<223> n是内部5'-氨基修饰剂C6 dT
<220>
<221> misc_feature
<222> (20)..(21)
<223> 插在中间的C3(三碳)间隔区
<400> 8
tgtagggaaa gagtgtttnt acactctttc cctacacgac gctcttccga tct 53