一种触发词和论元的抽取方法、系统、设备及介质
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及自然语言处理技术领域,特别是涉及一种触发词和论元的抽取方法、系统、设备及介质。
背景技术
事件抽取(event extraction)主要从文本中抽取预先定义好的各种类型事件实例(event mention,描述一个事件的句子)及其论元(argument,事件的参与者和属性,由实体实例组成,是构成事件的基本要素)。事件抽取一般分为2个子任务:(事件)触发词(trigger,用于标识事件的谓词,一般动词和名词居多)抽取和论元抽取。
早期的研究将事件抽取定义为一个标记级的分类问题,即直接定位文本中的触发词和参数并识别它们的类别。然而,这样的方法只捕获输入序列的内部模式,而没有使用标签语义的知识。因此,又出现了另一条研究线索,即基于问答的方法。有了准备好的模板,他们首先通过生成分别针对事件类型、触发词和参数的问题来增强训练语料库。然后,模型学习在原始句子中定位作为答案,从而显式地引入标签知识。但上述方法的性能在很大程度上依赖于问题模板的质量,而设计问题模板需要高水平的专业知识和大量的人力,因此,现有技术中的事件抽取检测的精确率不高。
发明内容
本发明的目的是提供一种触发词和论元的抽取方法、系统、设备及介质,能够提高事件抽取检测的精确率。
为实现上述目的,本发明提供了如下方案:
一种触发词和论元的抽取方法,包括:
获取目标文本;所述目标文本是由自然语言的字符数据构成的文本;
对所述目标文本进行预处理,得到事件信息;所述事件信息包括文本段落及对应的事件类型和事件属性;
利用事件抽取模型,对所述事件信息的触发词和论元进行抽取,得到事件分析结构;所述事件分析结构是由触发词及对应的字符数据、论元及对应的字符数据构成的;所述事件抽取模型包括依次连接的多头注意力模块和T5预训练模型;所述多头注意力模块包括依次连接的编码器和解码器。
可选地,所述编码器和所述解码器均包括12个结构块;各所述结构块均是根据依次连接的自注意力机制层、可选的编码器-解码器注意力机制层和前馈网络层。
可选地,所述前馈网络层包括依次连接的第一全连接层、线性整流函数非线性层和第二全连接层。
可选地,所述利用事件抽取模型,对所述事件信息的触发词和论元进行抽取,得到事件分析结构,具体包括:
根据所述事件信息确定对应的标记序列;
根据所述标记序列,计算顺序输入标记中的隐藏向量;
根据所述隐藏向量和所述基于前缀树的有限解码算法,抽取所述事件信息的触发词和论元,得到事件分析结构。
可选地,所述事件抽取模型的训练过程,具体包括:
获取训练数据;所述训练数据包括训练文本及对应的事件标签;所述事件标签包括预测触发词及对应的字符数据、预测论元及对应的字符数据;
基于多头注意力模块和T5预训练模型构建事件抽取预训练模型;
将所述训练数据输入所述事件抽取预训练模型中,以预设条件概率为目标进行训练,将训练好的事件抽取预训练模型确定为事件抽取模型。
本发明还提供了一种触发词和论元的抽取系统,包括:
数据采集模块,用于获取目标文本;所述目标文本是由自然语言的字符数据构成的文本;
数据预处理模块,用于对所述目标文本进行预处理,得到事件信息;所述事件信息包括文本段落及对应的事件类型和事件属性;
事件抽取模块,用于利用事件抽取模型,对所述事件信息的触发词和论元进行抽取,得到事件分析结构;所述事件分析结构是由触发词、论元及对应的字符数据构成的;所述事件抽取模型包括依次连接的多头注意力模块和T5预训练模型;所述多头注意力模块包括依次连接的编码器和解码器。
本发明还提供了一种电子设备,包括存储器及处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行根据上述的触发词和论元的抽取方法。
本发明还提供了一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的触发词和论元的抽取方法。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明公开了一种触发词和论元的抽取方法、系统、设备及介质,所述方法包括先对目标文本进行预处理,将经过预处理后由文本段落及对应的事件类型和事件属性构成的事件信息,输入基于多头注意力模块和T5预训练模型构建的事件抽取模型中,实现对文本中的触发词和论元进行抽取,从而形成事件分析结构,提高了对文本事件的触发词和论元抽取检测的精确率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明触发词和论元的抽取方法的流程示意图;
图2为本实施例中事件抽取流程逻辑示意图;
图3为本实施例中事件抽取模型结构示意图;
图4为本实施例中编码器-解码器结构示意图;
图5为本发明触发词和论元的抽取系统的结构框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种触发词和论元的抽取方法、系统、设备及介质,能够提高事件抽取检测的精确率。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1所示,本发明提供了一种触发词和论元的抽取方法,包括:
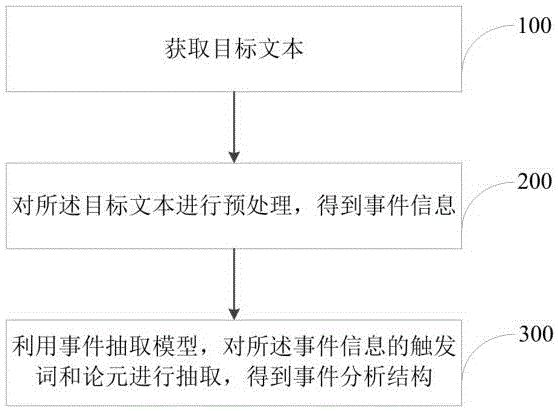
步骤100:获取目标文本;所述目标文本是由自然语言的字符数据构成的文本。
步骤200:对所述目标文本进行预处理,得到事件信息;所述事件信息包括文本段落及对应的事件类型和事件属性。
步骤300:利用事件抽取模型,对所述事件信息的触发词和论元进行抽取,得到事件分析结构;所述事件分析结构是由触发词及对应的字符数据、论元及对应的字符数据构成的;所述事件抽取模型包括依次连接的多头注意力模块和T5预训练模型;所述多头注意力模块包括依次连接的编码器和解码器。
其中,所述编码器和所述解码器均包括12个结构块;各所述结构块均是根据依次连接的自注意力机制层、可选的编码器-解码器注意力机制层和前馈网络层。并且,所述前馈网络层包括依次连接的第一全连接层、线性整流函数非线性层和第二全连接层。
作为步骤300的一种具体实施方式,包括:
根据所述事件信息确定对应的标记序列;根据所述标记序列,计算顺序输入标记中的隐藏向量;根据所述隐藏向量和所述基于前缀树的有限解码算法,抽取所述事件信息的触发词和论元,得到事件分析结构。
此外,所述事件抽取模型的训练过程,具体包括:
获取训练数据;所述训练数据包括训练文本及对应的事件标签;所述事件标签包括预测触发词及对应的字符数据、预测论元及对应的字符数据;基于多头注意力模块和T5预训练模型构建事件抽取预训练模型;将所述训练数据输入所述事件抽取预训练模型中,以预设条件概率为目标进行训练,将训练好的事件抽取预训练模型确定为事件抽取模型。
在上述技术方案的基础上,提供如下实施例:
在社交媒体分析中,信息抽取和事件抽取可以帮助企业快速地了解消费者需求、市场趋势等信息,从而更好地进行市场营销。在商业智能和法律文书处理中,信息抽取和事件抽取可以帮助企业快速地获取和处理大量的商业信息和法律文书,从而提高效率。在生物信息学中,信息抽取和事件抽取可以帮助生物学家快速地从大量的生物数据中提取有用的信息,从而更好地理解生物体系。
使用该方法建立事件抽取系统,主要目标是可以对文章中的文本进行分析和进行结构化表达,进而提升有关工作人员对消息的阅读效率。系统的使用对象是文字工作者和普通读者。首先是数据预处理模块,这个模块是从用户的层面出发的,用户使用这个系统是想要在一篇文章中查看有组织的事件信息,从而对文章的结构和逻辑有更好的理解,从而增强艰深文字的可读性。同时,通过事件抽取,能够迅速地获取海量的信息,并对其进行分析,从而达到提高信息获取效率的目的。对他们来说,导入的数据就是一篇文章,所以在用户导入了文档数据之后,系统需要对文档进行分析,并将分析后的数据转换成模型所需要的格式,以作为事件抽取模型的输入。
当用户输入所要处理的文章时,事件抽取模块会在对文章进行数据的预处理之后,得到自然的文本段落以及候选论元,并将其提供到事件抽取模型中,以作为输入。在此基础上,基于事件提取模型进行预测,并将提取的数据反馈到系统中。最终,该系统会以前端网页的形式向使用者展示抽取的结果。通过对文章进行事件抽取,能够快速提取文章中的关键信息和重要事件,从而帮助读者快速了解文章的主题和内容。同时,提取的关键信息和重要事件可以进行整理和总结。这样的系统可以帮助用户在处理大量的信息时节省时间和精力,具体流程如图2所示。
如图3所示的模型使用基于多头注意力模块(transformer)的编码器-解码器架构来生成事件结构。编码器-解码器结构图如图4所示,具体来说,编码器和解码器都由12个块组成(每个块包括自注意力机制、可选的编码器-解码器注意力机制和一个前馈网络)。每个块中的前馈网络由一个全连接层、一个线性整流函数非线性层和另一个全连接层组成,所有注意机制的头数为12。
给定标记序列
为此,该模型使用多层transformer编码器首先计算输入的隐藏向量表示
其中
在对输入标记序列进行编码后,解码器使用顺序输入标记中的隐藏向量逐个标记地预测输出结构。自注意力解码器在生成的第i步预测第i个线性化的标记y
其中
开始标记和结束标记用于生成的输出结构化序列。每一步的概率
其中
基于transformer的编码器-解码器架构使用预训练语言模型T5,因为线性事件表示中的所有标记也是来自英语语言的单词,允许直接重用通用文本生成知识。
然后在约束解码过程中:给定隐藏序列,网络需要从中一个接一个地生成线性化的事件表示。一个直接的解决方案是使用贪心解码算法,它在每个解码步骤上选择具有最高预测概率的标记。但是这种贪心解码算法不能保证生成有效的事件结构。换句话说,它可能以无效的事件类型、参数类型不匹配和不完整的结构结束。此外,贪婪译码算法忽略了有用的事件模式知识,这种事件模式知识可以有效地指导译码。为了利用事件模式知识,本实施例使用基于前缀树的有限解码算法来生成事件,以获取事件模式知识的好处。在约束解码过程中注入事件模式知识作为解码器的提示,保证生成有效的事件结构。换句话说,约束解码将直接限制每一步解码器的词汇表。
首先构建一个包含目标语言语料库中所有句子的前缀树(trie)。然后使用trie作为目标语言输出的约束来生成源语言语料库中的每个句子。具体来说,与贪婪解码算法在每一步从整个目标词汇表V中选择标记不同,基于trie树的约束解码方法根据当前生成的状态动态地选择并修剪一个候选词汇表V '。一个完整的线性化形式解码过程可以通过执行trie树搜索来表示,如图2所示,每个生成步骤都有三种候选词汇V ':
•事件模式:事件类型的标签名称和参数角色。
•提及字符串:事件触发词和参数提及,它是原始输入中的文本的一部分。
•结构指示符:“(”和“)”,用于组合事件模式和提及字符串。
解码从根“
最后,解码器的输出将被转换为事件记录,并作为最终的提取结果。
此外,本市实施例还提供一种具体的应用环境:利用Pytorch:1.7.1,CUDA:11.0,GPU:NVIDIA GeForce RTX 3090,24G的环境下进行训练。
本实施例提出了一种利用深度学习和提示学习进行事件触发词抽取和论元抽取的方法,通过引入提示学习以便在编码输入时通过不同的标签含义有效地添加知识,并采用解耦的训练结构进行训练。本发明欲保护点是这种设计结构,即:在触发词抽取和论元抽取时加入提示学习,进行有效的知识注入,并采用触发词抽取和论元抽取解耦模型进行事件抽取以提高计算并行性和识别精确度。
本实施例具有如下有益效果:
为了促进事件提取,本实施例将基于提示的学习技术应用到事件提取中,在T5预训练模型的基础上进行研究,T5的基本思想是将每个NLP问题(对字词、短语、句子、篇章的处理)都视为“文本到文本”问题,即将文本作为输入并生成新的文本作为输出,利用transformer的语言模型的迁移学习能力,将事件抽取问题转换为自然语言中的文本到文本任务。在基于神经网络的序列-结构体系结构中统一建模整个事件提取过程,所有触发词、参数及其标签均以自然语言词的形式生成。
允许在输入端和输出端自动使用标签语义,提出一种有效的序列结构体系结构来改进推理过程中的事件知识注入约束解码方法,实现高效的模型学习。主要包含三个步骤:(1)首先,本实施例将基于提示的学习集成到事件提取领域,以便在编码输入时通过不同的标签含义有效地添加知识;(2)解耦了触发词和参数的提取,可以极大提高计算并行性,并自动解决重叠问题。(3)由于架构和输出格式已经大大减少,模型相对易于实现和扩展,并且大大提高事件检测的精确率,召回率以及F1值。
如图5所示,本发明还提供了一种触发词和论元的抽取系统,包括:
数据采集模块,用于获取目标文本;所述目标文本是由自然语言的字符数据构成的文本;
数据预处理模块,用于对所述目标文本进行预处理,得到事件信息;所述事件信息包括文本段落及对应的事件类型和事件属性;
事件抽取模块,用于利用事件抽取模型,对所述事件信息的触发词和论元进行抽取,得到事件分析结构;所述事件分析结构是由触发词、论元及对应的字符数据构成的;所述事件抽取模型包括依次连接的多头注意力模块和T5预训练模型;所述多头注意力模块包括依次连接的编码器和解码器。
本发明还提供了一种电子设备,包括存储器及处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行根据上述的触发词和论元的抽取方法。
本发明还提供了一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的触发词和论元的抽取方法。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 文本公告中触发词的抽取方法及系统
- 英文事件触发词抽取方法和系统
- 一种摇一摇触发方法、装置、电子设备及存储介质
- 一种线阵相机触发时序同步方法、装置、设备和存储介质
- 文本中的实体关系抽取方法及系统、存储介质、电子设备
- 一种中文事件触发词的抽取系统及方法
- 一种中医针灸领域事件触发词的自动抽取方法及系统