一种机器人自主避障方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及一种机器人自主避障方法,属于机器人避障导航技术领域。
背景技术
机器人自主避障导航技术是所有可移动的机器人核心技术之一,如家务机器人,送餐机器人,清洁机器人等均要具备自主避障导航的能力。机器人的续航能力对机器人各方面的能耗提出了挑战,传统神经网络具有较高的运算量,伴随着较高运算量而来的便是高功耗,且采用传统神经网络进行避障计算的机器人在突然出现的强光等干扰机器人感知的噪声时,会导致机器人无法对当前状态决策。
发明内容
本发明的目的在于克服现有技术中的不足,提供一种机器人自主避障方法,具有相比于传统神经网络更小的计算量,在面对噪声时更强的鲁棒性,解决了传统神经网络在面对突然出现的强光等干扰机器人感知的噪声时,会导致机器人无法对当前状态决策,避障计算量大,能耗高的问题。
为达到上述目的/为解决上述技术问题,本发明是采用下述技术方案实现的:
一种机器人自主避障方法,包括:
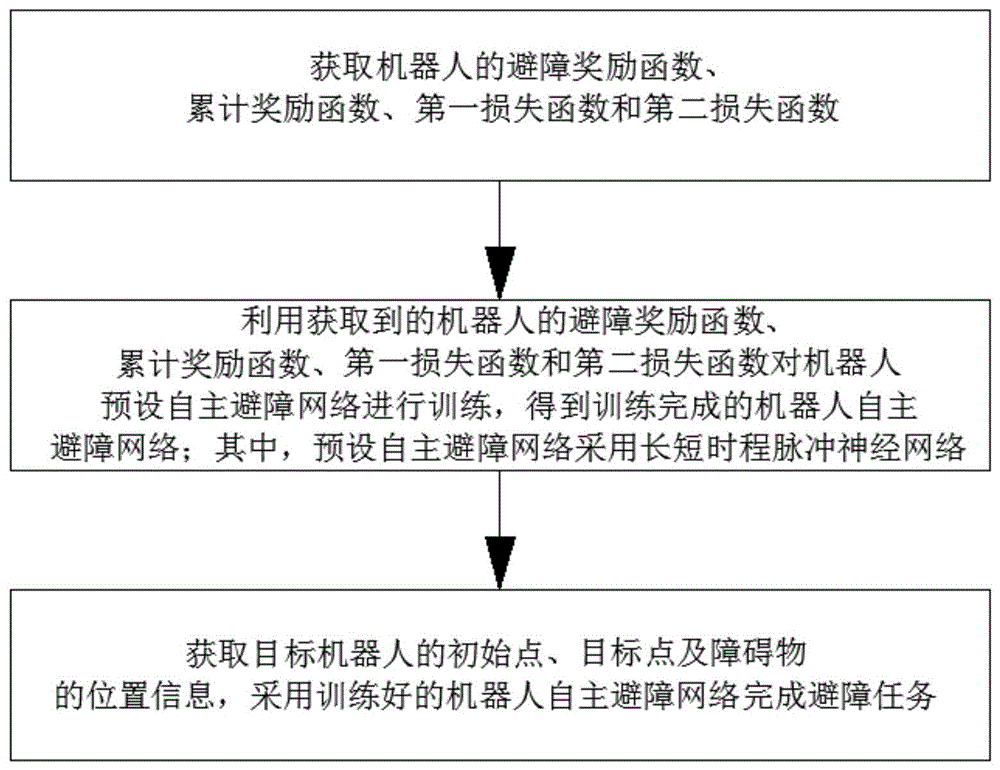
获取机器人的避障奖励函数、累计奖励函数、第一损失函数和第二损失函数;
利用获取到的机器人的避障奖励函数、累计奖励函数、第一损失函数和第二损失函数对机器人预设自主避障网络进行训练,得到训练完成的机器人自主避障网络;其中,预设自主避障网络采用长短时程脉冲神经网络;
获取目标机器人的初始点、目标点及障碍物的位置信息,采用训练好的机器人自主避障网络完成避障任务。
进一步地,所述利用获取到的机器人的避障奖励函数、累计奖励函数和损失函数对机器人避障网络进行训练,得到训练完成的机器人自主避障网络,包括:
构建机器人避障训练环境,开启导航任务;
初始化机器人预设自主避障网络、预设价值网络;
初始化机器人初始状态信息;
将机器人的初始状态信息归一化处理;
获取预设自主避障网络的神经元输入;
根据预设自主避障网络的神经元输入,获取机器人当前状态信息和下一时刻的状态信息;
基于机器人当前状态信息,通过避障奖励函数获取当前时刻的奖励;
判断机器人在运行过程中是否发生碰撞或到达预设终点;
若否,记录done=0,初始化机器人的状态信息并重新获取机器人当前状态信息和下一时刻的状态信息;
基于机器人重新获取的当前状态信息,通过避障奖励函数获取当前时刻的奖励;
判断机器人在运行过程中是否发生碰撞或到达预设终点,直到done=1;
将机器人在不同时刻的状态信息输入预设价值网络,获取机器人的状态评价;
基于获取到的奖励和机器人的状态评价,通过累计奖励函数获取累计奖励;
基于状态评价,通过第一损失函数获取第一损失值,反向传播第一损失值更新预设价值网络;
基于累计奖励函数,通过第二损失函数获取第二损失值,反向传播第二损失值,更新预设自主避障网络,直到更新次数满足阈值;
得到训练完成的机器人自主避障网络。
进一步地,所述机器人初始状态信息包括:机器人初始位置的雷达信号、线速度和角速度。
更进一步地,所述获取预设自主避障网络的神经元输入,包括:
计算遗忘门输出值f
f
其中:W
计算记忆门输出值i
i
其中:W
计算临时状态g
g
其中:W
计算当前时刻神经元的突出电流syn
syn
其中:syn
计算输出门的输出值o
o
其中:W
计算当前时刻神经元的膜电位mem
mem
将当前时刻神经元的突出电流syn
更进一步地,所述根据预设自主避障网络的神经元输入,获取机器人当前状态信息,包括:
获取机器人当前时刻均值和方差;
根据当前时刻均值和方差,获取机器人当前状态信息,其中,当前状态信息包括当前时刻的线速度和角速度。
更进一步地,所述判断机器人在运行过程中是否发生碰撞或到达预设终点,若是,则记录done=1,刷新机器人避障训练环境,开启新一轮导航任务。
更进一步地,所述机器人的避障奖励函数包括:
其中:
d
d
d
更进一步地,所述累计奖励函数包括:
R=[R[0],R[1],...,R[T]];
R[t]=reward[t]+γ*reward[t+1]+γ
其中:
Post_value是下一时刻机器人的状态评价,所述下一时刻机器人的状态评价的获取包括:
将机器人下一时刻的状态信息输入预设价值网络中,得到下一时刻机器人的状态评价;
R是累计奖励由0到T时刻构成,0是当前时刻,T是最后一个时刻;
R[0]是当前时刻奖励,R[T]是最后一个时刻的奖励;
R[t]是R子项的展开表达;
γ是(0,1)内的折扣因子;reward[t]是t时刻奖励。
更进一步地,所述第一损失函数包括:
advantage=R-Value;
其中:R为累计奖励;
Value是累计状态评价,所述累计状态评价的获取包括:将所有获取到的的状态评价累加;
将advantage的均方差作为第一损失值。
更进一步地,所述第二损失函数包括:
Loss=mean(min(ratio*advantage,advantage*clip(ratio,1-ξ,ξ);
其中:
ratio=P
clip(,,)表示截断的含义,clip(ratio,1-ξ,ξ)表示若ratio小于1-ξ,则ratio取值为1-ξ,若ratio大于ξ,则ratio取值为ξ,若ratio位于(1-ξ,ξ)范围内,则ratio取值不变;
ξ是超参数,表示保留更新参数的比例,ξ取值在(0,1)范围内。
有益效果
与现有技术相比,本发明所达到的有益效果:
本发明利用构建的机器人的避障奖励函数、累计奖励函数、第一损失函数和第二损失函数对机器人预设的长短时程脉冲神经网络进行训练,进而得到训练完成的机器人自主避障网络,通过长短时程脉冲神经网络对机器人的状态信息留有历史记忆,短时间的干扰不影响网络的工作,机器人仍然能够按照前一时刻的运动趋势下决策,并且长短时程结构能够提高脉冲神经网络的记忆能力,保证了机器人自主避障导航的鲁棒性的同时,降低了计算量,提高了计算效率,解决了传统神经网络在面对突然出现的强光等干扰机器人感知的噪声时,会导致机器人无法对当前状态决策,避障计算量大,能耗高的问题。
附图说明
图1是本发明实施例提供的一种机器人自主避障方法的流程图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
实施例
如图1所示,一种机器人自主避障方法,包括:
构建机器人避障训练环境,开启导航任务;
初始化机器人预设自主避障网络、预设价值网络;其中,预设自主避障网络采用长短时程脉冲神经网络;
初始化机器人初始状态信息,机器人初始状态信息包括:机器人初始位置的雷达信号、线速度和角速度;
将机器人的初始状态信息归一化处理,获取预设自主避障网络的神经元输入,具体的:
计算遗忘门输出值f
f
其中:W
计算记忆门输出值i
i
其中:W
计算临时状态g
g
其中:W
计算当前时刻神经元的突出电流syn
syn
其中:syn
计算输出门的输出值o
o
其中:W
计算当前时刻神经元的膜电位mem
mem
将当前时刻神经元的突出电流syn
根据预设自主避障网络的神经元输入,获取机器人当前状态信息和下一时刻状态信息,具体的:
获取机器人当前时刻均值和方差;
根据当前时刻均值和方差,获取机器人当前状态信息,其中,当前状态信息包括当前时刻的线速度和角速度,其中:
将机器人初始状态信息归一化到[0,1]中,再通过泊松编码将神经元当前时刻的输入编码为脉冲;
将脉冲作为机器人的当前状态信息,输入至预设自主避障网络中,计算出当前时刻均值和方差,根据当前时刻均值和方差能获得一个新的正态分布函数,对正态分布函数进行采样能够获得机器人当前时刻的线速度和角速度;
基于机器人当前状态信息,通过避障奖励函数获取当前时刻的奖励,具体的:机器人的避障奖励函数包括:
其中:
d
d
d
机器人在获得当前时刻的线速度和角速度后,在训练环境中进行运动,判断机器人在运行过程中是否发生碰撞或到达预设终点;若是,则记录done=1,刷新机器人避障训练环境,开启新一轮导航任务;
若否,记录done=0,初始化机器人的状态信息并重新获取机器人当前状态信息和机器人下一时刻的状态信息;基于机器人当前状态信息,通过避障奖励函数获取当前时刻的奖励,判断机器人在运行过程中是否发生碰撞或到达预设终点,直到done=1。
将机器人在不同时刻的状态信息输入预设价值网络,获取机器人的状态评价;
基于获取到的奖励和机器人的状态评价,通过累计奖励函数获取累计奖励,具体的:累计奖励函数包括:
R=[R[0],R[1],…,R[T]];
R[t]=reward[t]+γ*reward[t+1]+γ
其中:
Post_value是下一时刻机器人的状态评价;
下一时刻机器人的状态评价的获取包括:将机器人下一时刻的状态信息输入预设价值网络中,得到下一时刻机器人的状态评价;
R是累计奖励由0到T时刻构成,0是当前时刻,T是最后一个时刻;
R[0]是当前时刻奖励,R[T]是最后一个时刻的奖励;
R[t]是R子项的展开表达;
γ是(0,1)内的折扣因子;
reward[t]是t时刻奖励。
基于状态评价,通过第一损失函数获取第一损失值,反向传播第一损失值更新预设价值网络,具体的:第一损失函数包括:
advantage=R-Value;
其中:R为累计奖励;
Value是累计状态评价,累计状态评价的获取包括:将所有获取到的的状态评价累加;
将advantage的均方差作为第一损失值。
基于累计奖励函数,通过第二损失函数获取第二损失值,反向传播第二损失值,更新预设自主避障网络,直到更新次数满足阈值,具体的:第二损失函数包括:
Loss=mean(min(ratio*advantage,advantage*clip(ratio,1-ξ,ξ);
其中:
ratio=P
将不同时刻机器人的状态信息所对应的动作合成,并将合成后的动作分别输入前一时刻的预设自主避障网络和当前时刻的预设自主避障网络,得到均值μ
clip(,,)表示截断的含义,clip(ratio,1-ξ,ξ)表示若ratio小于1-ξ,则ratio取值为1-ξ,若ratio大于ξ,则ratio取值为ξ,若ratio位于(1-ξ,ξ)范围内,则ratio取值不变;
ξ是超参数,表示保留更新参数的比例,ξ取值在(0,1)范围内。
得到训练完成的机器人自主避障网络;
获取目标机器人的初始点、目标点及障碍物的位置信息,采用训练好的机器人自主避障网络完成避障任务。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。