一种基于CPU-FPGA混合平台加速子图匹配方法
文献发布时间:2023-06-19 18:34:06
技术领域
本发明涉及子图匹配技术领域,特别涉及一种基于CPU-FPGA混合平台加速子图匹配方法。
背景技术
随着大数据时代的到来,越来越多的数据采用图结构来进行表示和存储。图能够表达数据对象之间复杂的关系,被广泛应用于社交网络、Web 网络、物质结构、交通运输、城市规划、医疗信息等领域。因此,图数据处理在当今生活中变得越来越重要,同时随着人类社会信息化程度的提高,这些领域产生的图数据以爆炸式的速度增长。如截止到2021年,社交网络Facebook用户超过30亿,好友关系数超100亿条。子图匹配广泛应用于图数据库查询、分子交互网络分析、推荐系统、社交网络分析、生物数据分析等。
子图匹配问题的求解是给出查询图q,从数据图G中找到所有与查询图结构相同且节点标签相同的所有子图。例如,在附图1中,给定数据图G和查询图q,{(u0,ν0),(u1,ν3),(u2,ν4),(u3,ν12)}是q到G的一个子图匹配。然而,计算所有的子图匹配是NP难问题,尤其是在大图上查找所有子图嵌入。因此如何高效地解决子图匹配问题是目前亟待解决的问题。
现有技术中在CPU上的大多数子图匹配方法多是基于回溯的方法,即递归的进行部分嵌入通过映射查询顶点到数据顶点。该方法受限于通用CPU的设计特征,这种顺序解决方案在处理大量图数据时表现出了不理想的响应时间和较差的扩展性。另外基于通用CPU的单指令、多数据(SIMD) 的指令级并行在对图数据处理的高度并行性方面也表现不够灵活,以及通用CPU在不规则图的数据局部性约束方面也不够有效。
与CPU和GPU固定体系架构不同,Field Programmable Gate Arrays(FPGA)是可重新配置的计算平台,其计算引擎可由用户根据应用特点进行灵活定义,同时不需要与使用专用集成电路(ASIC)生产相关的时间开销和生产成本。FPGA芯片上包含许多资源,可以帮用户进行自定义应用的设计,如自适应逻辑模块(alm),内存块(BRAM),用于数字信号处理的嵌入式乘法器等,以及其他外设接口,如外部存储器(DDR,HMC 等)和外设组件互连快速接口(PCIe)。在FPGA上“执行”软件时,其执行方式与在CPU和GPU上执行已编译和汇编的指令的意义不同,取而代之的是,数据流经过与软件中表达的操作相匹配的FPGA上定制的深层流水线。由于数据流管道硬件与软件匹配,因此消除了控制开销,从而提高了性能和效率。另外FPGA的并行性可以实现数据并行性(SIMD),任务并行性(多个流水线)和超标量执行(并行执行的多个独立指令)与流水线并行性一起使用,从而达到最佳的并行性能。同时,与GPU和CPU对比,由于FPGA的低功耗特性,FPGA具有更好的能效比。因此FPGA提供了一种在硬件级的计算加速的可替代方案,与CPU相比,FPGA在并行性方面显示了巨大的优势。与GPU相比,FPGA在功耗方面显示了巨大的优势。
在工业界,FPGA已经被应用于实现复杂系统加速。例如,微软使用FPGA来加速Bing搜索和Azure机器学习。FPGA也被云服务器提供商推出来加速云服务器,如Amazon,Alibaba,Tencent,Huawei等。在学术界,FPGA被用加速各种不同的研究问题,包括许多图处理问题,AI加速等。
而子图匹配的枚举阶段是一个计算密集型的任务,那么如何充分利用 FPGA的流水线机制、数据流机制来达到FPGA的空间数据并行和时间数据并行,以加速子图匹配的枚举任务,从而高效地解决子图匹配问题。
发明内容
针对上述问题,本发明提出了一个根据数据图稠密自动选择匹配顺序的混合子图匹配算法,以及基于CPU-FPGA协同架构,利用FPGA的流水线机制和低功耗特征来加速子图匹配。
为了实现上述目的,本发明所采用的技术方案如下:
一种基于CPU-FPGA混合平台加速子图匹配方法,其特征在于,包括以下步骤:
步骤1:输入数据图和待查询的查询图至CPU端内存中;
步骤2:基于CPU-FPGA的协同混合架构进行子图匹配,从给定的数据图中找到所有与查询图结构相同且节点标签相同的所有子图,其包括以下三个阶段:
第一阶段,CPU端作为主机端,根据数据图和查询图生成候选顶点集并通过LDF和NLF规则进行过滤,再利用CFL方法构建辅助数据结构;
第二阶段,CPU端根据数据图的稠密性选择GQL方法或RI方法生成查询匹配顺序;
第三阶段,根据候选顶点集、辅助数据结构和查询匹配顺序在CPU 端和FPGA端分别进行子图匹配枚举,将CPU端和FPGA端结果进行汇总得到最终的子图匹配结果;
步骤3:输出最终的子图匹配的嵌入结果。
进一步地,所述第一阶段中候选顶点集和辅助数据结构的构建步骤为:
步骤201:对于给定的查询图q和数据图G,查询图q中的顶点u∈ V(q),数据图G的顶点v∈V(G),若(u,v)存在一个从图q到图G的对应匹配,则将顶点v加入候选顶点集,其中V表示顶点集合;
步骤202:使用LDF和NFL规则对候选顶点集进行过滤,得到过滤后的候选顶点集C(u);
步骤203:根据给定的查询图q,构建其BFS树qt;
步骤204:通过自上而下的方式逐级访问查询图q的顶点,找到对应数据图G中的顶点,从而构建辅助数据结构A,再利用CFL进行自底向上的细化,剔除无希望的候选点并在邻接表中删除那些不存在的顶点。
进一步地,所述第二阶段生成查询匹配顺序的步骤包括:
步骤301:若数据图为稠密图则选择GOL方法生成查询匹配顺序,转入步骤302;若数据图为稀疏图则选择RI方法生成对应的查询图的匹配顺序,转入步骤303;
步骤302:GOL方法:首先选择u’=arg minu∈V(q)|C(u)|作为匹配顺序§的开始顶点,然后GQL方法迭代的选择u’=arg minu∈N(§)-§|C(u)|作为匹配顺序的下一个顶点;
步骤303:RI方法:首先选择u’=arg maxu∈V(q)d(u)作为匹配顺序§。然后它迭代的选择u’=arg maxu∈N(§)-§|N(u)∩§|作为匹配顺序的下一个顶点。
进一步地,所述第三阶段子图匹配的步骤包括:
步骤401:在CPU端根据得到的匹配顺序采用基于交集的嵌入方法计算本地候选,得到相应的子图匹配结果;
步骤402:基于辅助数据结构和内核计算单元数将候选顶点集进行分区,将其分成多个区块,其中一块在CPU端执行,其余块在FPGA上执行,最终实现CPU端和FPGA端多计算单元的负载平衡;
步骤403:利用FPGA的空间数据并行设计多个计算单元来运行所述基于交集的嵌入方法中的枚举内核函数;利用FPGA时间数据并行设计使能Host-to-Kernel Dataflow;
步骤404:汇总FPGA端和CPU端子图匹配枚举结果。
进一步地,步骤402的具体操作步骤为:
步骤4021:确定分区因子k=min(k,|C(u);
步骤4022:从A的根顶点开始分区候选,若辅助数据结构A的根顶点数小于k,则沿着匹配顺序的下一个顶点的候选来继续分区,直至到达 A的最后一个顶点。
本发明的有益效果是:
第一,本发明提出了分阶段混合的子图匹配算法,其过滤候选顶点集使用LDF(thelabel and degree filter)和NLF(the neighborhood label frequency filter)来过滤映射顶点;构建辅助数据结构使用CFL方法;查询顶点顺序根据数据图的稀疏性选用GQL和RI,枚举子图匹配结果使用基于集合交集的方法。同时在枚举阶段根据数据图是稠密图还是稀疏图自动选择查询图匹配顺序,即稠密数据图选用GOL查询顺序方法,稀疏数据图选用RI查询顺序方法,能够解决子图匹配中枚举阶段的匹配速度问题。
第二,本发明提出了CPU-FPGA的协同混合架构来加速子图匹配,主机端(CPU)主要处理过滤候选顶点、构建候选顶点数据结构、构建查询匹配顺序、候选顶点数据划分和部分子图匹配枚举任务;内核端(FPGA) 主要处理子图匹配的枚举任务,能够明显加快子图匹配的枚举速度。
第三,本发明提出了候选顶点辅助数据结构集的分区划分方法,能够有效实现主机端和FPGA端多计算单元的负载平衡。
第四,本发明利用FPGA的空间数据并行(Spatial Data Parallelism) 和时间数据并行(Spatial Data Parallelism)的方法来加速子图匹配的枚举速度。
本发明通过大量实验在真实数据集和合成数据集上测试了我们混合子图匹配方法的性能,最终的实验结果显示了其性能突出于最先进的子图匹配方法。
附图说明
图1为给定的数据图G和查询图q,其中图1(a)为查询图q,图1 (b)为数据图G;
图2为辅助数据结构A的结构;
图3为GraphQL方法子图匹配时间情况;
图4为CECI方法子图匹配时间情况;
图5为GraphQL和CECI方法在子图匹配时CPU的使用情况;
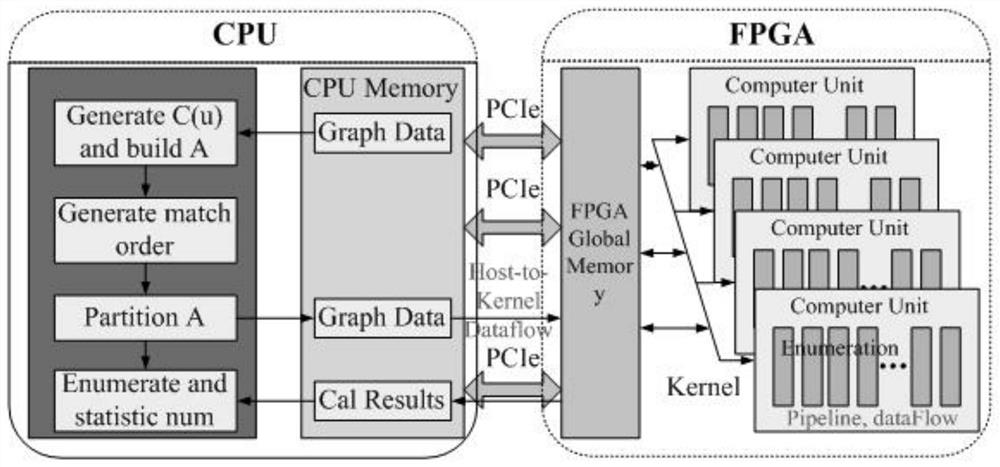
图6为本发明所提CPU与FPGA协同处理的系统结构图;
图7为辅助数据结构集示例,且由左至右分别为为原始辅助数据结构集A、A的第一层、A的第二层和A的第三层;
图8为Host-to-Kernel Dataflow的概念图;
图9为eu2005数据集枚举性能测试结果;
图10为Youtube数据集枚举性能测试结果;
图11为合成数据集SD05下枚举性能评估结果;
图12为合成数据集SD10下枚举性能评估结果;
图13为合成数据集SD15下枚举性能评估结果。
具体实施方式
为了使本领域的普通技术人员能更好的理解本发明的技术方案,下面结合附图和实施例对本发明的技术方案做进一步的描述。
一、以图、子图匹配为背景
定义1:一个图G被定义为一个元组G={V,E,∑V,L},其中,V代表图中顶点的非空集合,
定义2:无向图是指图中的每一个顶点都通过标签函数进行标签分配,而顶点之间的边是不存在方向的。无向图中的边是一个无序对,通常用圆括号来表示,如(u,ν)表示顶点u和顶点ν之间存在一条边,其中u,ν∈V,且(u,ν)等价于(ν,u)。
定义3:给定两个图G=(V,E,∑)和G’=(V’,E’,∑’),如果满足:
(1)
(2)
(3)
(4)
则称图G’是图G的子图。
定义4:给定一个数据图G(V,E,L),一个数据图Q=(V’,E’,L’),如果存在一个单射函数f:V’→V使得如下条件成立:
(1)
(2)
那么图Q是图G的一个子图同构的图,记为
基于上述定义,那么给定一个查询图q和一个数据图G,子图匹配就是从数据图G中找到与给定查询图q同构的所有子图。
本发明将一个子图同构映射称为一个子图匹配嵌入,那么假设一个查询图q是连通图并且查询图的顶点数|V(q)|≥3,找到单个顶点或者单个边的所有子图匹配的枚举过程如下:
例如,对于图1(a)中的查询图q和图1(b)中的数据图G,在图G中对于图q的所有子图匹配嵌入可以表示为:{(u
本发明关注的图为无向标签图G=(V,E,∑,L),其中V表示图的顶点集,E表示图的边集。给定顶点u∈V,N(u)表示顶点u的邻居顶点u’。标签图就是有一个标签函数L给顶点u(u∈V)分配一个标签l(l∈∑),d(u)表示图G中顶点u的度。在表1中给出了本发明的常用符号。
表1:常用符号
定义5:给定查询图q和数据图G,那么候选顶点集C(u)则是一个数据图的顶点集合,即u∈V(q),v∈V(G),如果(u,v)存在一个从图q到图G 的对应匹配,这样顶点v就属于C(u)中的一个顶点。
例子2:对于图1(a)中的查询图q和图1(b)中的数据图G,对应的BFS 树tq,候选顶点集C(u)和辅助数据结构A如图2所示。
对于给定查询图q和它的BFS树tq,在候选辅助数据结构A中,邻接顶点u和u
定义6:一个匹配顺序§就是查询图顶点集合V(q)的一个排列顺序,§[i]表示在匹配顺序§中的第i个顶点。§[i:j]表示从匹配顺序索引i到j的顶点集合(1≤i≤j≤|§|)。
下面的算法1描述了通用子图匹配算法分阶段流程。子图匹配算法的输入是查询图q和数据图G,输出是从q到G的所有匹配嵌入。基于回溯搜索的子图匹配算法可以分为以下几个阶段:输入数据图G和查询图q,过滤产生候选顶点集C(u),构建候选数据结构A,产生匹配顺序§,根据候选顶点集C(u)、候选数据结构A、匹配顺序§进行子图匹配枚举,输出所有子图匹配的嵌入结果。
算法1
二、基于CPU平台、GPU平台、FPGA平台的现有子图匹配的方法
1、基于CPU方法
现有的基于CPU的子图匹配算法分为三类:第一类子图匹配算法是基于直接枚举框架,它是通过搜索数据图G来枚举所有结果,如QuickSI、 RI、VF2++等算法。第二类算法是基于索引枚举框架,它是在数据图G上构建索引,然后在索引的帮助下完成所有的匹配查询,如GADDI、SPath、 SGMath等算法。第三类算法是基于预处理枚举框架,首先对查询数据图根据查询图顶点产生一个候选顶点集,并构建一个辅助数据结构来维护候选顶点集之间的边,然后产生查询图的一个查询匹配顺序集,最后,根据匹配顺序在辅助数据结构上枚举产生所有的匹配结果,如GraphQL、 TurboIso、CFL-Match、CECI、DP-iso等算法。同时,子图匹配算法也已经被广泛的研究在多核CPU平台上,例如VF3P,PGX.ISO,PSM等算法。
2、基于GPU方法
GPU体系结构是具有数十个多核流处理器,每个流处理器包含上百个单核处理器,因此具有大规模并行的优势。已经有许多子图匹配的算法是基于GPU平台的,利用GPU的并行性来加速子图匹配。例如:GpSM是工作在GPUs,并且以边作为基本单元,GpSM在验证阶段将候选边并行连接形成部分解,并且此过程被重复的构建,直到得到最终解。 GunrockSM运行在GPU平台中,采用二进制连接策略,收集查询图q的每条边的候选集,并将其连接起来以找到最终的匹配结果。GSI提出了一种预分配合并的方法,由过滤和拼接两部分组成,使用的是基于顶点拼接的策略,代替基于边拼接的策略,在拼接过程中,新结果可以先写入缓冲区中并保存起来,等待新的中间表分配好后,再把这些新结果写入到新的中间表中,通过这种方式,无需重做拼接过程,因此节省了大量的工作量,提高了整体性能。PBE是利用GPU加速子图的基于分区枚举方法,此方法将图形划分为多个分区,每个分区都适合GPU内存,GPU每一次处理一个分区,并且在分区中搜索给定模式的匹配子图就像在小图中一样。
3、基于FPGA方法
FPGA是由大量小型处理单元组成的阵列,其包含多达数百万个可编程的1位自适应逻辑块。因此具有深度流水线并行性和可重新配置的特性。 FPGAs提供了一种高效的能效比的解决方案为图处理应用提供专门的硬件。最近越来越多的研究者开发各种图算法和图处理框架应用在FPGA平台上。例如:MACIEJ提出使用FPGA加速子流中心最大匹配(Substream-Centric Maximum Matchings)。为了有效利用FPGA资源,提出了一种以子流为中心的方法,将输入的数据流分割成独立处理的子流,在降低通信成本的同时实现了更高的并行性。FAST利用一种CPU-FPGA 协同设计的体系结构,利用FPGA的流水线并行性在一台机器上加速子图的匹配。除了在FPGAs上加速这些通用图算法外,为了便于在FPGAs实施图算法应用,还有大量在FPGA上设计的通用框架,例如,ThunderGP, edge-centricparadigm,GraVF,GraphGen等。然而这些框架是基于以特定的编程模型(例如边中心、顶点中心)建立的,这限制了高度优化的子图匹配算法的实施。
三、本发明所提匹配方法
本发明首先测试了最先进的子图匹配算法各阶段在CPU上执行的时间。由于子图匹配算法枚举阶段是一个计算密集型的任务,因此设计了基于CPU-FPGA的协同混合架构来加速子图匹配并提出了一个分阶段混合的子图匹配算法。还实现了一个根据候选顶点辅助数据结构集的分区划分方法,以达到FPGA多计算单元负载平衡。通过设计FPGA多个计算单元,使能Host-to-Kernel Dataflow,枚举内核函数使用Loop pipeline、Loop Unrolling、dataflow、Function Inlining等优化技术来加速子图匹配。
子图匹配主要包括过滤候选顶点集、构建标签集、子图枚举三个阶段。为了分析三个阶段中哪个阶段资源耗费最多,故而分别测试子图匹配方法 GraphQL、CECI各个阶段的执行时间。在测试中数据图集使用HPRD,查询图分别使用含有8、16、32个顶点的稀疏图和稠密图。测试GraphQL 方法查询3*108个子图时,各个阶段花费的时间。图3显示了使用GraphQL 方法进行子图匹配时各个阶段的执行时间。测试CECI方法查询9*109 个子图时,各个阶段花费的执行时间。图4显示了使用CECI方法进行子图匹配时各个阶段的执行时间。
图3-4中的d_i、s_i,d代表周密图(d(q)≥3)、s代表稀疏图(d(q)<3), i表示查询图顶点数。从测试结果中可以很明显地看到,不管是稀疏图和还是稠密图,使用GraphQL、CECI方法,子图匹配的枚举过程的执行时间都是最长的,占所有阶段执行时间的99%以上。
并且本发明还测试了使用GraphQL和CECI方法在子图匹配时CPU 的使用情况,这里数据图使用HPRD数据集,查询图使用d_32。图5显示了使用GraphQL和CECI方法执行子图匹配时CPU的使用情况。
测试结果显示,在子图匹配的开始阶段CPU使用率较低,但是一进入的子图匹配的枚举阶段,CPU的使用率非常高,占据了90%以上的CPU 资源。从以上实验可知,在子图匹配中,各算法的枚举阶段占用CPU时间最长,且需要CPU资源最多。
基于上述分析,本发明提出了CPU与FPGA协同处理的系统架构,主机端为通用CPU,主要用来生成候选顶点集C(u),构建辅助数据结构A、生成查询图匹配顺序、候选顶点辅助数据结构集的分区划分、C(u)分块后其中的部分顶点数据结构集的子图匹配枚举,计算结果统计等。
内核端即FPGA加速卡,主要用于对子图匹配的枚举函数进行加速。 FPGA与CPU之间通过PCIe进行通信。本系统的整体架构如图6所示。
当进行子图匹配时,将一个数据图和一个查询图首先读入CPU端内存中,系统的整体执行流程为:
(1)CPU端根据数据图和查询图,基于LNF和NLF规则过滤生成候选顶点集,使用CFL方法构建候选辅助数据结构A;
(2)在CPU端,根据数据图的稀疏性,生成相应的查询图匹配顺序。在枚举阶段根据数据图是稠密图还是稀疏图自动选择查询图匹配顺序,稠密图选用GOL查询顺序方法,稀疏图选用RI查询顺序方法;
(3)基于构建好的候选辅助数据结构A和内核计算单元数,将A划分为多个数据集,实现主机端和FPGA端多计算单元的负载平衡;
(4)利用FPGA的空间数据并行设计多个计算单元来运行子图匹配的枚举内核函数;利用FPGA时间数据并行设计使能Host-to-Kernel Dataflow,内核枚举函数使能Looppipeline、Loop Unrolling、dataflow、 Function Inlining等来有优化枚举加速。
(5)最后,CPU将汇总FPGA端的枚举内核函数枚举出的子图匹配结果和CPU端的部分顶点数据结构集的子图匹配结果相累加,最终输出输入的数据图中与输入的查询图同构的所有子图匹配结果。
下面介绍分阶段混合的子图匹配算法。包括候选顶点过滤方法和辅助数据结构构建,查询匹配顺序方法,枚举方法和分阶段混合方法的整体流程。
1、生成C(u)和构建A
根据查询图和数据图生成候选顶点集C(u),使用LDF(the label and degreefilter)和NLF(the neighborhood label frequency filter)对C(u)进行候选顶点集过滤,LDF是标签和度的规则,要求顶点标签值要相同,v的度要大于等于u的度;NLF是邻居标签频率规则,要求v的邻居标签频率要大于等于u的标签频率,从而得到过滤后的候选顶点集。
构建辅助数据结构A时选用CFL方法构建,其采用自顶向下构建的方式逐级访问查询图的顶点,找到对应数据图G中的顶点,从而构建出辅助数据结构A,即辅助数据结构A包含了查询图q中的所有顶点对应的 C(u),例如查询图q有三个顶点u1、u2、u3,那么就有三个候选顶点集 C(u1)、C(u2)、C(u3),这三个候选顶点集就会构成辅助数据结构A。
辅助数据结构A自顶向下构建的过程包括三个阶段:前向候选生成(以前向处理的方式生成候选集合);后向候选剪枝(在后向处理时对无希望的候选进行剪枝);构造邻接表(构造数据图中与查询顶点及其父结点相对应的邻接表)。最后,CFL进行自底向上的细化,包括候选细化和邻接表剪枝。
2、查询顺序方法
根据数据图的稠密性自动选择GQL方法或者RI方法。稠密数据图选用GOL方法来产生查询匹配顺序,稀疏数据图选用RI方法来产生查询匹配顺序。然后在枚举阶段就使用相应的查询匹配顺序来进行枚举。下面介绍GQL和RI方法产生查询匹配顺序的算法思想。
GQL:GQL方法使用基于左深连接的方法,该方法将查询建模为一个左深连接树,其中叶子节点是候选顶点集。GQL方法首先选择u’=arg min
RI:RI方法根据查询图q的结构生成匹配顺序§。它首先选择u’=arg max
3、枚举方法
子图匹配过程中需要资源最多和执行时间最长的就是在枚举阶段。因此枚举阶段的算法优化是子图匹配加速的重中之重。在枚举阶段,采用算法1中递归枚举程序来找到所有的匹配嵌入结果。在计算本地候选时采用基于交集的枚举技术(set intersectionbased embedding enumeration technique),集合求交的过程如算法2所示,根据查询图q的匹配顺序和辅助数据结构A进行枚举来得到最终的子图匹配结果。(The procedure ofset Intersection based show as Algorithm 2.)
算法2:使用基于交集的方法计算本地候选
4、分阶段混合方法
本发明子图匹配过程使用分阶段混合的算法,在生成候选顶点集C(u) 时使用LDF和NLF规则进行候选顶点集过滤,构建辅助数据结构集A使用CFL方法构建,生成查询顺序阶段,根据数据图的稠密度自动选用GQL 或RI方法来生成匹配顺序,枚举阶段选用基于集合交集的枚举方法,详细的分阶段混合方法如算法3所示。
算法3:分阶段混合算法
5、辅助数据集分区
为了实现FPGA内核中各计算单元和CPU之间的辅助数据结构集的负载均衡,采用算法4介绍的分区策略:第一步是确定分区因子k,接下来为了分区辅助数据结构集A,我们从A的根顶点开始分区候选,如果A 的根顶点数小于k,我们沿着§顺序的下一个顶点的候选来继续分区。
算法4:APartition(A,C(u),k,§,i)
例子:如图7所示,原始辅助数据结构集如图7,这里假设k=3,首先分区根候选顶点为3部分:{v0},{v1},{v2},然后从辅助数据结构集A 中分别对根候选顶点一层一层挑选邻接顶点集。
总体来说,C(u)被分成几块,一块在CPU执行,FPGA上够多个计算单元,一个计算单元执行一块,各分区之间没有重复的搜索空间,因此分区间不会出现重复的枚举结果。同时分区可以使各计算单元更好的实现负载平衡。
6、FPGA内核设计
FPGA的深度流水线并行性、可重配置和低能耗特性,是用来进行对数据密集型运算加速的关键。而子图匹配的计算密集任务在于枚举阶段。因此内核函数的设计就是子图匹配的枚举函数。本发明利用FPGA的空间数据并行(Spatial Data Parallelism)和时间数据并行(Time Data Parallelism)来加速子图匹配的枚举阶段。空间数据并行是设计多个计算单元来运行子图匹配的枚举内核函数,整体设计结构如图6所示的内核端,其中计算单元的数目在实验中分别设置1,2,4,8,16来进行性能测试。子图匹配的枚举函数内核被编译成多个计算单元,在无序命令队列中, clEnqueueTask命令被多次调用,以实现数据并行。
利用FPGA时间数据并行设计使能Host-to-Kernel Dataflow。使能 Host-to-Kernel Dataflow可以进一步提高内核加速器的性能,它可以使内核仍在处理前一组数据时,而开始重新启动下一组新的数据。Host-to-Kernel Dataflow的概念图如图8所示。
内核从开始到结束处理一组数据所需的时间越长,使用主机到内核的数据流来提高性能的机会就越大。达到时间并行性,即同一个内核的不同阶段以流水线的方式处理来自多个clEnqueueTask命令的不同数据集。为了实现主机到内核的数据流,内核必须使用pragma HLS接口实现 ap_ctrl_chain协议。即在内核函数中通过#pragma HLS INTERFACEap_ctrl_chain port=return bundle=control指令来完成。
为了实现FPGA的深度流水线并行性,内核枚举函数使能Loop pipeline、LoopUnrolling、dataflow、Function Inlining等来有优化枚举加速。
在子图匹配的枚举阶段,循环是枚举匹配过程的重要实现方式。而循环优化技术是基于FPGA体系结构中流水线平行性高性能加速器的一个重要方面。在默认情况下,循环既不是流水线化的,也不是展开的。因此在枚举内核函数中的循环需要使用循环流水线和循环展开技术进行优化。具体实现就是在循环语句里面使用下面指令:
#pragma HLS PIPELINE//Loop Pipeline
#pragma HLS UNROLL//Loop unroll
在循环展开中,完全循环展开会消耗大量的设备资源,尤其是在循环迭代次数较大时。因此部分循环展开可以在使用较少硬件资源的情况下提高性能。部分循环展开的指令如下:
#pragma HLS UNROLL factor=n//n is a number
因此我们在枚举内核函数中首先使用循环流水线优化,同时循环中尽量使用小的循环体,以及有限的循环迭代展开(即定义factor=n),以进一步提高性能。
数据流优化是改善内核函数性能的一种强大的技术,可以在内核中支持任务级流水线并行来提高性能。它允许编译器调度内核的多个函数并发运行,以实现更高的吞吐量和更低的延迟。
实施例
本发明使用基于CPU-FPGA的混合平台来加速子图匹配,匹配算法使用分阶段混合的子图匹配算法,利用FPGA的流水线并行性枚举阶段。实验数据包括大量的真实数据集和合成数据集。下面详细介绍实验环境和数据集。
一、实验配置
实验环境:CPU端配置是AMD Ryzen Threadripper 3970X 32-Core Processor,CPU主频3.7GHz;核心数量:三十二核心;线程数:六十四线程;DDR内存128GB.
FPGA选用的Xilinx Alveo U250数据中心加速卡,它提供了1.3M LUTs, 11.5kDSP slices,64GB of DDR4内存(77GB/s总带宽),dual QSFP28 100Gbps网络接口,4320BRAM blocks,提供PCIe接口。
数据集:使用真实数据集合合成数据集来评估系统性能。
真实数据集:使用八个真实数据集:eu2005、Youtube、DBLP、Yeast、 Human、HPRD、WordNet、US Patents,这些数据集的特征如表2所示。数据集Yeast、Human、HPRD、WordNet是有标签数据集。对于无标签数据集,从标签集中随机的选择一个标签分配给一个顶点。
合成数据集:使用PaRMAT工具产生合成数据集,PaRMAT是一个多线程RMAT图形生成器。设置PaRMAT四个参数: a=0.45,b=0.15,c=0.15,d=0.25。因为在现实世界中的许多图中a:b和a:c的比值近似为3:1。同时随机的分配不同的标签到顶点集上。通过改变标签集|∑|从4到32,顶点集|V|从4M(million)到128M,度d从4到32。在实验中,默认使用的合成数据集是|V|=64M,d=16,|∑|=16。同时各自地改变 |V|、d、|∑|来测试算法和平台的扩展性。
改变|V|:我们合成产生5个数据图,分别地具有4M、16M、32M、 64M和128M个顶点。
改变|∑|:我们合成产生5个数据图,分别地具有不同的标签数为4、8、16、20、32。
改变d:我们合成产生5个数据图,分别地具有平均度为4、8、 16、20、32。
合成数据集详细的数据集特征如表3所示。
表2真实世界数据集的特征
表3合成数据集的特征
查询图:如前所述,随机地从每个数据图中抽取子图来生成查询图。从4到32改变查询图的顶点。对于各个顶点数目的查询图,顶点数为4 的查询图生成稠密查询图,其余顶点数的查询图均生成稀疏查询图,稠密查询图为d(q)≥3,稀疏查询图为d(q)<3。QiD和Qis分别表示稠密查询图和稀疏查询图包含i个顶点。查询图数据特征如表4所示。
表4查询图集的特点
二、实验结果
依据上述实验配置,利用本发明所提匹配方法进行匹配。
首先选择内核计算单元数n=4时,测试并比较基于CPU-FPGA的分阶段混合子图匹配算法与最先进得子图匹配算法GQL、CFL、CECI、DP-iso 的枚举性能。数据图分别选用eu2005,Youtube数据集,查询图分别使用 Q16D、Q32D和Q16S、Q32S,查询子图匹配数为9*109。评估结果如下:
基于内核计算单元数为4,在eu2005数据集上进行枚举性能评估,各算法的枚举性能比较结果如图9所示。
在eu2005数据集上,由于数据集在真实数据集中相对较大,因此我们的方法PH-CF枚举性能更佳。PH-CF方法对比CFL、CECI、DP-iso方法的枚举性能各自地最高加速比为16.07、38.61、11.46。从中可以看出 PH-CF方法的枚举性能相对比较稳定。
在Youtube数据集上进行枚举性能测试,各算法的枚举性能评估比较结果如图10所示。
在Youtube数据集上,查询9*109个子图匹配时,本发明方法PH-CF 对比CFL、CECI、DP-iso方法的枚举性能各自地最高加速比为5.16、5.87、 3.99。
接下来在合成数据集下进行性能评估。设置内核计算单元数n=4,合成数据集分别选用表3中的SD05、SD10、SD15数据集,查询图分别使用 Q16D、Q32D和Q16S、Q32S,查询9*1010个子图匹配,测试并比较CFL、 CECI、DP-iso算法和我们的算法PH-CF的性能。
在SD05数据集上进行枚举性能评估,各算法的枚举性能比较结果如图11所示。
在合成数据集SD05上,查询9*1010个子图匹配,评估结果显示我们的方法PH-CF对比CFL、CECI、DP-iso方法的枚举性能各自地最高加速比为4.08、4.67、3.16倍。
在合成数据集SD10上进行枚举性能评估,各算法的枚举性能比较结果如图12所示。在合成数据集SD10上,查询9*1010个子图匹配,评估结果显示我们的方法PH-CF对比CFL、CECI、DP-iso方法的枚举性能各自地最高加速比为2.78、3.41、3.78。
在合成数据集SD15上进行枚举性能评估,各算法的枚举性能比较结果如图13所示。在合成数据SD15上,查询9*1010个子图匹配,评估结果显示我们的方法PH-CF对比CFL、CECI、DP-iso方法的枚举性能各自地最高加速比为7.47、5.49、3.82。另外从评估结果中可以看出本发明的方法PH-CF在各种数据集的枚举性能的健壮性比较好,枚举时间比较稳定。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 一种基于同态加密和多项式计算的子图匹配方法
- 一种基于混合逻辑处理器平台的软件解密方法
- 一种基于CPU-FPGA内存共享的卷积神经网络加速器
- 一种基于CPU-FPGA内存共享的卷积神经网络加速器