用于估计受试对象的听觉能力的系统
文献发布时间:2024-05-31 01:29:11
技术领域
本申请涉及用于估计受试对象的听觉能力的系统。
本申请还涉及受试对象的听觉能力的估计方法。
本申请还涉及包括处理器和程序代码的数据处理系统,所述程序代码使得处理器执行本申请方法的至少部分步骤。
背景技术
一个版本的STM(谱-时调制,Spectro-Temporal Modulation)测试称为声频对比阈值(Audible Contrast Threshold,ACT)测试。在ACT测试中,听觉病矫治专家控制目标信号的对比电平(调制量)并控制在参考噪声序列内在哪些时间将该调制呈现给受试对象(例如患者)。
为确定该阈值,听觉病矫治专家以最高的对比电平开始并使用所谓的休森-维斯莱克(Hughson-Westlake)法[1]逼近该阈值。如果检测到目标刺激,对比电平降低两个阶位(递减逼近)。如果未检测到目标刺激,对比电平增大一个阶位(递升逼近)。该方法在递升逼近情形最近五次检测有三次对应于同一对比电平时停止。递升逼近时的检测值为所谓的阈值候选值,具有或没有反应的、包含最近五个阈值候选值的呈现为阈值候选窗口(threshold candidate window,TCW)。最终的ACT对应于心理测量函数的、适合TCW中包含的试验的特定点。
已表明该测试在语音测试中能准确地预测配备助听器的个人听力受损(HI)听者的语音接收表现[2]。
然而,使听觉病矫治专家进行该测试,听觉病矫治专家必然必须将其注意力聚焦于设备而较少聚焦于受试对象。
因此,需要优化该测试使得听觉病矫治专家至少部分摆脱操作该测试/设备。
发明内容
本申请致力于实施用户操作的ACT(UACT)测试,其不需要例如听觉病矫治专家/听力护理专家(HCP)来进行该测试,因而导致听觉病矫治专家/听力护理专家有更多时间服务于受试对象。
在本申请的一方面,提供用于估计受试对象的听觉能力的系统。
例如,该系统可适合评价受试对象的阈上(听得见的)听觉能力。
该系统包括具有变换器的至少一输出单元。
(声学)输出单元配置成经所述变换器将至少一刺激提供到受试对象的耳朵内。
例如,变换器可包括用于将刺激作为声学信号提供给受试对象的接收器(扬声器)。
该系统包括用于检测受试对象输入(即来自受试对象的反应)并向受试对象提供输出的受试对象接口。
该系统包括配置成产生所述至少一刺激的刺激发生器。
刺激发生器配置成根据测试协议提供多个相继的试验,其中测试协议被创建来估计受试对象的听觉能力,每一试验包括两个参考刺激和一个测试刺激,测试刺激根据所述测试协议或为目标刺激或为参考刺激。
受试对象输入包括两个二选一选项:一个对应于目标刺激,另一个对应于参考刺激。
术语对应于目标刺激和对应于参考刺激可分别指用于估计/指明刺激为目标刺激的选项和用于估计/指明刺激为参考刺激的选项。
例如,这些选项(例如屏幕上的区域例如按钮)可对应于目标和参考(即说明“目标”和“参考”),或者可说明“是”和“否”,等等。
例如,受试对象必须指明测试刺激(例如第二刺激)是参考刺激还是目标刺激。
刺激发生器可配置成响应于检测到的受试对象输入提供下一试验。
该系统包括用于分析所提供的试验中的每一个与后续受试对象输入之间的对应的分析单元,其中分析单元配置成根据分析的对应调整所述测试协议。
从而,提供使听觉病矫治专家/HCP进行测试的需要最小化或者最好消除的UACT测试,因而导致他们有更多时间服务于受试对象。
例如,由于听觉病矫治专家不是获得UACT的过程的一部分,测试协议应优选考虑下面几点:
1、受试对象的任务应容易;
2、测试协议应针对受试对象的表现、交替的高于阈值的刺激和低于阈值的刺激而调整难度;
3、测试协议应包括“捕捉试验”作为针对受试对象的表现的控制;
4、测试协议应包括基于听觉病矫治专家使用人工ACT时观察到的行为的“人类智力”。
例如,该方法应在不多于25次的试验中(不包括可能的、其中测试刺激为参考刺激的试验即捕捉试验)提供可靠且有效的阈值估计量。
测试协议可分为至少两个阶段。
至少两个阶段可包括测试前协议和实际测试协议。
例如,测试前协议可在开始实际测试协议之前进行以获得受试对象的听觉能力的(初步)估计。
例如,可进行实际测试协议以基于所述(初步)估计来估计受试对象的(实际)听觉能力。来自测试前协议的估计可在实际测试协议整个过程期间更新。
目标刺激可包括谱-时调制的音频信号。
谱-时调制的音频信号的调制深度可定义目标刺激的对比电平(contrast level,CL)。
目标刺激可包括组合的测试音频信号和噪声音频信号。
测试音频信号与噪声音频信号之间的声压级可定义目标刺激的信噪比(SNR)。
参考刺激可定义未经调制的音频信号。
参考刺激可包括噪声音频信号。
分析单元配置成根据分析的对应调整所述测试协议可包括自适应更新估计的听觉能力。
刺激发生器可配置成提供目标刺激的在下述之间交替的CL:
-高于受试对象的估计的听觉能力的CL;及
-低于受试对象的估计的听觉能力的CL。
刺激发生器可配置成提供目标刺激的在下述之间交替的SNR:
-高于受试对象的估计的听觉能力的SNR;及
-低于受试对象的估计的听觉能力的SNR。
估计的听觉能力可响应于受试对象输入而自适应更新,其中肯定的受试对象输入等于识别到所述目标刺激或所述参考刺激。
估计的听觉能力可响应于受试对象输入而自适应更新,其中否定的受试对象输入等于未正确识别所述目标刺激或所述参考刺激。
例如,用于获得所述阈值的方法包括所谓的捕捉试验,其中测试刺激(例如第二刺激)为参考刺激。受试对象预期指明其不是目标刺激。
例如,如果受试对象而是指明他/她听见了目标刺激,可在受试对象接口上显示否定的反馈来表明受试对象输入不正确。
受试对象接口可配置成响应于肯定的受试对象输入而向受试对象提供测试结果形式的输出。
受试对象接口可配置成响应于否定的受试对象输入而向受试对象提供测试结果形式的输出。
分析单元可配置成基于一个或多个先前确定的受试对象输入来确定所述测试刺激。
对于所述试验中的N个,测试刺激可以是目标刺激;对于所述试验中的M个,测试刺激可以是参考刺激。
数N>数M。
测试协议可提供试验的数量N和M的随机分布。
换言之,测试协议可提供所述目标刺激和所述参考刺激的随机分布。
每一测试协议之前可以是测试前协议。
在每一测试协议开始时:
-首先,刺激发生器可配置成提供第一试验和第二试验,其中第一试验可包括测试刺激为目标刺激,第二试验可包括测试刺激为参考刺激;及
-其次,对于固定的多个试验,刺激发生器可配置成提供所述目标刺激的CL,该CL通过下述方式进行调整:
--在肯定的受试对象输入之后减小CL;及
--在否定的受试对象输入之后增大CL。
在每一测试协议开始时:
-首先,刺激发生器可配置成提供第一试验和第二试验,其中第一试验可包括测试刺激为目标刺激,第二试验可包括测试刺激为参考刺激;及
-其次,对于固定的多个试验,刺激发生器可配置成提供所述目标刺激的SNR,该SNR通过下述方式进行调整:
--在肯定的受试对象输入之后减小SNR;及
--在否定的受试对象输入之后增大SNR。
响应于两个以上受试对象输入对应于目标刺激,分析单元可配置成调整所述测试协议以包含
-刺激发生器使得当前(即下一)试验包括测试刺激为参考刺激;及
-相继的试验包括测试刺激为目标刺激,相较于以前的包括目标刺激的试验具有减小的CL。
例如,相继的试验可包括测试刺激为具有比当前阈值估计量减小6dB nCL的CL的目标刺激。
响应于两个以上受试对象输入对应于目标刺激,分析单元可配置成调整所述测试协议以包含
-刺激发生器使得当前(即下一)试验包括测试刺激为参考刺激;及
-相继的试验包括测试刺激为目标刺激,相较于以前的包括目标刺激的试验具有减小的SNR。
例如,相继的试验可包括测试刺激为具有比当前阈值估计量减小6dB的SNR的目标刺激。
例如,这可看作患者连续多次回答“是/目标”,表明这对他们而言太容易或者他们刚刚撒谎。则首先提供参考刺激,检查他们是否正注意该测试,之后为具有减小的CL/SNR的目标刺激,检查是否远离阈值,该过程可被校正。
例如,两个以上受试对象输入可指2个、4个、6个或另一数量的输入。优选地,其可以是响应于4个受试对象输入。
受试对象输入对应于目标刺激可指受试对象指明测试刺激为目标刺激。
受试对象输入对应于参考刺激可指受试对象指明测试刺激为参考刺激。
响应于两个以上连续同样的受试对象输入对应于参考刺激,分析单元可配置成调整所述测试协议以包含
-刺激发生器使得当前试验包括相较于以前的包括目标刺激的试验具有增大的CL的目标刺激。
例如,当前试验可包括具有高于当前阈值估计量6dB nCL的CL的目标刺激。从而,帮助受试对象记住目标刺激听起来像什么。
响应于两个以上连续同样的受试对象输入对应于参考刺激,分析单元可配置成调整所述测试协议以包含
-刺激发生器使得当前试验包括相较于以前的包括目标刺激的试验具有增大的SNR的目标刺激。
例如,当前试验可包括具有高于当前阈值估计量6dB的SNR的目标刺激。从而,帮助受试对象记住目标刺激听起来像什么。
例如,两个以上连续同样的受试对象输入可指2个、4个、6个或另一数量的输入。优选地,其可以是响应于4个连续同样的受试对象输入。
分析单元可配置成从源自多个目标刺激的CL的心理测量函数估计受试对象的声频对比阈值或噪声中听力阈值。
分析单元可配置成从源自多个目标刺激的SNR的心理测量函数估计受试对象的声频对比阈值或噪声中听力阈值。
分析单元可包括神经网络。分析单元可配置成使用所述神经网络估计受试对象的声频对比阈值或噪声中听力阈值。
分析单元可基于贝叶斯理论。该方法可配置成将下一目标刺激的CL或SNR选择为具有更多信息增益的电平[3]。
应用
一方面,提供上面描述的及权利要求中限定的系统的应用。
方法
一方面,本申请还提供受试对象的听觉能力的估计方法。
该方法包括经至少一输出单元的变换器将刺激发生器根据测试协议产生的多个相继的试验提供到受试对象的耳朵内。
测试协议可基于受试对象的估计的听觉能力。
每一试验包括两个参考刺激和一个测试刺激。
因而,每一试验可包括三个一组的三个刺激。
例如,第一和第三刺激可始终为参考刺激(例如未经调制的噪声信号),而第二刺激可以是参考刺激或者目标刺激(例如谱-时调制的噪声信号)。
该方法包括经受试对象接口检测受试对象输入。
该方法可包括通过刺激发生器响应于检测到的受试对象输入而提供一试验。
测试刺激根据所述测试协议或为目标刺激或为参考刺激。
受试对象输入包括两个二选一的选项:一个对应于目标刺激,另一个对应于参考刺激。
该方法包括通过分析单元分析所提供的试验中的每一个与后续受试对象输入之间的对应。
该方法包括通过分析单元根据分析的对应调整所述测试协议。
该方法还可包括在开始所述测试协议之前进行的测试前协议中(初步)估计受试对象的听觉能力。
(初步)估计可在所述测试协议的整个过程中更新。
当由对应的过程适当代替时,上面描述的或权利要求中限定的系统的部分或所有结构特征可与本发明方法的实施结合,反之亦然。方法的实施具有与对应系统一样的优点。
计算机可读介质或数据载体
本发明进一步提供保存包括程序代码(指令)的计算机程序的有形计算机可读介质(数据载体),当计算机程序在数据处理系统(计算机)上运行时,使得数据处理系统执行(实现)上面描述的及权利要求中限定的方法的至少部分(如大部分或所有)步骤。
计算机程序
此外,本申请提供包括指令的计算机程序(产品),当该程序由计算机运行时,导致计算机执行上面描述的及权利要求中限定的方法(的步骤)。
数据处理系统
一方面,本发明进一步提供数据处理系统,包括处理器和程序代码,程序代码使得处理器执行上面描述的及权利要求中限定的方法的至少部分(如大部分或所有)步骤。
辅助设备
另一方面,提供包括上面描述的及权利要求中限定的系统以及包括辅助设备的系统。
该系统可适于在其操作员设备(例如包括分析单元和/或信号发生器)与辅助设备(例如包括受试对象接口)之间建立通信链路以使得信息(例如控制和状态信号)可进行交换或者从一设备转发给另一设备。
该系统可适于在其操作员设备与音频设备(例如包括输出单元,如耳机和/或耳麦)之间建立通信链路以使得信息(例如刺激)可进行交换或者从一设备转发给另一设备。
辅助设备可包括遥控器、智能电话或者其它便携电子装置如平板电脑等。
通信链路可以是有线或无线链路,例如基于蓝牙或一些其它标准化方案的通信链路。
APP
另一方面,本发明还提供称为APP的非短暂应用。APP包括可执行指令,其配置成例如在辅助设备上运行以实施上面描述的及权利要求中限定的受试对象接口。该APP可配置成在遥控器、智能电话或其它便携电子装置如平板电脑等上运行,从而使能与操作员设备通信。
附图说明
本发明的各个方面将从下面结合附图进行的详细描述得以最佳地理解。为清晰起见,这些附图均为示意性及简化的图,它们只给出了对于理解本发明所必要的细节,而省略其他细节。在整个说明书中,同样的附图标记用于同样或对应的部分。每一方面的各个特征可与其他方面的任何或所有特征组合。这些及其他方面、特征和/或技术效果将从下面的图示明显看出并结合其阐明,其中:
图1示出了用于测试受试对象的听觉能力的系统;
图2示出了测试受试对象的听觉能力的方法的流程图;
图3示出了改良的休森-维斯莱克(Hughson-Westlake)法的流程图;
图4A和4B示出了心理测量函数(Ψ)与信息增益函数(IG)之间的关系;
图5示出了包括25次试验的测试协议的发展过程。
通过下面给出的详细描述,本发明进一步的适用范围将显而易见。然而,应当理解,在详细描述和具体例子表明本发明优选实施例的同时,它们仅为说明目的给出。对于本领域技术人员来说,基于下面的详细描述,本发明的其它实施方式将显而易见。
具体实施方式
下面结合附图提出的具体描述用作多种不同配置的描述。具体描述包括用于提供多个不同概念的彻底理解的具体细节。然而,对本领域技术人员显而易见的是,这些概念可在没有这些具体细节的情形下实施。系统和方法的几个方面通过多个不同的块、功能单元、模块、元件、步骤、处理、算法等(统称为“元素”)进行描述。根据特定应用、设计限制或其他原因,这些元素可使用电子硬件、计算机程序或其任何组合实施。
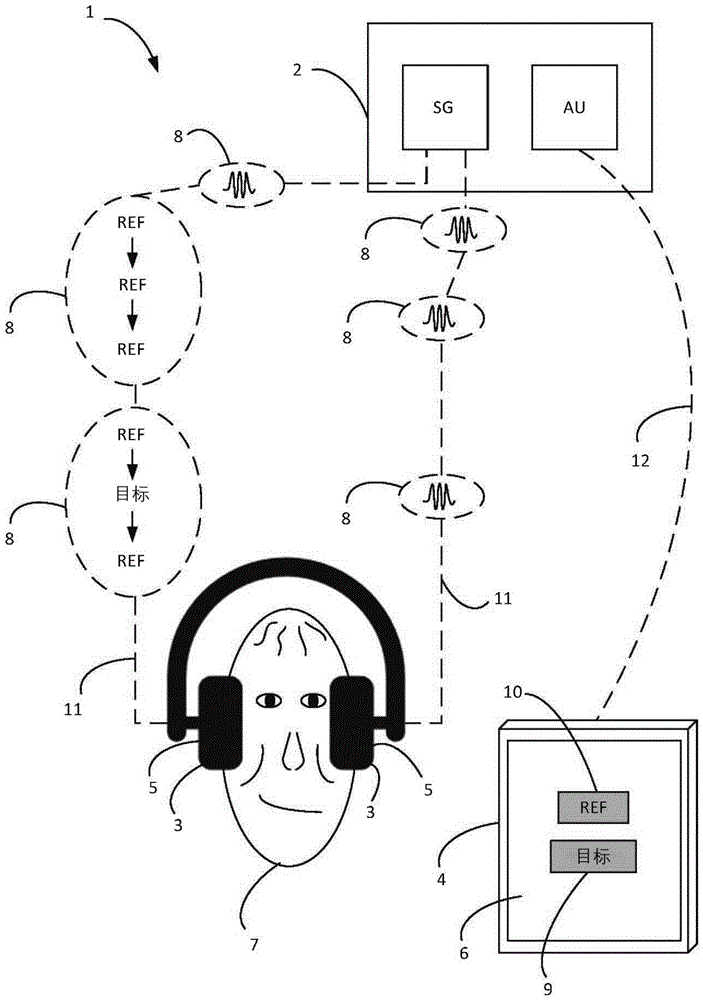
图1示出了用于测试受试对象的听觉能力的系统。
在图1中,示出了系统1可被分为一个以上设备。然而,可以预见,系统1可以仅为一个设备。因而,可以预见,刺激发生器SG和分析单元AU中的一个或两个可包含在音频设备如耳机内。
因而,系统1被示为包括操作员设备2、音频设备3和辅助设备4。
操作员设备2可包括刺激发生器SG和分析单元AU。
音频设备3可包括至少一输出单元5。在图1中,示出了两个输出单元。
辅助设备4可包括受试对象接口6。
刺激发生器SG可配置成产生至少一刺激并将至少一刺激传给音频设备3。
刺激发生器SG被示为配置成根据测试协议提供多个相继的试验8。在图1中,示出了拟呈现给音频设备3的两个输出单元5中的每一个的三个相继的试验8。然而,测试协议可包括呈现几个相继的试验8,例如20、25、30个试验(包括捕捉试验)。
刺激发生器SG可经有线或无线连接11将试验8传给音频设备3。
每一试验8可包括两个参考刺激REF和一个测试刺激,测试刺激根据测试协议或为目标刺激“目标”或为参考刺激REF。在图1中,呈现给受试对象的第一个试验8包含参考-目标-参考的三个一组刺激,随后的第二个试验8包含参考-参考-参考的三个一组刺激(所谓的捕捉试验)。
例如,当测试声频对比阈值时,目标刺激可以是调制的刺激(不是组合),调制深度根据测试协议变化,其按CL定义。
例如,作为替代,在测试噪声情形下的听力时,目标刺激为测试音频信号+噪声音频信号的组合,测试音频信号的电平根据测试协议变化,阈值按SNR定义。
在图1中,音频设备3被示为放在受试对象7的两只耳朵处的耳机,但音频设备3可仅放在耳朵之一处/中,作为替代,可使用其它耳麦或包括变换器的其它设备。音频设备3的两个输出单元5(中的每一个)可包括变换器,声学输出单元5中的每一个可配置成经变换器将至少一刺激提供到受试对象7的耳朵内。因而,相继的试验8可被传到音频设备3,输出单元5中的每一个可经所述变换器将试验8的刺激呈现到受试对象7的耳朵内。
在图1中,辅助设备4被示为平板电脑,但也可使用其它(例如便携)设备。辅助设备4的受试对象接口6可配置成检测受试对象7输入的受试对象输入并向受试对象7提供输出。
受试对象输入可包括两个二选一的选项,一个选项对应于目标刺激,例如在受试对象7确定当前试验中的目标刺激时可按压目标按钮9“目标”,另一选项对应于参考刺激,例如在受试对象7确定当前试验中的参考刺激时可按压参考按钮10“REF”。
刺激发生器SG可配置成响应于检测到的受试对象输入而提供/设计下一试验8。
分析单元AU可适合分析所提供的试验8中的每一个与后续通过辅助设备4检测到的受试对象输入之间的对应。
分析单元AU可配置成根据分析的对应而调整测试协议。
辅助设备4与分析单元AU之间可存在通信链路12,使得可来回传输信息。例如,辅助设备4可将受试对象输入传给分析单元AU。分析单元AU可传输拟在受试对象接口6上呈现给受试对象7的输出。
图2示出了测试受试对象的听觉能力的方法的流程图。
图2呈现了用于测试听觉能力的总体过程,换言之,测试协议。该过程的部分分开的步骤将在后续的图中进一步详细描述。
图2中所示的测试协议分为两个阶段:测试前协议和实际测试协议。对于试验序号n
在测试协议的起始(步骤“开始”),第n个试验(三个一组刺激)或为其中测试刺激为目标刺激的试验或为其中测试刺激为参考刺激的试验(步骤“捕捉试验?”)。
在第n个试验为捕捉试验的情形下,该试验按参考-参考-参考的三个一组呈现(步骤[1])。之后,受试对象给出反应(步骤[2])。捕捉试验在开始该方法时随机分配到间隔开4到8个试验的试验。对捕捉试验的受试对象输入被存储,因为其可以是测试协议的可靠性的标示。
捕捉试验不被计数为实际测试协议的n个试验之一。因而,第n个试验被再次呈现。在第n个试验不是捕捉试验的情形下,调整目标刺激的CL(步骤[3]),且该试验被呈现给受试对象(步骤[4])。在后续步骤(步骤[5]+[6])中,收集反应(即受试对象输入)并更新概率。
对于第n个试验,其中n 在n>NPre时,开始实际测试协议。在实际测试协议期间,自适应更新在测试前协议中估计的听觉能力。 对于第n个试验,每一可能的阈值(th 基于贝叶斯理论,我们可简化下面的等式: p(λ 其中,λ 为了简化,概率可理解为: 后验=似然x先验 这样,后验概率为似然p(r 在第一试验时,先验概率相同,这样,概率P(th th sl 对于第n个试验,最近K个试验的CL和反应用于计算似然。在该方法中,我们利用k=[n-1,n],这意味着使用当前n及在前n-1反应进行计算。然而,在第一试验时,k=[n],因为仅仅已呈现一个试验。 考虑一般的心理测量函数: 阈值和斜率的每一可能值的似然(likelihood)计算为: k=[n-1,n] 因此,后验概率则计算为先验矩阵和似然矩阵的项与项的积。 后验=先验⊙似然 因此,在本申请中,最后两次试验(n-1,n)用于更新概率。 阈值(λ 获得阈值和斜率估计量的步骤[8]可从后验概率通过估计参数λ α,β=argmax(后验) λ λ 基于使用人工管理的ACT测试获得的经验,先前阐述的测试协议的一些例外被包括为步骤[10]。 例外总结为系统基于最近的X个反应可采取的两个行动:额外的捕捉试验或者高于阈值的呈现。 例如,系统可使用X=4,这样,χ=[n-3,n]。 额外的捕捉试验:系统默认可考虑4-5个捕捉试验随机分配到其间具有4-8个试验的特定试验序号。另外可以是两倍: a)第一捕捉试验可总是为试验序号2。从而,第一试验将呈现完全调制的目标刺激,第二试验为参考刺激(作为测试刺激)。这意味着有助于受试对象产生他们自己的内部表示; b)每当非捕捉试验中X个相继受试对象输入对应于目标刺激(例如“是”或者“目标”反应),可添加额外的捕捉试验。如果受试对象系统地按压按钮“目标”,可每隔一试验触发一捕捉试验。捕捉试验的数量高将指明不可靠的测试轮次; c)在额外的捕捉试验之后,下一试验则可呈现低于当前阈值估计量(λ 高于阈值的呈现:如果受试对象在X个相继的试验中提供对应于参考刺激的输入(例如按压“REF”),下一试验可被呈现高于当前阈值估计量(λ 因而,除了自适应方法之外,基于听觉病矫治专家人工测试报告的经验的例外已包括在测试协议中。根据受试对象先前的反应,系统可触发额外的捕捉试验或者高于阈值的呈现以保持受试对象的注意力并确保一致的表现。 图3示出了改良的休森-维斯莱克(Hughson-Westlake)法[1]的流程图。 如果受试对象输入(步骤“反应”)正确(步骤“正确?”),下一CL即CL 如果CL 如果受试对象输入(步骤“反应”)不正确(步骤“正确?”),下一CL即CL 如果CL 图4A和4B示出了心理测量函数(Ψ)与信息增益函数(IG)之间的关系。 在本申请中,基于两个假设而使用简化的信息增益函数: 1)经历测试协议(例如进行是/否任务)的受试对象在被交替呈现稍高于(目前估计的)阈值和稍低于(目前估计的)阈值的刺激时更一致地保持他们的注意力; 2)心理测量函数的斜率控制这两个点(即稍高于阈值的刺激和稍低于阈值的刺激)之间的对比电平差异。 两个点可估计在心理测量函数的82%(即稍高于阈值)和18%(即稍低于阈值)。 为获得心理测量函数的82%点和18%点的估计量,首先必须计算心理测量函数关于斜率的导数: 信息增益(IG)函数则为针对th=λ 对于CL=th 对应的IG函数随心理测量函数的18%处的最小值而减小,及随82%处的最大值而增大。 在图4A和4B中,例示了心理测量函数(Ψ,实线)和信息增益函数(IG,虚线)怎样相关。 图4A示出了具有非常一致的受试对象反应的测试轮次,这样,最大值和最小值彼此接近,CL 图4B示出了其中CL 为使用所述两个点(即82%和18%)的交替呈现,最小值可在偶数试验时呈现,最大值在奇数试验时呈现。 这种方法的优点在于CL 如果在先前的试验中的反应不太一致,斜率将较小,步长较大。在所有N次试验结束时,声频对比阈值将源自适合数据的心理测量函数。由于该方法收集在18%和82%点估计的、许多试验的反应,所得的阈值相较其中许多呈现远低于或远高于18%或82%点的另一自适应方法更鲁棒且高效。重要的是,CL 图5示出了包括25次试验的测试协议的发展过程。 在图5的上部,示出了25次试验中的每一个的目标刺激的nCL。在6dB的虚线标示存储的阈值,其例如可能已在图5中所示的测试协议之前的测试前协议期间确定。 对于前四个刺激,受试对象提供识别到目标刺激的输入(由“+”标示)。对于每一步,nCL减小4dB(2个步长)。在第五个刺激,受试对象提供未识别到目标刺激的输入(由“.”标示),这也是后面三个刺激的情形。对于这些步中的每一个,CL增大2dB。受试对象在8dB的nCL时再次识别到目标刺激。其后,目标刺激在低于阈值的nCL和高于阈值的nCL之间波动。 在图5的下部,以适合测试数据的心理测量函数的形式示出了正确反应的百分比为nCL的函数。所得的声频对比阈值可从测试协议结束时的心理测量函数确定。如虚线所示,阈值估计为7.1dB。 当由对应的过程适当代替时,上面描述的、“具体实施方式”中详细描述的及权利要求中限定的装置和系统的结构特征可与本发明方法的步骤结合。 除非明确指出,在此所用的单数形式“一”、“该”的含义均包括复数形式(即具有“至少一”的意思)。应当进一步理解,说明书中使用的术语“具有”、“包括”和/或“包含”表明存在所述的特征、整数、步骤、操作、元件和/或部件,但不排除存在或增加一个或多个其他特征、整数、步骤、操作、元件、部件和/或其组合。应当理解,除非明确指出,当元件被称为“连接”或“耦合”到另一元件时,可以是直接连接或耦合到其他元件,也可以存在中间插入元件。如在此所用的术语“和/或”包括一个或多个列举的相关项目的任何及所有组合。除非明确指出,在此公开的任何方法的步骤不必须精确按所公开的顺序执行。 权利要求不限于在此所示的各个方面,而是包含与权利要求语言一致的全部范围,其中除非明确指出,以单数形式提及的元件不意指“一个及只有一个”,而是指“一个或多个”。除非明确指出,术语“一些”指一个或多个。 参考文献 [1]Carhart,R.,&Jerger,J.F.(1959).Preferred Method For ClinicalDetermination Of Pure-Tone Thresholds.Journal of Speech and HearingDisorders,24(4),330–345. [2]Zaar,J.,Simonsen,L.B.,Behrens,T.,Dau,T.,&Laugesen,S.(2019).Investigating the relationship between spectro-temporal modulationdetection,aided speech perception,and noise reduction preference.ISAAR. [3]Remus,J.J.,&Collins,L.M.(2008).Comparison of adaptive psychometricprocedures motivated by the Theory of Optimal Experiments:Simulated andexperimental results.The Journal of the Acoustical Society of America,123(1),315–326.https://doi.org/10.1121/1.2816567.
- 用于估计对象的部分事实含量的方法和系统
- 用于对受试对象血液内的物质浓度进行非侵入式测量的装置和方法
- 用于对受试对象血液内的物质浓度进行非侵入式测量的装置和方法