音乐处理系统、音乐处理程序以及音乐处理方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及一种音乐处理装置、音乐处理程序以及音乐处理方法,例如可运用于新的乐曲的制作。
背景技术
以往,作为辅助不具有制作乐曲用的知识的用户以便让他们也容易地生成乐曲的系统,例如有专利文献1的记载技术。
专利文献1记载的系统是一种通过用户的操作而在改变对原曲的改编程度的情况下辅助原曲的编曲的系统。在专利文献1记载的系统中,在利用发音时机除外的3个属性(音高、音长、音的大小)中的至少1个属性来定义音的状态时,会保持多个设定有从某一状态向下一状态的转变概率的转变概率数据。并且,在专利文献1记载的系统中,可以通过选择供选择的转变概率数据来改变原曲的改编程度,所以,即便是几乎没有音乐相关的知识的使用者也能在改变改编程度的情况下进行原曲的编曲。
现有技术文献
专利文献
专利文献1:日本专利特开2009-20323号公报
发明内容
发明要解决的问题
然而,在专利文献1的记载技术中,由于从转变概率数据的属性中去掉了发音时机,所以顶多只是对原曲进行了改编,难以说是在作曲。
因此,期望一种能在以原曲为输入的情况下生成新制作的曲子的音乐处理系统、音乐处理程序以及音乐处理方法。
解决问题的技术手段
第1本发明的音乐处理系统的特征在于,具有:(1)乐曲生成单元,其使用学习模型来生成乐曲,所述学习模型是根据包含乐曲数据和构成信息的输入数据进行机器学习得到的,所述乐曲数据记述有由1通道以上的旋律和1通道以上的和弦构成的乐曲的乐谱,所述构成信息表示构成所述乐曲数据的乐曲的要素的属性;以及(2)整形单元,其将所述乐曲生成单元所生成的生成乐曲整形为在音乐上和谐的内容。
第2本发明的音乐处理程序的特征在于,使计算机作为(1)乐曲生成单元和(2)整形单元发挥功能,所述(1)乐曲生成单元使用学习模型来生成乐曲,所述学习模型是根据具有学习用乐曲数据的学习用数据进行机器学习得到的,所述学习用乐曲数据记述有由1通道以上的旋律和1通道以上的和弦构成的乐曲的乐谱,所述(2)整形单元将所述乐曲生成单元所生成的生成乐曲整形为在音乐上和谐的内容。
第3本发明为一种音乐处理方法,供音乐处理系统进行,其特征在于,(1)所述音乐处理系统具备乐曲生成单元和整形单元,(2)所述乐曲生成单元使用学习模型来生成乐曲,所述学习模型是根据具有学习用乐曲数据的学习用数据进行机器学习得到的,所述学习用乐曲数据记述有由1通道以上的旋律和1通道以上的和弦构成的乐曲的乐谱,(3)所述整形单元将所述乐曲生成单元所生成的生成乐曲整形为在音乐上和谐的内容。
发明的效果
根据本发明,能在以原曲为输入的情况下生成新制作的曲子。
附图说明
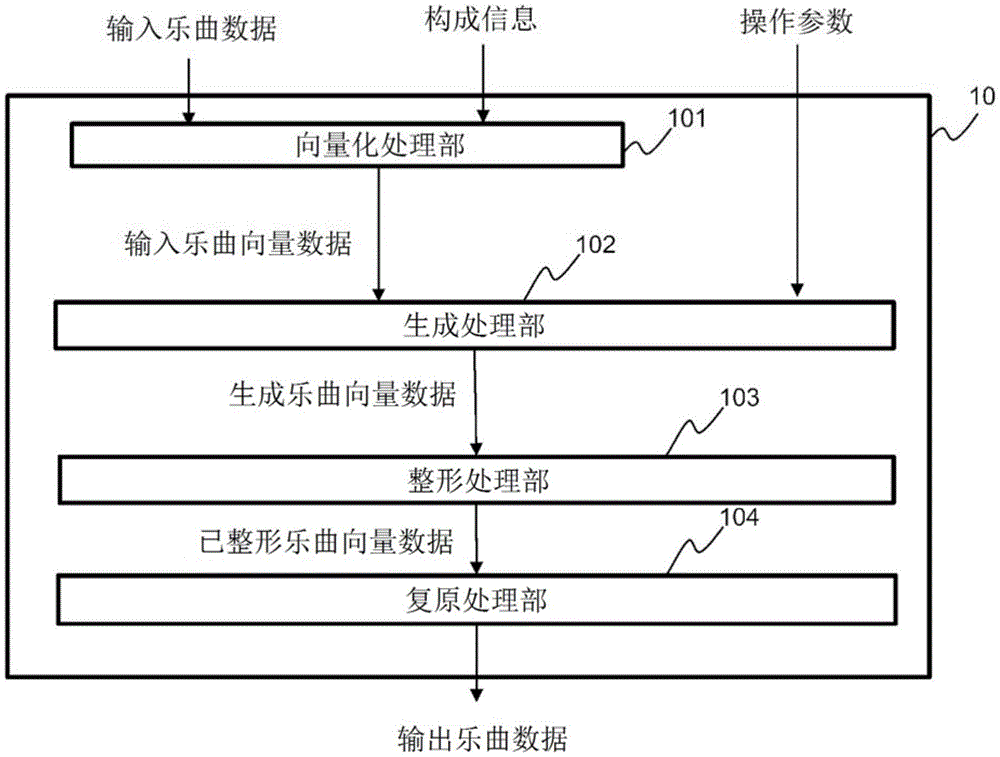
图1为表示第1实施方式的音乐处理装置的功能构成的框图。
图2为表示第1实施方式的生成处理部中使用的AI的学习时的构成例的框图。
图3为表示第1实施方式的生成处理部中的乐曲生成时的构成例的框图。
图4表示第1实施方式的以总谱形式的乐谱来表示输入乐曲例的例子。
图5为以表形式来表示第1实施方式的输入乐曲例中的旋律通道的乐谱转换成ID(数值)得到的内容的图。
图6为以表形式来表示第1实施方式的输入乐曲例中的和弦通道的乐谱转换成ID(数值)得到的内容的图。
图7为表示第1实施方式的针对旋律通道的各音符而转换为ID用的转换表的图。
图8为表示第1实施方式的针对和弦通道的各和弦而转换为ID用的转换表的图。
图9为表示第1实施方式的整形处理部所进行的整形处理的流程的流程图。
图10为表示第1实施方式中所处理的整形前乐曲(生成乐曲)的例子的图。
图11为表示第1实施方式中所处理的整形前乐曲例中的和弦进行的图。
图12为表示第1实施方式的整形处理部对各调的计数结果的图。
图13为表示第1实施方式中所处理的已作和弦整形的乐曲的例子的图。
图14为表示第1实施方式中所处理的已作旋律整形的乐曲的例子的图。
图15为表示第1实施方式中设定[操作参数=0]的情况下的生成乐曲的例子的图。
图16为表示第1实施方式中设定[操作参数=10]的情况下的生成乐曲的例子的图。
图17为表示第1实施方式中设定[操作参数=20]的情况下的生成乐曲的例子的图。
图18为表示第2实施方式的音乐处理装置的功能构成的框图。
图19为表示第2实施方式的生成处理部中的乐曲生成时的构成例的框图。
具体实施方式
(A)第1实施方式
下面,一边参考附图,一边对本发明的音乐处理系统、音乐处理程序以及音乐处理方法的第1实施方式进行详细叙述。
(A-1)第1实施方式的构成
图1为表示该实施方式的音乐处理系统10的整体构成的框图。
音乐处理系统10是新生成并输出乐曲的系统。
音乐处理系统10可全部由硬件(例如专用芯片等)构成,也可一部分或全部以软件(程序)的形式构成。音乐处理系统10例如可通过在具有处理器及存储器的计算机中安装程序(包含实施方式的音乐处理程序)来构成。此外,构成音乐处理系统10的计算机的数量不作限定,也可通过在多台计算机中分散配置程序和数据来实现。
当音乐处理系统10被输入包含输入乐曲数据、构成信息的数据(以下也称为“输入数据”)和操作参数时,进行利用该输入数据来生成并输出新的乐曲的处理。以下,将音乐处理系统10所输出的乐曲数据称为“输出乐曲数据”。
接着,对输入乐曲数据/输出乐曲数据进行说明。
在该实施方式中,是以输入乐曲数据/输出乐曲数据的数据形式(输入输出的音乐数据的形式)为标准MIDI文件(Standard Musical Instrument Digital Interface File,以下称为“SMF”)的形式这一方式来进行说明,但运用于输入乐曲数据/输出乐曲数据的数据形式并不限定于标准MIDI文件的形式,可以运用各种演奏信息(乐谱数据)的形式的数据。此外,在音乐处理系统10中,作为运用于输入乐曲数据/输出乐曲数据的数据形式,也可为WAV或MP3等直接的音响信号的形式而不是SMF之类的演奏信息的形式。在音乐处理系统10中,在输入乐曲数据/输出乐曲数据为音响信号的形式的情况下,会将所输入的输入乐曲数据转换处理为SMF等演奏信息的形式的数据,并输出已转换成音响信号的形式的数据作为输出乐曲数据。对于音乐处理系统10中将音响信号的形式的数据转换为演奏信息的形式的数据的处理以及将演奏信息的形式的数据转换为音响信号的形式的数据的处理(音乐播放处理),可以运用各种处理,所以省略详细说明。
再者,在该实施方式中,是以输入乐曲数据和输出乐曲数据为相同数据形式(SMF的形式)的方式进行说明,但当然也可设为各不相同的形式。
在该实施方式中,音乐处理系统10中所处理的乐曲的单位(例如长度、通道(MIDI上的通道)的数量等)不作限定。即,在该实施方式中,音乐处理系统10中所处理的乐曲的单位的长度可设为固定长度(例如规定的小节数),也可设为可变长度。在该实施方式中,是以音乐处理系统10中所处理的乐曲的单位的长度在4/4拍的换算下为8小节(32拍,2/2拍的情况下为16小节)的固定长度的方式进行说明。此外,在该实施方式中,是以音乐处理系统10中所处理的乐曲的通道数由旋律1通道与和弦(对旋律的伴奏的和音)1通道这合计2通道构成的方式进行说明。以下,将构成乐曲的旋律的通道称为“旋律通道”,将和弦的通道称为“和弦通道”。再者,在音乐处理系统中所处理的乐曲中,旋律通道及和弦通道也可分别设为多个(2个以上)。
接着,对“构成信息”进行说明。
构成信息是表示输入乐曲中的各区间的要素的属性(种类)的参数。在该实施方式的例子中,作为输入乐曲的要素,使用前奏、A段、B段或者副歌中的任一属性。可使用的要素的属性不限于上述,可使用各种形式(例如第1主题、第2主题等形式)。
构成信息能以不同于输入乐曲数据的别的数据的形式构成,但也可通过在SMF的标记(marker)中嵌入与构成信息相对应的信息来实现。在SMF中,以可由用户写入任意文本的字段的形式准备有标记。因此,也可设为在输入乐曲数据(SMF数据)的标记中写入与构成信息相对应的文本(例如前奏、A段、B段、副歌之类的文本)的形式。
例如,在以输入乐曲数据的形式供给的SMF数据中,在第1小节的开头的时机(位置)的标记中设定有“前奏”、第5小节的开头的时机的标记中设定有“A段”的情况下,音乐处理系统10将第1小节~第4小节的区间识别为“前奏”,将第5小节之后(第5小节~第8小节)的区间识别为A段。此外,例如在以输入乐曲数据的形式供给的SMF数据中,在第1小节的开头的时机(位置)的标记中设定有“A段”且未设定这以外的标记的情况下,音乐处理系统10将所有区间(第1小节~第8小节)识别为“A段”。如上所述,在SMF数据中,可以将每一区间的要素的属性写入标记。
区别于SMF数据而另行记述构成信息的情况的具体形式不作限定,只要记述有输入乐曲的每一区间的要素的属性即可。例如,可与SMF的标记同样地利用以时机(位置)和表示要素的属性的信息(例如与A段、B段、前奏相对应的文本或数值)为对的信息串来记述构成信息。此外,在对输入乐曲的所有区间使用相同属性的情况下,也可对构成信息仅设定与属性相对应的参数和文本而无须设定时机相关的信息。
接着,对“操作参数”进行说明。
操作参数是音乐处理系统10中可用作从用户受理要生成的乐曲的特性的操作用的接口的参数。在该实施方式中,以操作参数由1个数值(一维参数)表示的方式进行说明。但操作参数不作限定,也可由多个数值(多维参数)表示,也能以数值以外的形式(例如TRUE/FALSE这样的标志形式)表示。操作参数的详情于后文叙述。
接着,对音乐处理系统10的内部构成进行说明。
如图1所示,音乐处理系统10具有向量化处理部101、生成处理部102、整形处理部103以及复原处理部104。
向量化处理部101对包含输入乐曲数据及构成信息的数据进行转换为适于后面的生成处理部102中的处理的形式的向量数据(以下称为“输入乐曲向量数据”)的处理。继而,向量化处理部101将获取到的输入乐曲向量数据供给至生成处理部102。输入乐曲向量数据的具体形式于后文叙述。
生成处理部102通过使用AI的生成模型的处理、根据输入乐曲向量数据和操作参数来生成并输出与新的乐曲(以下称为“生成乐曲”)相对应的向量数据(与输入乐曲向量数据同样的形式的数据,以下称为“生成乐曲向量数据”)。生成处理部102将生成乐曲向量数据供给至整形处理部103。生成处理部102的详细构成于后文叙述。
整形处理部103对生成乐曲向量数据的乐曲进行整形为在音乐上和谐的内容的处理(例如整体的调的统一、旋律与和弦之间的音阶的调整等),并作为“已整形乐曲向量数据”输出。
生成乐曲向量数据的乐曲是从AI(生成处理部102)输出的原样的内容,所以有可能存在调不一致的情况、旋律与和弦之间音阶不般配的情况等在音乐(音乐理论)上看来不和谐的情况。因此,在音乐处理系统10中,通过配备整形处理部103来输出在音乐上作了整形的乐曲。再者,在无须对从AI(生成处理部102)输出的生成乐曲向量数据进行整形的情况(例如用户侧不需要的情况、一开始便生成在音乐上谐调的内容的情况)下,也可去掉整形处理部103的构成而将生成乐曲向量数据直接供给至复原处理部104。
复原处理部104针对已整形乐曲向量数据而复原(转换)为规定形式的音乐数据(该实施方式中为SMF的形式)并作为“输出乐曲数据”输出。
接着,对生成处理部102中使用的AI的构成例进行说明。
在生成处理部102中,根据基于深度学习进行机器学习得到的学习模型而构成有AI。具体而言,在生成处理部102中,获取在VAE(Variational AutoEncoder)的架构下进行学习得到的学习模型。
构成生成处理部102中使用的AI的平台(中间件)不作限定,可以使用各种平台。在该实施方式的例子中,是以使用Python(注册商标)及其周边的库来构成生成处理部102的方式来进行以下的说明。
图2为表示生成处理部102中使用的AI的学习时(获取学习模型时)的构成例的图。
如图2所示,在生成处理部102中,在学习时至少编码器201(encoder)、解码器202(decoder)、鉴别器203(识别器)以及潜在变量处理部204进行动作。
编码器201根据输入乐曲向量数据来获取并输出潜在变量的平均向量μ和表示概率分布的方差向量σ。
在学习时,潜在变量处理部204按照VAE的架构来获取对平均向量μ加上与标准偏差σ相应的噪声得到的值作为潜在变量z(潜在变量的样本)并供给至解码器202。此时,潜在变量处理部204例如可按照以下式(1)来获取潜在变量z。例如,式(1)中可设定I=1。
z=μ+εσ(ε~N(0,I))…(1)
例如,在潜在变量z为256维向量的情况下,潜在变量处理部204在学习时获取潜在变量z用的源码(以Python来记述的情况下的代码)可以设为“μ+numpy.random.normal(loc=0.0,scale=1*σ,size=256)”。
解码器202输出对潜在变量z进行复原处理得到的向量数据(以下称为“复原乐曲向量数据”)。在图2所示的VAE的架构中,由编码器201及解码器202构成了生成程序(生成器)。鉴别器203识别复原乐曲向量数据是否为由生成程序生成的数据。在生成处理部102中,生成程序以不被鉴别器203识破是生成程序所生成的向量数据的方式进行学习。在图2的学习时,生成程序使用鉴别器203的识别结果、LOSS(输入乐曲向量数据与复原乐曲向量数据的差分)来进行学习处理,图2中为简化说明而省略了图示。
在生成处理部102的学习时,可从向量化处理部101逐次供给用于学习的样本(输入乐曲向量数据)。生成处理部102的学习中使用的样本数不作限定,可使用1000~3000左右的样本数。此外,在生成处理部102的学习中,可对各样本(1个输入乐曲向量数据)进行1000次左右的学习处理(1000次左右根据潜在变量z来生成复原乐曲向量数据为止的学习处理)。
此外,通过针对成为生成处理部102的学习中使用的样本(输入乐曲向量数据)的基础的乐曲的种类(例如流行乐、爵士乐等)和艺术家等而改变比率,也能改变由生成程序生成的乐曲的特征。其原因在于,基本上在通过VAE的架构来进行AI的学习的情况下,潜在变量z的分布范围与学习中使用的样本相应。
在该实施方式中,潜在变量z为256维的固定大小,但z的大小并不限定于此。潜在变量z的大小较理想为根据所处理的向量数据(输入乐曲向量数据/复原乐曲向量数据)的大小进行变更。
图3为表示利用生成处理部102中使用的AI所学习得到的模型来进行生成乐曲向量数据的生成时(以下称为“乐曲生成时”)的构成例的图。
图3中,对与上述图2相同的部分或对应的部分标注同一符号或对应的符号。
如图3所示,在生成处理部102中,在乐曲生成时,至少编码器201、解码器202以及潜在变量处理部204进行动作。
编码器201和解码器202自身的动作与学习时相同,所以省略详细说明。
潜在变量处理部204在乐曲生成时使与方差向量σ及操作参数c相应的噪声混入(加到)潜在变量z中,这一点与学习时不一样。
具体而言,潜在变量处理部204在乐曲生成时在上述式(1)中设定I=c,由此,可以将噪声修正为使操作参数c反映到潜在变量z中得到的值。可对操作参数c设定的范围不作限定,可设为能由用户加以调整。例如,作为操作参数c,可设为能在0~10的范围内进行设定,也可设为能在0~50的范围内以规定的网格宽度(例如10)单位进行变更。此外,在潜在变量处理部204中,针对操作参数c的值而从用户受理输入的方式(例如受理输入的设备、操作画面的构成)不作限定。
例如,在潜在变量z为256维向量的情况下,潜在变量处理部204在乐曲生成时获取潜在变量z用的源码(以Python来记述的情况下的代码)可以设为“μ+numpy.random.normal(loc=0.0,scale=c*σ,size=256)”。
(A-2)第1实施方式的动作
接着,对具有如上构成的第1实施方式中的音乐处理系统10的动作(实施方式的音乐处理方法)进行说明。
首先,对向量化处理部101的处理的详情进行说明。
如上所述,在音乐处理系统10中,在2通道下以8小节(32拍)的乐曲单位加以处理。
图4展示了以总谱形式的乐谱来表示输入乐曲例的例子。
再者,图4所示的输入乐曲是来自亚历山大·鲍罗丁作曲的“鞑靼人之舞”(波罗维茨人之舞)的一节。
图4中,以总谱形式表现了输入乐曲的旋律通道及和弦通道的乐谱。再者,此处,各乐曲的通道的乐器(MIDI上的乐器名)为钢琴系乐器。
首先,向量化处理部101针对输入乐曲数据的各通道的音符的排列而以48分音符单位(12分之1拍单位)进行编码(数列化)。此处,输入乐曲数据为8小节(32拍),所以,当对各通道进行编码时,会产生8×48=384个代码串。此处,各代码由1个数值(以下简称为“ID”)表示。
图5以表形式来图示将图4所示的输入乐曲中的旋律通道的乐谱转换(编码)成ID得到的内容。
图6以表形式来图示将图4所示的输入乐曲中的和弦通道的乐谱转换(编码)成ID得到的内容。
在图5、图6的表中,1列中配置有1小节(4拍)的ID(设定48个ID的时隙)。
图7展示了针对旋律通道的各音符而转换为ID用的转换表的例子。
如图5、图7所示,在旋律通道下,对各音符的符头的时机(时隙)设定的是与音调的高度相对应的ID(2之后的ID),对休止符的符头的时机(时隙)设定的是“1”这一ID。此外,如图5、图7所示,在旋律通道下,对音符或休止符的符头的时机以外的时机(时隙)设定用于继续前一状态的“0”这一代码。具体而言,如图7所示,“0”这一ID意指“前一ID的状态在继续的状态”、“前一ID的状态在继续的状态。”、“在前一ID为0的情况下,其上上一状态在继续的状态。”、“在前一ID为1的情况下,未发出声音的状态。”、“在这以外的情况下,相应音调的声音在持续鸣响的状态。”等处理。
图8展示了针对和弦通道的各和弦而转换为ID用的转换表。
如图6、图8所示,在和弦通道下,对各和弦(和音)的符头的时机(时隙)设定与和弦的种类(和音的组合)相对应的ID(2之后的ID),对休止符的符头的时机(时隙)设定“1”这一ID。在和弦通道下,音调的最低音相当于MIDI中的国际式的C2,最高音相当于B5。此外,如图6、图8所示,在和弦通道下,对音符或休止符的符头的时机以外的时机(时隙)设定用于继续前一状态的“0”这一代码。具体而言,如图8所示,“0”这一代码意指“前一ID的状态在继续的状态”、“前一ID的状态在继续的状态。”、“在前一ID为0的情况下,其上上一状态在继续的状态。”、“在前一ID为1的情况下,未发出声音的状态。”、“在这以外的情况下,相应和弦的声音在持续鸣响的状态。”等处理。
如上所述,向量化处理部101针对输入乐曲数据的各通道而转换为数列,由此能获得与各通道相对应的独热向量(One-Hot Vector,适于AI的处理的数据形式的数据)。以下,将针对各通道进行编码(ID化/数列化/One-Hot Vector化)得到的数据的块称为“已编码输入乐曲数据”。已编码输入乐曲数据中包含旋律通道的数列(384个ID的串/代码串/One-HotVector)及和弦通道的数列(384个ID的串/数列/One-Hot Vector)。以下,将旋律通道的数列的各数值表示为Mi(i表示1~384的时隙编号(时间序列的顺序)),将和弦通道的数列的各数值表示为Ci。具体而言,将旋律通道的数列表示为M1、M2、M3、…、M384,将和弦通道的数列表示为C1、C2、C3、…、C384。
接着,对向量化处理部101将构成信息加以编码(数列化)的处理进行说明。
如上所述,在向量化处理部101中,可以根据构成信息来掌握输入乐曲的每一区间的要素的属性(例如前奏、A段、B段、副歌等)。因此,向量化处理部101掌握与输入乐曲的各时隙相对应的要素的属性,获取对各时隙设定与要素(要素的属性)相对应的数值(代码)得到的数列。
与各要素的属性相对应的数值(代码)的分配不作限定。在该实施方式中,与各要素相对应的数值是在0~50的范围内进行分配。具体而言,在该实施方式的例子中,作为与A段相对应的数值是分配10~19中的任一者,作为与B段相对应的数值是分配20~29中的任一者,作为与副歌相对应的数值是分配30~39中的任一者,作为与前奏相对应的数值是分配40~49中的任一者。例如,在向量化处理部101中,可将与A段相对应的数值设为10,将与B段相对应的数值设为20,将与副歌相对应的数值设为30,将与前奏相对应的数值设为40。在要素的属性不一样的情况下,通过空出一定程度的数值的间隔,能让AI易于区分要素的属性所决定的特征。此外,在输入乐曲中产生多个相同要素的区间的情况(例如像A段、B段、A段这样持续的情况)下,向量化处理部101也可对重复产生的区间设定不同数值。例如,在像A段、B段、A段这样持续的情况下,可对第1次的A段的区间设定30,对第2次的A段的区间设定31。再者,在该实施方式中,与构成要素相对应的参数是设为一维,但也能以多维来构成。例如,在假定了设定3个参数F、G、H作为与构成要素相对应的参数的情况下,可将A段定义为“F=1、G=0、H=0”,将B段定义为“F=0、G=1、H=0”,将副歌定义为“F=0、G=0、H=1”。
如上所述,在向量化处理部101中,可以根据构成信息对输入乐曲的各时隙(384个时隙)设定与要素的属性相对应的数值。以下,将基于构成信息的数列的各数值表示为Ei。具体而言,将基于构成信息的各时隙的数列表示为E1~E384。
继而,向量化处理部101对构成已编码输入乐曲数据的数列(旋律通道及和弦通道的数列)和基于构成信息的数列进行组装成适于AI处理的向量数据(行列式)的处理。
在该情况下,可获取向量化处理部101所生成的以下式(2)那样的行列式作为向量数据。式(2)中的行列式是以1时隙(48分音符)的数据为1行。也就是说,式(2)中,第i行(i为1~384中的任一整数)由(Mi、Ci、Ei)构成。
[数式1]
再者,在该实施方式中,是以由音乐处理系统10的AI(生成处理部102)加以处理的向量数据(输入乐曲向量数据、复原乐曲向量数据等)全部为式(2)那样的形式的方式进行说明。向量数据的形式不限于(2),只要是由相同数列构成,则具体的排列的顺序、各行的构成也可设为其他形式(例如以24分音符单位来构成1行的形式)。
此外,如上所述,在该实施方式中,在输入乐曲向量数据中,旋律通道及和弦通道的数列是以48分音符单位来进行数列化(ID化),但实质上可以说与原本的输入乐曲数据(SMF数据)一样是乐谱(演奏信息)的形式的数据。因而,在音乐处理系统10中,可从一开始便接受对旋律通道及和弦通道的数据进行数列化得到的数据的供给来作为输入乐曲数据。此外,在音乐处理系统10中,可从一开始便以输入乐曲向量数据的形式接受供给。在该情况下,在音乐处理系统10中可去掉向量化处理部101。
接着,对整形处理部103所进行的整形处理的详情进行说明。
如上所述,整形处理部103对生成乐曲向量数据进行整形处理而作为已整形乐曲向量数据输出。此外,以下将与生成乐曲向量数据相对应的乐曲称为“整形前乐曲”,将已整形乐曲向量数据的乐曲称为“已整形乐曲”。
在该实施方式中,整形前乐曲为8小节(32拍)左右的长度,所以整形处理部103以整形处理的形式对整形前乐曲进行在整体上将调加以统一的处理。再者,整形处理部103也可将整形前乐曲分为多个区间而针对各区间来单独决定统一调并进行其后的整形处理。
在该实施方式中,是以整形处理部103在向量数据的状态(生成乐曲向量数据)下进行整形处理的方式进行说明,但也可调换整形处理部103与复原处理部104的顺序而在复原为SMF数据的形式之后进行整形处理。
图9为表示整形处理部103所进行的整形处理的流程的流程图。
首先,整形处理部103对整形前乐曲进行推断适合作为统一的调的调的处理(以下称为“调推断处理”),并按照调推断处理的结果来决定统一的调(以下称为“统一调”)(S101)。
接着,整形处理部103对整形前乐曲的和弦通道进行以仅变为统一调中通常使用的和弦的方式加以整形的处理(以下称为“和弦整形处理”)(S102)。以下,将对整形前乐曲进行和弦整形处理后的乐曲称为“已作和弦整形的乐曲”。
接着,整形处理部103对已作和弦整形的乐曲的旋律通道的各音符进行以与和弦通道的和弦相和谐的方式加以整形的处理(以下称为“旋律整形处理”),作为已整形乐曲加以获取(S103)。具体而言,整形处理部103对已作和弦整形的乐曲的旋律通道的各音符进行以与对应于同时响起(以相同时间序列响起)的和弦通道的和弦(以下称为“对应和弦”)的音阶(以下称为“和弦音阶”)相合的方式对音调加以调整(整形)的处理。
接着,对步骤S101的调推断处理的详情进行说明。
在调推断处理中,整形处理部103针对整形前乐曲而推断全部24调((大调×12音)+(小调×12音)=24)中的哪一调适合作为统一调。
在该实施方式中,整形处理部103枚举整形前乐曲中包含的和弦与各调中使用的和弦一致到什么程度,将与这些和弦的一致数最多的调推断(决定)为最佳的统一调。
图10为以总谱形式表示整形前乐曲(生成乐曲)的例子的图。
图11为表示图10所示的整形前乐曲中的和弦进行的图。
图11中,对构成整形前乐曲的14个和弦从开头起依序标注有C01~C14等符号。并且,图10中,对和弦C01~C14附注有和弦名。如图10所示,和弦C01~C14的和弦为[DM7]、[A7]、[Am7]、[E]、[Bm7]、[Esus4]、[D7]、[B7]、[Am7]、[E7]、[Em7]、[A7]、[Em]、[Em7]。
整形处理部103针对构成整形前乐曲的各和弦的各音而进行在各调(全部24调中的各调)的全音阶和弦中含有多少的计数。此时的整形处理部103给出的计数结果示于图12。
图12为表示整形处理部103进行各调的全音阶和弦在构成整形前乐曲的各和弦的各音中含有多少的计数得到的结果的图。
图12的表中展示了按每一调来包含的全音阶和弦的数量(以下称为“计读数”)。
例如像图11、图12所示,E小调的全音阶和弦包含在共计8个和弦(C03[Am7]、C05[Bm7]、C07[D7]、C08[B7]、C09[Am7]、C11[Em7]、C13[Em]、C14[Em7])中,所以E小调的计读数为8。
并且,在该情况下,如图12所示,E小调的计读数为8,是最多的。因而,在该情况下,整形处理部103推断作为针对该整形前乐曲的统一调而言最佳的是E小调。
接着,对步骤S102的和弦整形处理的详情进行说明。
如上所述,在和弦整形处理中,整形处理部103对整形前乐曲的和弦通道以仅变为统一调中通常使用的和弦的方式进行和弦整形处理,生成已作和弦整形的乐曲。
首先,整形处理部103针对构成整形前乐曲的和弦通道的各和弦而判断是与统一调中使用的和弦一致的和弦(以下称为“一致和弦”)还是不一致的和弦(以下称为“不一致和弦”)。
继而,整形处理部103针对构成整形前乐曲的和弦通道的各和弦中的不一致和弦而以变为统一调的全音阶和弦(以下称为“统一调和弦”)的方式对和弦进行调整(整形)。
此时,整形处理部103选择对各不一致和弦进行修正的目标的统一调和弦(以下称为“调整目标和弦”)的方法不作限定,能以如下策略进行选择。
基本而言,在整形处理中,较理想为变更的量(变更音调的音符的数量)尽可能少。整形处理部103可按照以下策略来选择调整目标和弦。
[第1策略]
对于各不一致和弦,选择统一调和弦当中一致的构成音最多的和弦作为调整目标和弦。
[第2策略]
对于符合第1策略的统一调和弦存在多个的不一致和弦,选择与该不一致和弦的构成音数量的差最小(一致的构成音数量最多)的统一调和弦作为调整目标和弦。
[第3策略]
对于符合第2策略的统一调和弦也存在多个的不一致和弦,选择实施中的索引(例如实施上赋予的各和弦的管理编号(ID编号))最小的和弦作为调整目标和弦。再者,在该情况下,也可将从多个统一调和弦中随机选择的和弦作为调整目标和弦。
在图10所示的整形前乐曲中,若将统一调设为E小调,则一致和弦为C03[Am7]、C05[Bm7]、C07[D7]、C08[B7]、C09[Am7]、C11[Em7]、C13[Em]、C14[Em7],不一致和弦为C01[DM7]、C02[A7]、C04[E]、C06[Esus4]、C10[E7]、C12[A7]。
图13为表示对图10所示的整形前乐曲进行和弦整形处理得到的结果(已作和弦整形的乐曲)的图。
图13中展示了在该整形前乐曲中将统一调设为E小调并按上述策略将不一致和弦C01[DM7]、C02[A7]、C04[E]、C06[Esus4]、C10[E7]、C12[A7]修正为统一调和弦得到的结果。
例如,当针对第1小节的和弦C01[DM7](构成音DF#AC#)而应用于上述策略时,变更为E小调的全音阶和弦下一致的构成音最多的统一调和弦即F#m7b5(构成音F#ACE)。
接着,对步骤S103的旋律整形处理的详情进行说明。
如上所述,在旋律整形处理中,整形处理部103对已作和弦整形的乐曲的旋律通道的各音符进行以变为对应和弦的音阶(以下称为“对应和弦音阶”)的构成音的方式进行调整(整形)的处理。以下,在旋律通道下,由于不是对应和弦音阶的构成音,所以将成为调整对象的音符称为“调整对象音符”。
再者,相对和弦音阶基本上为对应和弦的音阶(例如,若对应和弦为Am7,则对应和弦音阶为A小调的音阶),而在对应和弦为add9和弦的情况下,可将与该对应和弦的根音相对应的利底亚音阶视为对应和弦音阶。
此时,整形处理部103对调整对象音符(旋律通道的各音符)的音调进行调整的方法不作限定,能以如下策略来进行。再者,音符即便是分开的,以连音符相连的相同音调的音符也可视为1个音符(调整对象音符)而运用于以下的各策略。
[第1策略]
对于调整对象音符,以仅由对应和弦音阶的构成音构成的方式调整音调。
[第2策略]
关于跨越多个和弦的区间的调整对象音符(以下称为“多和弦对应音符”),以仅由这多个和弦的所有对应和弦音阶中共通的音构成的方式调整音调。例如,在多和弦对应音符的区间内,在和弦切换1次时,对应和弦为2个,在和弦切换2次时,对应和弦为3个。
[第3策略]
对于不存在满足第2策略的音调的多和弦对应音符,在和弦的断开处(和弦的切换的时机)进行分割,针对分割后的各音符而分别以单独的调整对象音符的形式从头开始音调整形处理(根据第1策略来运用的处理)。
[第4策略]
在对调整对象音符的音调进行调整时,保持整形前乐曲中的该调整对象音符与前一个音符(以下称为“前一音符”)及后一个音符(以下称为“后一音符”)的相对的音调的上下关系(“音调在上升”、“音调在下降”、“音调相同”这3个类型中的任一者)。
以下,将该调整对象音符的音调表示为PT,将前一音符的音调表示为PB,将后一音符的音调表示为PA。例如,在前一音符的音调PB与该调整对象音符的音调PT的关系中,存在PB=PT(音调相同)、PB>PT(音调在下降)、PB<PT(音调在上升)等类型。此外,例如在该调整对象音符的音调PT与后一音符的音调PA的关系中,存在PT=PA(音调相同)、PT>PA(音调在下降)、PT>PA(音调在上升)等类型。
[第5策略]
在仅靠该调整对象音符的音调调整而无法满足第4策略的情况下,在对后一音符也进行音调调整的前提下决定满足第4策略的音调的调整类型。
[第6策略]
在进行该调整对象音符的音调调整时,使调整前后的音调的差分在规定程度以下(例如±1个八度音以下)。
整形处理部103较理想为以如上策略、以仅由对应和弦音阶的构成音构成的方式对调整对象音符进行调整。再者,在无法遵守第4策略及第5策略的状态的情况下,可将这2个策略排除来进行调整。此外,在遵守第4策略及第5策略便无法满足第6策略的状态的情况下,可运用“排除第6策略”或者“排除第4策略或第5策略”中的任一方式。
图14为表示对图13所示的已作和弦整形的乐曲进行旋律整形处理得到的结果(已作旋律整形的乐曲)的图。
如图14所示,通过旋律整形处理,第1小节F的音按照上述策略而变更为F#(为E小调音阶构成音,与前后音的高度关系不变的音)。
(A-3)第1实施方式的效果
根据第1实施方式,能取得如下效果。
在第1实施方式的音乐处理系统10中,可以借助使用AI的生成模型而在以输入乐曲数据(原曲)为输入的情况下生成新制作的乐曲。
此外,在第1实施方式的音乐处理系统10中,能使与操作参数c相应的噪声混入(加到)潜在变量z中。由于可以对操作参数c设定任意值,所以用户可以改变操作参数c的值来生成多个乐曲,由此从生成的乐曲中针对生成乐曲而选择获取可以说是在以输入乐曲数据(原曲)为输入的情况下新制作的内容。
接着,使用图15~图17,对随着操作参数的变动而生成乐曲发生变化的具体例进行说明。
图15~图17分别为以乐谱(五线谱)的形式来表示将输入乐曲设为图4的乐曲、使操作参数的值变为0、10、20的情况下的生成乐曲的图。
如图15所示,在将操作参数的值设为0的情况下,生成了能推断为与原曲(图4)相同的调(F#小调)或其平行调(A大调)的曲子。此外,在图15的乐谱中,见到与原曲(图4)同样地以4小节单位凑在一起这样的旋律的构成。
如图16所示,在将操作参数的值设为10的情况下,生成了推断为原曲(图4)的下属调(D大调)而不是与原曲(图4)相同的调的曲子。
如图17所示,在将操作参数的值设为20的情况下,曲子不仅调与原曲(图4)大为不同,所使用的音符的种类和节奏感也完全不同。
如上所述,在第1实施方式的音乐处理系统10中,通过改变操作参数c的值,能使生成乐曲成为可以说是在以输入乐曲数据(原曲)为输入的情况下新制作的内容。
(B)第2实施方式
下面,一边参考附图,一边对本发明的音乐处理系统、音乐处理程序以及音乐处理方法的第2实施方式进行详细叙述。
(B-1)第2实施方式的构成及动作
图18为表示第2实施方式的音乐处理系统10A的整体构成的框图。
图18中,对与上述图1相同的部分或对应的部分标注同一符号或对应的符号。
下面,针对第2实施方式来说明与第1实施方式的差异。
第2实施方式的音乐处理系统10A与第1实施方式的不同点在于,生成处理部102被替换成了生成处理部102A。
第2实施方式的生成处理部102A中,AI的学习时的构成与第1实施方式相同,但其后的乐曲生成时的构成不一样。
图19为表示第2实施方式的生成处理部102A中的乐曲生成时的构成例的图。
图19中,对与上述图3和上述图1相同的部分或对应的部分标注同一符号或对应的符号。
如图19所示,在第2实施方式的生成处理部102A中,在乐曲生成时,仅潜在变量处理部204A和解码器202进行动作。
与第1实施方式的不同点在于,在乐曲生成时,潜在变量处理部204A不依靠来自编码器201的数据而是根据通过规定方法获取的数值(例如随机数等)来自主生成供给至解码器202的潜在变量z。
例如,在上述式(1)中,可通过设定μ=0、σ=1、I=1来获取基于方差为1的随机数的潜在变量z。例如,在潜在变量z为256维向量的情况下,潜在变量处理部204A获取潜在变量z用的源码(以Python来记述的情况下的代码)可以设为“numpy.random.normal(loc=0.0,scale=1.0,size=256)”。
再者,在第2实施方式中,对σ及I设定的具体值不限定于上述例子,可以使用各种值。
(B-2)第2实施方式的效果
根据第2实施方式,能获得如下效果。
在第2实施方式的音乐处理系统10A中,不依靠输入乐曲而是使用由潜在变量处理部204A根据随机数而获取的潜在变量z来生成乐曲。由此,在第2实施方式的音乐处理系统10A中,能在不进行输入乐曲的输入的情况下生成新的乐曲。
(C)其他实施方式
本发明不限定于上述各实施方式,还能列举如下面例示的变形实施方式。
(C-1)在第1实施方式中,对音乐处理系统根据输入乐曲向量数据(输入乐曲数据)及操作参数进行乐曲生成的动作模式(以下称为“参考模式”)进行了说明,在第2实施方式中,对音乐处理系统根据随机数进行乐曲生成的动作模式(以下称为“随机模式”)进行了说明,但也可对应于这2个动作模式两者而构建可根据用户的操作等来变更动作模式的音乐处理系统。
(C-2)在上述各实施方式中,以生成处理部102具备学习时的构成和乐曲生成时的构成两者的方式进行了说明,但如果是学习的处理已完结的状态,则也可不具备学习时的构成(例如鉴别器203等)。
符号说明
10…音乐处理系统、101…向量化处理部、102…生成处理部、103…整形处理部、104…复原处理部、201…编码器、202…解码器、203…鉴别器、204…潜在变量处理部。