一种环肽药物从头设计方法、电子设备、及存储介质
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于计算机辅助药物设计领域,更具体地,涉及一种环肽药物从头设计方法、电子设备、及存储介质。
背景技术
多肽(Peptides)已经被作为与抗体和小分子药物互补的治疗方式,与抗体相比,多肽可以高亲和力和选择性地结合到平坦的蛋白质表面,它们可以穿透细胞膜进入细胞内靶点。因此,多肽提供了抗体和小分子药物无法达到的治疗空间。多肽主要分为线性肽和环肽,线性肽由于可以随意扭曲和翻转,结构过于松弛而不能很好的成药,而合理的环肽结构往往存在稳定的局部二级结构,使得环肽与靶点表面结合时所耗费的熵成本更小。环肽根据环合成方式分为首尾相连环肽,侧链和侧链相连环肽,侧链和端基环肽,含二硫键桥的环肽,以及其他桥接环肽。天然环肽已经成为上个世纪成药环肽的一个主要来源。在过去的二十年中,肽药物发现的主要趋势是从天然分离的环肽转向优化以提高效力、稳定性和药代动力学特性的环肽类似物。环肽库的高通量筛选,如mRNA展示,DNA展示,噬菌体展示等无疑是发现活性较好的环肽的有效方式,不过这些库仅仅是整个环肽序列空间的一个很小的子集,不能覆盖更广阔的序列和构象空间。因此在未来基于靶点结构的环肽药物的从头设计也会是一个潜力很大的研究方向。不过,目前基于靶点结构从头设计环肽序列的工作并不多。
华盛顿大学David Baker组在2017年发布了利用计算机设计的两百多个独立稳定的环肽结构,他们利用Generaized Kinematic Closure(genKIC)从聚甘氨酸(Poly-Gly)环肽骨架出发,同时使用L、D两种手性的氨基酸来拓宽构象空间从而得到一系列稳定的多肽骨架同时进行序列设计。在此方法的基础上,在Rosetta设计序列阶段将主链上存在不饱和NH的氨基酸替换为主链甲基化的氨基酸类型,并且侧链序列设计空间只允许非极性残基。使用类似方法,可以设计透膜的环肽分子。想要直接设计能够直接靶向目标蛋白的环肽结合剂,可以在目标蛋白表面对环肽的序列和构象进行采样。即将已知的结合分子作为锚点,将聚甘氨酸骨架在口袋处展开和环化,细化侧链之后,利用形状互补系数或自由能筛选最优环肽,且使用下游实验方法评估最佳设计。不过,使用现成环肽骨架然后通过突变氨基酸设计的环肽和目标蛋白的亲和力只有微摩尔级别。David Baker组2021年发表的文章指出,先使用SHA(2S-2-amino-7-sulfanylheptanoic acid,2S-2-氨基-7-硫烷基庚酸)锚定到目标蛋白的口袋中,然后从两个方向延伸所有可能的经典氨基酸,找出形状互补或者ΔΔG评价最高的方案,延展环肽骨架并且突变氨基酸设计环肽能找到与目标蛋白亲和力达到纳摩尔级别的环肽。中国专利文件CN114333985A提供的从头设计环肽方法通过蒙特卡洛采样算法框架进行多肽的环化与对接。他们首先将三肽与靶点蛋白特定表位区域对接,并通过突变和构象采样筛选出结合自由能最低的三肽与靶点结合构象,然后向两端延长三肽到设定阈值,再根据预设骨架二面角变化规则筛选能够成环的候选环肽构象,优化后选出目标环肽序列。
目前基于靶点结构的环肽设计,只能够根据已知的各类蛋白的热点残基,通过局部对接的方法设计出相对应的环肽分子,然后通过能量函数等筛选最优环肽分子。局部对接的方法目标蛋白通过局部结构域来计算,局限了搜索到能够靶向其他表位的环肽分子的可能性。同时基于分子动力学或Rosetta对接方法需要预测二面角范围,再通过蒙特卡洛退火法进行抽样模拟出构象,往往需要大量的计算从而花费大量时间,并且精确度往往达不到要求。
发明内容
针对现有技术的以上缺陷或改进需求,本发明提供了一种环肽药物从头设计方法、电子设备、及存储介质,其目的在于筛选种子短肽结合蛋白质复合物的结构预测和肽段结构预测,在无需先验蛋白热点残基信息的前提下,进行环肽药物的序列和结构设计筛选,实现仅需要目标蛋白序列的环肽药物从头设计,由此解决现有的环肽药物设计方法以来先验蛋白热点残基或结构域信息,限制药物设计的靶向位点结构、依赖于二面角的肽段成环优化,限制了环肽肽段结构多样性的技术问题。
为实现上述目的,按照本发明的一个方面,提供了一种环肽药物从头设计方法,其特征在于,包括以下步骤:
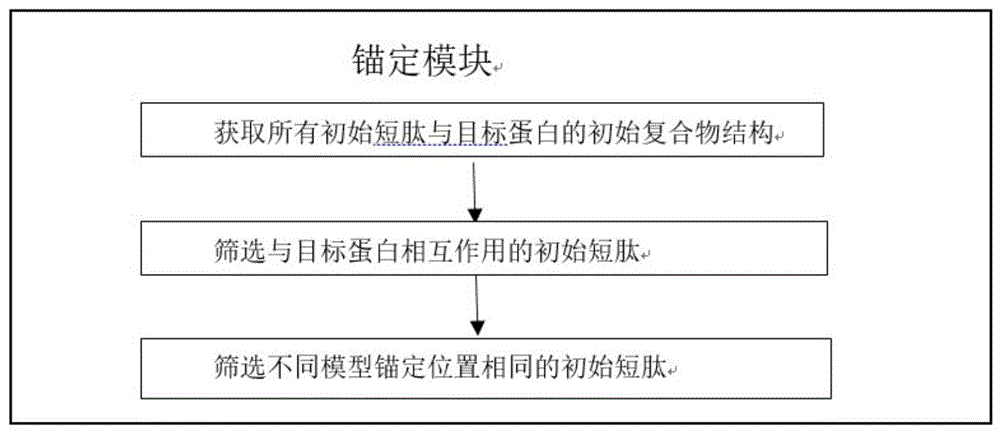
(1)筛选种子短肽:对于预设长度的短肽,采用蛋白质结构预测算法模拟其与目标蛋白的复合物结构;将与目标蛋白相互作用的短肽作为种子短肽,从而初始化种子短肽;
(2)肽段延伸:在种子短肽的N端和/或C端按照预设步长延伸一段搜索肽段作为备选肽段,进入步骤(3);
(3)备选肽段筛选:对于备选肽段采用蛋白质结构预测算法模拟其与目标蛋白的复合物结构;对于与目标蛋白的结合能力超过预设阈值的备选肽段获取其与目标蛋白的复合物结构中的构象;
当备选肽段的构象形成二环肽或首尾相接的环肽时,结束肽段延伸将此备选肽段作为环肽药物候选结构;
当备选肽段的构象形成长度超过预设阈值的线性肽时,结束肽段延伸;
否则,进入步骤(2);
优选地,所述环肽药物从头设计方法,其步骤(3)当备选肽段的构象形成二环肽、首尾相接的环肽时或当备选肽段的构象形成长度超过预设阈值的线性肽时,结束肽段延伸并进入步骤(4);对于备选肽段的构象形成二环肽或首尾相接的环肽或对于长度超过预设阈值的线性环肽药物候选结构,按照如下方法进行成环优化:
(4)在成环的关键氨基酸残基外,进行氨基酸突变获得新的备选肽段,当所述备选肽段的构象形成首尾相接的环肽或套索结构且与目标蛋白的结合能力超过预设阈值时,将所述备选肽段作为环肽药物候选结构。
优选地,所述环肽药物从头设计方法,其所述与目标蛋白相互作用的短肽按照如下方法之一判断:
(1-1)将其所有原子与目标蛋白的距离小于等于预设阈值的短肽判定为与目标蛋白质相互作用的短肽;
(1-2)采用多种不同模型模拟短肽与目标蛋白的复合物结构,以RMSD值和/或DockQ值作为筛选指标筛选所述复合物结构,将筛选指标超过预设阈值的短肽判定为与目标蛋白质相互作用的短肽;
(1-3)属于方法(1-1)和/或(1-2)获得的短肽为与目标蛋白质相互作用的短肽。
优选地,所述环肽药物从头设计方法,其对于具有特定结构域的目标蛋白,将锚定到预设表位的短肽作为种子短肽;
优选地,对所述种子短肽进行筛选:
将评估指标处于预设范围内的短肽作为种子短肽,所述评估指标包括但不限于接触残基对数量、形状互补系数、相互作用面积、结合自由能、或亲和力。
优选地,所述环肽药物从头设计方法,其步骤(2)所述搜索肽段的氨基酸残基选自天然的20种氨基酸,步长优选为1;
当所述种子短肽具有线性结构时,优选分别延伸N端和C端。
当所述种子短肽具有套索结构时,在套索结构的游离端延伸一段搜索肽段作为备选肽段。
优选地,所述环肽药物从头设计方法,其当短肽中存在氨基酸残基与其间隔两个或两个以上的氨基酸残基距离小于预设阈值时,且两个氨基酸残基之一为N端或C端残基时,则判断所述种子短肽具有套索结构;优选地,所述预设阈值为4.5埃。
优选地,所述环肽药物从头设计方法,其步骤(3)所述肽段与蛋白的结合能力,采用结合能力评价指标进行量化评估,所述结合能力评价指标包括但不限于:接触残基对数量、形状互补系数、相互作用面积、结合自由能、亲和力的排名、和/或噬菌体展示技术筛选结果。
优选地,所述环肽药物从头设计方法,其所述备选肽段的构象形成二环肽,具体指短肽的N端、C端残基分别与其间隔两个或两个以上的非末端残基的距离小于预设阈值;所述备选肽段的构象形成首尾相接的环肽,具体指:短肽的N端与C端残基距离小于预设阈值;所述预设阈值为4.5埃。
按照本发明的另一个方面,提供了一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现本发明提供的环肽药物从头设计方法的步骤。
按照本发明的另一个方面,提供了一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现本发明提供的所述环肽药物从头设计方法的步骤。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
本发明在不依赖先验蛋白质热点残基信息的前提下,可直接设计可靶向目标蛋白分子的环肽,与先设计环肽库再筛选相比,节省绝大部分的筛选过程。并且本发明能实现全局对接,可在没有蛋白质表位的信息下,全局搜索对接表位,同时完成对接,结合蛋白质复合物结构预测和肽段结构预测,快速全面的获得备选的环肽药物分子。
优选方案,也可根据特定的表位进行筛选,能有效增加环肽分子的特异性。
附图说明
图1是筛选种子短肽的锚定模块流程图;
图2是肽段延伸和备选肽段筛选的延伸模块流程图;
图3是成环优化的优化模块流程图;
图4是SEQ ID NO:2准环肽分子结构;
图5是SEQ ID NO:2准环肽分子与SEQ ID NO:1(SORT1)复合物结构;
图6是SEQ ID NO:3准环肽分子结构;
图7是SEQ ID NO:4准环肽分子结构;
图8是SEQ ID NO:5准环肽分子结构;
图9是SEQ ID NO:6准环肽分子结构;
图10是SEQ ID NO:7准环肽分子结构;
图11是SEQ ID NO:8准环肽分子结构;
图12是SEQ ID NO:10准环肽分子结构;
图13是SEQ ID NO:10准环肽分子与SEQ ID NO:9(PD1)复合物结构。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明提供的环肽药物从头设计方法,包括以下步骤:
(1)筛选种子短肽:对于预设长度的短肽,采用蛋白质结构预测算法模拟其与目标蛋白的复合物结构;将与目标蛋白相互作用的短肽作为种子短肽,从而初始化种子短肽;所述与目标蛋白相互作用的短肽按照如下方法之一判断:
(1-1)将其所有原子与目标蛋白的距离小于等于预设阈值的短肽判定为与目标蛋白质相互作用的短肽;
(1-2)采用多种不同模型模拟短肽与目标蛋白的复合物结构,以RMSD值和/或DockQ值作为筛选指标筛选所述复合物结构,将筛选指标超过预设阈值的短肽判定为与目标蛋白质相互作用的短肽;
与传统方法对比,无需预设二面角范围并且进行耗时很长的蒙特卡罗退火构象采样过程,可以速度更快地获得比分子动力学或者基于Rosetta方法更精确的复合物结构,同时无需氨基酸二面角相关知识即可进行操作。
(1-3)属于方法(1-1)和/或(1-2)获得的短肽为与目标蛋白质相互作用的短肽。
一般来说,种子短肽的长度过短,与目标蛋白的复合物不具备代表性,种子短肽的长度过长,遍历种子短肽可能性过多,较为适合的种子短肽长度为3肽至7肽,优选3肽。
优选方案,对于具有特定结构域的目标蛋白,将锚定到预设表位的短肽作为种子短肽。种子短肽还可以根据需要进行进一步筛选,将评估指标处于预设范围内的短肽作为种子短肽,所述评估指标包括但不限于接触残基对数量、形状互补系数、相互作用面积、结合自由能、或亲和力。
(2)肽段延伸:在种子短肽的N端和/或C端按照预设步长延伸一段搜索肽段作为备选肽段,进入步骤(3);所述搜索肽段的氨基酸残基选自天然的20种氨基酸,步长优选为1。
当所述种子短肽具有线性结构时,优选分别延伸N端和C端。
当所述种子短肽具有套索结构时,在套索结构的游离端延伸一段搜索肽段作为备选肽段;优选方案,当短肽中存在氨基酸残基与其间隔两个或两个以上的氨基酸残基距离小于预设阈值时,且两个氨基酸残基之一为N端或C端残基时,则判断所述种子短肽具有套索结构;优选地,所述预设阈值在3~8埃,优选为4.5埃;
(3)备选肽段筛选:对于备选肽段采用蛋白质结构预测算法模拟其与目标蛋白的复合物结构;对于与目标蛋白的结合能力超过预设阈值的备选肽段获取其与目标蛋白的复合物结构中的构象;所述肽段与蛋白的结合能力,采用结合能力评价指标进行量化评估,所述结合能力评价指标包括但不限于:接触残基对数量、形状互补系数、相互作用面积、结合自由能、亲和力的排名、和/或噬菌体展示技术筛选结果。
当备选肽段的构象形成二环肽或首尾相接的环肽时,结束肽段延伸将此备选肽段作为环肽药物候选结构或进入步骤(4);所述备选肽段的构象形成二环肽,具体指短肽的N端、C端残基分别与其间隔两个或两个以上的非末端残基的距离小于预设阈值;所述备选肽段的构象形成首尾相接的环肽,具体指:短肽的N端与C端残基距离小于预设阈值;所述预设阈值在3~8埃,优选为4.5埃。
当备选肽段的构象形成长度超过预设阈值的线性肽或套索肽时,结束肽段延伸并进入步骤(4);所述预设阈值为6到20氨基酸残基。
否则,进入步骤(2)。
对于备选肽段的构象形成环肽或二环肽的环肽药物候选结构或对于长度超过预设阈值的线性环肽药物候选结构,按照如下方法进行成环优化:
(4)在成环的关键氨基酸残基外,进行氨基酸突变获得新的备选肽段,当所述备选肽段的构象形成首尾相接的环肽或套索结构且与目标蛋白的结合能力超过预设阈值时,将所述备选肽段作为环肽药物候选结构。
所述成环关键氨基酸残基,指具有环结构的多肽环结构两端的氨基酸残基:对于线性肽,所有的残基都不是成环关键氨基酸,即所有氨基酸残基都在成环的关键氨基酸残基外;对于环肽,则N端和C端的氨基酸为成环关键氨基酸;对于二环肽或套索肽,则N端与中间接触的氨基酸或C端与中间接触的氨基酸为成环关键氨基酸。
以下为实施例:
开发能够靶向特定靶点的环肽是一个巨大的挑战,而基于靶点结构的环肽药物从头设计也是一个潜力巨大的研究方向。近年来,Alphafold2以及Alphafold-Multimer的出现,大大提高了准确预测蛋白质以及蛋白质复合物的结构的准确率和时间,我们将基于人工智能预测蛋白质复合物的结构,无需提前知道目标蛋白的特定表位,全局搜索目标蛋白与初始短多肽的复合物结构。取决于算力,初始短多肽可以是1个氨基酸,2肽,3肽,4肽或者更长的短肽,然后延长初始短多肽直到形成环肽构象或者达到长度阈值,再筛选出符合预设条件的环肽或者将线性肽直接改造成环肽。
实施例1
本实施例提供的环肽药物从头设计方法,以SORT1蛋白为例,设计靶向SORT1的环肽,具体包括以下步骤:
(1)筛选种子短肽:对于预设长度的短肽,采用蛋白质结构预测算法模拟其与目标蛋白的复合物结构;将与目标蛋白相互作用的短肽作为种子短肽,从而初始化种子短肽;所述与目标蛋白相互作用的短肽按照如下方法之一判断:
(1-1)将其所有原子与目标蛋白的距离小于等于预设阈值的短肽判定为与目标蛋白质相互作用的短肽;
(1-2)采用多种不同模型模拟短肽与目标蛋白的复合物结构,以RMSD值和/或DockQ值作为筛选指标筛选所述复合物结构,将筛选指标超过预设阈值的短肽判定为与目标蛋白质相互作用的短肽;
(1-3)属于方法(1-1)和/或(1-2)获得的短肽为与目标蛋白质相互作用的短肽。
本实施例具体为:
获取SORT1的主要序列,SEQ ID NO:1;生成所有20种天然氨基酸组成的初始3肽,共20
本实施例采用多种不同模型模拟短肽与目标蛋白的复合物结构,有原子距离小于4.5埃为氨基酸相互作用的判断,筛选能够与目标蛋白相互作用的初始三肽。
使用AlphaFold2.2.0生成所有初始3肽与SORT1的复合物结构,Alphafold有5个不同的模型,共有5个不同的种子短肽与目标蛋白的复合物结构。
采用短肽的RMSD值或DockQ值作为种子短肽筛选指标。
将5个复合物结构的目标蛋白坐标两两对齐:采用SVD奇异值分解算法找到最佳的旋转与平移,使得两个结构的RMSD值最小。对齐目标蛋白的结构坐标之后,只计算种子短肽的坐标的RMSD,如果种子短肽的RMSD太大,则说明不同模型预测的对接差别太大,结果不可靠。
用5个复合物坐标的两两DockQ值作筛选,优选两两DockQ值大于0.67的短肽作为种子短肽。
DockQ值的计算方法如下:
DockQ主要由三项构成,Fna(诱饵接触残基占天然接触残基比例),LRMSD(对齐受体后配体骨架原子均方根偏差)和iIRMS(对齐接触界面后的骨架原子均方根偏差),其中LRMSD即为上文中种子短肽的RMSD,可见DockQ是比种子短肽的LRMSD更全面的评估参数。参照Basu S,Wallner B.DockQ:a quality measure for protein-protein docking models[J].PloS one,2016,11(8):e0161879.计算平均DockQ值,mDockQ值。
依据mDockQ值排序,选取最优(mDockQ值最大)的25条初始三肽,作为锚定初始三肽。本实施例对特定结构域没有要求,如果特定结构域有要求,则在靶向特定结构域的初始三肽中优选前25条初始三肽。
(2)肽段延伸:在种子短肽的N端和/或C端按照预设步长延伸一段搜索肽段作为备选肽段,进入步骤(3);所述搜索肽段的氨基酸残基选自天然的20种氨基酸,步长为1。具体地:
当所述种子短肽具有线性结构时,分别延伸N端和C端。本实施例首先向25条短肽在N端和C端分别延伸1个氨基酸残基,选自20种天然氨基酸,共25*20*2=1000条。
当所述种子短肽具有套索结构时,在套索结构的游离端延伸一段搜索肽段作为备选肽段;
(3)备选肽段筛选:对于备选肽段采用蛋白质结构预测算法模拟其与目标蛋白的复合物结构;对于与目标蛋白的结合能力超过预设阈值的备选肽段获取其与目标蛋白的复合物结构中的构象;本实施例具体为:
使用AlphaFold2.2.0生成所有备选肽段与SORT1的复合物结构;根据AlphaFold 5个模型生成的不同复合物结构,以其中一个模型为参考,计算其他模型与此模型的DockQ值,并且计算平均DockQ值,即mDockQ值;筛选mDockQ>0.5的备选肽段,进行结构获取:
当备选肽段的构象形成二环肽或首尾相接的环肽时,结束肽段延伸将此备选肽段作为环肽药物候选结构;所述备选肽段的构象形成二环肽,具体指短肽的N端、C端残基分别与其间隔两个或两个以上的非末端残基的距离小于4.5埃;所述备选肽段的构象形成首尾相接的环肽,具体指:短肽的N端与C端残基距离小于4.5埃时。
当备选肽段的构象形成长度超过16的线性肽时,结束肽段延伸并进入步骤(4);否则,进入步骤(2)。
步骤(2)和(3)中,判断肽段结构的方法具体如下:每个氨基酸与其不相邻残基的距离(中间至少间隔2个残基),如果N端或C端氨基酸与中间氨基酸距离小于4.5埃,则认为含有套索肽;如果N端氨基酸与C端氨基酸距离小于4.5埃,则认为是环肽;如果N端氨基酸与中间氨基酸距离小于4.5埃,C端氨基酸与另一个中间氨基酸距离小于4.5埃,则认为是二环肽。
所述肽段与蛋白的结合能力,采用结合能力评价指标进行量化评估,所述结合能力评价指标包括但不限于:接触残基对数量、形状互补系数、相互作用面积、结合自由能、亲和力的排名、和/或噬菌体展示技术筛选结果。本实施例肽段与蛋白的结合能力评价方法如下:
计算肽段与SORT1蛋白的相互作用残基对数N,根据相互作用残基对数N从大到小排序,选取前100个短肽,计算短肽N端到C端的C
最终我们筛选出侧链-侧链相连的环肽,SEQ ID NO:2,环肽可通过N端天冬氨酸侧链的羧基与C端丝氨酸的羟基形成酯化反应相连(图4),并且环肽分子与SORT1的结合非常紧密(图5)。
对于长度超过16个氨基酸残基的线性环肽药物候选结构,按照如下方法进行成环优化:
(4)在成环的关键氨基酸残基外,进行氨基酸突变获得新的备选肽段,当所述备选肽段的构象形成首尾相接的环肽或套索结构且与目标蛋白的结合能力超过预设阈值时,将所述备选肽段作为环肽药物候选结构,本实施例成环的关键氨基酸残基即N端和C端残基。具体为:
对于SEQ ID NO:2除N端和C端残基外,对其他残基作突变,插入,或者删除20种天然氨基酸处理,使用AlphaFold2.2.0生成上一步所有短肽与SORT1的复合物结构,计算短肽N端到C端的C
最终我们筛选出5个能够成环的短肽。
SEQ ID NO:3,如图6所示,N端的天冬氨酸与C端的丝氨酸非常接近,Cα碳原子距离仅为3.8埃,我们可以将L-天冬氨酸修改成D-天冬氨酸,把天冬氨酸的氨基变得离丝氨酸的羧基更接近,由羧基和氨基形成酰氨键来合成首尾相连环肽。
SEQ ID NO:4,如图7所示,N端的天冬氨酸与C端的丝氨酸非常接近,Cα碳原子距离仅为3.9埃,我们可以将L-天冬氨酸修改成D-天冬氨酸,把天冬氨酸的氨基变得离丝氨酸的羧基更接近,由羧基和氨基形成酰氨键来合成首尾相连环肽。
SEQ ID NO:5,如图8所示,N端的天冬氨酸与C端的丝氨酸较为接近,Cα碳原子距离为4.4埃,天冬氨酸的氨基和丝氨酸的羧基在同一侧,我们可以直接将羧基和氨基形成酰氨键来合成首尾相连环肽。
SEQ ID NO:6,如图9所示,N端的天冬氨酸侧链羧基与C端的丝氨酸的羟基较为接近,我们可以通过羧基与羟基形成酯化反应形成侧链侧链相连环肽。
SEQ ID NO:7,如图10所示,N端的天冬氨酸末端羧基与C端的丝氨酸末端氨基非常接近,我们可以直接将羧基和氨基形成酰氨键来合成首尾相连环肽。
SEQ ID NO:8,如图11所示,N端的天冬氨酸氨基和C端的丝氨酸的羧基在异侧,我们可以将L-天冬氨酸换成D-天冬氨酸或者将L-丝氨酸换成D-丝氨酸,可直接将羧基和氨基形成酰氨键来合成首尾相连环肽。
以下为实施例2:
本实施例提供的环肽药物从头设计方法,以PD1蛋白为例,设计靶向PD1特定热点残基的环肽,达到阻断PDL1与PD1结合的目的。具体包括以下步骤:
(1)筛选种子短肽:对于预设长度的短肽,采用蛋白质结构预测算法模拟其与目标蛋白的复合物结构;将其所有原子与目标蛋白的距离小于等于预设阈值的短肽作为种子短肽,从而初始化种子短肽;具体为:
获取PD1的主要序列,SEQ ID NO:9;获取PD1与PDL1结合的热点残基;生成所有20种天然氨基酸组成的初始3肽,共20
本实施例采用多种不同模型模拟短肽与目标蛋白的复合物结构,有原子距离小于4.5埃为氨基酸相互作用的判断,筛选能够与目标蛋白热点残基相互作用的初始三肽。
使用AlphaFold2.2.0生成所有初始3肽与PD1的复合物结构,Alphafold有5个不同的模型,共有5个不同的种子短肽与目标蛋白的复合物结构。
采用短肽的RMSD值或DockQ值作为种子短肽筛选指标。
将5个复合物结构的目标蛋白坐标两两对齐(采用SVD奇异值分解算法找到最佳的旋转与平移,使得两个结构的RMSD值最小)。对齐目标蛋白的结构坐标之后,只计算种子短肽的坐标的RMSD,如果种子短肽的RMSD太大,则说明不同模型预测的对接差别太大,结果不可靠。
用5个复合物坐标的两两DockQ值作筛选,优选两两DockQ值大于0.67的种子短肽。
DockQ值的计算方法如下。
DockQ主要由三项构成,Fnat(诱饵接触残基占天然接触残基比例),LRMSD(对齐受体后配体骨架原子均方根偏差)IRMS(对齐接触界面后的骨架原子均方根偏差)RMSD即为上文中种子短肽的RMSD,可见DockQ是比种子短肽的LRMSD更全面的评估参数。Basu S,Wallner B.DockQ:a quality measure for protein-protein docking models[J].PloSone,2016,11(8):e0161879.计算平均DockQ值,mDockQ值。
筛选能够靶向以上特定热点残基的初始三肽,然后依据mDockQ值排序,选取最优的25条初始三肽,作为锚定初始三肽。
(2)肽段延伸:在种子短肽的N端和/或C端按照预设步长延伸一段搜索肽段作为备选肽段,进入步骤(3);所述搜索肽段的氨基酸残基选自天然的20种氨基酸,步长为1。具体地:
当所述种子短肽具有线性结构时,分别延伸N端和C端。本实施例首先向25条短肽在N端和C端分别延伸20种天然氨基酸,共25*20*2=1000条。
当所述种子短肽具有套索结构时,在套索结构的游离端延伸一段搜索肽段作为备选肽段;
(3)备选肽段筛选:对于备选肽段采用蛋白质结构预测算法模拟其与目标蛋白的复合物结构;对于与目标蛋白的结合能力超过预设阈值的备选肽段获取其与目标蛋白的复合物结构中的构象;本实施例具体为:
使用AlphaFod2.2.0生成所有备选肽段与PD1的复合物结构;根据AlphaFold 5个模型生成的不同复合物结构,以其中一个模型为参考,计算其他模型与此模型的DockQ值,并且计算平均DockQ值,即mDockQ值;筛选mDockQ>0.5的备选肽段,进行结构获取:
当备选肽段的构象形成二环肽或首尾相接的环肽时,结束肽段延伸将此备选肽段作为环肽药物候选结构或进入步骤(4);所述备选肽段的构象形成二环肽,具体指短肽的N端、C端残基分别与其间隔两个或两个以上的非末端残基的距离小于4.5埃;所述备选肽段的构象形成首尾相接的环肽,具体指:短肽的N端与C端残基距离小于4.5埃。
当备选肽段的构象形成长度超过16的或套索肽时,结束肽段延伸并进入步骤(4);否则,进入步骤(2)。
步骤(2)和(3)中,判断肽段结构的方法具体如下:每个氨基酸与其不相邻残基的距离(中间至少间隔2个残基),如果N端或C端氨基酸与中间氨基酸距离小于4.5埃,则认为含有套索肽;如果N端氨基酸与C端氨基酸距离小于4.5埃,则认为是环肽;如果N端氨基酸与中间氨基酸距离小于4.5埃,C端氨基酸与另一个中间氨基酸距离小于4.5埃,则认为是二环肽。
所述肽段与蛋白的结合能力,采用结合能力评价指标进行量化评估,所述结合能力评价指标包括但不限于:接触残基对数量、形状互补系数、相互作用面积、结合自由能、亲和力的排名、和/或噬菌体展示技术筛选结果。本实施例肽段与蛋白的结合能力评价方法如下:
计算肽段与PD1蛋白热点残基的相互作用残基对数N’,根据相互作用残基对数N’从大到小排序,选取前100个短肽,计算短肽N端到C端的C
最终我们筛选出首尾主链相连的环肽,SEQ ID NO:10,环肽可通过N端天冬氨酸游离的氨基与C端亮氨酸游离的羧基通过肽键相连(图12),并且环肽分子与PD1的热点残基结合,达到阻断PD1与PDL1结合的目的(图13)。
(4)在成环的关键氨基酸残基外,进行氨基酸突变获得新的备选肽段,当所述备选肽段的构象形成首尾相接的环肽或套索结构且与目标蛋白的结合能力超过预设阈值时,将所述备选肽段作为环肽药物候选结构。
所述成环关键氨基酸残基,指具有环结构的多肽环结构两端的氨基酸残基:对于线性肽,所有的残基都不是成环关键氨基酸,即所有氨基酸残基都在成环的关键氨基酸残基外;对于环肽,则N端和C端的氨基酸为成环关键氨基酸;对于二环肽或套索肽,则N端与中间接触的氨基酸或C端与中间接触的氨基酸为成环关键氨基酸。
本实施例中,未搜索到构象形成长度超过16的线性肽。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。