一种基于少样本的文本分类方法
文献发布时间:2023-06-19 10:54:12
技术领域
本发明涉及文本分类技术领域,特别涉及一种基于少样本的文本分类方法。
背景技术
文本分类,或者称为自动文本分类,是指计算机将再有信息的一篇文本映射到预先给定的某一类别或某几类别主题的过程。文本包括新闻、文章、文字作品、小说、通知等,比如对一条新闻的文本进行分类时,可以判断将其分为体育新闻、娱乐新闻、时事政治新闻或天气预报等类别;再比如对一部小说的文本进行分类时,可以将其分为言情小说、武侠小说或悬疑小说等。可见,文本分类也属于对自然语言的处理过程,是对语义信息进行处理的技术应用领域。
主流的针对样本分类的传统深度学习技术需要大量的数据来训练一个好的模型,即需要大量的样本来训练模型,从而使用该模型对文本进行测试,以得到对该文本的分类结果。但是由于需要标记大量的数据,费时费力,因此少样本分类的学习是一个不错的选择。
少样本分类的学习是指使用较少的数据样本(即文本)达到准确分类的结果。少样本分类的学习关键是解决过拟合(overfitting)的问题,由于训练的数据样本太少,训练出的模型可能在训练集上的作用效果还行,但是在测试集上则会面临灾难性的打击,使得文本分类不准确。
为了解决现有技术中少样本分类学习的缺陷,人们的想法直接简单,既然训练集的数据样本不够,那就增加训练集的数据样本。但是增加训练集的数据样本后,又回到了传统深度学习的方式,需要对大量的训练集数据样本进行标记,仍然存在费时费力的问题。
所以,现在急需一种既可以增加训练集的数据样本,又节省人力、节省时间的方法。
发明内容
本发明的目的在于解决两个问题,一是少样本训练分类不准确,二是增加训练集但需要大量人工标注,提供一种基于少样本的文本分类方法。
为了实现上述发明目的,本发明实施例提供了以下技术方案:
一种基于少样本的文本分类方法,包括以下步骤:
步骤S1:使用z个翻译工具将数据集a中的每条数据分别翻译z次,以得到扩充后的数据集b;
步骤S2:使用预训练模型对扩充后的数据集b进行编码,得到向量集V;
步骤S3:将向量集V作为训练集x,将数据集a的标签作为训练集y,将所述训练集x和训练集y共同输入分类模型,对分类模型进行训练,直到得到收敛的分类模型。
在步骤S1中,所述数据集a中包括m类数据,平均每类数据中包括n条数据;
使用z个翻译工具将数据集a中m*n条数据分别翻译z次后,得到翻译数据z*m*n条;扩充后的数据集b包括z*m*n条翻译数据和m*n条数据集a。
所述预训练模型为BERT预训练模型。
分别使用每个翻译工具所对应的BERT预训练模型对各翻译工具翻译后对应的翻译数据进行编码。
还包括步骤S4:将待分类文本输入收敛的分类模型,得到该待分类文本的分类结果。
所述数据集a和/或待分类文本为文本,包括新闻、文章、文字、作品、小说、通知。
对所述训练集x和训练集y共同进行训练的分类模型为TextCNN文本分类模型。
与现有技术相比,本发明的有益效果:
本发明提出的基于少样本的文本分类方法,将原始少样本的数据进行大量扩充,以增加训练的样本,但并没有增加人工标注,因此一方面解决了少样本训练分类不准确的问题,另一方面也避免了需要人工标注所耗费的人力和时间。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍, 应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
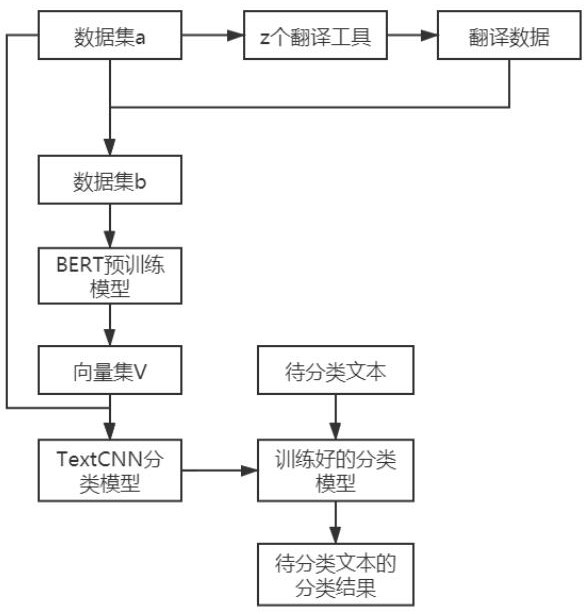
图1为本发明文本分类方法的流程图。
具体实施方式
下面将结合本发明实施例中附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。同时,在本发明的描述中,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性,或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。
本发明通过下述技术方案实现,如图1所示,一种基于少样本的文本分类方法,包括以下步骤:
步骤S1:使用z个翻译工具将数据集a中的每条数据分别翻译z次,以得到扩充后的数据集b。
所述数据集a中包括m类数据,平均每类数据中包括n条数据;使用z个翻译工具将数据集a中m*n条数据分别翻译z次后,得到翻译数据z*m*n条,具有几个翻译工具,就意味着可以将数据翻译为几种语言;扩充后的数据集b包括z*m*n条翻译数据和m*n条数据集a。
作为举例,数据集a中包括两类数据,第一类数据中有2条数据,第二类数据中有4条数据,因此平均每类数据中包括3条数据,那么数据集a中一共有6条数据。
接着使用三个翻译工具,比如中文-英文翻译工具、中文-日本翻译工具、中文-韩文翻译工具,对数据集a中的6条数据分别进行翻译,那么可以得到18条翻译数据。
这18条翻译数据再加上原始的数据集a中的6条数据,则构成数据集b,该数据集b即是本方案对少样本的数据集a进行扩充后的数据集。使用公式可以表达为数据集b=m*n*(z+1),其中m为数据集a的类别数量,n为数据集a平均每类数据中包含的数据条数,z为翻译工具的个数。
再作为举例,假设数据集a中包括1类数据,该类数据中包含1条数据,该条数据为“今天天气真好!”,使用中文-英文、中文-日本、中文-韩文这三个翻译工具对该条数据进行翻译后,得到:
“It's a nice day!”
“今日はいい天気ですね!”
“오늘 날씨 좋다!”
那么翻译后的3条数据再加上原始的数据集a中的一条数据,构成对数据集a扩充后的数据集b。
再作为举例,假设数据集a中包括15类数据,平均每类数据中包含50条数据,则数据集a中总共包含750条数据;使用10个翻译工具对数据集a中的数据分别进行翻译,得到翻译数据7500条数据;最后得到数据集b中的数据有8250条。
可见,本方案对数据集a进行翻译扩充后,即使数据集a是少样本类别,经过扩充后也能得到数据量翻倍的数据集b;并且不需要对数据集a或数据集b进行人工标注,也能用于后续的模型训练,既节省了人力,也节省了时间,大大降低了文本分类的成本。
步骤S2:使用BERT预训练模型对扩充后的数据集b进行编码,得到向量集V。
所述BERT预训练模型是基于双向Transformer的大规模预训练语言模型,该预训练模型能分别捕捉词语和句子级别的表示,高效抽取文本信息,并应用于各种NLP任务。
需要说明的是,本方案所述预训练模型采用BERT预训练模型只是一种较优的实施方式,所述预训练模型还可以使用其他可对语言进行预训练的模型,不过所述BERT预训练模型可以对各种语言(语种)进行训练,因此BERT预训练模型是最优选择。
在步骤S1中使用z个翻译工具对数据集a进行翻译后,会得到z种语言的翻译数据,每个翻译工具对应一个BERT预训练模型,比如在本方案中使用了中文-英文、中文-日本、中文-韩文这三个翻译工具,那么中文-英文翻译工具对应一个BERT预训练模型,中文-日文翻译工具对应一个BERT预训练模型,中文-韩文翻译工具对应一个BERT预训练模型。
接着使用中文-英文翻译工具对应的BERT预训练模型对中文-英文翻译工具翻译了数据集a后的翻译数据进行编码,假设经过对应的BERT预训练模型编码后得到英文语言下的向量V_Eng;使用中文-日文翻译工具对应的BERT预训练模型对中文-日文翻译工具翻译了数据集a后的翻译数据进行编码,假设经过对应的BERT预训练模型编码后得到日文语言下的向量V_Jap;使用中文-韩文翻译工具对应的BERT预训练模型对中文-韩文翻译工具翻译了数据集a后的翻译数据进行编码,假设经过对应的BERT预训练模型编码后得到韩文语言下的向量V_Kor。
还要使用中文对应的BERT预训练模型对数据集a进行编码,假设经过对应的BERT预训练模型编码后得到中文语言下的向量V_Chs。因此,使用各自对应的BERT预训练模型对扩充后的数据集b进行编码后,得到的向量集V即包括向量V_Eng、向量V_Jap、向量V_Kor、向量V_Chs。
步骤S3:将向量集V作为训练集x,将数据集a的标签作为训练集y,使用分类模型对所述训练集x和训练集y共同进行训练,直到得到收敛的分类模型。
本步骤是对通用的分类模型进行训练的过程,对分类模型进行训练的训练集包括训练集x和训练集y,其中:
训练集x=向量V_Eng+向量V_Jap+向量V_Kor+向量V_Chs;
训练集y=数据集a;
所述分类模型使用传统通用的分类模型即可,比如可以使用TxetCNN文本分类模型,将训练集x和训练集y输入该TxetCNN文本分类模型中进行训练,直到模型收敛,即得到收敛的分类模型,完成分类模型训练。
需要说明的是,所述文本分类模型不限于使用TxetCNN文本分类模型,还可以使用一般的逻辑回归模型、svm模型、深度学习的lstm模型及各种相关变体。
步骤S4:将待分类文本输入收敛的分类模型,得到该待分类文本的分类结果。
步骤S3中训练完成的分类模型即可用于实际测试,将待分类文本输入收敛的分类模型后,即可得到该待分类文本的分类结果。
综上所述,本发明提出的基于少样本的文本分类方法,将原始少样本的数据进行大量扩充,以增加训练的样本,但并没有增加人工标注,因此一方面解决了少样本训练分类不准确的问题,另一方面也避免了需要人工标注所耗费的人力和时间。
实施例2:
在实施例1的基础上,本实施例给出示意性的案例:
目前有标注好的金融相关数据作为数据集a,可得知数据集a中包括的类别,即表1中具有9个类别(m=9),一共有数据量873条(n=879/9=97)。在实际使用中,每类数据中包括的数据量不是相等的,因此n为平均每类数据中包括的数据条数。
使用中文-英文、中文-日文、中文-韩文这三种翻译工具对表1中的数据集a进行翻译,得到数据集b=9*97*(3+1)=3492条数据,如表2所示:
使用各翻译工具对应的BERT预训练模型对数据集b进行编码后,得到向量集V,然后将向量集V输入TextCNN分类模型中进行新联直至模型收敛,训练好的模型可用于对待分类文本进行分类。
本实施例其他方案与实施例1相同,故不赘述。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 一种基于少样本的文本分类方法
- 一种基于领域适应的少样本文本分类方法