一种基于深度学习的智能AI视频比对算法
文献发布时间:2023-06-19 18:29:06
技术领域
本发明涉及智能AI视频比对算法领域,具体是一种基于深度学习的智能AI视频比对算法。
背景技术
在互联网信息爆炸的时代,部分低俗的信息会降低人民群众的精神追求,一些虚假的谣言会使无辨别能力的人产生错觉,从而造成不必要的恐慌。因此,对互联网的众多信息需要做到大力监管。
由于很多有害的视频在传播前将其中内容会做一定的变换,使得大多数智能AI检测系统不能识别到,例如:将视频中的图像进行旋转、平移、色域变换等方式以此来欺骗智能AI 检测系统,深度学习的视频比对方式,鲁棒性已经很强,通常的变换方式都能够很好的识别到为有害视频,但是如果将视频中的图像经过旋转平移后出现大面积的黑色边框,黑色边框在整张图像中的占比大于一个阈值,这样还是很大程度上影响模型的效果。
发明内容
本发明要解决的技术问题就是克服以上的技术缺陷,提供一种基于深度学习的智能AI 视频比对算法,设置阈值,去除经过处理后的敏感视频出现经过旋转和平移等变换后图像出现大面积的黑色边框区域,去除边框干扰,提高图像比对准确率。
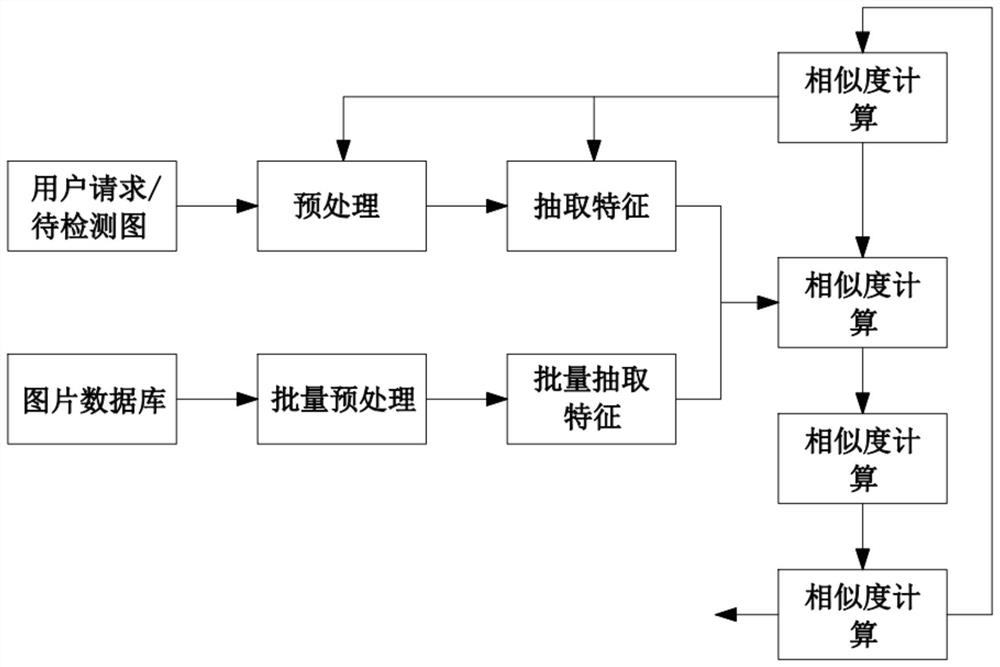
为了解决上述问题,本发明的技术方案为:一种基于深度学习的智能AI视频比对算法,包括以下步骤:
(1)将视频中违规的内容的起始时间和截止时间写入标签文件并与视频名称相对应且备注违规类型,之后读取标签文件中时间点信息对违规视频进行按秒截帧,并将违规区间内的视频帧进行保存形成违规库;
(2)使用Vgg_16卷积神经网络对违规库视频帧提取最后一层卷积特征,将提取到的特征向量进行归一化后存入第5代版本的层次数据格式文件中,即h5文件;
(3)h5将文件结构简化成数据集或组,其中,数据集就是同一类型数据的多维数组,组,是一种容器结构,可以包含数据集和其他组,若一个文件中存放了不同种类的数据集,这些数据集的管理就用到了组;
(4)对待比对视频帧进行去除黑边操作,判断图像中黑框面积占整张图像的比例,设置阈值,若黑框面积占比超过阈值则认为黑框对图像比对产生了干扰所以将其去除,然后使用 Vgg_16网络进行特征提取;
(5)加速查询,首先可以把数据集切分成多个Voronoi Cells,每个数据向量只能落在一个cell中,通过IndexIVFFlat索引,记为quantizer,来判断向量属于哪个cell,并将索引存入文件中;
(6)读取索引文件与特征h5文件,通过search方法通过余弦相似度查询待比对图像特征,得到top1或top n个结果以及比对到的视频帧对应视频中的时间,形成时间序列,根据时间前后差值得到此视频违规区间的起始时间和截至时间并得到违规类型。
进一步,所述步骤(1)中起始时间和截止时间均以秒为单位。
进一步,所述步骤(5)中查询时,只需查询query向量落在cell中的数据。
进一步,所述步骤(6)中的余弦相似度查询方法为通过向量空间中的两个向量夹角的余弦值衡量两个个体间差异大小的度量,值越接近1,就说明夹角角度越接近0°,也就是两个向量越相似。
进一步,所述衡量的对象为两个变量在各个方向即属性上的比例的相似度。
本发明与现有的技术相比的优点在于:本发明在精度上提高视频比对准确率8个百分点至99.2%,黑色边框不再干扰比对结果;在灵活性上,增加违规数据时,只需将增加数据提取特征添加到h5文件中,不需要对所有数据进行重新的特征提取;查询单张待比对图像耗时 0.19~0.78ms。
附图说明
图1是本发明中数据流程图。
具体实施方式
以下通过具体实施例进一步描述本发明,但本发明不仅仅限于以下实施例。在本发明的范围内或者在不脱离本发明的内容、精神和范围内,对本发明进行的变更、组合或替换,对于本领域的技术人员来说是显而易见的,且包含在本发明的范围之内。
实施例一
视频相似度比对测试
使用1台服务器,具体服务器的配置如下:
Gpu:NVIDIA Corporation GP102[TITAN Xp]
内存:128g
网卡:千兆网卡
磁盘:5T
实验数据采用多个视频进行每秒抽帧后得到的1千万张图像。
测试数据采用相同视频随机按秒抽帧后的1万张图像,这1万张图像为原始图像不做任何处理,并将这1万张图像插入新的正常视频中进行比对。
测试过程Gpu的利用率达到90-100%。
测试的结果,将新合成的视频按秒抽帧与库中1千万张数据比对时间共2.1s,比对准确率达到100%。
实施例二
视频相似度比对测试
使用1台服务器,具体服务器的配置如下:
Gpu:NVIDIA Corporation GP102[TITAN Xp]
内存:128g
网卡:千兆网卡
磁盘:5T
实验数据采用多个视频进行每秒抽帧后得到的1千万张图像。
测试数据采用相同视频随机按秒抽帧后的1万张图像,并对这1万张视频帧进行图像增强包括Flip、Rotation、Scale、Crop、Translation、Gaussian Noise等多种变换,并插入到新的正常视频中。
测试过程Gpu的利用率达到90-100%。
测试的结果,1万张测试数据与库中1千万张数据比对时间共2.1s,比对准确率达到99.2%。
实施例一和实施例二的数据如表1所示:
表1
以上所述仅为本发明专利的较佳实施例而已,并不用以限制本发明专利,凡在本发明专利的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明专利的保护范围之内。
- 一种基于深度学习的视频智能监控算法架构方法和系统
- 一种基于深度学习的视频智能监控算法架构方法和系统