一种应用于垂直领域的固定格式文档结构化识别的方法
文献发布时间:2023-06-19 19:23:34
技术领域
本发明属于图像识别技术领域,具体是一种应用于垂直领域的固定格式文档结构化识别的方法。
背景技术
随着深度学习的发展,人们对OCR(光学字符识别)技术提出了更高的要求,不仅仅识别图片中的文字,更希望OCR技术可以理解图片内容,自动从图片中抽取所需要的信息,对图片进行结构化识别。现实中图片内容排版千奇百怪,内容间的语义关联也各种各样,不同用户对语义信息的需求也不一样,这对于OCR技术是很大的挑战,目前仍没有一个OCR模型可以较好的理解现实即通常场景的图片文档。但在垂直领域中,文档结构化识别应用十分广泛,如身份证、行驶证、发票、合同等结构化识别,原因在于,文档格式固定,不同文档中,位置相同的地方,语义信息相同,例如,所有身份证姓名所在的位置都是一样的。
对于垂直领域固定格式文档的结构化识别的方法,直接使用通用场景的OCR模型识别效果差,原因在通用的OCR模型在训练时无该垂直领域的文档数据,其次,通用的OCR模型进行文档结构化识别,无法理解文本区域的语义信息,需要编写规则匹配。通常的方案是人为标记目标区域,训练检测和识别模型,在使用时通过检测模型检测感兴趣的区域,再通过识别模型进行OCR识别。但该方案需要人工标记大量的数据,来训练检测和识别模型,因此,为了解决上述问题,本发明提供了一种应用于垂直领域的固定格式文档结构化识别的方法。
发明内容
为了解决上述方案存在的问题,本发明提供了一种应用于垂直领域的固定格式文档结构化识别的方法。
本发明的目的可以通过以下技术方案实现:
一种应用于垂直领域的固定格式文档结构化识别的方法,具体方法包括:
步骤一:定义参照区域和目标区域,制作模板文档;
进一步地,制作模板文档的方法包括:
从所有文档中选择无形变的图片,进行图片预处理,根据参照区域和目标区域的定义对文档中的参照区域和目标区域进行标注,形成预定好的模板文档格式。
进一步地,模板文档格式定义为由
步骤二:生成标记数据;
进一步地,生成标记数据的方法包括:
获取未标注的文档,通过OCR检测和识别模型检测和识别参照区域,检测模型检测文本行所在区域,输出文本区域的左上角和右下角坐标;识别模型识别图片中的文本内容,输出文本,获得文本区域的位置信息和内容信息;与模板文档进行模板匹配确定参照字段,基于OCR检测和识别模型的输出的结果,与模板文档中的文本内容进行匹配,获得输出结果对应的参照字段;根据模板匹配的结果,标记参照区域和目标区域,基于检测结果修正标记结果。
进一步地,确定参照区域和目标区域的方法包括:
当在待识别的文档中找到与模板文档四组及以上对应的坐标点时,进行透视变换,计算透视矩阵,计算待识别的文档中参照区域和目标区域的坐标点;当匹配到三组坐标点时,则进行仿射变换;当小于三组坐标点时,则放弃该样本;经过透视或者放射变换获得参照区域和目标区域。
比对生成的结果和检测的结果,利用平移,缩放,旋转等操作,对生成的标记结果进行细微的修正。
步骤三:对参照区域的OCR检测和识别模型进行优化;
进一步地,对参照区域的检测和识别模型进行优化的方法包括:
对标记数据进行数据增强,增加有样本多样性,利用标记数据对通用的OCR检测和识别模型进行训练,获得优化OCR检测和识别模型。
步骤四:优化目标区域的OCR识别模型;
进一步地,优化目标区域的OCR识别模型的方法包括:
获取步骤二中得到的文档中目标区域对应位置的标记数据,采取数据合成方式,提取目标区域的背景,在背景图片上合成文字,生成对应的训练数据,通过获得的训练数据对通用的OCR识别模型进行优化,获得优化OCR识别模型。
步骤五:通过优化OCR检测和识别模型与优化OCR识别模型对文档进行结构化识别。
进一步地,对文档进行结构化识别的方法包括:
获取未标记的文档数据,通过优化OCR检测和识别模型检测和识别参照区域,根据模板文档匹配确定参照字段,基于模板匹配结果确定目标区域,通过优化OCR识别模型进行内容提取。
与现有技术相比,本发明的有益效果是:利用在通用场景训练好的OCR模型并结合模板匹配,自动生成标记数据,对模型进行优化,无需人为标记垂直领域的文档数据。相比于通用场景的OCR模型,具有更高的识别准确度,相比于人工标记大量的数据,来训练的检测和识别模型,本发明无需人为标记数据,减少人力成本。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
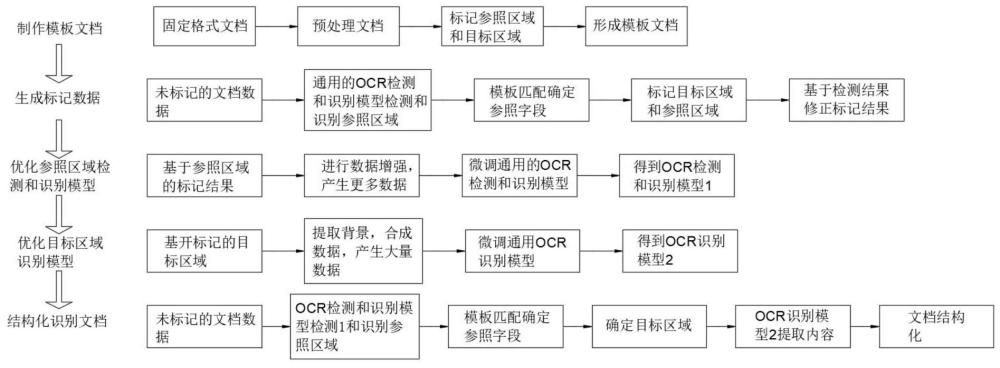
图1为本发明方法流程图。
具体实施方式
下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,一种应用于垂直领域的固定格式文档结构化识别的方法,利用在通用场景训练好的OCR模型并结合模板匹配,自动生成标记数据,对模型进行优化。相比于只使用通用场景的OCR模型,具有更高的识别准确度,相比于人工标记大量的数据,来训练的检测和识别模型,本发明无需人为标记数据,减少人力成本。本发明应用场景为垂直领域的固定格式文档,文档中字段值不变的区域称为参照区域,文档中字段值变化的区域称为目标区域,每个字段位置表示的语义含义已知,例如,身份证人像面中,右下角一连串数字所在的位置即身份证号所在位置。
具体方法包括:
步骤一:定义参照区域和目标区域,制作模板文档;
制作模板文档的方法包括:
从所有文档中选择无形变的图片,进行图片预处理,预处理为去除背景,旋转等预处理操作,确保图片中只有文档信息,并且文档为摆正的形态;根据参照区域和目标区域的定义对文档中的参照区域和目标区域进行标注,形成预定好的模板文档格式。
其中模板文档格式定义为由
步骤二:生成标记数据;
生成标记数据的方法包括:
针对未标注的文档,首先利用通用的OCR检测和识别模型检测和识别参照区域。检测模型检测文本行所在区域,输出文本区域的左上角和右下角坐标;识别模型识别图片中的文本内容,输出文本。一张图片文档经过OCR检测模型和识别模型最终输出文本区域的位置信息和内容信息。再与模板文档进行模板匹配确定参照字段,基于OCR检测和识别模型的输出的结果,与模板文档中的文本内容进行匹配,找到输出结果对应的参照字段。基于模板匹配的结果,确定参照区域和目标区域,具体做法是:若能在待识别的文档中找到与模板文档四组及以上的对应的坐标点,可进行透视变换,计算透视矩阵,进而计算待识别的文档中参照区域和目标区域的坐标点;若只能匹配到三组坐标点,则进行仿射变换;若小于三组坐标点,则放弃该样本。模板文档中的文本框为人为标记,而待识别文档中的文本框是算法输出的最小矩形,经过透视或者放射变换的得到的参照区域和目标区域,与实际区域较小的差异。为得到更精确的文本框标记结果,我们比对生成的结果和检测的结果,利用平移,缩放,旋转等操作,对生成的标记结果进行细微的修正。
步骤三:优化参照区域的检测和识别模型;
优化参照区域的检测和识别模型的方法包括:
对标记数据进行数据增强,增加有样本多样性,利用标记数据,对通用的OCR检测和识别模型进行微调,获得OCR检测和识别模型1;
对标记数据进行数据增强是参照Data Augmentation for Scene TextRecognition.Interactive Labeling and Data Augmentation for Vision ICCV2021Workshop中的方式进行的。
步骤四:优化目标区域识别模型;
经过步骤二的处理,得到文档中目标区域的位置的标记数据,内容未知,采取数据合成方式,提取目标区域的背景,在背景图片上合成文字,生成大量的数据,来微调通用的OCR识别模型,得到OCR识别模型2。
采取数据合成方式,参考Editing Text in the Wild.Proceedings of the 27thACM international conference on multimedia.2019.中的方式进行。
步骤五:文档结构化,利用步骤三和步骤四训练的模型,对文档进行结构化识别。
对文档进行结构化识别的方法包括:
获取未标记的文档数据,通过OCR检测和识别模型1检测和识别参照区域,根据模板文档匹配确定参照字段,基于模板匹配结果确定目标区域,通过OCR识别模型2进行内容提取。
上述公式均是去除量纲取其数值计算,公式是由采集大量数据进行软件模拟得到最接近真实情况的一个公式,公式中的预设参数和预设阈值由本领域的技术人员根据实际情况设定或者大量数据模拟获得。
以上实施例仅用以说明本发明的技术方法而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方法进行修改或等同替换,而不脱离本发明技术方法的精神和范围。
- 一种解析便携式文档格式文档表格的方法及装置
- 一种基于图像数据处理的非结构化文档格式识别方法
- 一种对固定格式文档的识别处理方法及处理系统