一种基于车联网大数据的车辆能耗评价方法
文献发布时间:2023-06-19 10:32:14
技术领域
本发明涉及一种基于车联网大数据的车辆能耗评价方法,属于车辆能耗评价领域。
背景技术
随着科学技术的不断发展,发动机所涉及的方面越来越多,人们也在努力的研究着不同用途多种类型的发动机,人们对于车辆的经济性方面关注也越来越多;在目前传统的汽车行业中,也有着能耗分析的技术,但大多都基于单个车辆或是对于单一品牌的车辆进行抽样分析和评估,并且要求车辆必须驶入特定场地进行测试。
近年来,大数据在各行各业的发展规模都在迅速扩大、发展迅猛,行业应用所产生的数据呈爆炸性增长,物联网也在随之发展,车联网大数据也初具规模,但而目前却缺少将大数据和机器学习相结合完成车辆能耗评价的应用;通过对少量车辆的抽样评估来定义一种车辆的能耗水平,虽然可以反应出一定的问题,但是却也存在局限性,并且限制条件苛刻,无法大规模应用。
传统的车辆能耗评价方法需要大量线下抽样检测来增加结果的普遍性和准确度,但却无法实时监测每一辆车的能耗是否出现异常;而仅仅基于大数据技术,也会因影响能耗因素众多、缺乏完整科学的数据处理分析方法,导致无法完成车辆能耗评价问题,如果想要检测一辆车的能耗水平,只能通过修理厂或检测机构的检测才能实现;而将大数据实时处理技术和机器学习相结合,能够实时监测每一辆车的能耗水平,完美的解决了传统检测方法耗时、耗力的弊端。
发明内容
本发明提出的是一种基于车联网大数据的车辆能耗评价方法,其目的旨在解决现有技术无法实时监测车辆能耗水平的问题。
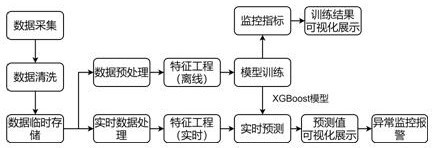
本发明的技术解决方案:一种基于车联网大数据的车辆能耗评价方法,该方法包括数据采集阶段,训练阶段,预测阶段;所述数据采集阶段包括:步骤1-1)数据采集获得原始数据,步骤1-2)数据清洗,步骤1-3)数据临时存储;所述训练阶段包括:步骤2-1)数据预处理,步骤2-2)离线特征工程,步骤2-3)经过模型训练生成XGBoost模型,步骤2-4)监控指标,步骤2-5)训练结果可视化展示;所述预测阶段包括:步骤3-1)实时数据处理,步骤3-2)实时特征工程,步骤3-3)实时预测,步骤3-4)预测值可视化展示,步骤3-5)异常监测报警;所述训练阶段为预测阶段的基础,预测阶段以训练阶段所生成的XGBoost模型为基础来进行预测。
进一步地,所述数据采集获得原始数据具体包括:通过将车辆终端采集的原始报文数据进行实时传输收集,并将收集的原始报文数据通过批量解析获得原始数据。
进一步地,所述数据清洗具体包括:将数据采集获得的原始数据中不合理数据以及空数据去除。
进一步地,所述数据临时存储具体包括:采用临时存储模块对经过数据清洗后的原始数据进行数据临时存储;经过数据临时存储三天以上的原始数据为离线数据。
进一步地,所述数据预处理具体包括以下过程:
1) 对离线数据连续性进行分片标记,针对连续两条离线数据,对时间间隔大于20s的离线数据标记为1,离线数据中的其他数据标记为0,避免后续筛选连续工况时导致的选择性偏差;
2) 对离线数据进行分片标记后,剔除掉数据量极少的车辆终端所采集的数据;所述数据量根据具体车辆终端的采样频率,计算出每个车辆终端一天内的总采样时间,对于一天内总采样时间的跨度不大于半小时的车辆终端,该车辆终端所采集的数据被认为是数据量极少的车辆终端所采集的数据;
3) 剔除异常数据;所述异常数据为出现车辆速度≥200 km/h、发动机转速为负、能耗量为负三种情况中的一种或两种或三种的数据;
4) 根据车辆终端采集并上传原始报文数据的时间,将时间标记精确到分钟(如转化前:12:10:50,12:10:20;转化后:12:10),转化为对应的分钟级;
5) 剔除分片标记包含1的对应终端该分钟的数据;对于聚合后分片标记包含1的数据,该分钟数据连续性较差,与常规工况差异较大,不具有参考价值。
进一步地,所述离线特征工程是把经过数据预处理后的离线数据进行原始特征的特征值提取处理,并将提取处理后的特征值分为训练集和验证集;所述原始特征包括车辆速度、发动机转速、能耗量;所述离线数据为经过数据临时存储三天以上的原始数据;经过对离线数据进行原始特征的特征值提取处理,将提取处理后的特征值分为训练集和验证集。
进一步地,所述能耗量的特征值提取处理包括对能耗量的数据进行筛选,对能耗量的数据进行筛选具体包括如下步骤:
1) 将数据预处理后形成的分钟级数据进行聚合,关注每分钟内每辆车各自发动机转速平均值;
2) 对发动机转速的平均值进行分区;优选地,发动机转速平均值范围在0~2000r/min之间,将发动机转速平均值范围以每10个转速值为一个小区间划分为200个小区间;
3) 绘制发动机转速和能耗量的关系图,在每个发动机转速区间上,计算90分位数得到90分位点,取90分位点以下的能耗量作为正常能耗水平的数据,用于训练能耗量的回归模型。
进一步地,所述经过模型训练生成XGBoost模型具体包括:将训练集用于模型训练,剔除训练集中的缺失值,确保进入模型训练前不包含任何缺失值;其中能耗量作为标签,离线特征工程后获取的除能耗量以外的原始特征的特征值作为工况特征,因标签信息明确,所以采用监督学习的方法,使用XGBoost算法构建回归模型拟合能耗量与工况特征的关联性;XGBoost算法的超参数设定为默认值。
进一步地,所述监控指标具体为:在模型训练过程中采取交叉验证的方法,需要记录验证集的相关参数,将验证集的相关参数作为监控指标使用,具体验证集相关参数通过以下步骤取得:
1)将验证集代入XGBoost模型,通过XGBoost模型拟合后得到模拟值;
2)将离线数据进行分钟内求和得到真实的能耗;
3)利用公式
4)利用公式
5)利用公式
进一步地,所述实时数据处理采用流式处理,实时的对数据进行清洗和预处理为实时特征工程做准备。
进一步地,所述实时特征工程具体包括:获取实时数据的分钟级的特征值用作实时预测;所述实时预测具体为:将合实时数据代入经过训练阶段中经过交叉验证的XGBoost模型进行预测得到预测值,比较预测值和真实值的偏差。
进一步地,所述预测值可视化展示具体为:将预测值和真实值在直角坐标系上以时间为横轴,预测值和真实值作为纵轴进行打点,在可视化平台上通过图表展示,取真实值高出预测值1.2倍的点为异常点。
所述异常监测报警,为了避免单个分钟级的数据点的误差影响结果的判断,所以采用按天的周期进行统计,当超过20%的数据出现异常,则认为车辆的能耗水平出现偏差,可实现对能耗异常的车辆告警。
本发明的优点:
1)本发明实现了当前大数据场景下车辆的能耗评价工作,能够实时监测车辆的能耗水平,基于完善的预警体系,为车辆的故障排查提供了可靠的依据,在一定程度上避免了能耗异常却不知情而造成的能源浪费,降低了因不能及时发现发动机故障而发生事故的风险;
2)基于车联网大数据和机器学习技术,能够在海量数据收集、存储、计算基础之上,构建合理的分析模型,两者相辅相成,进一步提高了模型分析结果的准确性、降低了检测成本。
附图说明
附图1是本发明的整体实施流程图。
附图2是训练阶段的具体实施流程。
附图3是预测阶段的具体实施流程。
具体实施方式
下面结合具体实施方式对本发明做详细说明。
一种基于车联网大数据的车辆能耗评价方法,该方法包括数据采集阶段,训练阶段,预测阶段;所述数据采集阶段包括:步骤1-1)数据采集获得原始数据,步骤1-2)数据清洗,步骤1-3)数据临时存储;所述训练阶段包括:步骤2-1)数据预处理,步骤2-2)离线特征工程,步骤2-3)经过模型训练生成XGBoost模型,步骤2-4)监控指标,步骤2-5)训练结果可视化展示;所述预测阶段包括:步骤3-1)实时数据处理,步骤3-2)实时特征工程,步骤3-3)实时预测,步骤3-4)预测值可视化展示,步骤3-5)异常监测报警;所述训练阶段为预测阶段的基础,预测阶段以训练阶段所生成的XGBoost模型为基础来进行预测。
所述数据采集获得原始数据具体为:通过将车辆终端采集的原始报文数据进行实时传输收集,并通过批量解析获得原始数据;在对不同批次的原始报文数据进行批量解析时采用的解析标准存在一定差异,且存在不合理数据和空数据所以需要进行数据清洗。
所述数据清洗具体为:将数据采集获得的原始数据中不合理数据、空数据去除以及将对应的问题数据进行提取并统一命名;所述不合理数据为超出常理的数据,例如:车辆速度≥200km/h;所述空数据为未采集到值的数据,因为网络传输异常或终端异常等原因,会出现脏数据以及少量数据丢失情况,因解析标准的改变,而产生的对相同数据不同的称呼,需要将对应的问题数据进行提取并统一命名。
所述数据临时存储具体为:采用临时存储模块对经过数据清洗后的原始数据进行数据临时存储;因为训练阶段需要用到离线数据,而预测阶段需要对实时数据进行实时预测,所以采用临时存储模块对经过数据清洗后的原始数据进行数据临时存储,起到防止数据丢失和根据处理能力自行调节数据拉取速度的作用。
所述数据预处理具体包括以下过程:
1) 对离线数据连续性进行分片标记,针对连续两条离线数据,对时间间隔大于30s的离线数据标记为1,离线数据中的其他数据标记为0,避免后续筛选连续工况时导致的选择性偏差;
2) 对离线数据进行分片标记后,剔除掉数据量极少的车辆终端所采集的数据;所述数据量根据具体车辆终端的采样频率,计算出每个车辆终端一天内的总采样时间,对于一天内总采样时间的跨度不大于半小时的车辆终端,该车辆终端所采集的数据被认为是数据量极少的车辆终端所采集的数据;数据量极少的车辆终端所采集的数据,其分布会出现较大差异,干扰XGBoost模型的模型训练过程;
3) 剔除异常数据;所述异常数据为出现车辆速度≥200 km/h、发动机转速为负、能耗量为负三种情况中的一种或两种或三种的数据;
4) 根据车辆终端采集并上传原始报文数据的时间,将时间标记忽略秒数精确到分钟级(如转化前:12:10:50,12:10:20;转化后:12:10),用于后续操作;后续进行XGBoost模型建模时需要对同一分钟内的离线数据进行聚合,聚合方式见表1;
5) 剔除分片标记包含1的对应终端该分钟的数据;对于聚合后分片标记包含1的数据,该分钟数据连续性较差,与常规工况差异较大,不具有参考价值。
所述数据预处理是因为驾驶员个人行为、终端异常状态、网络传输等原因,部分车辆终端采集数据完整度较差,数据不连续的情况非常常见;因此在模型训练进行建模之前,需要对离线数据采取数据预处理,才能用于离线特征工程的构建和模型训练的建模。
通过以上的数据预处理过程,数据基本满足离线特征工程的需要,接下来需要通过离线特征工程构建训练集和验证集作为模型训练的基础。
所述离线特征工程是把经过数据预处理后的离线数据进行原始特征的特征值提取处理,并将提取处理后的特征值分为训练集和验证集;所述原始特征包括车辆速度、发动机转速、能耗量;所述离线数据为经过数据临时存储三天以上的原始数据;进一步的,所述原始特征还包括传动比倒数(档位)、环境温度、大气湿度、大气压力、机油温度、发动机水温、实际总扭矩百分比、摩擦扭矩百分比、发动机净输出扭矩、实际扭矩百分比、风扇转速、能耗量;经过对离线数据进行原始特征的特征值提取处理,使特征值更易于模型训练,将提取处理后的特征值分为训练集和验证集用于交叉验证。
所述训练集构建的目的是为了训练出能够检测出在与所提取处理的特征值相类似的工况条件下,能耗超过正常水平的车辆;由于缺少较为直接的能耗水平好坏的评价标准,所以本发明采用级联模型的方法,选取正常能耗水平的车辆数据作为训练集,构建能耗与车辆行驶状态及工况的关联关系;优选地,所述级联模型为XGBoost算法,XGBoost算法就是决策树的级联模型。
所述特征值提取处理的方法如表1所示,其中与能耗水平相关联的最重要的变量为发动机转速和车辆速度,发动机转速和车辆速度为不可缺少的特征值,能耗量作为监督学习标签也不可缺少,其余原始特征的特征值对能耗水平也有着一定的影响,可根据终端采集到的原始数据的实际情况进行调整,需要基于不同标准的发动机转速,对能耗量的数据进行筛选。
所述能耗量的特征值提取处理包括对能耗量的数据进行筛选,所述对能耗量的数据进行筛选具体包括如下步骤:
1) 将数据预处理后形成的分钟级数据进行聚合,关注每分钟内每辆车各自发动机转速平均值;
2) 对发动机转速的平均值进行分区;优选地,发动机转速平均值范围在0~2000r/min之间,将发动机转速平均值范围以每10个转速值为一个小区间划分为200个小区间;
3) 绘制发动机转速和能耗量的关系图,在每个发动机转速区间上,计算90分位数得到90分位点,取90分位点以下的能耗量作为正常能耗水平的数据,用于训练能耗量的回归模型。
通过上述处理,可以最大程度上确保进入模型训练的训练集为正常能耗水平的数据,避免因为引入异常的数据而导致建立级联模型时引入误差;经过离线特征工程后的训练集,将作为训练数据用于XGBoost模型的构建,其中能耗量为目标变量,其余变量为描述车辆运行工况和总体情况的特征变量,来构建正常能耗水平下能耗量与这些描述车辆运行工况和总体情况的特征变量间的关联关系,所述描述车辆运行工况和总体情况的特征变量为发动机转速和车辆速度等原始特征的特征值变量;因为将秒级数据聚合至分钟级数据时会产生缺失值,可能对模拟训练产生不利,需要在模型训练前进行过滤,所以选取90分位点以下数据作为能耗水平正常的数据;验证集的范围为离线特征工程后获得的特征值数据中未被训练集覆盖的数据集(用于比较级联模型的效果)。
所述经过模型训练生成XGBoost模型具体包括:剔除所有特征集中的缺失值,将通过处理后的百分之八十的特征集作为模型的训练集,特征集是指离线特征工程中提取处理后的特征值的集合,确保进入模型训练前不包含任何缺失值;其中能耗量作为标签,离线特征工程后获取的除能耗量以外的原始特征的特征值作为工况特征,因标签信息明确,所以采用监督学习的方法,使用XGBoost算法构建回归模型拟合能耗量与工况特征的关联性;XGBoost算法的超参数设定为默认值即可。
所述监控指标具体为:在模型训练过程中采取交叉验证的方法,需要记录验证集的相关参数,将验证集的相关参数作为监控指标使用,具体验证集相关参数通过以下步骤取得:
1)将验证集代入XGBoost模型,通过XGBoost模型拟合后得到模拟值;
2)将离线数据进行分钟内求和得到真实的能耗;
3)利用公式
4)利用公式
5)利用公式
通过上述监控指标,可以监控XGBoost模型是否存在问题,XGBoost模型的准确性直接影响着预测阶段的结果。
所述训练结果可视化展示主要目标是更直观观察模拟训练所得的XGBoost模型的可靠性,可以通过XGBoost模型在验证集上的表现作为判断模型效果的标准,借助模型训练过程中的数据打点,在可视化平台上构建相应报表展示训练的结果;XGBoost模型不仅需要通过验证集的检验,还需要至少三次将实时数据代入XGBoost模型,通过观测得到的监控指标来检验模型的可靠性。
所述实时数据处理采用流式处理,实时的对数据进行清洗和预处理为实时特征工程做准备。
所述实时特征工程具体为:获取实时数据的分钟级的特征值用作实时预测;所述实时预测具体为:将合实时数据代入训练阶段中经过交叉验证的XGBoost模型进行预测得到预测值,比较预测值和真实值的偏差。
所述预测值可视化展示具体为:将预测值和真实值在直角坐标系上以时间为横轴,预测值和真实值作为纵轴进行打点,在可视化平台上通过图表展示,取真实值高出预测值1.2倍的点为异常点。
所述异常监测报警,为了避免单个分钟级的数据点的误差影响结果的判断,所以采用按天的周期进行统计,当超过20%的数据出现异常,则认为车辆的能耗水平出现偏差,可实现对能耗异常的车辆告警。
将时间标记转化为对应的分钟级时的聚合方式如下方表1:
表1中最大值、最小值、平均值、中位数、求和分别为对同一分钟内对各个处理特征的数据分别进行取最大值、取最小值、取平均值、取中位数、求和。
本发明的整体实施流程如图1所示,对通过终端采集来的原始报文数据进行解析得到原始数据然后进行初步数据清洗,采集的数据根据不同终端均有不同,本发明所用到的测点均为国标数据,将数据放入临时存储模块进行临时存储,然后使用存储到本地的离线数据进行分析建模,再通过模型训练获取的XGBoost模型对处理后的实时数据进行实时预测,将实时预测的到的理论能耗量作为预测值和特征值中的能耗量形成的真实值进行对比寻找能耗异常设备;临时存储模块主要起到将采集的数据临时存储,避免数据丢失,方便同时进行离线和实时处理;本发明的模型训练整体采用级联的形式,先进行数据预处理,然后使用XGBoost算法构建正常能耗水平下能耗量与特征值的相关关系,得到预测值,再根据实时特征工程获取的分钟级的能耗量所体现出的真实能耗和预测值的差值来判断车辆是否处于异常能耗的水平。
本发明中部分术语的定义如下:
能耗异常:特指车辆行驶时能耗高于正常水平;监督学习:使用带标签的数据构建模型的方法,可以用于构建分类或回归模型;离线数据:将采集的数据进行存储,存储后的多天数据,优选地,本发明中采取存储三天以上的数据为离线数据;实时数据:线上采集的具有实时性的数据;级联模型:模型集成的一种常见方法,特征在于下一阶段的模型使用了上一阶段模型的输出,可以是模型的输出结果,或经过二次处理的特征。
- 一种基于车联网大数据的车辆能耗评价方法
- 一种基于车联网大数据的车辆动力性综合评价方法