面向社交媒体平台的中文多模态命名实体识别方法及系统
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于自然语言处理的技术领域,具体涉及一种面向社交媒体平台的中文多模态命名实体识别方法及系统。
背景技术
命名实体识别是自然语言处理中一项具有重要实用价值的基本任务。它旨在非结构化文本中定位和分类命名实体,如人名、地名、组织机构名等。多模态命名实体识别是一项集成多种感知模态信息的自然语言处理任务,旨在从多源数据中准确识别和分类命名实体。传统的命名实体识别通常仅关注文本信息,而多模态命名实体识别将文本与其他模态(如图像、音频、视频等)的信息相结合,大幅提升了命名实体识别的效果和应用范围。
以往的命名实体识别工作和多模态命名实体识别工作大都集中在英语语料库上,对中文多模态命名实体识别任务的相关研究和分析较少。一方面,受限于中文多模态语料库的匮乏;另一方面,中文文本存在大量的汉语特殊语言现象和复杂结构、中文文本句式灵活、结构不如英语严谨;此外,中文多模态社交媒体推文存在多图像的特点,因此,中文多模态命名实体识别任务中不同模态之间的数据特征交互更加困难,加大了中文多模态命名实体识别的难度。
发明内容
本发明的目的在于针对现有技术的不足之处,提供一种一种面向社交媒体平台的中文多模态命名实体识别方法,该方法解决了现有技术中中文多模态语料库的匮乏以及中文文本存在大量的汉语特殊语言现象和复杂结构导致的识别精度不高的问题。
为解决上述技术问题,本发明采用如下技术方案:
一种面向社交媒体平台的中文多模态命名实体识别方法,包括如下步骤:
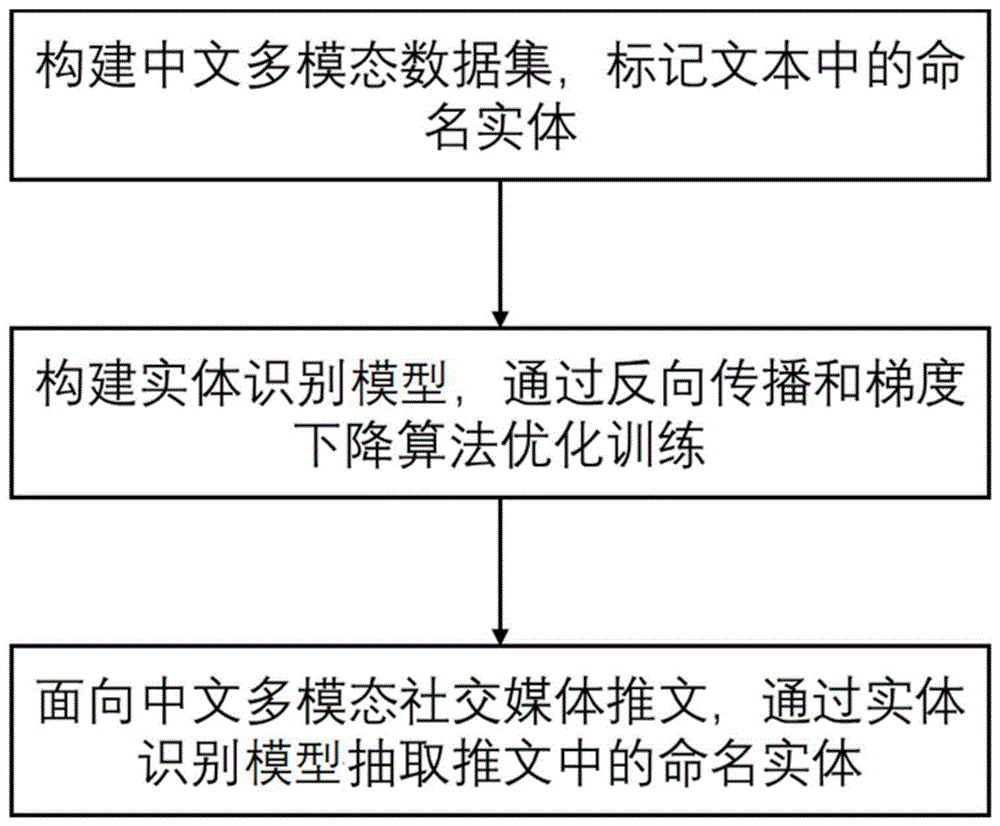
步骤1、获取社交媒体平台中包含不同模态信息的推文,并以此构建中文多模态数据集,将数据集按比例随机划分为训练集、验证集和测试集,标记数据集中每条推文所包含的所有命名实体以及对应的实体类别;
步骤2、构建实体识别模型,将训练集中的每条推文输入到实体识别模型中对其进行训练,在训练过程中构建损失函数,对实体识别模型不断迭代训练直至损失函数不再降低,并采用验证集进行验证得到优化后的实体识别模型;
步骤3、采用测试集对优化后的实体识别模型进行精度评价,并采用精度符合要求的实体识别模型对中文多模态社交媒体推文进行预测,得到中文多模态社交媒体推文中包含的所有命名实体及命名实体所对应的实体标签。
进一步地,步骤1中每条推文为每条包含了文本和若干图像的社交媒体推文,且文本中至少包含一个命名实体。
进一步地,步骤2中实体识别模型包括文本编码模块、图像编码模块、多模态交互模块、实体边界检测模块、实体识别模块;其中,
文本编码模块,用于对每条推文的文本进行编码以得到每条推文文本的目标文本向量,并将每条推文文本的目标文本向量输出至多模态交互模块和实体边界检测模块中;
图像编码模块,用于将每条推文的图像进行编码以得到每条推文对应图像的目标图像向量,并将每条推文对应图像的目标图像向量输出至多模态交互模块;
多模态交互模块,用于将每条推文的目标文本向量和目标图像向量进行交互融合,得到融合了目标文本特征和目标图像特征的目标推文向量,并将每条推文的目标推文向量输出至实体识别模块;
实体边界检测模块,用于将每条推文的目标文本向量通过自注意力机制处理得到新的目标文本向量,并对每条推文新的目标文本向量进行实体边界检测,再将每条推文的实体边界检测结果输出至实体识别模块;
实体识别模块,用于以实体边界检测结果作为实体识别约束,对每条推文新的目标推文向量进行实体识别。
进一步地,文本编码模块包括BERT模块,图像编码模块包括ResNet模块,多模态交互模块包括Transformer模块,实体边界检测模块包括Transformer模块和CRF模块,实体识别模块包括CRF模块。
进一步地,步骤2中,在训练的过程中通过反向传播和梯度下降优化算法对实体识别模型进行迭代训练。
进一步地,步骤2中构建的损失函数为:
其中,
进一步地,实体识别模型预测命名实体及命名实体所对应的实体标签的方法为:
将每条推文的文本和图像输入至实体识别模型中,推文的文本经过文本编码器得到推文的目标文本向量,推文的图像经过图像编码器得到推文的目标图像向量;目标文本向量经过Transformer自注意力机制处理后,与目标图像向量一起输入至多模态交互模块,分别以文本向量为key和value、以图像向量为query和以图像向量问key和value、以文本向量为query做跨模态注意力处理,再通过视觉门控制图像向量的贡献,得到融合了文本信息和图像信息的目标推文向量;目标文本向量经过另一Transformer自注意力机制处理后,输入至实体边界检测模块,得到每条推文的多个预测命名实体;将目标推文向量和实体边界检测模块预测的命名实体输入至实体识别模块,得到实体识别模块输出的每条推文的文本预测命名实体、每条推文的文本预测命名实体所对应的实体标签。
进一步地,步骤3中采用评价指标对实体识别模型的精度进行评价,其中,评价指标包括精确率Precision(P)、召回率Recall(R)、F1分数。
进一步地,精准率的计算公式为:P=TP/(TP+FP);
召回率的计算公式为:R=TP/(TP+FN);
F1分数的计算公式为:F1=2*P*R/(P+R);
式中,TP表示True Positive,True表示预测正确,Positive表示正样本,同理FP表示False Positive,FN表示False Negative。
本发明的另一个目的是提供一种根据上述的面向社交媒体平台的中文多模态命名实体识别方法的系统,包括:
数据获取模块,用于获取社交媒体平台中包含不同模态信息的推文;
数据集划分模块,用于根据数据获取模块获取的数据构建中文多模态数据集,并将数据集按比例随机划分为训练集、验证集和测试集;
模型构建模块,用于构建对推文的命名实体及命名实体所对应的实体标签进行预测的实体识别模型;
模型优化模块,用于采用训练集对实体识别模型进行训练,并采用验证集进行验证,最后采用测试集进行测试,得到精度符合要求的实体识别模型。
与现有技术相比,本发明的有益效果为:本发明聚焦中文多模态社交媒体推文,将中文文本信息和对应的图像信息融合用于命名实体识别任务中,突破了依靠单一的文本信息进行实体识别的局限性,并进一步利用图像信息提高了命名实体识别的准确性,构建了一个可用于各种中文多模态推文的命名实体识别模型;
本发明基于公开社交媒体平台获取中文多模态推文,构建中文多模态语料库并标记目标推文中的命名实体以及命名实体所属的类别,解决了现有技术中中文多模态语料库的匮乏以及中文文本存在大量的汉语特殊语言现象和复杂结构导致的识别精度不高的问题,从而使得命名实体识别模型能够更准确地对社交媒体平台上的推文进行定位和分类命名实体,将优化后的实体识别网络应用于中文多模态数据,可以直接获取非结构化的中文多模态数据文本中的命名实体。
附图说明
图1为本发明实施例中文多模态命名实体识别方法的流程图。
具体实施方式
下面将结合本发明实施例对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合具体实施例对本发明作进一步说明,但不作为本发明的限定。
如图1所示,本发明提供一种面向社交媒体平台的中文多模态命名实体识别方法,包括以下步骤:
步骤1:基于社交媒体平台微博,获取包含不同模态信息的推文,构建中文多模态数据集,将数据集按比例随机划分为训练集、验证集和测试集,标记数据集中每条推文所包含的所有命名实体以及对应的实体类别;
在该步骤中,通过公开的社交媒体平台如微博,采集特定领域的推文,选取配有与文本对应图像的推文构建中文多模态数据集。即数据集中每条推文为每条包含了文本和若干图像的社交媒体推文,且文本中至少包含一个命名实体;每条推文的定义如下:
S={s
其中,s表示训练集中每条推文的文本,s
将获得的数据集按照3∶1∶1的比例随机划分为训练集、验证集和测试集,其中训练集包含3000条目标推文,验证集包含1000条目标推文,测试集包含1000条目标推文,每条目标推文的文本字符数量限制为250,每条目标推文的图像数量限制为18。标记数据集中每条目标推文的文本中包含的所有命名实体标签,并标记目标推文中文本包含的所有命名实体对应的实体类别。
步骤2、构建实体识别模型,将训练集中的每条推文输入到实体识别模型中对其进行训练,在训练过程中构建损失函数,对实体识别模型不断迭代训练直至损失函数不再降低,并采用验证集进行验证得到优化后的实体识别模型;
实体识别模型包括文本编码模块、图像编码模块、多模态交互模块、实体边界检测模块、实体识别模块;
文本编码模块,其包括BERT(Bidirectional Encoder Representations FromTransformers)模块,用于对每条推文的文本进行编码以得到每条推文文本的目标文本向量,并将每条推文文本的目标文本向量输出至多模态交互模块和实体边界检测模块中;
图像编码模块,其包括ResNet模块,用于将每条推文的图像进行编码以得到每条推文对应图像的目标图像向量,并将每条推文对应图像的目标图像向量输出至多模态交互模块;
多模态交互模块,包括Transformer模块,用于将每条推文的目标文本向量和目标图像向量进行交互融合,得到融合了目标文本特征和目标图像特征的目标推文向量,将训练集中每条推文的目标推文向量输出至所述实体识别模块;
实体边界检测模块,包括Transformer和CRF(Conditional Random Field)模块,用于将每条推文的目标文本向量通过Transformer模块的自注意力机制处理得到新的目标文本向量,并将每条推文新的目标文本向量输入至CRF模块中进行实体边界检测,再将每条推文的实体边界检测结果输出至所述实体识别模块;
实体识别模块,包括CRF模块,每条推文的目标推文向量输入至CRF进行实体识别,引入实体边界检测结果作为实体识别约束,对每条推文新的目标推文向量进行实体识别。
在训练时,将训练集中每条推文的文本和图像输入至构建好的实体识别模型中,推文的文本经过文本编码器得到推文的目标文本向量,推文的图像经过图像编码器得到推文的目标图像向量;目标文本向量经过Transformer自注意力机制处理后,与目标图像向量一起输入至多模态交互模块中,分别以文本向量为key和value、以图像向量为query和以图像向量问key和value、以文本向量为query做跨模态注意力处理,再通过视觉门控制图像向量的贡献,得到融合了文本信息和图像信息的目标推文向量;目标文本向量经过另一Transformer自注意力机制处理后,输入至实体边界检测模块,得到每条推文的多个预测命名实体;将目标推文向量和实体边界检测模块预测的命名实体输入至实体识别模块,得到实体识别模块输出的每条推文的文本预测命名实体、每条推文的文本预测命名实体类别,结合每条推文的标记命名实体以及实体类别,构建损失函数计算实体识别网络的损失函数数值,通过反向传播和梯度下降算法不断迭代训练实体识别模型直至损失函数不再降低,经过多轮训练后得到训练后的实体识别模型。
在本实施例中,构建的损失函数具体定义如下:
其中,
实体识别模型经过迭代训练后,每一轮训练后采用验证集进行验证,最后得到优化后的实体识别模型。
步骤3、采用测试集对优化后的实体识别模型进行精度评价,并采用精度符合要求的实体识别模型对中文多模态社交媒体推文进行预测,得到中文多模态社交媒体推文中包含的所有命名实体,以及该中文多模态社交媒体推文中命名实体所对应的实体标签;
采用测试集对优化后的实体识别模型进行精度评价,并采用精度符合要求的实体识别模型对中文多模态社交媒体推文进行预测,在本实施例中,采用评价指标:精确率Precision(P)、召回率Recall(R)、F1分数对模型的精度进行评价,其中,精准率的计算公式为:P=TP/(TP+FP);
召回率的计算公式为:R=TP/(TP+FN);
F1=2*P*R/(P+R);
式中,TP表示True Positive,True表示预测正确,Positive表示正样本,同理FP表示False Positive,FN表示False Negative。
可以设置相应指标的阈值,选择精确率、召回率、F1分数大于阈值的实体命名模型进行预测。在本实施例中,实体命名模型在测试集上进行验证,精确率达到了87.08%,召回率达到了90.16%,F1分数达到88.60,符合要求。
在本实施例中,将中文多模态推文文本“某球星离开某球队到底赚了还是亏了”和对应的若干图像输入至精度符合要求的实体识别模型中,由实体识别模型输出命名实体“某球星”和“某球队”,并将其分类为人名和组织机构名,得到该推文中的命名实体:{“某球星”:“PER”,“某球队”:“ORG”}。
本发明还提供了一种根据上述的面向社交媒体平台的中文多模态命名实体识别方法的系统,包括:
数据获取模块,用于获取社交媒体平台中包含不同模态信息的推文;
数据集划分模块,用于根据数据获取模块获取的数据构建中文多模态数据集,并将数据集按比例随机划分为训练集、验证集和测试集;
模型构建模块,用于构建对推文的命名实体及命名实体所对应的实体标签进行预测的实体识别模型;
模型优化模块,用于采用训练集对实体识别模型进行训练,并采用验证集进行验证,最后采用测试集进行测试,得到精度符合要求的实体识别模型。
以上仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 一种面向金融领域的中文命名实体识别方法及系统
- 一种多模态信息选择性融合的中文命名实体识别方法