乐器、声学
-
交叉横向增强排布隔板填充粘弹性材料水下吸声结构
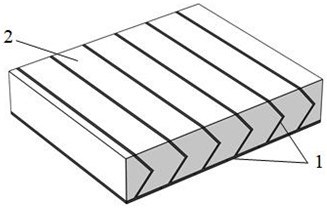
本发明提供了一种交叉横向增强排布隔板填充粘弹性材料水下吸声结构,包括底板,底板上刚性连接有若干等距分布的竖直隔板,相邻两个竖直隔板之间组成一个元胞,每个元胞内分布有若干水平隔板并填充有密度为500 kg/m3~1000kg/m3粘弹性材料;所述的水平隔板包括与左侧竖直隔板刚性连接的左隔板以及与右侧竖直隔板刚性连接的右隔板,左隔板和右隔板在竖直方向上交错分布。本发明通过结构的合理设计提高粘弹性材料水下吸声性能,解决了宽频吸声性能较差的难题。
2023-08-21 -
一种语音信号处理方法、装置、存储介质及终端设备
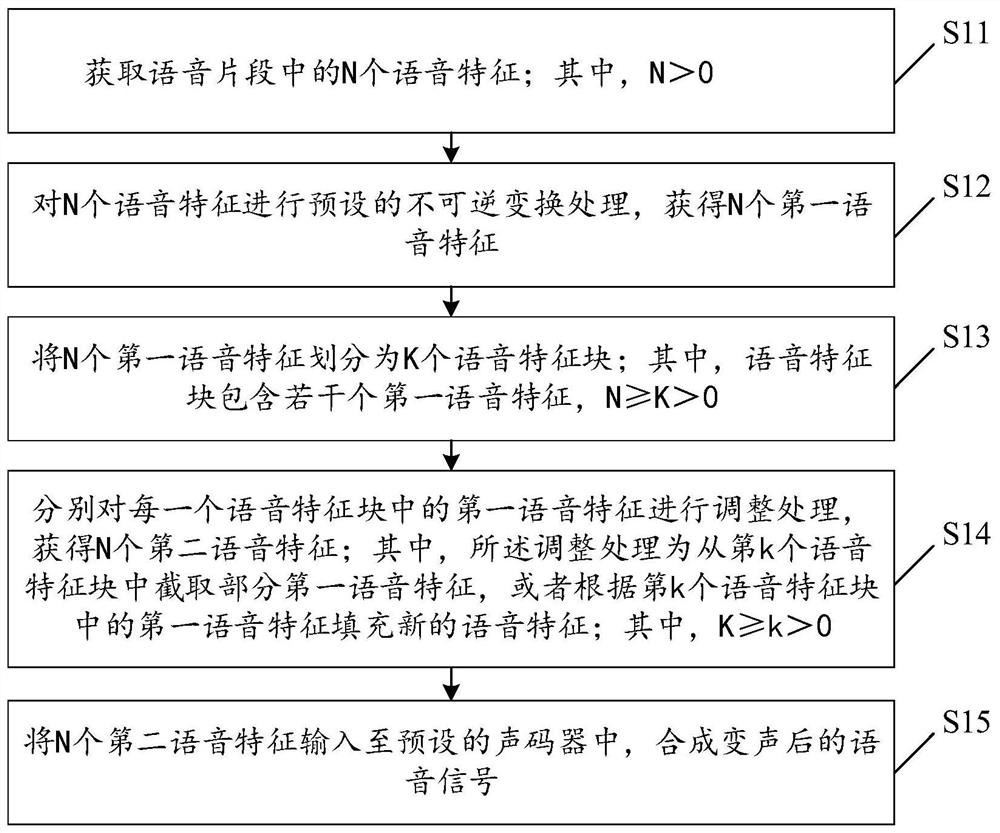
本发明公开了一种语音信号处理方法、装置、存储介质及终端设备,该方法包括:获取语音片段中的N个语音特征;对N个语音特征进行预设的不可逆变换处理,获得N个第一语音特征;将N个第一语音特征划分为K个语音特征块;其中,语音特征块包含若干个第一语音特征,N≥K>0;分别对每一个语音特征块中的第一语音特征进行调整处理,获得N个第二语音特征;其中,所述调整处理为从第k个语音特征块中截取部分第一语音特征,或者根据第k个语音特征块中的第一语音特征填充新的语音特征;其中,K≥k>0;将N个第二语音特征输入至预设的声码器中,合成变声后的语音信号;通过本发明难以从变声后的语音信号中识别出用户身份,加强用户的隐私保护。
2023-08-21 -
一种控制智能家居设备的方法、装置和音响
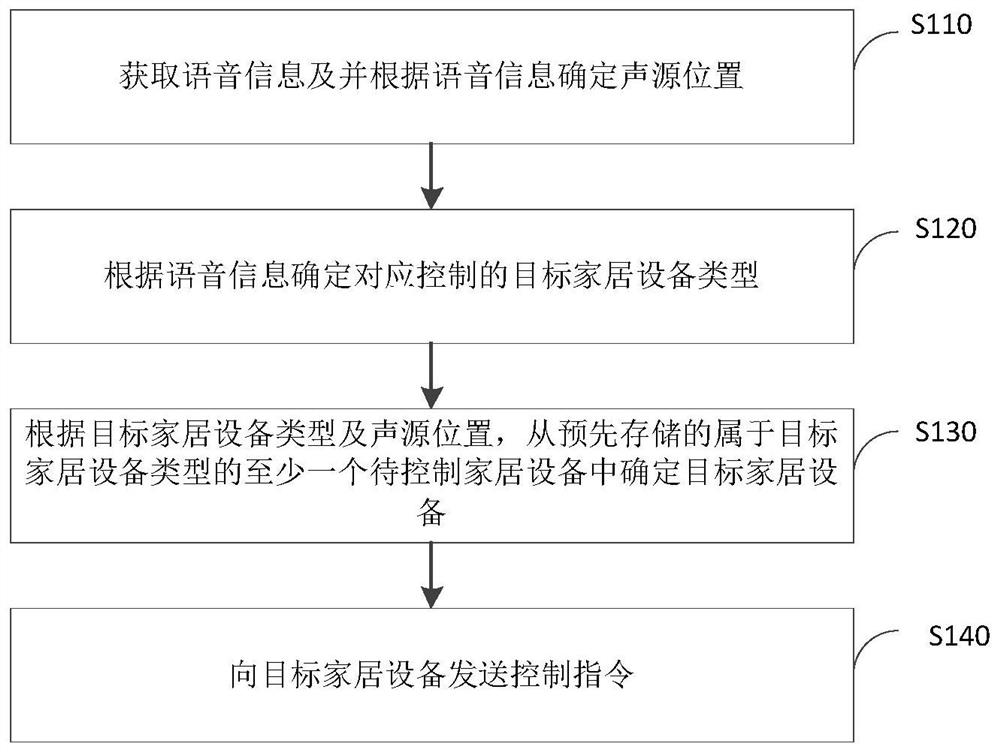
本发明提供了一种控制智能家居设备的方法、装置和音响,其中一种控制智能家居设备的方法包括获取语音信息及并根据所述语音信息确定声源位置,根据所述语音信息确定对应控制的目标家居设备类型,根据所述目标家居设备类型及所述声源位置,从预先存储的属于所述目标家居设备类型的至少一个待控制家居设备中确定目标家居设备,向所述目标家居设备发送控制指令。本发明能够对语音信息的声源位置进行定位,并根据语音信息的声源位置确定目标家居设备。
2023-08-21 -
一种确定语音意图的方法及装置
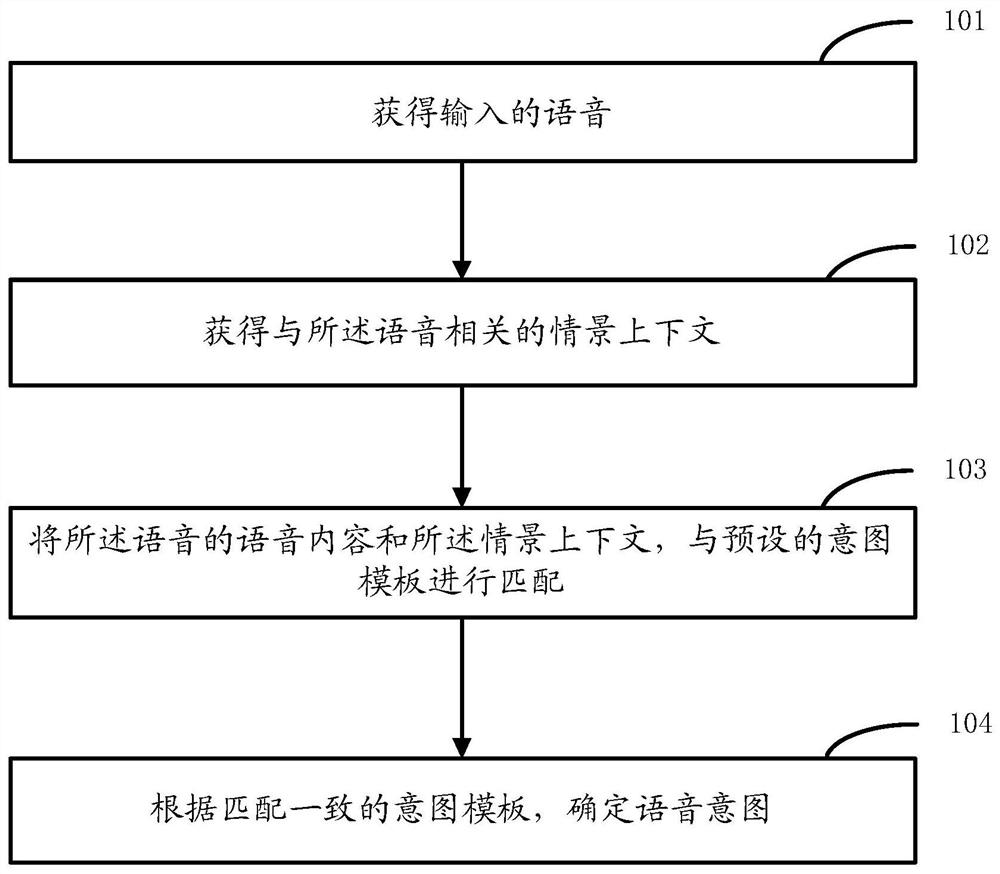
本发明公开了一种确定语音意图的方法及装置,用以实现得到更准确的语音意图,有助于实现语音精准控制。所述方法,包括:获得输入的语音;获得与所述语音相关的情景上下文;将所述语音的语音内容和所述情景上下文,与预设的意图模板进行匹配;根据匹配一致的意图模板,确定语音意图。
2023-08-21 -
一种基于差分隐私的联邦声纹识别方法
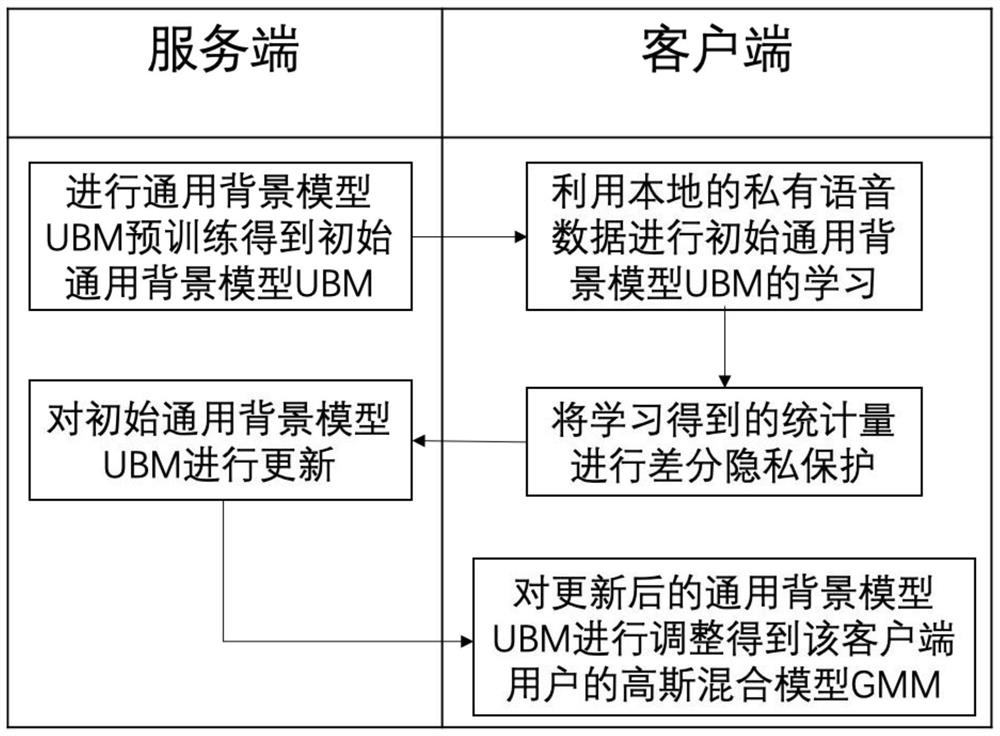
本发明提出一种基于差分隐私的联邦声纹识别方法,包括一:在服务端进行通用背景模型UBM预训练得到初始通用背景模型UBM;二:客户端接收预训练后的初始通用背景模型UBM,利用本地的私有语音数据进行初始通用背景模型UBM的学习;三:客户端学习得到的统计量进行差分隐私保护;四:服务端聚合多个客户端上传的差分隐私保护后的统计量,更新初始通用背景模型UBM;五:客户端接收更新后通用背景模型UBM,借助本地私有语音数据调整得到该客户端用户的高斯混合模型GMM,利用更新后通用背景模型UBM和该用户的高斯混合模型GMM判别待验证语音是否为该客户端用户所产生。
2023-08-21 -
一种基于RNN和PAD情感模型的情感语音合成方法
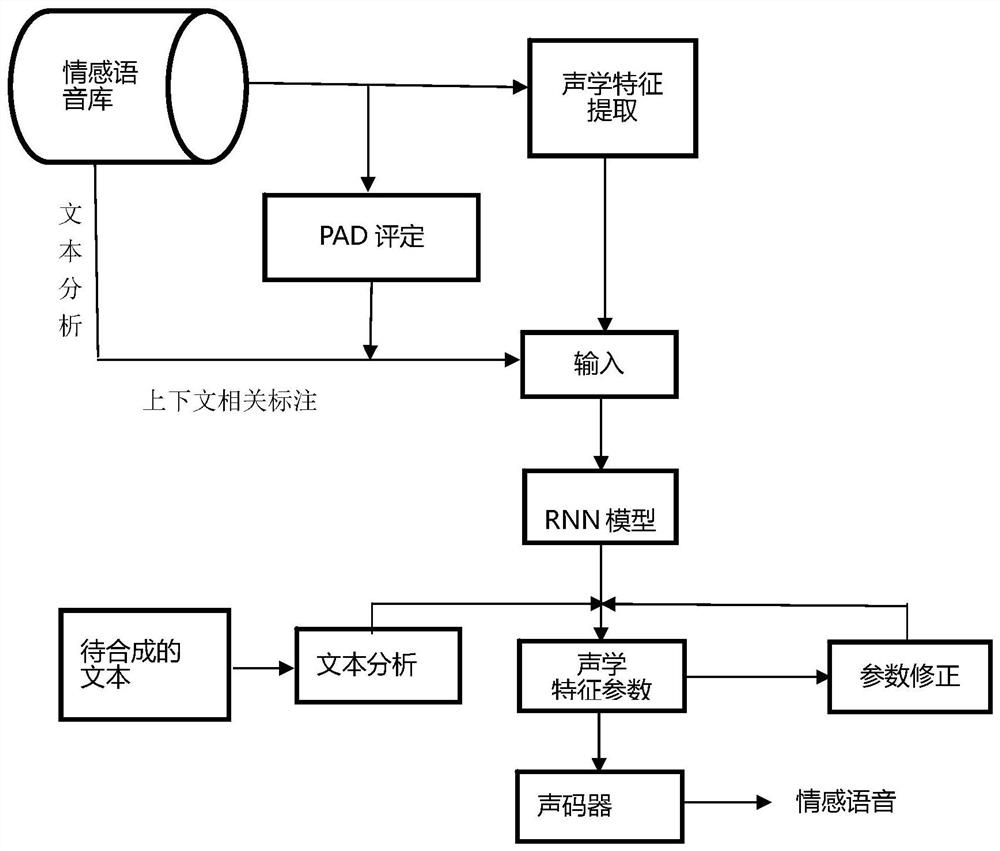
本发明公开了一种基于RNN和PAD情感模型的情感语音合成方法,包括:步骤1,基于情感语音库获取训练数据,包括PAD量化标注得到的PAD值、上下文相关标注、以及特征参数MGC、BAP和F0;步骤2,将训练数据输入基于LSTM的RNN模型进行训练,得到训练后的特征参数MGC、BAP和F0;步骤3,基于PAD情感模型,利用欧几里得距离计算用于修正训练后的特征参数MGC、BAP和F0的权重,然后利用权重对训练后的特征参数进行修正;步骤4,将待合成的文本经过文本分析得到上下文相关标注,然后将其与修正后的特征参数MGC、BAP和F0合成为情感语音。本发明将基于LSTM的RNN模型和PAD情感模型加入到语音合成中,解决传统语音合成带来的问题以及语音合成中情感不足的问题,提高了语音合成的自然度。
2023-08-21 -
语音识别方法、装置及电子设备

本申请提供了语音识别方法、装置及电子设备,适用于人工智能中的语音识别技术领域,可实现端侧语音识别,该方法包括:获取第一语音数据,并利用语音识别模型对第一语音数据进行处理,得到第一语音识别结果。其中语音识别模型是基于变换器架构的模型,且语音识别模型中包含编码器网络、预测网络和联合网络。编码器网络和预测网络中均包含卷积网络。在本申请实施例中,语音识别模型的编码器网络和预测网络均由包含卷积神经网络。因此,本申请实施例中的语音识别模型训练耗时较短。
2023-08-21 -
用于采掘装备远程控制的人机语音对讲平台
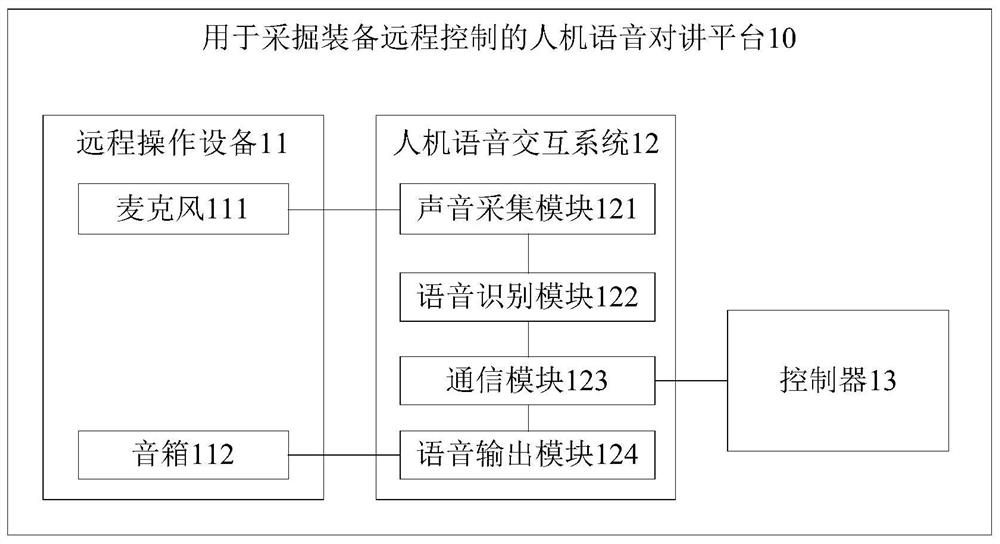
本发明提出了一种用于采掘装备远程控制的人机语音对讲平台,其中,平台通过远程操作设备的麦克风采集远程操作人员发出的语音信号后,声音采集模块获取麦克风采集的语音信号,语音识别模块对语音信号进行语音识别,以得到语音信息,并将语音信息发送至控制器,控制器响应于接收到的语音信息判断采掘装备的整机状态和传感器状态,并将判断结果通过通信模块发送至语音识别模块,语音识别模块根据判断结果生成回复信息后,语音输出模块将接收到的回复信息发送至音箱,以使音箱播放回复信息。由此,远程操作人员在控制采掘装备启动之前,通过语音交互的方式确定采掘装备的整机状态和传感器状态,从而提高了工作效率,降低了人工成本。
2023-08-21 -
一种双螺旋耦合水下吸声超表面结构
本发明公开了一种双螺旋耦合水下吸声超表面结构,包括层芯,层芯内间隔设置有多个双螺旋耦合单元,每个双螺旋耦合单元的螺旋中心设置有空腔,空腔与螺旋通道间设置有环型隔板,螺旋通道的侧壁上设置有螺旋型的阻尼内衬层,层芯的顶部设置有穿孔上面板,穿孔上面板上对应双螺旋耦合单元的空腔周期性的开有小孔,层芯的底部设置有下面板,穿孔上面板、层芯和下面板连接形成双螺旋耦合水下吸声超表面结构。本发明具有优异的低频吸声性能以及超薄的亚波长结构尺寸。在设计方面具有更多的可调结构参数,可根据实际工况需求进行相应调节,结构简单,易于制造。
2023-08-21 -
意图识别方法、模型的训练方法及其装置、设备、介质
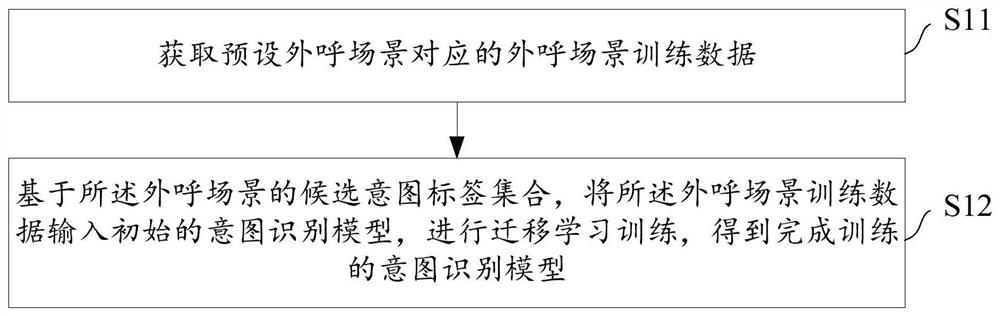
意图识别方法、模型的训练方法及其装置、设备、介质,所述意图识别模型的训练方法包括:获取预设外呼场景对应的外呼场景训练数据;基于所述外呼场景的候选意图标签集合,将所述外呼场景训练数据输入初始的意图识别模型,进行迁移学习训练,得到完成训练的意图识别模型;其中,所述外呼场景训练数据包括:用于所述外呼场景的训练话术文本集合和所述训练话术文本集合对应的真实意图标签集合,所述意图识别模型包括:已完成预训练的神经网络模型。采用上述方案,提高意图识别准确率,改善客户交互体验。
2023-08-21 -
高频音频重建技术的集成
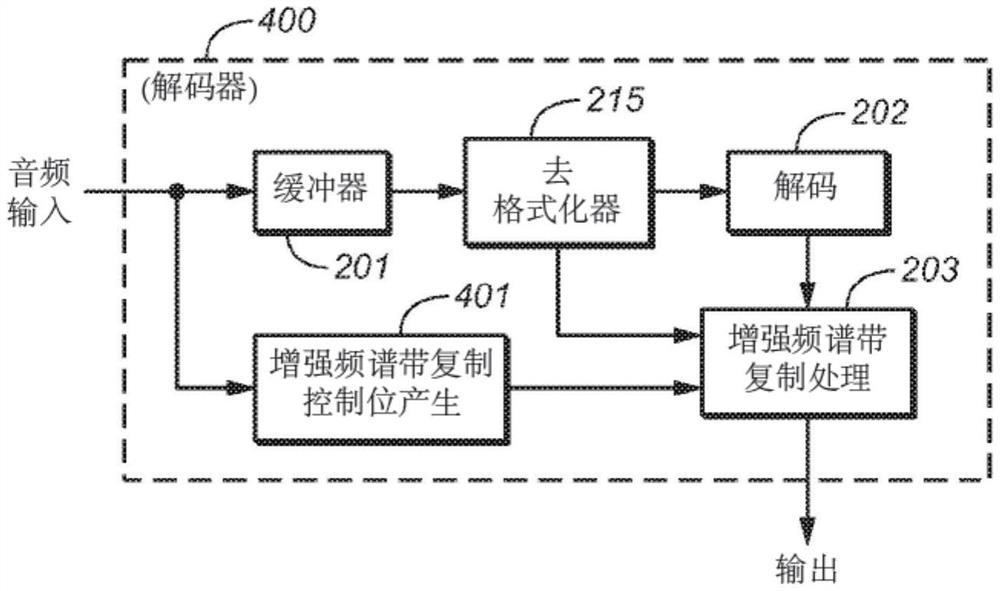
本发明揭示一种用于解码经编码音频位流的方法。所述方法包含接收所述经编码音频位流且解码音频数据以产生经解码低频带音频信号。所述方法进一步包含提取高频重建元数据且使用分析滤波器组来对所述经解码低频带音频信号滤波以产生经滤波低频带音频信号。所述方法还包含提取指示是对所述音频数据执行频谱平移还是谐波转置的标记且根据所述标记使用所述经滤波低频带音频信号及所述高频重建元数据来再生所述音频信号的高频带部分。将所述高频再生执行为每个音频频道具有3010个样本的延迟的后处理操作。
2023-08-21 -
针对计算机化个人助手的技能发现
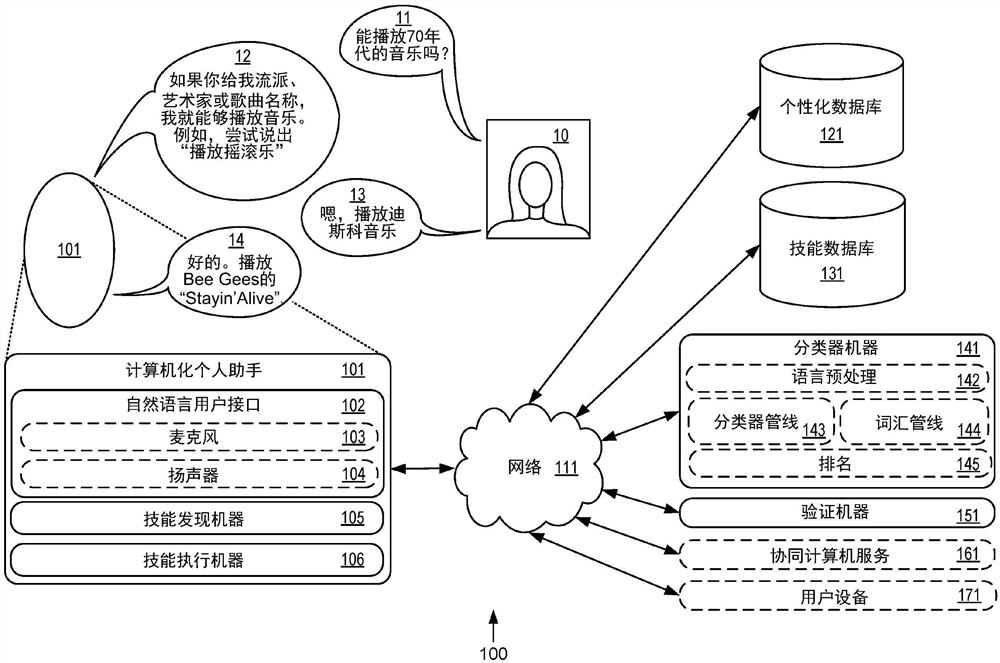
一种计算机化个人助手通信耦合至计算机数据库,所述计算机数据库包括该计算机化个人助手的多种可用技能。该计算机化个人助手识别用户的当前情境。该计算机化个人助手操作先前训练的学习分类器以评估候选技能的匹配置信度,该匹配置信度指示该当前情境与先前关联于该候选技能的基准情境之间的匹配质量。该计算机化个人助手响应于该匹配置信度超过预定义匹配置信度阈值而执行定义与该候选技能相关联的辅助动作的指令。该计算机化个人助手响应于该匹配置信度并未超过预定义匹配置信度阈值而执行定义与该候选技能相关联的补充帮助动作的指令。
2023-08-21 -
音频处理方法及装置

一种音频处理方法及装置。该方法包括:基于语音活性检测方法从音频信号中截取音频片段;采用滑动窗口方法对所述音频片段进行目标处理,得到所述音频片段的处理结果。由于滑动窗口方法可以在一个或多个窗口中将语音活性检测所截取出的音频片段中包括的噪声排除在外,因此本申请采用滑动窗口方法对音频片段进行目标处理,可以避免音频片段中噪声的影响,从而可以提高音频处理的准确性。
2023-08-21 -
语音交互设备、方法、装置、电子设备和存储介质
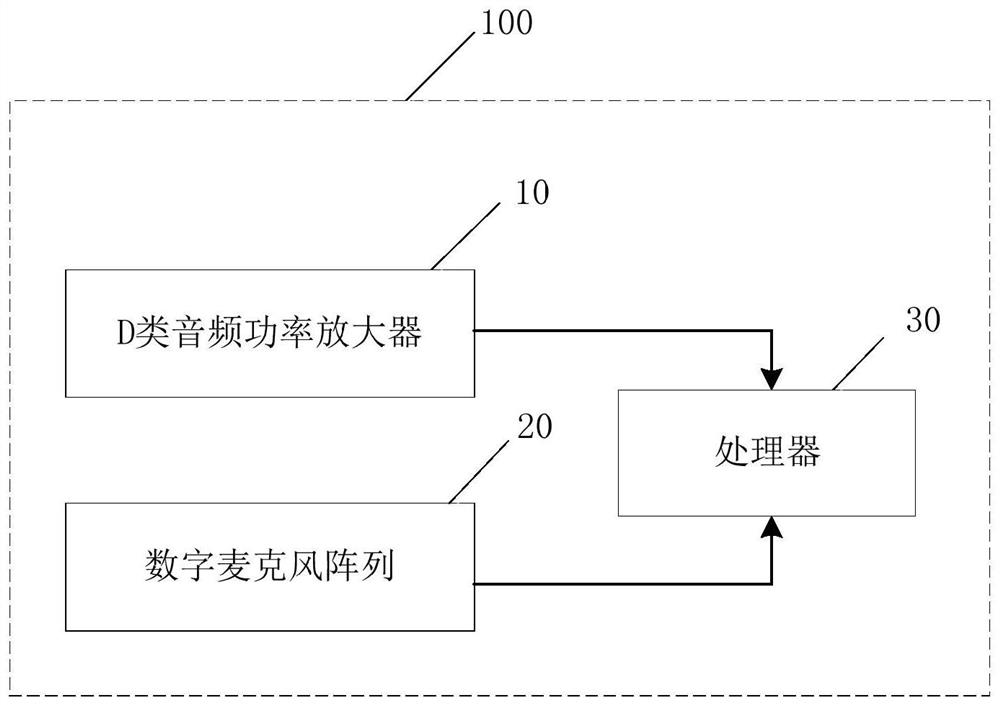
本申请公开了一种语音交互设备、方法、装置、电子设备和存储介质,涉及语音技术、人工交互、回声消除技术领域。具体实现方案为:通过D类(数字)音频功率放大器将待播放的第一语音信号经过脉冲密度调制器调制,以生成第一脉冲密度调制信号;通过处理器根据获取的第一脉冲密度调制信号及数字麦克风阵列采集的音频信号,确定音频信号中包含的语音指令,以对音频信号进行回声消除,并生成第二待播放的语音信号。由此,通过采集脉冲密度调制信号对音频信号进行调制,并采集调制后的脉冲密度调制信号作为回声参考信号,对数字麦克风采集的音频信号进行回声消除,无需模数转换,从而避免了模数转换带来的干扰噪声,改善了回声消除的效果。
2023-08-21 -
针对基于车辆的有源噪声控制系统的存储的次级路径精度
验证
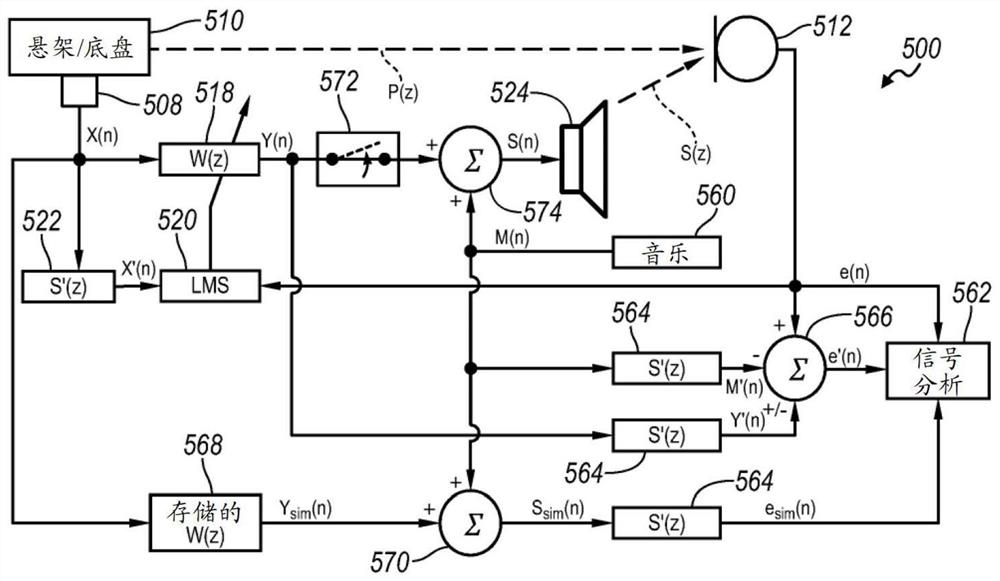
一种有源噪声消除(ANC)系统可包括提供验证存储在次级路径滤波器中的建模的传递特性的精度,这提供对所述次级路径(即,扬声器与误差传声器之间的传递函数)的估计。使用估计的抗噪声或音乐信号来调整来自所述误差传声器的误差信号,信号分析控制器可检测到ANC不稳定性或噪声升高。这种噪声升高可指示所述次级路径滤波器中的所述存储的传递特性没有准确地表示实际次级路径。因此,在检测到噪声升高后,可修改所述次级路径滤波器的所述存储的传递特性。
2023-08-21 -
驱动模式优化的发动机阶次消除
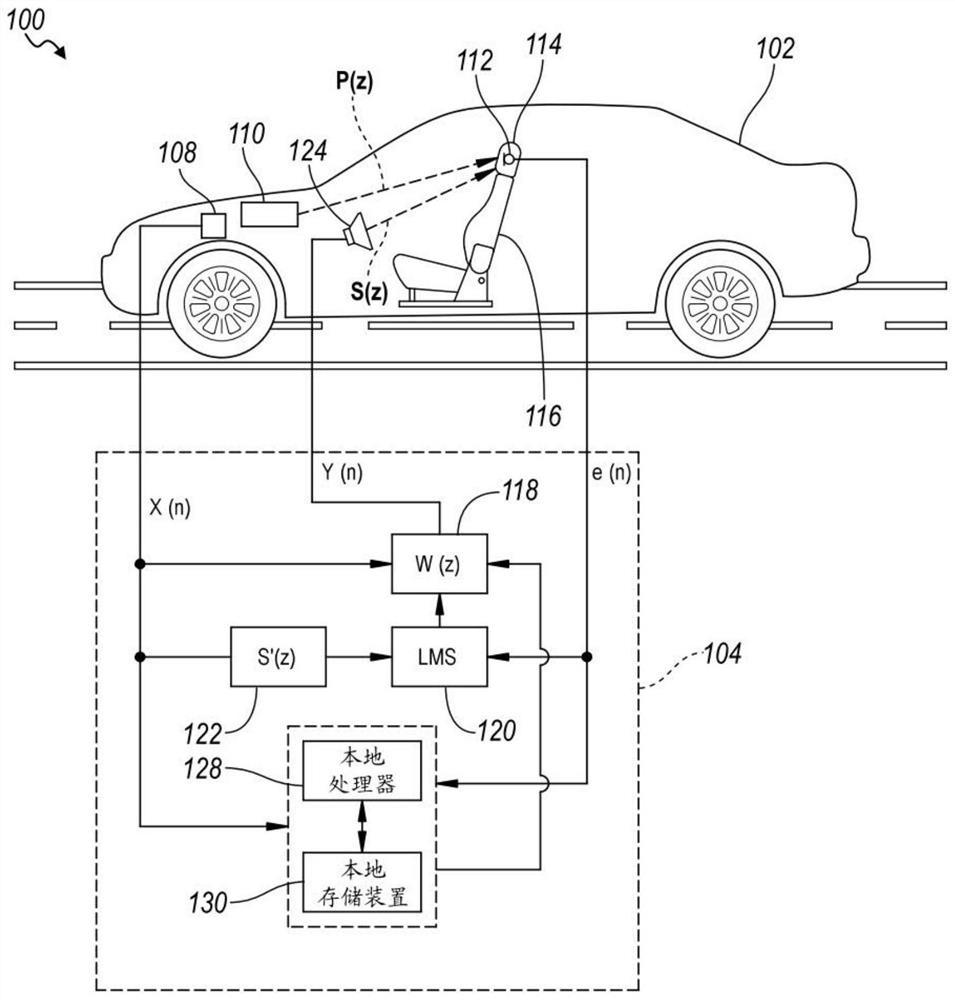
发动机阶次消除(EOC)系统基于发动机或其他旋转轴RPM而生成前馈噪声信号,并且使用那些信号和自适应地配置的W滤波器通过经由扬声器发射抗噪声来降低车厢内的SPL。一种EOC系统可包括驱动模式检测器,所述驱动模式检测器用于基于对指示当前车辆工况的信号的分析来检测不同车辆驱动模式。在检测时,所述EOC系统可基于所述当前车辆驱动模式来自适应地调整EOC算法的各种调谐参数。所述EOC系统还可根据所述当前车辆驱动模式基于在所述驱动模式期间哪些发动机阶次占优势而选择性地将不同组的发动机阶次作为噪声消除的目标。
2023-08-21 -
一种单弦琴
京族单弦琴,历史悠久,流传至今,成为京族人家珍爱的传统乐器,宗族长辈,用单弦琴演奏具有民族风格的乐曲,庆祝节日,拜祭先祖;年轻人,用单弦琴演奏具有民族特色的情歌,隔岸交流,风情独特。单弦琴构造简单,音色独特,低音部分发音悠扬深远,高音部分发音婉转动人,还可以用演奏技巧模仿鸟鸣,人讲话的声音等。但,存在原声音量小;泛音多,基音少;演奏技巧复杂等缺陷。为解决以上问题,本发明提供了一种,通过叠加共鸣的方式,使琴发音洪亮;按照十二平均律的比例在琴体上,设置琴弦发音点相对应的音阶标识,方便演奏;演奏者,以手柄控制定音嘴按压琴弦,使琴发音。可用手指弹拨、拨子碰撞,或者琴弓摩擦琴弦等多种方式演奏的单弦琴。
2023-08-21 -
一种智能化语音识别装置
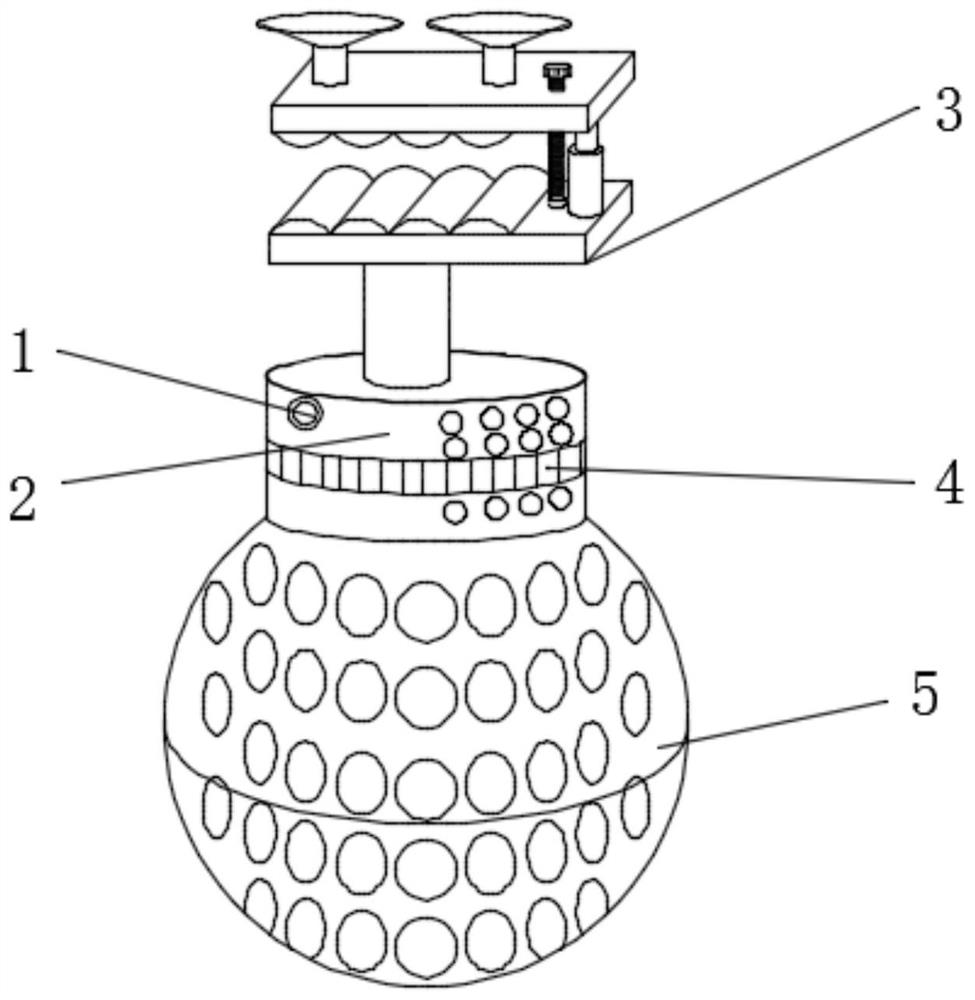
本发明公开了一种智能化语音识别装置,包括电源开关、固定盒、固定结构、电源灯、安装罩、控制总成、储备电池、滤波器、散热孔、固定架、喇叭型听筒、放大器和声音接收器,所述固定盒的外侧顶部侧面安装有电源开关,通过将把安装罩和固定架设置为球型,通过在安装架内安装有喇叭型听筒,能够达到多方位采集声音,同时达到提升采集音量的效果,能够扩大识别范围;通过固定结构,可以通过吸盘固定,也可以通过上挤压板与下固定板配合卡接固定,能够随意移动,安装方便,操作简单,通过在固定盒内设置有滤波器和放大器,能够实现对采集音量的处理,去除噪音,扩大音效,能够提高识别的准确度。
2023-08-21 -
语音信号处理方法、装置、电子设备及存储介质
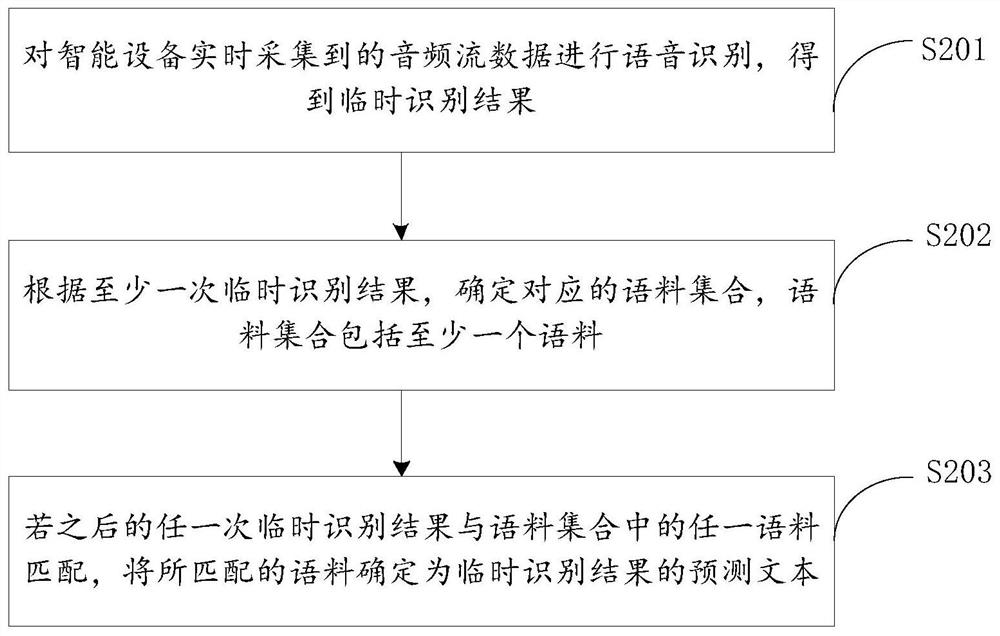
本发明涉及人工智能技术领域,公开了一种语音信号处理方法、装置、电子设备及存储介质,所述方法包括:对智能设备实时采集到的音频流数据进行语音识别,得到临时识别结果;根据至少一次临时识别结果,确定对应的语料集合,所述语料集合包括至少一个语料;若之后的任一次临时识别结果与所述语料集合中的任一语料匹配,将所匹配的语料确定为所述临时识别结果的预测文本。本发明实施例提供的技术方案,提高了文本预测的效率,缩短了智能设备的响应时间。
2023-08-21 -
一种同时识别人声和非人声的装置及方法
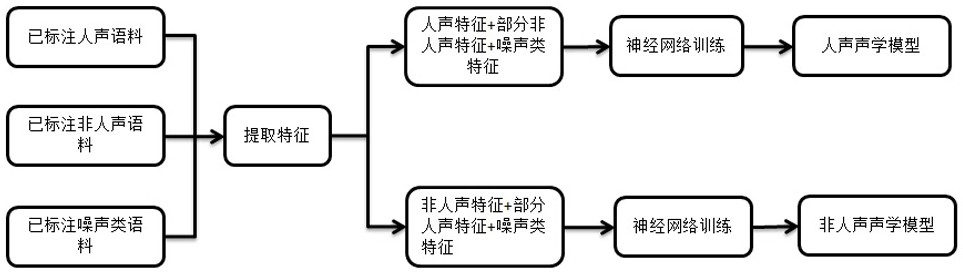
一种同时识别人声和非人声的装置,包括声源输入单元及与其连接的特征提取单元,所述装置还包括N个识别模型和N个识别结果处理单元,每个识别模型连接有一个识别结果处理单元;所述N个识别模型由人声识别模型和非人声识别模型两种识别模型组成;所述识别结果处理单元对全部识别模型的输出结果进行判断识别为人声或非人声;所述装置还包括识别结果融合单元,所述融合单元的作用是根据人声非人声识别结果处理单元的结果触发上层应用。本发明还公开了一种同时识别人声和非人声的方法。本发明可以解决声源中的多源复杂信号同时分别识别;在保证两者识别效果的情况下,识别响应速度快,反应灵敏。
2023-08-21 -
音频处理方法和装置

本申请提供了一种音频处理方法和装置,该方法包括:获得待处理的目标音频以及待识别用户的基准音频;基于目标音频中具有的音频间隔端点,将目标音频划分为至少一个音频段;针对每个音频段,将音频段切分为多个第一音频切片,从多个第一音频切片中确定出第一参照音频切片,并基于第一参照音频切片确定出多个第一音频切片中的第一主音频切片集;基于音频段对应的第一主音频切片集的音频特征以及基准音频的音频特征,从至少一个音频段中确定出属于待识别用户的音频段。本申请的方案可以提高从音频中识别属于特定用户的音频段的准确度。
2023-08-21 -
隔音装置及隔音检测单元体和隔音检测流水作业线
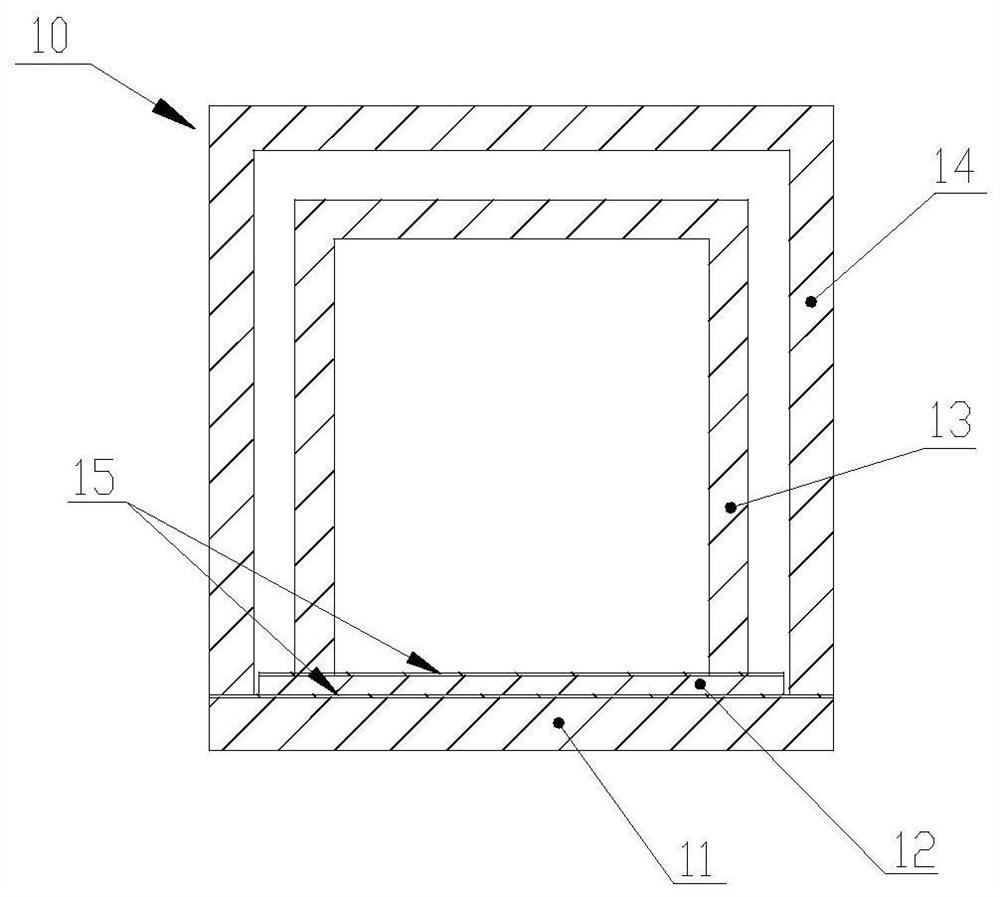
本发明提供一种隔音装置及隔音检测单元体和隔音检测流水作业线,其隔音装置包括隔振密封底板、隔振密封垫板、隔音内罩和隔音外罩,隔音内罩和隔音外罩皆为底部开口的筒体或箱体,隔音内罩以底部开口扣合在隔振密封垫板上,隔音外罩套装在隔音内罩的外部且其内壁与隔音内罩的外壁保持一定的间隙,隔音外罩的开口底部扣合在隔振密封底板上且其底部开口的内缘与隔振密封垫板的外缘密合。本发明提供的隔音装置具有隔音外罩+间隙空腔+隔音内罩的复合隔声结构,使得隔声结构层在整体厚度小于200mm的情况下,可以轻易阻隔55db以上的声音,达到了高效隔音的目的;在隔音装置的基础上可以拓展成为隔音检测单元体并运用于隔音检测流水作业线上。
2023-08-21 -
语音合成方法、语音合成装置、存储介质与电子设备
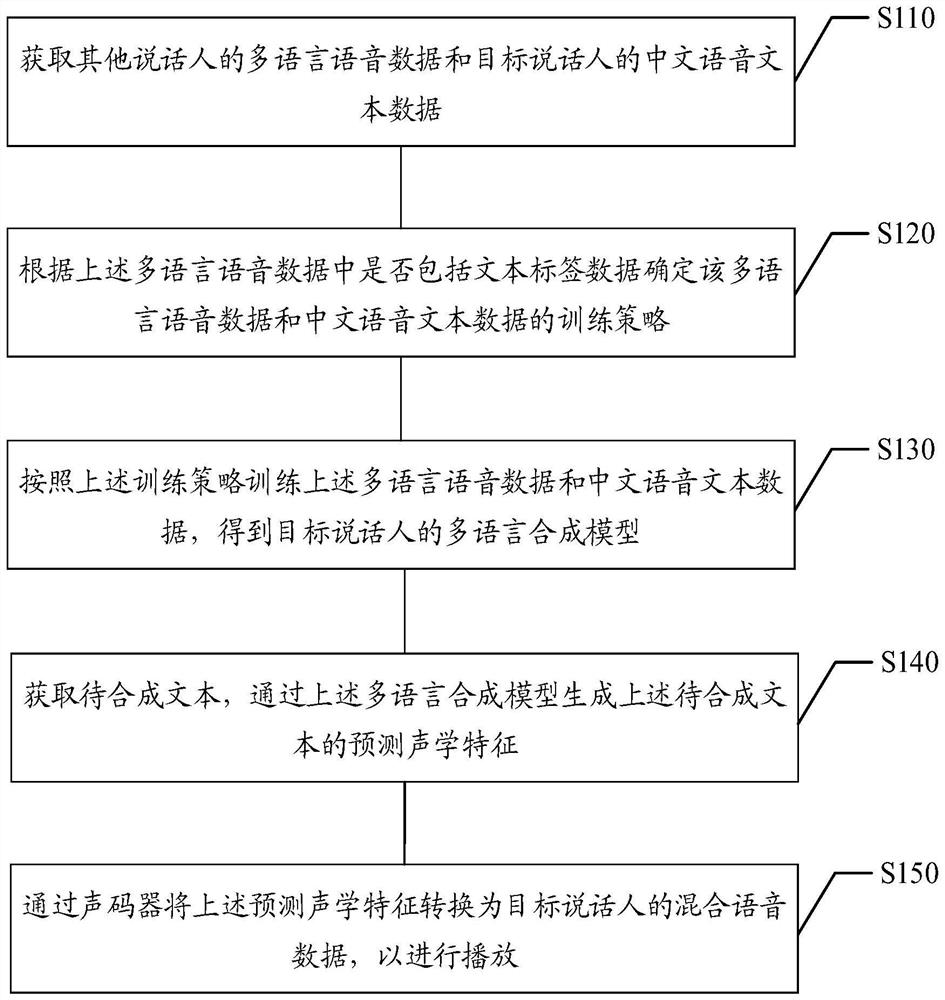
本公开提供了一种语音合成方法、语音合成装置、计算机可读存储介质与电子设备,属于语音合成技术领域。所述方法包括:获取其他说话人的多语言语音数据和目标说话人的中文语音文本数据;根据所述多语言语音数据中是否包括文本标签数据确定所述多语言语音数据和所述中文语音文本数据的训练策略;按照所述训练策略训练所述多语言语音数据和所述中文语音文本数据,得到目标说话人的多语言合成模型;获取待合成文本,通过所述多语言合成模型生成待合成文本的预测声学特征;通过声码器将所述预测声学特征转换为所述目标说话人的混合语音数据,以进行播放。本公开可以降低混合语音生成对数据的依赖性,提高合成语音的流利度和自然度。
2023-08-21 -
一种民间架子鼓
本发明公开了一种民间架子鼓,包括固定框、挂在所述固定框一端的移动框,所述固定框内部设置有第一镲、第二檫、第三檫,所述固定框顶部设置有与其固定连接的第一锣,与其旋转连接的旋转架、旋转盖,所述移动框一侧设置有用于挂在所述固定框上的挂钩,另一侧设置有与其旋转连接的翻转架,所述移动框内部挂设有第一鼓、第二鼓,所述固定框上端面一侧固定设置有第四镲、第五镲,所述移动框上端面一侧固定设置有第六镲。本发明通过合理的布置实现了一人即可同时操作多种乐器完成演奏的有益效果。本发明构思巧妙,布局合理,操作方便,实用性强,具有较高的推广意义。
2023-08-21 -
一种轻质薄膜低频降噪结构

本发明一种轻质薄膜低频降噪结构,属于降噪结构领域;包括纯聚酰亚胺(PI)膜以及附着在纯聚酰亚胺(PI)膜上的十字型铝合金振子和中心十字振子,所述纯聚酰亚胺(PI)膜外圆周均匀设置一个乙烯乙酸乙烯酯共聚物(EVA)圆环,所述中心十字振子位于纯聚酰亚胺(PI)膜中心位置,十字型铝合金振子分别对称设置在中心十字振子的四周。本发明的降噪结构不仅具有良好的降噪效能,而且可以大幅降低结构重量,实现降噪结构轻质化、小型化要求。
2023-08-21 -
人工合成语音检测方法、装置、计算机设备及存储介质
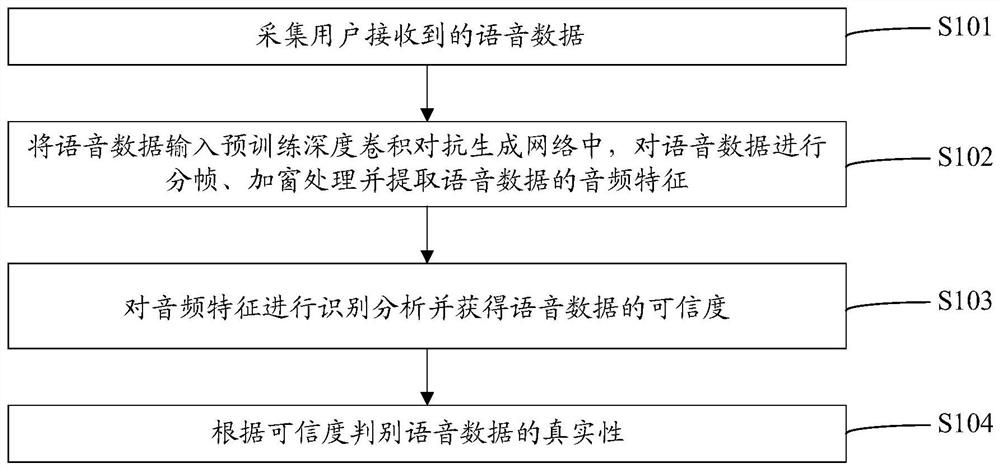
本发明公开了一种人工合成语音检测方法、装置、计算机设备及存储介质,该人工合成语音检测方法包括:采集用户接收到的语音数据;将语音数据输入预训练深度卷积对抗生成网络中,对语音数据进行分帧、加窗处理并提取语音数据的音频特征;对音频特征进行识别分析并获得语音数据的可信度;根据可信度判别语音数据的真实性。通过上述方式,本发明能够通过对抗生成网络对用户接收到的语音数据的真实性进行识别,帮助用户更好地提高对语音诈骗的防范意识。
2023-08-21 -
音频处理方法及装置
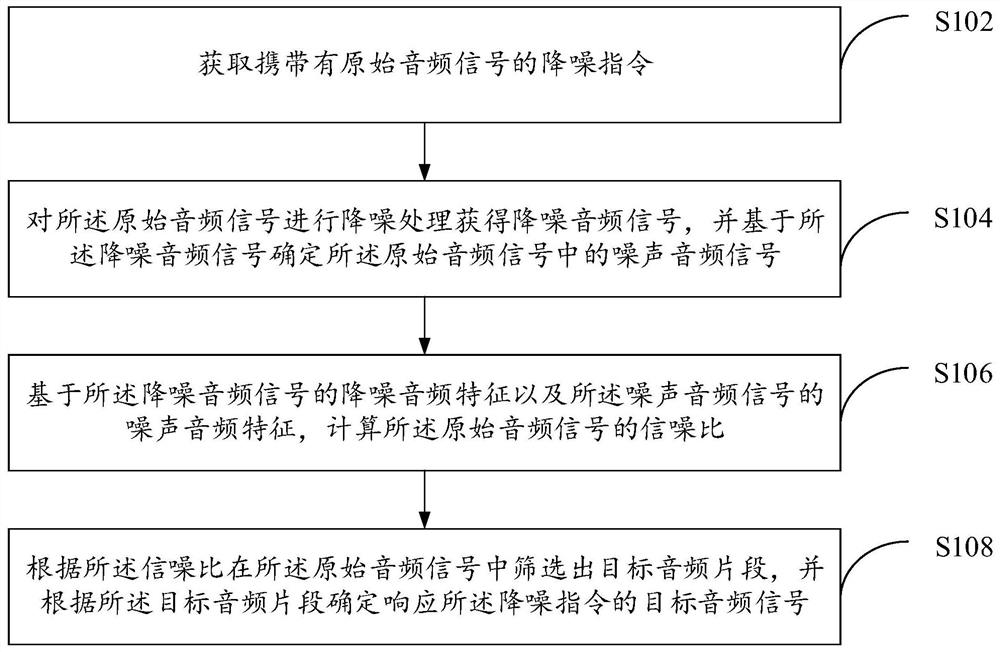
本说明书提供音频处理方法及装置,其中所述音频处理方法包括:获取携带有原始音频信号的降噪指令;对所述原始音频信号进行降噪处理获得降噪音频信号,并基于所述降噪音频信号确定所述原始音频信号中的噪声音频信号;基于所述降噪音频信号的降噪音频特征以及所述噪声音频信号的噪声音频特征,计算所述原始音频信号的信噪比;根据所述信噪比在所述原始音频信号中筛选出目标音频片段,并根据所述目标音频片段确定响应所述降噪指令的目标音频信号。
2023-08-21 -
音频处理方法及装置
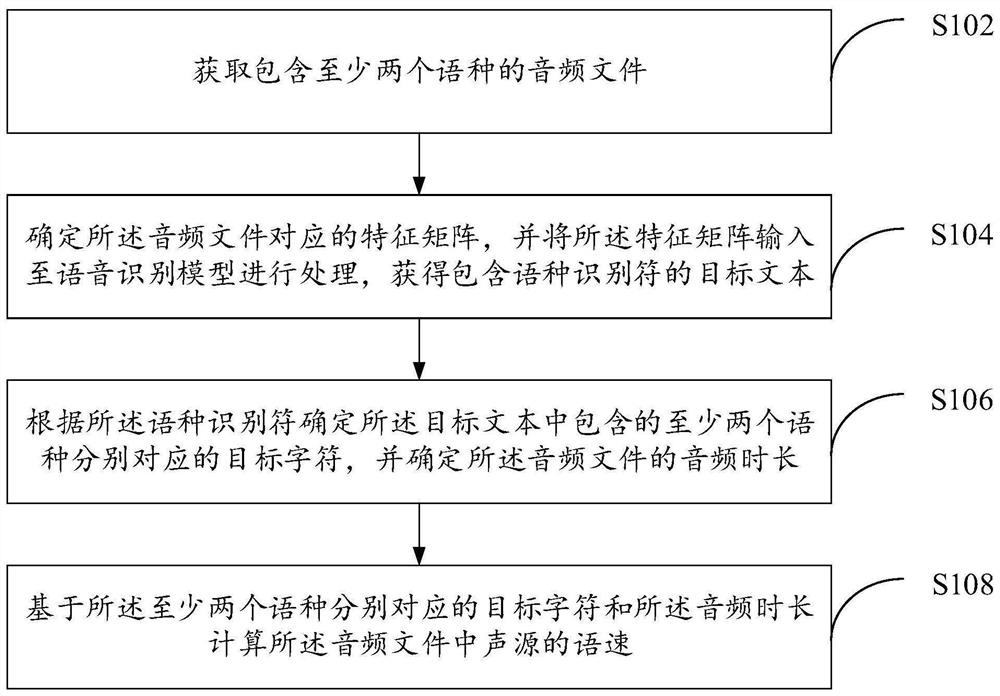
本说明书提供音频处理方法及装置,其中所述音频处理方法包括:获取包含至少两个语种的音频文件;确定所述音频文件对应的特征矩阵,并将所述特征矩阵输入至语音识别模型进行处理,获得包含语种识别符的目标文本;根据所述语种识别符确定所述目标文本中包含的至少两个语种分别对应的目标字符,并确定所述音频文件的音频时长;基于所述至少两个语种分别对应的目标字符和所述音频时长计算所述音频文件中声源的语速;实现对存在混合语种的语音语速进行精准的确定,进一步满足不同业务场景的使用需求。
2023-08-21 -
语音交互的方法、装置、设备和计算机存储介质
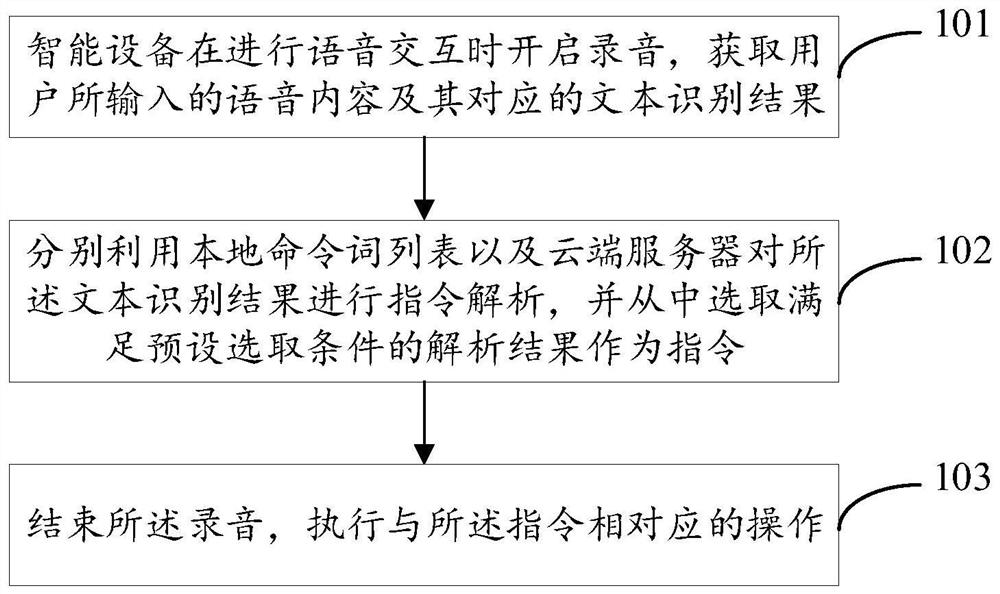
本发明提供一种语音交互的方法、装置、设备和计算机存储介质,所述方法包括:智能设备在进行语音交互时开启录音,获取用户所输入的语音内容及其对应的文本识别结果;分别利用本地命令词列表以及云端服务器对所述文本识别结果进行指令解析,并从中选取满足预设选取条件的解析结果作为指令;结束所述录音,执行与所述指令相对应的操作。本发明能够缩短用户与智能设备进行语音交互所需的时间,提升语音交互的效率。
2023-08-21 -
音频信号处理方法、装置、设备及存储介质
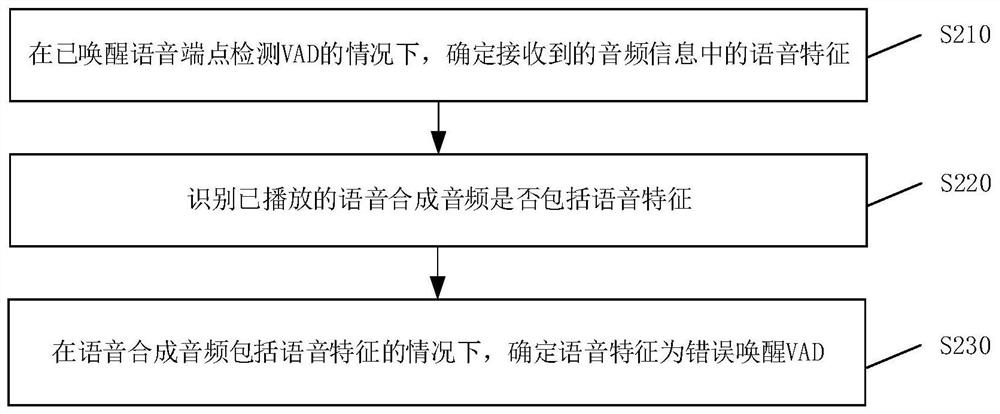
本发明实施例提供一种音频信号处理方法、装置、设备及存储介质,该方法包括:首先,在已唤醒语音端点检测VAD的情况下,确定接收到的音频信息中的语音特征;其次,识别已播放的语音合成音频是否包括语音特征;然后,在语音合成音频包括语音特征的情况下,确定语音特征为错误唤醒VAD。由此,解决了设备端“自己跟自己对话”的问题,提高智能语音交流的准确率。
2023-08-21 -
语音交互的方法、装置、设备和计算机存储介质
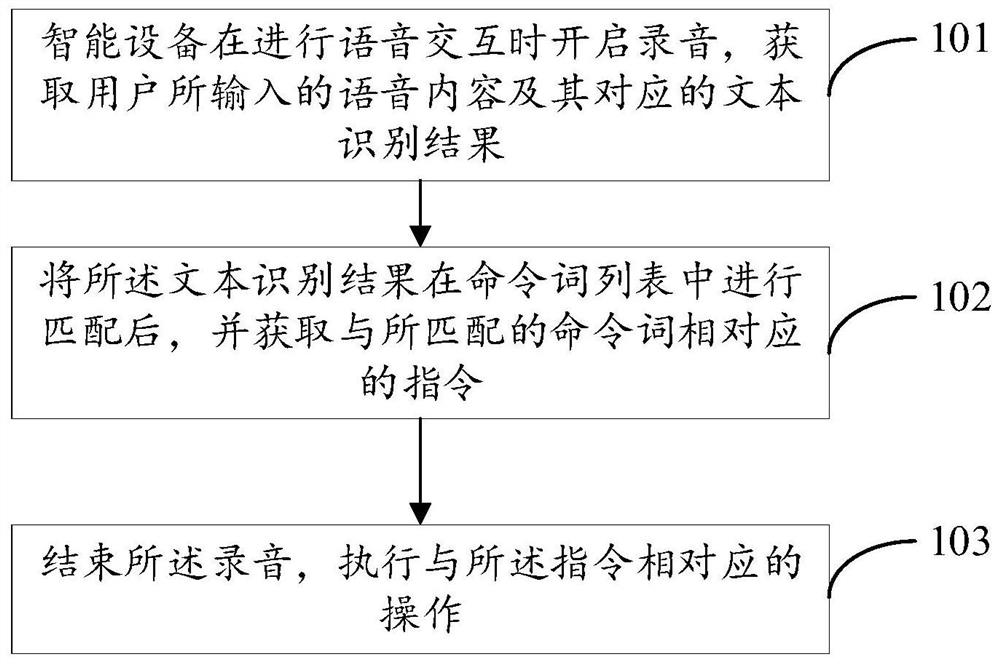
本发明提供一种语音交互的方法、装置、设备和计算机存储介质,所述方法包括:智能设备在进行语音交互时开启录音,获取用户所输入的语音内容及其对应的文本识别结果;将所述文本识别结果在命令词列表中进行匹配后,获取与所匹配的命令词相对应的指令;结束所述录音,执行与所述指令相对应的操作。本发明能够缩短语音交互所需的时间,提升语音交互的效率。
2023-08-21 -
一种基于子带信噪比估计的低复杂度双端检测方法
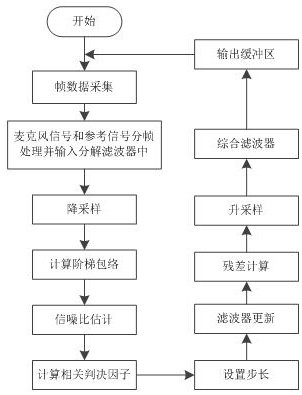
本发明公开了一种基于子带信噪比估计的低复杂度双端检测方法,包括以下步骤。首先将一帧信号通过分解滤波器得到子带信号,并进行降采样处理;其次在每个子带信号的每帧内找最大值,再将其转到对数域,得到阶梯包络;然后分别估计语音包络和噪声包络,得到当前帧的信噪比估计值;最后将子带信噪比映射为双端判决阈值,将自适应判决阈值应用到相关性判决因子上。使系统进入双讲状态时,及时冻结自适应滤波器的更新步长。本发明在复杂的噪声环境下,能有效提高回声抵消器的双端检测的准确率,在音频会议系统中具有良好的应用前景。
2023-08-21 -
一种基于语音控制的音量调节方法、装置、设备和介质
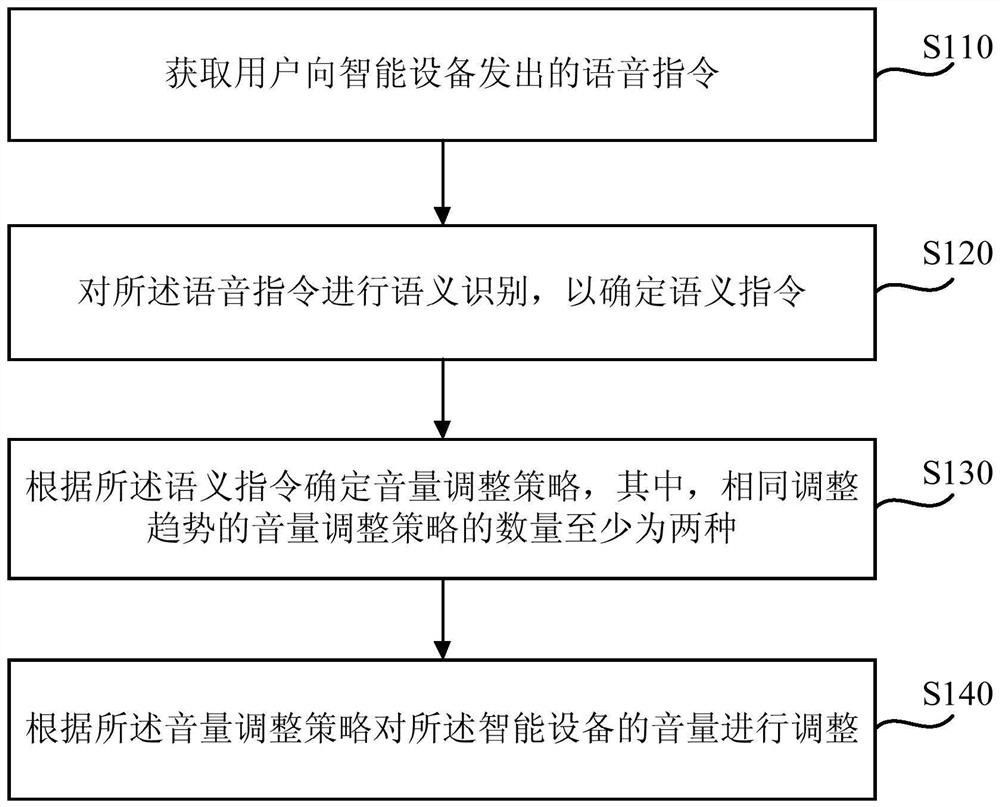
本发明实施例公开了一种基于语音控制的音量调节方法、装置、设备和介质。该方法包括:获取用户向智能设备发出的语音指令;对所述语音指令进行语义识别,以确定语义指令;根据所述语义指令确定音量调整策略,其中,相同调整趋势的音量调整策略的数量至少为两种;根据所述音量调整策略对所述智能设备的音量进行调整。该方法强化了基于语音指令进行音量调节的智能化程度,满足了用户的个性化、智能化交互体验需求。
2023-08-21 -
自适应的人机语音对话装置和设备、交互系统和车辆
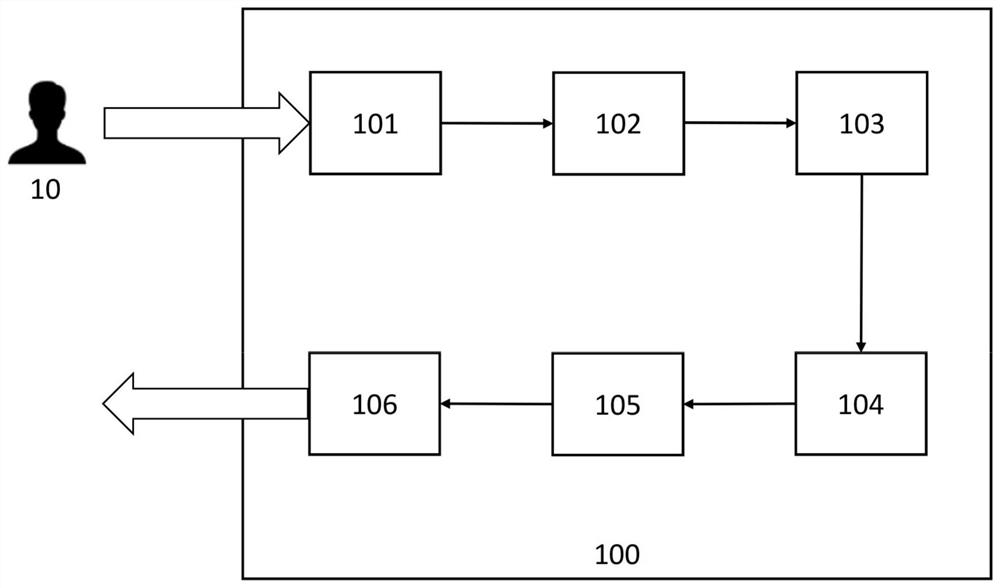
本发明涉及一种自适应的人机语音对话装置,包括:语音获取模块,用于获取语音信;语音识别模块,用于生成语音信息对应的文本信息;语义理解模块,用于分析语音信息对应的语义信息;对话管理模块;用于根据语义信息决定对话过程;对话生成模块,用于基于对话过程生成对话文本;其特征在于,所述人机语音对话装置进一步包括:语音片段形成模块,用于从由语音获取模块所获取的语音信息和由语音识别模块所生成的文本信息形成语音片段组;语音合成模块,用于基于所形成的语音片段组和所生成的对话文本合成语音对话。此外,本发明还包括一种人机语音交互系统、一种车辆以及一种自适应的人机语音对话设备。
2023-08-21 -
语音分离方法、装置、介质和电子设备
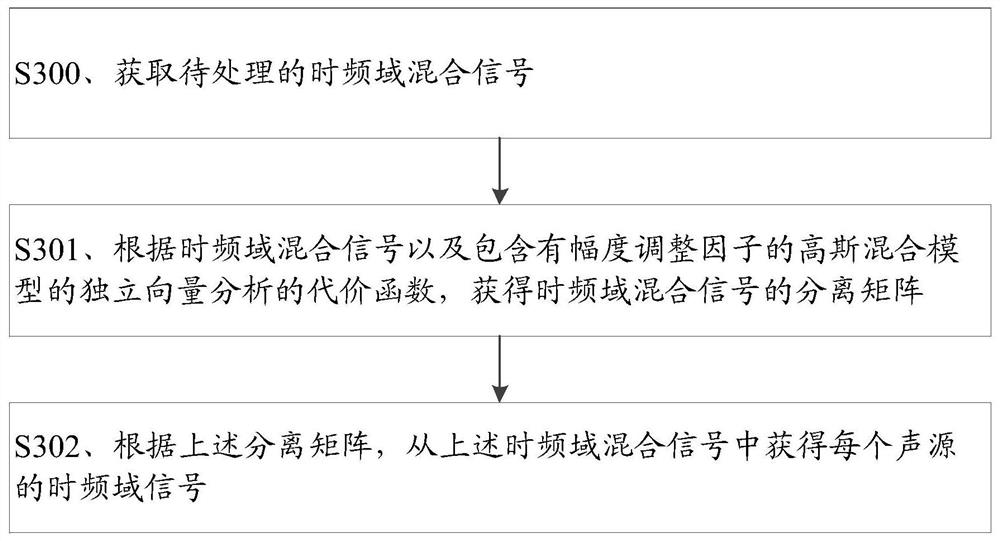
公开了一种语音分离方法、装置、介质和电子设备。其中的语音分离方法包括:获取待处理的时频域混合信号;根据所述时频域混合信号以及包含有幅度调整因子的高斯混合模型的独立向量分析的代价函数,获得所述时频域混合信号的分离矩阵;根据所述分离矩阵,从所述时频域混合信号中获得每个声源的时频域信号。本公开提供的技术方案有利于提高语音分离技术的可实施性,从而有利于提高语音分离技术的适用范围。
2023-08-21 -
语音识别模块的控制方法、语音识别模块及家用电器
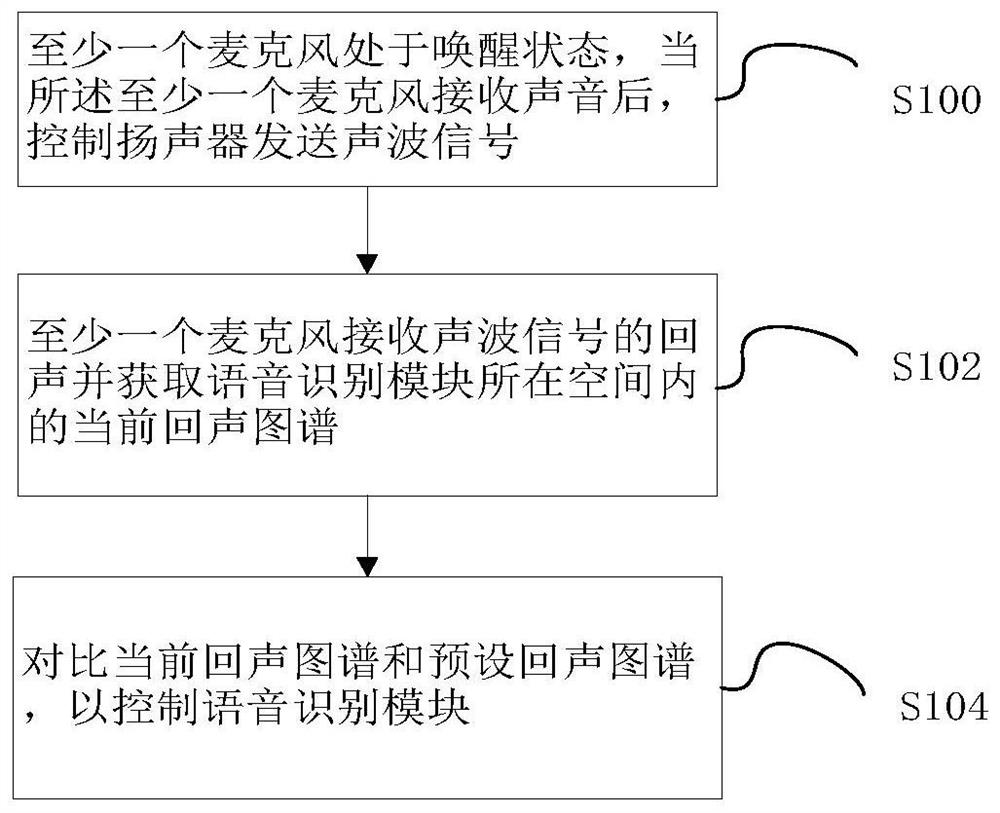
一种语音识别模块的控制方法、语音识别模块和家用电器,其中语音识别模块处于休眠状态,且语音识别模块包括麦克风阵列和扬声器,所述方法步骤包括:至少一个麦克风处于唤醒状态,当所述至少一个麦克风接收声音后,控制扬声器发送声波信号;所述至少一个麦克风接收所述声波信号的回声并获取语音识别模块所在空间内的当前回声图谱;对比当前回声图谱和预设回声图谱,以控制语音识别模块。通过该方案,能够实现在检测到用户需要使用语音识别功能时再唤醒语音识别模块,从而节约能耗,降低成本。
2023-08-21 -
一种设备组的播放方法、装置和播放系统
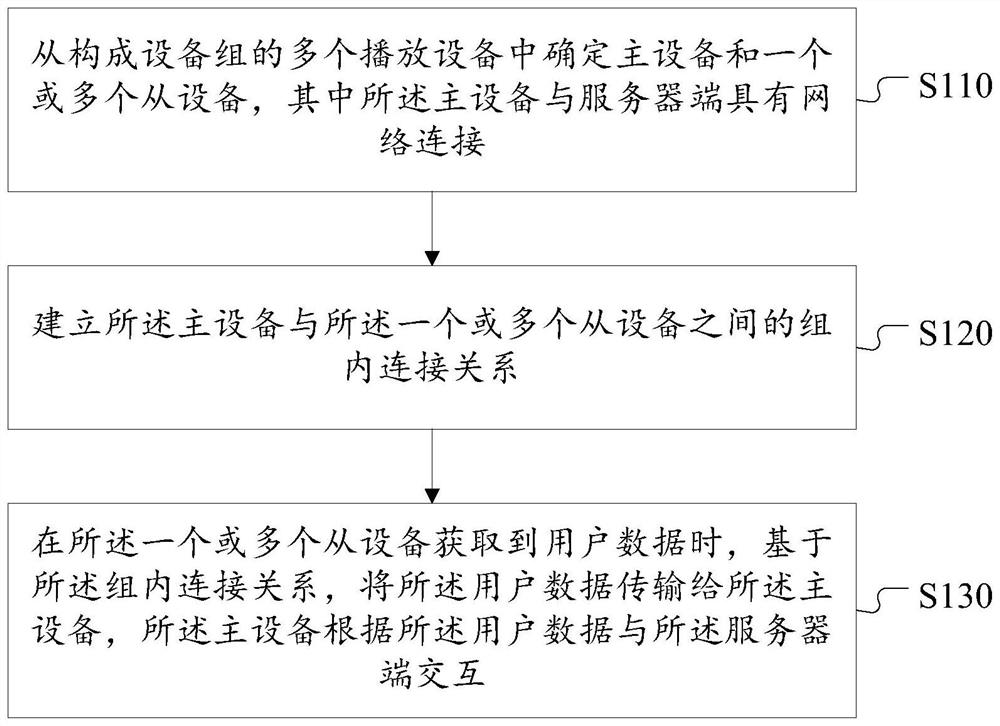
本发明公开一种设备组的播放方法、装置和播放系统。本发明的方法包括:从构成设备组的多个播放设备中确定主设备和一个或多个从设备,其中所述主设备与服务器端具有网络连接;建立所述主设备与所述一个或多个从设备之间的组内连接关系;在所述一个或多个从设备获取到用户数据时,基于所述组内连接关系,将所述用户数据传输给所述主设备,所述主设备根据所述用户数据与所述服务器端交互。本发明通过构建设备组中播放设备的主从关系,由主设备与服务器端进行统一的交互,即可实现整个设备组的上下文一致。
2023-08-21 -
多语言神经文本到语音合成
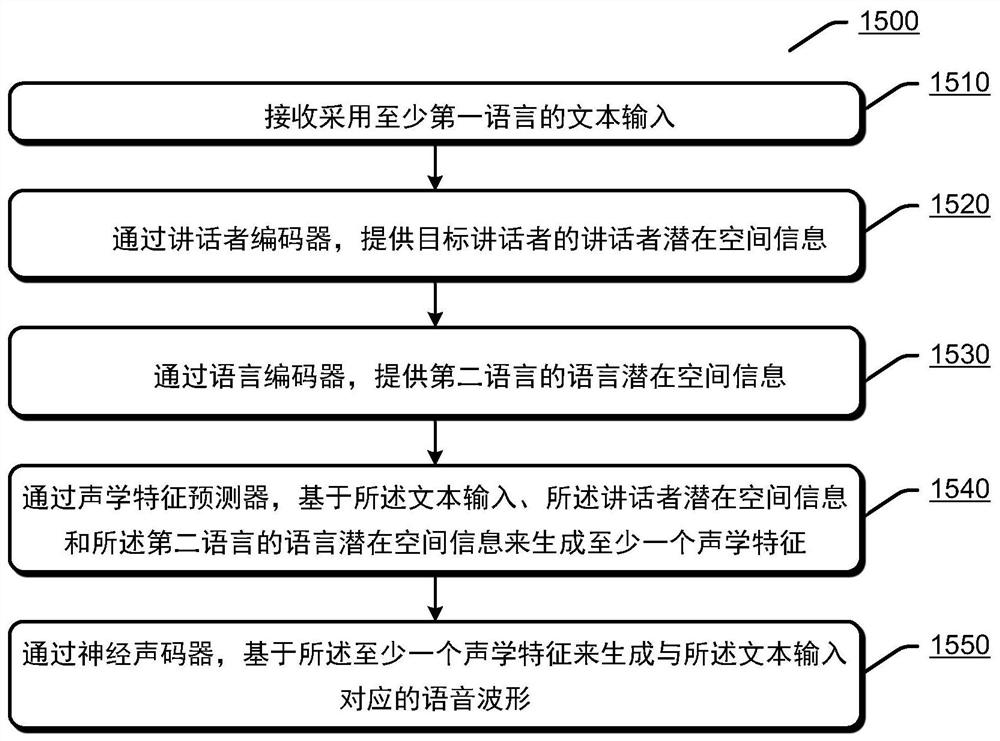
本公开提供了用于通过多语言神经文本到语音(TTS)合成来生成语音的方法和装置。可以接收采用至少第一语言的文本输入。可以通过讲话者编码器来提供目标讲话者的讲话者潜在空间信息。可以通过语言编码器来提供第二语言的语言潜在空间信息。可以通过声学特征预测器,基于所述文本输入、所述讲话者潜在空间信息和所述第二语言的语言潜在空间信息来生成至少一个声学特征。可以通过神经声码器,基于所述至少一个声学特征来生成与所述文本输入对应的语音波形。
2023-08-21 -
一种动态控制器
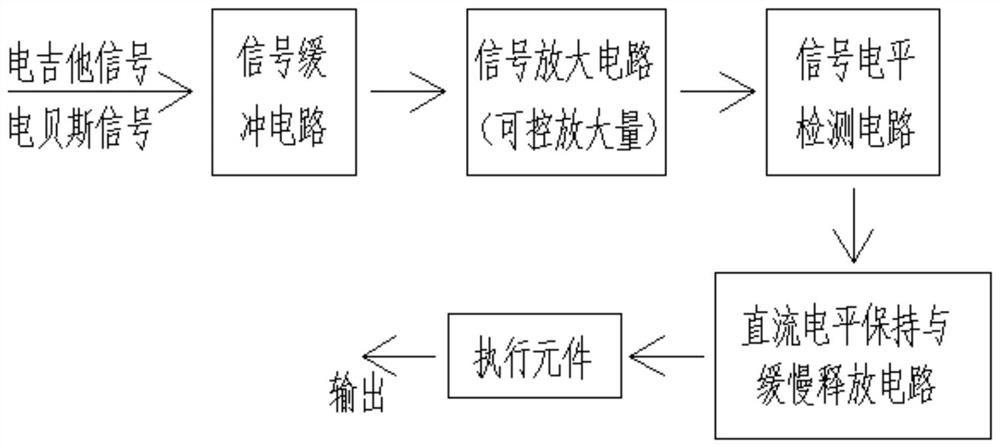
本发明公开了一种动态控制器,属于乐器领域,包括依次电连接的信号缓冲电路、信号放大电路、信号电平检测电路、直流电平保持与缓慢释放电路及执行元件,信号缓冲电路用于对输入的音频信号进行稳定化处理并降低阻抗;放大电路用于对信号缓冲电路处理后的音频信号进行放大,其中设有可调节本电路放大量的电位器;信号电平检测电路用于检测直流电平;直流电平保持与缓慢释放电路中包括实现电流缓慢释放的电容和光耦的发光管,该发光管接收到足够大的直流电流后才在光耦内发光;执行元件为光电阻,其根据接受的光照情况来改变自身电阻值。本发明实现了效果音的动态触发和延时启动,乐音转换衔接自然,且效果音不会影响到弹奏的乐音,音符清晰。
2023-08-21 -
关键词检测方法和装置、计算机可读存储介质、电子设备
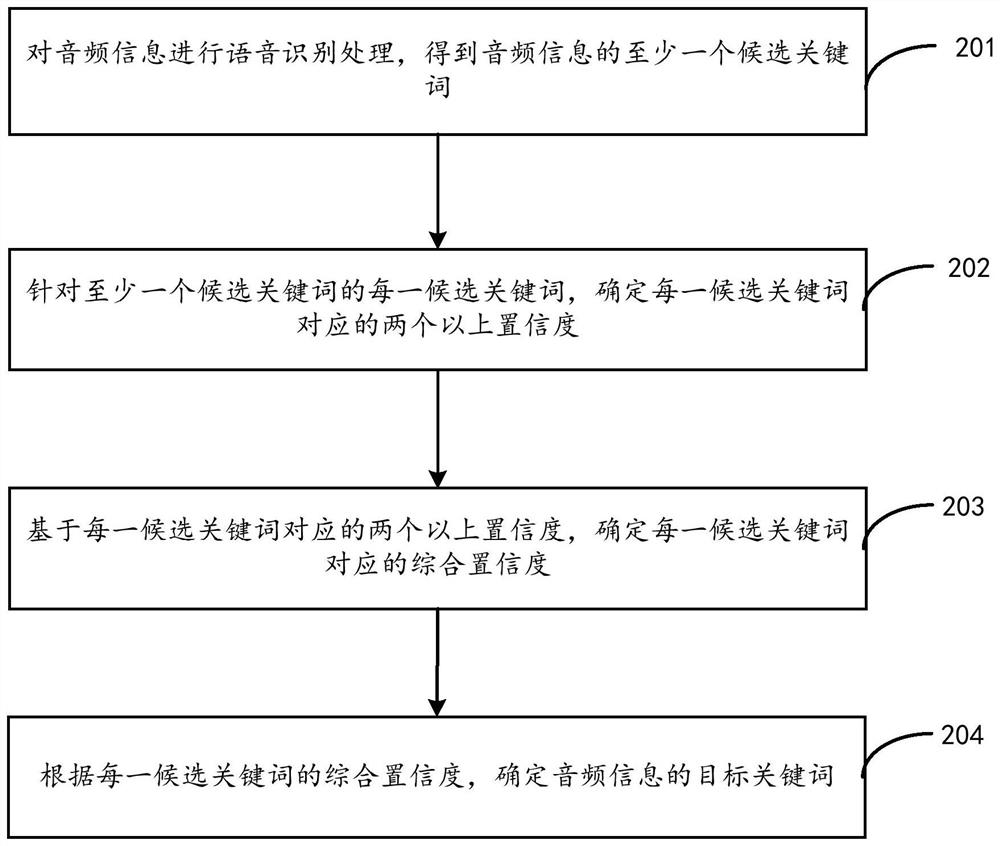
公开了一种关键词检测方法和装置、计算机可读存储介质和电子设备,其中,方法包括:对音频信息进行语音识别处理,得到音频信息的至少一个候选关键词;针对至少一个候选关键词的每一候选关键词,确定每一候选关键词对应的两个以上置信度;基于每一候选关键词对应的两个以上置信度,确定每一候选关键词对应的综合置信度;根据每一候选关键词的综合置信度,确定音频信息的目标关键词,当以该目标关键词进行语音唤醒时,由于是基于综合置信度确定的目标关键词,并且综合置信度体现了多个置信度的特点,因此可以实现在提升关键词的识别率的同时,有效降低关键词的误报率,同时兼顾关键词的识别率和误报率,从而获得较好的语音唤醒效果。
2023-08-21 -
歌曲生成

本公开内容提供了用于生成歌曲的方法和装置。可以接收文本输入。可以从文本输入中提取主题和情感。可以根据主题和情感来确定旋律。可以根据旋律和文本输入来生成歌词。可以至少根据旋律和歌词来生成歌曲。
2023-08-21 -
确定显示的识别文本的方法、装置、设备以及存储介质
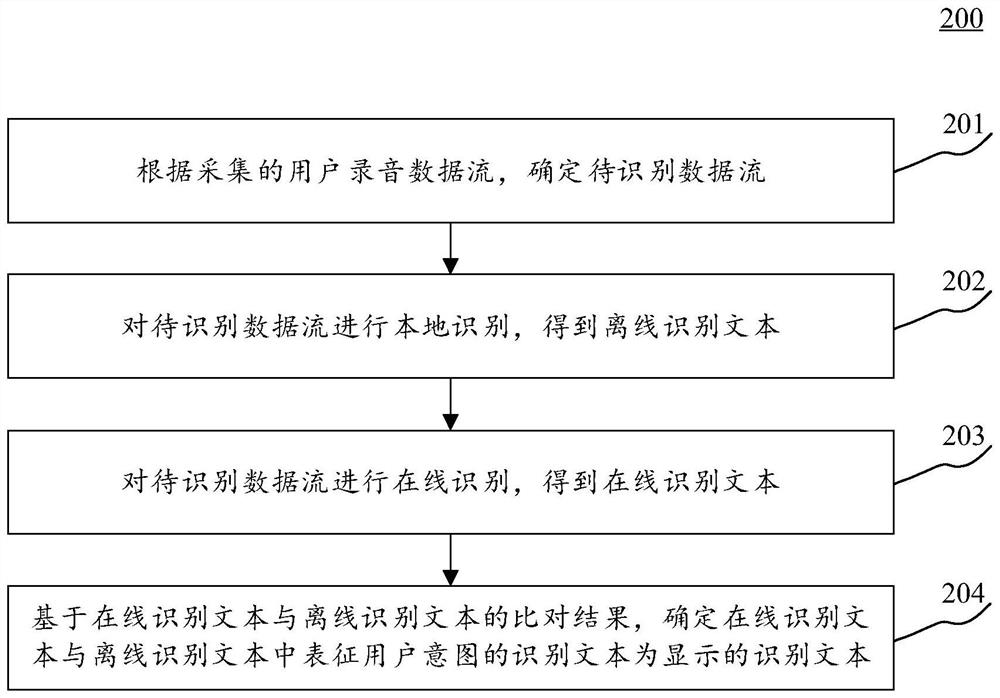
本申请实施例公开了确定显示的识别文本的方法、装置、设备以及存储介质,涉及语音识别、自然语言处理等人工智能技术领域。该方法包括:根据采集的用户录音数据流,确定待识别数据流;对待识别数据流进行本地识别,得到离线识别文本;对待识别数据流进行在线识别,得到在线识别文本;基于在线识别文本与离线识别文本的比对结果,确定在线识别文本与离线识别文本中优于表征用户意图的识别文本为显示的识别文本,通过采用在线识别与离线识别并行的方案,既充分发挥了离线识别的速度,又兼有在线识别的准确度,从而既解决了识别文本上屏慢的问题,又能保证识别效果。
2023-08-21 -
语音设备及其唤醒方法、装置以及存储介质
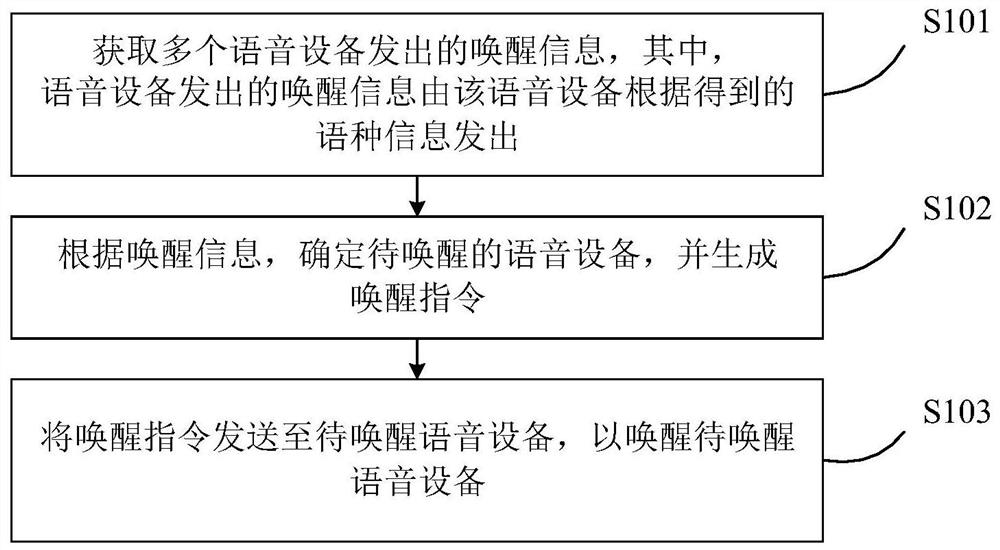
本发明公开了一种语音设备及其唤醒方法、装置以及存储介质,所述唤醒方法包括以下步骤:获取多个语音设备发出的唤醒信息,其中,语音设备发出的唤醒信息由该语音设备根据得到的语种信息发出,语种信息和唤醒能量值均由对应的语音设备根据接收到的语音唤醒指令得到;根据唤醒信息,确定待唤醒的语音设备,并生成唤醒指令;将唤醒指令发送至待唤醒语音设备,以唤醒待唤醒语音设备。该唤醒方法,可实现多个语音设备同时对语音唤醒指令进行识别分析,以获取语种信息和唤醒信息,并根据语种信息和唤醒信息确定需要唤醒的待唤醒语音设备,通过向其发送唤醒指令以将该待唤醒设备唤醒,从而实现多个语音设备的唯一唤醒。
2023-08-21 -
语音设备及其唤醒方法、装置以及存储介质
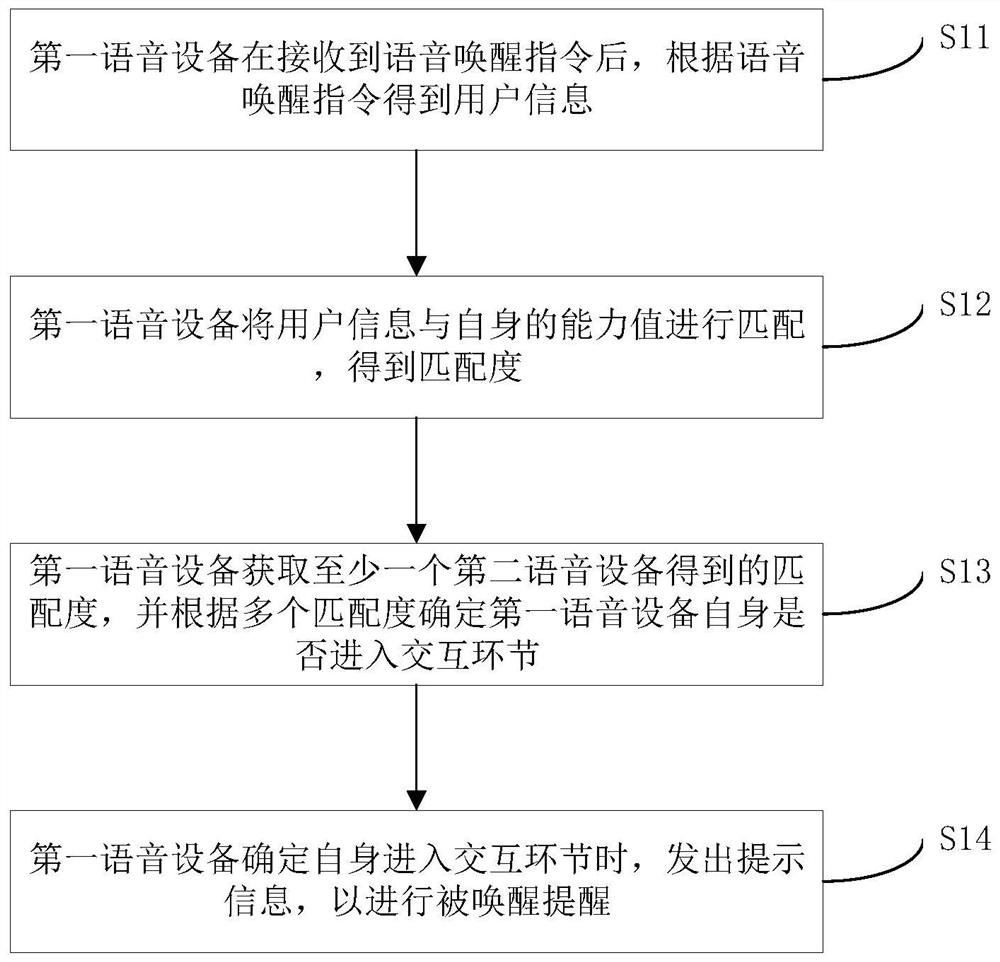
本发明公开了一种语音设备及其唤醒方法、装置以及存储介质。其中,语音设备的唤醒方法包括:第一语音设备在接收到语音唤醒指令后,根据语音唤醒指令得到用户信息;第一语音设备将用户信息与自身的能力值进行匹配,得到匹配度;第一语音设备获取至少一个第二语音设备得到的匹配度,并根据多个匹配度确定第一语音设备自身是否进入交互环节;第一语音设备确定自身进入交互环节时,发出提示信息,以进行被唤醒提醒。该语音设备的唤醒方法,可以根据语音唤醒指令提取得到用户信息,进而根据用户信息实现对响应语音唤醒指令的语音设备进行识别,从而实现在有多个语音设备响应语音唤醒指令时唯一唤醒语音设备。
2023-08-21 -
语音设备及其唤醒方法、装置以及存储介质
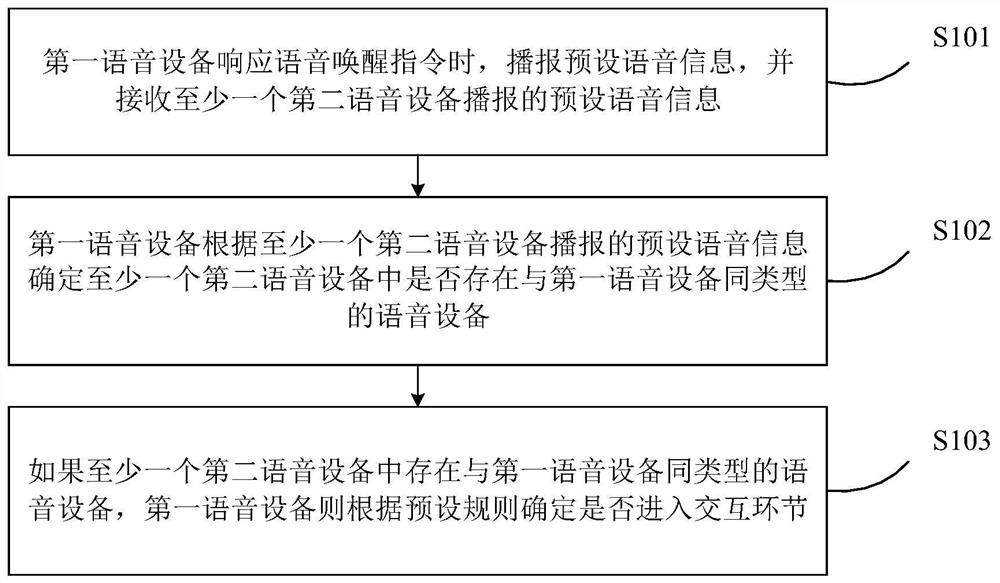
本发明公开了一种语音设备及其唤醒方法、装置以及存储介质,语音设备的唤醒方法,包括以下步骤:第一语音设备响应语音唤醒指令时,播报预设语音信息,并接收至少一个第二语音设备播报的预设语音信息;所述第一语音设备根据至少一个第二语音设备播报的预设语音信息确定至少一个第二语音设备中是否存在与第一语音设备同类型的语音设备;如果至少一个第二语音设备中存在与第一语音设备同类型的语音设备,第一语音设备则根据预设规则确定是否进入交互环节。由此,该唤醒方法可以在多个语音设备均响应语音唤醒指令时,进一步进行唤醒修正,以便实现唯一唤醒功能,提升用户使用体验。
2023-08-21 -
语音设备及其交互控制方法、装置以及存储介质
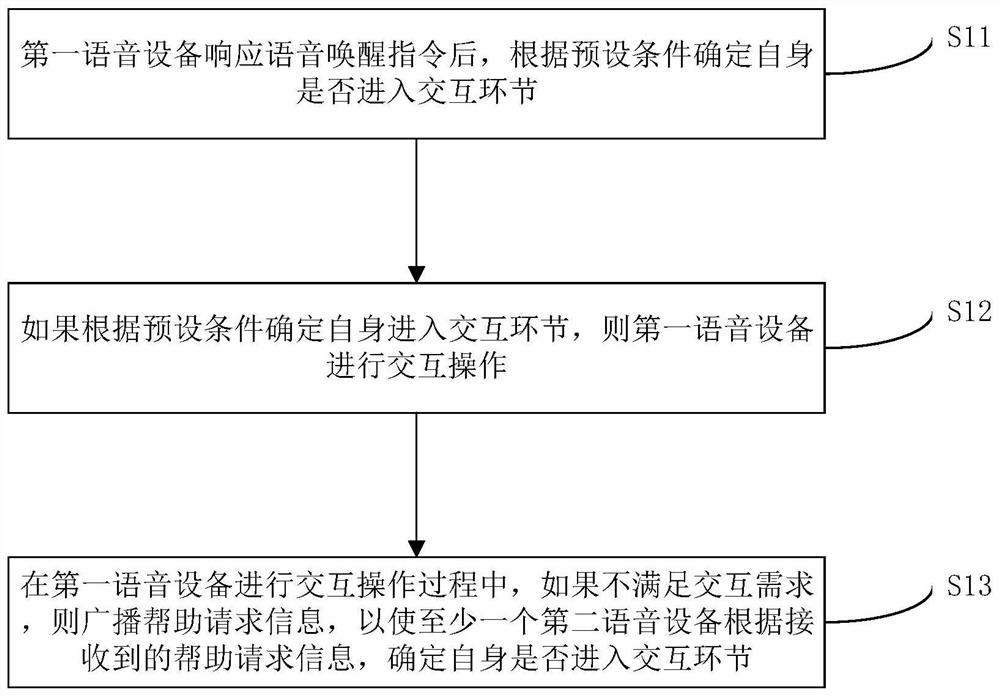
本发明公开了一种语音设备及其交互控制方法、装置以及存储介质。其中,交互控制方法包括:第一语音设备响应语音唤醒指令后,根据预设条件确定自身是否进入交互环节;如果根据预设条件确定自身进入交互环节,则第一语音设备进行交互操作;在第一语音设备进行交互操作过程中,如果不满足交互需求,则广播帮助请求信息,以使至少一个第二语音设备根据接收到的帮助请求信息,确定自身是否进入交互环节。该交互控制方法,可以实现当与用户进行交互的语音设备无法满足用户的交互需求时,可以将与用户进行交互的语音设备切换为其他语音设备,进而通过其他语音设备与用户进行交互,从而满足用户的交互需求。
2023-08-21 -
床上耳机导音装置

床上耳机导音装置,解决了耳机在睡眠时与身体接触引起不适,音量调节时要动手会让神经活跃不利于入睡,对听力保护不佳,人会担心辐射或触电等等影响入睡的问题。包括:支持部件和转动导音管,转动导音管上设计有出音口,将该装置固定在床头,将市面上的耳机头放入其上进音口,其上出音口可非接触定位于躺床人的耳朵附近,不会刺激皮肤导致不适,转动导音管与支持部件之间是转动连接的,通过转动,该出音口可调节离耳距离,从而调节输入耳朵的音量,加大该出音口的离耳距离只需通过转动人自身的头部来推动调节,这比动手去找音量调节按钮来调节的神经活跃度更低,人更易入睡,快睡着或睡着后人头部的转动会使出音口远离耳朵,从而更加保护听力。
2023-08-21 -
一种基于声纹识别技术的远程身份认证方法及系统
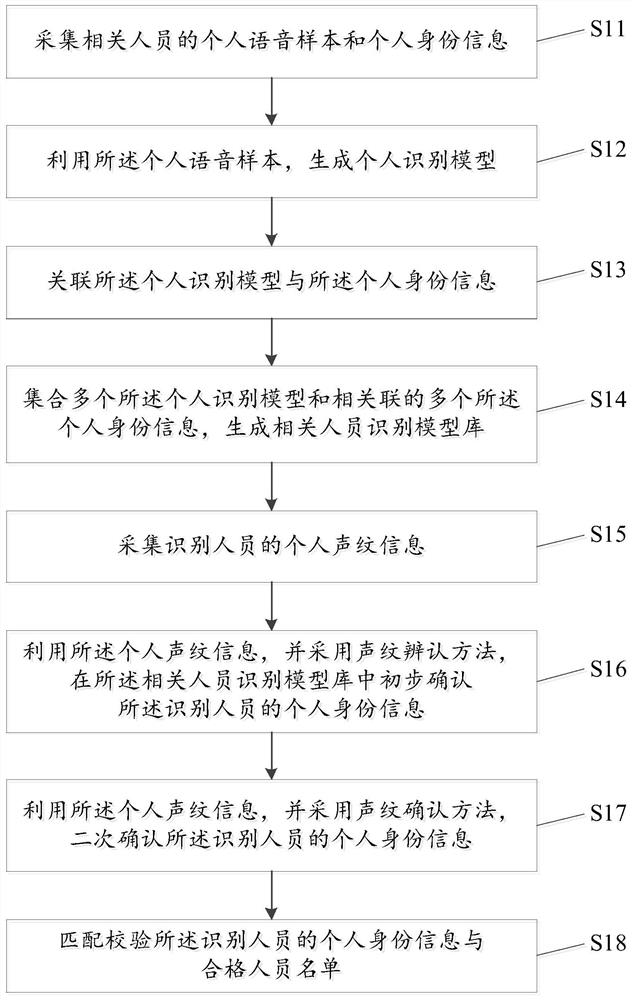
本发明公开了一种基于声纹识别技术的远程身份认证方法及系统,远程身份认证方法包括:采集相关人员的个人语音样本和个人身份信息;利用个人语音样本,生成个人识别模型;关联个人识别模型与个人身份信息;集合多个个人识别模型和多个个人身份信息,生成相关人员识别模型库;采集识别人员的个人声纹信息;利用个人声纹信息,采用声纹辨认方法,在相关人员识别模型库中初步确认识别人员的个人身份信息;利用个人声纹信息,采用声纹确认方法,二次确认识别人员的个人身份信息;匹配校验识别人员的个人身份信息与合格人员名单。在本发明实施例中,采用远程身份认证方法及系统能百分百确保对方是合格人员,确保对方业务技能达标,避免造成安全隐患。
2023-08-21 -
基于深度学习的猪咳嗽声监测与预警系统
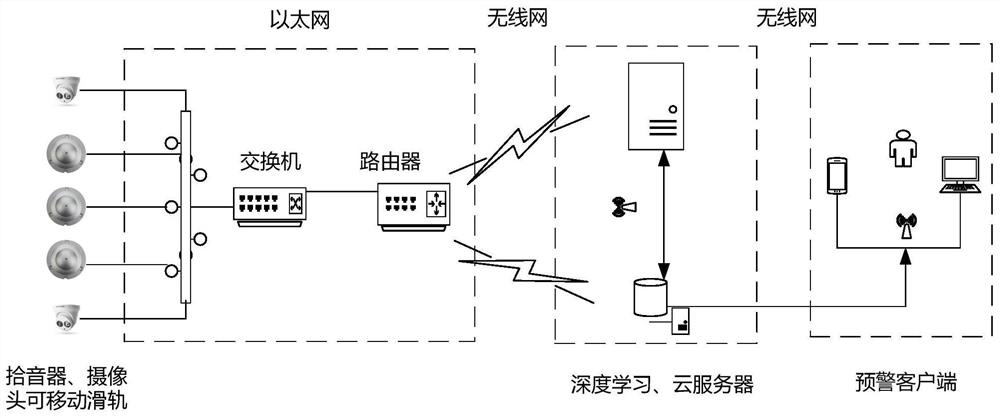
本发明公开了一种基于深度学习的猪咳嗽声监测与预警系统,它包括数据采集模块、路由、深度学习服务器、云服务器和预警客户端,该系统通过拾音器获取、存储猪舍内采集的音频信息,利用Socket无线通信技术实现本地音频数据实时上传至深度学习服务器,利用声学分析技术对复杂环境下的猪舍声音信号进行预处理与特征获取;研究对比基于双向长短时记忆网络(BLSTM)和深层前馈序列记忆神经网络(DFSMN)的猪咳嗽声变化规律,建立端对端的咳嗽声识别模型;最终形成猪呼吸系统疾病预警平台,高效、精准地实现猪呼吸系统疾病早期预警。
2023-08-21 -
音频文件生成方法、装置、设备及计算机可读存储介质

本申请实施例提供一种音频文件生成方法、装置、设备及计算机可读存储介质,涉及人工智能技术领域。方法包括:对接收到的文本和目标对象分别进行特征提取,对应得到文本的第一特征向量和目标对象的第二特征向量;对所述第一特征向量和所述第二特征向量进行拼接,形成拼接特征向量;对所述拼接特征向量进行音频属性特征的预测,得到至少两个具有不同类型的音频属性特征;根据至少两个所述音频属性特征,生成包含有所述文本且具有所述目标对象的声音特性的音频文件。通过本申请实施例,能够提高音频文件生成方法的实际使用范围,提高方法的泛化性。
2023-08-21