乐器、声学
-
用于检查机动车中的语音识别系统的在线功能的可用性的方法和系统

本发明涉及一种用于检查机动车(1)中的语音识别系统(4)的在线功能(5)的可用性的方法以及系统。该方法包括:在机动车(1)中的通信接口(12)和外部设备(3)之间提供(S1)通信连接(13);以及连续确定(S2)所提供的通信连接(13)在当前时间点存在还是中断。如果通信连接(13)存在,则检查(S3)机动车(1)的语音识别系统(4)的在线功能(5)是否经由存在的通信连接(13)可用。如果在线功能(5)不可用和/或通信连接(13)中断,则在机动车(1)中提供(S5)描述语音识别系统(4)的在线功能(5)的缺失可用性的通知(15)。通知(15)独立于语音识别系统(4)的实际的启用和/或使用来提供。
2024-06-24 -
一种基于SincNet的短语音说话人识别方法

本发明提出了一种基于SincNet的短语音说话人识别方法,在测试语音长度较短的真实场景中,达到较高的说话人识别性能。为了提升说话人身份特征的提取能力,采用Sinc函数实现带通滤波器来替换传统卷积神经网络的卷积层,用不同窗口大小的Sinc滤波器组提取多分辨率的特征,并结合注意力机制增强相关特征;再将特征图输入到SEResNet中得到更高层的特征,通过空洞空间金字塔池化进行多尺度特征融合,最后通过全连接层获得语音分类得分。在TIMIT语料库上进行实验,在0.5s的测试语音条件下分类错误率降低到了7.72%,高于传统CNN等对比方法。本发明可以用于金融证券认证身份,用于司法刑事提供刑罚判处佐证等。
2024-06-24 -
一种可穿戴婴幼儿语音录入系统

本发明公开了一种可穿戴婴幼儿语音录入系统,包括可穿戴端、信息中转端、云端服务器和其它终端;所述可穿戴端通过运算将语音在本地进行粗筛,然后将语音数据直接发送给信息中转端进行缓存;所述信息中转端将数据转发给其它终端或云端服务器;所述云端服务器将数据进行深度处理后转发给其它终端。本发明,可穿戴信息自动录入方便随时随地保护婴幼儿,防止突发情况,不局限于特定环境;当发现数据满足条件时,便开始实时上传数据到信息中转站,节省大量电量,缩小电池体积;解决了、续航能力、体积和实时性相互制约的问题,还能发挥云端的超级处理能力。
2024-06-24 -
对讲终端的语音处理方法、装置、终端设备及存储介质

本发明公开了一种对讲终端的语音处理方法、装置、终端设备及存储介质。所述方法包括:获取对讲终端的输入语音;对所述输入语音进行检测,在检测到所述输入语音包含噪声时,将所述输入语音输入降噪模型中,以使所述降噪模型提取输入语音中的活动语音,并对所述活动语音进行增益,输出消除噪声的第一语音;根据所述第一语音确定输出语音,以使对讲终端输出所述输出语音。通过实施本发明能提高对讲终端输出语音质量。
2024-06-24 -
基于会话驱动的流程编排在通讯智能机器人的管理系统

本发明涉及自动会话流程编排技术领域,具体为基于会话驱动的流程编排在通讯智能机器人的管理系统,系统由会话管理模块、流程编排模块以及节点执行模块组成;有益效果为:本发明提出的基于会话驱动的流程编排在通讯智能机器人的管理系统,通过提取会话的关键词来触发特定场景会话流程启动。一旦触发,流程中的节点和流程将被激活,形成一个基于设计好的节点与流程的“机器人”。该“机器人”能够依次执行流程中的各个节点,接收会话消息、调用接口、发送回复等,从而实现一段自动化的会话过程。这种基于会话驱动的流程编排方式使得智能机器人能够更加灵活地响应用户需求,提供个性化的服务,提升交互体验,提供智能化、高效率的会话交互服务。
2024-06-23 -
一种耳机及声纹解锁方法、装置、可读存储介质

本申请适用于声纹识别技术领域,提供了一种耳机及声纹解锁方法、装置、可读存储介质。所述方法包括:采集用户的待测语音信号,并提取待测语音信号的特征参数;根据特征参数和已训练完成的声纹识别模型,获得声纹识别结果;根据声纹识别结果,验证用户身份;若验证通过,则向目标设备发送解锁指令。本申请能够实现语音信号解锁目标设备,即使双手被占用,也能够方便解锁。同时,通过声纹识别,能够快速验证用户身份,耗时短。
2024-06-23 -
方言流式语音识别方法、装置、电子设备及存储介质

本发明提供一种方言流式语音识别方法、装置、电子设备及存储介质,其中方法包括:分别调整预训练语音识别模型的注意力机制和卷积感受野,以将其进行流式化处理;在流式化的预训练语音识别模型中引入蒸馏损失,以实现非流式模型至流式模型的知识迁移;对目标方言语音对应的方言语音样本进行预处理并分段,并利用分段的方言语音样本对经知识迁移的预训练语音识别模型进行微调训练,获取目标方言语音识别模型;将目标方言语音进行预处理并分段后,将分段的目标方言语音输入所述目标方言语音识别模型,以获取对目标方言语音的识别结果。本发明通过对预训练语音识别模型进行流式化处理,并利用知识迁移进行辅助,能够显著提升流式模型的识别精度。
2024-06-23 -
音频信号的处理方法及其装置

本申请公开了一种音频信号的处理方法及其装置,属于音频信号处理技术领域。该方法包括:获取音频信号的多个子带及每个子带的标度因子;基于多个子带的标度因子,确定用于对音频信号的频谱包络进行整形的基准值;以基准值为基线,对音频信号的频谱包络进行整形,得到经过整形的频谱包络对应的每个子带的调节因子,调节因子用于对音频信号的频谱值进行量化,和/或,调节因子用于对频谱值的码值进行反量化。本申请在保证音质效果的同时,提升对音频信号进行编码的压缩效率。
2024-06-23 -
一种应用于头盔的加权融合风噪降噪方法

本发明提出了一种应用于头盔的加权融合风噪降噪方法。所述方法包括:步骤一:将参考麦克风1置于头盔内部下巴偏右处,参考麦克风2置于头盔内部右耳水平处,参考麦克风3置于头盔内部右边太阳穴水平处,误差麦克风置于右耳耳蜗处,多个参考麦克风拾取到的信号按照功率加权融合为一路参考信号,进行前馈有源噪声控制;步骤二,参考信号经过步骤一训练得到的固定系数前馈控制滤波器与反馈参考信号经过实时迭代更新的反馈控制滤波器进行叠加共同作用于有源噪声控制。本发明提出了头盔风噪降噪的参考麦克风物理布局与一种应用于头盔的加权融合风噪降噪方法,较低运算量的同时保证了较好的降噪性能,对硬件资源的性能要求较低,实用性强。
2024-06-23 -
由电子设备执行的方法、电子设备及存储介质
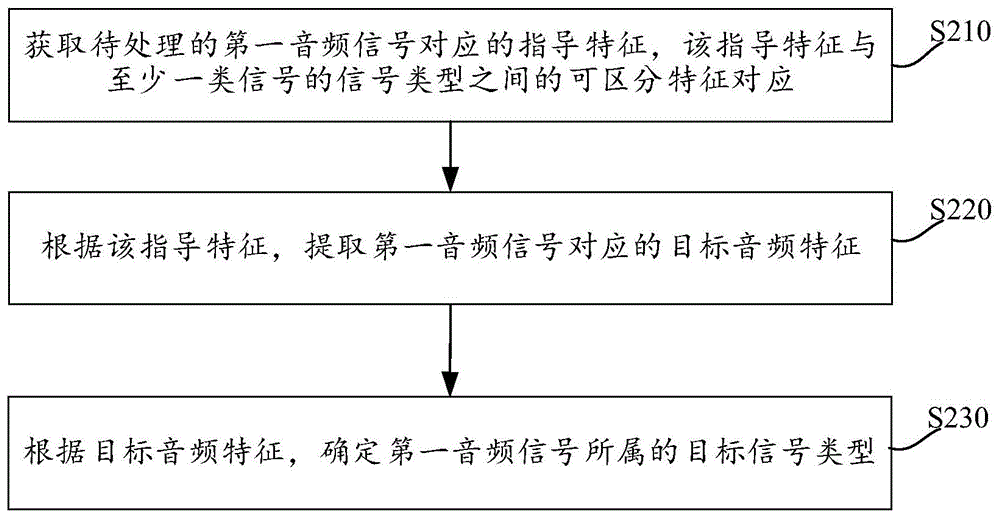
本申请提供一种由电子设备执行的方法、电子设备及存储介质,涉及音频处理及人工智能技术领域。该方法包括:获取待处理的第一音频信号对应的指导特征,所述指导特征与至少一类信号的信号类型之间的可区分特征对应;根据所述指导特征,提取所述第一音频信号对应的目标音频特征;根据所述目标音频特征,确定所述第一音频信号所属的目标信号类型。基于本申请提供的方案,能够有效提高信号检测效果,可以更好的满足实际应用需求。
2024-06-22 -
吸油烟机的音频注入调控方法、装置、电子设备和介质
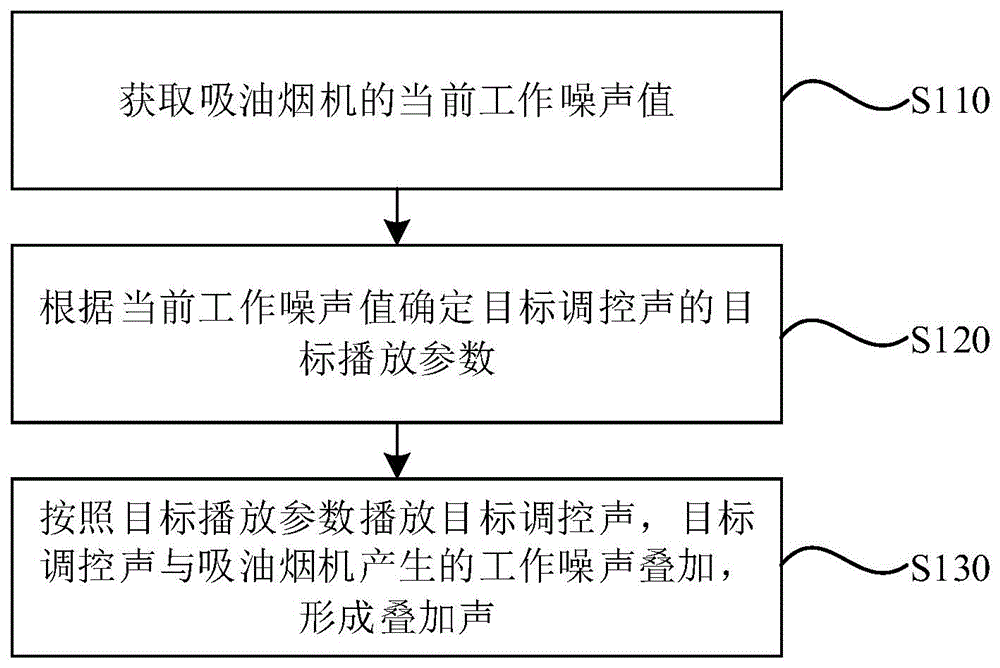
本发明公开了一种吸油烟机的音频注入调控方法、装置、电子设备和介质。音频注入调控方法包括:获取吸油烟机的当前工作噪声值;根据当前工作噪声值确定目标调控声的目标播放参数;按照目标播放参数播放目标调控声,目标调控声与吸油烟机产生的工作噪声叠加,形成叠加声。通过上述方案,吸油烟机注入的调控声能够与吸油烟机实际工作状态匹配,实现调控声的智能化匹配调节,提升吸油烟机的音频注入效果,降低用户烦恼度,提升用户使用体验;另外用户也可通过注入的调控声直观得知吸油烟机的运行状态。
2024-06-22 -
语音交互方法、服务器和计算机可读存储介质
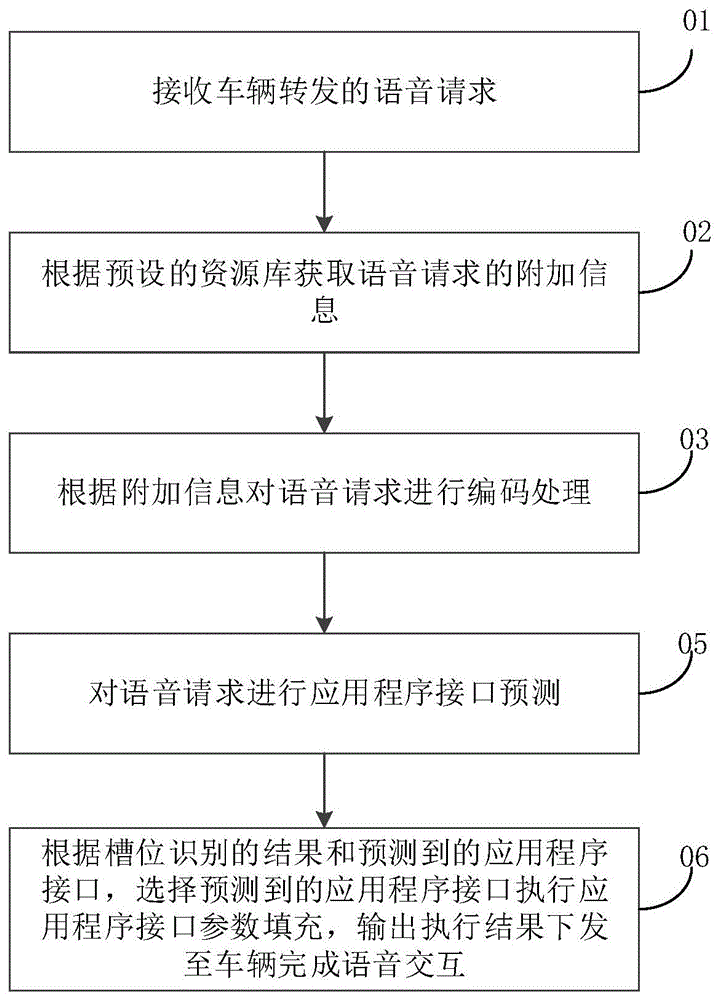
本申请公开了一种语音交互方法,包括:接收车辆转发的语音请求,根据预设的资源库获取语音请求的附加信息,根据附加信息对语音请求进行编码处理,根据编码处理的结果对语音请求进行槽位识别,对语音请求进行应用程序接口预测,根据槽位识别的结果和预测到的应用程序接口,选择预测到的应用程序接口执行应用程序接口参数填充,输出执行结果下发至车辆完成语音交互。本申请实施方式的语音交互方法,在槽位识别的过程中,引入资源库中存储的语音请求的附加信息,并根据附加信息对语音请求进行编码处理,使得附加信息编入语音请求的编码信息中,为槽位提取提供更多更全面的外部信息,从而可以有效地提升槽位识别的准确性,提高用户的语音交互体验。
2024-06-22 -
基于LORA微调辅助的语音唤醒快速自适应方法
本发明公开了基于LORA微调辅助的语音唤醒快速自适应方法,通过训练得到一个通用的音素识别模型,对输入音频进行初步的音素序列分类;并在唤醒词通用训练集上对音素识别模型进行微调,快速提高识别模型的唤醒词识别能力;进一步地,基于客户提供的目标唤醒词语料,使用LORA训练的方法进行模型的部分参数微调,使得模型快速提高目标关键词唤醒的自适应能力。本发明在现有唤醒水平的基础上依照客户的具体唤醒词与唤醒环境的需求,利用少量的目标域数据进行快速高效的模型微调训练,使得模型可以在短时间内适应目标域的实际应用场景,在短时间低成本内实现唤醒模型的实际应用效果的提升。
2024-06-22 -
音频编码方法、音频解码方法、装置、可读存储介质

本申请提供了一种音频编码方法、音频解码方法、装置、电子设备、计算机可读存储介质及计算机程序产品;音频解码方法包括:响应于针对音频码流封装的解码请求,从音频码流封装包括的帧头中获取目标编码模式以及目标码率模式;其中,音频码流封装包括的音频码流是通过目标编码模式以及目标码率模式,对音频信号进行音频编码得到的,目标编码模式是从多个编码模式中获取的,目标码率模式是从多个码率模式中获取的;通过目标编码模式以及目标码率模式,对音频码流进行信号解码处理,得到音频码流对应的编码特征估计值;通过目标编码模式,对音频码流对应的编码特征估计值进行重建处理,得到音频码流对应的合成音频信号。
2024-06-22 -
设备唤醒方法、装置、存储介质及电子设备

本申请公开了一种设备唤醒方法、装置、存储介质及电子设备,涉及物联网技术领域,该方法包括:获取目标用户的多个用户语音对应的唤醒评定信息;从所述多个用户语音对应的唤醒评定信息中,提取至少包括各所述用户语音的唤醒置信度的语音特征信息,所述唤醒置信度为语音唤醒模型对用户语音分析得到的;对所述语音特征信息进行分析处理,得到所述目标用户对应的用户语音唤醒阈值,所述用户语音唤醒阈值用于判断是否根据所述目标用户的唤醒语音进行设备唤醒。本申请可以提升设备的语音唤醒效果,提升用户的体验。
2024-06-21 -
流式语音合成方法、装置、电子设备和存储介质
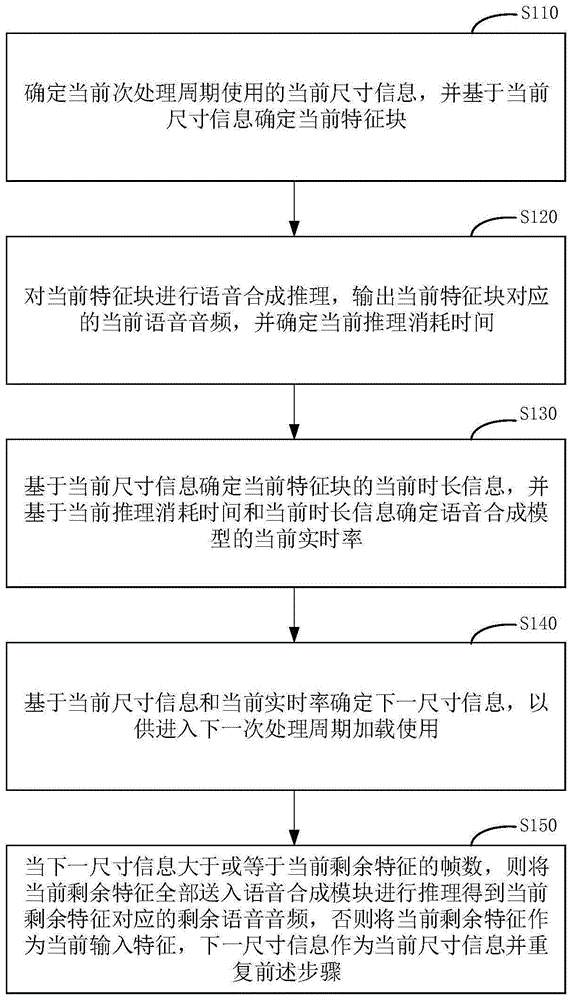
本发明公开了一种流式语音合成方法、装置、电子设备和存储介质。该方法包括:确定当前次处理周期使用的当前尺寸信息,并基于当前尺寸信息确定当前特征块,确定对当前特征块进行语音合成推理的当前推理消耗时间,基于当前尺寸信息确定当前特征块的当前时长信息,并基于当前推理消耗时间和当前时长信息确定语音合成模型的当前实时率,基于当前尺寸信息和当前实时率确定下一尺寸信息;当下一尺寸信息大于或等于当前剩余特征的帧数,则将当前剩余特征全部送入语音合成模块得到剩余语音音频,否则继续重复上述步骤。本申请解决了因固定分块尺寸而导致首帧时延与整体推理速度降低及合成效果无法兼顾的问题,提高了整体推理速度和合成效果。
2024-06-21 -
基于双扭结拓扑能谷边界态的声波束调控器及其制备和调控方法
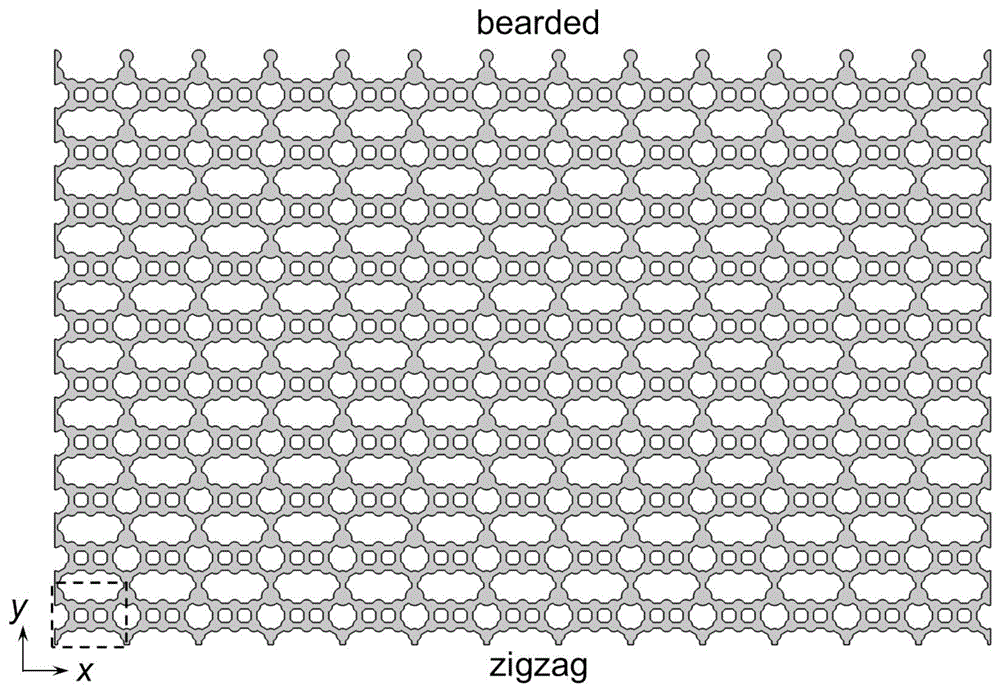
本发明公开一种基于双扭结拓扑能谷边界态的声波束调控器,包括顶层、底层和中间层,所述中间层包括声学原胞阵列取反的结构;所述声学原胞阵列包括若干在x方向和y方向上周期性排列的具有S‑石墨烯晶体结构的声学原胞,所述声学原胞在x方向或y方向上具有不对称性;所述中间层还被构造为:仅在x方向与空气联通,在y方向上布置有bearded边界以及zigzag边界。进一步本发明还提供一种上述声波束调控器的制备和调控方法。本发明可在不同边界处实现具有不同形貌的双扭结拓扑能谷边界态,并且,在边界上以一频率激发,通过调节两激发声源的相位差,可以分别得到准直出射和劈裂成两支斜出射的波束。
2024-06-20 -
通过操纵特征声学模态对音调噪声进行主动噪声消除
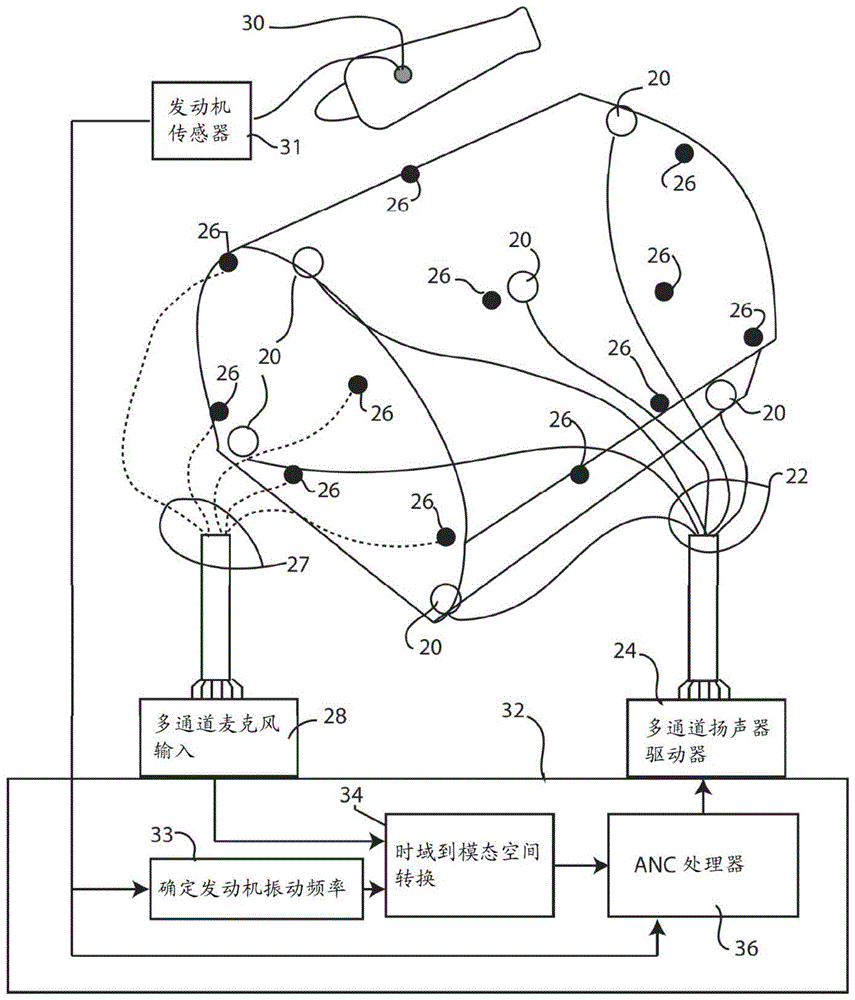
为了减少飞机的机舱中的发动机噪声,在机舱内的预定位置处部署多个误差麦克风,以产生与机舱中的发动机噪声相关联的误差麦克风响应信号。从耦合到飞机发动机的传感器获得发动机振动输入。使用处理器通过编码矩阵将误差麦克风响应信号编码为机舱中的编码模态响应。使用处理器应用自适应滤波器以确定消除机舱中的编码模态响应所需的多个模态信号。使用处理器通过解码矩阵将模态信号解码为扬声器输入信号。然后将扬声器输入信号发送到多个扬声器以减少机舱中的发动机噪声。
2024-06-20 -
音频信号处理方法、装置、电子设备及存储介质
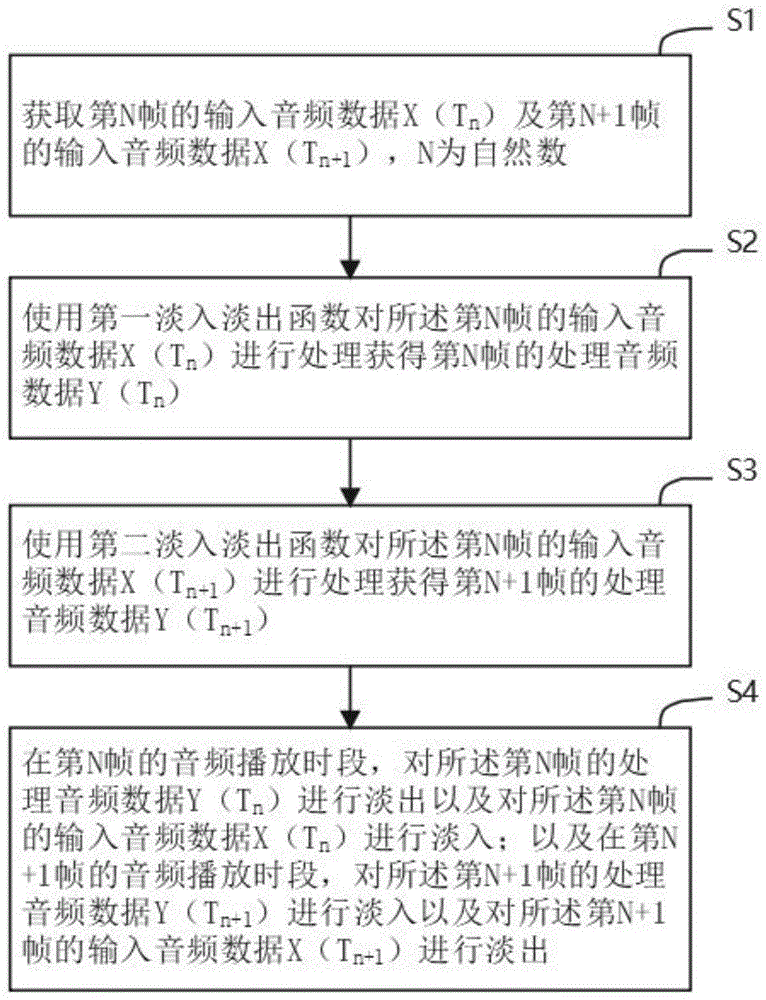
本发明公开一种音频信号处理方法、装置、电子设备及计算机可读存储介质,所述音频信号处理方法包括以下步骤:获取第N帧的输入音频数据X(Tn)及第N+1帧的输入音频数据X(Tn+1);使用第一淡入淡出函数对所述第N帧的输入音频数据X(Tn)进行处理获得第N帧的处理音频数据Y(Tn);使用第二淡入淡出函数对所述第N帧的输入音频数据X(Tn+1)进行处理获得第N+1帧的处理音频数据Y(Tn+1);在第N帧的音频播放时段,对所述第N帧的处理音频数据Y(Tn)进行淡出以及对所述第N帧的输入音频数据X(Tn)进行淡入;在第N+1帧的音频播放时段,对所述第N+1帧的处理音频数据Y(Tn+1)进行淡入以及对所述第N+1帧的输入音频数据X(Tn+1)进行淡出。
2024-06-19 -
可视化激光竖琴及其控制方法
本发明实施例公开了一种可视化激光竖琴及其控制方法,所述激光竖琴包括相对设置的激光头与光敏传感器,所述激光竖琴还包括对应设于激光头与光敏传感器之间透光管,透光管内装有用于与激光产生丁达尔现象的粒子溶液。本发明可以使操作者轻易看到光路,便于准确进行弹奏,实现了可视化,且不受演奏场所的限制,提升了演奏的观赏性。
2024-06-19 -
一种基于循环神经网络和全子频带特征的实时语音降噪方法
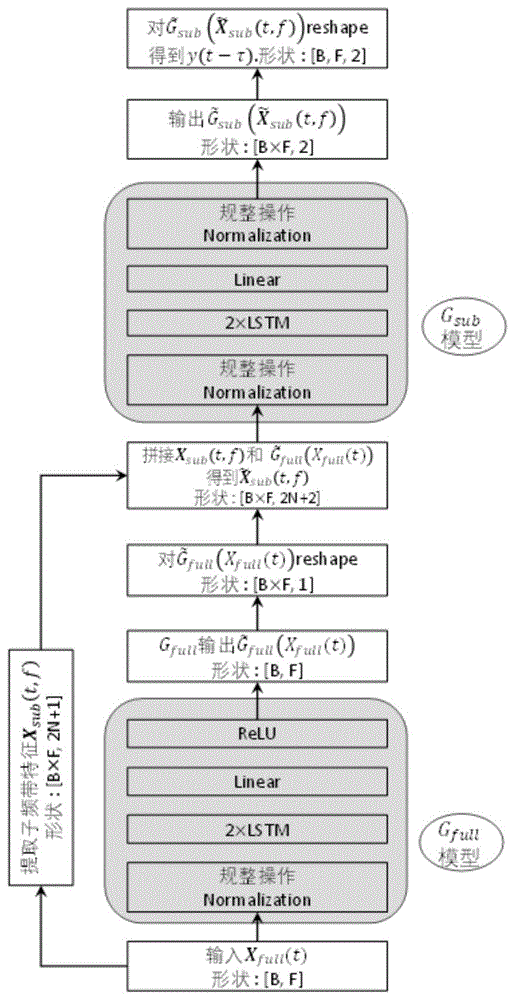
本发明公开了一种基于循环神经网络和全子频带特征的实时语音降噪方法,包括S1、搜集纯净语音、不同类型的噪声以及不同尺寸的房间冲激响应;S2、合成对应的带噪语音;S3、对其预设参数做短时傅里叶变换,得到其时频域的表示;S4、在每个频点联合其相邻的频点一起构成子频带特征;S5、把常规的全频带特征融合子频带特征作为最终的模型输入特征;S6、分别对全频带特征和子频带特征建立模型并且做合适的融合以充分利用;S7、依据S1‑S6训练出完整的降噪模型,对真实的带噪语音进行测试;S8、进行提升音质。本发明采用循环神经网络架构,融合了子频带特征以捕获更多的频谱信息,做到按帧实时处理,降低实时通信、语音会议场景下的延时。
2024-06-19 -
用于语音转换的可控说话者音频表示的方法及装置
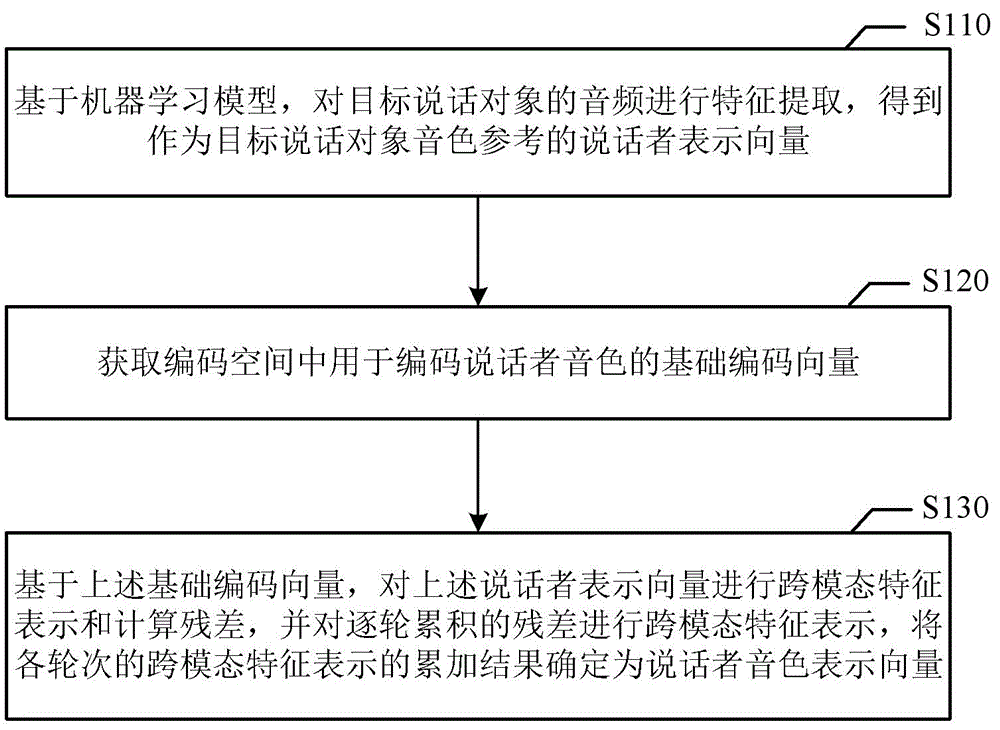
本公开涉及一种用于语音转换的可控说话者音频表示的方法及装置,上述方法包括:基于机器学习模型,对目标说话对象的音频进行特征提取,得到作为目标说话对象音色参考基准的说话者表示向量;获取编码空间中用于编码说话者音色的基础编码向量;基于上述基础编码向量,对上述说话者表示向量进行跨模态特征表示和计算残差,并对逐轮累积的残差进行跨模态特征表示,将各轮次的跨模态特征表示的累加结果确定为说话者音色表示向量。由于脱离了不同音色特征采用基础编码向量进行各类音色的表示,具有广泛的适用性,有助于提升语音转换方法或语音转换模型面对训练未出现过的说话者的鲁棒性。
2024-06-19 -
推进文本和语音在具有一致性和对比损失的ASR预训练中的使用
一种方法(600)包括接收训练数据,该训练数据包括非口头文本话语(320)、未转录非合成语音话语(306)和转录非合成语音话语(304)。每个非口头文本话语不与非合成语音的任何对应口头话语配对。每个未转录非合成语音话语不与对应转录配对。每个转录非合成语音话语与对应转录(302)配对。该方法还包括:使用文本到语音模型(330)针对接收到的训练数据的每个非口头文本话语生成对应合成语音表示(332)。该方法还包括:在针对非口头文本话语生成的合成语音表示、未转录非合成语音话语和转录非合成语音话语上预训练音频编码器(210),以教导该音频编码器联合地学习共享语音和文本表示。
2024-06-19 -
一种伴奏与人声分离方法、系统、编码器、介质及设备

本申请公开了一种伴奏与人声分离方法、系统、编码器、介质及设备,属于音频编解码技术领域,该方法包括:对混合音频信号中的音频帧进行编码的过程中,确定音频帧对应的混合幅度谱;将混合幅度谱输入到预训练神经网络模型中进行处理,得到对应的谱系数浮值掩膜;根据谱系数浮值掩膜对音频帧对应的混合谱系数进行分离,得到分离后的伴奏谱系数或人声谱系数;对伴奏谱系数或人声谱系数继续进行编码,得到对应的伴奏码流或人声码流。本申请利用神经网络模型对音频信号进行伴奏和人声的分离,保证音质效果;同时利用现有编码过程的时频变换和重叠相加过程,避免了增加算法延时,提高用户使用体验。
2024-06-19 -
基于韵律域信息监督的解耦-增强越南语语音识别口音自适应方法
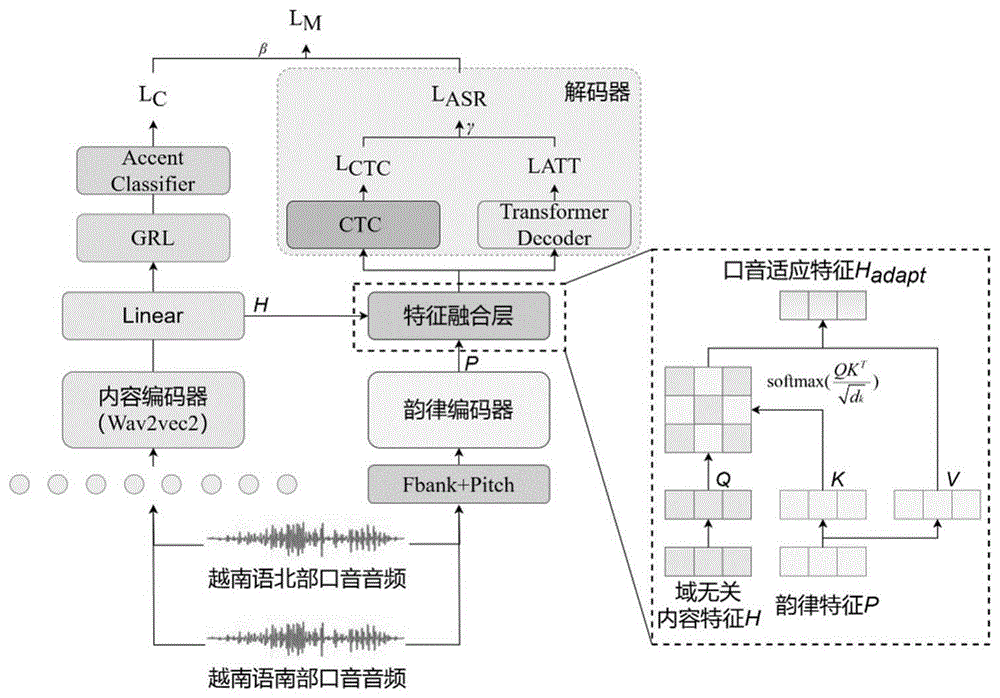
本发明涉及基于韵律域信息监督的解耦‑增强越南语语音识别口音自适应方法,属于人工智能技术领域。针对发音差异性下自适应语音识别问题,提出以韵律和域标签信息为指导的越南语语音解耦‑增强的自适应表征策略,实现了越南语南北口音差异性特征的自适应表征。首先,基于域对抗解耦实现域无关内容特征表征;其次,基于自适应选择实现域无关内容特征与韵律特征融合增强;最后,联合域分类与混合连接主义时序分类CTC/Attention实现越南语口音自适应识别。本发明显著降低了南部口音的识别词错率,缓解了识别模型因口音差异导致的性能下降问题,提高了越南语语音识别模型对南北口音的识别鲁棒性。
2024-06-19 -
一种基于循环神经网络的音乐生成和演奏方法及系统
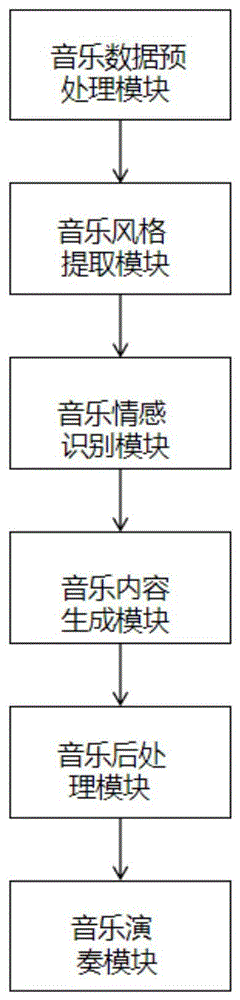
本发明公开了一种基于循环神经网络的音乐生成和演奏方法及系统,包括以下步骤:S1、将原始音乐数据通过音乐数据预处理模块转换格式;S2、从数据库中选择音乐数据作为训练集,通过音乐风格提取模块和音乐情感识别模块,提取训练集中音乐的风格和情感特征;S3、通过音乐内容生成模块训练改进的长短时记忆网络LSTM;S4、接收用户的输入条件,通过已训练好的LSTM网络生成相应的音乐内容。本发明用循环神经网络来生成具有多样性、连贯性、个性和表达力的音乐,且能够从音乐数据中提取音乐风格和情感的特征,增加了音乐生成的多样性和个性,采用改进的LSTM网络来生成音乐内容,从而增加了音乐生成的连贯性和表达力。
2024-06-18 -
基于交互注意力机制的多级声学信息的语音情感识别方法
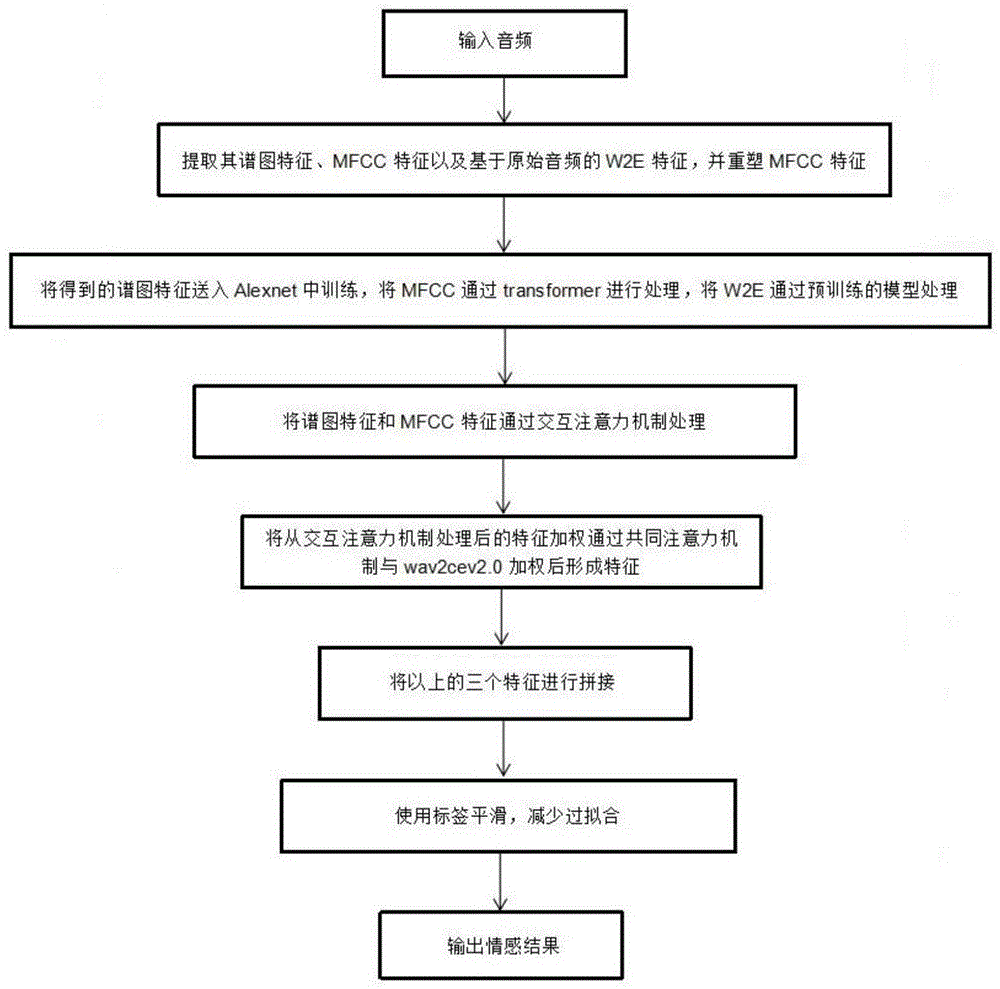
本发明提供一种基于交互注意力机制的多级声学信息的语音情感识别方法,对语音情感数据集的训练集和测试集提取基于卷积神经网络CNN的谱图特征、梅尔频率倒谱系数MFCC特征和高级声学信息W2E特征;设计包含Transformer模块和交互式注意力机制模块的用于多级声学信息的网络模型;将特征处理后的谱图特征、MFCC特征输入至交互式注意力机制模块进行融合处理;处理后的谱图特征和MFCC特征与经过wav2vec2.0模型的W2E特征加权,并通过共同注意力机制模块形成最终的wav2vec2.0特征;将经过网络处理后的谱图特征、MFCC特征以及得到的最终的wav2vec2.0特征进行拼接处理,形成最终的网络模型;多级声学信息的综合利用和交互式注意力机制的引入,提高了语音情感识别的性能,在实际应用中更加有效和可靠。
2024-06-18 -
基于复杂网络的高密度表面肌电无声语音识别通道选择方法
本发明属于语音识别技术领域,具体为一种基于复杂网络的高密度表面肌电无声语音识别通道选择方法。本发明方法包括:面部肌电信号采集及处理,减少运动伪影,降低高频噪声;采用陷波滤波器避免电力线的干扰;构建复杂网络,复杂网络用图G(V,E)表示,利用互信息方法,分析每对通道之间的相关性;对于每个电极阵列,构造邻接矩阵A(asq);使用louvain算法优化网络;提取特征及分类,将提取的特征矩阵输入到线性判别分析分类器中进行训练。本发明在初始肌肉网络的基础上,利用复杂网络理论中社区优化的Louvain算法,保证识别准确率,减少冗余通道,提高计算速度;筛选出对无声语音识别贡献大的通道,降低冗余的同时提高准确率。
2024-06-18 -
一种基于蜂窝结构的隔声超材料及其制备方法
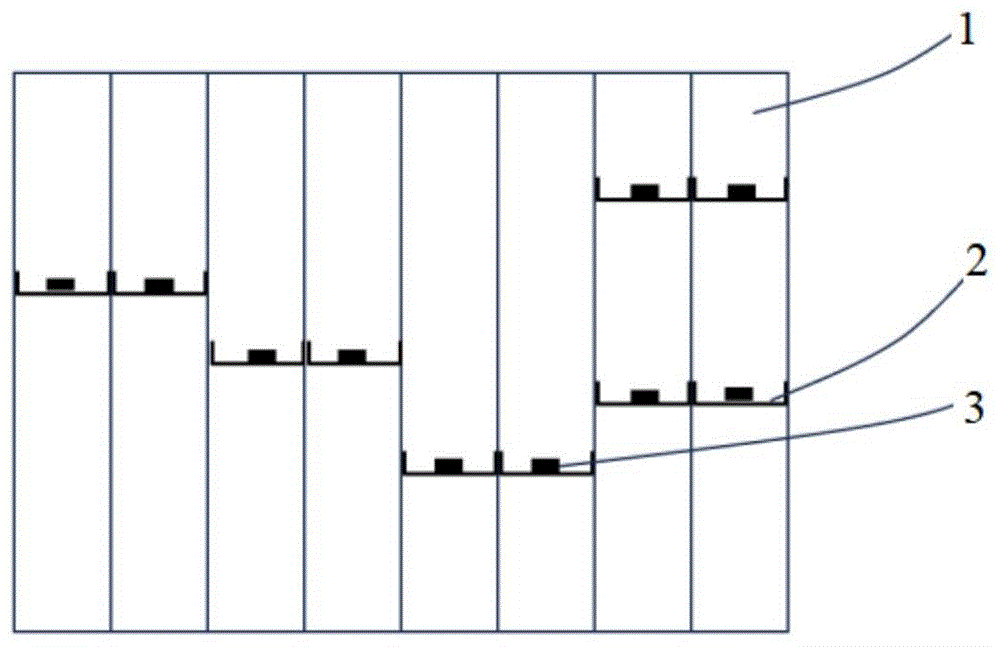
本发明涉及隔声材料技术领域,具体涉及一种基于蜂窝结构的隔声超材料及其制备方法。隔声超材料包括蜂窝结构、弹性膜和质量块,至少一层弹性膜嵌设于蜂窝结构的孔格内,质量块设于蜂窝结构的孔格内。该基于蜂窝结构的隔声超材料及其制备方法的目的是解决传统局域共振声学超材料的重量较大、隔声频带较窄的问题。
2024-06-18 -
一种防干扰晨读器及防干扰方法
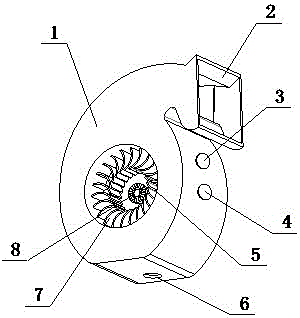
本发明一种防干扰晨读器及防干扰方法公开了一种能够通过变形消音片和消音棉对声音进行多重消除的防干扰晨读器及防干扰方法,可以减少声音在空气中的传播,降低相互干扰。其特征在于包括能够通过变形消音片和消音棉对声音进行多重消除的消音装置和用于播放声音的播放装置,所述播放装置内嵌于所述消音装置的前侧面,所述消音装置由晨读录音筒,进音口,录音机开关按钮,播放机开关按钮,出气偏孔,微型录音机,变形导音板,变形消音片,导音通道,过气细孔,消音棉和供电电源组成,晨读录音筒顶面开有进音口,所述晨读录音筒右侧面置有录音机开关按钮,所述晨读录音筒右侧面置有播放机开关按钮。
2024-06-18 -
吸音材料及其制备方法、装置、设备、炭基粘结剂及应用
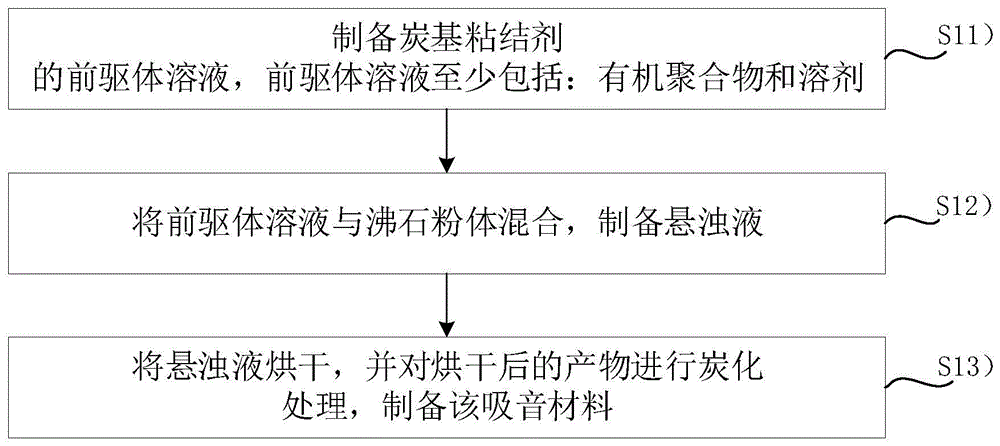
本申请涉及电子设备吸音技术领域,特别是涉及一种吸音材料及其制备方法、装置、设备、炭基粘结剂及应用。可以减小扬声器的声学性能损失。一种吸音材料,所述吸音材料呈颗粒状,每个吸音颗粒包括多个沸石粒子,以及将所述多个沸石粒子粘结在一起的炭基粘结剂,所述炭基粘结剂具有孔结构。
2024-06-17 -
用于泊位视频采集的语音互动系统
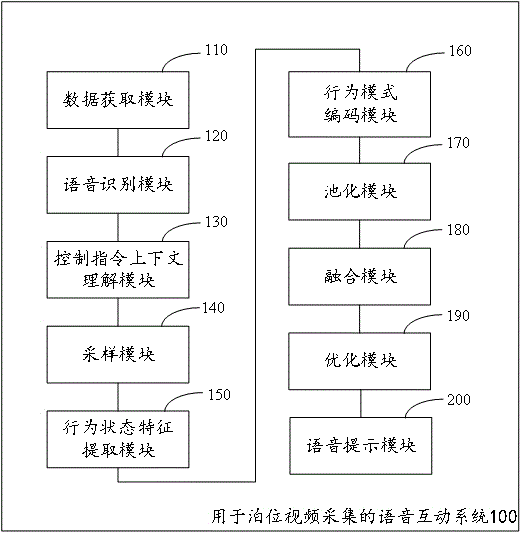
本申请涉及语音互动领域,其具体地公开了一种用于泊位视频采集的语音互动系统,其首先采集驾驶员的语音输入以及汽车在停泊位的行为状态监控视频,接着提取出驾驶员的语音控制指令特征以及汽车的相关停车行为特征,然后将所述驾驶员的语音控制指令特征以及所述汽车的相关停车行为特征进行融合以得到汽车调整指令相关特征,最后将所述汽车调整指令相关特征进行优化后输入到生成器中以生成语音信号,所述语音信号用来指导驾驶员该如何操作以使停车的位置更加合适。这样,给停车提供了更多的信息辅助,使得停车过程更加方便和准确。
2024-06-17 -
语音测试方法、装置、设备、存储介质及程序产品
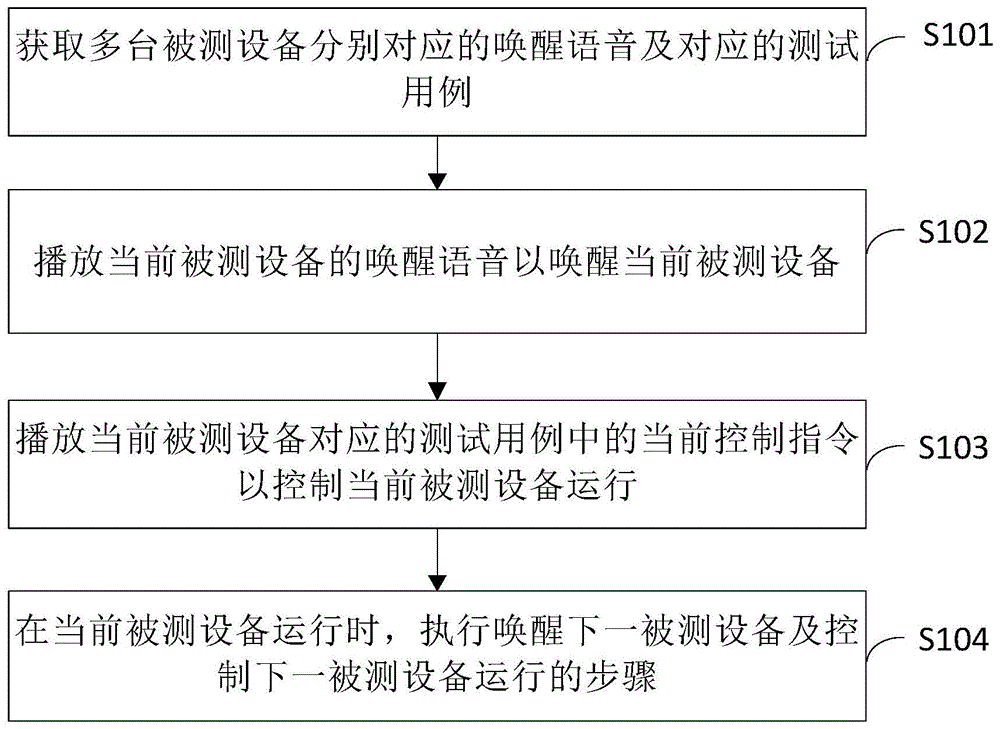
本申请提供一种语音测试方法、装置、设备、存储介质及程序产品。具体方案为:获取多台被测设备分别对应的唤醒语音及对应的测试用例;所述对应的测试用例中包括至少一个控制指令;所述多台被测设备分别对应的唤醒语音不同;播放当前被测设备的唤醒语音以唤醒当前被测设备;播放当前被测设备对应的测试用例中的当前控制指令以控制当前被测设备运行;在当前被测设备运行时,执行唤醒下一被测设备及控制下一被测设备运行的步骤。在当前被测设备按控制指令运行后,不等待当前被测设备运行完毕,就令下一被测设备按对应的控制指令运行可以节约测试时间,提高测试效率。
2024-06-17 -
音频插件的生成方法、装置、电子设备及可读存储介质

本申请实施例提供一种音频插件的生成方法、装置、电子设备及可读存储介质,涉及计算机技术领域,通过获取待模拟声频的至少一个关键元素以及各关键元素的音频参数,基于各关键元素的音频参数进行音频调制,形成待模拟声频的音频数据,对音频数据进行编译,得到待模拟声频的初始音频插件,基于初始音频插件中各控件的属性信息对初始音频插件进行重编译,得到待模拟声频的音频插件,通过对待模拟声频的关键元素的音频参数进行音频调整,形成音频数据,可以适配不同环境下的音频表现需求,具有更好的通用性和复用性,并通过编译和重编译得到待模拟声频的音频插件,能够大大节省了音频插件的制作成本、时间成本、人力成本,提高音频插件的制作效率。
2024-06-17 -
基于语音分析的森林枪声定位方法
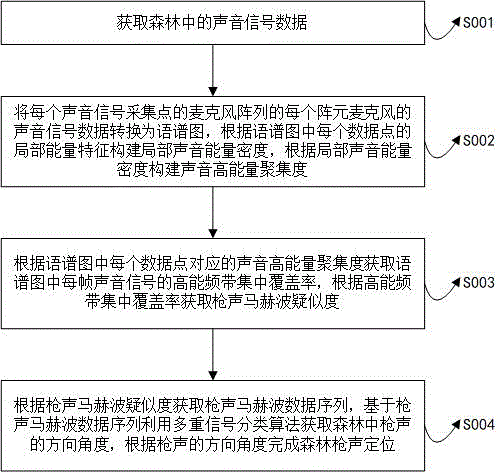
本申请涉及语音处理技术领域,提出了基于语音分析的森林枪声定位方法,包括:获取森林中的声音信号数据,将每个声音信号采集点的声音信号数据转换为语谱图,根据语谱图中每个数据点的局部能量特征构建局部声音能量密度,根据局部声音能量密度构建声音高能量聚集度,根据语谱图中每个数据点对应的声音高能量聚集度获取语谱图中每帧声音信号的高能频带集中覆盖率,根据高能频带集中覆盖率获取枪声马赫波疑似度,根据枪声马赫波疑似度获取枪声马赫波数据序列,基于枪声马赫波数据序列利用多重信号分类算法获取森林中枪声的方向角度,根据枪声的方向角度完成森林枪声定位。本申请通过马赫波数据序列获取枪声的方向角度,提高森林枪声定位的准确性。
2024-06-16 -
一种基于轻量级网络的无监督机器异常声音检测方法
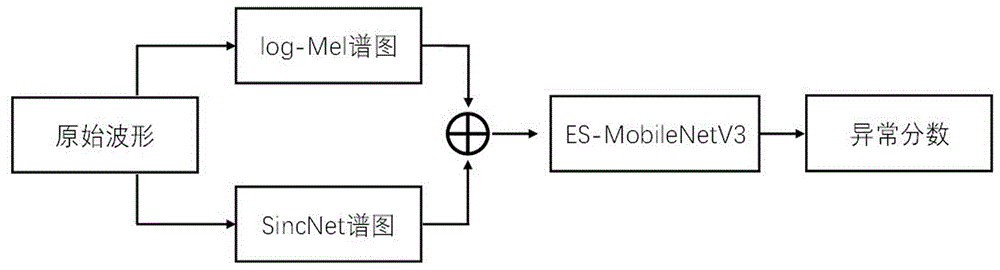
本发明针对工业场景下,异常声音检测的特征组合问题,提出了一种基于轻量级网络的无监督机器异常声音检测方法,该方法使用log‑Mel谱图和SincNet谱图融合特征作为输入,使得机器工作声音的特征信息更加丰富,有利于提高轻量化网络的检测性能。检测模型是在MobileNetV3主干网络中使用了更加轻量化的ES注意力机制,既可以避免池化过程中精细特征丢失的风险,又可以进一步减小模型的计算量,使得系统可以更好的部署在移动端设备,增强机器异常声检测的实用性和灵活性。该方法不仅适用于工业场景下机器工作声音信号的异常检测,也适用于各种异常声音检测任务的移动端部署。
2024-06-16 -
模型训练方法、装置、电子设备和介质
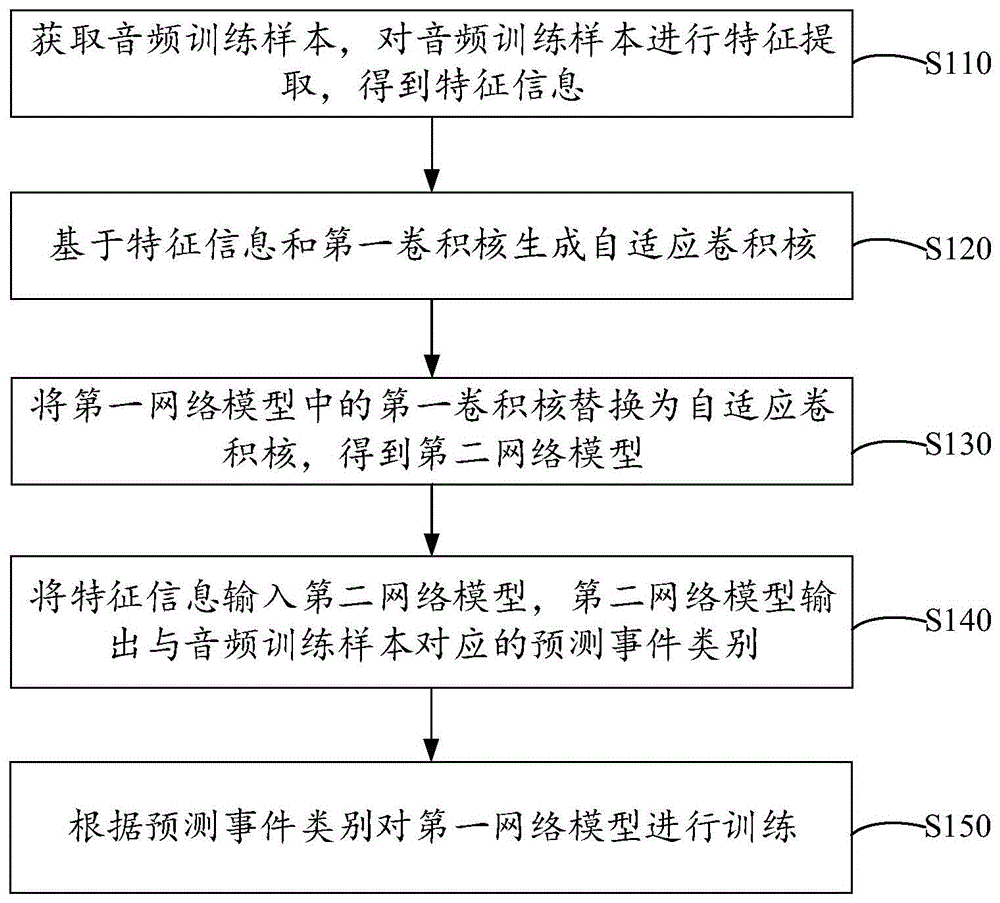
本申请公开了一种模型训练方法、装置、电子设备和介质,属于声音事件检测领域。模型训练方法包括获取音频训练样本,对音频训练样本进行特征提取,得到特征信息;基于特征信息和第一卷积核生成自适应卷积核,第一网络模型包括第一卷积核;将第一网络模型中的第一卷积核替换为自适应卷积核,得到第二网络模型;将特征信息输入第二网络模型,第二网络模型输出与音频训练样本对应的预测事件类别;根据预测事件类别对第一网络模型进行训练。
2024-06-16 -
一种语音交互方法、系统、计算机设备和存储介质
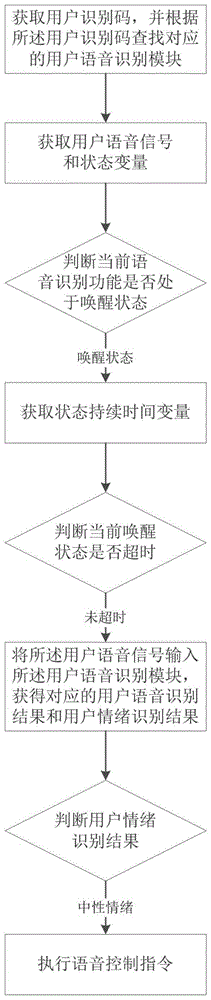
本申请涉及一种语音交互方法、系统、计算机设备和存储介质。所述方法包括:获取用户识别码,并查找对应的用户语音识别模块;获取用户语音信号和状态变量,并根据所述状态变量判断当前语音识别功能是否处于唤醒状态;响应于当前语音识别功能处于唤醒状态,获取状态持续时间变量,并判断当前唤醒状态是否超时;响应于当前唤醒状态未超时,将所述用户语音信号输入所述用户语音识别模块,获得对应的用户语音识别结果和用户情绪识别结果;根据所述用户情绪识别结果,确定是否执行语音控制指令;响应于所述用户情绪识别结果为中性情绪,执行所述语音控制指令。采用本方法能够实现个性化语音交互,并保证语音交互的安全性。
2024-06-16 -
基于深度学习的实时语音脱敏方法、装置、设备及存储介质
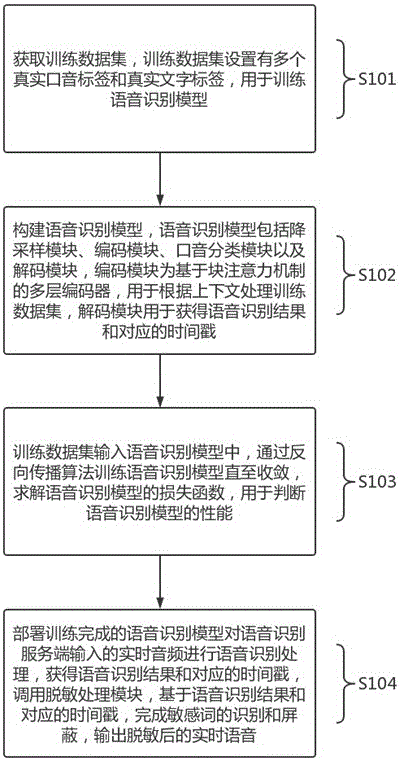
本发明提出了一种基于深度学习的实时语音脱敏方法、系统、设备及介质,方法包括:获取训练数据集;构建语音识别模型;将训练数据集输入语音识别模型中,通过反向传播算法训练语音识别模型直至收敛,求解语音识别模型的损失函数,用于判断语音识别模型的性能;将训练完成的语音识别模型部署于语音识别服务端,对输入的实时音频进行语音识别处理,调用脱敏处理模块,完成敏感词的识别和屏蔽,输出脱敏后的识别结果。本发明通过训练模型实现实时语音识别和脱敏处理,基于块注意力机制平衡模型的实时性和准确性,对口音识别具有较高的鲁棒性,同时加入时间戳提高脱敏处理的效率,实现了实时语音的精准脱敏。
2024-06-15 -
多系统融合的语音识别方法、装置、设备及可读存储介质
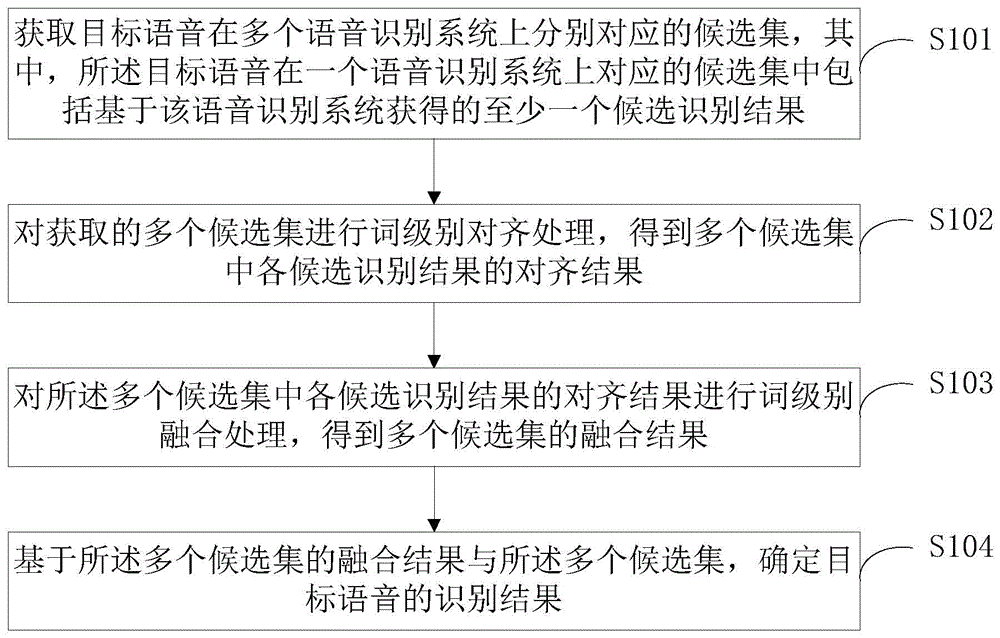
本申请公开了一种多系统融合的语音识别方法、装置、设备及可读存储介质。本方案中,首先获取目标语音在多个语音识别系统上分别对应的候选集,然后,对获取的多个候选集进行词级别对齐处理,得到多个候选集中各候选识别结果的对齐结果;对多个候选集中各候选识别结果的对齐结果进行词级别融合处理,得到多个候选集的融合结果;最后基于多个候选集的融合结果与多个候选集,确定目标语音的识别结果。在本方案中,每个候选识别结果的对齐结果是从多条候选对齐结果中择优选取的,对齐准确性更高,对多个候选集中各候选识别结果的对齐结果进行词级别融合处理,也更有利于得到更准确的融合结果,从而能够得到准确度更高的语音识别结果。
2024-06-15 -
一种音频处理方法、装置、设备及可读存储介质
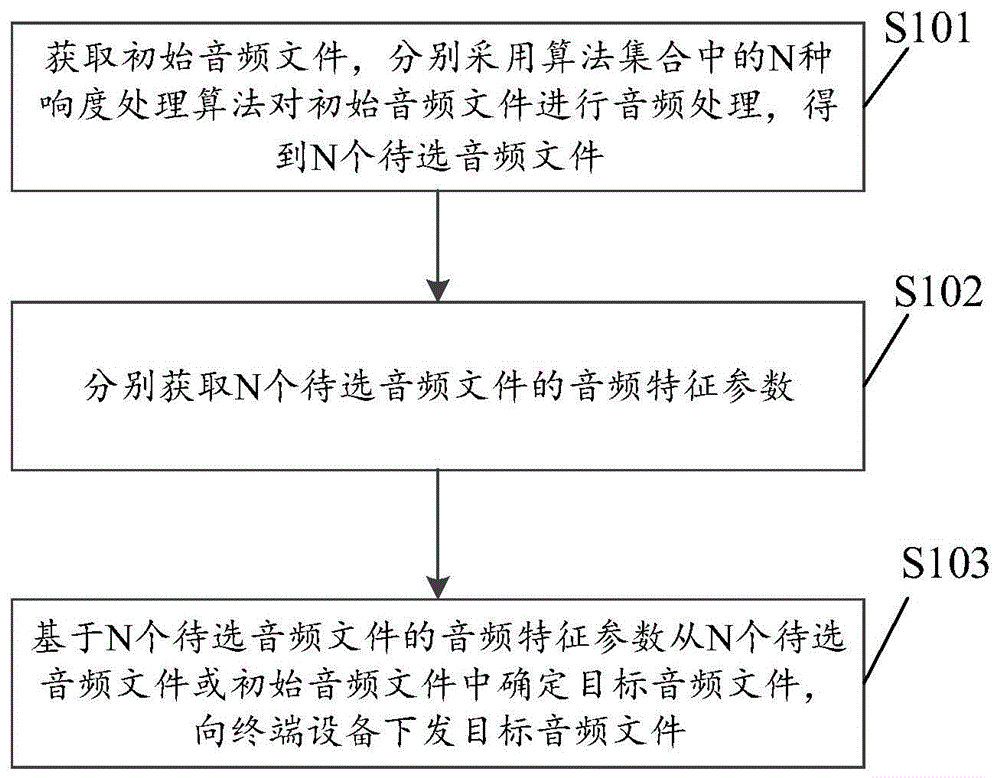
本申请实施例公开了一种音频处理方法、装置、设备及可读存储介质,其中,方法包括:获取初始音频文件,分别采用算法集合中的N种响度处理算法对该初始音频文件进行音频处理,得到N个待选音频文件;一种响度处理算法对应一个待选音频文件,N为正整数;分别获取该N个待选音频文件的音频特征参数;该音频特征参数用于指示待选音频文件的音频质量;基于该N个待选音频文件的音频特征参数从该N个待选音频文件或该初始音频文件中确定目标音频文件,向终端设备下发该目标音频文件。采用本申请实施例,可以提升音频文件的质量,减少音频刺耳的情况,减少用户投诉,进而提升用户体验。
2024-06-15 -
一种基于音频的电网频率实时跟随与篡改鉴别方法及系统
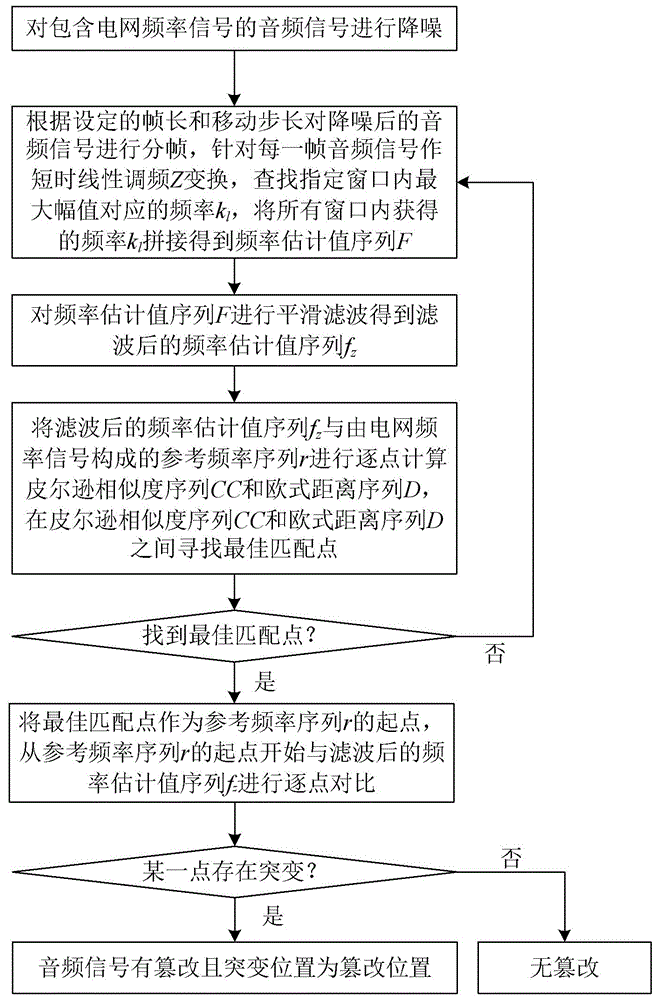
本发明公开了一种基于音频的电网频率实时跟随与篡改鉴别方法及系统,本发明方法包括对包含电网频率的音频信号进行降噪、分帧、短时线性调频Z变换,查找指定窗口内最大幅值对应的频率kl,将所有窗口内获得的频率拼接,得到频率估计值序列F,对其进行平滑滤波得到滤波后的频率估计值序列fz,然后将其与参考频率序列r进行逐点计算皮尔逊相似度CC和欧式距离D,得到最佳匹配点,最后将最佳匹配点作为参考频率序列r的起点与fz进行对比,根据是否突变进行篡改判断。本发明旨在实现对电网频率信号的准确提取,尤其是在低信噪比条件下电网频率信号的准确提取,以及实现对包含电网频率的音频信号实现基于电网频率信号的实时跟随与篡改鉴别。
2024-06-15 -
一种含有金属螺旋结构和空腔结构的组合型吸声覆盖层
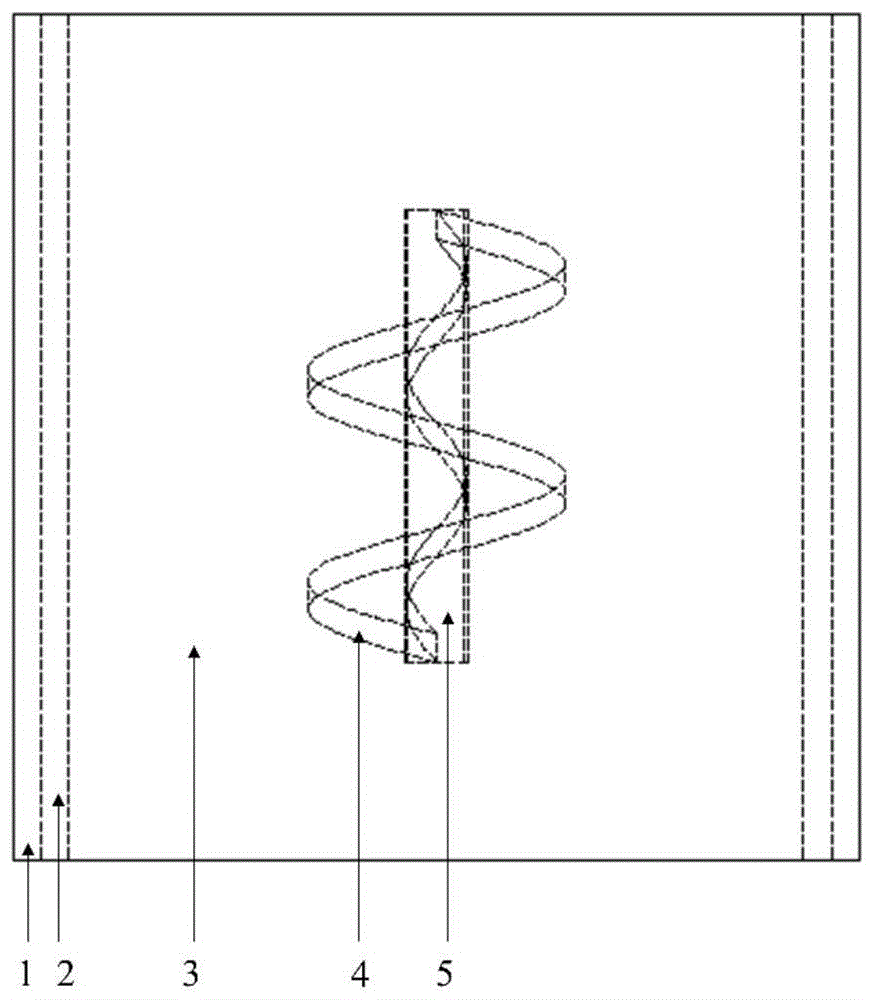
本发明公开了一种含有金属螺旋结构和空腔结构的组合型吸声覆盖层,涉及减振降噪装置技术领域。包括软质橡胶层、基体橡胶层、金属螺旋结构和空腔结构,所述基体橡胶层内部嵌入金属螺旋结构,基体橡胶层外部紧贴有软橡胶质层,且所述金属螺旋结构内部嵌入空腔结构。本发明的吸声覆盖层由基体橡胶层,软质橡胶层,金属螺旋结构和空腔结构构成,通过金属螺旋结构的引入使基体橡胶层产生反向运动,与入射波引起的基体橡胶位移方向相反,两个方向的运动在一定程度上可以相互抵消,消耗了入射声波能量并有效提升了吸声性能。
2024-06-15 -
可通过语音配置参数的电子装置及其方法
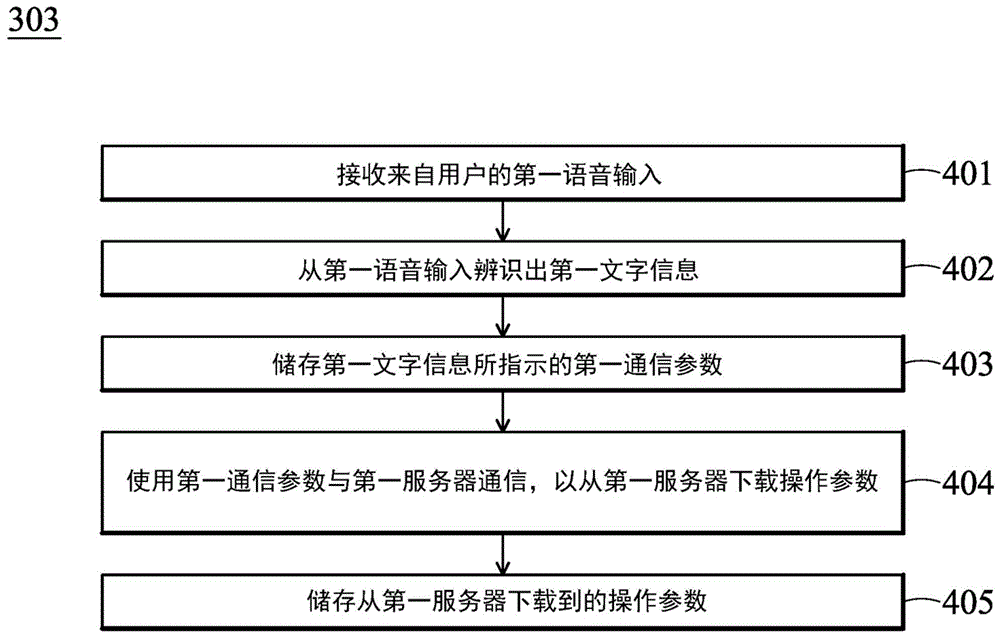
本发明提供一种可通过语音配置参数的电子装置及其方法,该电子装置包含储存单元、语音输入设备、语音辨识模块及控制模块。语音输入设备用以接收来自用户的第一语音输入。语音辨识模块配置以从语音输入设备接收第一语音输入,及从第一语音输入辨识出第一文字信息。控制模块配置以从第一语音辨识模块接收第一文字信息。控制模块更配置以将第一文字信息所指示的第一通信参数储存至储存单元。控制模块更配置以使用第一通信参数与第一服务器通信,以从第一服务器下载多个操作参数。控制模块更配置以将从第一服务器下载的操作参数储存至储存单元。仅需通过语音配置最关键的第一通信参数,即可自动取得其他所有参数。
2024-06-14 -
基于深度学习的智能语音识别交互方法和系统
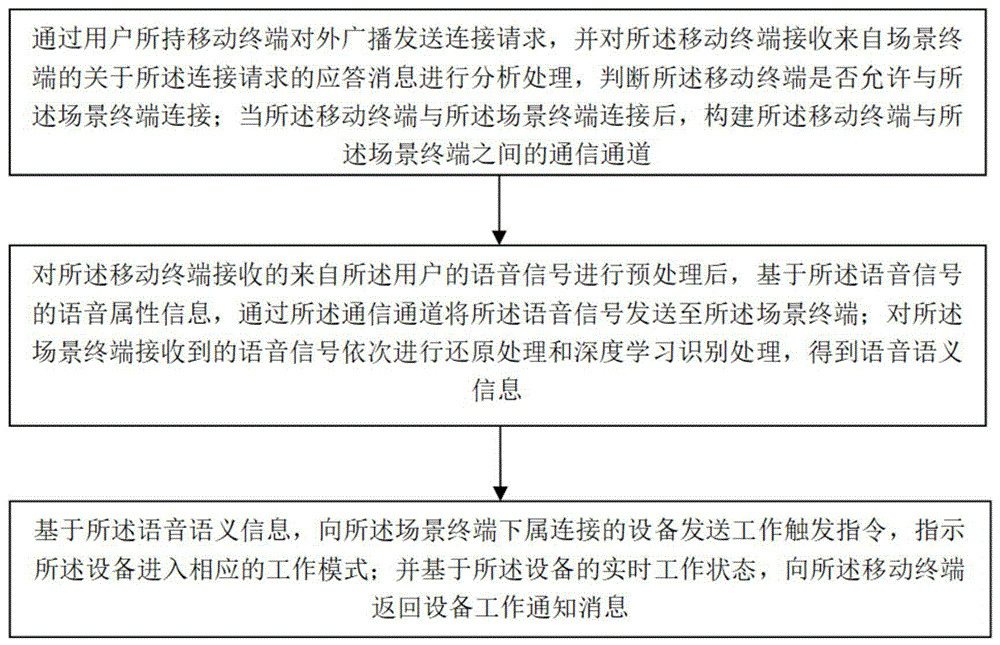
本发明提供基于深度学习的智能语音识别交互方法和系统,其通过移动终端对外发送连接请求,并分析场景终端返回的应答消息,将移动终端与场景终端连接,并构建两者的通信通道,实现移动终端与场景终端的专用语音通信;再对来自用户的语音信号进行预处理后,基于语音属性信息,发送至场景终端,以此对语音信号进行还原和深度学习识别,得到语音语义信息,便于通过场景终端根据语音语义信息,向下属连接的设备发送工作触发指令,从而在不同场合下对应的设备进行直接高效的控制,提高对移动终端在不同场合下的语音识别控制可靠性。
2024-06-14 -
语音合成方法、装置、电子设备及计算机可读存储介质
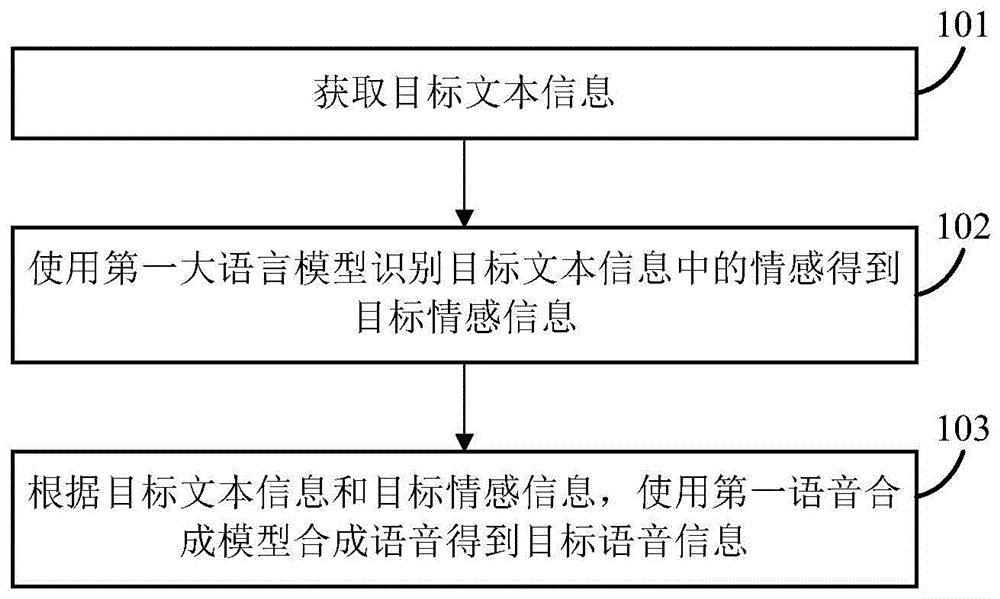
本申请公开了一种语音合成方法、装置、电子设备及计算机可读存储介质,该方法包括:获取目标文本信息;使用第一大语言模型识别所述目标文本信息中的情感,得到目标情感信息,所述目标情感信息包括一个或多个情感信息,所述多个情感信息包括不同级别的情感信息;根据所述目标文本信息和所述目标情感信息,使用第一语音合成模型合成语音得到目标语音信息。本申请实施例中,在合成语音的时候,使用了文本信息对应的情感信息,可以使合成的语音信息带有相应的感情,降低了合成的语音信息的机械性,从而可以提高合成语音的自然度和适用性。
2024-06-14 -
无监督学习的语音增强模型的训练方法、系统和电子设备
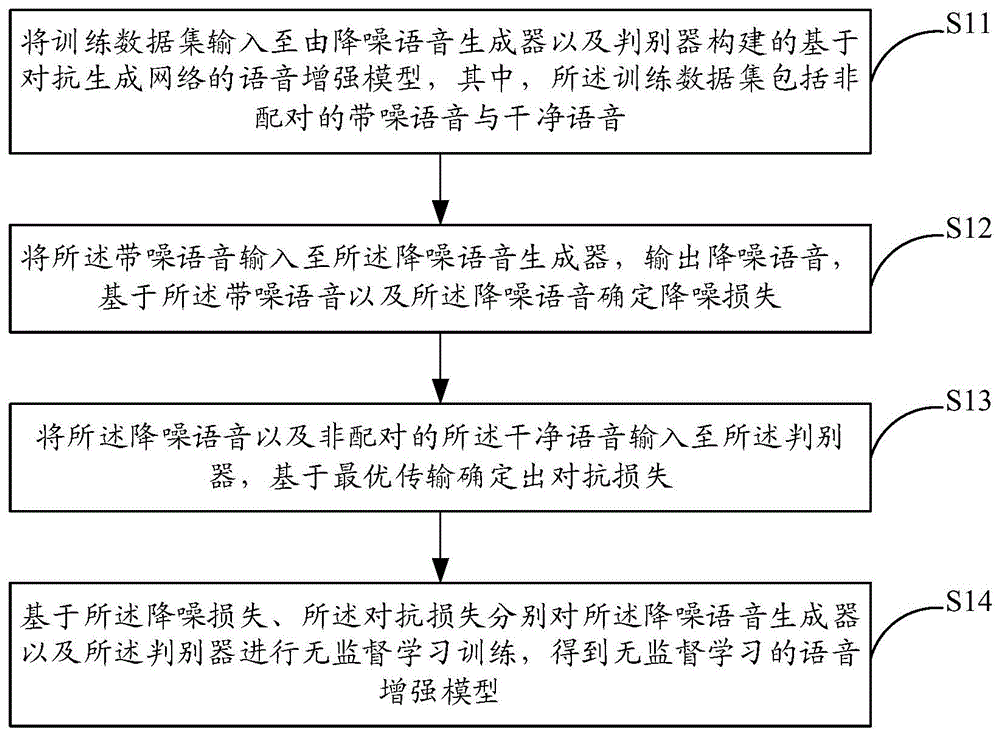
本发明实施例提供一种无监督学习的语音增强模型的训练方法、系统和电子设备。该方法包括:将训练数据集输入至由降噪语音生成器以及判别器构建的基于对抗生成网络的语音增强模型;将带噪语音输入至降噪语音生成器,输出降噪语音,基于带噪语音以及降噪语音确定降噪损失;将降噪语音以及非配对的干净语音输入至判别器,基于最优传输确定出对抗损失;基于降噪损失、对抗损失分别对降噪语音生成器以及判别器进行无监督学习训练,得到无监督学习的语音增强模型。本发明实施例将最优传输的无监督训练应用到对抗生成网络的语音增强中。规避了一对一的带噪语音‑纯净语音数据对的使用,训练出了更有效的语音增强模型。
2024-06-14 -
数字图像捕获会话和元数据关联
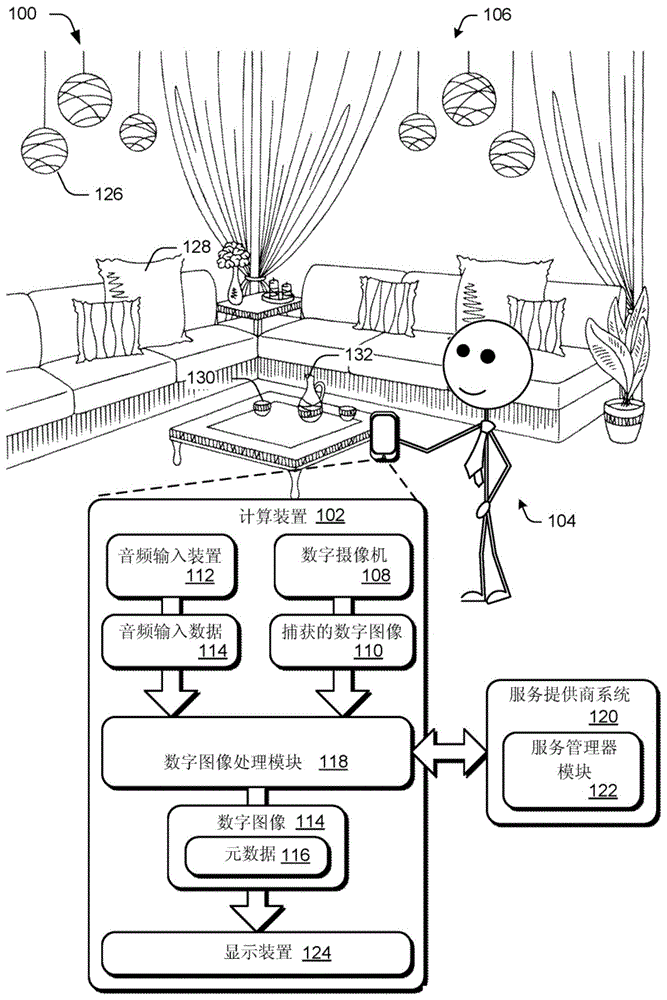
本公开内容涉及用于处理图像的由计算装置实现的方法、用于处理图像的系统和用于处理图像的计算装置。描述了数字图像捕获会话和元数据关联技术。在一个示例中,接收用户输入以发起图像捕获会话。在图像捕获会话期间使用数字摄像机捕获至少一个数字图像。在图像捕获会话期间还使用音频输入装置收集音频输入数据,并将音频输入数据转换成文本数据,例如语音至文本。元数据是基于文本数据生成的并且与至少一个数字图像相关联。作为图像捕获会话的完成,将至少一个数字图像输出为具有相关联的元数据。
2024-06-13 -
音频信号的处理方法、装置、音频设备及存储介质
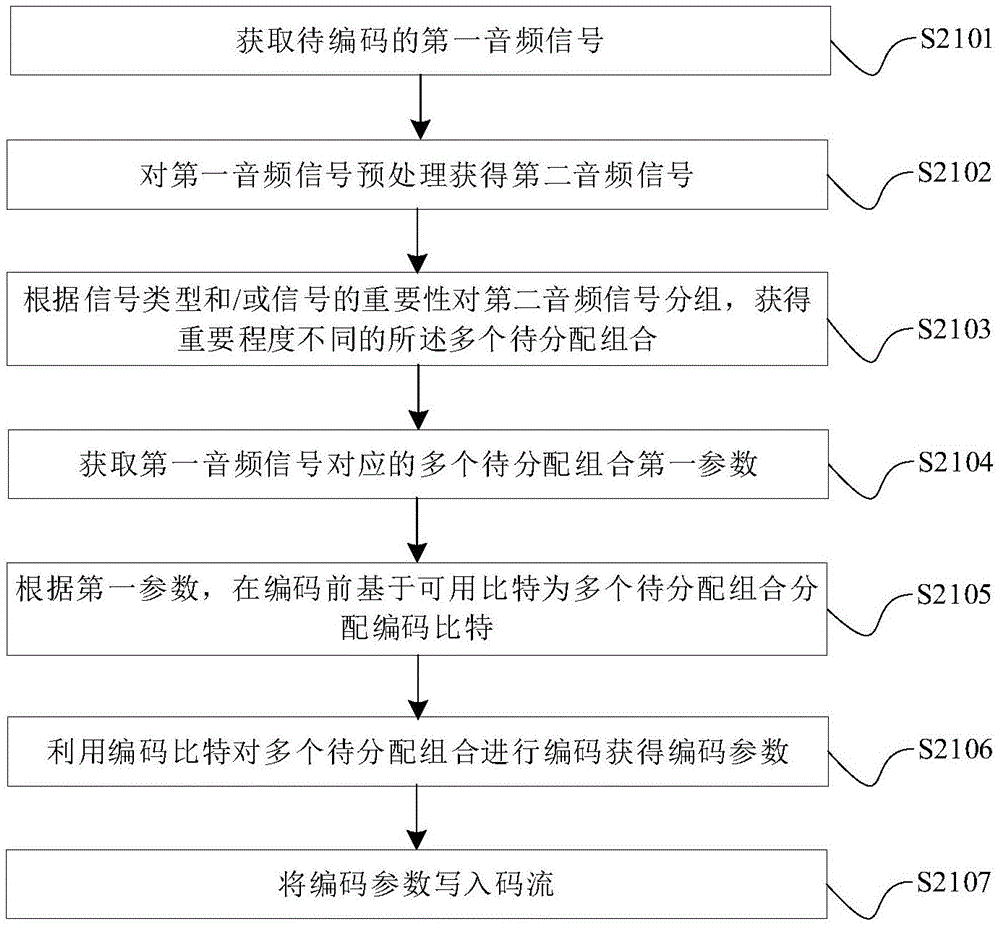
本公开提供一种音频信号的处理方法、装置、音频设备及存储介质。方法包括:获取第一音频信号对应的多个待分配组合的第一参数,所述第一参数用于指示所述多个待分配组合的重要程度;根据所述第一参数,在编码前基于可用比特为所述多个待分配组合分配编码比特。本公开的方法中,根据第一音频信号中不同待分配组合的第一参数,在编码前适应性的分配待分配组合的编码比特,从而根据待分配组合的重要性更好的指导编码比特的分配,便于提升信号音质,进而提升编码质量。
2024-06-13 -
基于端到端的人-机器人语音交互系统
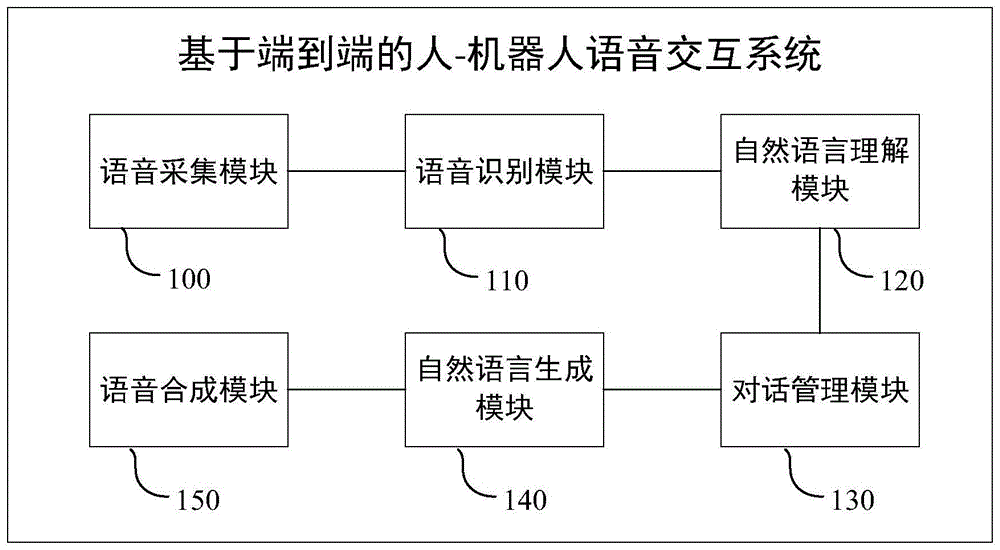
本发明提供一种基于端到端的人‑机器人语音交互系统,该系统应用于机器人,包括:语音采集模块,用于采集用户的音频信号;语音识别模块,用于基于端到端的语音识别模型,得到音频信号的文本结果;自然语言理解模块,用于基于语义向量之间的距离识别出文本结果的相似语句,相似语句作为文本结果的语义理解结果;对话管理模块,用于根据相似语句从数据库中选择相应的回复语句或者执行相应的动作指令;自然语言生成模块,用于根据回复语句生成回复文本;语音合成模块,用于将回复文本转换成语音进行输出。本发明提供的系统,不仅提升了语音识别的准确率,而且提升了语义理解的准确度,从而能够大大提升该系统在相应任务场景下的表现。
2024-06-13